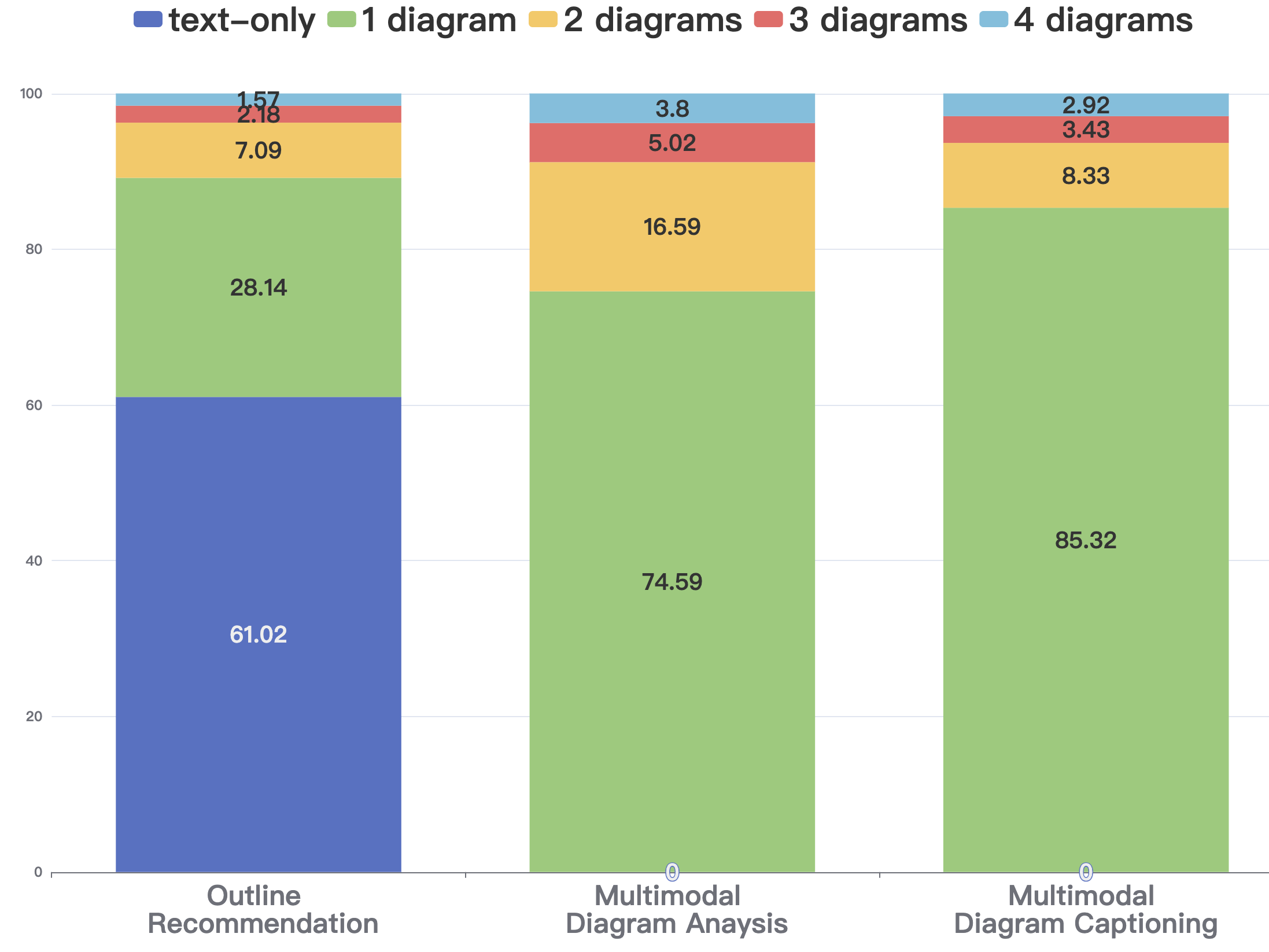
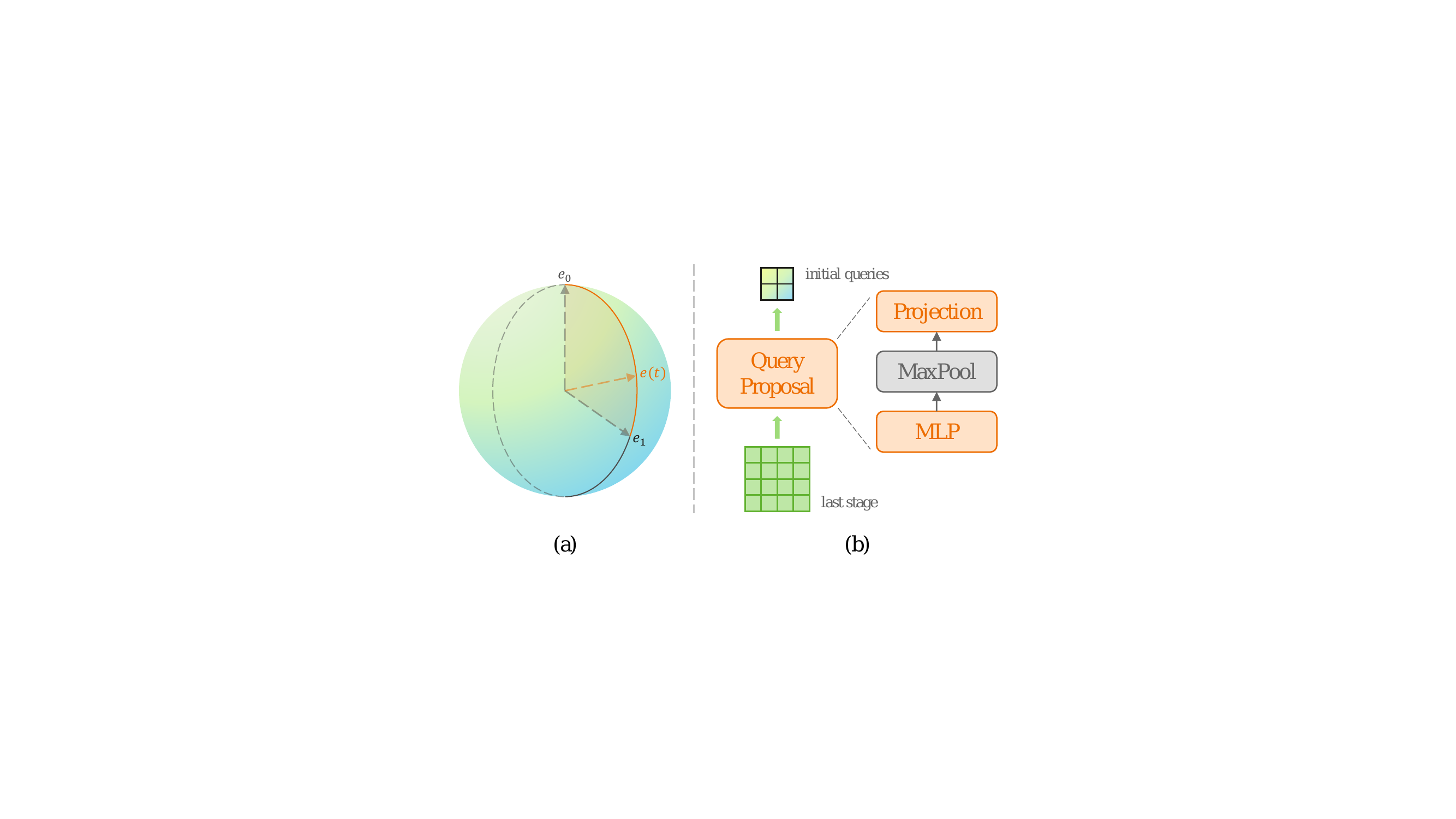
We review in this post the literature on Vision-Language Models for fine-grained images (documents).What are VLMs?Vision-Language Models
, also known as "Multimodal Models" (with image and text as modalities), take an image as input
(such as a natural image or a document page
or multiple document pages for multi-page document models in our case) and a prompt as input
(a question for QA, an instruction, or nothing for single-task models). These models process the inputs with a decoder (a language model)
to return an output in natural language
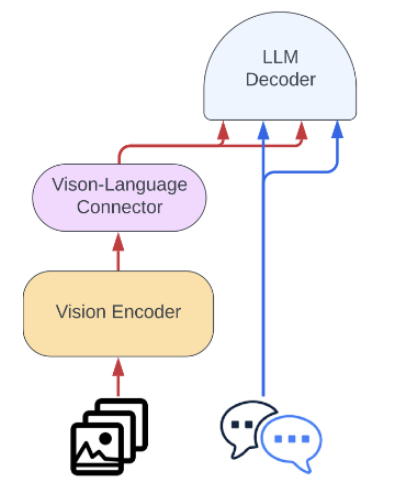
(the answer to a question for QA tasks, a response to an instruction for instruction-type inputs, a class for classification tasks, a JSON of entities extracted for entity extraction tasks, etc.). The architecture of VLMs
includes an image encoder
and a language model decoder
, which takes both the image representation and text input
(such as a question for QA or an instruction for instructional tasks). A projection layer (also called "Vision-Language Connector)
is placed between the visual representation and the Language Model to convert the visual data into a format understandable by the LLM
. This projection layer is trained using techniques like cross-attention, masked-language modeling, and image-text matching to link visual semantics with textual representations. This VLM structure is presented in this image from [Llava's paper](https://arxiv.org/pdf/2304.08485):  or here:
with a concrete example in [Llava1.5's paper](https://arxiv.org/pdf/2310.03744): 
Many VLMs have been released recently. Here is a timeline of the main released VLMs depicted in [LLaVA-Next's paper](https://arxiv.org/pdf/2406.16860):
What are Fine-Grained Images?Fine-grained images
(in this context, documents) are images that contain text and numerous details
(such as graphs, charts with text, etc.). In such images, each detail is crucial, and the images must be high-resolution
since every detail (character, element in the image) matters, as opposed to natural images. An example of Document Understanding task on fine-grained documents is presented in the [Fox's paper](https://arxiv.org/pdf/2405.14295): 
Organisation of this blog post:
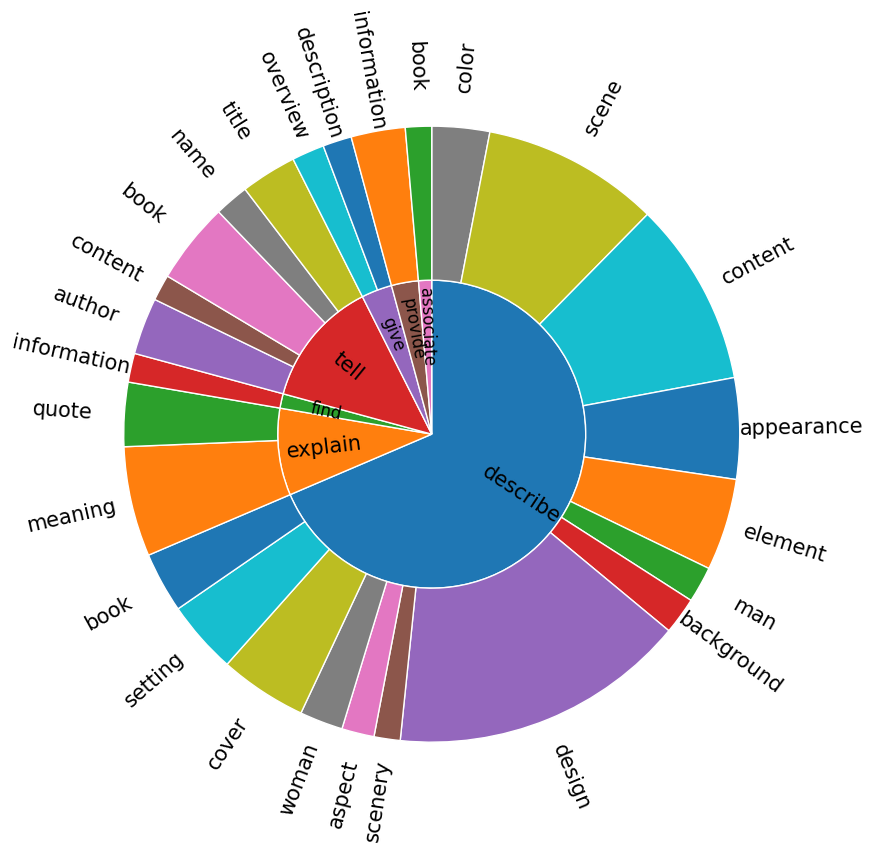
We can classify Visual-Language Models handling fine-grained images into three categories: those using low-grained vision models with an LLM as a decoder(1.)
those using both (a fine-grained vision model and an LLM as a decoder)
through various techniques (2.)
, and those using fine-grained vision models but a small language decoder(3.)
.
##
1. Models using low-grained vision model and a LLM as decoder
These models are classic vision-language models
(not specialized for fine-grained images). To be capable of understanding fine-grained images, some classic vision-language models were trained on text-rich images.
These classic vision-language models work with a projection layer between the vision encoder and the LLM
. Indeed, for the LLM to effectively understand and interact with the visual encoder's data, it is necessary that the representations generated by the encoder are in a format or context that is understandable to the LLM. This means that visual data must be transformed into a representation that makes sense in the linguistic domain. That's why an intermediary (a projection matrix) between the visual encoder and the LLM decoder is added. This projection layer helps to semantically align visual representations with textual representations. This means that similar visual concepts are mapped to close semantic spaces in the feature space of the LLM, thus facilitating the understanding and generation of language in relation to visual inputs.
Can we take a pretrained vision encoder and LLM or should we fine-tune them to construct a VLM? And which Vision encoder / LLM to use?
Traditional VLMs use a pretrained ViT as vision encoder
(either CLIP-ViT-H/L
([InternLM-XComposer2-4KHD](https://arxiv.org/pdf/2404.06512), [VL-Mamba](https://arxiv.org/pdf/2403.13600), [Ferret-UI](https://arxiv.org/pdf/2404.05719), [Vary](https://arxiv.org/pdf/2312.06109), [Llava-HR](https://arxiv.org/pdf/2403.03003), [Llava-UHD](https://arxiv.org/pdf/2403.11703), [UReader](https://arxiv.org/pdf/2310.05126), [UniDoc](https://arxiv.org/pdf/2308.11592), [LLaVAR](https://arxiv.org/pdf/2306.17107), [mPLUG-Owl](https://arxiv.org/pdf/2304.14178), [Llava](https://arxiv.org/pdf/2304.08485), [LaRA](https://arxiv.org/pdf/2406.06730)), CLIP-ViT-BigG ([QwenVL](https://arxiv.org/pdf/2308.12966), [Monkey](https://arxiv.org/pdf/2311.06607)), EVA-CLIP
([BLIP2](https://arxiv.org/pdf/2301.12597), [MiniGPT4](https://arxiv.org/pdf/2304.10592), [CogAgent](https://arxiv.org/pdf/2312.08914)), SigLIP
([Tinychart](https://arxiv.org/pdf/2404.16635), [TextHawk](https://arxiv.org/pdf/2404.09204), [Idefics2](https://arxiv.org/pdf/2405.02246)), NFNet
([Flamingo](https://arxiv.org/pdf/2204.14198)), Swin Transformer
([DocPedia](https://arxiv.org/pdf/2311.11810), [DocParser](https://arxiv.org/pdf/2304.12484), [DONUT](https://arxiv.org/pdf/2111.15664), [Nougat](https://arxiv.org/pdf/2308.13418))...)
Traditional VLMs use a pretrained LLM as decoder, usually with 7 or 13B parameters
, like Llama1-2
([UReader](https://arxiv.org/pdf/2310.05126), [mPLUG-DocOwl1.5](https://arxiv.org/pdf/2403.12895), [Llava-HR](https://arxiv.org/pdf/2403.03003), [mPLUG-PaperOwl](https://arxiv.org/pdf/2311.18248), [mPLUG-DocOwl](https://arxiv.org/pdf/2307.02499)), InternLM1-2
([InternLM-XComposer2-4KHD](https://arxiv.org/pdf/2404.06512), [TextHawk](https://arxiv.org/pdf/2404.09204)), Vicuna
([Ferret-UI](https://arxiv.org/pdf/2404.05719), [Llava-UHD](https://arxiv.org/pdf/2403.11703), [DocPedia](https://arxiv.org/pdf/2311.11810), [LLaVAR](https://arxiv.org/pdf/2306.17107), [MiniGPT4](https://arxiv.org/pdf/2304.10592), [Llava](https://arxiv.org/pdf/2304.08485), [LaRA](https://arxiv.org/pdf/2406.06730)), Mistral
([Idefics2](https://arxiv.org/pdf/2405.02246)), Phi-2 ([Tinychart](https://arxiv.org/pdf/2404.16635)), OPT
([BLIP2](https://arxiv.org/pdf/2301.12597), [Vary](https://arxiv.org/pdf/2312.06109)), Qwen
([Monkey](https://arxiv.org/pdf/2311.06607), [TextMonkey](https://arxiv.org/pdf/2403.04473), [QwenVL](https://arxiv.org/pdf/2308.12966)) or FlanT5XXL
([BLIP2](https://arxiv.org/pdf/2301.12597)) (chat / instruct versions).
The paper [What matters when building vision-language models?](https://arxiv.org/pdf/2405.02246) has shown that for a fixed number of parameters, the quality of the language model has a higher impact on the performance of the final VLM than the quality of the vision encoder
.
How the projection layer works?
As shown in the paper [What matters when building vision-language models?](https://arxiv.org/pdf/2405.02246), there are 2 types of projection layer
: (1) the cross-attention architectures
, in which the encoding of the image is injected at different layers within the language model by interleaving cross-attention blocks in which the text cross-attends to the image hidden states, and (2) the fully autoregressive architectures
in which the encoding of the image is directly concatenated to the sequence of text embeddings, and the entire sequence is passed as input to the language model.
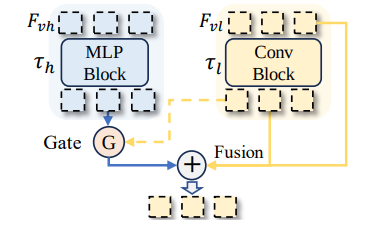
Models with a projection layer defined as cross-attention architecture
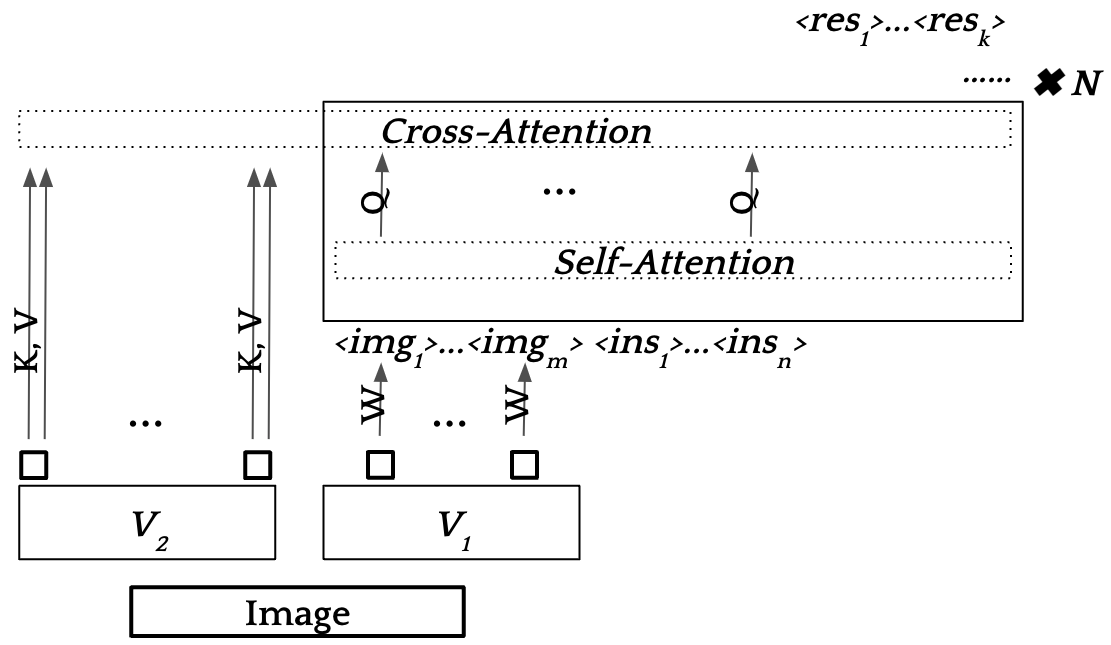
The cross-attention architecture (1) of the projection layer is depicted in the Perceiver Resampler layer
, implemented in [Flamingo](https://arxiv.org/pdf/2204.14198), [Kosmos 2.5](https://arxiv.org/pdf/2309.11419), and [Monkey](https://arxiv.org/pdf/2311.06607) as a "shared resampler", which uses cross-attention layer between text (query) and visual tokens (key and values) as depicted in the following shema from [Flamingo's paper](https://arxiv.org/pdf/2204.14198):
The Q-Former layer
is also in this category, implemented in [BLIP-2](https://arxiv.org/pdf/2301.12597), [MiniGPT-4](https://arxiv.org/pdf/2304.10592) and [InstructDr](https://arxiv.org/pdf/2401.13313) as a "Document-Former". It extracts relevant features from the image representation with learnable queries, and adds the input text representation through attention mechanism. The result is then used as input to the LLM, as presented in the following shema from [BLIP-2's paper](https://arxiv.org/pdf/2301.12597) : .
The Partial LoRA module
is also in this category, implemented in [InternLM-XComposer2](https://arxiv.org/pdf/2401.16420) and in [InternLM-XComposer2-4KHD](https://arxiv.org/pdf/2404.06512)'s papers.
Models with a projection layer defined as fully autoregressive architecture
The fully autoregressive architectures (2) is depicted in the linear projection layers (MLP)
from [Llava](https://arxiv.org/pdf/2304.08485), [LLaVAR](https://arxiv.org/pdf/2306.17107), [UniDoc](https://arxiv.org/pdf/2308.11592), [DocPedia](https://arxiv.org/pdf/2311.11810), [Vary](https://arxiv.org/pdf/2312.06109), [Tinychart](https://arxiv.org/pdf/2404.16635), [InternLM-XComposer2-4KHD](https://arxiv.org/pdf/2404.06512) and [Idefics2](https://arxiv.org/pdf/2405.02246) which project linearly the visual representation to another space and then this transformed representation is concatenated with the textual input and fed into the language model, as well as in the Visual Abstractor Layer
, implemented in [mPLUG-Owl](https://arxiv.org/pdf/2304.14178), [mPLUG-DocOwl](https://arxiv.org/pdf/2307.02499), [mPLUG-PaperOwl](https://arxiv.org/pdf/2311.18248) and [UReader](https://arxiv.org/pdf/2310.05126), which concatenates a selection of image patchs (done through the addition of learnable tokens interracting with visual patchs through cross-attention mechanism) to textual tokens, as well as in the H-Reducer layer
, implemented in [mPLUG-DocOwl1.5](https://arxiv.org/pdf/2403.12895), which concatenated the reduced representation of the endoded image (convolution techniques) to the text representation, and the concatenated result is then fed to the LLM.
The paper [What matters when building vision-language models?](https://arxiv.org/pdf/2405.02246) has shown that the cross-attention architecture (1) performs better than the fully autoregressive one (2) when pre-trained Vision and Language models are kept frozen
. However, when fine-tuning them, the fully autoregressive architecture outperforms the cross-attention one, even though the latter has more parameters.
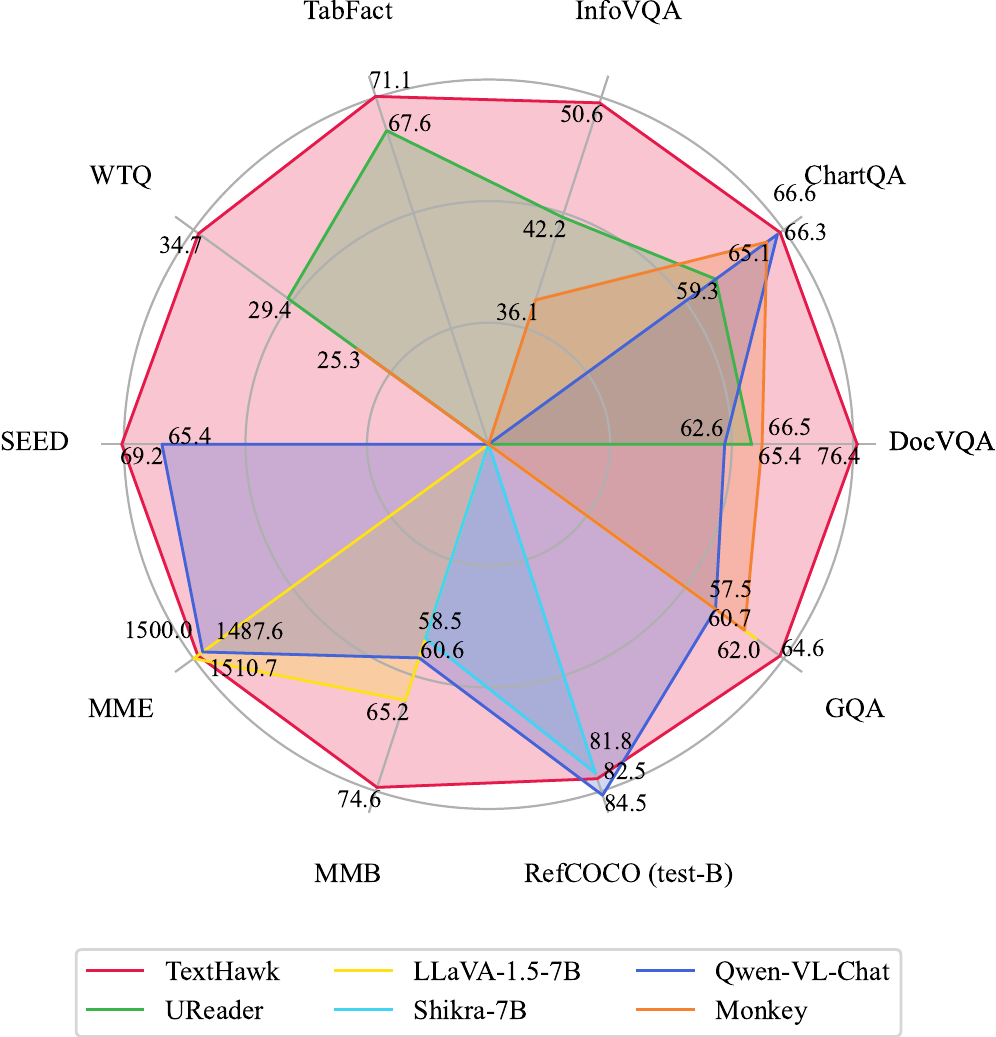
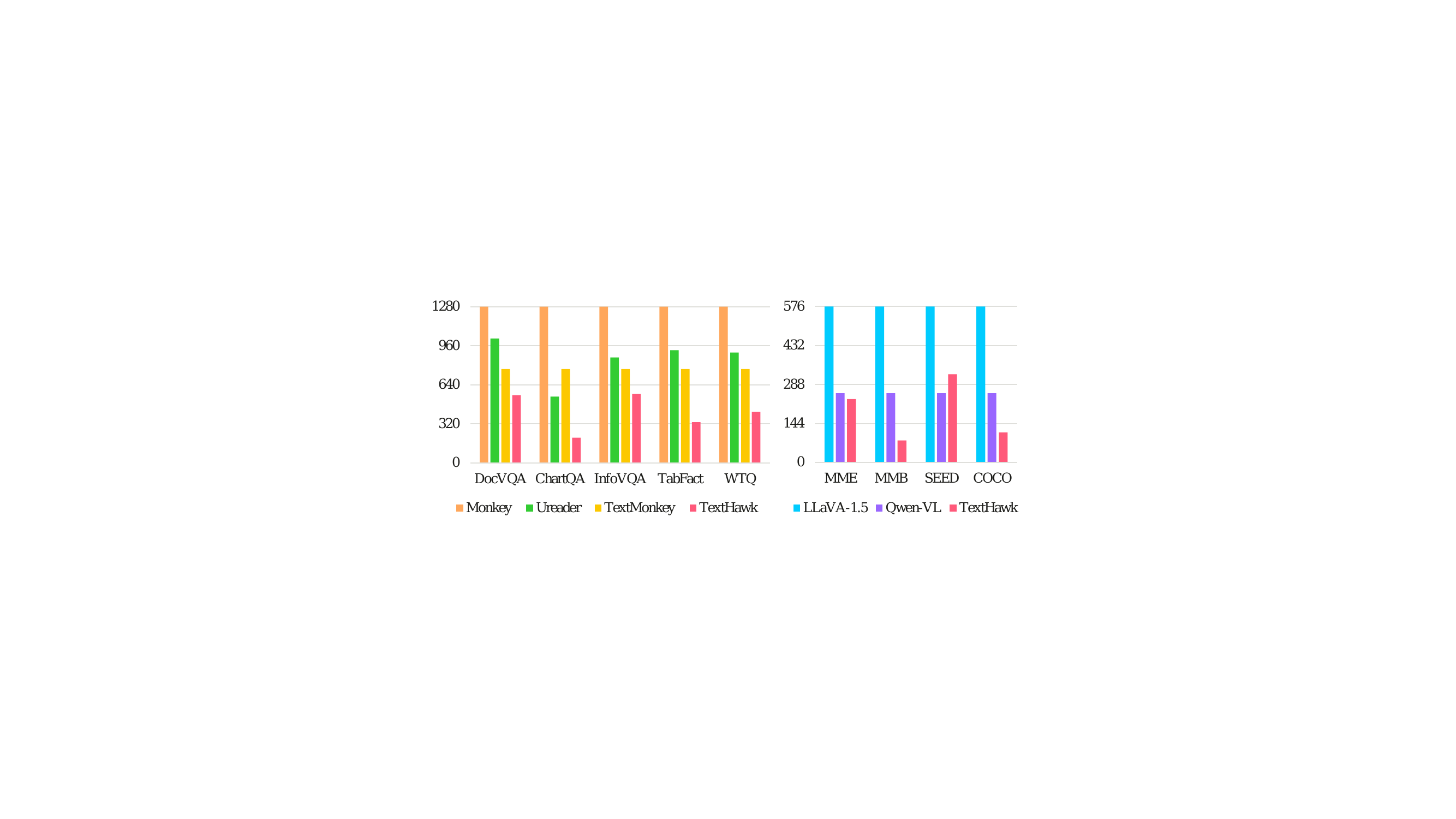
Below are some examples of classic vision-language models:
Matryoshka Multimodal Models
2024-05-27
Mu Cai, Jianwei Yang, Jianfeng Gao, Yong Jae Lee
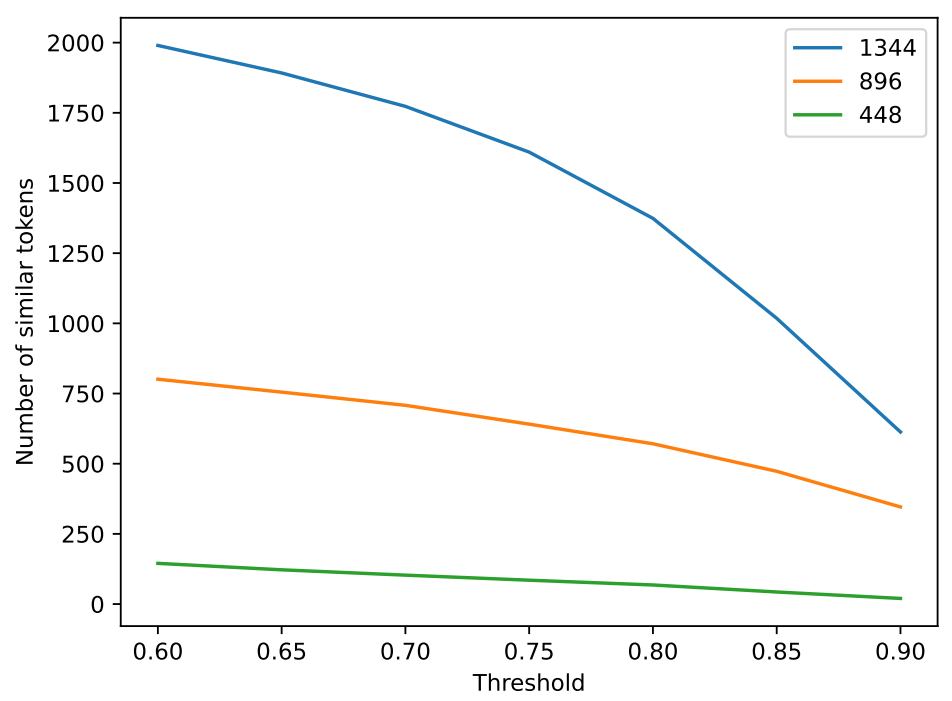
Large Multimodal Models (LMMs) such as LLaVA have shown strong performance in visual-linguistic reasoning. These models first embed images into a fixed large number of visual tokens and then feed them into a Large Language Model (LLM). However, this design causes an excessive number of tokens for dense visual scenarios such as high-resolution images and videos, leading to great inefficiency. While token pruning/merging methods do exist, they produce a single length output for each image and do not afford flexibility in trading off information density v.s. efficiency. Inspired by the concept of Matryoshka Dolls, we propose M3: Matryoshka Multimodal Models, which learns to represent visual content as nested sets of visual tokens that capture information across multiple coarse-to-fine granularities. Our approach offers several unique benefits for LMMs: (1) One can explicitly control the visual granularity per test instance during inference, e.g. , adjusting the number of tokens used to represent an image based on the anticipated complexity or simplicity of the content; (2) M3 provides a framework for analyzing the granularity needed for existing datasets, where we find that COCO-style benchmarks only need around ~9 visual tokens to obtain accuracy similar to that of using all 576 tokens; (3) Our approach provides a foundation to explore the best trade-off between performance and visual token length at sample level, where our investigation reveals that a large gap exists between the oracle upper bound and current fixed-scale representations.
Show Paper Content
# Introduction
Large Multimodal
models (LMMs) [GPT4V_System_Card](https://cdn.openai.com/papers/GPTV_System_Card.pdf), [liu2023llava](http://arxiv.org/pdf/2402.11690v1), [zhu2023minigpt](http://arxiv.org/pdf/2402.17510v1), [liu2024llavanext](https://llava-vl.github.io/blog/2024-01-30-llava-next/), [liu2023improvedllava](http://arxiv.org/pdf/2310.19145v1), [wang2023cogvlm](https://arxiv.org/pdf/2311.03079), [Qwen-VL](http://arxiv.org/pdf/2308.12966v3)
have shown strong performance in visual-linguistic understanding and
reasoning. Models such as
LLaVA [liu2023llava](http://arxiv.org/pdf/2402.11690v1), [liu2023improvedllava](http://arxiv.org/pdf/2310.19145v1), [liu2024llavanext](https://llava-vl.github.io/blog/2024-01-30-llava-next/)
first embed the input image with a fixed number of visual tokens, and
then feed them as prefix tokens to a Large Language Model
(LLM) [Vicuna](https://vicuna.lmsys.org/), [llama-3](https://ai.meta.com/blog/meta-llama-3/) to reason about the input image.
Similar model designs are borrowed in video
LMMs [lin2023video](http://arxiv.org/pdf/2311.10122v2), [zhang2023video](http://arxiv.org/pdf/2311.12919v2), where each frame
contributes a fixed number of tokens to form the final video
representation.
In reality, the number of visual tokens can be prohibitively large in
the case of high-resolution images, and even more so for long videos.
Existing
works [lin2023video](http://arxiv.org/pdf/2311.10122v2), [liu2024llavanext](https://llava-vl.github.io/blog/2024-01-30-llava-next/), [zhang2024llavanextvideo](https://llava-vl.github.io/blog/2024-04-30-llava-next-video/), [geminiteam2024gemini](https://arxiv.org/pdf/2312.11805)
mainly tackle this issue by increasing the input context length and
consequently, feeding a large number -8k of visual tokens into the LLM.
This approach has a couple of significant drawbacks: (1) the extremely
long context makes both training and inference inefficient; (2) an
excessive number of visual tokens can actually *harm* the LMM’s
performance, distracting it from attending to the relevant information,
as we show in
Sec. [sec:exp:video
understanding]. Several recent
works [bolya2023tome](None), [chen2024image-fastv](http://arxiv.org/pdf/2403.06764v2), [shang2024LLaVA-PruMerge](http://arxiv.org/pdf/2403.15388v5)
use heuristics to prune and merge visual tokens to reduce the sequence
length. However, they produce a single-length output and *do not afford
control over the final sequence length*, which could be useful to trade
information density versus efficiency while accounting for resource
constraints in the deployment phase.
Images and videos naturally exhibit a hierarchical structure from coarse
to fine details, and our human visual system has evolved to recognize
visual information in this coarse to fine manner, as shown by biologists
and psychologists decades
ago [harris2000coarse](http://arxiv.org/pdf/2208.13560v1), [hegde2008time](http://arxiv.org/pdf/2108.02839v1). Can we create a
similar structure for LMMs, where within one suite of model weights, the
visual content tokens are organized into different scales of
granularities? Conceptually, our goal is to learn the visual tokens to
have a nested structure, similar to the Matryoshka
Doll [kusupati2022matryoshka](http://arxiv.org/pdf/2405.17430v1). Matryoshka Representation
Learning (MRL) [kusupati2022matryoshka](http://arxiv.org/pdf/2405.17430v1) builds the
Matryoshka mechanism over a neural network’s representation vector,
where each of the segments with various feature dimensions is capable of
handling tasks like classification or retrieval. However, for LMMs, the
inefficiency mainly comes from the number of tokens. Thus, inspired by,
but different from MRL, our work is motivated to build upon the *token
length dimension*, so that we can flexibly adjust it.
l0.5
Specifically, we propose *:* , which enforces an LMM to learn a
hierarchy of visual representation granularities at the token sequence
level, instead of the feature dimension level as in
MRL [kusupati2022matryoshka](http://arxiv.org/pdf/2405.17430v1). With this representation,
at inference time, the visual granularity can be *flexibly controlled*
based on specific requirements, e.g., to account for the input image’s
information density and efficiency constraints. Our training process is
simple and straightforward. During training, we encode the image into
$M$ sets of visual tokens from coarse to fine, $\mathbf{X} _{S_i}$,
$i = 1, \cdots, M$, where the number of visual tokens gradually
increases, $|\mathbf{X}_{S_{i-1}} | < |\mathbf{X}_{S_i}|$. And
importantly, the visual tokens in a coarser level are derived from the
visual tokens in a finer level,
$\mathbf{X}_{S_{i-1}} \subset \mathbf{X}_{S_i}$, $\forall i$. In this
way, the visual information in
$[ {\mathbf{X}} _{S_1}, {\mathbf{X}} _{S_2}, \cdots, {\mathbf{X}} _{S_M}]$
gradually includes more fine-grained details. For example, given a
natural image as shown in
Figure 1,
$\mathbf{X} _{S_1}$ includes high-level semantics such as the restaurant
and girl, while $\mathbf{X} _{S_M}$ includes more details such as the
Pepsi cup and white paper bag. All other training settings, such as the
loss function and model architecture, are kept the same as
LLaVA [liu2023llava](http://arxiv.org/pdf/2402.11690v1), [liu2023improvedllava](http://arxiv.org/pdf/2310.19145v1), [liu2024llavanext](https://llava-vl.github.io/blog/2024-01-30-llava-next/).
Our approach, , introduces several novel properties and benefits for
LMMs. First, our approach can adaptively and efficiently represent
visual content. Under *one suite of weights*, it generates multiple
nested sets of visual tokens with different granualarities in
information density. This enables flexibility in the number of visual
tokens used for any image during inference, enabling control over the
best tradeoff between cost and performance based on the image or video
content. For example, one can use all visual tokens for images with
dense details and use just a few tokens for simpler images. This
flexibility can be particularly significant when handling very long
visual sequences, such as videos. For instance, given a fixed budget of
2880 visual tokens, a user could represent a video of 2880 frames each
with one token or represent the same video by sampling 5 frames each
with 576 tokens.
Second, our approach can be used as a general framework to evaluate the
visual complexity of vision-language datasets or benchmarks, which level
of granularity is needed in order to perform the given task correctly.
Surprisingly, we find that most benchmarks, especially those mainly
crafted from natural scenes (such as
COCO) [goyal2017vqav2](http://arxiv.org/pdf/1612.00837v3), [li2023pope](http://arxiv.org/pdf/2402.15721v1), [liu2023mmbench](http://arxiv.org/pdf/2005.12661v2), can be
handled well with only $\sim9$ tokens per image. In contrast, dense
visual perception tasks such as document understanding or
OCR [singh2019textvqa](http://arxiv.org/pdf/1811.11903v1), [masry-etal-2022-chartqa](https://doi.org/10.18653/v1/2022.findings-acl.177) require a
greater amount of tokens ($144-576$ tokens) per image to handle the task
well. The detailed findings are presented in
Sec. [sec:exp:Image
Understanding].
Finally, our approach provides a foundation to tackle a critical task in
LMMs: *How to use the least amount of visual tokens while answering the
visual questions correctly?*. Based on the model’s predictions on the
test set, we find that compared to full visual tokens, the oracle can
use far fewer tokens while performing much better. For example, under
six common LMM benchmarks used in
LLaVA-NeXT [liu2024llavanext](https://llava-vl.github.io/blog/2024-01-30-llava-next/), the oracle with the
trained model can use as few as 8.9 visual tokens on average to achieve
performance that is 8% points better than LLaVA-NeXT which uses 576
tokens per image grid. This indicates that there is a large room for
improvement compared to the oracle upperbound, as we show in
Sec. [sec:exp:Image
Understanding].
To enable further research on adaptive LMMs that learn diverse
information granularities, we publicly release our code and models.
# Related Work
**Large Multimodal Models.** Large Language Models (LLMs) like
ChatGPT [chatgpt](https://openai.com/blog/chatgpt/), GPT-4 [gpt4](http://arxiv.org/pdf/2311.15732v2), and
LLaMA [touvron2023LLaMA](touvron2023LLaMA) have demonstrated impressive
reasoning and generalization capabilities for text. The landscape of
LLMs has been significantly transformed by the recent introduction of
models that also incorporate visual information, such as
GPT-4V(ision)[GPT4V_System_Card](https://cdn.openai.com/papers/GPTV_System_Card.pdf). Building upon
open-source LLMs [touvron2023LLaMA](touvron2023LLaMA), [Vicuna](https://vicuna.lmsys.org/), a plethora
of multimodal models have made significant strides, spearheaded by
models like LLaVA [liu2023llava](http://arxiv.org/pdf/2402.11690v1), [liu2023improvedllava](http://arxiv.org/pdf/2310.19145v1)
and MiniGPT-4 [zhu2023minigpt](http://arxiv.org/pdf/2402.17510v1), which combine
LLaMA’s [touvron2023LLaMA](touvron2023LLaMA) language capabilities with a
CLIP [radford2021learning](http://arxiv.org/pdf/2404.19696v1) based image encoder. Recently,
LMMs on more tasks and modalities have emerged, such as region level
LMMs [cai2024vipllava](http://arxiv.org/pdf/2312.00784v2), [zhang2023gpt4roi](http://arxiv.org/pdf/2309.12109v1), [chen2023shikra](http://arxiv.org/pdf/2306.15195v2), [peng2023kosmos](http://arxiv.org/pdf/2305.16103v1), [zhang2023llavagrounding](https://arxiv.org/pdf/2312.02949),
3D LMMs [3dllm](http://arxiv.org/pdf/2403.09631v1), and video
LMMs [lin2023video](http://arxiv.org/pdf/2311.10122v2), [zhang2023video](http://arxiv.org/pdf/2311.12919v2), [zhang2024llavanextvideo](https://llava-vl.github.io/blog/2024-04-30-llava-next-video/).
However, existing LMMs typically represent the visual content with a
large and fixed number of tokens, which makes it challenging to scale to
very long visual sequences such as high-resolution images or long-form
videos. In this work, we propose to adaptively and efficiently represent
the visual content by learning multiple nested sets of visual tokens,
providing flexibility in the number of visual tokens used for any image
during inference.
**Matryoshka Representation Learning.** Matryoshka Representation
Learning (MRL) [kusupati2022matryoshka](http://arxiv.org/pdf/2405.17430v1) addresses the
need for flexible representations that can adapt to multiple downstream
tasks with varying computational resources. This approach, inspired by
the nested nature of Matryoshka dolls, encodes information at different
granularities within the same high-dimensional feature vector produced
by a neural network. The adaptability of MRL extends across different
modalities, including vision (ResNet [he2016deep](http://arxiv.org/pdf/1608.05895v1),
ViT [dosovitskiy2020vit](http://arxiv.org/pdf/2105.15075v2)), vision + language
(ALIGN [jia2021scaling](http://arxiv.org/pdf/2102.05918v2)), and language
(BERT [devlin2018bert](http://arxiv.org/pdf/1810.04805v2)), demonstrating its versatility
and efficiency. Recent work [li20242d](http://arxiv.org/pdf/1804.10975v1) extends MRL to
both the text embedding space and the Transformer layers space. Our
approach is inspired by MRL, but instead of learning multiple nested
embeddings for a high-dimensional feature vector, we learn *nested
visual tokens along the token length dimension* for the visual input. We
are the first to show that the idea of Matryosha learning can enable
explicit control over the visual granularity of the visual content that
an LMM processes.
**Token Reduction.** One of the main causes of inefficiency in recent
LMMs is their large number of prefix visual tokens that are fed into the
LLM [liu2023llava](http://arxiv.org/pdf/2402.11690v1), [zhu2023minigpt](http://arxiv.org/pdf/2402.17510v1). The quadratic
complexity in Transformers [vaswani2017attention](http://arxiv.org/pdf/2107.08000v1) is the
key issue in scaling the input sequence length for Transformers. Token
reduction serves as an effective technique to reduce computational costs
in Transformers. Sparse attention methods such as
Linformer [wang2020linformer](https://arxiv.org/pdf/2006.04768) and
ReFormer [kitaev2020reformer](https://openreview.net/forum?id=rkgNKkHtvB) conduct attention
operations within local windows rather than the full context, thereby
reducing the quadratic complexity of the vanilla attention operation.
Another notable method is Token Merging
(ToMe) [bolya2023tome](None), which utilizes full attention but
gradually reduces the number of tokens in each transformer block by
selecting the most representative tokens through bipartite matching for
the Vision Transformer (ViT). A recent
work [Haurum_2023_ICCVW](http://arxiv.org/pdf/2308.04657v1) further studies different
families of token reduction methods for ViT. However, prior approaches
produce a single length output per input image and do not offer multiple
granularities over the reduced token sequence. Our approach instead
learns a multi-granularity, coarse-to-fine token representation within
the same model architecture and weights, enabling it to easily be
adjusted to various computational or memory constraints.
# : [sec:approach]
Our goal is to learn a Large Multimodal Model (LMM) that represents
visual content as nested sets of visual tokens capturing information
across multiple coarse-to-fine granularities, so that one can explicitly
control the visual granularity per test instance during inference. Here
we introduce how we learn a Matryoshka doll-like token sequence.
LMMs such as LLaVA [liu2023llava](http://arxiv.org/pdf/2402.11690v1) typically input a
sequence of visual tokens as prefix tokens to the LLM for
visual-linguistic reasoning. The visual encoder from pretrained
vision-language models, such as
CLIP [radford2021learning](http://arxiv.org/pdf/2404.19696v1) and
SigLIP [zhai2023sigmoid](http://arxiv.org/pdf/2303.15343v4), is typically utilized to
project the images into the set of visual tokens. In particular, the
CLIP visual encoder represents an input image $\mathbf{I}$ as an
$H\times W$ grid of visual tokens ${\mathbf{X}} _{H\times W}$, where
each $\mathbf{X}_i \in \mathbb{R}^{ C}$ is a $C$ dimensional feature
vector. Our goal is to learn nested sets of visual tokens
$[ {\mathbf{X}} _{S_1}, {\mathbf{X}} _{S_2}, \cdots, {\mathbf{X}} _{S_M}]$
which encode the visual information in a coarse-to-fine manner. To this
end, we enforce
${\mathbf{X}} _{S_i} \subset {\mathbf{X}} _{S_{i+1}}, \forall i$.
Importantly, we do not introduce any new learnable parameters to the
LMM. We instead optimize the CLIP visual encoder to learn the nested
visual representation directly, and train the ensuing LLM to adapt to
the learned nested set of tokens.
For ease of exposition, we consider
CLIP-ViT-L-336 [radford2021learning](http://arxiv.org/pdf/2404.19696v1) as the visual
encoder, where an image is encoded as $24\times24$ visual tokens (576
total). We create $M$ sets of tokens e.g.,
$|S_i| \in \{ 1, 9, 36, 144, 576 \}$, in which the visual tokens at the
coarser level are derived directly from those at the finer level.
Specifically, given the initial $24\times24$ visual tokens, We
sequentially apply $2\times2$ pooling with a stride 2, resulting in
$12\times12, 6\times6$, and $3\times3$ visual tokens. Finally, we apply
$3\times3$ pooling and get the most condensed single visual token. In
this way, the sets of Matryoshka visual tokens can gradually preserve
the spatial information in the original tokens while simultaneously
forming a coarse-to-fine nested representation.
We train by averaging the autoregressive next token prediction loss for
each scale $S_i$ for each image $\mathbf{I}_i$. Specifically, given a
Matryoshka visual representation ${\mathbf{X}} _{S_i}$ for scale $S_i$,
we maximize the likelihood of the predicted tokens matching the
ground-truth answer $\mathbf{X}_{\mathrm{a}}$:
$$P(\mathbf{X}_{\mathrm{a}} \mid {\mathbf{X}}_{S_i}, \mathbf{X}_{\text {q}})=\prod_{j=1}^L P_{\boldsymbol{\theta}}(x_j \mid {\mathbf{X}}_{S_i}, \mathbf{X}_{\text {q}}, \mathbf{X}_{\mathrm{a},1 shows our model architecture.
The final objective averages over all $M$ visual token scales:
$$\min_{\boldsymbol{\theta}} \frac{1}{M} \sum_{i=1}^M -\log P(\mathbf{X}_{\mathrm{a}} \mid {\mathbf{X}}_{S_i}, \mathbf{X}_{\text {q}}).$$
With this objective function, learns nested sets of visual tokens that
gradually include more details with increasing scale. For example, in
Figure [fig:detail-specturm-visualization],
the smaller set of visual tokens describes the whole scene at a high
level while the larger set of visual tokens includes more details such
as the Pepsi cup. Our training objective affords our model to conduct
visual question answering under any granularity during inference. This
can be particularly useful in resource constrained applications; e.g.,
the visual granularity can be flexibly adjusted based on the anticipated
simplicity or complexity of the visual content while taking into account
compute and memory constraints.
# Experiments
In this section, we first detail the experiment settings in
Sec 1.1. Then we show the performance
of on both image-level
benchmarks 1.2 and video-level
benchmarks 1.3. Finally, we
analyze the behavior of and provide ablations in
Sec 1.4 and
1.5.
## Experiment Settings [sec:exp:setting]
#### Model
We use LLaVA-1.5 [liu2023improvedllava](http://arxiv.org/pdf/2310.19145v1) and
LLaVA-NeXT [liu2024llavanext](https://llava-vl.github.io/blog/2024-01-30-llava-next/) as the base LMMs, both with
Vicuna 7B as the language model backbone. We finetune the whole model
using the exact visual instruction data from LLaVA-1.5 and LLaVA-NeXT,
respectively. The learning rate of LLM is $2\times10^{-5}$ and
$1\times10^{-5}$, respectively for LLaVA-1.5 and LLaVA-NeXT. The
learning rate for the visual encoder is $2\times10^{-5}$ for both
models. We train both models for 1 epoch using 8 NVIDIA H100 GPUs.
Instead of training the language model from scratch, we initialize the
language model weights from pre-trained LLaVA-1.5 and LLaVA-NeXT, which
we empirically works better. We name our LLaVA-1.5- and LLaVA-NeXT-.
#### Visual Token Scales
We design 5 scales for the visual tokens.
LLaVA-1.5 [liu2023improvedllava](http://arxiv.org/pdf/2310.19145v1) and
LLaVA-NeXT [liu2024llavanext](https://llava-vl.github.io/blog/2024-01-30-llava-next/) both leverage
CLIP-ViT-L-336 [radford2021learning](http://arxiv.org/pdf/2404.19696v1) as the visual
encoder, where an image is embedded into $24\times24$ visual tokens. We
gradually apply $2\times2$ pooling with stride 2, resulting in
$12\times12, 6\times6$, and $3\times3$ visual tokens, where we finally
apply a $3\times3$ pooling to get the final single visual token.
Therefore, the size of Matryoshka visual token sets are
$S \in \{ 1, 9, 36, 144, 576 \}$, following a nested manner. The
efficiency anlaysis on the system level is shown in
Appendix [sec: Efficiency Analysis],
where boosts the speed of the LMM prefill process through diminished
floating-point operations (FLOPs) and lessens computational memory
requirements.
#### Evaluations.
For **image understanding**, we evaluate LLaVA-1.5 and LLaVA-NeXT on (a)
diverse multimodal benchmarks: POPE [li2023pope](http://arxiv.org/pdf/2402.15721v1),
GQA [hudson2019gqa](http://arxiv.org/pdf/2112.05136v1),
MMBench [liu2023mmbench](http://arxiv.org/pdf/2005.12661v2),
VizWiz [gurari2018vizwiz](http://arxiv.org/pdf/1802.08218v4),
SEEDBench [li2023seed](http://arxiv.org/pdf/2311.15759v1),
ScienceQA [lu2022learnscienceqa](http://arxiv.org/pdf/2209.09513v2),
MMMU [yue2023mmmu](http://arxiv.org/pdf/2311.16502v3), and (b) document
understanding/Optical character recognition (OCR) benchmarks:
DocVQA [mathew2021docvqa](http://arxiv.org/pdf/2111.05547v1),
ChartQA [masry-etal-2022-chartqa](https://doi.org/10.18653/v1/2022.findings-acl.177),
AI2D [ai2d](http://arxiv.org/pdf/1603.07396v1) and
TextVQA [singh2019textvqa](http://arxiv.org/pdf/1811.11903v1).
For **video understanding**, we use both (a) open ended video question
answering benchmarks evaluated by GPT-3.5:
MSVD-QA [xu2017video](http://arxiv.org/pdf/1904.04357v1),
MSRVTT-QA [xu2017video](http://arxiv.org/pdf/1904.04357v1) and
ActivityNet-QA [yu2019activitynet](http://arxiv.org/pdf/1906.02467v1); and (b) multi-choice
video question answering benchmarks:
NExT-QA [xiao2021next](http://arxiv.org/pdf/2307.04412v1),
IntentQA [Li2023IntentQACV](http://arxiv.org/pdf/2002.08945v1), and
EgoSchema [mangalam2023egoschema](http://arxiv.org/pdf/2308.09126v1).
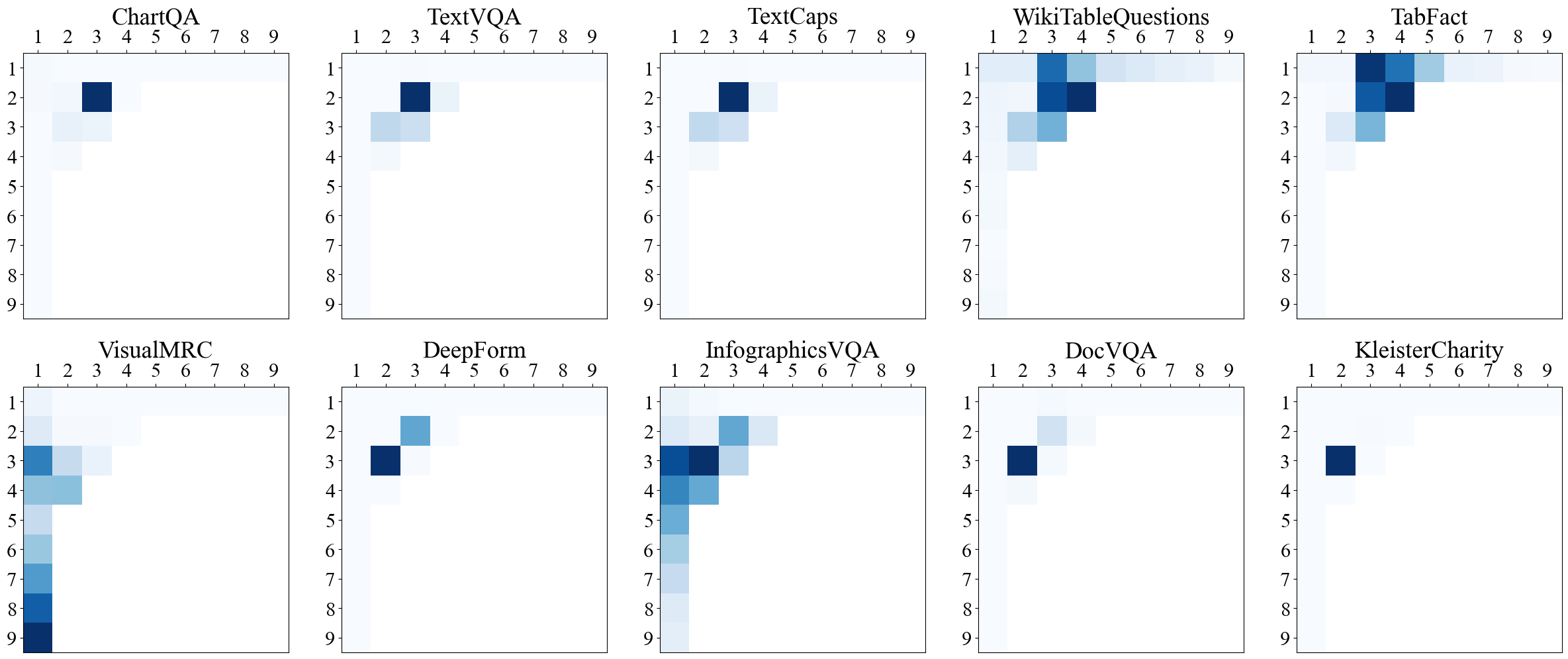
## Image Understanding [sec:exp:Image Understanding]
#### LLaVA-1.5-
We evaluate LLaVA-1.5- on the common multimodal understanding and
reasoning benchmarks. Results are shown in
Table 1. LLaVA-1.5- with
full tokens maintains the performance of LLaVA-1.5 across diverse
benchmarks. More importantly, our approach shows strong performance even
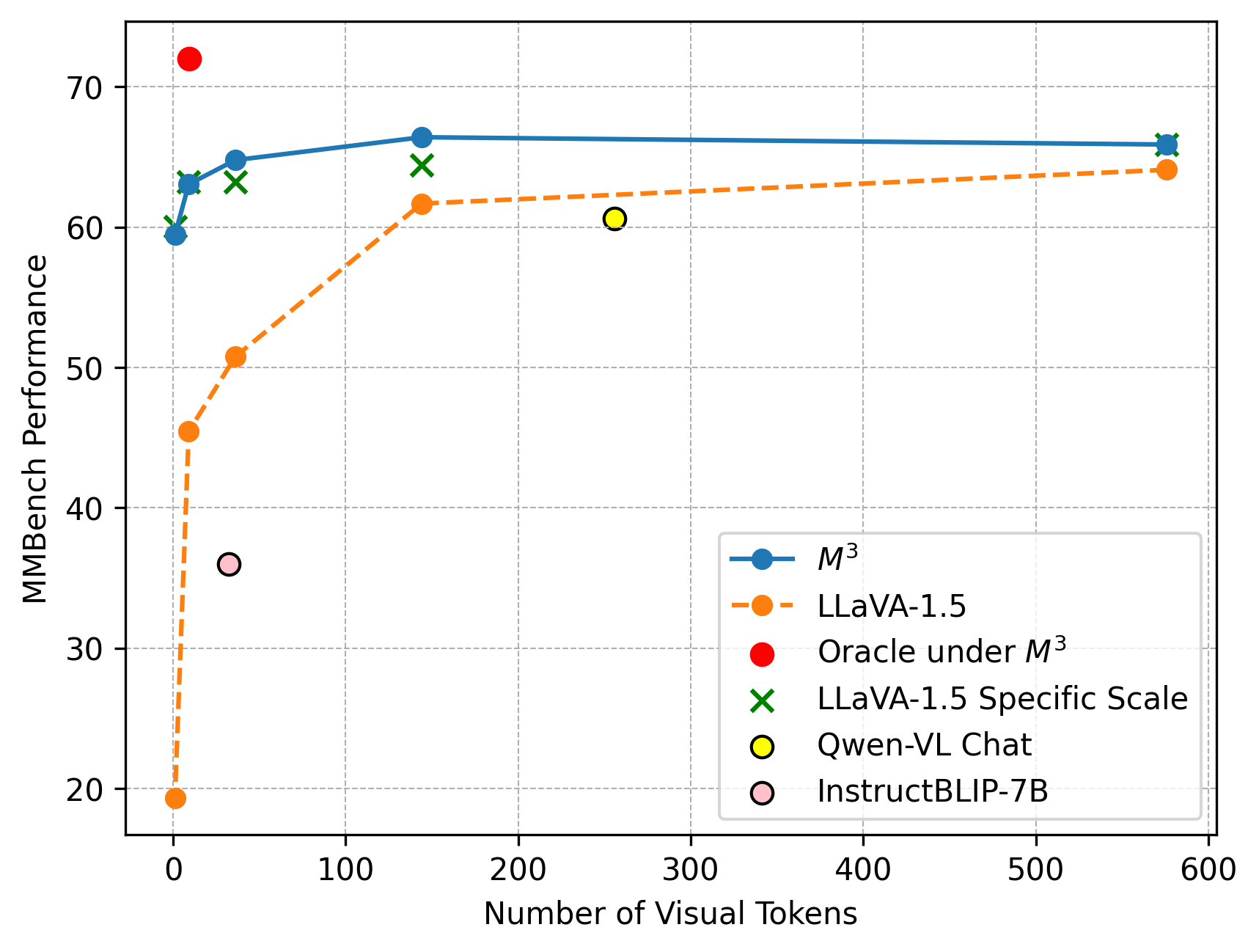
with 1 or 9 tokens. Specifically, in MMBench, a comprehensive multimodal
understanding benchmark, LLaVA-1.5- with 9 tokens surpasses Qwen-VL-Chat
with 256 tokens, and achieves similar performance as Qwen-VL-Chat with
even 1 token. Compared with InstructBLIP [instructblip](http://arxiv.org/pdf/2311.00233v2),
LLaVA-1.5 with 9 tokens surpasses InstructBLIP-7B and InstructBLIP-13B
across all benchmarks. This demonstrates that our model has both
flexibility and strong empirical performance under diverse number of
visual tokens.
#### LLaVA-NeXT-
We use the proposed to finetune LLaVA-NeXT, and compare LLaVA-NeXT- with
, which denotes the setting where the LLaVA-NeXT is trained under a
**S**pecific **S**cale of visual tokens also for 1 epoch. We also
include the oracle upperbound performance. Specifically, ‘Oracle’
denotes the case where the best tradeoff between visual tokens and
performance is picked for each test instance. Specifically, for each
test instance, we select the the scale with the fewest amount of tokens
but can answer the question correctly. Results are shown in
Table 2. Our approach, , is
at least as good as , while performing better on tasks such as document
understanding (TextVQA and ChartQA) and common benchmarks such as
MMBench [liu2023mmbench](http://arxiv.org/pdf/2005.12661v2).
max width=
| \# Tokens Per Grid | Approach | TextVQA | AI2D | ChartQA | DocVQA | MMBench | POPE | ScienceQA | MMMU |
|:---|:--:|:--:|:--:|:--:|:--:|:--:|:--:|:--:|:--:|
| | | 64.53 | 64.83 | 59.28 | 75.40 | 66.58 | 87.02 | 72.29 | 34.3 |
| | $M^3$ | 63.13 | 66.71 | 58.96 | 72.61 | 67.96 | 87.20 | 72.46 | 34.0 |
| | | 62.16 | 65.77 | 55.28 | 67.69 | 67.78 | 87.66 | 72.15 | 36.4 |
| | $M^3$ | 62.61 | 68.07 | 57.04 | 66.48 | 69.50 | 87.67 | 72.32 | 36.1 |
| | | 58.15 | 65.90 | 45.40 | 56.89 | 67.01 | 86.75 | 71.87 | 36.2 |
| | $M^3$ | 58.71 | 67.36 | 50.24 | 55.94 | 68.56 | 87.29 | 72.11 | 36.8 |
| | | 50.95 | 65.06 | 37.76 | 44.21 | 65.29 | 85.62 | 72.37 | 36.8 |
| | $M^3$ | 51.97 | 66.77 | 42.00 | 43.52 | 67.35 | 86.17 | 71.85 | 35.2 |
| | | 38.39 | 63.76 | 28.96 | 33.11 | 61.43 | 82.83 | 72.32 | 35.3 |
| | $M^3$ | 38.92 | 64.57 | 31.04 | 31.63 | 62.97 | 83.38 | 71.19 | 34.8 |
| | \# Tokens | 31.39 | 11.54 | 41.78 | 64.09 | 8.90 | 6.08 | 7.43 | 22.85 |
| | Performance | 70.51 | 76.36 | 70.76 | 81.73 | 74.35 | 94.29 | 76.07 | 50.44 |
Comparison of approaches with the baseline and $M^3$ across various
benchmarks under LLaVA-NeXT [liu2024llavanext](https://llava-vl.github.io/blog/2024-01-30-llava-next/). Here \#
Tokens denotes the number of visual tokens per image grid in LLaVA-NeXT.
denotes the baseline model trained with a **S**pecific **S**cale of
visual tokens. is at least as good as , while performing better on tasks
such as TextVQA, ChartQA, and MMBench.
Oracle denotes the case where the best
tradeoff between visual tokens and performance is picked.
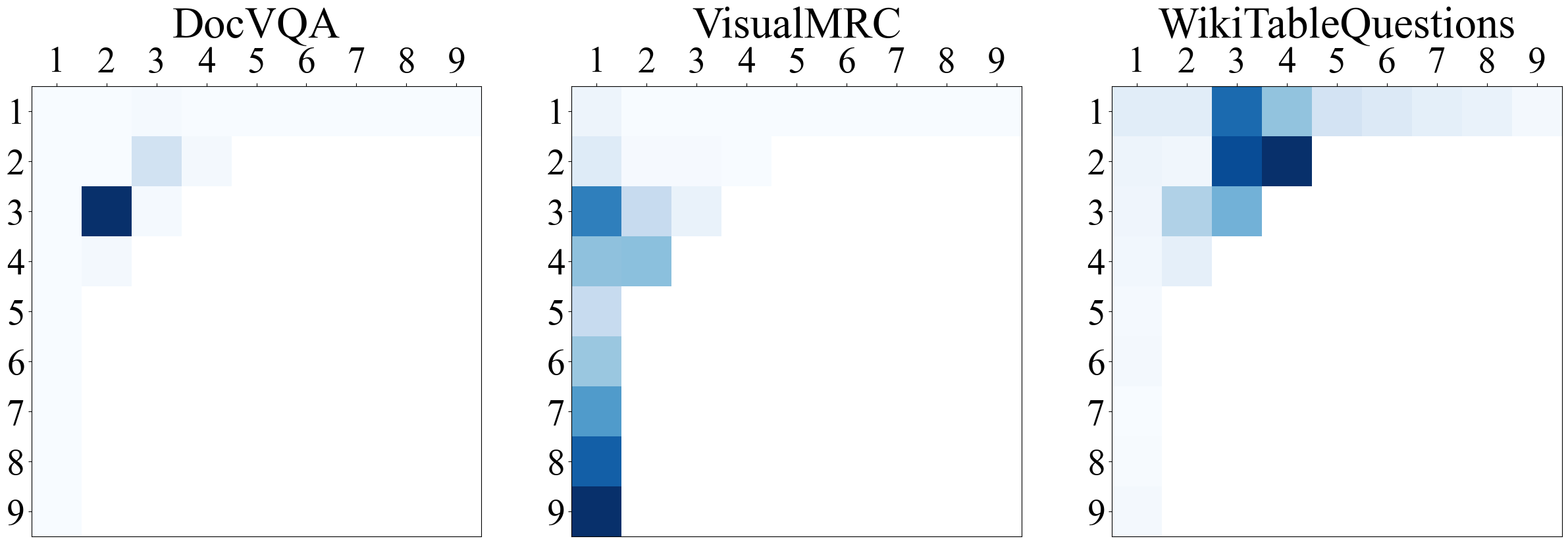
Our results also show that dataset level biases towards the visual token
scales do exist. For example, ScienceQA maintains consistent performance
across all visual token scales. AI2D and MMBench only encounter a small
performance drop for even as few as 9 to 1 tokens. On the other hand,
dense visual perception tasks such as TextVQA and DocVQA show a
significant performance with fewer tokens. This analysis shows that
could serve as a framework to analyze the granularity that a benchmark
needs.
Furthermore, there is a large gap between the model’s actual performance
under full tokens and the upper-bound oracle. This indicates that using
full tokens cannot always result in the optimal performance for all
samples; i.e., there is a large room of improvement towards the oracle
point.
## Video Understanding [sec:exp:video understanding]
Following IG-VLM [kim2024image](http://arxiv.org/pdf/2403.18406v1), we directly conduct
zero-shot inference on diverse video benchmarks using LLaVA-NeXT-.
Specifically, 6 frames are uniformly sampled over the entire video, then
arranged as a collage, which is fed into LLaVA-NeXT along with the
question to get the response. Results under LLaVA-NeXT- and recent video
LMMs are show in
Table 3.
LLaVA-NeXT- with full visual tokens again shows comparable performance
with LLaVA-NeXT. More interestingly, results indicate that full visual
tokens usually *do not lead to the best performance* in video
understanding tasks. Specifically, on 4 out of 6 benchmarks, full visual
tokens show less desirable performance compared to 720 or 180 visual
tokens. We suspect that very long visual context could bring distraction
(e.g., too much focus on potentially irrelevant background) to the
model’s prediction, where a compact representation of the video focusing
on the more relevant information may be more advantageous.
Finally, for most video understanding tasks such as ActivityNet,
IntentQA and EgoSchema, with 9 tokens per image grid (45 tokens in
total), the accuracy difference compared to full tokens (2880 in total)
is less than 1%. This demonstrates that the video questions in these
benchmarks usually require very sparse visual information, as the source
of such video understanding benchmarks mostly comes from natural scenes,
which matches our observation in image understanding benchmarks.
## In-depth Analysis [sec:exp:analysis]
#### shows much stronger performance compared to heuristics based sampling at test time.
A simple way to reduce the number of visual tokens via a training-free
way is to conduct heuristic token merging or reduction. In
Table 4, we compare
with three training-free approaches: average pooling, spatial sampling,
and sequential sampling. is much more resilient when the number of
tokens decreases, while the heuristic based sampling approaches show
dramatic performance drop. A visualization of the spatial and sequential
sampling is shown in
Figure [fig:vis sampling
inference].
max width=0.9
| \# Tokens | | Average Pooling | Spatial Sampling | Sequential Sampling |
|:----------|:----|:---------------:|:----------------:|:-------------------:|
| | | 67.18 | 67.18 | 67.18 |
| | | 61.68 | 65.81 | 60.14 |
| | | 50.77 | 60.05 | 44.76 |
| | | 45.45 | 45.45 | 31.96 |
| | | 19.33 | 26.29 | 22.42 |
Comparison between , and heuristics based sampling baselines—average
pooling, spatial sampling, and sequential sampling—at inference time on
MMBench with the LLaVA-NeXT architecture.
#### serves as a good metric for image complexity.
We extract the response from LLaVA-NeXT- in the TextVQA benchmark, and
show the samples where using visual tokens across different scales can
answer the question correctly and incorrectly. Shown in
Figure 1, the OCR performance
aligns with the complexity of the images, which indicates that can be
utilized as a metric towards sample level complexity.
#### Large gap between oracle and actual performance.
As shown in
Table 2, the oracle
upper-bound can use very few ($6\sim64$) tokens yet achieve at least 10%
better performance compared to full visual tokens. This suggests that a
visual token scale predictor, where the model learns to automatically
select the best visual token scale given the input images or both input
images and questions, has potential to achieve a better tradeoff. This
would be interesting future work.
#### Zero-shot generalization to longer visual sequences.
Here we extend the length of the visual tokens at inference time to
study the model’s zero-shot generalization behavior. Results under
LLaVA-NeXT are shown in
Table 5. Here
LLaVA-NeXT- is trained on $2\times2$ image grids but evaluated on
$3\times3$ grids. We set the number of visual tokens to be 144 in each
image during evaluation. The model obtains a significant improvement in
document understanding by 2.12, 1.80, and 4.11 on TextVQA, ChartQA, and
DocVQA, respectively, while maintaining the same performance on
benchmarks mainly composed of natural scene images. $3\times3$ image
grids with 144 tokens per grid own 1440 tokens, yet achieve similar
performance with the default LLaVA-NeXT $2\times2$ image grids with 2880
total tokens (576 tokens per grid). This indicates it is promising to
feed more subimages while making the number of visual tokens within each
subimage much smaller.
## Ablation Studies [sec:exp:ablation]
We ablate the key designs in , including the sampling method of
Matryoshka visual tokens, and training strategy.
#### Matryoshka visual token sampling.
Here we compare three different ways to select the visual tokens for ,
including average pooling, spatial sampling, and sequential sampling,
which is illustrated in
Figure [fig:vis sampling
inference]. Shown in
Table 6, averaging pooling
shows better performance than the two alternatives across diverse
benchmarks. In general, sequential sampling performs the worst. We
hypothesize that this is due to the visual tokens having spatial
information, while sequential sampling does not naturally align with the
spatial distribution of the visual tokens.
| Num of Vis Tokens | TextVQA | | MMBench | | AI2D | | DocVQA | |
|:-----------------:|:-------:|:-------:|:-------:|:-------:|:------:|:-------:|:------:|:-------:|
| 2-9 | w/ LLM | w/o LLM | w/ LLM | w/o LLM | w/ LLM | w/o LLM | w/ LLM | w/o LLM |
| 576 | 63.13 | 61.16 | 67.96 | 63.66 | 66.71 | 63.92 | 72.61 | 69.15 |
| 144 | 62.61 | 57.79 | 69.50 | 65.21 | 68.07 | 63.73 | 66.48 | 59.77 |
| 36 | 58.71 | 49.75 | 68.56 | 63.92 | 67.36 | 62.89 | 55.94 | 44.08 |
| 9 | 51.97 | 36.15 | 67.35 | 61.08 | 66.77 | 62.05 | 43.52 | 28.36 |
| 1 | 38.92 | 19.72 | 62.97 | 51.80 | 64.57 | 60.59 | 31.63 | 17.37 |
Performance comparison of training LLaVA-NeXT- with and without training
the LLM across diverse benchmarks. We see a clear drop when freezing the
LLM.
max width=0.95
| Technique | TextVQA | | | | AI2D | | | |
|:------------------------------:|:-------:|:-----:|:-----:|:-----:|:-----:|:-----:|:-----:|:-----:|
| Init LLM weights from LLaVA | | | | | | | | |
| Average losses over all scales | | | | | | | | |
| 576 | 60.36 | 62.25 | 61.01 | 63.13 | 62.40 | 65.06 | 65.84 | 66.71 |
| 144 | 59.61 | 61.02 | 59.80 | 62.61 | 63.67 | 65.61 | 65.77 | 68.07 |
| 36 | 54.86 | 55.91 | 55.32 | 58.71 | 63.67 | 65.32 | 66.68 | 67.36 |
| 9 | 46.84 | 47.04 | 48.80 | 51.97 | 63.02 | 64.83 | 65.38 | 66.77 |
| 1 | 33.78 | 33.68 | 36.05 | 38.92 | 61.53 | 63.21 | 63.37 | 64.57 |
Impact of (a) initializing the LLM weights from LLaVA, and (b) averaging
the loss from all scales vs randomly selecting a scale for each sample
during training.
#### Training the entire LMM vs only training CLIP.
Since the nested behavior of Matryoshka visual tokens is learned within
the CLIP visual encoder, we next evaluate whether it is necessary to
also finetune the LLM. Shown in
Table 7, training the whole LLM
achieves better performance. This demonstrates that by also training the
LLM, the model can better adapt to the patterns of the visual tokens
distributed in the Matryoshka manner.
As explained in Sec. [sec:approach]
and 1.1, we (a) initialize the LLM
weights from LLaVA and (b) minimize the loss averaged upon all visual
token scales for each sample during training. An alternative choice is
to randomly sample a visual token scale. Shown in
Table 8, initializing the
LLM weights from LLaVA and minimizing the losses over all scales shows
consistent performance boost compared to using the vanilla text-only
pre-trained LLM weights [Vicuna](https://vicuna.lmsys.org/) and randomly selecting a
visual token scale. Initializing the LLM weights from LLaVA makes the
training process of more stable. By learning all scales at once, the
model is forced to learn the nested behavior for each sample, which
leads to better performance.
# Conclusion and Future Work [sec:conclusion and limitation]
We introduced : , which learns to represent visual content as nested
sets of visual tokens, capturing information across multiple
coarse-to-fine granularities. LMMs equipped with afford explicit control
over the visual granularity per test instance during inference. We also
showed that can serve as an analysis framework to investigate the visual
granularity needed for existing datasets, where we discovered that a
large number of multimodal benchmarks only need as few as 9 visual
tokens to obtain accuracy similar to that of using all visual tokens,
especially for video understanding. Furthermore, we disclosed a large
performance-efficiency gap between the oracle upper-bound and the
model’s performance.
Our work can be naturally extended to other domains. For example, the
long context in a text-only LLM or vision tokens in dense vision tasks
can also be represented as nested sets of tokens in a Matryoshka manner.
One limitation of our current approach is that we are lacking an
effective visual token predictor that can bridge the gap between the
oracle and LMM’s actual performance at a specific scale. We believe this
would be an exciting next direction of research in this space.
# Acknowledgement [acknowledgement]
This work was supported in part by NSF CAREER IIS2150012, and Institute
of Information & communications Technology Planning & Evaluation(IITP)
grants funded by the Korea government(MSIT) (No. 2022-0-00871,
Development of AI Autonomy and Knowledge Enhancement for AI Agent
Collaboration) and (No. RS2022-00187238, Development of Large Korean
Language Model Technology for Efficient Pre-training), and Microsoft
Accelerate Foundation Models Research Program.
# Broader Impact [sec:boarder_impact]
The broader impact of , a framework with nested visual representations,
has potential benefits and risks associated with its deployment and
release. Our model is trained using the exact same architecture and data
of LLaVA-1.5 [liu2023improvedllava](http://arxiv.org/pdf/2310.19145v1) and
LLaVA-NeXT [liu2024llavanext](https://llava-vl.github.io/blog/2024-01-30-llava-next/). All the concerns are same
as LLaVA. Specifically, as one example, LLaVA conducts instruction
tuning using GPT-4 and GPT-4V generated data. The bias from GPT-4 and
GPT-4V would still exist in LLaVA.
# Efficiency Analysis [sec: Efficiency Analysis]
To illuminate the computational benefits conferred by , we employ the
roofline-based LLM-Viewer analysis as detailed
in [yuan2024llm](http://arxiv.org/pdf/2402.16363v6). Our analysis is set within a
hypothetical context designed to emphasize the effects of on processing
efficiency in LMMs. We study the LLaVA-1.5 case where a $336 \times 336$
resolution image is processed using a CLIP-ViT image encoder, resulting
in 576 visual tokens. Accompanied by a text prompt with an assumed
number of 30 tokens, the nested visual tokens in substantially lowers
the visual token count. The consequences of this reduction are
substantial as outlined in
Table 1, detailing the computational
costs involved in the LMM prefill process. Notably, not only boosts the
speed of the LMM prefill process through diminished floating-point
operations (FLOPs) but also lessens computational memory requirements.
It is crucial to highlight that the advantages of are not limited to
just efficiency improvements. The token reduction approach of can also
enhance other LMM acceleration methods, such as quantization and
factorization, as referenced in [yuan2023asvd](http://arxiv.org/pdf/2403.07378v4). This
complementary relationship accentuates the broad potential of to
contribute to a wider array of efficiency-boosting strategies.
| \# Tokens | FLOPs (TB) | Prefill Time (ms) | Total Memory (GB) | Storing Activation (GB) |
|:--:|:--:|:--:|:--:|:--:|
| 576 | 8.0 | 58.1 | 21.6 | 3.8 |
| 144 | 2.2 | 19.5 | 15.0 | 0.7 |
| 36 | 0.9 | 18.0 | 13.8 | 0.3 |
| 9 | 0.5 | 17.7 | 13.6 | 0.2 |
| 1 | 0.4 | 17.6 | 13.5 | 0.1 |
Computation Cost Analysis. The development device is Tesla V100 GPU, and
time estimated by the roofline model represents the theoretical
performance that the hardware can achieve.
# More Visualizations on Nested Visual Representation
Shown in Figure 1, with more visual tokens, LMMs can
discover more details, such as furniture and human attributes. Besides,
LMMs can generate higher quality descriptions with more visual tokens,
as demonstrated by the OCR capability in
Figure 1 (b).
What matters when building vision-language models?
2024-05-03
Hugo Laurençon, Léo Tronchon, Matthieu Cord, Victor Sanh
The growing interest in vision-language models (VLMs) has been driven by improvements in large language models and vision transformers. Despite the abundance of literature on this subject, we observe that critical decisions regarding the design of VLMs are often not justified. We argue that these unsupported decisions impede progress in the field by making it difficult to identify which choices improve model performance. To address this issue, we conduct extensive experiments around pre-trained models, architecture choice, data, and training methods. Our consolidation of findings includes the development of Idefics2, an efficient foundational VLM of 8 billion parameters. Idefics2 achieves state-of-the-art performance within its size category across various multimodal benchmarks, and is often on par with models four times its size. We release the model (base, instructed, and chat) along with the datasets created for its training.
Show Paper Content
# Introduction
Vision-language models (VLMs) that take images and texts as inputs and
output texts, are useful for many tasks, like retrieving information in
a scanned PDF [mPLUG-DocOwl-1.5](https://arxiv.org/pdf/2403.12895), explaining charts or
diagrams [Chart-PaLI](https://arxiv.org/pdf/2403.12596), transcribing the text in an image
[Nougat](https://arxiv.org/pdf/2308.13418), counting objects in a picture
[VQAv2](https://doi.org/10.1109/CVPR.2017.670) or turning screenshots of webpages into code
[WebSight](https://arxiv.org/pdf/2403.09029). The development of powerful open large
language models [Llama2](https://arxiv.org/pdf/2307.09288), [Mistral7B](https://arxiv.org/pdf/2310.06825), [Gemma](https://arxiv.org/pdf/2403.08295) and image
encoders [SigLIP](https://arxiv.org/pdf/2303.15343), [EVA-CLIP](https://arxiv.org/pdf/2303.15389), [CLIP](http://arxiv.org/pdf/2404.19696v1) enables researchers to
build upon these unimodal pre-trained models to create advanced VLMs
that solve these problems with increasing accuracy
[InstructBLIP](https://openreview.net/forum?id=vvoWPYqZJA), [LLaVA](https://openreview.net/forum?id=w0H2xGHlkw), [Qwen-VL](https://arxiv.org/pdf/2308.12966), [VILA](https://arxiv.org/pdf/2312.07533), [SPHINX](https://arxiv.org/pdf/2311.07575), [Monkey](https://arxiv.org/pdf/2311.06607), [CogVLM](https://arxiv.org/pdf/2311.03079).
Despite the progress in the field, the literature reveals many disparate
design choices which are often not justified experimentally, or very
briefly.
This situation makes it challenging to distinguish which decisions truly
account for model performance, thereby making it difficult for the
community to make meaningful and grounded progress. For instance,
[Flamingo](https://proceedings.neurips.cc/paper_files/paper/2022/file/960a172bc7fbf0177ccccbb411a7d800-Paper-Conference.pdf), [OBELICS](https://openreview.net/forum?id=SKN2hflBIZ) use interleaved Transformer-based
cross-attentions to fuse the image information into the language model,
while [BLIP-2](http://arxiv.org/pdf/2301.12597v3), [LLaVA](https://openreview.net/forum?id=w0H2xGHlkw) concatenate the sequence of image
hidden states with the sequence of text embeddings, and feed the
concatenated sequence to the language model. To our knowledge, this
choice has not been properly ablated, and trade-offs in terms of
compute, data efficiency and performance are poorly understood. In this
work, we aim to bring experimental clarity to some of these core design
choices and pose the question: **What matters when building
vision-language models?**
We identify two areas where various works adopt different design
choices: (a) model architecture, and in particular, connector modules
that fuse the vision and text modalities and their impact on inference
efficiency, (b) multimodal training procedure and its impact on training
stability. For each of these areas, we rigorously compare different
design choices in a controlled environment and extract experimental
findings. Notably, we find that (a) the progress of vision-language
models is in large part driven by the progress of pre-trained unimodal
backbones, (b) the more recent fully autoregressive architecture
outperforms the cross-attention architecture, although it requires
modifications to the optimization procedure to ensure a stable training,
(c) adaptation of the pre-trained vision backbone and the modules
connecting the text and vision modalities allow for more efficiency at
inference time on one side, and handling images in their original ratio
and size without harming downstream performance on the other side, and
(d) modifications to the image processing enables trading inference cost
for downstream performance.
Our results are complementary with those presented in
[prismatic](https://arxiv.org/pdf/2402.07865), [MM1](https://arxiv.org/pdf/2403.09611), [VILA](https://arxiv.org/pdf/2312.07533) which derive insights about
multi-stage training, selective unfreezing of the pre-trained backbones,
data repetition, and impact of training mixture on zero and few-shot
performance. We specifically delve into unexplored aspects such as model
architecture, training methods, stability, and efficiency improvements
at inference.
Learning from these insights, we train Idefics2, a foundational VLM with
8 billion parameters. Idefics2 achieves state-of-the-art performance in
its size category on various benchmarks while being more efficient at
inference, for both the base and the fine-tuned version. It is on par
with state-of-the-art models 4 times larger on some vision-language
benchmarks and matches the performance of Gemini 1.5 Pro on some
challenging benchmarks. We release the base, instructed, and chat
versions of Idefics2[^1] as resources for the VLM community along with
the data created to train the model.
[^1]:
# Terminology [section:terminology]
We first establish shared terminology for discussing the different
design choices. Training VLMs typically requires gluing together a
pre-trained vision backbone and a pre-trained language backbone by
initializing new parameters to connect the two modalities. Training
these new parameters is done during the *pre-training phase*. This stage
commonly leverages a large multimodal dataset such as image-caption
pairs. We note that even though it is most common to start from two
separate unimodal pre-trained backbones, the parameters of these two
backbones can be optionally shared and initialized from scratch as done
in [fuyu](https://www.adept.ai/blog/fuyu-8b). As in the large language models literature,
the pre-training stage is followed by an instruction fine-tuning stage,
in which the model learns from task-oriented samples.
Recent works explore two main choices to combine the visual inputs and
the text inputs. In the *cross-attention architecture*
[Flamingo](https://proceedings.neurips.cc/paper_files/paper/2022/file/960a172bc7fbf0177ccccbb411a7d800-Paper-Conference.pdf), [OBELICS](https://openreview.net/forum?id=SKN2hflBIZ), [OpenFlamingo](https://arxiv.org/pdf/2308.01390), the images encoded
through the vision backbone are injected at different layers within the
language model by interleaving cross-attention blocks in which the text
cross-attends to the image hidden states. In contrast, in the *fully
autoregressive architecture* [FROMAGe](http://arxiv.org/pdf/2301.13823v4), [PaLM-E](http://arxiv.org/pdf/2302.14030v3), [LLaVA](https://openreview.net/forum?id=w0H2xGHlkw),
the output of the vision encoder is directly concatenated to the
sequence of text embeddings, and the entire sequence is passed as input
to the language model. The input sequence of the language model is thus
the concatenation of *visual tokens* and text tokens. The sequence of
visual tokens can be optionally pooled into a shorter sequence,
providing more compute efficiency. We refer to the layers that maps the
vision hidden space to the text hidden space as *modality projection*
layers.
Figure 1 highlights the
fully-autoregressive architecture we ultimately use for Idefics2.
# Exploring the design space of vision-language models
In this section, we compare recurrent design choices in the
vision-language model literature and highlight findings. Unless
specified otherwise, we run the ablations for 6’000 steps and report the
average score of the 4-shot performance on 4 downstream benchmarks
measuring different capabilities: VQAv2 [VQAv2](https://doi.org/10.1109/CVPR.2017.670) for
general visual question answering, TextVQA [textvqa](http://arxiv.org/pdf/1811.11903v1) for
OCR abilities, OKVQA [okvqa](http://arxiv.org/pdf/1906.00067v2) for external knowledge, and
COCO [coco](http://arxiv.org/pdf/2012.01295v1) for captioning.
## Are all pre-trained backbones equivalent for VLMs?
Most recent VLMs start from pre-trained unimodal backbones. How does the
choice of the backbones (vision and text) influence the performance of
the resulting VLM?
r4.4cm
We fix the size of the pretrained backbones, the data used for
multimodal pre-training, and the number of training updates. Under the
cross-attention architecture, we observe that the greatest improvement
in the performance on vision-language benchmarks comes from changing the
language model to a better one. More specifically, replacing LLaMA-1-7B
[LLaMA](https://arxiv.org/pdf/2302.13971) (35.1% on MMLU [MMLU](https://openreview.net/forum?id=d7KBjmI3GmQ)) by
Mistral-7B [Mistral7B](https://arxiv.org/pdf/2310.06825) (60.1% on MMLU) yields a boost of
5.1 (see Table
[tab:ablations_archi_lm_backbone]).
Additionally, switching the vision encoder from CLIP-ViT-H
[CLIP](http://arxiv.org/pdf/2404.19696v1) (78.0% on ImageNet[ImageNet](https://doi.org/10.1109/CVPR.2009.5206848)) to
SigLIP-SO400M [SigLIP](https://arxiv.org/pdf/2303.15343) (83.2% on ImageNet) yields a 3.3
increase in performance on the benchmarks (see Table
[tab:ablations_archi_vision_encode_backbone]).
This result on better vision backbones corroborates observations from
[prismatic](https://arxiv.org/pdf/2402.07865).
r5cm
We note that [PaLI-17B](http://arxiv.org/pdf/2402.18932v1) reports a stronger increase in
performance by scaling the size of the vision encoder compared to
scaling the size of the language model even though scaling the vision
encoder leads to a smaller parameter count increase. Although
EVA-CLIP-5B [EVA-CLIP](https://arxiv.org/pdf/2303.15389) is ten times bigger in parameter
counts than SigLIP-SO400M [SigLIP](https://arxiv.org/pdf/2303.15343), we obtain similar
performance across 4 benchmarks, suggesting that EVA-CLIP-5B could be
heavily under-trained, and we acknowledge that the open VLM community is
missing a large well-trained vision encoder.
#### ***Finding* 1.**
For a fixed number of parameters, the quality of the language model
backbone has a higher impact on the performance of the final VLM than
the quality of the vision backbone.
## How does the fully autoregressive architecture compare to the cross-attention architecture?
To our knowledge, there is no proper comparison between the fully
autoregressive and the cross-attention architecture. We aim to fill this
gap by considering their trade-offs, namely performance, parameter
count, and inference cost.
r7.1cm
Following [Flamingo](https://proceedings.neurips.cc/paper_files/paper/2022/file/960a172bc7fbf0177ccccbb411a7d800-Paper-Conference.pdf), we first compare the two
architectures by freezing the unimodal backbones and training only the
newly initialized parameters (cross-attention on one side, and modality
projection along with learned pooling on the other side), while fixing
the amount of training data. [Flamingo](https://proceedings.neurips.cc/paper_files/paper/2022/file/960a172bc7fbf0177ccccbb411a7d800-Paper-Conference.pdf) shows that the
more frequently the cross-attention blocks are interleaved with the
language model layers, and the higher the vision-language performance.
As such, we note that under this setup, the cross-attention architecture
has 1.3B more trainable parameters (2B trainable parameters in total)
than the fully autoregressive architecture. Additionally, at inference
time, the former uses 10% more flops than the latter. Under these
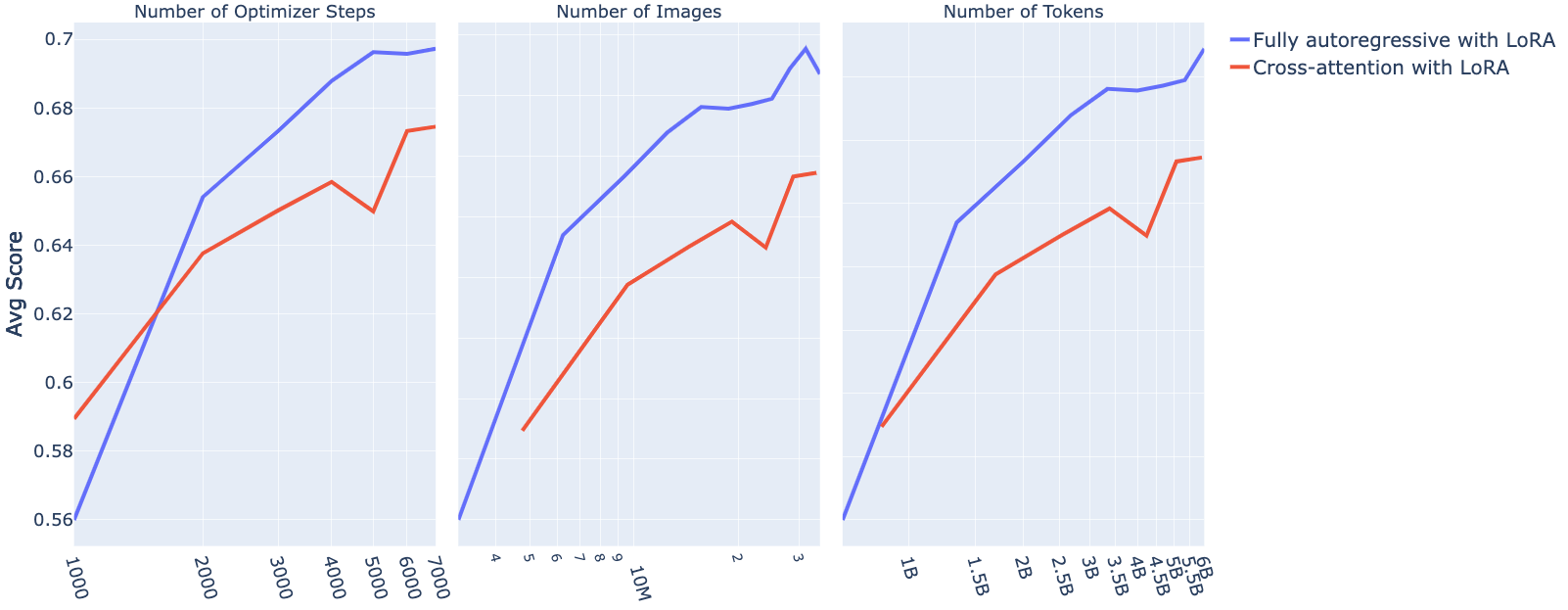
conditions, we observe that the cross-attention architecture performs 7
points better in Table
[tab:ablations_archi_type_archi_method_training].
Out of the total number of parameters, approximately 15% for the fully
autoregressive architecture and 25% for the cross-attention are trained.
We hypothesize that this low proportion limits the expressivity of the
training and hinders performance. To test that hypothesis, we compare
the two architectures by unfreezing all parameters (newly initialized
parameters and parameters of the pre-trained unimodal backbones). Under
these conditions, training the fully autoregressive architecture would
yield loss divergences, and we were not successful in stabilizing the
training even by aggressively lowering the learning rate or gradually
unfreezing various components. To overcome this stability challenge, we
leverage Low-Rank Adaptation [LoRA](https://openreview.net/forum?id=nZeVKeeFYf9) to adapt the
pre-trained parameters while using standard full fine-tuning for the
newly initialized ones.
This setup yields significantly more stable trainings, and more
importantly, we observe a 12.9 points increase under the fully
autoregressive architecture, and 0.6 point under the cross-attention
architecture. While the cross-attention architecture performs better
than the fully autoregressive architecture with frozen backbones, it is
worse when we add degrees of liberty for the pre-trained backbones.
Besides, using LoRA allows training the unimodal backbones at a fraction
of the GPU memory cost of full fine-tuning, and LoRA layers can be
merged back into the original linear layers yielding no additional cost
at inference. We therefore choose the fully autoregressive architecture
in the rest of this work.
It is interesting to note that this finding contradicts
[prismatic](https://arxiv.org/pdf/2402.07865) in which the authors observed that
unfreezing the pre-trained visual backbone would significantly degrade
the performance. We hypothesize that using parameter-efficient
fine-tuning methods is a key difference.
#### ***Finding* 2.**
The cross-attention architecture performs better than the fully
autoregressive one when unimodal pre-trained backbones are kept frozen.
However, when training the unimodal backbones, the fully autoregressive
architecture outperforms the cross-attention one, even though the latter
has more parameters.
#### ***Finding* 3.**
Unfreezing the pre-trained backbones under the fully autoregressive
architecture can lead to training divergences. Leveraging LoRA still
adds expressivity to the training and stabilizes it.
## Where are the efficiency gains?
#### Number of visual tokens
Recent VLMs typically route the entire sequence of the vision encoder’s
hidden states directly into the modality projection layer, which
subsequently inputs into the language model, without no pooling. This is
motivated by previous works in which adding a pooling strategy, like
average pooling, was found to deteriorate the performance
[DePALM](https://arxiv.org/pdf/2403.13499). This results in a high number of visual tokens
for each image ranging from 576 for DeepSeek-VL
[DeepSeek-VL](https://arxiv.org/pdf/2403.05525) to 2890 for SPHINX-2k
[SPHINX](https://arxiv.org/pdf/2311.07575). With the resulting sequence lengths, training
is computationally costly, and in-context learning with interleaved
images and texts is challenging because it requires modifications to the
language models to handle very large context windows.
We reduce the sequence length of each image’s hidden states by using a
perceiver resampler [perceiver](https://proceedings.mlr.press/v139/jaegle21a.html), [Flamingo](https://proceedings.neurips.cc/paper_files/paper/2022/file/960a172bc7fbf0177ccccbb411a7d800-Paper-Conference.pdf), [Qwen-VL](https://arxiv.org/pdf/2308.12966) as a
form of trainable Transformer-based pooling. The number of queries (also
referred to as latents) corresponds to the number of resulting visual
tokens after the pooling. We observe that the learned pooling is
effective in two ways: it increases the performance by 8.5 points on
average and reduces the number of visual tokens necessary for each image
from 729 to 64 (see Table
[tab:ablations_archi_type_archi_method_training]).
r4.6cm
In contrast to [DePALM](https://arxiv.org/pdf/2403.13499), [MM1](https://arxiv.org/pdf/2403.09611) which find that the more
visual tokens the higher the performance, we observe no gains when using
more than 64 visual tokens. We hypothesize that in a hypothetical
scenario of infinite training on unlimited data, performance might
eventually improve, at the cost of a longer training time. Other
variations over the Perceiver architecture
[MAPL](https://doi.org/10.18653/v1/2023.eacl-main.185), [register-tokens](https://openreview.net/forum?id=2dnO3LLiJ1), [DePALM](https://arxiv.org/pdf/2403.13499) resulted in decreased
performance.
#### ***Finding* 4.**
Reducing the number of visual tokens with learned pooling significantly
improves compute efficiency at training and inference while improving
performance on downstream tasks.
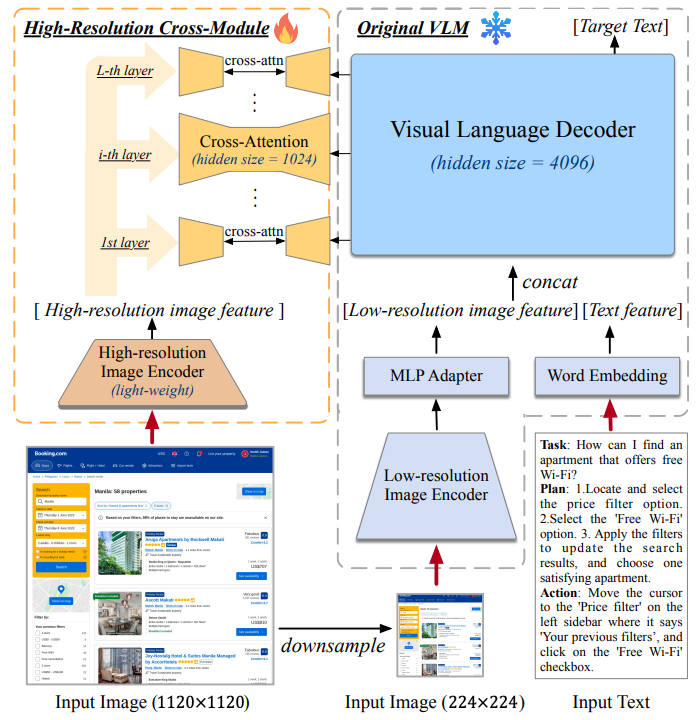
#### Preserving the original aspect ratio and image resolution
Vision encoders, such as SigLIP, are typically trained on fixed-size
square images. Resizing images alters their original aspect ratio, which
is problematic, for instance, for tasks requiring reading long texts.
Furthermore, conditioning the training on a single resolution size
inherently introduces limitations: a low resolution omits crucial visual
details, while a high resolution leads to inefficiency in training and
inference. Allowing the model to encode images at various resolutions
allows users to decide how much compute is spent on each image.
r5.2cm
Following [pix2struct](http://arxiv.org/pdf/2210.03347v2), [PatchNPack](https://openreview.net/forum?id=VpGFHmI7e5), we pass the image
patches to the vision encoder without resizing the image or modifying
its aspect ratio. Given that SigLIP was trained on fixed-size
low-resolution square images, we interpolate the pre-trained positional
embeddings to allow for a higher resolution and train the vision encoder
with LoRA parameters to adapt to these modifications.[^1] Our findings
indicate that the aspect ratio preserving strategy maintains performance
levels on downstream tasks while unlocking computational flexibility
during both training and inference (see Table
[tab:ablations_archi_aspect_ratio_preserving]).
In particular, not having to resize images to the same high resolution
allows for saving GPU memory and handling images at the resolution they
require.
#### ***Finding* 5.**
Adapting a vision encoder pre-trained on fixed-size square images to
preserve images’ original aspect ratio and resolution does not degrade
performance while speeding up training and inference and reducing
memory.
## How can one trade compute for performance?
[SPHINX](https://arxiv.org/pdf/2311.07575), [Monkey](https://arxiv.org/pdf/2311.06607), [LLAVA-NeXT](https://llava-vl.github.io/blog/2024-01-30-llava-next/), [MM1](https://arxiv.org/pdf/2403.09611) show that splitting an
image into sub-images allows boosting the downstream performance with no
changes to the model’s signature. An image is decomposed into sub-images
(for instance 4 equal sub-images), which are then concatenated to the
original image to form a sequence of 5 images. Additionally, the
sub-images are resized to the original image’s size. This strategy
however comes at the cost of a much higher number of tokens to encode
the images.
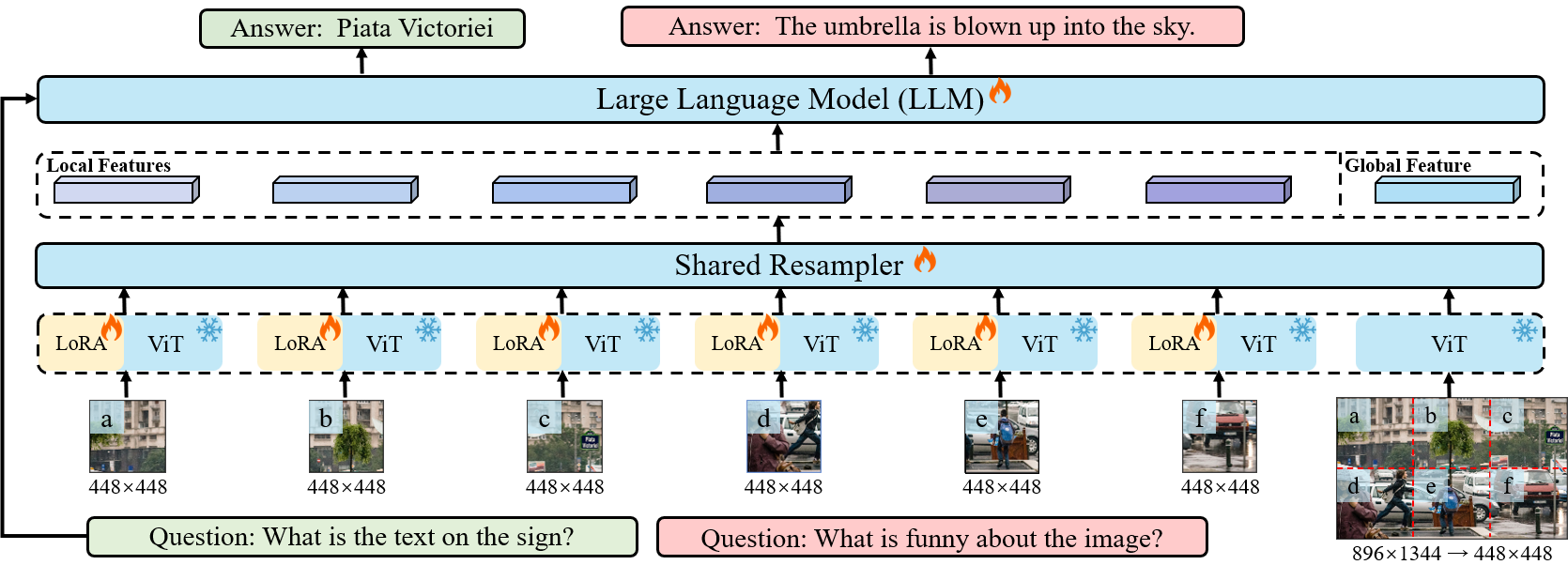
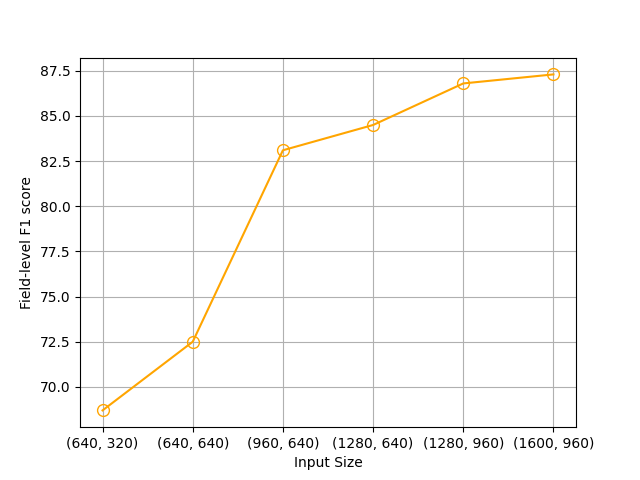
We adopt this strategy during the instruction fine-tuning stage. Each
single image becomes a list of 5 images: 4 crops and the original image.
This way, at inference, the model is able to deal with standalone images
(64 visual tokens per image), as well as artificially augmented images
(320 visual tokens in total per image). We notice that this strategy is
particularly useful for benchmarks like TextVQA and DocVQA, which
require a sufficiently high resolution to extract the text in an image
(see Table [table:perf_sft]).
Moreover, when we apply image spitting to only 50% of the training
samples (instead of 100% of the samples), we observe that it does not
impair the performance increase that image splitting provides.
Surprisingly, we find at evaluation time that increasing the resolution
of the sub-images (and the standalone image) provides only a minor boost
in performance compared to the improvement yielded by sole image
splitting: 73.6% when increasing the resolution of the sub-images to the
maximum vs 73.0% accuracy on our validation set of TextVQA, and
respectively 72.7 vs 72.9 ANLS on the validation set of DocVQA.
#### ***Finding* 6.**
Splitting images into sub-images during training allow trading compute
efficiency for more performance during inference. The increase in
performance is particularly noticeable in tasks involving reading text
in an image.
[^1]: Since SigLIP is trained with a fixed resolution, the positional
embeddings can be interpreted both as absolute or relative
positions. With the aspect ratio and resolution preserving, these
positions become relative positional embeddings.
# Idefics2 - an open state-of-the-art vision-language foundation model
With these learnings in hand, we train an open 8B parameters
vision-language model: Idefics2. This section describes the construction
of the model, the choice of the dataset, the sequence of training phases
and compares the resulting model against VLMs baselines.
## Multi-stage pre-training
We start from SigLIP-SO400M and Mistral-7B-v0.1 and pre-train Idefics2
on 3 types of data.
**Interleaved image-text documents** We use OBELICS
[OBELICS](https://openreview.net/forum?id=SKN2hflBIZ), an open web-scale dataset of interleaved
image-text documents with 350 million images and 115 billion text
tokens. As shown by the authors, the long documents of OBELICS allow for
preserving the performance of the language model while learning to deal
with an arbitrary number of interleaved images and texts and long
context. Additionally, the authors show that interleaved image-text
documents are the biggest driving factor in increasing the performance
on visual question answering (VQA) tasks, in particular in the
in-context learning setup. We perform an additional removal of newly
opted-out content in January 2024 using the Spawning API[^1] even though
OBELICS had already been filtered to exclude opted-out content as of
September 2023. We also removed the 5% of documents with the highest
perplexity scores, as computed by Falcon-1B
[RefinedWeb](https://openreview.net/forum?id=kM5eGcdCzq).
r3.5cm
**Image-text pairs** Training on image-text pairs allows the model to
learn the alignment between images and their associated texts. We use a
combination of high-quality human-annotated image-text pairs from PMD
[flava](https://doi.org/10.1109/CVPR52688.2022.01519) and higher-noise web-scale image-text pairs from
[LAION-5B](https://proceedings.neurips.cc/paper_files/paper/2022/file/a1859debfb3b59d094f3504d5ebb6c25-Paper-Datasets_and_Benchmarks.pdf). To limit the amount of poor-quality data, we
opt for the synthetic captions obtained through the LAION COCO[^2]
version of the dataset where images have been captioned with a model
trained on COCO. This improves the quality of the training samples and
thus the quality of the resulting model (see Table
[tab:ablations_pretraining_type_captions]).
We use a NSFW classifier[^3] with a high recall and remove 7% of the
samples in LAION COCO. We manually inspect 5’000 examples and found 28
pornographic images in the original LAION COCO and only 1 after
filtering. This filtering does not negatively impact the downstream
performance.
r5cm
**PDF documents** [multimodal-rlhf](https://arxiv.org/pdf/2309.14525) shows that a large
proportion of mistakes of state-of-the art VLMs stem from their failure
to accurately extract text in images or documents. In order to obtain
strong OCR and document understanding abilities, we train Idefics2 on
different sources of PDF documents: 19 million industry documents from
OCR-IDL [OCRIDL](https://arxiv.org/pdf/2202.12985) and 18 million pages from PDFA[^4].
Moreover, we add Rendered Text[^5] to complement the dataset with texts
written with a wide variety of fonts and colors and on diverse
backgrounds. These integrations significantly boost the performance on
benchmarks that require reading text without decreasing the performance
on other benchmarks (see Table
[tab:ablations_finetuning_ocr]).
To maximize compute efficiency, we decompose the pre-training in two
stages. In the first stage, we limit the max image resolution to 384
pixels, which allows us to use a large global batch size of 2’048 (17k
images and 2.5M text tokens on average). We sample OBELICS for 70% of
the examples with a maximum sequence length of 2’048, and the image-text
pairs datasets for 30% of the examples with a maximum sequence length of
1’536. In the second stage, we introduce PDF documents. Since they
require a higher image resolution for the text to be legible, we
increase the resolution to a maximum of 980 pixels. We use the same
global batch size, but have to decrease the per-device batch size and
use gradient accumulation to compensate for the additional memory cost.
OBELICS represents 45% of the examples with a maximum sequence length of
2’048, image-text pairs represent 35% of the examples with a maximum
sequence length of 1’536, and PDF documents represent the remaining 20%
of the examples with a maximum sequence length of 1’024. Additionally,
we randomly scale up images to adequately cover the distribution of
potential image sizes. We emphasize that the training stages are
different than the ones ablated in [prismatic](https://arxiv.org/pdf/2402.07865): instead
of selectively freezing/unfreezing parts of the model, we train the
entire model during both stages (some parameters are trained with LoRA)
and increase the image resolution from one stage to the other.
We use a learning rate of $10^{-4}$ and do around 2 epochs on our
training data. It corresponds to approximately 1.5 billion images and
225 billion text tokens. We note that this is orders of magnitude more
training data than other open VLMs. For example, ShareGPT
[ShareGPT4V](https://arxiv.org/pdf/2311.12793) uses 1.2 million images, while Monkey
[Monkey](https://arxiv.org/pdf/2311.06607) uses 1.4 million for training.
To evaluate the base model, we consider VQAv2 [VQAv2](https://doi.org/10.1109/CVPR.2017.670),
TextVQA [textvqa](http://arxiv.org/pdf/1811.11903v1), OKVQA [okvqa](http://arxiv.org/pdf/1906.00067v2), and
COCO [coco](http://arxiv.org/pdf/2012.01295v1). Table
1 presents the results. While
having fewer tokens per image, and thus being more efficient, Idefics2
performs favorably compared to the other current best base VLMs
(OpenFlamingo [OpenFlamingo](https://arxiv.org/pdf/2308.01390), Idefics1
[OBELICS](https://openreview.net/forum?id=SKN2hflBIZ), Flamingo [Flamingo](https://proceedings.neurips.cc/paper_files/paper/2022/file/960a172bc7fbf0177ccccbb411a7d800-Paper-Conference.pdf), and MM1
[MM1](https://arxiv.org/pdf/2403.09611)). It is notably much better at reading texts in an
image. Figure
1 shows an example of
an output from the base model on a task similar to the pre-training.
[^1]:
[^2]:
[^3]:
[^4]:
[^5]:
## Instruction fine-tuning
We continue the training with an instruction fine-tuning phase.
To do so, we create and release The Cauldron[^1], a massive collection
of 50 vision-language datasets, covering a wide range of tasks: general
visual question answering, counting, captioning, text transcription,
document understanding, chart/figure understanding, table understanding,
visual reasoning, geometry, spotting differences between 2 images or
converting a screenshot to a functional code. Similarly to
[T0](https://openreview.net/forum?id=9Vrb9D0WI4), [flan](https://openreview.net/forum?id=gEZrGCozdqR), [promptsource](https://doi.org/10.18653/v1/2022.acl-demo.9), [InstructBLIP](https://openreview.net/forum?id=vvoWPYqZJA), [m3it](https://arxiv.org/pdf/2306.04387), each
dataset is prompted into a shared question/answer format. When there are
multiple question/answer pairs per image, we concatenate the pairs into
a multi-turn conversation. We deduplicate the training set against the
evaluation sets, ensuring that there is minimum contamination from the
training to the evaluation.
In addition to these vision-language datasets and following insights
from [MM1](https://arxiv.org/pdf/2403.09611), we add text-only instruction datasets to the
mixture. The datasets aim at teaching the model to follow complex
instructions, solve mathematical problems, or do arithmetic
calculations. We give more details about the chosen datasets, the number
of images, question-answer pairs, and size of each of the subsets, as
well as our selected mixture proportion in Table
[table:mixture_sft] in Appendix
[subsection:details_the_cauldron].
| | | | | | | | | | |
|:--:|:--:|:--:|:--:|:--:|:--:|:--:|:--:|:--:|:--:|
| **Model** | **Size** | | | | | | | | |
| per image | **MMMU** | **MathVista** | **TextVQA** | **MMBench** | | | | | |
| LLaVA-NeXT | 13B | 2880 | 36.2/- | 35.3 | 67.1 | 70.0 | | | |
| DeepSeek-VL | 7B | 576 | 36.6/- | 36.1 | 64.4 | 73.2 | | | |
| MM1-Chat | 7B | 720 | 37.0/35.6 | 35.9 | 72.8 | 72.3 | | | |
| Idefics2 | 8B | **64** | **43.5**/**37.9** | **51.6** | 70.4 | **76.8** | | | |
| Idefics2 | 8B | 320 | 43.0/37.7 | 51.4 | **73.0** | 76.7 | | | |
Performance of Idefics2 against state-of-the-art VLMs up to a size of
14B parameters. The evaluations are done in zero shot. Idefics2 with 64
or 320 tokens per image is the same model (same weights), only the
inference differs. The full table is present in Appendix
[subsection:expanded_evals].
*(Benchmark, Split, Metric): (MMMU, val/test, MMMU score), (MathVista,
testmini, MMMU score), (TextVQA, val, VQA acc.), (MMBench, test,
accuracy).*
We instruction-tune the base model using DoRA [DoRA](https://arxiv.org/pdf/2402.09353) (a
variant of LoRA). During the fine-tuning, we only compute the loss on
the tokens of the answers in the Q/A pairs. Since we are doing many
epochs over some of the datasets, we employ several strategies to lower
the risk of overfitting. First, we add noise to the embeddings with the
NEFTune [NEFTune](https://openreview.net/forum?id=0bMmZ3fkCk) technique. Then, we scale up randomly
the resolution of the images during the training. Finally, when
applicable, we shuffle the multiple user/assistant turns randomly before
feeding the example to the model.
We evaluate Idefics2 on commonly adopted benchmarks: MMMU
[MMMU](http://arxiv.org/pdf/2311.16502v3) for multidiscipline college-level problems,
MathVista [mathvista](http://arxiv.org/pdf/2310.02255v3) for mathematical reasoning,
TextVQA [textvqa](http://arxiv.org/pdf/1811.11903v1) for text reading on natural images,
and MMBench [MMBench](https://arxiv.org/pdf/2307.06281) for various perception and
reasoning tasks. Table
1 presents the results (see Table
[table:perf_sft_full] for the
complete result table) of Idefics2 against the current strongest VLMs in
its class size: LLaVA-Next [LLAVA-NeXT](https://llava-vl.github.io/blog/2024-01-30-llava-next/), DeepSeek-VL
[DeepSeek-VL](https://arxiv.org/pdf/2403.05525) and MM1-Chat [MM1](https://arxiv.org/pdf/2403.09611). While
being computationally much more efficient at inference, Idefics2
exhibits strong performance on various benchmarks, outperforming the
current best foundation VLMs in its size category. It is on par with
state-of-the-art models 4x its size, or with closed-source models like
Gemini 1.5 Pro on several benchmarks like MathVista or TextVQA.
## Optimizing for chat scenarios
The evaluation benchmarks expect very short answers, but humans prefer
long generations when interacting with a model. We find that Idefics2
can exhibit difficulties in precisely following instructions about the
expected format, making it difficult to reconcile “chattiness“ and
downstream performance. As such, after instruction fine-tuning, we
further train Idefics2 on dialogue data. We fine-tune Idefics2 for a few
hundred steps on LLaVA-Conv [LLaVA](https://openreview.net/forum?id=w0H2xGHlkw) and ShareGPT4V
[ShareGPT4V](https://arxiv.org/pdf/2311.12793), with a large batch size. Our blind human
evaluations reveal that Idefics2-chatty is overwhelmingly preferred over
its instruction fine-tuned version in many user interactions. We also
adversarially stress-tested the model to generate inaccurate, biased, or
offensive responses and reported the findings in
Appendix [sec:red_teaming]. We show examples
of generations with Idefics2-chatty in Figure
[fig:qualitative_gen_0], and
in Appendix in Figures
[fig:qualitative_gen_1],
[fig:qualitative_gen_2] and
[fig:qualitative_gen_3].
[^1]:
# Conclusion
In this work, we re-examine common choices made in the VLM literature
and rigorously compare these choices in controlled experiments. Our
findings touch upon the effectiveness of different architectures, their
performance/inference cost trade-offs as well as training stability.
With these learnings at hand, we train Idefics2, an open 8B parameters
vision-language model. Idefics2 is state-of-the-art on various
benchmarks in its category size and is much more efficient at inference.
By releasing our findings, as well as our models and our training
dataset, we aim to contribute to the ongoing evolution of VLMs and their
applications in solving complex real-world problems.
# Acknowledgement [acknowledgement]
We thank Mustafa Shukor for helpful suggestions on the paper, and Yacine
Jernite, Sasha Luccioni, Margaret Mitchell, Giada Pistilli, Lucie-Aimée
Kaffee, and Jack Kumar for red-teaming the model.
# Appendix
## Further experimental details of the ablations
### Cross-attention vs. fully autoregressive architectures
We apply LoRA modules to the LLM for the fully autoregressive
architecture and to the cross-attention modules and the LLM for the
cross-attention architecture. In
Figure 1, we
report the average performance with respect to the number of steps, the
number of images, as well as the number of text tokens. We see an
improvement across the board with the fully autoregressive architecture.
Comparing the average score with these different axes is essential
because the cross-attention architecture feeds a single token per image
to the language model, against 64 for the fully autoregressive
architecture with perceiver pooling. This implies that for the same
training sequence length, the number of images and text tokens is
different for the two architectures. Equivalently, the same multimodal
document will yield different sequence lengths. Even though we fix the
batch size in the comparison, the number of text tokens and number of
images grow at different paces under the two architectures.
Comparison of the cross-attention and fully autoregressive
architectures through the number of steps, the number of images and the
number of text tokens.
### Comparing various vision backbones
We present in
Table [tab:ablations_archi_vision_encode_backbone_detailed]
the detailed results of comparing multiple vision backbones. While
EVA-CLIP-5B performs similarly to SigLIP-SO400M, we emphasize that it
has 11 times more parameters. We also noticed in early experiments that
TextVQA is the most sensitive benchmark to image resolution, which
accounts for the performance increase.
### Comparing various pooling strategies
We compare multiple pooling strategies: a simple linear layer that takes
the flattened sequence of vision hidden states and projects it into a
shorter sequence of visual tokens, as well as a Mapping Network
[MAPL](https://doi.org/10.18653/v1/2023.eacl-main.185). The perceiver resampler significantly
outperforms these two options (see
Table [tab:vision_language_adaptor_ablation]).
We also ablate the number of layers in the perceiver resampler, and find
no statistically significant differences when increasing the number of
layers, similarly to results from [palm2vadapter](https://arxiv.org/pdf/2402.10896). We
settle on 3 layers out of caution to avoid any potential capacity
bottleneck.
Finally, we add a 2-layer modality projection MLP on top of the vision
encoder hidden states to project the vision hidden dimension to the
language model hidden dimension prior to the perceiver resampler. These
changes yield better performance as well (see
Table [tab:modality_projection_prior_to_perceiver]).
### Ablations on OCR data
We hypothesize that adding PDF documents helps the model learn to read
text from images. In
Table [tab:ablations_finetuning_ocr],
we compare checkpoints trained with and without OCR documents, along
with image resolution increase to ensure that the text is legible. We do
not observe statistically significant differences when evaluating
checkpoints in zero or few shot. Instead, we fine-tune the checkpoints
on DocVQA for 500 steps with a learning rate of $1e-5$, leading to
checkpoints showing much stronger differences.
## Details of the instruction fine-tuning
### Statistics of The Cauldron [subsection:details_the_cauldron]
In Table 1, we present the statistics of
the datasets included in The Cauldron, as well as the text-only
instruction datasets used for the supervised fine-tuning. For each
dataset, we give the number of different images it contains, the number
of question-answer pairs, the total number of tokens for the answers in
the question-answer pairs, and the selected percentage of tokens it
represents in our final mixture after upsampling or downsampling.
## Details of the evaluations
### Evaluation setup
We perform all evaluations with a batch size of 1 and greedy decoding.
For the multi-choice questions in MMMU, MathVista, MMBench, we evaluate
with the same prompt used for similar types of datasets during the
instruction fine-tuning:
Question: {question} Choices: A. {choice_a} B. {choice_b} C. {choice_c}
... Answer with the letter.
For the open-ended questions in TextVQA, DocVQA, and VQAv2, we evaluate
with the prompt:
Question: {question} Give a very brief answer.
We use the stop words `Question`, `User`, `` and
`` to stop a generation.
### Expanded evaluation table [subsection:expanded_evals]
We report the expanded evaluation of Idefics2 and the comparison to
other models in Table
2. This includes scores on
VQAv2 [VQAv2](https://doi.org/10.1109/CVPR.2017.670), which is widely adopted for evaluation.
We acknowledge, though, that the metric used for the open-ended visual
question answering benchmarks strongly penalizes models that do not
generate in the same format as the ground truth. For example, answering
"large" when the ground truth is "big" or more verbose reformulations
will be counted as incorrect. Our manual qualitative analysis reveals
that on benchmarks like VQAv2, the generations of two models differing
by 5 points would be barely noticeable. This problem is less concerning
for other open-ended benchmarks like TextVQA or DocVQA which require
finding a text in an image, making the expected answer less prone to
ambiguity.
### Qualitative evaluation
We show in Figures
2,
3, and
4, examples of generations
with Idefics2-chatty.
## Red-teaming [sec:red_teaming]
In the context of a red-teaming exercise, our objective is to evaluate
the propensity of the model to generate inaccurate, biased, or offensive
responses. We evaluate more specifically the chat-optimized
checkpoint[^4].
While the model typically refrains from responding to offensive inputs,
we observe that through repeated trials or guided interactions, it tends
to hastily form judgments in situations necessitating nuanced contextual
understanding, often perpetuating harmful stereotypes. Noteworthy
instances include:
- Speculating or passing judgments, or perpetuating historical
disparities on individuals’ professions, social status, or insurance
eligibility based solely on visual cues (e.g., age, attire, gender,
facial expressions).
- Generating content that promotes online harassment or offensive
memes reinforcing harmful associations from a portrait, or from a
benign image.
- Assuming emotional states or mental conditions based on outward
appearances.
- Evaluating individuals’ attractiveness solely based on their visual
appearance.
Additionally, we identify behaviors that increase security risks that
already exist:
- Successfully solving CAPTCHAs featuring distorted text within
images.
- Developing phishing schemes from screenshots of legitimate websites
to deceive users into divulging their credentials.
- Crafting step-by-step guides on constructing small-scale explosives
using readily available chemicals from common supermarkets or
manipulating firearms to do maximum damage.
It’s important to note that these security concerns are currently
limited by the model’s occasional inability to accurately read text
within images.
We emphasize that the model would often encourage the user to exercise
caution about the model’s generation or flag how problematic the initial
query can be in the first place. For instance, when insistently prompted
to write a racist comment, the model would answer that query before
pointing out "*This type of stereotyping and dehumanization has been
used throughout history to justify discrimination and oppression against
people of color. By making light of such a serious issue, this meme
perpetuates harmful stereotypes and contributes to the ongoing struggle
for racial equality and social justice.*".
However, certain formulations can circumvent (i.e. "jailbreak") these
cautionary prompts, emphasizing the need for critical thinking and
discretion when engaging with the model’s outputs. While jail-breaking
text LLMs is an active research area, jail-breaking vision-language
models have recently emerged as a new challenge as vision-language
models become more capable and prominent [jailbreak](https://openreview.net/forum?id=plmBsXHxgR).
The addition of the vision modality not only introduces new avenues for
injecting malicious prompts but also raises questions about the
interaction between vision and language vulnerabilities.
[^1]:
[^2]:
[^3]:
[^4]:
mPLUG-Owl: Modularization Empowers Large Language Models with Multimodality
2023-04-27
Qinghao Ye, Haiyang Xu, Guohai Xu, Jiabo Ye, Ming Yan, Yiyang Zhou, Junyang Wang, Anwen Hu, Pengcheng Shi, Yaya Shi, Chenliang Li, Yuanhong Xu, Hehong Chen, Junfeng Tian, Qi Qian, Ji Zhang, Fei Huang, Jingren Zhou
Large language models (LLMs) have demonstrated impressive zero-shot abilities on a variety of open-ended tasks, while recent research has also explored the use of LLMs for multi-modal generation. In this study, we introduce mPLUG-Owl, a novel training paradigm that equips LLMs with multi-modal abilities through modularized learning of foundation LLM, a visual knowledge module, and a visual abstractor module. This approach can support multiple modalities and facilitate diverse unimodal and multimodal abilities through modality collaboration. The training paradigm of mPLUG-Owl involves a two-stage method for aligning image and text, which learns visual knowledge with the assistance of LLM while maintaining and even improving the generation abilities of LLM. In the first stage, the visual knowledge module and abstractor module are trained with a frozen LLM module to align the image and text. In the second stage, language-only and multi-modal supervised datasets are used to jointly fine-tune a low-rank adaption (LoRA) module on LLM and the abstractor module by freezing the visual knowledge module. We carefully build a visually-related instruction evaluation set OwlEval. Experimental results show that our model outperforms existing multi-modal models, demonstrating mPLUG-Owl's impressive instruction and visual understanding ability, multi-turn conversation ability, and knowledge reasoning ability. Besides, we observe some unexpected and exciting abilities such as multi-image correlation and scene text understanding, which makes it possible to leverage it for harder real scenarios, such as vision-only document comprehension. Our code, pre-trained model, instruction-tuned models, and evaluation set are available at https://github.com/X-PLUG/mPLUG-Owl. The online demo is available at https://www.modelscope.cn/studios/damo/mPLUG-Owl.
Show Paper Content
# Introduction
Large language models (LLMs) such as GPT-3 [gpt3](http://arxiv.org/pdf/2112.07522v2), BLOOM
[bloom](None), LLaMA [llama](http://arxiv.org/pdf/2402.08075v1) have experienced
rapid development to make general artificial intelligence possible,
which demonstrates impressive zero-shot abilities on various linguistic
applications. However, except GPT-4 [gpt4](None), current
general LLMs cannot support different modalities of input and develop
impressive multimodal abilities.
Although GPT-4 [gpt4](None) has exhibited remarkable
multimodal abilities, the methods behind its extraordinary abilities
remain a mystery. Recently, researchers have been extending LLMs to
understand visual inputs in two different paradigms: systematic
collaboration and end-to-end trained models. However, systematic
collaboration approaches, including Visual ChatGPT
[visualchatgpt](None), MM-REACT [mmreact](None), and
HuggingGPT [hugginggpt](None), are designed to facilitate the
coordination of various vision models or tools to express visual
information with text descriptions. However, these approaches may not be
able to comprehend specific multimodal instructions due to their lack of
alignment with different modalities. Additionally, these approaches may
encounter challenges related to inference efficiency and cost.
End-to-end models, such as BLIP-2 [blip2](None), LLaVA
[llava](http://arxiv.org/pdf/2402.11690v1), and MiniGPT-4 [minigpt4](http://arxiv.org/pdf/2402.17510v1) aim to
use unified models to support different modalities. However, these
models have some limitations as they take frozen visual models, which
may lead to inadequate alignment due to the limited number of
parameters. Moreover, they cannot unlock various abilities due to
missing unimodal and multimodal instruction.
In this paper, we present mPLUG-Owl with an innovative modularized
training paradigm for large multi-modal language models that can support
multiple modalities concurrently, drawing inspiration from the concept
of modularization [mplug2](None), [mplug](None), [e2evlp](None), [hitea](https://doi.org/10.48550/arXiv.2212.14546). Our
method harnesses the power of pre-trained LLM, visual knowledge module,
and connected visual abstractor module to achieve effective alignment
between images and text, and utilizes a two-stage training scheme to
stimulate impressive unimodal and multimodal abilities. Our approach
even enhances the strong generation abilities of LLM by modality
collaboration between modalities. In the first step, we align the image
and text to acquire comprehensive visual knowledge using text-image
pairs, which is accomplished by training the visual knowledge module and
abstractor module with the frozen LLM module. Subsequently, we fine-tune
mPLUG-Owl with language-only and multi-modal instructions to unlock a
range of unimodal and multimodal abilities. We freeze the visual
knowledge module and train low-rank adaption (LoRA)
[lora](http://arxiv.org/pdf/2402.11485v1) on LLM and visual abstractor module jointly. This
approach allows for the effective integration of textual and visual
information, facilitating the development of versatile and robust
cognitive abilities.
Our experiments on a carefully-built visually related instruction
evaluation set OwlEval shows that mPLUG-Owl outperforms existing models
such as MiniGPT-4 [minigpt4](http://arxiv.org/pdf/2402.17510v1) and LLaVA
[llava](http://arxiv.org/pdf/2402.11690v1). We separately verifies mPLUG-Owl’s remarkable
abilities in instruction understanding, visual understanding, knowledge
transfer, and multi-turn dialogue. Abundant ablation study is performed
to show the effectiveness of our training paradigm. Furthermore, we find
some unexpected emerging ability such as multi-image correlation,
multilingual conversation and scene text understanding.
Our main contributions can be highlighted as follows:
- We propose mPLUG-Owl, a novel training paradigm for large language
models through modularization.
- We carefully construct an instruction evaluation set, dubbed
**OwlEval**, to assess the capabilities of different models in the
context of visual-related tasks.
- Experimental results demonstrate that mPLUG-Owl excels in
multi-modal instruction understanding and multi-turn dialogue,
surpassing the performance of existing models.
# Related Work
## Large Language Models
In recent times, Large Language Models (LLMs) have garnered increasing
attention for their exceptional performance in diverse natural language
processing (NLP) tasks. Initially, transformer models such as BERT
[bert](None), GPT [gpt1](http://arxiv.org/pdf/2310.01427v1), and T5
[t5](None) were developed with different pre-training
objectives. However, the emergence of GPT-3 [gpt3](http://arxiv.org/pdf/2112.07522v2),
which scales up the number of model parameters and data size, showcases
significant zero-shot generalization abilities, enabling them to perform
commendably on previously unseen tasks. Consequently, numerous LLMs such
as OPT [opt](None), BLOOM [bloom](None), PaLM
[palm](http://arxiv.org/pdf/2209.05735v4), and LLaMA [llama](http://arxiv.org/pdf/2402.08075v1) are created,
ushering in the success of LLMs. Additionally, Ouyang et al.
[instructgpt](http://arxiv.org/pdf/2302.05206v1) propose InstructGPT by aligning human
instruction and feedback with GPT-3. Furthermore, it has been applied to
ChatGPT [chatgpt](https://openai.com/blog/chatgpt), which facilitates conversational
interaction with humans by responding to a broad range of diverse and
intricate queries and instructions.
## Multi-Modal Large Language Models
Despite the successful applications of LLMs in natural language
processing, it is still struggling for LLMs to perceive other modalities
such as vision and audio. Recently, researchers have been extending
language models to understand visual inputs in two different paradigms:
systematic collaboration and end-to-end trained models. Systematic
collaboration approaches, such as Visual ChatGPT
[visualchatgpt](None), MM-REACT [mmreact](None), and
HuggingGPT [hugginggpt](None), leverage various vision experts
or tools to express visual information with text descriptions.
Subsequently, large language models, such as ChatGPT, can act as the
agents, and be prompted to select the appropriate experts and tools for
visual understanding. Finally, LLMs would summarize the output of these
experts to answer user queries. On the other hand, some approaches
[blip2](None), [flamingo](http://arxiv.org/pdf/2205.07065v1), [llava](http://arxiv.org/pdf/2402.11690v1) leverage the pre-trained large
language model to build unified models for multi-modality. For example,
Flamingo [flamingo](http://arxiv.org/pdf/2205.07065v1) freezes the pre-trained vision
encoder and large language model and fuses vision and language
modalities with gated cross-attention showing impressive few-shot
capabilities. Additionally, BLIP-2 [blip2](None) designs
Q-Former to align the visual features from the frozen visual encoder and
large language models with Flan-T5 [flant5](http://arxiv.org/pdf/2202.03371v1) and OPT
[opt](None). Moreover, PaLM-E [palm-e](http://arxiv.org/pdf/2302.14030v3)
directly inputs features from sensor modalities with PaLM
[palm](http://arxiv.org/pdf/2209.05735v4), which has 520 billion parameters, contributing
to robust performance in real-world perceptions. Furthermore, some
powerful instruction-tuned language models that built upon open-sourced
foundation model LLaMA [llama](http://arxiv.org/pdf/2402.08075v1), such as Alpaca
[alpaca](https://github.com/tatsu-lab/stanford_alpaca) and Vicuna [vicuna](https://github.com/lm-sys/FastChat), exhibit
comparable performance to ChatGPT [chatgpt](https://openai.com/blog/chatgpt) and GPT-4
[gpt4](None). MiniGPT-4 [minigpt4](http://arxiv.org/pdf/2402.17510v1) and LLaVA
[llava](http://arxiv.org/pdf/2402.11690v1) align these finetuned models with extracted
visual features from the frozen visual backbone. In contrast, mPLUG-Owl
not only aligns the representation between the vision and language
foundation model (e.g. CLIP and LLaMA) in terms of knowledge acquisition
and grounding to the real world but also can understand language and
multi-modal instructions, showcasing strong zero-shot generalization and
multi-turn conversation capabilities.
# mPLUG-Owl
## Architecture Overview
As illustrated in Figure
1, there exist mainly three
types of end-to-end multimodal LLMs: 1) models that utilize limited
parameters with frozen LLM and visual models during pretraining and
instruction tuning, such as MiniGPT4; 2) models that incorporate
trainable LLMs and frozen visual models, exemplified by Kosmos-1; and 3)
models that involve trainable LLMs during instruction tuning and frozen
visual models, as seen in LLaVA. Nevertheless, these models exhibit
certain constraints since they depend on frozen visual models, which can
lead to insufficient alignment due to the limited number of parameters.
Furthermore, they fail to effectively stimulate a diverse set of
abilities, as they lack both unimodal and multimodal instruction.
To this end, we propose mPLUG-Owl, a multi-modal language model that is
capable of perceiving various modalities while taking the visual context
and information into account and generating corresponding outputs.
Specifically, as illustrated in Figure
[fig:model], mPLUG-Owl consists of a
vision foundation model $f_{\mathbf{V}}$ to encode the visual knowledge,
a language foundation model $f_{\mathbf{L}}$, and a visual abstractor
module $f_{\mathbf{K}}$. We first obtain dense image representations
from the pre-trained visual foundation model $f_{\mathbf{V}}$. However,
such dense features would fragment the fine-grained image information
and bring large computation due to the lengthy sequence when feeding
into $f_{\mathbf{L}}$. To mitigate this issue, we employ the visual
abstractor module $f_{\mathbf{K}}$ to summarize visual information
within several learnable tokens, thereby obtaining higher semantic
visual representations and reducing computation, as illustrated in
Figure [fig:model]. The visual representations
are combined with text queries and fed into the language model to
generate the response.
## Training Scheme
#### Multimodal Pretraining
Large-scale language models, such as GPT-3 [gpt3](http://arxiv.org/pdf/2112.07522v2) and
LLaMA [llama](http://arxiv.org/pdf/2402.08075v1), are trained on extensive and diverse data
collected from the internet, providing them with a comprehensive
understanding of the world. This vast knowledge base endows these models
with remarkable capabilities across a range of tasks. However, the
utilization of visual information in such models remains underexplored.
Previous approaches [minigpt4](http://arxiv.org/pdf/2402.17510v1), [llava](http://arxiv.org/pdf/2402.11690v1) have employed a
limited number of additional parameters to learn the alignment between
visual data and language models, constraining their capacity to
comprehend complex visual information. To enhance the ability of
large-scale language models to perceive visual information while
integrating their internal abilities, we propose a novel training
paradigm that incorporates a trainable visual backbone $f_{\mathbf{V}}$
and an additional visual abstractor $f_{\mathbf{K}}$, while maintaining
the pre-trained language model $f_{\mathbf{L}}$ in a frozen state. This
approach enables the model to effectively capture both low-level and
higher semantic visual information and align it with the pre-trained
language model without compromising its performance.
#### Joint Instruction Tuning
Upon completion of the prior phase, the model acquires the ability to
retain a considerable amount of knowledge and provide reasonable answers
to human queries. Nonetheless, it continues to exhibit challenges in
generating coherent linguistic responses. As posited in GPT-3
[gpt3](http://arxiv.org/pdf/2112.07522v2), refining the model through instruction tuning is
essential for accurately discerning user intentions. Previous attempts
[mplug](None), [mplug2](None) in multi-modal learning have
demonstrated that joint learning from uni-modal and multi-modal sources
can lead to significant improvements owing to the collaboration between
different modalities. Building on this insight, we present a novel
vision-language joint instruction tuning strategy to facilitate better
alignment between mPLUG-Owl and human instructions and intentions.
Specifically, given that the model can comprehend the visual concepts
and knowledge depicted in images through visual knowledge learning, we
freeze the entire model and employ low-rank adaption (i.e., LoRA
[lora](http://arxiv.org/pdf/2402.11485v1)) to adapt $f_{\mathbf{L}}$ by training multiple
low-rank matrices for efficient alignment with human instructions. For
each data record, we unified them in a snippet of conversation following
Vicuna [vicuna](https://github.com/lm-sys/FastChat), and we compute the loss on the
response. During the training, we accumulate the gradient for text-only
instruction data and multi-modal instruction data for multiple batches
and updated the parameters. Therefore, by joint training with both
language and multi-modal instructions, mPLUG-Owl can better understand a
wide range of instructions and respond with more natural and reliable
output. Moreover, our approach can easily handle various text and
multi-modal instructions without the need for realignment of the vision
and language models, as required by methods such as MiniGPT-4
[minigpt4](http://arxiv.org/pdf/2402.17510v1) and LLaVA [llava](http://arxiv.org/pdf/2402.11690v1).
#### Training Objective
The model is trained using the language modeling task, which entails
learning to generate subsequent tokens based on the preceding context.
The primary objective of the training process is to maximize the
log-likelihood of the tokens. It is important to note that only discrete
tokens, such as text tokens, are considered in the calculation of the
training loss. Most significantly, the emergence of diverse capabilities
resulting from the training task during the joint instruction tuning
stage enhances the performance of mPLUG-Owl in downstream applications.
# Experiment
## Experimental Setup
#### Model Settings.
We choose ViT-L/14 [vit](http://arxiv.org/pdf/2105.15075v2) as the visual foundation model
$f_{\mathbf{V}}$ which has 24 layers with hidden dimension set as 1024
and patch size set as 14. For faster convergence, the ViT is initialized
from CLIP ViT-L/14 model pre-trained via contrastive learning. Different
with LLaVA [llava](http://arxiv.org/pdf/2402.11690v1) and MiniGPT-4
[minigpt4](http://arxiv.org/pdf/2402.17510v1), to demonstrate the effectiveness and
generalization ability, we utilize raw LLaMA-7B [llama](http://arxiv.org/pdf/2402.08075v1)
rather than its instruction-tuned variants such as Alpaca
[alpaca](https://github.com/tatsu-lab/stanford_alpaca) and Vicuna [vicuna](https://github.com/lm-sys/FastChat). The total
number of parameters of mPLUG-Owl is about 7.2B. More details about
hyper-parameters can be found in Appendix.
#### Data and Training Details.
For the first stage, we utilize the image-caption pairs from several
datasets, including LAION-400M [laion400m](None), COYO-700M
[coyo700m](https://github.com/kakaobrain/coyo-dataset), Conceptual Captions
[conceptualcap](None) and MSCOCO [cococap](None). We
use a batch size of 2.1 million tokens and train mPLUG-Owl for 50k
steps, corresponding to about 104 billion tokens. We adopt the AdamW
optimizer with $\beta=(0.9, 0.98)$, and set the learning rate and weight
decay to 0.0001 and 0.1 respectively. We warm up the training with 2k
warm-up steps then decay the learning rate with the cosine schedule. The
input image is randomly resized to $224\times 224$. Besides, we tokenize
the text input with SentencePiece [sentencepiece](None)
tokenizer. For the second stage, we gather pure text instruction data
from three distinct sources: 102k data from the Alpaca
[alpaca](https://github.com/tatsu-lab/stanford_alpaca), 90k from the Vicuna [vicuna](https://github.com/lm-sys/FastChat),
and 50k from the Baize [baize](None). Additionally, we utilize
150k multi-modal instruction data from the LLaVA dataset
[llava](http://arxiv.org/pdf/2402.11690v1). We train mPLUG-Owl for 2k steps with the batch
size 256, and the learning rate is set to 0.00002.
#### Baselines.
We compare our mPLUG-Owl with end-to-end models and systematic
collaboration approaches as follows:
- *OpenFlamingo* [openflamingo](None) is an open-source
version of Flamingo [flamingo](http://arxiv.org/pdf/2205.07065v1) model. We use the
released code of OpenFlamingo-9B[^3] to run zero-shot generation.
- *BLIP-2* [blip2](None) is pre-trained through bootstrapped
learning from off-the-shelf frozen pre-trained image models and
large language models using an efficient pre-training strategy. We
use the released code of BLIP-2 ViT-G FlanT5$_{XXL}$[^4] to perform
zero-shot generation.
- *MiniGPT-4* [minigpt4](http://arxiv.org/pdf/2402.17510v1) utilizes a single projection
layer to align visual information from a pre-trained vision encoder
with LLM. Specifically, they employ the same visual encoder as used
in BLIP-2, a ViT coupled with their pre-trained Q-Former, and Vicuna
as LLM. We use the released demonstration[^5] to perform
image-instruction generation.
- *LLaVA* [llava](http://arxiv.org/pdf/2402.11690v1) applies a single projection layer to
convert image features from pre-trained CLIP visual encoder ViT-L/14
into the language embedding space of Vicuna. We use their released
demonstration[^6] to perform image-instruction generation.
- *MM-REACT* [mmreact](None) integrates ChatGPT/GPT-4 with
various specialized vision experts to achieve multimodal reasoning
and action. We use their released demonstration[^7] to get
responses.
## Quantitative analysis
In order to comprehensively evaluate various models, we construct a
visually-related evaluation set **OwlEval** by collecting 82
artificially constructed questions based on 50 images, where 21 from
MiniGPT-4, 13 from MM-REACT, 9 from BLIP-2, 3 from GPT-4 and 4 collected
by us. Partial images have multiple rounds of questions, refers to
multi-turn conversation cases. These questions examine a variety of
model capabilities including natural image understanding, diagram and
flowchart comprehension, optical character recognition (OCR),
multi-modal creation, knowledge-intensive QA, and referential
interaction QA. As questions are open-ended, we employ manual evaluation
metrics to rate the model’s responses as A, B, C, or D following the
rating method proposed in Self-Instruct [self-instruct](https://doi.org/10.48550/arXiv.2212.10560).
We manually score 82 responses given by mPLUG-Owl and baselines. The
comparison results are shown in
Figure 2. First, mPLUG-Owl gets 66 $A$
and $B$, while the most competitive baseline MiniGPT-4 gets 54. Second,
mPLUG-Owl doesn’t get any $D$ scores, outperforming all the models.
These results suggest that mPLUG-Owl can better understand both
instructions and images, which results in a stronger capability in
generating satisfactory responses. For a fair comparison, we have
excluded those cases in which MM-REACT failed to make predictions. The
results are shown separately in
Figure 14 and mPLUG-Owl still exhibits
superior performance.
To separately examine the single-turn and multi-turn conversation
capabilities, we reorganize 82 questions into a single-turn conversation
set and a multi-turn conversation set. The former contains the first
question from 50 images. The latter contains 52 questions from
multi-turn conversation cases. As shown in
Figure 3, the mPLUG-Owl achieves
outstanding performance in both single-turn and multi-turn
conversations.
The comparison results of 50 single-turn responses (left)
and 52 multi-turn responses (right) among mPLUG-Owl and baselines on
OwlEval with manual evaluation metrics.
## Ablation Study
We ablate the two-stage training scheme and the data modality of
instruction tuning. Six dimensions of abilities are defined to complete
visually related tasks, as shown in
Table [fig:mult-modle-level]. For
each question, we manually label the required abilities and annotate
which abilities are reflected in the model’s response.
Table [tb:ablation] shows the ability
accuracy of different variants of mPLUG-Owl.
**Training Strategy Ablation.** As shown in
Table [tb:ablation], without joint
instruction tuning, the model is not good at instruction understanding
and fail to generalize pre-training abilities to other tasks (r1 vs r5).
With the instruction tuning alone, although the model can better
comprehend instructions, the model is incapable of achieving promising
performance in visual knowledge-related tasks due to lacking of
visually-related knowledge pretraining (r2 vs r5). With both multimodal
pretraining and joint instruction tuning, the model achieves the best
performance and demonstrates the effectiveness of our two-stage training
scheme.
**Instruction Data Ablation.** By comparing r3 with r4, text-only
instruction tuning brings more improvement in instruction understanding,
while multi-modal instruction tuning achieves better knowledge and
reasoning capabilities. This is due to that visual question answering
mainly requires the alignment of vision and language knowledge, which is
not optimized during text-only instruction tuning. Besides, we also
verify that introducing multi-modal data during instruction tuning could
further improve the model’s performance on text-only tasks, as shown in
Table [tab:text-only result] (r5 vs
r4). Concretely, following the evaluation setting as
Vicuna[vicuna](https://github.com/lm-sys/FastChat), for each question, we pair the response
of each model with the one given by ChatGPT and prompt ChatGPT[^8] to
give two scores respectively for these two responses. Table
[tab:text-only result] shows
the total score and the score ratio with the ChatGPT score as a
reference.
## Qualitative Analysis
In this section, we show qualitative results from our evaluation set
OwlEval.
A comparison of Knowledge-intensive QA.
#### Knowledge-intensive QA
As shown in Figure 4, the instruction expects the model to
identify the movie characters in the image. MM-REACT is unable to
provide an effective response to the instruction, while MiniGPT-4
understands the instruction but failed to answer the movie characters.
In contrast, mPLUG-Owl answers four out of the five characters present
in the image. This demonstrates that mPLUG-Owl has a better
understanding of the knowledge in the image.
A comparison of Multi-turn Conversation.
#### Multi-round Conversation
The instruction in
Figure 5 requires the model to identify
the content of the image based on the referential information. The
baseline models often made mistakes when faced with referential
expressions related to spatial orientation, human behavior, and target
attributes in the questions, whereas mPLUG-Owl provided the most
accurate response. This capability stems from mPLUG-Owl’s fine-grained
understanding of the image, allowing it to locate the corresponding part
of the image based on the referential information in the instruction.
A comparison of Reasoning QA.
#### Reasoning
Figure 6 shows an instruction asking models
to give a prediction based on visual information and explain the reason.
mPLUG-Owl analyzes the characteristics of the two teams from the aspects
of the lineup and tactics and uses them to reason for the outcome.
Although MiniGPT-4 also performs well, its persuasiveness in reasoning
is slightly inferior to mPLUG-Owl.
A comparison of Joke Understanding.
#### Joke Comprehension
The case in Figure 7 comes from the
GPT-4[gpt4](None), which requires the model to understand and
explain a visually related joke. GPT-4 not only follows the instructions
in performing analysis panel by panel but also almost perfectly
understands the humor of the charging method. mPLUG-Owl also understands
this unusual humor, but it incorrectly identified the “VGA” to “USB”.
This is mainly due to the limitation of visual information in our
training data. More cases about joke comprehension are shown in
Figure 8.
# Discussion and Limitation
In this section, we show some nascent abilities of mPLUG-Owl that is not
yet fully developed and discuss the limitation. Part of cases (without
scores) in this section are not in OwlEval.
Multi-image correlation cases.
#### Multi-image Correlation
In Figure 9, mPLUG-Owl shows a
emerging but not strong vision correlation capability across multiple
images. In the left case, the model could identify an identical person
in two images and correctly tell the difference of cloth color. But in
the left case, the model fails to relate 4 images and produces some text
hallucinations.
Example prompt of multilingual understanding which showcases
the multilingual abilities across Chinese, French, and Japanese,
respectively.
#### Multilingual Conversation
Besides English, we further test the model’s multilingual ability. As
shown in Figure 10, although there is no
multilingual data during our two-stage training, mPLUG-Owl shows a
promising multilingual understanding for Chinese, French and Japanese.
We mainly attribute this ability to the raw text knowledge in
LLaMa[llama](http://arxiv.org/pdf/2402.08075v1). However, due to the lacking of
multilingual training, mPLUG-Owl may fail to response in corresponding
languages.
#### Scene Text Understanding
In Figure 15, mPLUG-Owl demonstrates its OCR
ability in some simple scenes, but we can see that the model’s
perception of numbers in images is still limited. However, for the OCR
of complex scenes, as shown in Figure
16-17, the performance of mPLUG-Owl
is more general, mainly because the perception of numbers in images is
weak, which affects the subsequent reasoning calculation.
#### Vision-only Document Comprehension
Although we did not use any document annotation data for training, the
model exhibited some text recognition and document understanding
capabilities. Hence, we delved deeper into the combination of document
understanding and functionality of our model. as illustrated in Figure
11, we explored movie review
writing, code generation, code explanation, chat summary, and
application guidance. The model show decent performance in (a) and (b),
but still, had some errors. Meanwhile, it was unable to provide usable
responses in (d), (e), and (f). Therefore, there is further scope to
explore our model’s potential in document understanding and downstream
applications.
#### Open-ended Creation
mPLUG-Owl performs well in the creation of poetry, lyrics,
advertisements and other works based on images. Its performance in some
cases is shown in Figure
12-13. However, further exploration is
needed for more functional and practical creations.
Copywriting cases.
# Conclusion
We propose mPLUG-Owl, a novel training paradigm that enhances the
multi-modal abilities of large language models (LLMs). Our approach
consists of modularized learning of foundation LLM, a visual knowledge
module, and a visual abstractor module, which can support multiple
modalities and facilitate diverse unimodal and multimodal abilities
through modality collaboration. We employ a two-stage method for
aligning image and text, which learns visual knowledge with the
assistance of LLM while maintaining and even improving the generation
abilities of LLM. Experimental results demonstrate the impressive
capabilities of mPLUG-Owl, indicating its potential for various
applications in multi-modal generation.
# Training Hyperparameters
We report the detailed model training hyperparameters for visual
knowledge learning in
Table 1 and vision-language joint
instruction tuning in
Table 2.
| **Hyperparameters** | |
|:-------------------------------------------|:------------:|
| Training steps | 2,000 |
| Warmup steps | 50 |
| Max length | 1,024 |
| Batch size of text instruction data | 128 |
| Batch size of multi-modal instruction data | 128 |
| Optimizer | AdamW |
| Learning rate | 2e-5 |
| Learning rate decay | Cosine |
| AdamW $\epsilon$ | 1e-6 |
| AdamW $\beta$ | (0.9, 0.999) |
| Weight decay | 0.0001 |
Training hyperparameters for vision-language joint instruction tuning
stage.
# Comparison with MM-REACT
The comparison results which exclude the cases that were
generated unsuccessfully by MM-REACT.
[^1]: Equal contribution
[^2]: Corresponding author
[^3]:
[^4]:
[^5]:
[^6]:
[^7]:
[^8]: Without access to the GPT-4, we use the ChatGPT as the suboptimal
scorer.
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
2023-04-20
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, Mohamed Elhoseiny
The recent GPT-4 has demonstrated extraordinary multi-modal abilities, such as directly generating websites from handwritten text and identifying humorous elements within images. These features are rarely observed in previous vision-language models. However, the technical details behind GPT-4 continue to remain undisclosed. We believe that the enhanced multi-modal generation capabilities of GPT-4 stem from the utilization of sophisticated large language models (LLM). To examine this phenomenon, we present MiniGPT-4, which aligns a frozen visual encoder with a frozen advanced LLM, Vicuna, using one projection layer. Our work, for the first time, uncovers that properly aligning the visual features with an advanced large language model can possess numerous advanced multi-modal abilities demonstrated by GPT-4, such as detailed image description generation and website creation from hand-drawn drafts. Furthermore, we also observe other emerging capabilities in MiniGPT-4, including writing stories and poems inspired by given images, teaching users how to cook based on food photos, and so on. In our experiment, we found that the model trained on short image caption pairs could produce unnatural language outputs (e.g., repetition and fragmentation). To address this problem, we curate a detailed image description dataset in the second stage to finetune the model, which consequently improves the model's generation reliability and overall usability. Our code, pre-trained model, and collected dataset are available at https://minigpt-4.github.io/.
Show Paper Content
# Introduction
# Related Works
# Method
# Experiments
## Limitation analysis
# Discussion
# Appendix
[^1]: equal contribution
The recent GPT-4 has demonstrated extraordinary multi-modal abilities,
such as directly generating websites from handwritten text and
identifying humorous elements within images. These features are rarely
observed in previous vision-language models. However, the technical
details behind GPT-4 continue to remain undisclosed. We believe that the
enhanced multi-modal generation capabilities of GPT-4 stem from the
utilization of sophisticated large language models (LLM). To examine
this phenomenon, we present MiniGPT-4, which aligns a frozen visual
encoder with a frozen advanced LLM, Vicuna, using one projection layer.
Our work, for the first time, uncovers that properly aligning the visual
features with an advanced large language model can possess numerous
advanced multi-modal abilities demonstrated by GPT-4, such as detailed
image description generation and website creation from hand-drawn
drafts. Furthermore, we also observe other emerging capabilities in
MiniGPT-4, including writing stories and poems inspired by given images,
teaching users how to cook based on food photos, and so on. In our
experiment, we found that the model trained on short image caption pairs
could produce unnatural language outputs (e.g., repetition and
fragmentation). To address this problem, we curate a detailed image
description dataset in the second stage to finetune the model, which
consequently improves the model’s generation reliability and overall
usability. Our code, pre-trained model, and collected dataset are
available at .
In recent years, large language models (LLMs) have experienced rapid
advancements [instructGPT](http://arxiv.org/pdf/2302.05206v1), [chatgpt](http://arxiv.org/pdf/2307.11380v2), [gpt3](http://arxiv.org/pdf/2112.07522v2), [bloom](http://arxiv.org/pdf/2106.06683v2), [llama](http://arxiv.org/pdf/2402.08075v1), [chowdhery2022palm](http://arxiv.org/pdf/2209.05735v4), [hoffmann2022training](http://arxiv.org/pdf/2202.03371v1).
With exceptional language understanding capabilities, these models can
perform a variety of intricate linguistic tasks in a zero-shot manner.
Notably, GPT-4, a large-scale multimodal model, has been recently
introduced and demonstrated several impressive capabilities of
vision-language understanding and generation [gpt4](http://arxiv.org/pdf/2311.15732v2). For
example, GPT-4 can produce detailed and accurate image descriptions,
explain unusual visual phenomena, and even construct websites based on
handwritten text instructions.
Although GPT-4 has exhibited remarkable vision language capabilities,
the methods behind its exceptional abilities are still a mystery
[gpt4](http://arxiv.org/pdf/2311.15732v2). We believe that these impressive skills may stem
from the utilization of a more advanced large language model (LLM). LLMs
have demonstrated various emergent abilities, as evidenced in GPT-3’s
few-shot prompting setup [gpt3](http://arxiv.org/pdf/2112.07522v2) and the findings of Wei
*et al*. (2022) [wei2022emergent](https://openreview.net/forum?id=yzkSU5zdwD). Such emergent
properties are hard to find in smaller-scale models. It is conjectured
that these emergent abilities are also applicable to multi-modal models,
which could be the foundation of GPT-4’s impressive visual description
capabilities.
To substantiate our hypothesis, we present a novel vision-language model
named MiniGPT-4. It utilizes an advanced large language model (LLM),
Vicuna [vicuna2023](https://vicuna.lmsys.org), which is built upon
LLaMA [llama](http://arxiv.org/pdf/2402.08075v1) and reported to achieve 90% of ChatGPT’s
quality as per GPT-4’s evaluation, as the language decoder. In terms of
visual perception, we employ the same pretrained vision components of
BLIP-2 [blip2](http://arxiv.org/pdf/2301.12597v3) that consists of a ViT-G/14 from
EVA-CLIP [fang2022eva](http://arxiv.org/pdf/2402.18128v1) and a Q-Former network. MiniGPT-4
adds a single projection layer to align the encoded visual features with
the Vicuna language model and freezes all the other vision and language
components. MiniGPT-4 is initially trained for 20k steps using a batch
size of 256 on 4 A100 GPUs, leveraging a combined image captioning
dataset that includes images from LAION [laion](http://arxiv.org/pdf/2111.02114v1),
Conceptual
Captions [changpinyo2021conceptual](http://arxiv.org/pdf/2102.08981v2), [sharma2018conceptual](http://arxiv.org/pdf/2304.13130v1),
and SBU [ordonez2011im2text](http://arxiv.org/pdf/2204.00679v1) to align visual features
with the Vicuna language model. Nevertheless, merely aligning visual
features with the language model (LLM) is inadequate to ensure robust
visual conversation capabilities, resembling that of a chatbot. The
presence of underlying noise in raw image-text pairs can lead to subpar
language outputs. Therefore, we collect another 3,500 detailed image
description pairs to further fine-tune the model with a designed
conversational template in order to improve the naturalness of the
generated language and its usability.
In our experiments, we discovered that MiniGPT-4 possesses numerous
capabilities similar to those demonstrated by GPT-4. For instance,
MiniGPT-4 can generate intricate image descriptions, create websites
based on handwritten text instructions, and explain unusual visual
phenomena. Furthermore, our findings revealed that MiniGPT-4 also has a
variety of other intriguing abilities not showcased in the GPT-4
demonstrations. For example, MiniGPT-4 can directly generate detailed
cooking recipes from food photos, write stories or poems inspired by
images, write advertisements for products in images, identify problems
shown in photos and provide corresponding solutions, and retrieve rich
facts about people, movies, or art directly from images, among other
capabilities. These abilities are absent in previous vision-language
models like Kosmos-1 [kosmos](http://arxiv.org/pdf/2302.14045v2) and BLIP-2
[blip2](http://arxiv.org/pdf/2301.12597v3) that use less powerful language models. This
further validates that integrating visual features with an advanced
language model is one of the keys to enhancing vision-language models.
We present a summary of our key findings:
- Our research reveals with compelling evidence that by aligning
visual features with advanced large language models like Vicuna,
MiniGPT-4 can achieve advanced vision-language capabilities
comparable to those exhibited in the GPT-4 demonstrations.
- Our findings suggest that training merely one projection layer can
effectively align a pretrained vision encoder with the large
language model. Our MiniGPT-4 only requires training approximately
10 hours on 4 A100 GPUs.
- We discovered that simply aligning visual features with large
language models using short image caption pairs is not sufficient
for developing a well-performing model and leads to unnatural
language generation. Further finetuning with a small but detailed
image description pairs can address this limitation and
significantly improves its usability.
**Large language models** have experienced tremendous success in recent
years due to the scaling up of training data and an increase in the
number of parameters. Early models, such as BERT [bert](http://arxiv.org/pdf/1810.04805v2),
GPT-2 [gpt2](http://arxiv.org/pdf/2203.12926v1), and T5 [t5](http://arxiv.org/pdf/1910.10683v4), laid the
foundation for this progress. Subsequently,
GPT-3 [gpt3](http://arxiv.org/pdf/2112.07522v2), with a massive scale of 175 billion
parameters, was introduced, demonstrating significant breakthroughs
across numerous language benchmarks. This development inspired the
creation of various other large language models, including
Megatron-Turing NLG [smith2022using](http://arxiv.org/pdf/2201.11990v3),
Chinchilla [hoffmann2022training](http://arxiv.org/pdf/2202.03371v1),
PaLM [chowdhery2022palm](http://arxiv.org/pdf/2209.05735v4),
OPT [zhang2022opt](http://arxiv.org/pdf/2405.04515v2),
BLOOM [scao2022bloom](http://arxiv.org/pdf/2106.06683v2), and
LLaMA [llama](http://arxiv.org/pdf/2402.08075v1), among others. Wei *et
al.* [wei2022emergent](https://openreview.net/forum?id=yzkSU5zdwD) further discovered several
*emergent abilities*, which appear exclusively in large models. The
emergence of these abilities underscores the importance of scaling up in
the development of large language models. Moreover, by aligning the
pre-trained large language model GPT-3 with human intent, instructions
and human feedback, InstructGPT [instructGPT](http://arxiv.org/pdf/2302.05206v1) and
ChatGPT [chatgpt](http://arxiv.org/pdf/2307.11380v2) enable conversational interactions
with humans and can answer a wide range of diverse and complex
questions. More recently, several open-sourced models, such as
Alpaca [alpaca](https://github.com/tatsu-lab/stanford_alpaca) and Vicuna [vicuna2023](https://vicuna.lmsys.org),
have been developed based on LLaMA [llama](http://arxiv.org/pdf/2402.08075v1) and also
exhibit similar performance.
**Leveraging Pre-trained LLMs in Vision-Language Tasks.** In recent
years, the trend of using autoregressive language models as decoders in
vision-language tasks has gained significant
traction [visualgpt](http://arxiv.org/pdf/2102.10407v5), [kosmos](http://arxiv.org/pdf/2302.14045v2), [yang2022zero](http://arxiv.org/pdf/2206.08155v2), [tiong2022plug](http://arxiv.org/pdf/2210.08773v3), [alayrac2022flamingo](http://arxiv.org/pdf/2205.07065v1), [blip2](http://arxiv.org/pdf/2301.12597v3), [blip1](http://arxiv.org/pdf/2311.01038v2), [palm_e](http://arxiv.org/pdf/2302.14030v3).
This approach takes advantage of cross-modal transfer, allowing
knowledge to be shared between language and multimodal domains.
Pioneering studies like VisualGPT [visualgpt](http://arxiv.org/pdf/2102.10407v5) and
Frozen [tsimpoukelli2021multimodal](http://arxiv.org/pdf/2106.13884v2) have demonstrated
the benefits of employing a pre-trained language model as a
vision-language model decoder.
Flamingo [alayrac2022flamingo](http://arxiv.org/pdf/2205.07065v1) was then developed to
align a pre-trained vision encoder and language model using gated
cross-attention, and was trained on billions of image-text pairs,
showcasing impressive in-context few-shot learning capabilities.
Following that, BLIP-2 [blip2](http://arxiv.org/pdf/2301.12597v3) was introduced, employing
a Flan-T5 [flanT5](http://arxiv.org/pdf/2202.03371v1) with a Q-Former to efficiently align
visual features with the language model. Most recently,
PaLM-E [palm_e](http://arxiv.org/pdf/2302.14030v3), featuring 562 billion parameters, has
been developed to integrate real-world continuous sensor modalities into
an LLM, thereby establishing a connection between real-world perceptions
and human languages. GPT-4 [gpt4](http://arxiv.org/pdf/2311.15732v2) has also been recently
released, showcasing more powerful visual understanding and reasoning
abilities after pre-training on a vast collection of aligned image-text
data.
LLMs, such as ChatGPT, have proven to be powerful tools in enhancing the
performance of vision-language tasks by collaborating with other
specialized models. For instance, Visual
ChatGPT [visualChatGPT](http://arxiv.org/pdf/2303.04671v1) and
MM-REACT [yang2023mmreact](http://arxiv.org/pdf/2303.11381v1) showcase how ChatGPT can act
as a coordinator, integrating with diverse visual foundation models and
facilitating their collaboration to tackle more complex challenges.
ChatCaptioner [chatcaptioner](http://arxiv.org/pdf/2303.06594v1) treats ChatGPT as a
questioner, prompting diverse questions for BLIP-2 to answer. Through
multi-round conversations, ChatGPT extracts visual information from
BLIP-2 and effectively summarizes the image content. Video
ChatCaptioner [chen2023video](http://arxiv.org/pdf/2304.04227v3) extends this approach,
applying it to video spatiotemporal understanding.
ViperGPT [vipergpt](http://arxiv.org/pdf/1905.11127v1) demonstrates the potential of
combining an LLM with different vision models to address complex visual
queries programmatically. In contrast, MiniGPT-4 directly aligns visual
information with the language model to accomplish diverse
vision-language tasks without the usage of external vision models.
MiniGPT-4 aims to align visual information from a pretrained vision
encoder with an advanced large language model (LLM). Specifically, we
utilize the Vicuna [vicuna2023](https://vicuna.lmsys.org) as our language decoder,
which is constructed upon LLaMA [llama](http://arxiv.org/pdf/2402.08075v1) and can perform
a wide range of complex linguistic tasks. For visual perception, we
employ the same visual encoder as used in
BLIP-2 [blip2](http://arxiv.org/pdf/2301.12597v3), a ViT
backbone [fang2022eva](http://arxiv.org/pdf/2402.18128v1) coupled with their pre-trained
Q-Former. Both language and vision models are open-sourced. We target to
bridge the gap between the visual encoder and LLM using a linear
projection layer, with an overview of our model displayed in
Fig.[fig:overview].
To achieve an effective MiniGPT-4, we propose a two-stage training
approach. The initial stage involves pretraining the model on a large
collection of aligned image-text pairs to acquire vision-language
knowledge. In the second stage, we finetune the pretrained model with a
smaller but high-quality image-text dataset with a designed
conversational template to enhance generation reliability and usability.
## First pretraining stage
During the initial pretraining stage, the model is designed to acquire
vision-language knowledge from a large collection of aligned image-text
pairs. We regard the output from the injected projection layer as a soft
prompt for the LLM, prompting it to generate the corresponding
ground-truth texts.
Throughout the entire pretraining process, both the pretrained vision
encoder and the LLM remain frozen, with only the linear projection layer
being pretrained. We use a combined dataset of Conceptual Caption
[changpinyo2021conceptual](http://arxiv.org/pdf/2102.08981v2), [sharma2018conceptual](http://arxiv.org/pdf/2304.13130v1), SBU
[ordonez2011im2text](http://arxiv.org/pdf/2204.00679v1) and LAION [laion](http://arxiv.org/pdf/2111.02114v1)
to train our model. Our model undergoes 20,000 training steps with a
batch size of 256, covering approximately 5 million image-text pairs.
The entire process takes about 10 hours to complete, utilizing 4 A100
(80GB) GPUs.
**Issues of the first pretraining stage** Following the first
pretraining stage, our MiniGPT-4 demonstrates the capacity to possess a
wealth of knowledge and offer reasonable responses to human inquiries.
However, we have observed instances where it produces incoherent
linguistic outputs, such as repetitive words or sentences, fragmented
sentences, or irrelevant content. These issues hinder MiniGPT-4’s
ability to engage in a fluent visual conversation with humans.
We also observed similar challenges encountered in GPT-3. Despite its
pretraining on a extensive language dataset, GPT-3 struggles to generate
language outputs that are accurately aligned with users’ intentions.
Through a process of instruction fine-tuning and reinforcement learning
from human feedback, GPT-3 evolves into GPT-3.5
[instructGPT](http://arxiv.org/pdf/2302.05206v1), [chatgpt](http://arxiv.org/pdf/2307.11380v2) and becomes capable of producing
more human-friendly outputs. This phenomenon bears a resemblance to the
current state of MiniGPT-4 following its initial pretraining stage. As
such, it is not surprising that our model may struggle to generate
fluent and natural human language outputs at this stage.
## Curating a high-quality alignment dataset for vision-language domain.
To achieve greater naturalness in the generated language and enhance the
model’s usability, a second-stage alignment process is essential. While
in the realm of NLP, instruction fine-tuning datasets
[alpaca](https://github.com/tatsu-lab/stanford_alpaca) and conversations [sharegpt](https://github.com/domeccleston/sharegpt)
are easily accessible, no equivalent datasets exist for the
vision-language domain. To address this deficiency, we carefully curated
a detailed image description dataset, specifically tailored for
vision-language alignment purposes. This dataset is subsequently
utilized to fine-tune our MiniGPT-4 during the second-stage alignment
process.
#### Initial aligned image-text generation
In the initial phase, we employ the model derived from the first
pretraining stage to generate comprehensive descriptions of input
images. To enable our model to produce more detailed image descriptions,
we designed a prompt that adheres to the conversational format of the
Vicuna [vicuna2023](https://vicuna.lmsys.org) language model, as shown below. In
this prompt, *\* represents the visual features produced
by the linear projection layer.
*\###Human: \\\Describe this image in
detail. Give as many details as possible. Say everything you see.
\###Assistant:*
To identify incomplete sentences, we examine whether the generated
sentence exceeds 80 tokens. If it does not, we incorporate an additional
prompt, *\###Human: Continue \###Assistant:* , prompting our MiniGPT-4
to extend the generation process. By concatenating the outputs from both
steps, we can create a more comprehensive image description. This
approach enables us to generate image-text pairs with detailed and
informative image descriptions. We randomly select 5,000 images from the
Conceptual Caption dataset
[changpinyo2021conceptual](http://arxiv.org/pdf/2102.08981v2), [sharma2018conceptual](http://arxiv.org/pdf/2304.13130v1) and use
the pretrained model to generate corresponding language descriptions for
each image.
#### Data post-processing
The above automatically generated image descriptions contain noisy or
incoherent descriptions, such as repetition of words or sentences,
fragmented sentences, or irrelevant content. In order to fix these
issues, we employ ChatGPT to mend the descriptions by utilizing the
following prompt:
*Fix the error in the given paragraph. Remove any repeating sentences,
meaningless characters, not English sentences, and so on. Remove
unnecessary repetition. Rewrite any incomplete sentences. Return
directly the results without explanation. Return directly the input
paragraph if it is already correct without explanation.*
Upon completing the post-processing stage, we manually verify the
correctness of each image description to guarantee its high quality.
Specifically, we first identified several frequently shown errors (*“I’m
sorry I made a mistake...”, or “I apologize for that ...”*) and then
hard-coded rules to automatically filter them out. We also manually
refine the generated captions by eliminating redundant words or
sentences that ChatGPT fails to detect. Finally, only approximately
3,500 out of 5,000 image-text pairs satisfy our requirement, and these
pairs are subsequently utilized for the second-stage alignment process.
## Second-stage finetuning
During the second stage, we finetune our pretrained model with the
curated high-quality image-text pairs. During the finetuning, we use the
predefined prompts in the following template:
*\###Human: \\\\###Assistant:*
In this prompt, *\* represents a randomly sampled
instruction from our predefined instruction set containing variant forms
of instructions such as *“Describe this image in detail”* or *“Could you
describe the contents of this image for me”*. It is important to note
that we do not calculate the regression loss for this specific
text-image prompt.
As a result, MiniGPT-4 is now capable of producing more natural and
reliable language outputs. Furthermore, we observed that this
fine-tuning process is remarkably efficient, only requiring a mere 400
training steps with a batch size of 12, which takes around 7 minutes
with a single A100 GPU.
In the experiment, we aim to showcase the diverse and emergent
capabilities of our MiniGPT-4 model through various qualitative
examples. These abilities include generating detailed image
descriptions, identifying amusing aspects within memes, providing food
recipes from photos, writing poems for images, etc. Additionally, we
present quantitative results on the task of image captioning.
## Uncovering emergent abilities with MiniGPT-4 through qualitative examples
MiniGPT-4 demonstrates many advanced abilities compared to traditional
vision-language models. For example, it can describe images in detail
and interpret the humorous aspects of a given meme. Here, we
qualitatively compared our model to one of the leading vision-language
models, BLIP-2 [blip2](http://arxiv.org/pdf/2301.12597v3), with eight distinct examples,
each highlighting a different ability.
An example in Fig.[fig:detailed] demonstrates that
MiniGPT-4 effectively identifies various elements within the image, such
as busy city streets, clock towers, shops, restaurants, motorcycles,
people, streetlights, and clouds. In contrast, BLIP-2 can only cover
city streets, people, and motorcycles in its image caption generation.
Another example presented in
Fig.2 shows that MiniGPT-4 successfully
explains why the meme is humorous. It interprets that the lying dog is
feeling the same way as many people do on Monday, which is often
considered to be the most dreaded day of the week. In contrast, BLIP-2
only briefly describes the image content and fails to comprehend the
amusing aspects of the image.
We also showcase MiniGPT-4’s other abilities by demonstrating other
distinctive abilities. These include creating advertising promotions
based on a given image (Fig.1), retrieving factual information from a
movie photograph (Fig.[fig:movie]), generating a food recipe
from a food image (Fig.[fig:cook]), diagnosing plant diseases and
suggesting treatment plans
(Fig.[fig:plant]), creating a website from a
hand-written draft
(Fig.3), and writing poems inspired by an
image (Fig.[fig:poem]). These abilities are absent in
traditional vision-language models like BLIP-2 (utilizing Flan-T5
XXL [flanT5](http://arxiv.org/pdf/2202.03371v1) as a language model), which use less
powerful language models (LLMs). This contrast indicates that those
advanced vision-language abilities only emerge when the visual features
are properly aligned with an advanced LLM such as Vicuna
[vicuna2023](https://vicuna.lmsys.org).
Model generations from BLIP-2, BLIP-2 finetuned our second
stage data (BLIP-2 FT), MiniGPT-4 finetuned with Local Narrative data in
the second stage (MiniGPT-4 LocNa), MiniGPT-4 model without Q-Former
(MiniGPT-4 No Q-Former), and MiniGPT-4.
## Quantitative analysis
#### Advanced Abilities
To quantify performance on advanced vision-language tasks, we compiled a
small evaluation dataset comprising 4 tasks: meme interpretation with
the question “Explain why this meme is funny.”, recipe generation with
the question “How should I make something like this?”, advertisement
creation with the prompt “Help me draft a professional advertisement for
this.”, and poem composition with “Can you craft a beautiful poem about
this image?”. In total, we collect 100 diverse images, with 25 images
allocated to each task. We asked human evaluators to determine whether
the model generation satisfies the request. We compared our results with
BLIP-2 [blip2](http://arxiv.org/pdf/2301.12597v3) and present the findings in
Tab.[tab: quanti_adv]. In meme
interpretation, poem writing, and advertisement creation, BLIP-2 largely
struggles to fulfill any requests. For recipe generation, BLIP-2
succeeds in 4 out of 25 cases. In contrast, MiniGPT-4 manages to address
the requests in recipes, advertisements, and poem generation in nearly
80% of the instances. Furthermore, MiniGPT-4 correctly comprehends the
challenging humor understanding in memes in 8 out of 25 cases.
#### Image Captioning
We evaluate the performance of MiniGPT-4 on the COCO caption benchmark
and compare it with BLIP-2 [blip2](http://arxiv.org/pdf/2301.12597v3). Our model’s
generated captions typically contain rich visual details. As such,
conventional similarity-based image-caption evaluation metrics struggle
to provide an accurate evaluation of our models. In this regard, we
evaluate the performance by checking if the generated captions cover all
the ground truth captions’ information with the help of ChatGPT and
details can be found in
Appx.[appx: caption_eval]. Results in
Tab.[human_evaluation] shows that
MiniGPT-4 outperforms BLIP-2 in generating captions that are more
closely aligned with the ground-truth visual objects and relationships.
With a success rate of 66.2%, MiniGPT-4 is considerably more accurate
than BLIP-2, which achieves only 27.5%. Further evaluation on
traditional VQA tasks can be found in
Appx.[appx: vqa].
## Analysis on the second-stage finetuning
#### Effectiveness of the second-stage finetuning
The utilization of only the model pretrained after the first pretraining
stage may result in failures, such as the occurrence of repetitive words
or sentences, fragmented sentences, or irrelevant content. However,
these issues have been largely mitigated through the second-stage
finetuning process. This can be observed in
Fig.[fig:secondstage], where MiniGPT-4
generates incomplete captions before the second-stage finetuning.
However, after the second-stage finetuning, MiniGPT-4 is capable of
generating complete and fluent captions. In this section, we investigate
the importance and effectiveness of the second-stage finetuning
approach.
To quantify the impact of second-stage finetuning, we randomly sampled
100 images from the COCO test set and investigated the model performance
on two tasks: detailed description generation and poem writing. The
prompts used were “*Describe the image in detail.*” and “*Can you write
a beautiful poem about this image?*”. These tasks were performed by both
the models before and after second-stage finetuning. We manually counted
the number of failure generations for the model in each stage. The
results are presented in
Tab.[exp:stage2ablation]. Prior to
the second-stage finetuning, approximately 1/3 of the generated outputs
failed to match ground truth captions or poems. In contrast, the model
after second-stage fineuning has less than two failure cases out of the
100 test images for both tasks. These experimental results demonstrate
that second-stage finetuning yields a significant improvement in the
quality of generated outputs. A qualitative example of the model
generation before and after the second-stage finetuning is shown in
Fig.[fig:secondstage].
#### Can the original BLIP-2 benefit from the second-stage data?
In this study, we finetune BLIP-2 [blip2](http://arxiv.org/pdf/2301.12597v3) with our
second-stage data in the same way as MiniGPT-4, and check if it can
obtain similar advanced abilities as MiniGPT-4. The finetuned BLIP-2 is
denoted as BLIP-2 FT. Note that MiniGPT-4 uses the same visual module as
BLIP-2; while BLIP-2 uses FlanT5 XXL [flanT5](http://arxiv.org/pdf/2202.03371v1) as the
language model, which is not as strong as the Vicuna
[vicuna2023](https://vicuna.lmsys.org) model used in our MiniGPT-4 model. We rely
on the same prompts to assess the advanced capabilities of our model.
Qualitative results are shown in
Fig.4,
[fig:ab_cook], and
[fig:ab_des]. We discover that BLIP-2 FT
still generates short responses and fails to generalize to advanced
tasks like meme explaining and website coding
(Fig.4). Our finding suggests that
BLIP-2’s relatively weaker language model FlanT5 XXL benefits less from
such a small dataset, and highlights the effectiveness of a more
advanced LLM in a VLM system.
#### Second stage with Localized Narratives
The dataset Localized Narratives [pont2020connecting](http://arxiv.org/pdf/2302.11217v2) is
a detailed image description dataset where annotators describe images
while simultaneously localizing the corresponding regions. Here, we test
the performance of our model by replacing our self-collected dataset in
the second-stage with the Localized Narratives dataset. The model is
denoted as MiniGPT-4 LocNa. Qualitative results in
Fig.4,
[fig:ab_cook], and
[fig:ab_des] show that MiniGPT-4 LocNa
can generate long image descriptions
(Fig.[fig:ab_des]). However, the generated
outputs have lower quality with monotonous expressions. Besides,
MiniGPT-4 LocNa does not generalize as well as the original MiniGPT-4 in
other complex tasks like explaining why the meme is funny
(Fig.2). The performance gap may be due to
the monotonous and repeated image descriptions in Localized Narratives.
## Ablation on the architecture designs
To further demonstrate the effectiveness of using one single linear
layer to align visual features with LLM, we conduct experiments with
different architecture designs, including (a) removing the Q-Former and
directly mapping the VIT’s output to Vicuna’s embedding space (i.e.,
without Q-former), (b) using three linear layers instead of one layer,
and (c) additionally finetuning the Q-Former in the vision module. All
the variants are trained in the same way as the original design. Results
on AOK-VQA [schwenk2022okvqa](http://arxiv.org/pdf/2206.01718v1) and GQA
[hudson2019gqa](http://arxiv.org/pdf/2112.05136v1) datasets in
Tab.[tab: ablation] show that the variant
(a) **MiniGPT-4 w/o Q-Former** has a similar performance to the original
design. Qualitative results of this variant in
Fig.4,
[fig:ab_cook], and
[fig:ab_des] also show similar advanced
skills. This reveals that the Q-Former from BLIP-2 doesn’t plays a
critical roles for advanced skills. Besides, both variants (b)
**MiniGPT-4+ 3 Layers** and (c) **MiniGPT-4 + finetuning Q-Former**,
perform slightly worse than the original MiniGPT-4. This indicates a
single projection layer is sufficient to align the vision encoder and
the large language model in our limited training data setting.
#### Hallucination
As MiniGPT-4 is built upon LLMs, it inherits LLM’s limitations like
hallucinating nonexistent knowledge. An example in Fig.
[fig:Limitation] shows that
MiniGPT-4 incorrectly identifies the presence of white tablecloths in
the image, despite their absence. Here, we use the metric
$\text{CHAIR}_i$ [rohrbach2018object](http://arxiv.org/pdf/1809.02156v2) to gauge the
hallucination rate of the generation, with the two distinct prompts to
control the model generation length: *MiniGPT-4 (long)*: Please describe
this image as detailed as possible. *MiniGPT-4 (short)*: Please describe
the image shortly and precisely, in less than 20 words.
Results in Tab.[tab:hallu] show that longer captions
tend to have higher hallucination rates. For example, MiniGPT-4 (long)
generates captions averaging 175 words with a higher hallucination rate,
while MiniGPT-4 (short) averages 28.8 words with a lower rate. BLIP-2,
averaging 6.5 words, hallucinates less but covers fewer objects as seen
in Tab.[human_evaluation]. Hallucination
in detailed image descriptions is still an unresolved issue. Using
Reinforcement Learning with AI feadback with hallucination detection
modules may be a potential solution.
#### Spatial Information Understanding
MiniGPT-4’s visual perception remains limited. It may struggle to
differentiate spatial localization. For example, MiniGPT-4 in Fig.
[fig:Limitation] fails to identify
the location of the windows. This limitation may stem from a lack of
aligned image-text data designed for spatial information understanding.
Training on such datasets like RefCOCO
[kazemzadeh2014referitgame](http://arxiv.org/pdf/1808.08754v1) or Visual Genome
[krishna2017visual](http://arxiv.org/pdf/1602.07332v1) could potentially alleviate this
issue.
How does MiniGPT-4 obtain these advanced abilities? Many of the advanced
vision-language capabilities demonstrated by GPT-4 can be understood as
compositional skills rooted in two foundational skills: image
understanding and language generation. Take the task of image-based poem
writing as an example. Advanced LLMs like ChatGPT and Vicuna can already
craft poems based on users’ instructions. If they acquire the ability to
understand images, compositionally generalizing to the task of
image-based poem writing even without having image-poem pairs in their
training data is possible.
In the first pretraining stage, MiniGPT-4 learns to understand images by
modeling the correlation between images and short image descriptions
from image caption datasets. However, the language style in these image
caption datasets differs from that of modern LLMs’ generation, which
leads to distorted language generation and hinders successful
compositional generalization. Therefore, we introduce a second-stage
finetuning to restore the language generation ability. MiniGPT-4 after
the two-stage training successfully generalizes to many advanced
compositional vision-language abilities like website coding from drafts
or meme interpretation, verifies our assumption. Future research might
delve deeper into the mechanism of compositional generalization and seek
ways to enhance them. We hope our work, as an early exploration of these
vision-based LLM capabilities, will spur further investigations in this
domain.
## More Qualitative Results
## Evaluation in traditional VQA benchmarks [appx: vqa]
The aim of this study is to replicate the remarkable multi-modal
capabilities demonstrated in GPT-4, such as generating detailed image
descriptions and creating websites from hand-drawn drafts. To emphasize
the most crucial component of advanced vision-language skills, the
methodology of MiniGPT-4 is intentionally kept minimal. For instance,
the learnable model capacity is limited (only one linear layer), and
MiniGPT-4 is trained with just 5 million pairs, in contrast to BLIP-2
with 129 million image-text pairs. Such a pared-down approach is
anticipated to yield suboptimal results on traditional benchmarks. While
this isn’t our primary goal, we offer a quantitative analysis of the VQA
datasets A-OKVQA (multi-choice) [schwenk2022okvqa](http://arxiv.org/pdf/2206.01718v1) and
GQA [hudson2019gqa](http://arxiv.org/pdf/2112.05136v1). Additionally, to showcase the
potential of MiniGPT-4 with traditional benchmarks, we conduct a
straightforward ablation study. Here, we simply unfreeze the LLM using
LoRA [hu2021lora](http://arxiv.org/pdf/2402.11485v1) and incorporate more training data
from the VQAv2, OKVQA, and A-OKVQA datasets during the second finetuning
stage. Results in Tab. [tab_supp] indicate that the original
MiniGPT-4 lags behind BLIP-2 by a reasonable margin, and merely
augmenting the learning capacity and the training data results in a
substantial performance improvement, which confirms our expectations. We
believe our model’s performance on conventional vision benchmarks can be
enhanced with a carefully designed training strategy (e.g., dataset
sample ratios, learning rate schedule, etc.), more training
data/datasets, and additional learnable parameters. Since enhancing
performance on traditional vision benchmarks isn’t this project’s
objective, we reserve this aspect for future research.
## Details of Caption Evaluation [appx: caption_eval]
We employ ChatGPT to determine whether the baseline models cover all the
objects and visual relations presented in the ground-truth captions. For
the COCO evaluation dataset, we randomly choose one ground-truth caption
and treat it as the reference caption. We apply the following prompt to
perform the evaluation.
*There is one image caption1 ‘{ground-truth caption}’, and there is
another image caption2 ‘{comparison caption}’. Does image caption2 cover
all the objects and visual relations shown in image caption1? Only
answer yes or no without any explanation.*
## More qualitative ablation results
Instruction tuning large language models (LLMs) using machine-generated instruction-following data has improved zero-shot capabilities on new tasks, but the idea is less explored in the multimodal field. In this paper, we present the first attempt to use language-only GPT-4 to generate multimodal language-image instruction-following data. By instruction tuning on such generated data, we introduce LLaVA: Large Language and Vision Assistant, an end-to-end trained large multimodal model that connects a vision encoder and LLM for general-purpose visual and language understanding.Our early experiments show that LLaVA demonstrates impressive multimodel chat abilities, sometimes exhibiting the behaviors of multimodal GPT-4 on unseen images/instructions, and yields a 85.1% relative score compared with GPT-4 on a synthetic multimodal instruction-following dataset. When fine-tuned on Science QA, the synergy of LLaVA and GPT-4 achieves a new state-of-the-art accuracy of 92.53%. We make GPT-4 generated visual instruction tuning data, our model and code base publicly available.
Show Paper Content
# Introduction
Humans interact with the world through many channels such as vision and
language, as each individual channel has a unique advantage in
representing and communicating certain concepts, and thus facilitates a
better understanding of the world. One of the core aspirations in
artificial intelligence is to develop a general-purpose assistant that
can effectively follow multi-modal vision-and-language instructions,
aligned with human intent to complete various real-world tasks in the
wild [askell2021general](http://arxiv.org/pdf/2112.00861v3), [li2022elevater](None), [li2023multimodal](http://arxiv.org/pdf/2309.10020v1).
To this end, the community has witnessed an emergent interest in
developing language-augmented foundation vision
models [li2022elevater](None), [gan2022vision](http://arxiv.org/pdf/2110.03902v1), with strong
capabilities in open-world visual understanding such as
classification [radford2021learning](http://arxiv.org/pdf/2404.19696v1), [openclip](https://doi.org/10.5281/zenodo.5143773), [yuan2021florence](http://arxiv.org/pdf/2301.05065v2), [yang2022unicl](http://arxiv.org/pdf/2107.11945v1), [pham2021combined](http://arxiv.org/pdf/1602.01255v2),
detection [li2022grounded](http://arxiv.org/pdf/2210.09263v1), [zhong2022regionclip](http://arxiv.org/pdf/1606.00540v1), [liu2023grounding](http://arxiv.org/pdf/2401.02361v2),
segmentation [li2022language](http://arxiv.org/pdf/2304.10326v1), [zou2022generalized](http://arxiv.org/pdf/2212.11270v1), [zhang2023simple](http://arxiv.org/pdf/1809.09299v1)
and captioning [wang2022git](http://arxiv.org/pdf/2204.07780v1), [li2023blip](http://arxiv.org/pdf/2301.12597v3), as well as
visual generation and
editing [DALLE2](http://arxiv.org/pdf/2204.06125v1), [LDM](http://arxiv.org/pdf/2307.10094v1), [PARTI](http://arxiv.org/pdf/2102.11495v1), [MAKEASCENE](http://arxiv.org/pdf/2211.01602v2), [Imagen](http://arxiv.org/pdf/2205.11487v1), [li2023gligen](http://arxiv.org/pdf/2311.09144v2).
We refer readers to the *Computer Vision in the Wild* reading list for a
more up-to-date literature compilation [cvinw](https://github.com/Computer-Vision-in-the-Wild/CVinW_Readings). In this
line of work, each task is solved independently by one single large
vision model, with the task instruction implicitly considered in the
model design. Further, language is only utilized to describe the image
content. While this allows language to play an important role in mapping
visual signals to language semantics—a common channel for human
communication, it leads to models that usually have a fixed interface
with limited interactivity and adaptability to the user’s instructions.
Large language models (LLM), on the other hand, have shown that language
can play a wider role: a universal interface for a general-purpose
assistant, where various task instructions can be explicitly represented
in language and guide the end-to-end trained neural assistant to switch
to the task of interest to solve it. For example, the recent success of
ChatGPT [chatgpt](https://openai.com/blog/chatgpt/) and GPT-4 [gpt4](https://arxiv.org/pdf/2303.08774) have
demonstrated the power of aligned LLMs in following human instructions,
and have stimulated tremendous interest in developing open-source LLMs.
Among them, LLaMA [touvron2023llama](http://arxiv.org/pdf/2402.08075v1) is an open-source
LLM that matches the performance of GPT-3.
Alpaca [alpaca](https://github.com/tatsu-lab/stanford_alpaca), Vicuna [vicuna](https://lmsys.org/blog/2023-03-30-vicuna/),
GPT-4-LLM [peng2023instruction](None) utilize various
machine-generated high-quality instruction-following samples to improve
the LLM’s alignment ability, reporting impressive performance compared
with proprietary LLMs. Importantly, this line of work is *text-only*.
In this paper, we present *visual instruction-tuning*, the first attempt
to extend instruction-tuning to the language-image multimodal space, to
pave the way towards building a general-purpose visual assistant. In
particular, our paper makes the following contributions:
- *Multimodal instruction-following data*. One key challenge is the
lack of vision-language instruction-following data. We present a
data reformation perspective and pipeline to convert image-text
pairs into an appropriate instruction-following format, using
ChatGPT/GPT-4.
- *Large multimodal models*. We develop a large multimodal model
(LMM), by connecting the open-set visual encoder of
CLIP [radford2021learning](http://arxiv.org/pdf/2404.19696v1) with the language decoder
Vicuna [vicuna](https://lmsys.org/blog/2023-03-30-vicuna/), and fine-tuning end-to-end on our
generated instructional vision-language data. Our empirical study
validates the effectiveness of using generated data for LMM
instruction-tuning, and suggests practical tips for building a
general-purpose instruction-following visual agent. When ensembled
with GPT-4, our approach achieves SoTA on the Science
QA [lu2022learn](http://arxiv.org/pdf/2209.09513v2) multimodal reasoning dataset.
- *Multimodal instruction-following benchmark*. We present LLaVA-Bench
with two challenging benchmarks, with a diverse selection of paired
images, instructions and detailed annotations.
- *Open-source*. We release the following assets to the public: the
generated multimodal instruction data, the codebase, the model
checkpoints, and a visual chat demo.
# Related Work
**Multimodal Instruction-following Agents.** In computer vision,
existing works that build instruction-following agents can be broadly
categorized into two classes: $(i)$ End-to-end trained models, which are
separately explored for each specific research topic. For example, the
vision-language navigation
task [anderson2018vision](http://arxiv.org/pdf/2402.11498v1), [hao2020towards](http://arxiv.org/pdf/2304.04907v1) and
Habitat [szot2021habitat](http://arxiv.org/pdf/2106.14405v2) require the embodied AI agent
to follow natural language instructions and take a sequence of actions
to complete goals in visual environments. In the image editing domain,
given an input image and a written instruction that tells the agent what
to do, InstructPix2Pix [brooks2022instructpix2pix](http://arxiv.org/pdf/2405.14785v1) edits
images by following the human instructions. $(ii)$ A system that
coordinates various models via LangChain [langchain](https://github.com/hwchase17/langchain) /
LLMs [chatgpt](https://openai.com/blog/chatgpt/), such as Visual
ChatGPT [wu2023visual](http://arxiv.org/pdf/2303.04671v1),
X-GPT [zou2022generalized](http://arxiv.org/pdf/2212.11270v1),
MM-REACT [yang2023mm](http://arxiv.org/pdf/2303.11381v1),
VisProg [gupta2022visual](http://arxiv.org/pdf/2203.15442v1), and
ViperGPT [suris2023vipergpt](http://arxiv.org/pdf/1905.11127v1). While sharing the same goal
in building instruction-following agents, we focus on developing an
end-to-end trained language-vision multimodal model for *multiple*
tasks.
**Instruction Tuning.** In the natural language processing (NLP)
community, to enable LLMs such as
GPT-3 [brown2020language](http://arxiv.org/pdf/2112.07522v2),
T5 [raffel2020exploring](http://arxiv.org/pdf/1910.10683v4),
PaLM [chowdhery2022palm](http://arxiv.org/pdf/2209.05735v4), and
OPT [zhang2022opt](None) to follow natural language
instructions and complete real-world tasks, researchers have explored
methods for LLM
instruction-tuning [ouyang2022training](http://arxiv.org/pdf/2302.05206v1), [wang2022benchmarking](http://arxiv.org/pdf/2212.12017v3), [wang2022self](http://arxiv.org/pdf/2311.00233v2),
leading to instruction-tuned counterparts such as
InstructGPT [ouyang2022training](http://arxiv.org/pdf/2302.05206v1)/ChatGPT [chatgpt](https://openai.com/blog/chatgpt/),
FLAN-T5 [chung2022scaling](http://arxiv.org/pdf/2202.03371v1),
FLAN-PaLM [chung2022scaling](http://arxiv.org/pdf/2202.03371v1), and
OPT-IML [iyer2022opt](http://arxiv.org/pdf/2210.11617v1), respectively. It turns out that
this simple approach can effectively improve the zero- and few-shot
generalization abilities of LLMs. It is thus natural to borrow the idea
from NLP to computer vision. More broadly, the teacher-student
distillation ideas with foundation models have been studied in other
topics such as image
classification [faghri2023reinforce](http://arxiv.org/pdf/2303.08983v3).
Flamingo [alayrac2022flamingo](http://arxiv.org/pdf/2205.07065v1) can be viewed as the GPT-3
moment in the multimodal domain, due to its strong performance on
zero-shot task transfer and in-context-learning. Other LMMs trained on
image-text pairs include BLIP-2 [li2023blip](http://arxiv.org/pdf/2301.12597v3),
FROMAGe [koh2023grounding](http://arxiv.org/pdf/2401.13388v2), and
KOSMOS-1 [huang2023language](http://arxiv.org/pdf/2302.14045v2).
PaLM-E [driess2023palm](None) is an LMM for embodied AI. Based
on the recent “best” open-source LLM LLaMA,
OpenFlamingo [anas_awadalla_2023_7733589](https://doi.org/10.5281/zenodo.7733589) and
LLaMA-Adapter [zhang2023llama](http://arxiv.org/pdf/2207.10858v1) are open-source efforts
that enable LLaMA to use image inputs, paving the way to build
open-source multimodal LLMs. While these models present promising task
transfer generalization performance, they are not explicitly tuned with
vision-language instruction data, and their performance in multimodal
tasks usually falls short compared to language-only tasks. In this
paper, we aim to fill this gap and study its effectiveness. Finally,
note that visual instruction tuning is different from visual prompt
tuning [jia2022visual](http://arxiv.org/pdf/2309.01155v2): the former aims to improve the
model’s instruction-following abilities, while the latter aims to
improve the parameter-efficiency in model adaptation.
# GPT-assisted Visual Instruction Data Generation [sec:visual_instruc_data]
The community has witnessed a surge in the amount of public multimodal
data such as image-text pairs, ranging from
CC [changpinyo2021conceptual](http://arxiv.org/pdf/2102.08981v2) to
LAION [schuhmann2022laion](http://arxiv.org/pdf/2312.15897v1). However, when it comes to
multimodal instruction-following data, the available amount is limited,
partially because the process for creating such data is time-consuming
and less well-defined when human crowd-scouring is considered. Inspired
by the success of recent GPT models in text-annotation
tasks [gilardi2023chatgpt](http://arxiv.org/pdf/2303.15056v2), we propose to leverage
ChatGPT/GPT-4 for multimodal instruction-following data collection,
based on the widely existing image-pair data.
For an image $\Xmat_{\texttt{v}}$ and its associated caption
$\Xmat_{\texttt{c}}$, it is natural to create a set of questions
$\Xmat_{\texttt{q}}$ with the intent to instruct the assistant to
describe the image content. We prompt GPT-4 to curate such a list of
questions (see details in Appendix). Therefore, a simple way to expand
an image-text pair to its instruction-following version is
$\texttt{Human}: \Xmat_{\texttt{q}} ~\Xmat_{\texttt{v}} \texttt{}~
\texttt{Assistant}:
\Xmat_{\texttt{c} }
\texttt{}$. Though cheap to construct, this simple expanded
version lacks diversity and in-depth reasoning in both the instructions
and responses.
| | |
|:---|:--:|
| | |
| A group of people standing outside of a black vehicle with various luggage. | |
| Luggage surrounds a vehicle in an underground parking area | |
| People try to fit all of their luggage in an SUV. | |
| The sport utility vehicle is parked in the public garage, being packed for a trip | |
| Some people with luggage near a van that is transporting it. | |
| | |
| person: \[0.681, 0.242, 0.774, 0.694\], backpack: \[0.384, 0.696, 0.485, 0.914\], suitcase: ...\ | |
| | |
| | |
| Question: What type of vehicle is featured in the image? | |
| Answer: The image features a black sport utility vehicle (SUV) ...\ | |
| | |
| The image is an underground parking area with a black sport utility vehicle (SUV) parked. There are three people in the scene, with one person standing closer to the left side of the vehicle, another person in the middle, and the third person on the right side. They are all working together to pack their luggage into the SUV for a trip. ...\ | |
| | |
| Question: What challenges do these people face? | |
| Answer: In the image, a group of people is standing outside a black SUV in a parking area, surrounded by various pieces of luggage, including suitcases and backpacks. They are facing the challenge of fitting all their luggage into the black SUV. There are multiple suitcases and backpacks to be packed, which suggests that the group has a significant amount of belongings ...\ | |
To mitigate this issue, we leverage language-only GPT-4 or ChatGPT as
the strong teacher (both accept only text as input), to create
instruction-following data involving visual content. Specifically, in
order to encode an image into its visual features to prompt a text-only
GPT, we use two types of symbolic representations: $(i)$ *Captions*
typically describe the visual scene from various perspectives; $(ii)$
*Bounding boxes* usually localize the objects in the scene, and each box
encodes the object concept and its spatial location. One example is
shown in the top block of
Table [tab:full_example_car_bbox].
This symbolic representation allows us to encode the image as an
LLM-recognizable sequence. We use COCO
images [lin2014microsoft](None) and generate three types of
instruction-following data. One example per type is shown in the bottom
block of
Table [tab:full_example_car_bbox].
For each type, we first manually design a few examples. They are the
only human annotations we have during data collection, and are used as
seed examples in in-context-learning to query GPT-4.
- *Conversation*. We design a conversation between the assistant and a
person asking questions about this photo. The answers are in a tone
as if the assistant is seeing the image and answering the question.
A diverse set of questions are asked about the visual content of the
image, including the object types, counting the objects, object
actions, object locations, relative positions between objects. Only
questions that have definite answers are considered. Please see
Appendix for the detailed prompt.
- *Detailed description*. To include a rich and comprehensive
description for an image, we create a list of questions with such an
intent. We prompt GPT-4 then curate the list (see detailed prompts
and curation process in Appendix). For each image, we randomly
sample one question from the list to ask GPT-4 to generate the
detailed description.
- *Complex reasoning*. The above two types focus on the visual content
itself, based on which we further create in-depth reasoning
questions. The answers typically require a step-by-step reasoning
process by following rigorous logic.
We collect 158K unique language-image instruction-following samples in
total, including 58K in conversations, 23K in detailed description, and
77k in complex reasoning, respectively. We ablated the use of ChatGPT
and GPT-4 in our early experiments, and found that GPT-4 consistently
provides higher quality instruction-following data, such as spatial
reasoning.
# Visual Instruction Tuning
## Architecture
The primary goal is to effectively leverage the capabilities of both the
pre-trained LLM and visual model. The network archtecture is illustrated
in Figure 1. We choose
Vicuna [vicuna](https://lmsys.org/blog/2023-03-30-vicuna/) as our LLM $f_{\phiv}(\cdot)$
parameterized by $\phiv$, as it has the best instruction following
capabilities in language tasks among publicly available
checkpoints [alpaca](https://github.com/tatsu-lab/stanford_alpaca), [vicuna](https://lmsys.org/blog/2023-03-30-vicuna/), [peng2023instruction](None).
For an input image $\Xmat_{\texttt{v}}$, we consider the pre-trained
CLIP visual encoder ViT-L/14 [radford2021learning](http://arxiv.org/pdf/2404.19696v1), which
provides the visual feature
$\Zmat_{\texttt{v}} = g(\Xmat_{\texttt{v}})$. The grid features before
and after the last Transformer layer are considered in our experiments.
We consider a simple linear layer to connect image features into the
word embedding space. Specifically, we apply a trainable projection
matrix $\Wmat$ to convert $\Zmat_{\texttt{v}}$ into language embedding
tokens $\Hmat_{\texttt{v}}$, which have the same dimensionality as the
word embedding space in the language model:
$$\Hmat_{\texttt{v}} = \Wmat \cdot \Zmat_{\texttt{v}},~ \text{with}~~
\Zmat_{\texttt{v}} = g(\Xmat_{\texttt{v}})
\label{eq:image_encoding}$$ Thus, we have a sequence of visual
tokens $\Hmat_{\texttt{v}}$. Note that our simple projection scheme is
lightweight, which allows us to iterate data centric experiments
quickly. More sophisticated schemes to connect the image and language
representations can also be considered, such as gated cross-attention in
Flamingo [alayrac2022flamingo](http://arxiv.org/pdf/2205.07065v1) and Q-former in
BLIP-2 [li2023blip](http://arxiv.org/pdf/2301.12597v3). We leave exploring possibly more
effective and sophisticated architecture designs for as future work.
## Training
For each image $\Xmat_{\texttt{v}}$, we generate multi-turn conversation
data
$(\Xmat_{\texttt{q}}^1, \Xmat_{\texttt{a}}^1, \cdots, \Xmat_{\texttt{q}}^T, \Xmat_{\texttt{a}}^T )$,
where $T$ is the total number of turns. We organize them as a sequence,
by treating all answers as the assistant’s response, and the instruction
$\Xmat_{\texttt{instruct}}^t$ at the $t$-th turn as: $$\begin{aligned}
\label{eq:organize_data_turn_rule}
\Xmat_{\texttt{instruct}}^t =
\left\{\begin{matrix}
& \text{Randomly choose}~~
[\Xmat_{\texttt{q}}^1, \Xmat_{\texttt{v}}] ~~\text{or}~~ [ \Xmat_{\texttt{v}}, \Xmat_{\texttt{q}}^1] , ~~~\text{the first turn}~t=1 \\
& \Xmat_{\texttt{q}}^t, \hspace{45mm} \text{the remaining turns}~t>1
\end{matrix}\right.
\end{aligned}$$
This leads to the unified format for the multimodal
instruction-following sequence illustrated in
Table [tab:input_sequence]. We perform
instruction-tuning of the LLM on the prediction tokens, using its
original auto-regressive training objective.
Specifically, for a sequence of length $L$, we compute the probability
of the target answers $\Xmat_{\texttt{a}}$ by:
$$p( \Xmat_{\texttt{a}} | \Xmat_{\texttt{v}}, \Xmat_{\texttt{instruct}}) =
\prod_{i=1}^{L} p_{\thetav} ( {\color{mygreen} \xv_i}
| \Xmat_{\texttt{v}}, \Xmat_{\texttt{instruct}, [tab:input_sequence] for an
illustration of the prediction tokens. For the conditionals
in [eq:auto_regressive], we
explicitly add $\Xmat_{\texttt{v}}$ to emphasize the fact that the image
is grounded for all answers, and we omit
$\Xmat_{\texttt{system-message}}$ and all previous `` for better
readability. For model training, we consider a two-stage
instruction-tuning procedure.
#### Stage 1: Pre-training for Feature Alignment.
To strike a balance between concept coverage and training efficiency, we
filter CC3M to 595K image-text pairs. Please see Appendix for details of
the filtering process. These pairs are converted to the
instruction-following data using the naive expansion method describe in
Section 1. Each sample can be
treated as a single-turn conversation. To construct the input
$\Xmat_{\texttt{instruct}}$ in
[eq:organize_data_turn_rule],
for an image $\Xmat_{\texttt{v}}$, a question $\Xmat_{\texttt{q}}$ is
randomly sampled, which is a language instruction to request the
assistant to describe the image briefly. The ground-truth prediction
answer $\Xmat_{\texttt{a}}$ is the original caption. In training, we
keep both the visual encoder and LLM weights frozen, and maximize the
likelihood of [eq:auto_regressive] with
trainable parameters $\thetav = \Wmat$ (the projection matrix) only. In
this way, the image features $\Hmat_{\texttt{v}}$ can be aligned with
the pre-trained LLM word embedding. This stage can be understood as
training a compatible visual tokenizer for the frozen LLM.
#### Stage 2: Fine-tuning End-to-End.
We always keep the visual encoder weights frozen, and continue to update
both the pre-trained weights of the projection layer and LLM in ; i.e.,
the trainable parameters are $\thetav = \{\Wmat, \phiv \}$
in [eq:auto_regressive]. We
consider two specific use case scenarios:
- *Multimodal Chatbot*. We develop a Chatbot by fine-tuning on the
158K language-image instruction-following data in
Section 1. Among the three
types of responses, conversation is multi-turn while the other two
are single-turn. They are uniformly sampled in training.
- *Science QA*. We study our method on the ScienceQA
benchmark [lu2022learn](http://arxiv.org/pdf/2209.09513v2), the first large-scale
multimodal science question dataset that annotates the answers with
detailed lectures and explanations. Each question is provided a
context in the form of natural language or an image. The assistant
provides the reasoning process in natural language and selects the
answer among multiple choices. For training in
[eq:organize_data_turn_rule],
we organize the data as a single turn conversation, the question &
context as $\Xmat_{\texttt{instruct}}$, and reasoning & answer as
$\Xmat_{\texttt{a}}$.
# Experiments
We assess the performance of in instruction-following and visual
reasoning capabilities with two primary experimental settings:
multimodal chatbot and the ScienceQA dataset, respectively. We train all
models with 8$\times$ A100s, following Vicuna’s
hyperparameters [vicuna](https://lmsys.org/blog/2023-03-30-vicuna/). We pre-train our model on the
filtered CC-595K subset for 1 epoch with a learning rate of 2e-3 and a
batch size of 128, and fine-tune on the proposed LLaVA-Instruct-158K
dataset for 3 epochs, with a learning rate of 2e-5 and a batch size of
32. See Appendix for more training details.
## Multimodal Chatbot
We developed a chatbot demo to show the image understanding and
conversation abilities of , and to study how well is able to digest
visual inputs and exhibit instruction-following capabilities. We first
use the examples in the original GPT-4 paper [gpt4](https://arxiv.org/pdf/2303.08774),
shown in
Table [tab:visual_example_ironing]
(more examples in Appendix), that require in-depth image understanding.
For comparisons, we quote the prompt and response of the multimodal
GPT-4 from their paper, and query BLIP-2 and OpenFlamingo model
checkpoints to get their response.
Surprisingly, although is trained with a small multimodal
instruction-following dataset ($\sim$``{=html}80K unique
images), it demonstrates quite similar reasoning results with multimodal
GPT-4 on these examples. Note that while these images are out-of-domain
for , is still able to understand the scenes and follow the question
instruction to provide a reasonable response. In contrast, BLIP-2 and
OpenFlamingo focus on describing the image, instead of following the
user instruction to answer in an appropriate manner.
#### Quantitative Evaluation.
To gain a systematic understanding of the performance of , we propose a
quantitative metric to measure the model’s instruction-following
capability on multimodal data. Inspired by [vicuna](https://lmsys.org/blog/2023-03-30-vicuna/), we
leverage GPT-4 to measure the quality of generated responses.
Specifically, we create triplets consisting of image, ground-truth
textual descriptions, and question. The candidate models () predict the
answers based on the question and the image. To provide an *approximate
theoretical upper bound*, we create a reference prediction based on the
question and the *ground-truth* textual descriptions, using the
text-only GPT-4. After obtaining the responses from both models, we feed
the question, visual information (in the format of textual
descriptions), and the generated responses from both assistants, to the
judge (text-only GPT-4). It evaluates the helpfulness, relevance,
accuracy, and level of detail of the responses from the assistants, and
gives an overall score on a scale of 1 to 10, where a higher score
indicates better overall performance. It is also asked to provide a
comprehensive explanation for the evaluation, for us to better
understand the models. We report relative scores *w.r.t.* the text-only
GPT-4 model that uses the textural ground truth description as visual
input. We create two benchmarks to evaluate the model’s performance.
#### .
We randomly select 30 images from COCO-Val-2014, and for each image, we
generate three types of questions (conversation, detailed description,
complex reasoning) using the proposed data generation pipeline in
Sec. [sec:visual_instruc_data],
totaling 90 questions. This benchmark studies the model’s alignment
behavior and capabilities with consistent visual inputs. We vary the
training datasets to study the effectiveness of different types of
instruction-following data, and show the results in
Table [tab:results]. First, with instruction
tuning, the model’s ability of following user instructions improves
significantly by over 50 points. Second, adding a small amount of
detailed description and complex reasoning questions contributes to a
considerable improvement of the model’s overall capability by 7 points.
Furthermore, it also improves the model’s performance on conversational
questions, suggesting that improvements in reasoning capabilities
complement conversational abilities. Finally, we show that having all
three types of data yields the best performance at 85.1%.
#### .
To evaluate the model’s capability in more challenging tasks and
generalizability to novel domains, we collect a diverse set of 24 images
with 60 questions in total, including indoor and outdoor scenes, memes,
paintings, sketches, , and associate each image with a highly-detailed
and manually-curated description and a proper selection of questions. We
compare , BLIP, and OpenFlamingo in
Table [tab:results_wild]. Thanks to
visual instruction tuning, achieves significantly better performance
compared with BLIP-2 (+29%) and OpenFlamingo (+48%). Compared to the
text-only GPT-4 that has access to ground-truth labels, achieves an
impressive 81.7% performance on complex reasoning questions, with an
overall score of 67.3%.
#### Limitations.
This is designed to be challenging and to reveal a model’s weaknesses.
We provide two examples with associated captions and questions in
Table [tab:example_bench]. For the
ramen example (left), to correctly answer the name of the restaurant, it
requires the model to have a large knowledge coverage and multilingual
understanding capability; to correctly describe the side dishes, the
model may need to retrieve relevant multimodal information from
Internet. For the fridge example (right), perceiving the correct brand
of the yogurt requires the model to process high resolution images and
possess extensive knowledge coverage. We also observed an interesting
failure of , as it responds with *yes* when asked if strawberry-flavored
yogurt is present, even though the fridge contains only yogurt *and*
strawberries. This indicates that, at times, perceives the image as a
“bag of patches”, failing to grasp the complex semantics within the
image. We hope serves as a solid baseline on the benchmarks, on which
our findings can inspire future work in developing more capable LMMs.
## ScienceQA
ScienceQA [lu2022learn](http://arxiv.org/pdf/2209.09513v2) contains 21k multimodal multiple
choice questions with rich domain diversity across 3 subjects, 26
topics, 127 categories, and 379 skills. The benchmark dataset is split
into training, validation, and test splits with 12726, 4241, and 4241
examples, respectively. We consider two representative methods,
including GPT-3.5 model () with and without chain-of-thought (CoT),
LLaMA-Adapter [zhang2023llama](http://arxiv.org/pdf/2207.10858v1), as well as multimodal
chain-of-thought (MM-CoT) [zhang2023multimodal](http://arxiv.org/pdf/2401.06805v2), which is
the current SoTA method on this dataset. For more baseline numbers,
please see [lu2022learn](http://arxiv.org/pdf/2209.09513v2).
The results are reported in
Table [tab:scienceqa_model_performance].
For , we use the visual features before the last layer, ask the model to
first predict reasons and then the answer, and train it for 12 epochs.
It yields 90.92% accuracy, which is quite close to the SoTA 91.68%. To
explore the limit of LLMs, we also prompt GPT-4 using 2-shot
in-context-learning and achieve 82.69% accuracy, which is a 7.52%
absolute gain compared with 75.17% from GPT-3.5. For a substantial
number of questions, we note that GPT-4 fails simply because it reports
that there is insufficient context such as images or plots. We consider
two schemes to combine the outcomes from our model and GPT-4. $(i)$ *A
GPT-4 complement*. Whenever GPT-4 fails to provide answers, we use the
prediction from our method. This schemes yields 90.97% accuracy, which
is almost the same as applying our method alone. $(ii)$ *GPT-4 as the
judge*. Whenever GPT-4 and produce different answers, we prompt GPT-4
again, asking it to provide its own final answer based on the question
and two outcomes. The spirit is similar with CoT, but with the external
knowledge from the other model. Surprisingly, this scheme is able to
provide consistent improvement over all question classes, and achieves a
new SoTA accuracy of 92.53%. Interestingly, the text-only GPT-4, which
cannot process images, improves the overall performance of the model on
questions that have an image as context. This is because some of these
questions do not actually require the image context for a correct
answer. The GPT-4 judge can identify such cases and correct some of the
errors that makes. See the example in Appendix. To the best of our
knowledge, this is the first time that GPT-4 is used for model
ensembling. We hope this finding can encourage future research to
explore more effective methods to leverage LLMs for model ensembling.
r0.5
#### Ablations.
We ablate several design choices on ScienceQA in
Table [tab:scienceqa_ablation].
$(i)$ *Visual features*. We tried using the last layer feature from CLIP
vision encoder, which yields 89.96% and is 0.96% lower than the feature
before the last layer. We hypothesize that this is because CLIP’s last
layer features may focus more on global and abstract image properties
compared to the layer before it, which can focus more on localized
properties that are useful for understanding specific image details.
$(ii)$ *Chain-of-thought*. To decide the order between the answer and
reasoning process in the model prediction, we run both variants and
observe that answer-first reports the best number 89.77% accuracy in 12
epochs, while reasoning-first can quickly reach 89.77% accuracy in 6
epochs, but no further improvement with more training. Training the
model for 24 epochs does not improve the performance. We conclude that
CoT-like reasoning-first strategy can largely improve convergence, but
contributes relatively little to the final performance. $(iii)$
*Pre-training*. We skip pre-training and directly train on Science QA
from scratch – performance drops to 85.81% accuracy. The 5.11% absolute
degradation indicates the importance of our pre-training stage, in
aligning multimodal features while preserving the vast pre-trained
knowledge. $(iv)$ *Model size*. We keep all configurations the same as
our best 13B model, and train a 7B model. This yields 89.84% accuracy,
which is 1.08% lower than 90.92%, demonstrating the importance of model
scale.
# Conclusion
This paper demonstrated the effectiveness of visual instruction tuning.
We presented an automatic pipeline to create language-image
instruction-following data, based on which we train , a multimodal model
to follow human intent to complete visual tasks. It achieves the new
SoTA accuracy when fine-tuned on ScienceQA, and excellent visual chat
capabilities when fine-tuned on multimodal chat data. Besides, we
present the first benchmark to study multimodal instruction-following
capability. This paper is an initial step in visual instruction tuning,
and mainly focuses on real-life tasks. For more quantitative results of
on academic benchmarks, please refer to the improved baselines with
visual instruction tuning [liu2023improvedllava](http://arxiv.org/pdf/2310.19145v1). We hope
our work can inspire future research on building more capable multimodal
models.
**Acknowledgements.** We thank Baolin Peng and Pan Lu for valuable
discussions on instruction-tuning language models and Science QA,
respectively. We thank the LLaMA team for giving us access to their
models, and open-source projects, including Alpaca and Vicuna. This work
was supported in part by NSF CAREER IIS2150012, and Institute of
Information & communications Technology Planning & Evaluation(IITP)
grants funded by the Korea government(MSIT) (No. 2022-0-00871,
Development of AI Autonomy and Knowledge Enhancement for AI Agent
Collaboration) and (No. RS-2022-00187238, Development of Large Korean
Language Model Technology for Efficient Pre-training).
# Broader Impact
The broader impact of , a general-purpose visual assistant, has
potential benefits and risks associated with its deployment and release.
Some considerations are unique to due to its visual nature, while others
share similarities with existing instruction-following LLMs (Alpaca,
Vicuna, ). As is built upon LLaMA, Vicuna, and CLIP, it inherits some of
the issues associated with LLMs and vision encoders. In the following,
we outline both the risks and mitigation strategies in place for the
release of this model.
#### Malicious input.
To minimize potential misuse and harmful consequences, we employ two
precautionary measures for : (1) *OpenAI Filter API* for user input text
to prevent harmful or inappropriate text instructions from being
processed by the model, and (2) *NSFW Filter* for uploaded user images
to detect and block Not Safe For Work (NSFW) content or any other
potentially harmful image inputs.
#### Hallucination.
Similar to LLMs, might generate outputs that aren’t grounded in facts or
input data. This raises concerns about inferences made, especially in
critical applications (medical).
#### Biases.
Bias can be transferred from the base models to , both from the vision
encoder (CLIP) and the language decoder (LLaMA/Vicuna). This may lead to
biased outcomes or unfair representations of diverse content.
#### Energy consumption.
Though energy consumption is not a primary concern for due to a smaller
pretraining dataset (see details in
Sec. 3), it may become a
concern when scaling up the pretraining dataset or increasing the model
size, e.g., to a larger LLaMA version like the 65B model.
#### Evaluation complexities.
Assessing the performance of is challenging as it involves both language
and visual tasks. Our evaluation benchmark covers several aspects,
including accuracy, concept coverage, reasoning ability, and creativity.
However, additional aspects need consideration, such as the degree of
visual content hallucination and fine-grained understanding of visual
content. While text-only GPT-4 based multimodal evaluation is consistent
and accurate in our study, its robustness in different situations and
capability to evaluate other unexplored aspects are subjects for future
work.
Despite these risks, we believe that the benefits of releasing to the
research community outweigh the potential harm. It allows for ongoing
investigation and improvement of the model and engages the community in
developing better mitigation strategies to address these concerns.
Moreover, the release of can spur the development of new applications
and research directions, ultimately contributing to the progress and
responsible deployment of foundation models in vision-language tasks.
# More Results
We present more qualitative results of to analyze its emergent behaviors
and observed weaknesses. For more quantitative results of on academic
benchmarks, please refer to the improved baselines with visual
instruction tuning [liu2023improvedllava](http://arxiv.org/pdf/2310.19145v1). In
Table [tab:visual_example_chichken],
demonstrates a similar behavior as GPT-4 in another example from its
paper. Similar to the GPT-4 live demo by OpenAI, is capable of
generating the HTML/JS/CSS code for an interactive joke website based on
a simplified user input sketch in
Fig. 1, despite a minor error. As
shown in Fig. 2, can follow user’s
instructions in a conversational style and provide detailed responses or
creative writings. Furthermore, is able to relate the visual content to
the textual knowledge from the pretrained LLM, as demonstrated in
Fig. 3 and
Fig. 4.
One interesting emergent behavior of is that it is able to understand
visual contents that are not covered in the training. For example, in
Fig. 5, it is able to recognize
Elon Musk both in a headshot and in a humorous meme where he is dressed
as a doge, even though Elon Musk *never* appears in the training data
for either the visual feature alignment or visual instruction tuning
stages of . also demonstrates impressive OCR (optical character
recognition) ability in
Table [tab:visual_example_chichken]
and Fig. 1, which is rarely covered in
our training data.
We hope these additional results and observations showcase the potential
of in various application areas. In future work, it is important to
investigate these emergent behaviors more thoroughly and to understand
the underlying mechanisms that enable to demonstrate such generalization
abilities. This will pave the way towards building better LMMs,
including enhancing robustness, reducing biases, and improving the
alignment and the scope of the learned vision-language representations.
is capable of recognizing the visual content following the
user’s intent, without directly prompting for visual recognition. It
also provides a detailed response when prompted with a follow-up
request, and the generated response is closely related to the provided
visual content.
| | |
|:---|:--:|
| | |
| Which material is this rocking chair made of? | |
| Options: (A) wood (B) silk | |
| | |
| LECTURE: A material is a type of matter. | |
| Wood, glass, metal, and plastic are common materials. | |
| Some objects are made of just one material. | |
| Most nails are made of metal. | |
| Other objects are made of more than one material. | |
| This hammer is made of metal and wood. | |
| SOLUTION: Look at the picture of the rocking chair. The rocking chair is made of two different materials. The legs are made of wood, and the back and seat are made of silk. | |
| The answer is B. | |
| | |
| The answer is A. BECAUSE: Rocking chairs are typically made of sturdy materials that can support the weight of a person and withstand the rocking motion. Wood is a common material used for making rocking chairs due to its strength, durability, and natural appearance. | |
| | |
| | |
| Since there is no context or image to refer to, I cannot independently analyze the rocking chair in question. However, I can try to analyze the reasoning given by the assistants. | |
| Assistant 1, who claims to have seen the image, mentions that the legs of the rocking chair are made of wood, and the back and seat are made of silk, implying that it’s a combination of two materials. However, this response seems less plausible, as silk is not a common material used for the construction of rocking chairs due to issues with stability and durability. Typically, one would expect the frame, legs, and seat or back to be made of wood, with cushions and padding made of fabrics, such as cotton or polyester. | |
| Assistant 2 argues that rocking chairs are typically made of sturdy materials, and wood is a common material used for making rocking chairs due to its strength, durability, and natural appearance. This reasoning stands true and is based on common knowledge. | |
| Given the information available, the most plausible answer is that the rocking chair is made of wood, as suggested by Assistant 1. The answer is A. | |
# Training Details [sec:appendix_training_details]
We pre-train our model on the filtered CC-595K subset for 1 epoch with a
learning rate of 2e-3 and a batch size of 128, and fine-tune on the
proposed LLaVA-Instruct-158K dataset for 3 epochs, with a learning rate
of 2e-5 and a batch size of 32. Following Vicuna, we use the Adam
optimizer with no weight decay and a cosine learning rate with a warmup
ratio of 3%. During finetuning, FSDP (Full Shard Data Parallel) and
gradient checkpointing is used to save GPU memory, and offloading is not
used. BF16 and TF32 are enabled to achieve a balance between speed and
precision.
We train all models with 8$\times$ A100s. Pretraining on CC-595K
completes within 4 hours. Finetuning on Instruct-158K completes within
10 hours. Finetuning on ScienceQA completes within 4 hours.
# Assets
Our source code, generated instruction-tuning data, proposed benchmark
are uploaded to the anonymized GitHub repository:
[LLaVA-Annonymous/LLaVA](https://github.com/LLaVA-Annonymous/LLaVA).
1. Source Code: [link](https://github.com/LLaVA-Annonymous/LLaVA)
2. README: [link](https://github.com/LLaVA-Annonymous/LLaVA)
3. Instructions to launch the demo:
[link](https://github.com/LLaVA-Annonymous/LLaVA#web-ui)
4. All prompts and few shot examples for querying GPT-4:
[link](https://github.com/LLaVA-Annonymous/LLaVA/tree/master/playground/data/prompts)
5. LLaVA-Instruct-158K:
[link](https://github.com/LLaVA-Annonymous/LLaVA/blob/master/playground/data/llava_instruct_150k.json)
6. LLaVA-Bench:
[COCO](https://github.com/LLaVA-Annonymous/LLaVA/blob/master/playground/data/coco2014_val_gpt4_qa_30x3.jsonl),
[In-The-Wild](https://github.com/LLaVA-Annonymous/LLaVA/tree/master/playground/data/llava_bench_in_the_wild)
7. Model checkpoints. The size of the model checkpoints after
compression is 25GB, which exceeds the 5GB limit of GitHub LFS
(Large File Storage). We’ll release the checkpoint to the public, or
upon request with reviewers for this submission.
# Data [sec:appendix_data]
#### Instructions for brief image description.
The list of instructions used to briefly describe the image content are
shown in
Table [tab:concise_describe_instructions].
They present the same meaning with natural language variance.
- "Describe the image concisely."
- "Provide a brief description of the given image."
- "Offer a succinct explanation of the picture presented."
- "Summarize the visual content of the image."
- "Give a short and clear explanation of the subsequent image."
- "Share a concise interpretation of the image provided."
- "Present a compact description of the photo’s key features."
- "Relay a brief, clear account of the picture shown."
- "Render a clear and concise summary of the photo."
- "Write a terse but informative summary of the picture."
- "Create a compact narrative representing the image presented."
#### Instructions for detailed image description.
The list of instructions used to describe the image content in detail
are shown in
Table [tab:detailed_describe_instructions].
They present the same meaning with natural language variance.
- "Describe the following image in detail"
- "Provide a detailed description of the given image"
- "Give an elaborate explanation of the image you see"
- "Share a comprehensive rundown of the presented image"
- "Offer a thorough analysis of the image"
- "Explain the various aspects of the image before you"
- "Clarify the contents of the displayed image with great detail"
- "Characterize the image using a well-detailed description"
- "Break down the elements of the image in a detailed manner"
- "Walk through the important details of the image"
- "Portray the image with a rich, descriptive narrative"
- "Narrate the contents of the image with precision"
- "Analyze the image in a comprehensive and detailed manner"
- "Illustrate the image through a descriptive explanation"
- "Examine the image closely and share its details"
- "Write an exhaustive depiction of the given image"
#### CC3M.
We extract noun-phrases using Spacy for each caption over the whole CC3M
dataset, and count the frequency of each unique noun-phrase. We skip
noun-phrases whose frequency is smaller than $3$, as they are usually
rare combinations concept and attributes that has already been covered
by other captions. We then start from the noun-phrases with lowest
remaining frequency, add the captions that contain this noun-phrase to
the candidate pool. If the frequency of the noun-phrase is larger than
$100$, we randomly choose a subset of size $100$ out of all its
captions. This results in around 595K image-text pairs.
The comparison of noun-phrase statistics before and after filtering CC3M
is shown in
Figure [fig:cmp_noun_phrase_counter].
The filtered dataset shows a good coverage of concepts whose frequency
is higher from 3, but with a smaller number of image-text pairs.
# Prompts
The prompt used to generate image-based conversation from ChatGPT/GPT-4
is shown in
Table [tab:prompt_conversation].
| |
|:---|
| |
| Design a conversation between you and a person asking about this photo. The answers should be in a tone that a visual AI assistant is seeing the image and answering the question. Ask diverse questions and give corresponding answers. |
| Include questions asking about the visual content of the image, including the **object types, counting the objects, object actions, object locations, relative positions between objects**, etc. Only include questions that have definite answers: |
| \(1\) one can see the content in the image that the question asks about and can answer confidently; |
| \(2\) one can determine confidently from the image that it is not in the image. Do not ask any question that cannot be answered confidently. |
| Also include complex questions that are relevant to the content in the image, for example, asking about background knowledge of the objects in the image, asking to discuss about events happening in the image, etc. Again, do not ask about uncertain details. Provide detailed answers when answering complex questions. For example, give detailed examples or reasoning steps to make the content more convincing and well-organized. You can include multiple paragraphs if necessary."""} |
| \] |
| |
| | |
|:---|:--:|
| | |
| A group of people standing outside of a black vehicle with various luggage. | |
| Luggage surrounds a vehicle in an underground parking area | |
| People try to fit all of their luggage in an SUV. | |
| The sport utility vehicle is parked in the public garage, being packed for a trip | |
| Some people with luggage near a van that is transporting it. | |
| | |
| person: \[0.681, 0.242, 0.774, 0.694\], person: \[0.63, 0.222, 0.686, 0.516\], person: \[0.444, 0.233, 0.487, 0.34\], backpack: \[0.384, 0.696, 0.485, 0.914\], backpack: \[0.755, 0.413, 0.846, 0.692\], suitcase: \[0.758, 0.413, 0.845, 0.69\], suitcase: \[0.1, 0.497, 0.173, 0.579\], bicycle: \[0.282, 0.363, 0.327, 0.442\], car: \[0.786, 0.25, 0.848, 0.322\], car: \[0.783, 0.27, 0.827, 0.335\], car: \[0.86, 0.254, 0.891, 0.3\], car: \[0.261, 0.101, 0.787, 0.626\] | |
| | |
| | |
| Question: What type of vehicle is featured in the image? | |
| Answer: The image features a black sport utility vehicle (SUV). | |
| Question: Where is the vehicle parked? | |
| Answer: The vehicle is parked in an underground parking area, likely in a public garage. | |
| Question: What are the people in the image doing? | |
| Answer: The people are trying to fit all of their luggage into the SUV, likely preparing for a trip. | |
| | |
| The image is an underground parking area with a black sport utility vehicle (SUV) parked. There are three people in the scene, with one person standing closer to the left side of the vehicle, another person in the middle, and the third person on the right side. They are all working together to pack their luggage into the SUV for a trip. | |
| In the parking area, various luggage items are scattered around the vehicle. There are two backpacks, one located near the left rear wheel and the other closer to the right side of the vehicle. Additionally, there are two suitcases, one on the right side of the car and another further away near the center of the parking area. A bicycle can also be seen on the left side of the vehicle. | |
| Other cars are parked around the main SUV, with one car positioned behind it and slightly to the left, another behind and slightly to the right, and the third car further behind on the right side. | |
| | |
| Question: What challenges do these people face? | |
| Answer: In the image, a group of people is standing outside a black SUV in a parking area, surrounded by various pieces of luggage, including suitcases and backpacks. They are facing the challenge of fitting all their luggage into the black SUV. There are multiple suitcases and backpacks to be packed, which suggests that the group has a significant amount of belongings to accommodate. They might have to strategize and arrange the luggage efficiently to ensure that everything fits properly into the vehicle. Additionally, they need to consider the comfort of the passengers and visibility while driving, so the placement of the luggage must not obstruct the driver’s view or make the passengers uncomfortable during the trip. | |
| |
|:---|
| |
| There is a movie theater that displays the show times above the doors. |
| A red fire hydrant is deep in the snow. |
| The fire hydrant is in the snow near a recently plowed sidewalk. |
| This city has had a very hard winter with snow. |
| A hotel for dogs in the snow in winter. |
| |
| Question: |
| What color is the fire hydrant in the image? |
| === |
| Answer: |
| The fire hydrant in the image is red. |
| === |
| Question: |
| Is the fire hydrant fully covered by snow or partially visible? |
| === |
| Answer: |
| The fire hydrant is partially visible, with a significant portion of it covered by the deep snow. |
| === |
| Question: |
| What is the condition of the sidewalk near the fire hydrant? |
| === |
| Answer: |
| The sidewalk near the fire hydrant has been recently plowed, so it is relatively clear of snow compared to the surrounding area. |
| === |
| Question: |
| What does the image suggest about the winter season in the city? |
| === |
| Answer: |
| The image suggests that the winter season in the city has been quite harsh and challenging. The significant snow accumulation seen in the image indicates that the city has experienced heavy snowfall, which can lead to various difficulties and disruptions for its residents. |
| |
| For instance, the deep snow covering the fire hydrant could potentially hinder its accessibility in case of emergencies, which poses safety concerns. The recently plowed sidewalk implies that the city’s maintenance crews have been actively working to keep the walkways clear and safe for pedestrians, but the sheer amount of snowfall might make it difficult to keep up with the continuous snow removal efforts. |
| |
| Furthermore, such extreme winter conditions can impact transportation, leading to traffic issues, delays in public transit, and increased risks of accidents due to slippery roads. It can also cause problems for businesses and schools, as people might face challenges commuting to work or attending classes. Additionally, the heavy snow can put extra strain on infrastructure, such as roofs and power lines, increasing the likelihood of structural damage or power outages. |
| |
| In conclusion, the image of the red fire hydrant deep in the snow and the recently plowed sidewalk suggest that the city has faced a particularly severe winter season, with substantial snowfall that has likely caused various challenges and disruptions for its residents and infrastructure. |
| |
|:---|
| |
| A man is skiing in the open snow covered hills |
| A skier is making his way into the snow. |
| A skier on the foothills of a huge mountain range. |
| A skier looks at mountains while standing near a trail sign. |
| a single person skiing by an area with a lot of bushes |
| |
| Question: |
| What is the skier doing? |
| === |
| Answer: |
| The skier is skiing in the snow-covered hills, making his way through the snow and enjoying the beautiful mountain scenery. They are also standing near a trail sign, which indicates their location on the mountain. |
| === |
| Question: |
| Are there any other people or skiers visible in the image? |
| === |
| Answer: |
| No, there is only a single person skiing in the image, and they are surrounded by an area with a lot of bushes. |
| === |
| Question: |
| What kind of skiing is the person doing? Cross-country or downhill? |
| === |
| Answer: |
| Based on what I can see in the photo, it is not possible to definitively determine whether the skier is doing cross-country or downhill skiing. However, given the presence of a trail sign and the fact that they are skiing in the foothills, it is more likely that the skier is engaged in cross-country skiing. Downhill skiing typically takes place on more steep slopes and involves ski lifts, whereas cross-country skiing often occurs on relatively flatter terrain with marked trails. |
| === |
| Question: |
| Can you explain cross-country and downhill skiing a bit more? |
| === |
| Answer: |
| Cross-country skiing and downhill skiing are two distinct types of skiing, each with its own techniques, equipment, and terrain preferences. |
| |
| 1\. Cross-Country Skiing: |
| Also known as Nordic skiing, cross-country skiing involves traversing relatively flat terrain or gentle slopes using skis and poles. It is a popular recreational and competitive sport that focuses on endurance, balance, and aerobic fitness. Cross-country skiers use their own locomotion to move across snow-covered terrain, rather than relying on ski lifts or other forms of assistance. |
| There are two main techniques in cross-country skiing: |
| \- Classic: This technique involves skiing in parallel tracks, using a forward-and-backward gliding motion while keeping the skis parallel to each other. The skier uses their poles to propel themselves forward. |
| \- Skate skiing: This technique is similar to ice skating, where the skier pushes off one ski at an angle and glides on the other. It requires a smooth, groomed surface and is typically faster than the classic technique. |
| Cross-country ski equipment consists of lightweight skis, boots, bindings, and poles. The boots are more flexible than those used in downhill skiing, allowing for better ankle movement and control. |
| |
| 2\. Downhill Skiing: |
| Also known as alpine skiing, downhill skiing involves descending slopes at high speeds using skis and poles for balance and control. This sport is more focused on speed, technique, and navigating challenging terrain, including steep slopes, moguls, and even jumps. |
| Downhill skiing can be further categorized into several disciplines, such as slalom, giant slalom, super-G, and downhill racing. Each discipline has its own set of rules, courses, and ski equipment. |
| Downhill ski equipment includes heavier and stiffer skis, boots, bindings, and poles than those used in cross-country skiing. The boots are more rigid to provide better support and control during high-speed descents and sharp turns. |
| |
| In summary, cross-country skiing is an endurance-based sport that involves traveling across flat or gently sloping terrain, while downhill skiing is focused on speed and technique as skiers navigate steeper slopes and challenging terrain. Both sports require specialized equipment and techniques, but they offer different experiences and challenges to participants. |
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
2023-01-30
Junnan Li, Dongxu Li, Silvio Savarese, Steven Hoi
The cost of vision-and-language pre-training has become increasingly prohibitive due to end-to-end training of large-scale models. This paper proposes BLIP-2, a generic and efficient pre-training strategy that bootstraps vision-language pre-training from off-the-shelf frozen pre-trained image encoders and frozen large language models. BLIP-2 bridges the modality gap with a lightweight Querying Transformer, which is pre-trained in two stages. The first stage bootstraps vision-language representation learning from a frozen image encoder. The second stage bootstraps vision-to-language generative learning from a frozen language model. BLIP-2 achieves state-of-the-art performance on various vision-language tasks, despite having significantly fewer trainable parameters than existing methods. For example, our model outperforms Flamingo80B by 8.7% on zero-shot VQAv2 with 54x fewer trainable parameters. We also demonstrate the model's emerging capabilities of zero-shot image-to-text generation that can follow natural language instructions.
Show Paper Content
# Introduction
Vision-language pre-training (VLP) research has witnessed a rapid
advancement in the past few years, where pre-trained models with
increasingly larger scale have been developed to continuously push the
state-of-the-art on various downstream
tasks [clip](None), [ALBEF](None), [blip](None), [ofa](None), [flamingo](None), [beit3](None). However, most
state-of-the-art vision-language models incur a high computation cost
during pre-training, due to end-to-end training using large-scale models
and datasets.
Vision-language research sits at the intersection between vision and
language, therefore it is naturally expected that vision-language models
can harvest from the readily-available unimodal models from the vision
and natural language communities. In this paper, we propose a *generic*
and *compute-efficient* VLP method by bootstrapping from off-the-shelf
pre-trained vision models and language models. Pre-trained vision models
offer high-quality visual representation. Pre-trained language models,
in particular *large language models* (LLMs), offer strong language
generation and zero-shot transfer abilities. To reduce computation cost
and counteract the issue of catastrophic forgetting, the unimodal
pre-trained models remain frozen during the pre-training.
In order to leverage pre-trained unimodal models for VLP, it is key to
facilitate cross-modal alignment. However, since LLMs have not seen
images during their unimodal pre-training, freezing them makes
vision-language alignment in particular challenging. In this regard,
existing methods ( Frozen [Frozen](None),
Flamingo [flamingo](None)) resort to an image-to-text
generation loss, which we show is insufficient to bridge the modality
gap.
To achieve effective vision-language alignment with frozen unimodal
models, we propose a Querying Transformer () pre-trained with a new
two-stage pre-training strategy. As shown in
Figure [fig:teaser], is a lightweight
transformer which employs a set of learnable query vectors to extract
visual features from the frozen image encoder. It acts as an information
bottleneck between the frozen image encoder and the frozen LLM, where it
feeds the most useful visual feature for the LLM to output the desired
text. In the first pre-training stage, we perform vision-language
representation learning which enforces the to learn visual
representation most relevant to the text. In the second pre-training
stage, we perform vision-to-language generative learning by connecting
the output of the to a frozen LLM, and trains the such that its output
visual representation can be interpreted by the LLM.
We name our VLP framework as BLIP-2: Bootstrapping Language-Image
Pre-training with frozen unimodal models. The key advantages of BLIP-2
include:
- BLIP-2 effectively leverages both frozen pre-trained image models
and language models. We bridge the modality gap using a pre-trained
in two-stages: representation learning stage and generative learning
stage. BLIP-2 achieves state-of-the-art performance on various
vision-language tasks including visual question answering, image
captioning, and image-text retrieval.
- Powered by LLMs ( OPT [opt](None),
FlanT5 [flanT5](None)), BLIP-2 can be prompted to perform
zero-shot image-to-text generation that follows natural language
instructions, which enables emerging capabilities such as visual
knowledge reasoning, visual conversation, etc. (see
Figure [fig:example] for examples).
- Due to the use of frozen unimodal models and a lightweight , BLIP-2
is more compute-efficient than exisiting state-of-the-arts. For
example, BLIP-2 outperforms Flamingo [flamingo](None) by
8.7% on zero-shot VQAv2, while using 54$\times$ fewer trainable
parameters. Furthermore, our results show that BLIP-2 is a generic
method that can harvest more advanced unimodal models for better VLP
performance.
# Related Work
## End-to-end Vision-Language Pre-training
Vision-language pre-training aims to learn multimodal foundation models
with improved performance on various vision-and-language tasks.
Depending on the downstream task, different model architectures have
been proposed, including the dual-encoder
architecture [clip](None), [align](None), the fusion-encoder
architecture [LXMERT](None), [ALBEF](None), the encoder-decoder
architecture [VL_T5](None), [simvlm](None), [pali](None), and more recently, the
unified transformer architecture [blip](None), [beit3](None). Various
pre-training objectives have also been proposed over the years, and have
progressively converged to a few time-tested ones: image-text
contrastive learning [clip](None), [filip](None), [ALBEF](None), [blip](None), image-text
matching [ALBEF](None), [blip](None), [VLMo](None), and (masked) language
modeling [ALBEF](None), [blip](None), [coca](None), [beit3](None).
Most VLP methods perform end-to-end pre-training using large-scale
image-text pair datasets. As the model size keeps increasing, the
pre-training can incur an extremely high computation cost. Moreover, it
is inflexible for end-to-end pre-trained models to leverage
readily-available unimodal pre-trained models, such as
LLMs [gpt3](None), [opt](None), [flanT5](None).
## Modular Vision-Language Pre-training
More similar to us are methods that leverage off-the-shelf pre-trained
models and keep them frozen during VLP. Some methods freeze the image
encoder, including the early work which adopts a frozen object detector
to extract visual features [uniter](None), [oscar](None), [vinvl](None), and the
recent LiT [LiT](None) which uses a frozen pre-trained image
encoder for CLIP [clip](None) pre-training. Some methods freeze
the language model to use the knowledge from LLMs for vision-to-language
generation
tasks [Frozen](None), [flamingo](None), [vgpt](None), [mapl](None), [pnp-vqa](None), [img2prompt](None). The
key challenge in using a frozen LLM is to align visual features to the
text space. To achieve this, Frozen [Frozen](None) finetunes an
image encoder whose outputs are directly used as soft prompts for the
LLM. Flamingo [flamingo](None) inserts new cross-attention
layers into the LLM to inject visual features, and pre-trains the new
layers on billions of image-text pairs. Both methods adopt the language
modeling loss, where the language model generates texts conditioned on
the image.
Different from existing methods, BLIP-2 can effectively and efficiently
leverage both frozen image encoders and frozen LLMs for various
vision-language tasks, achieving stronger performance at a lower
computation cost.
# Method [sec:method]
We propose BLIP-2, a new vision-language pre-training method that
bootstraps from frozen pre-trained unimodal models. In order to bridge
the modality gap, we propose a Querying Transformer () pre-trained in
two stages: (1) vision-language representation learning stage with a
frozen image encoder and (2) vision-to-language generative learning
stage with a frozen LLM. This section first introduces the model
architecture of , and then delineates the two-stage pre-training
procedures.
## Model Architecture
We propose as the trainable module to bridge the gap between a frozen
image encoder and a frozen LLM. It extracts a fixed number of output
features from the image encoder, independent of input image resolution.
As shown in Figure [fig:stage1], consists of two
transformer submodules that share the same self-attention layers: (1) an
image transformer that interacts with the frozen image encoder for
visual feature extraction, (2) a text transformer that can function as
both a text encoder and a text decoder. We create a set number of
learnable query embeddings as input to the image transformer. The
queries interact with each other through self-attention layers, and
interact with frozen image features through cross-attention layers
(inserted every other transformer block). The queries can additionally
interact with the text through the same self-attention layers. Depending
on the pre-training task, we apply different self-attention masks to
control query-text interaction. We initialize with the pre-trained
weights of BERT$_\text{base}$ [bert](None), whereas the
cross-attention layers are randomly initialized. In total, contains
188M parameters. Note that the queries are considered as model
parameters.
In our experiments, we use 32 queries where each query has a dimension
of 768 (same as the hidden dimension of the ). We use $Z$ to denote the
output query representation. The size of $Z$ ($32\times768$) is much
smaller than the size of frozen image features ( $257\times1024$ for
ViT-L/14). This bottleneck architecture works together with our
pre-training objectives into forcing the queries to extract visual
information that is most relevant to the text.
## Bootstrap Vision-Language Representation Learning from a Frozen Image Encoder
In the representation learning stage, we connect to a frozen image
encoder and perform pre-training using image-text pairs. We aim to train
the such that the queries can learn to extract visual representation
that is most informative of the text. Inspired by
BLIP [blip](None), we jointly optimize three pre-training
objectives that share the same input format and model parameters. Each
objective employs a different attention masking strategy between queries
and text to control their interaction (see
Figure [fig:stage1]).
**Image-Text Contrastive Learning** (ITC) learns to align image
representation and text representation such that their mutual
information is maximized. It achieves so by contrasting the image-text
similarity of a positive pair against those of negative pairs. We align
the output query representation $Z$ from the image transformer with the
text representation $t$ from the text transformer, where $t$ is the
output embedding of the `[CLS]` token. Since $Z$ contains multiple
output embeddings (one from each query), we first compute the pairwise
similarity between each query output and $t$, and then select the
highest one as the image-text similarity. To avoid information leak, we
employ a unimodal self-attention mask, where the queries and text are
not allowed to see each other. Due to the use of a frozen image encoder,
we can fit more samples per GPU compared to end-to-end methods.
Therefore, we use in-batch negatives instead of the momentum queue in
BLIP.
**Image-grounded Text Generation** (ITG) loss trains the to generate
texts, given input images as the condition. Since the architecture of
does not allow direct interactions between the frozen image encoder and
the text tokens, the information required for generating the text must
be first extracted by the queries, and then passed to the text tokens
via self-attention layers. Therefore, the queries are forced to extract
visual features that capture all the information about the text. We
employ a multimodal causal self-attention mask to control query-text
interaction, similar to the one used in UniLM [UniLM](None).
The queries can attend to each other but not the text tokens. Each text
token can attend to all queries and its previous text tokens. We also
replace the `[CLS]` token with a new `[DEC]` token as the first text
token to signal the decoding task.
**Image-Text Matching** (ITM) aims to learn fine-grained alignment
between image and text representation. It is a binary classification
task where the model is asked to predict whether an image-text pair is
positive (matched) or negative (unmatched). We use a bi-directional
self-attention mask where all queries and texts can attend to each
other. The output query embeddings $Z$ thus capture multimodal
information. We feed each output query embedding into a two-class linear
classifier to obtain a logit, and average the logits across all queries
as the output matching score. We adopt the hard negative mining strategy
from [ALBEF](None), [blip](None) to create informative negative pairs.
## Bootstrap Vision-to-Language Generative Learning from a Frozen LLM
In the generative pre-training stage, we connect (with the frozen image
encoder attached) to a frozen LLM to harvest the LLM’s generative
language capability. As shown in
Figure [fig:stage2], we use a fully-connected
(FC) layer to linearly project the output query embeddings $Z$ into the
same dimension as the text embedding of the LLM. The projected query
embeddings are then prepended to the input text embeddings. They
function as *soft visual prompts* that condition the LLM on visual
representation extracted by the . Since the has been pre-trained to
extract language-informative visual representation, it effectively
functions as an information bottleneck that feeds the most useful
information to the LLM while removing irrelevant visual information.
This reduces the burden of the LLM to learn vision-language alignment,
thus mitigating the catastrophic forgetting problem.
We experiment with two types of LLMs: decoder-based LLMs and
encoder-decoder-based LLMs. For decoder-based LLMs, we pre-train with
the language modeling loss, where the frozen LLM is tasked to generate
the text conditioned on the visual representation from . For
encoder-decoder-based LLMs, we pre-train with the prefix language
modeling loss, where we split a text into two parts. The prefix text is
concatenated with the visual representation as input to the LLM’s
encoder. The suffix text is used as the generation target for the LLM’s
decoder.
## Model Pre-training
**Pre-training data.** We use the same pre-training dataset as BLIP with
129M images in total, including COCO [coco](None), Visual
Genome [VG](None), CC3M [CC](None),
CC12M [cc12m](None), SBU [sbu](None), and 115M images
from the LAION400M dataset [laion](None). We adopt the CapFilt
method [blip](None) to create synthetic captions for the web
images. Specifically, we generate 10 captions using the
BLIP$_\mathrm{large}$ captioning model, and rank the synthetic captions
along with the original web caption based on the image-text similarity
produced by a CLIP ViT-L/14 model. We keep top-two captions per image as
training data and randomly sample one at each pre-training step.
**Pre-trained image encoder and LLM.** For the frozen image encoder, we
explore two state-of-the-art pre-trained vision transformer models: (1)
ViT-L/14 from CLIP [clip](None) and (2) ViT-g/14 from
EVA-CLIP [eva](None). We remove the last layer of the ViT and
uses the second last layer’s output features, which leads to slightly
better performance. For the frozen language model, we explore the
unsupervised-trained OPT model family [opt](None) for
decoder-based LLMs, and the instruction-trained FlanT5 model
family [flanT5](None) for encoder-decoder-based LLMs.
**Pre-training settings.** We pre-train for 250k steps in the first
stage and 80k steps in the second stage. We use a batch size of
2320/1680 for ViT-L/ViT-g in the first stage and a batch size of
1920/1520 for OPT/FlanT5 in the second stage. During pre-training, we
convert the frozen ViTs’ and LLMs’ parameters into FP16, except for
FlanT5 where we use BFloat16. We found no performance degradation
compared to using 32-bit models. Due to the use of frozen models, our
pre-training is more computational friendly than existing large-scale
VLP methods. For example, using a single 16-A100(40G) machine, our
largest model with ViT-g and FlanT5-XXL requires less than 6 days for
the first stage and less than 3 days for the second stage.
The same set of pre-training hyper-parameters are used for all models.
We use the AdamW [adamw](None) optimizer with $\beta_1=0.9$,
$\beta_1=0.98$, and a weight decay of 0.05. We use a cosine learning
rate decay with a peak learning rate of 1e-4 and a linear warmup of 2k
steps. The minimum learning rate at the second stage is 5e-5. We use
images of size 224$\times$``{=html}224, augmented with random
resized cropping and horizontal flipping.
# Experiment
Table 1 provides an overview of the performance of BLIP-2 on various
zero-shot vision-language tasks. Compared to previous state-of-the-art
models, BLIP-2 achieves improved performance while requiring
substantially fewer number of trainable parameters during
vision-language pre-training.
## Instructed Zero-shot Image-to-Text Generation
BLIP-2 effectively enables a LLM to understand images while preserving
its capability in following text prompts, which allows us to control
image-to-text generation with instructions. We simply append the text
prompt after the visual prompt as input to the LLM.
Figure [fig:example] shows examples to
demonstrate a wide range of zero-shot image-to-text capabilities
including visual knowledge reasoning, visual commensense reasoning,
visual conversation, personalized image-to-text generation, etc.
**Zero-shot VQA**. We perform quantitative evaluation on the zero-shot
visual question answering task. For OPT models, we use the prompt
“Question: {} Answer:”. For FlanT5 models, we use the prompt “Question:
{} Short answer:”. During generation, we use beam search with a beam
width of 5. We also set the length-penalty to -1 which encourages
shorter answers that align better with human annotation.
As shown in Table [tbl:vqa_zeroshot]. BLIP-2
achieves state-of-the-art result on the VQAv2 [VQA2](None) and
GQA [GQA](None) datasets. It outperforms Flamingo80B by 8.7% on
VQAv2, despite having 54x fewer trainable parameters. On the
OK-VQA [okvqa](None) dataset, BLIP-2 comes secondary to
Flamingo80B. We hypothesis that this is because OK-VQA focuses more on
open-world knowledge than visual understanding, and the 70B
Chinchilla [chinchilla](None) language model from Flamingo80B
possesses more knowledge than the 11B FlanT5$_\text{XXL}$.
We make a promising observation from
Table [tbl:vqa_zeroshot]: **a stronger
image encoder or a stronger LLM both lead to better performance.** This
observation is supported by several facts: (1) ViT-g outperforms ViT-L
for both OPT and FlanT5. (2) Within the same LLM family, larger models
outperform smaller ones. (3) FlanT5, an instruction-tuned LLM,
outperforms the unsupervised-trained OPT on VQA. This observation
validates BLIP-2 as a **generic vision-language pre-training method**
that can efficiently harvest the rapid advances in vision and natural
language communities.
**Effect of Vision-Language Representation Learning.**
The first-stage representation learning pre-trains the to learn visual
features relevant to the text, which reduces the burden of the LLM to
learn vision-language alignment. Without the representation learning
stage, relies solely on the vision-to-language generative learning to
bridge the modality gap, which is similar to the Perceiver Resampler in
Flamingo. Figure [fig:qformer_effect] shows the
effect of representation learning on generative learning. Without
representation learning, both types of LLMs give substantially lower
performance on zero-shot VQA. In particular, OPT suffers from
catastrophic forgetting where performance drastically degrades as
training proceeds.
## Image Captioning
We finetune BLIP-2 models for the image captioning task, which asks the
model to generate a text description for the image’s visual content. We
use the prompt “a photo of” as an initial input to the LLM and trains
the model to generate the caption with the language modeling loss. We
keep the LLM frozen during finetuning, and updates the parameters of the
together with the image encoder. We experiment with ViT-g and various
LLMs. Detailed hyperparameters can be found in the appendix. We perform
finetuning on COCO, and evaluate on both COCO test set and zero-shot
transfer to NoCaps [nocaps](None) validation set.
The results are shown in
Table [tbl:caption]. BLIP-2 achieves
state-of-the-art performance with significant improvement on NoCaps over
existing methods, demonstrating strong generalization ability to
out-domain images.
## Visual Question Answering
Given annotated VQA data, we finetune the parameters of the and the
image encoder while keeping the LLM frozen. We finetune with the
open-ended answer generation loss, where the LLM receives ’s output and
the question as input, and is asked to generate the answer. In order to
extract image features that are more relevant to the question, we
additionally condition on the question. Specifically, the question
tokens are given as input to the and interact with the queries via the
self-attention layers, which can guide the ’s cross-attention layers to
focus on more informative image regions.
Following BLIP, our VQA data includes the training and validation splits
from VQAv2, as well as training samples from Visual Genome.
Table [tbl:vqa_finetune] demonstrates
the state-of-the-art results of BLIP-2 among open-ended generation
models.
## Image-Text Retrieval
Since image-text retrieval does not involve language generation, we
directly finetune the first-stage-pretrained model w/o LLM.
Specifically, we finetune the image encoder together with on COCO using
the same objectives ( ITC, ITM, and ITG) as pre-training. We then
evaluate the model for both image-to-text retrieval and text-to-image
retrieval on COCO and Flickr30K [flickr](None) datasets. During
inference, we follow [ALBEF](None), [blip](None) which first select
$k=128$ candidates based on the image-text feature similarity, followed
by a re-ranking based on pairwise ITM scores. We experiment with both
ViT-L and ViT-g as the image encoder. Detailed hyperparameters can be
found in the appendix.
The results are shown in
Table [tbl:retrieval]. BLIP-2 achieves
state-of-the-art performance with significant improvement over existing
methods on zero-shot image-text retrieval.
The ITC and ITM losses are essential for image-text retrieval as they
directly learn image-text similarity. In
Table [tbl:retrieval_ablation], we
show that the ITG (image-grounded text generation) loss is also
beneficial for image-text retrieval. This result supports our intuition
in designing the representation learning objectives: the ITG loss
enforces the queries to extract visual features most relevant to the
text, thus improving vision-language alignment.
# Limitation [sec:limitation]
Recent LLMs can perform in-context learning given few-shot examples.
However, our experiments with BLIP-2 do not observe an improved VQA
performance when providing the LLM with in-context VQA examples. We
attribute the lack of in-context learning capability to our pre-training
dataset, which only contains a single image-text pair per sample. The
LLMs cannot learn from it the correlation among multiple image-text
pairs in a single sequence. The same observation is also reported in the
Flamingo paper, which uses a close-sourced interleaved image and text
dataset (M3W) with multiple image-text pairs per sequence. We aim to
create a similar dataset in future work.
BLIP-2’s image-to-text generation could have unsatisfactory results due
to various reasons including inaccurate knowledge from the LLM,
activating the incorrect reasoning path, or not having up-to-date
information about new image content (see
Figure [fig:example_limitation]).
Furthermore, due to the use of frozen models, BLIP-2 inherits the risks
of LLMs, such as outputting offensive language, propagating social bias,
or leaking private information. Remediation approaches include using
instructions to guide model’s generation or training on a filtered
dataset with harmful content removed.
# Conclusion
We propose
BLIP-2, a generic and compute-efficient method for vision-language
pre-training that leverages frozen pre-trained image encoders and LLMs.
BLIP-2 achieves state-of-the-art performance on various vision-language
tasks while having a small amount of trainable parameters during
pre-training. BLIP-2 also demonstrates emerging capabilities in
zero-shot instructed image-to-text generation. We consider BLIP-2 as an
important step towards building a multimodal conversational AI agent.
Flamingo: a Visual Language Model for Few-Shot Learning
2022-04-29
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katie Millican, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob Menick, Sebastian Borgeaud, Andrew Brock, Aida Nematzadeh, Sahand Sharifzadeh, Mikolaj Binkowski, Ricardo Barreira, Oriol Vinyals, Andrew Zisserman, Karen Simonyan
Building models that can be rapidly adapted to novel tasks using only a handful of annotated examples is an open challenge for multimodal machine learning research. We introduce Flamingo, a family of Visual Language Models (VLM) with this ability. We propose key architectural innovations to: (i) bridge powerful pretrained vision-only and language-only models, (ii) handle sequences of arbitrarily interleaved visual and textual data, and (iii) seamlessly ingest images or videos as inputs. Thanks to their flexibility, Flamingo models can be trained on large-scale multimodal web corpora containing arbitrarily interleaved text and images, which is key to endow them with in-context few-shot learning capabilities. We perform a thorough evaluation of our models, exploring and measuring their ability to rapidly adapt to a variety of image and video tasks. These include open-ended tasks such as visual question-answering, where the model is prompted with a question which it has to answer; captioning tasks, which evaluate the ability to describe a scene or an event; and close-ended tasks such as multiple-choice visual question-answering. For tasks lying anywhere on this spectrum, a single Flamingo model can achieve a new state of the art with few-shot learning, simply by prompting the model with task-specific examples. On numerous benchmarks, Flamingo outperforms models fine-tuned on thousands of times more task-specific data.
Show Paper Content
#### Acknowledgments and Disclosure of Funding.
This research was funded by DeepMind. We would like to thank many
colleagues for useful discussions, suggestions, feedback, and advice,
including: Samuel Albanie, Relja Arandjelović, Kareem Ayoub,
Lorrayne Bennett, Adria Recasens Continente, Tom Eccles,
Nando de Freitas, Sander Dieleman, Conor Durkan, Aleksa Gordić,
Raia Hadsell, Will Hawkins, Lisa Anne Hendricks, Felix Hill,
Jordan Hoffmann, Geoffrey Irving, Drew Jaegle, Koray Kavukcuoglu,
Agustin Dal Lago, Mateusz Malinowski, Soňa Mokrá, Gaby Pearl,
Toby Pohlen, Jack Rae, Laurent Sifre, Francis Song, Maria Tsimpoukelli,
Gregory Wayne, and Boxi Wu.
# Appendix [appendix]
results overview.Left: Our
largest model, dubbed , outperforms state-of-the-art fine-tuned models
on 6 of the 16 tasks we consider with no fine-tuning. For the 9 tasks
with published few-shot results, sets the new few-shot state of the art.
Note: We omit RareAct, our 16th benchmark, as it is a zero-shot
benchmark with no available fine-tuned results to compare to.
Right: performance improves with model size and number of
shots.
# Introduction
One key aspect of intelligence is the ability to quickly learn to
perform a new task given a short
instruction [griffiths2019doing](None), [markman1989categorization](None).
While initial progress has been made towards a similar capability in
computer vision, the most widely used paradigm still consists of first
pretraining on a large amount of supervised data, before fine-tuning the
model on the task of
interest [lu2019vilbert](None), [wang2021ufo](None), [zellers2022merlot](None).
However, successful fine-tuning often requires many thousands of
annotated data points. In addition, it often requires careful per-task
hyperparameter tuning and is also resource intensive. Recently,
multimodal vision-language models trained with a contrastive
objective [align](None), [clip](None) have enabled zero-shot adaptation
to novel tasks, without the need for fine-tuning. However, because these
models simply provide a similarity score between a text and an image,
they can only address limited use cases such as classification, where a
finite set of outcomes is provided beforehand. They crucially lack the
ability to generate language, which makes them less suitable to more
open-ended tasks such as captioning or visual question-answering. Others
have explored visually-conditioned language
generation [wang2021simvlm](None), [tsimpoukelli2021multimodal](None), [cho2021unifying](None), [wang2022unifying](None), [xu2021vlm](None)
but have not yet shown good performance in low-data regimes.
We introduce , a Visual Language Model (VLM) that sets a new state of
the art in few-shot learning on a wide range of open-ended vision and
language tasks, simply by being prompted with a few input/output
examples, as illustrated in
Figure [fig:teaser]. Of the 16 tasks we
consider, also surpasses the fine-tuned state of the art on 6 tasks,
despite using orders of magnitude less task-specific training data (see
Figure 1). To achieve this, Flamingo takes
inspiration from recent work on large language models (LMs) which are
good few-shot
learners [gpt3](None), [gopher](None), [chinchilla](None), [chowdhery2022palm](None). A
single large LM can achieve strong performance on many tasks using only
its text interface: a few examples of a task are provided to the model
as a prompt, along with a query input, and the model generates a
continuation to produce a predicted output for that query. We show that
the same can be done for image and video understanding tasks such as
classification, captioning, or question-answering: these can be cast as
text prediction problems with visual input conditioning. The difference
from a LM is that the model must be able to ingest a multimodal prompt
containing images and/or videos interleaved with text. have this
capability—they are visually-conditioned autoregressive text generation
models able to ingest a sequence of text tokens interleaved with images
and/or videos, and produce text as output. leverage two complementary
pre-trained and frozen models: a vision model which can “perceive”
visual scenes and a large LM which performs a basic form of reasoning.
Novel architecture components are added in between these models to
connect them in a way that preserves the knowledge they have accumulated
during computationally intensive pre-training. are also able to ingest
high-resolution images or videos thanks to a
Perceiver-based [jaegle2021perceiver](None) architecture that
can produce a small fixed number of visual tokens per image/video, given
a large and variable number of visual input features.
A crucial aspect for the performance of large LMs is that they are
trained on a large amount of text data. This training provides
general-purpose generation capabilities that allows these LMs to perform
well when prompted with task examples. Similarly, we demonstrate that
the way we train the models is crucial for their final performance. They
are trained on a carefully chosen
mixture of complementary large-scale multimodal data coming only from
the web, *without using any data annotated for machine learning
purposes*. After this training, a model can be directly adapted to
vision tasks via simple few-shot learning without any task-specific
tuning.
**Contributions.** In summary, our contributions are the following:
**(i)** We introduce the family of VLMs which can perform various
multimodal tasks (such as captioning, visual dialogue, or visual
question-answering) from only a few input/output examples. Thanks to
architectural innovations, the models can efficiently accept arbitrarily
interleaved visual data and text as input and generate text in an
open-ended manner. **(ii)** We quantitatively evaluate how models can
be adapted to various tasks via few-shot learning. We notably reserve a
large set of held-out benchmarks which have not been used for validation
of any design decisions or hyperparameters of the approach. We use these
to estimate unbiased few-shot performance. **(iii)** sets a new state of
the art in few-shot learning on a wide array of 16 multimodal language
and image/video understanding tasks. On 6 of these 16 tasks, also
outperforms the fine-tuned state of the art despite using only 32
task-specific examples, around 1000 times less task-specific training
data than the current state of the art. With a larger annotation
budget, can also be effectively fine-tuned to set a new state of the
art on five additional challenging benchmarks: VQAv2, VATEX, VizWiz,
MSRVTTQA, and HatefulMemes.
# Approach [sec:approach]
This section describes Flamingo: a visual language model that accepts
text interleaved with images/videos as input and outputs free-form text.
The key architectural components shown in
Figure 2 are chosen to leverage pretrained
vision and language models and bridge them effectively. First, the
Perceiver Resampler
(Section 2.1) receives
spatio-temporal features from the Vision Encoder (obtained from either
an image or a video) and outputs a fixed number of visual tokens.
Second, these visual tokens are used to condition the frozen LM using
freshly initialised cross-attention layers
(Section 2.2) that are interleaved between
the pretrained LM layers. These new layers offer an expressive way for
the LM to incorporate visual information for the next-token prediction
task. Flamingo models the likelihood of text $y$ conditioned on
interleaved images and videos $x$ as follows: $$\begin{aligned}
p(y | x) = \prod_{\ell=1}^L p(y_\ell | y_{< \ell}, x_{\leq \ell}),
\label{eq:modeling}
\end{aligned}$$ where $y_{\ell}$ is the $\ell$-th language token of the
input text, $y_{<\ell}$ is the set of preceding tokens, $x_{\leq \ell}$
is the set of images/videos preceding token $y_{\ell}$ in the
interleaved sequence and $p$ is parametrized by a model. The ability to
handle interleaved text and visual sequences
(Section 2.3) makes it natural to use
models for in-context few-shot learning, analogously to GPT-3 with
few-shot text prompting. The model is trained on a diverse mixture of
datasets as described in
Section 2.4.
## Visual processing and the Perceiver Resampler [sec:transformer_resampler]
**Vision Encoder: from pixels to features.** Our vision encoder is a
pretrained and frozen Normalizer-Free ResNet (NFNet)
[nfnets](None) – we use the F6 model. We pretrain the vision
encoder using a contrastive objective on our datasets of image and text
pairs, using the two-term contrastive loss from [clip](None).
We use the output of the final stage, a 2D spatial grid of features that
is flattened to a 1D sequence. For video inputs, frames are sampled at 1
FPS and encoded independently to obtain a 3D spatio-temporal grid of
features to which learned temporal embeddings are added. Features are
then flattened to 1D before being fed to the Perceiver Resampler. More
details on the contrastive model training and performance are given in
Appendix [app:contrastive_details][app:contrastive_details]
and
Appendix [app:contrastive_ablation][app:contrastive_ablation],
respectively.
**Perceiver Resampler: from varying-size large feature maps to few
visual tokens.** This module connects the vision encoder to the frozen
language model as shown in
Figure 2. It takes as input a variable number
of image or video features from the vision encoder and produces a fixed
number of visual outputs (64), reducing the computational complexity of
the vision-text cross-attention. Similar to
Perceiver [jaegle2021perceiver](None) and
DETR [carion2020end](None), we learn a predefined number of
latent input queries which are fed to a Transformer and cross-attend to
the visual features. We show in our ablation studies
(Section 3.3) that using such a
vision-language resampler module outperforms a plain Transformer and an
MLP. We provide an illustration, more architectural details, and
pseudo-code in
Appendix [app:transformer_resampler][app:transformer_resampler].
## Conditioning frozen language models on visual representations [sec:xattn_dense]
Text generation is performed by a Transformer decoder, conditioned on
the visual representations produced by the Perceiver Resampler. We
interleave pretrained and frozen text-only LM blocks with blocks trained
from scratch that cross-attend to the visual output from the Perceiver
Resampler.
**Interleaving new gated xattn-dense
layers within a frozen pretrained LM.** We freeze the pretrained LM
blocks, and insert *gated cross-attention dense* blocks
(Figure 3) between the original layers,
trained from scratch. To ensure that at initialization, the conditioned
model yields the same results as the original language model, we use a
$\tanh$-gating mechanism [hochreiter1997long](http://arxiv.org/pdf/2103.15232v1). This
multiplies the output of a newly added layer by $\tanh(\alpha)$ before
adding it to the input representation from the residual connection,
where $\alpha$ is a layer-specific learnable scalar initialized to
$0$ [bachlechner2021rezero](None). Thus, at initialization, the
model output matches that of the pretrained LM, improving training
stability and final performance. In our ablation studies
(Section 3.3), we compare the proposed
gated xattn-dense layers against recent
alternatives [desai2021virtex](None), [luo2022vc](None) and explore the
effect of how frequently these additional layers are inserted to trade
off between efficiency and expressivity. See
Appendix [app:xattn_dense][app:xattn_dense] for more details.
**Varying model sizes.** We perform experiments across three models
sizes, building on the 1.4B, 7B, and 70B parameter Chinchilla
models [chinchilla](None); calling them respectively , and .
For brevity, we refer to the last as throughout the paper. While
increasing the parameter count of the frozen LM and the trainable
vision-text gated xattn-dense modules, we
maintain a fixed-size frozen vision encoder and trainable Perceiver
Resampler across the different models (small relative to the full model
size). See
Appendix [sec:models_details][sec:models_details] for further
details.
## Multi-visual input support: per-image/video attention masking [sec:multi_im_att]
The image-causal modelling introduced in
Equation [eq:modeling] is obtained by masking
the full text-to-image cross-attention matrix, limiting which visual
tokens the model sees at each text token. At a given text token, the
model attends to the visual tokens of the image that appeared just
before it in the interleaved sequence, rather than to all previous
images (formalized and illustrated in
Appendix [app:multi-visual-details][app:multi-visual-details]).
Though the model only *directly* attends to a single image at a time,
the dependency on all previous images remains via self-attention in the
LM. This single-image cross-attention scheme importantly allows the
model to seamlessly generalise to any number of visual inputs,
regardless of how many are used during training. In particular, we use
only up to 5 images per sequence when training on our interleaved
datasets, yet our model is able to benefit from sequences of up to 32
pairs (or “shots”) of images/videos and corresponding texts during
evaluation. We show in
Section 3.3 that this scheme is more
effective than allowing the model to cross-attend to all previous images
directly.
## Training on a mixture of vision and language datasets [sec:datasets]
We train the models on a mixture of three kinds of datasets, all scraped
from the web: an interleaved image and text dataset derived from
webpages, image-text pairs, and video-text pairs.
**M3W: Interleaved image and text dataset.**
The few-shot capabilities of
Flamingo models rely on training on interleaved text and image data. For
this purpose, we collect the *MultiModal MassiveWeb* () dataset. We
extract both text and images from the HTML of approximately 43 million
webpages, determining the positions of images relative to the text based
on the relative positions of the text and image elements in the Document
Object Model (DOM). An example is then constructed by inserting
`` tags in plain text at the locations of the images on the page,
and inserting a special `` (*end of chunk*) token (added to the
vocabulary and learnt) prior to any image and at the end of the
document. From each document, we sample a random subsequence of $L=256$
tokens and take up to the first $N=5$ images included in the sampled
sequence. Further images are discarded in order to save compute. More
details are provided in
Appendix [app:datasets][app:datasets].
**Pairs of image/video and text.** For our image and text pairs we first
leverage the ALIGN [align](None) dataset, composed of 1.8
billion images paired with alt-text. To complement this dataset, we
collect our own dataset of image and text pairs targeting better quality
and longer descriptions: LTIP (Long Text & Image Pairs) which consists
of 312 million image and text pairs. We also collect a similar dataset
but with videos instead of still images: VTP (Video & Text Pairs)
consists of 27 million short videos (approximately 22 seconds on
average) paired with sentence descriptions. We align the syntax of
paired datasets with the syntax of M3W by prepending `` and
appending `` to each training caption (see
Appendix [app:vtp_and_itp][app:vtp_and_itp] for details).
**Multi-objective training and optimisation strategy.** We train our
models by minimizing a weighted sum of per-dataset expected negative
log-likelihoods of text, given the visual inputs:
$$\sum_{m=1}^{M} \lambda_m \cdot \mathbb{E}_{(x, y)\sim \mathcal{D}_m} \left[ -\sum_{\ell=1}^L \log p(y_\ell | y_{< \ell}, x_{\leq \ell})\right],$$
where $\mathcal{D}_m$ and $\lambda_m$ are the $m$-th dataset and its
weighting, respectively. Tuning the per-dataset weights $\lambda_m$ is
key to performance. We accumulate gradients over all datasets, which we
found outperforms a “round-robin”
approach [cho2021unifying](None). We provide further training
details and ablations in
Appendix [app:large_scale_training][app:large_scale_training].
## Task adaptation with few-shot in-context learning [sec:adapt-vlm]
Once Flamingo is trained, we use it to tackle a visual task by
conditioning it on a multimodal interleaved prompt. We evaluate the
ability of our models to rapidly adapt to new tasks using **in-context
learning**, analogously to GPT-3 [gpt3](None), by interleaving
support example pairs in the form of $(image, text)$ or $(video, text)$,
followed by the query visual input, to build a prompt (details in
Appendix [app:in_context_eval_details][app:in_context_eval_details]).
We perform **open-ended** evaluations using beam search for decoding,
and **close-ended** evaluations using our model’s log-likelihood to
score each possible answer. We explore **zero-shot generalization** by
prompting the model with two text-only examples from the task, with no
corresponding images. Evaluation hyperparameters and additional details
are given in
Appendix [app:fewshot-eval-hyper][app:fewshot-eval-hyper].
# Experiments [sec:experiments]
Our goal is to develop models that can rapidly adapt to diverse and
challenging tasks. For this, we consider a wide array of 16 popular
multimodal image/video and language benchmarks. In order to validate
model design decisions during the course of the project, 5 of these
benchmarks were used as part of our development
(dev) set: COCO, OKVQA, VQAv2, MSVDQA and
VATEX. Performance estimates on the dev
benchmarks may be biased, as a result of model selection. We note that
this is also the case for prior work which makes use of similar
benchmarks to validate and ablate design decisions. To account for this,
we report performance on an additional set of 11 benchmarks, spanning
captioning, video question-answering, as well as some less commonly
explored capabilities such as visual dialogue and multi-choice
question-answering tasks. The evaluation benchmarks are described in
Appendix [sec:eval_benchmarks][sec:eval_benchmarks]. We keep
all evaluation hyperparameters fixed across all benchmarks. Depending on
the task, we use four few-shot prompt templates we describe in more
detail in
Appendix [app:fewshot-eval-hyper][app:fewshot-eval-hyper]. We
emphasize that *we do not validate any design decisions on these 11
benchmarks* and use them solely to estimate unbiased few-shot learning
performance of our models.
Concretely, estimating few-shot learning performance of a model involves
prompting it with a set of *support* samples and evaluating it on a set
of *query* samples. For the dev
benchmarks that are used both to validate design decisions and
hyperparameters, as well as to report final performance, we therefore
use four subsets: *validation support*, *validation query*, *test
support* and *test query*. For other benchmarks, we need only the latter
two. We report in
Appendix [sec:eval_benchmarks][sec:eval_benchmarks] how we
form these subsets.
We report the results of the models on few-shot learning in
Section 3.1.
Section 3.2 gives fine-tuned results. An
ablation study is given in
Section 3.3.
Appendix [app:more_performance][app:more_performance]
provides more results including ’s performance on the ImageNet and
Kinetics700 classification tasks, and on our contrastive model’s
performance. Appendix [app:qual_res][app:qual_res] includes additional
qualitative results.
## Few-shot learning on vision-language tasks [sec:fewshot_openended]
**Few-shot results.** Results are given in
Table [tab:fewshot_all_tasks].
outperforms by a large margin *all* previous zero-shot or few-shot
methods on the 16 benchmarks considered. This is achieved with as few as
four examples per task, demonstrating practical and efficient adaptation
of vision models to new tasks. More importantly, is often competitive
with state-of-the-art methods additionally fine-tuned on up to hundreds
of thousands of annotated examples. On six tasks, even outperforms the
fine-tuned SotA despite using a *single* set of model weights and only
32 task-specific examples. Finally, despite having only used the
dev benchmarks for design decisions, our
results generalize well to the other benchmarks, confirming the
generality of our approach.
**Scaling with respect to parameters and shots.** As shown in
Figure 1, the larger the model, the better the
few-shot performance, similar to GPT-3 [gpt3](None). The
performance also improves with the number of shots. We further find that
the largest model better exploits larger numbers of shots.
Interestingly, even though our models were trained with sequences
limited to only 5 images on , they are still able to benefit from up to
32 images or videos during inference. This demonstrates the flexibility
of the architecture for processing a variable number of videos or
images.
## Fine-tuning as a pretrained vision-language model [sec:ft_results]
While not the main focus of our work, we verify that when given more
data, models can be adapted to a task by fine-tuning their weights. In
Table [tab:ft-sota-table-compressed],
we explore fine-tuning our largest model, , for a given task with no
limit on the annotation budget. In short, we do so by fine-tuning the
model on a short schedule with a small learning rate by additionally
unfreezing the vision backbone to accommodate a higher input resolution
(details in Appendix [app:finetuning][app:finetuning]). We find that we
can improve results over our previously presented in-context few-shot
learning results, setting a new state of the art on five additional
tasks: VQAv2, VATEX, VizWiz, MSRVTTQA, and HatefulMemes.
## Ablation studies [sec:ablations]
In
Table [tab:ablation-table-no-classif],
we report our ablation results using on the *validation* subsets of the
five dev benchmarks with 4 shots. Note
that we use smaller batch sizes and a shorter training schedule compared
to the final models. The **Overall score** is obtained by dividing each
benchmark score by its state-of-the-art (SotA) performance from
Table [tab:fewshot_all_tasks] and
averaging the results. More details and results are given in
Appendix [app:all_ablation_studies][app:all_ablation_studies]
and
Table [tab:ablation-table-appendix].
**Importance of the training data mixture.** As shown in row **(i)**,
getting the right training data plays a crucial role. In fact, removing
the interleaved image-text dataset leads to a *decrease of more than
$17\%$* in performance while removing the conventional paired image-text
pairs also decreases performance (by $9.8\%$), demonstrating the need
for different types of datasets. Moreover, removing our paired
video-text dataset negatively affects performance on all video tasks. We
ablate replacing our image-text pairs (ITP) by the publicly available
LAION-400M dataset [schuhmann2021laion](None), which leads to a
slight degradation in performance. We show in row **(ii)** the
importance of our gradient accumulation strategy compared to using
round-robin updates [cho2021unifying](None).
**Visual conditioning of the frozen LM.** We ablate the use of the
0-initialized tanh gating when merging the cross-attention output to the
frozen LM output in row **(iii)**. Without it, we see a drop of $4.2\%$
in our overall score. Moreover, we have noticed that disabling the
0-initialized tanh gating leads to training instabilities. Next, we
ablate different conditioning architectures in row **(iv)**.
vanilla xattn, refers to the vanilla
cross-attention from the original Transformer
decoder [vaswani2017attention](None). In the
grafting approach
from [luo2022vc](None), the frozen LM is used as is with no
additional layers inserted, and a stack of interleaved self-attention
and cross-attention layers that take the frozen LM output are learnt
from scratch. Overall, we show that our gated
xattn-dense conditioning approach works best.
**Compute/Memory vs. performance trade-offs.** In row **(v)**, we ablate
the frequency at which we add new gated
xattn-dense blocks. Although adding them at every layer is
better, it significantly increases the number of trainable parameters
and time complexity of the model. Notably, inserting them every fourth
block accelerates training by $66\%$ while only decreasing the overall
score by $1.9\%$. In light of this trade-off, we maximize the number of
added layers under hardware constraints and add a
gated xattn-dense every fourth layer for
and every seventh for . We further compare in row **(vi)** the Perceiver
Resampler to a MLP and a vanilla Transformer given a parameter budget.
Both underperform the Perceiver Resampler while also being slower.
**Vision encoder.** In row **(vii)**, we compare our NFNet-F6 vision
encoder pretrained with contrastive learning (details in
Appendix [app:contrastive_details][app:contrastive_details])
to the publicly available CLIP ViT-L/14 [clip](None) model
trained at 224 resolution. Our NFNet-F6 has a $+5.8\%$ advantage over
the CLIP ViT-L/14 and $+8.0\%$ over a smaller NFNet-F0 encoder, which
highlights the importance of using a strong vision backbone.
**Freezing LM components prevents catastrophic forgetting.** We verify
the importance of freezing the LM layers at training in row **(viii)**.
If trained from scratch, we observe a large performance decrease of
$-12.9\%$. Interestingly, fine-tuning our pretrained LM also leads to a
drop in performance of $-8.0\%$. This indicates an instance of
“catastrophic forgetting” [mccloskey1989catastrophic](None),
in which the model progressively forgets its pretraining while training
on a new objective. In our setting, freezing the language model is a
better alternative to training with the pre-training dataset
(MassiveText) in the mixture.
# Related work
**Language modelling and few-shot adaptation.** Language modelling has
recently made substantial progress following the introduction of
Transformers [vaswani2017attention](None). The paradigm of
first pretraining on a vast amount of data followed by an adaptation on
a downstream task has become
standard [mikolov2010recurrent](None), [graves2013generating](None), [jozefowicz2016exploring](None), [howard2018universal](None), [bert](None), [t5](None), [sutskever2011generating](None), [gpt3](None).
In this work, we build on the 70B Chinchilla language
model [chinchilla](None) as the base LM for . Numerous works
have explored techniques to adapt language models to novel tasks using a
few examples. These include adding small adapter
modules [houlsby2019parameter](None), fine-tuning a small part
of the LM [zaken_bitfit_2022](None), showing in-context
examples in the prompt [gpt3](None), or optimizing the
prompt [li2021prefix](None), [lester2021power](None) through gradient
descent. In this paper, we take inspiration from the
in-context [gpt3](None) few-shot learning technique instead of
more involved few-shot learning approaches based on metric
learning [doersch2020crosstransformers](None), [vinyals2016matching](None), [snell2017prototypical](None), [tian2020rethinking](None)
or
meta-learning [finn2017model](None), [bertinetto2018meta](None), [zintgraf2019fast](None), [requeima2019fast](None), [gordon2018meta](None), [bertinetto2016learning](None).
**When language meets vision.** These LM breakthroughs have been
influential for vision-language modelling. In particular,
BERT [bert](None) inspired a large body of vision-language
work [lu2019vilbert](None), [su2019vl](None), [chen2020uniter](None), [hendricks2021decoupling](None), [wang2021vlmo](None), [li2020oscar](None), [tan2019lxmert](None), [zhu2020actbert](None), [wang2021ufo](None), [li2020hero](None), [gan2020large](None), [fu2021violet](None), [zellers2021merlot](None), [zellers2022merlot](None), [singh2021flava](None), [sun2019videobert](None).
We differ from these approaches as do not require fine-tuning on new
tasks. Another family of vision-language models is based on contrastive
learning [alayrac2020self](None), [clip](None), [align](None), [zhai2021lit](None), [pham2021combined](None), [miech2020end](None), [bain2021frozen](None), [yuan2021florence](None), [li2021align](None), [yao2021filip](None), [jain2021mural](None).
differs from contrastive models as it can generate text, although we
build and rely upon them for our vision encoder. Similar to our work are
VLMs able to generate text in an autoregressive
manner [vinyals2015show](None), [donahue2015long](None), [luo2020univl](None), [hu2021scaling](None), [dai2022](None).
Concurrent
works [wang2021simvlm](None), [cho2021unifying](None), [wang2022unifying](None), [zhu2021uni](None), [li2022blip](None)
also propose to formulate numerous vision tasks as text generation
problems. Building on top of powerful pretrained language models has
been explored in several recent works. One recent line of
work [tsimpoukelli2021multimodal](None), [eichenberg2021magma](None), [mokady2021clipcap](None), [luo2022vc](None), [yang2021empirical](None), [zeng2022socraticmodels](None)
proposes to freeze the pretrained LM weights to prevent catastrophic
forgetting [mccloskey1989catastrophic](None). We follow this
idea by freezing the Chinchilla LM layers [chinchilla](None)
and adding learnable layers within the frozen LM. We differ from prior
work by introducing the first LM that can ingest arbitrarily interleaved
images, videos, and text.
**Web-scale vision and language training datasets.** Manually annotated
vision and language datasets are costly to obtain and thus relatively
small (10k-100k) in
scale [young2014image](None), [chen2015microsoft](None), [antol2015vqa](None), [marino2019ok](None), [wang2019vatex](None), [xiao2021next](None).
To alleviate this lack of data, numerous
works [align](None), [sharma2018conceptual](None), [changpinyo2021conceptual](None), [thomee2016yfcc100m](None)
automatically scrape readily available paired vision-text data. In
addition to such paired data, we show the importance of also training on
entire multimodal webpages containing interleaved images and text as a
single sequence. Concurrent work CM3 [aghajanyan2022cm3](None)
proposes to generate HTML markup from pages, while we simplify the text
prediction task by only generating plain text. We emphasize few-shot
learning and vision tasks while CM3 [aghajanyan2022cm3](None)
primarily evaluates on language-only benchmarks in a zero-shot or
fine-tuned setup.
# Discussion [sec:discussion]
**Limitations.** First, our models build on pretrained LMs, and as a
side effect, directly inherit their weaknesses. For example, LM priors
are generally helpful, but may play a role in occasional hallucinations
and ungrounded guesses. Furthermore, LMs generalise poorly to sequences
longer than the training ones. They also suffer from poor sample
efficiency during training. Addressing these issues can accelerate
progress in the field and enhance the abilities of VLMs like Flamingo.
Second, the classification performance of lags behind that of
state-of-the-art contrastive
models [clip](None), [pham2021combined](None). These models directly
optimize for text-image retrieval, of which classification is a special
case. In contrast, our models handle a wider range of tasks, such as
open-ended ones. A unified approach to achieve the best of both worlds
is an important research direction.
Third, in-context learning has significant advantages over
gradient-based few-shot learning methods, but also suffers from
drawbacks depending on the characteristics of the application at hand.
We demonstrate the effectiveness of in-context learning when access is
limited to only a few dozen examples. In-context learning also enables
simple deployment, requiring only inference, generally with no
hyperparameter tuning needed. However, in-context learning is known to
be highly sensitive to various aspects of the
demonstrations [zhao2021calibrate](None), [truefewshot](None), and its
inference compute cost and absolute performance scale poorly with the
number of shots beyond this low-data regime. There may be opportunities
to combine few-shot learning methods to leverage their complementary
benefits. We discuss the limitations of our work in more depth in
Appendix [sec:limitations][sec:limitations].
**Societal impacts.** In terms of societal impacts, offers a number of
benefits while carrying some risks. Its ability to rapidly adapt to a
broad range of tasks have the potential to enable non-expert users to
obtain good performance in data-starved regimes, lowering the barriers
to both beneficial and malicious applications. is exposed to the same
risks as large language models, such as outputting offensive language,
propagating social biases and stereotypes, as well as leaking private
information [weidinger2021harms](None), [chinchilla](None). Its ability
to additionally handle visual inputs poses specific risks such as gender
and racial biases relating to the contents of the input images, similar
to a number of visual recognition
systems [hendricks2018women](None), [zhao2021understanding](None), [buolamwini2018gender](None), [de2019does](None), [schwemmer2020diagnosing](None).
We refer the reader to
Appendix [sec:broader_impact][sec:broader_impact] for a more
extensive discussion of the societal impacts of our work, both positive
and negative; as well as mitigation strategies and early investigations
of risks relating to racial or gender bias and toxic outputs. Finally we
note that, following prior work focusing on language
models [thoppilan2022lamda](None), [perez2022red](None), [menick2022teaching](None),
the few-shot capabilities of could be useful for mitigating such risks.
**Conclusion.** We proposed Flamingo, a general-purpose family of models
that can be applied to image and video tasks with minimal task-specific
training data. We also qualitatively explored interactive abilities of
such as “chatting” with the model, demonstrating flexibility beyond
traditional vision benchmarks. Our results suggest that connecting
pre-trained large language models with powerful visual models is an
important step towards general-purpose visual understanding.
# Checklist [checklist]
1. For all authors...
1. Do the main claims made in the abstract and introduction
accurately reflect the paper’s contributions and scope?
2. Did you describe the limitations of your work?
3. Did you discuss any potential negative societal impacts of your
work?
4. Have you read the ethics review guidelines and ensured that your
paper conforms to them?
2. If you are including theoretical results...
1. Did you state the full set of assumptions of all theoretical
results?
2. Did you include complete proofs of all theoretical results?
3. If you ran experiments...
1. Did you include the code, data, and instructions needed to
reproduce the main experimental results (either in the
supplemental material or as a URL)?
2. Did you specify all the training details (e.g., data splits,
hyperparameters, how they were chosen)?
3. Did you report error bars (e.g., with respect to the random seed
after running experiments multiple times)?
4. Did you include the total amount of compute and the type of
resources used (e.g., type of GPUs, internal cluster, or cloud
provider)?
4. If you are using existing assets (e.g., code, data, models) or
curating/releasing new assets...
1. If your work uses existing assets, did you cite the creators?
2. Did you mention the license of the assets?
3. Did you include any new assets either in the supplemental
material or as a URL?
4. Did you discuss whether and how consent was obtained from people
whose data you’re using/curating?
5. Did you discuss whether the data you are using/curating contains
personally identifiable information or offensive content? .
5. If you used crowdsourcing or conducted research with human
subjects...
1. Did you include the full text of instructions given to
participants and screenshots, if applicable?
2. Did you describe any potential participant risks, with links to
Institutional Review Board (IRB) approvals, if applicable?
3. Did you include the estimated hourly wage paid to participants
and the total amount spent on participant compensation?
Classic VLMs trained on document images
These classic Vision-Language Models are trained on natural images to perform tasks such as image-based question answering. However, to adapt them to text-rich images like documents
(the data is way less abundant than natural images), some work have fine-tuned these vision-language models on datasets containing text-rich images
such as documents. Here are some examples of classic vision-language models fine-tuned on text-rich data:
mPLUG-PaperOwl: Scientific Diagram Analysis with the Multimodal Large Language Model
2023-11-30
Anwen Hu, Yaya Shi, Haiyang Xu, Jiabo Ye, Qinghao Ye, Ming Yan, Chenliang Li, Qi Qian, Ji Zhang, Fei Huang
Recently, the strong text creation ability of Large Language Models(LLMs) has given rise to many tools for assisting paper reading or even writing. However, the weak diagram analysis abilities of LLMs or Multimodal LLMs greatly limit their application scenarios, especially for scientific academic paper writing. In this work, towards a more versatile copilot for academic paper writing, we mainly focus on strengthening the multi-modal diagram analysis ability of Multimodal LLMs. By parsing Latex source files of high-quality papers, we carefully build a multi-modal diagram understanding dataset M-Paper. By aligning diagrams in the paper with related paragraphs, we construct professional diagram analysis samples for training and evaluation. M-Paper is the first dataset to support joint comprehension of multiple scientific diagrams, including figures and tables in the format of images or Latex codes. Besides, to better align the copilot with the user's intention, we introduce the `outline' as the control signal, which could be directly given by the user or revised based on auto-generated ones. Comprehensive experiments with a state-of-the-art Mumtimodal LLM demonstrate that training on our dataset shows stronger scientific diagram understanding performance, including diagram captioning, diagram analysis, and outline recommendation. The dataset, code, and model are available at https://github.com/X-PLUG/mPLUG-DocOwl/tree/main/PaperOwl.
Show Paper Content
[^1]: Equal Contribution.
[^2]: Corresponding Author
# Introduction [sec:intro]
The strong text creation ability of the Large Language
Model(LLM)[llama](http://arxiv.org/pdf/2402.08075v1), [gpt3](http://arxiv.org/pdf/2112.07522v2), [vicuna](https://github.com/lm-sys/FastChat), [alpaca](https://github.com/tatsu-lab/stanford_alpaca) inspires the
development of paper-writing copilot recently, such as jenni[^1].
However, existing LLMs or Multimodal LLMs are still not fully competent
to assist academic paper writing due to the weak scientific diagram
analysis abilities.
As shown in 1, to assist the user in writing academic
analysis about scientific diagrams, the copilot should be equipped with
major three abilities. **First and most basically**, the model should be
able to understand multiple diagrams of various types (figures, tables,
etc.) and in different formats (image or latex). **Second**, the diagram
analysis should remain consistent with the preceding texts and therefore
ask to model to correlate multimodal context and diagram information.
**Third**, for better aligning the user’s intention, the copilot should
be interactable with the user, which requires the model controllable.
Recently, there have been many Multimodal Large Language
Models(MLLMs)[Alayrac2022FlamingoAV](http://arxiv.org/pdf/2205.07065v1), [ye2023mplugowl2](https://arxiv.org/pdf/2311.04257), [qwenvl](None), [minigpt4](http://arxiv.org/pdf/2402.17510v1), [llava](http://arxiv.org/pdf/2402.11690v1), [llava1.5](http://arxiv.org/pdf/2310.19145v1), [instructblip](None), [cogvlm2023](http://arxiv.org/pdf/2210.00066v1)
proposed by connecting a vision encoder with a Large Language Model as
the language decoder. These MLLMs are good at chatting about a general
image but poor at understanding diagrams. Some
work[ureader](None), [docowl](None) tried to develop MLLMs for
Multimodal Document Understanding, covering tables, charts,
webpages,.etc. However, these models mainly focus on strengthening the
vision comprehension of a single diagram and can’t generate detailed
scientific analysis.
In this work, to develop scientific diagram analysis skills for the
paper-writing copilot, we first build a comprehensive dataset to
support the learning of the three critical abilities mentioned above. By
parsing Latex source files of high-quality academic papers, we carefully
extract diagrams in both image and latex formats and align them with
their captions and paragraph analysis. To simulate two main scenarios of
scientific diagrammatic understanding, we design two main tasks, namely
***Multimodal Diagram Captioning*** and ***Multimodal Diagram
Analysis***, where multiple diagrams are the main comprehending objects.
In addition, we provide the preceding text, namely $[Context]$, as part
of the input to teach the model how to utilize background knowledge and
maintain fluency with previous content. Furthermore, to better align
users’ writing intentions, we design $[Outline]$ as control signals,
which are comprised of concise key points to be covered in the analysis.
We utilize the ChatGPT to construct $[Outline]$ based on ground-truth
paragraph analysis and feed it as the input for *Multimodal Diagram
Analysis*. For more user-friendly interaction, recommending $[Outline]$
could inspire users or reduce interaction costs. Thus, we set up another
***Outline Recommendation*** task to make the copilot more versatile and
user-friendly. For accurately evaluating the diagram analysis quality,
besides commonly used ngram-based metrics (e.g.
CIDEr[cider](http://arxiv.org/pdf/2106.15553v1)), we carefully designed a $\rm{CIDEr}^{gpt}$
score to evaluate both n-gram matching and semantic similarity with the
help of ChatGPT.
We benchmark multiple state-of-the-art MLLMs on our dataset, validating
the challenge of our three tasks. Based on the
DocOwl[docowl](None), we perform instruction-tuning on a
combination of training data from three tasks and propose a strong
generalist as the baseline, named . Comprehensive experiments validate
the effectiveness of introducing $[Context]$ and $[Outline]$ as inputs.
Besides, we perform sufficient ablation studies about vision encoding to
provide insights about the model improvement, such as increasing the
image resolution and enhancing the ability to correlate multiple
diagrams.
In summary, our contributions are three-fold: =0.1em
- We build the first high-quality scientific diagram analysis dataset
to support the learning of correlating multiple diagrams, keeping
consistency with the preceding content, and being interactable with
users.
- Simulating real paper-writing scenarios, we carefully design three
multimodal tasks and propose a GPT-based metric, $\rm{CIDEr}^{gpt}$,
to measure the paragraph analysis quality by considering both
detailed n-gram and overall semantic similarity.
- We carefully tune a generalist based on an existing MLLM as the
baseline and perform comprehensive experiments to validate the
effectiveness of multimodal inputs and training strategies.
[^1]:
# Related Work [sec:rela]
**Text-only Paper
Understanding**[S2ORC2020](None), [AnPaperSum2021](http://arxiv.org/pdf/2104.03057v1), [AbuPaperSum2011](http://arxiv.org/pdf/1907.01272v2), [SaierF19](None), [Ammar18](http://arxiv.org/pdf/2301.10140v1), [ShenMW18](http://arxiv.org/pdf/1805.12216v1)
focuses on text and citation graph comprehension in academic papers.
Such models are competent for a number of text-only thesis comprehension
tasks, including information extraction, text classification, paper
summarization, or citation recommendation. Benefiting from the strong
text understanding ability of Large Language Models(LLMs), many
LLM-based tools have been developed as paper-reading assistants, such as
ChatDoc[^1], ChatPDF[^2] and Zhiwen[^3]. However, they are still not
capable of assisting paper writing due to a lack of multimodal abilities
to understand vision information and generate helpful diagram analyses,
which are indispensable in scientific papers.
**Multimodal Document Understanding** aims to develop multimodal
comprehension abilities for images with rich text information, including
charts[chartqa2022](None), [chart2text2022](None), [VisText2023](None),
tables[wikitableqa](http://arxiv.org/pdf/2009.13845v2), [TabFact](http://arxiv.org/pdf/2311.06592v1),
documents[docvqa](None), [mpmqa](None), [deepform](http://arxiv.org/pdf/2303.13839v1), [klc](None) and infographic
images[infovqa](http://arxiv.org/pdf/2104.12756v2), etc. In particular, some
works[SciGraphQA2023](None), [scicap2021](http://arxiv.org/pdf/2403.17784v1), [scicap+2023](None) focus on
understanding scientific figures from papers. Task formats of these work
range from Information Extraction[deepform](http://arxiv.org/pdf/2303.13839v1), [klc](None),
Question Answering[docvqa](None), [chartqa2022](None), [infovqa](http://arxiv.org/pdf/2104.12756v2), Natural
Language Inference[TabFact](http://arxiv.org/pdf/2311.06592v1) to Image
Captioning[chart2text2022](None), [VisText2023](None), [scicap2021](http://arxiv.org/pdf/2403.17784v1), [scicap+2023](None).
Recently, some
works[docowl](None), [ureader](None), [llavar](http://arxiv.org/pdf/2306.17107v2), [qwenvl](None), [feng2023unidoc](http://arxiv.org/pdf/2308.11592v2), [wang2023tgdoc](http://arxiv.org/pdf/2311.13194v2)
have proposed Multimodal Large Language Models with visually-situated
text understanding ability. For example, UReader[ureader](None)
performs instruction tuning on an ensembled dataset covering various
types of images and designs a Shape-adaptive Cropping Module to process
high-resolution document images. However, these MLMMs are still far from
acting as a paper-writing copilot for scientific diagram analysis due to
main two shortages. First, they can only generate a short answer or
description and lack comprehensive diagram analysis abilities. Second,
they are all trained to understand a single image, and thus can’t
correlate context and multiple figures or tables for accurate multimodal
analysis. To empower MLMMs with such abilities, we carefully build a
scientific diagram analysis dataset based on high-quality academic
papers. Fineunted on this dataset, our shows stronger multimodal
diagram analysis abilities and moves a step closer to paper-writing
copilot.
[^1]:
[^2]:
[^3]:
# [sec:data]
Towards a paper-writing copilot, this work aims to build to help
develop multimodal scientific diagram analysis abilities. The dataset
construction and task definition are shown in
[fig:data_process].
## Paper Collection
The arXiv[^1] is an open-access repository of electronic preprints and
postprints, consisting of scientific papers in computer science,
mathematics, physics, etc. Due to the field gap, diagrams, writing, and
analysis styles are quite different across these fields. In this work,
we chose ‘Computer Science’ as the study object. Due to that not all
papers are reviewed by peers before posting, the paper quality in arXiv
varies a lot and low-quality papers may hurt the model’s logical
analysis abilities. Considering PapersWithCode[^2] is a community-driven
platform for learning about state-of-the-art research papers on machine
learning, we think the quality of papers listed in PapersWithCode is
reliable enough. Therefore, with the PapersWithCode API[^3], we collect
48k arXiv ids, ranging from 2012 to 2023, covering 15 categories and
then download their corresponding Latex source files following official
instructions[^4].
## Paper Parse
PDF and Latex are two kinds of commonly used paper formats in
paper-related research. In this work, we choose to parse Latex source
files for two main reasons. Firstly, by comparing the content in the
‘$\backslash$`ref{.}`’ tag and ‘$\backslash$`label{.}`’ tag in Latex
files, it’s easy to accurately align diagrams with paragraph analysis in
papers. Secondly, the Latex format is more natural and general for LLM
to understand or generate diverse texts, including plain text and
mathematical expression, etc. Taking into account these two points,
Latex-style text understanding and generation is more suitable for a
paper-writing copilot. Following S2ORC[S2ORC2020](None), we
first parse Latex source files into XML format and then extract diagrams
and correlate them with captions and paragraphs. More details on text
cleaning can be found in the supplementary material.
Both figures and tables are widely used in scientific academic papers.
By parsing the Latext source file, it’s easy to align figure reference
with figures in image format (e.g.,‘jpg’) by the
‘$\backslash$`includegraphics`’ tag. But for tables, there are only
Latex codes and no image-format files provided. Towards wider
application scenarios, a diagram analysis copilot is necessary to
understand tables in both latex and image formats. To support learning
such abilities, we further collect table images as inputs. Directly
extracting table bounding boxes from PDF-format papers with pdf-parsing
tools (e.g., GROBID[^5]) and then cropping table image is a naive way.
However, due to the diverse layout in scientific papers, table
coordinates given by such tools are not accurate enough. In this work,
we collect accurate table images by following three steps. Firstly, we
revise the Latex source file to ensure that each table will occupy a
separate page after PDF compiling. This operation could greatly reduce
the difficulty of table recognition. Then, for each PDF page containing
a table, we utilize the classical Edge Detection algorithm
Canny[canny1986](http://arxiv.org/pdf/1711.01606v2) to recognize the table bounding box.
Finally, the table image is cropped from the PDF page according to the
table coordinates. It’s worth noting that, to also support the table
captioning task and avoid leaking caption information in the cropped
table image, the content within the ‘$\backslash$`caption{.}`’ tag is
removed during the first step.
During paper writing, for an identical figure or table, even different
co-authors can give analysis from different perspectives. Therefore,
although a paper-writing copilot can give a comprehensive analysis of a
diagram, its analysis can still go against the author’s wishes or be
inconsistent with the preceding texts. To better cater to users’
intentions, we propose to use the ‘outline’ as the intermediate control
signal during diagram analysis. Besides directly generating the
paragraph analysis, the copilot should also be able to analyze the
diagram more accurately following provided key points, namely ‘outline’.
During paper writing, the outline could given by users or generated by
the copilot and revised by users.
For developing such a versatile and controllable copilot, it’s necessary
to construct appropriate training data for outline generation and
analysis generation with outlines. To construct these training samples,
in this work, we utilize the GPT-3.5[^6] to generate corresponding
outlines for each paragraph by in-context learning. More details can be
found in the supplementary material.
## Task Definition
After processing Latex source files as mentioned above, we carefully
organize these data to support the training and test of multiple tasks
designed for the paper-writing copilot, including *Multimodal Diagram
Captioning*, *Multimodal Diagram Analysis*, and *Outline
Recommendation*.
Different from conventional Image Captioning which aims to describe the
attributes and relation between objects, Diagram Captioning requires the
model to accurately summarize the content in the figure or table,
including some concrete mathematical symbols and proper nouns. Besides,
due to partial diagrams being a combination of sub-diagrams, it also
asks the model to correlate multiple images. Further, the table during
paper-writing can be an image or Latex code, which requires the model to
understand different formats of input.
By parsing the Latex source file, it’s easy to get diagram captions by
extracting content from the ‘$\backslash$`caption{.}`’ tag. For
generating captioning more consistent with the paper content and better
mentioning prop nouns, we also provide preceding text as the textual
input, denoted as $[Context]$. To keep the completeness of semantics,
the preceding text is comprised of multiple un-truncated paragraphs
before the first reference of the diagram, with max 512 tokens. Thus,
the input of Multimodal Diagram Captioning is a triplet of
$\langle[Context], [Diagrams], [Inst]\rangle$, where $[Diagrams]$ can
be images of a diagram or Latex code of a table, $[Inst]$ is the
instruction.
Following classical image captioning tasks, we utilize
BELU[papineni2002bleu](http://arxiv.org/pdf/2202.11027v1),
METEOR[banerjee2005meteor](None),
ROUGE-L[lin2004rouge](http://arxiv.org/pdf/2209.06517v2), and
CIDEr[vedantam2015cider](http://arxiv.org/pdf/2106.15553v1) as evaluation metrics. The CIDEr
is valued most because it puts higher weight on rarer tokens (e.g.,
proper nouns), which are more informative.
Much more difficult than writing a caption, Diagram Analysis requires
the model to generate a paragraph analysis according to multiple
diagrams, even a combination of figures and tables. Besides, diagram
analysis is more open-ended than captioning. Different people can
analyze a diagram from quite different perspectives. As a paper-writing
copilot, the diagram analysis should follow users’ intentions as well as
possible, otherwise, it will not improve the writing efficiency.
Therefore, besides providing the preceding text like the Multimodal
Diagram Captioning task to imply the author’s intention, we further
design the ‘outline’ as the explicit control signal, which instructs key
points to discuss with diagrams. Overall, the input of Multimodal
Diagram Analysis is a quartet of
$\langle[Context], [Outline], [Diagrams], [Inst]\rangle$.
Captioning metrics are not quite suitable for paragraph analysis because
they mainly measure the n-gram similarity and neglect overall semantic
matching. To better evaluate the analysis quality, we design a metric to
measure the semantic similarity based on GPT 3.5, namely $F1^{gpt}$.
Concretely, given the predicted analysis and the ground-truth one, we
first prompt the GPT to extract their key points in the list format,
respectively. Then, we prompt GPT to judge whether each pair of
predicted key point and ground-truth key point matched or not. Finally,
we calculate the semantic precision, recall, and F1 score ($F1^{gpt}$)
based on GPT’s judgment. The detailed prompt design for these two steps
can be found in the supplementary material. The $F1^{gpt}$ is good at
measuring semantic similarity but hard to assess the quality of detailed
descriptions, which is rather what CIDEr is good at. For paragraph
analysis, accurately describing key points is more important and we are
more tolerant of the form of expression. Considering $F1^{gpt}$ reflects
the percentage of mentioning key points and CIDEr measures the n-gram
similarity of the whole paragraph. we therefore multiply the CIDEr with
$F1^{gpt}$ as the final evaluation metric $\rm{CIDEr}^{gpt}$, where
$F1^{gpt}$ plays a critical role. As shown in
1, prediction A gets a lower CIDEr
score because it mentions fewer n-grams within ground truth. However, it
describes semantics more accurately and therefore gets a higher
$\rm{CIDEr}^{gpt}$ score.
Towards a user-friendly paper-writing copilot, the ‘outline’ can be
given directly by users or generated by the copilot and then revised by
the user. So recommending outlines accurately is also an important
ability for inspiring users or improving writing efficiency. In this
work, to develop such ability, we also design an Outline Recommendation
task, where the input can be $\langle[Context], [Inst]\rangle$ or
$\langle[Context], [Diagrams], [Inst]\rangle$ and the target is
$[Outline]$. Captioning metrics are used to evaluate this task.
Instructions of these three tasks can be found in the supplementary
material.
## Statistic [sec:statistic]
**Paper Category.** contains 48,688 papers from more than 15
categories, covering almost all popular research directions in ‘Deep
Learning’, especially Computer Vision(CV) and Natural language
Processing(NLP). The detailed category distribution can be found in the
supplementary material.
**Dataset Splits.** 1 shows the split statistic of
*Multimodal Diagram Captioning*, *Multimodal Diagram Analysis* and
*Outline Recommendation*. For each task, there is no paper overlap
across the training, validation and test splits. Both *Multimodal
Diagram Captioning* and *Multimodal Diagram Analysis* cover more than
40k papers and provide sufficient training samples. As for *Outline
Recommendation*, considering that ‘outlines’ are just intermediate
control signals used to interact with users, we don’t expect perfect
quality of generated outlines. Thus only partial papers are processed to
support the training and test of this task.
**Diagram.** As shown in
2, the distribution of diagram
counts varies across different tasks. For *Multimodal Diagram Analysis*,
there are more than 25% samples with multiple diagrams as inputs, much
more than *Multimodal Diagram Captioning*. This indicates that
correlating multiple diagrams is a major challenge for *Multimodal
Diagram Analysis*. Besides,
3 shows the distribution of
diagram types in *Multimodal Diagram Analysis* task. Our dataset is not
limited to a single diagram type but a fusion of figures and tables in
the form of vision or latex code. Especially, for better evaluating
analysis ability on different diagram types, we slightly balance the
diagram type distribution in the test.
The distribution (%) of diagram count across 3 tasks.
**Token Length.**
2 presents the token length statistic
of different textual components in our tasks. The average caption length
is much smaller than the paragraph analysis, indicating the *Multimodal
Diagram Analysis* task requires both more comprehensive diagram
understanding and more detailed description. Besides, the length of the
‘outline’ is far from the ‘analysis’, showing that the input ‘outline’
will not leak too much information about the target analysis but just
point out some key points to discuss.
[^1]:
[^2]:
[^3]:
[^4]:
[^5]:
[^6]:
# mPLUG-PaperOwl [sec:model]
Existing Multimodal Large Language Models(MLLMs)
[mplugowl](http://arxiv.org/pdf/2405.00390v2), [minigpt4](http://arxiv.org/pdf/2402.17510v1), [llava](http://arxiv.org/pdf/2402.11690v1), [qwenvl](None) follow a three-module
framework, consisting of a vision encoder, a vision-to-text connector,
and a Large Language Model as the language decoder. Models with such a
framework are easy to adapt to our multimodal tasks by constructing
image-text interleaved sequences. In this work, we choose one of the
state-of-the-art MLLMs: mPLUG-DocOwl[docowl](None) as the base
model to perform instruction-tuning on our .
## Model Architecture
The overall architecture of PaperOwl is shown in
1.
Following UReader[ureader](None), to better recognize texts in
the image, we utilize a parameter-free Cropping Module to cut a 448x448
image to 4 sub-images of 224x224 resolution and then feed each sub-image
to the following Vision Encoder independently.
The ViT-L/14[vit2021](http://arxiv.org/pdf/2105.15075v2) is utilized as the Vision Encoder,
comprised of 24 transformer layers with 16 attention heads and the
dimension of hidden states set to 1024. For each image $I$ in the
$[Diagrams]$, it’s represented as a sequence of visual features
$V=\{v_{1}, ...,v_{n}\}$ after the Vision Encoder.
The Vision Abstractor is used to align visual features with the language
decoder and aggregate or filter vision semantics. It consists of 6
transformer layers with 8 attention heads and the dimension of hidden
states is set as 1024. With 64 learnable tokens $Q=\{q_1,..q_k\}$ as the
query, the concatenated sequence $[V:Q]$ as the key and value, the
visual features are finally condensed to
$\hat{V}=\{\hat{v}_{1}, ...,\hat{v}_{k}\}$ after cross attention.
The architecture of Language Decoder is the same as
LLaMA-7B[llama](http://arxiv.org/pdf/2402.08075v1). To adapt to vision-and-language tasks
and alleviate catastrophic forgetting, LoRA[hu2022lora](https://openreview.net/forum?id=nZeVKeeFYf9)
is utilized in the LLM with the rank set as 8.
## Model Training
To develop a versatile paper-writing copilot for scientific diagram
understanding, we aim to perform instruction-tuning to enhance an
existing MLLM to be a generalist capable of Multimodal Diagram
Captioning, Multimodal Diagram Analysis, and Outline Recommendation.
Therefore, the training data is a combination of three tasks. Besides,
for *Multimodal Diagram Analysis*, to avoid the model heavily relying on
‘outline’ to guess paragraph analysis, samples removing outlines from
inputs are also added to the training data to strengthen vision
understanding ability. Finally, the total number of instruction-tuning
samples is 702,247.
Following most MLLMs[mplugowl](http://arxiv.org/pdf/2405.00390v2), [minigpt4](http://arxiv.org/pdf/2402.17510v1), [llava](http://arxiv.org/pdf/2402.11690v1), the
Vision Encoder in the PaperOwl is frozen during instruction-tuning to
avoid hurting the strong vision representation ability learned during
large-scale pretraining. The Vision Abstactro is fine-tuned to better
learn how to filter usefully visual diagram information for generating
analysis. The raw parameters of LLaMA-7B are frozen, and only the LoRA
in the Language Decoder is updated to learn the analysis logic of
academic papers. Our model is trained for 10 epochs with the learning
rate set as $1e-4$ and the batch size as 256, costing 64 A100 days.
# Experiments [sec:exper]
## Comparison with SOTA MLLMs.
We first compare the zero-shot performance of existing MLLMs on our
three tasks. As shown in
[tab:sota_mllm],
mPLUG-Owl[mplugowl](http://arxiv.org/pdf/2405.00390v2) achieves the worst performance,
showing the importance of high resolution for our tasks. After
increasing image resolution, mPLUG-Owl2[ye2023mplugowl2](https://arxiv.org/pdf/2311.04257)
and LLaVA 1.5[llava1.5](http://arxiv.org/pdf/2310.19145v1) outperform the other 3 models
trained with multimodal document understanding samples on *Multimodal
Diagram Analysis* task. Besides, UReader[ureader](None), a
model fine-tuned only on document benchmarks, achieves the worst
analysis performance. This validates that existing multimodal document
understanding data is far from energizing the comprehensive diagram
analysis ability of MLLMs and may cause overfitting on question
answering or information extraction benchmarks. However, Owl2, LLaVA 1.5
and Qwen-VL all optimize the whole LLM during instruction-tuning while
UReader and DocOwl only tune the LoRA. Considering both the performance
and training costs, we finally chose DocOwl as our basic model. After
fine-tuning with a combination of three tasks, PaperOwl achieves much
better performance across three tasks.
## Ablation Study
For comprehensively analyzing critical elements for developing a
scientific diagram analysis copilot, we perform sufficient comparison
experiments to validate the effectiveness of $[Context]$ and
$[Outline]$, and present the influence of vision encoding strategies.
For *Multimodal Diagram Captioning* and *Multimodal Diagram Captioning*
tasks, we provide $[Context]$ as auxiliary inputs to implicitly
represent users’ next writing intention and provide some background
information of proper nouns. We first utilize
Owl[mplugowl](http://arxiv.org/pdf/2405.00390v2) as the basic model to study whether using
$[Context]$ during training and testing. All models are just trained on
captioning and analysis tasks and remove $[Outline]$ from inputs. As
shown in [tab:context_abla], for the model
trained without $[Context]$, providing $[Context]$ during inference
could improve the captioning performance (r2 vs r1), showing $[Context]$
is critical for Diagram Captioning. However, adding $[Context]$ only in
testing hurts the analysis performance, indicating the model is hard to
balance the comprehension of preceding texts and multiple diagrams for
paragraph analysis generation. After adding $[Context]$ in training, the
model achieves better performance on both two tasks (r3 vs r2),
validating that for better scientific diagram comprehension, it’s
necessary to incorporate $[Context]$ during both training and inference.
To better align the diagram analysis from a paper-writing copilot with
users’ intention, we propose to introduce $[Outline]$ as explicit
control signals. For validating the effectiveness of $[Outline]$, we
further compare variants of Owl about whether utilizing $[Outline]$
during training and testing. As presented in
[tab:outline_abla], for models
trained with $[Outline]$ as inputs or not, adding $[Outline]$ during
inference could both improve the performance (r2 vs r1, r5 vs r3),
showing ‘Outlines’ is an effective control signal for guiding diagram
analysis. Besides, even adding pseudo $[Outline]$ generated by the model
itself as inputs, the analysis quality could also be improved (r4 vs
r3). This indicates that ‘recommending $[Outline]$ first and then
generating diagram analysis’ may be a better two-step framework, where
the user could also control the copilot by slightly revising the
recommended $[Outline]$. Finally, trained with $[Outline]$ makes a
significant improvement (r5 vs r2), validating it’s essential to teach
the model how to correlate multimodal $[Context]$, $[Outline]$ and
$[Diagrams]$ for scientific diagram analysis.
For vision-and-language tasks, the visual features play a big role in
the final performance. In this section, we compare the influence of
different vision-representing strategies, including image resolution,
whether to fine-tune the Vision Abstractor, and whether to crop the
image. As shown in
[tab:vision_abla], during
instruction-tuning, freezing the Vision Abstractor greatly hurt the
diagram analysis performance (r1 vs r2), validating that fine-tuning the
Vision Abstractor is important for adapting an existing MLLM for
professional diagram understanding. Besides, at the condition of
freezing the Vision Encoder, directly increasing the image resolution
and expanding patch position embeddings by bicubic interpolation doesn’t
bring significant improvement (r3 vs r2), showing that only finetuning
the Vsion Abstractor is not enough to adapt to higher-resolution images.
When equipped with a parameter-free Cropping Module as
UReader[ureader](None) to cut the 448x448 image to 4 sub-images
of 224x224 resolutions, the model achieves significantly better
performance on the diagram captioning task (r4 vs r2), showing that when
the Vision Encoder is frozen, cropping images is a better solution for
leveraging higher-resolution images. But, compared with the diagram
captioning task, the cropping module still brings a weak improvement to
the analysis task. This is mainly because the cropping module results in
too many visual tokens (max 1024 tokens from 16 sub-images) and
therefore greatly increases the difficulty of multimodal understanding
for the language decoder. This shows that how to better encode
high-resolution images and balance multimodal inputs is a major
challenge for the *Multimodal Diagram Analysis* task.
## Qualitative Results
[fig:case] presents a qualitative result
of *Multimodal Diagram Analysis*. With preceding texts as the input and
a simple $[Outline]$ as the control signal, PaperOwl generates a
paragraph analysis following the $[Outline]$ and describes more details
about diagrams. However, PaperOwl still makes some mistakes about the
concrete numbers in the figure, showing the challenge of accurately
understanding details among multiple scientific diagrams. More
qualitative results of *Multimodal Diagram Captioning* and the
comparison of using $[Outline]$ or not can be found in the supplementary
material.
# Conclusion
To enhance the scientific diagram analysis ability of Multimodal LLMs,
we carefully build a multimodal dataset based on high-quality Latex
files of papers by aligning diagrams with captions and paragraph
analysis. Simulating real scenarios of paper writing, we design
Multimodal Diagam Captioning, Multimodal Diagram Analysis, and Outline
Recommendation tasks. To better evaluate the analysis quality, we
propose a GPT-based metric to measure both detailed n-gram matching and
overall semantic similarity. We benchmark multiple state-of-the-art
MLLMs and propose a strong baseline, PaperOwl, by performing instruction
tuning on ensembled training data. Comprehensive experiments validate
the effectiveness of the input of the preceding text and outline.
Finally, our ablation study provides insights into model improvement,
such as increasing image resolution to see more details and how to
balance the multimodal information of context, outline and diagrams.
#
## Text Cleaning [sup:text_clean]
Towards paper-writing copilot, this work focuses on improving the
model’s multimodal diagram analysis abilities and pays little attention
to other writing abilities, such as equation generation or citation
recommendation. Both formulas and paper references are virtually
impossible to infer from diagrams or preceding texts. Therefore, we
further clean paragraph texts by removing such unnecessary information.
Concretely, we first replace all citation tags ‘$\backslash$`cite{.}`’
with a special token ‘``’ to remove citation reference. Besides,
to avoid generating too long equations, paragraphs containing too long
equations ($>40$ chars) in ‘`$.$`’ tags are dropped.
## Outline Construction
Taking into account that the ‘outline’ given by users could be multiple
content-related key points or a highly concise summary, such as ‘the
overall architecture of our model’, we construct two types of outlines
by designing different prompts and in-context demonstrations for
GPT-3.5, as shown in
[tab:simple_summary_prompt]
and
[tab:detailed_summary_prompt].
The category distribution of 48,688 academic papers.
## Statistic
The detailed category distribution of papers in is shown in
1.
## Task Instruction
As shown in
[tab:instruct_templates],
for each task, we apply various instructions to enhance the model’s
instruction-following ability.
# GPT-based Metric
For evaluating the overall semantic similarity of a predicted diagram
analysis and ground-truth one, we design a GPT-based metric, namely
$F1^{gpt}$. We first prompt GPT to extract key points of prediction and
ground truth. Then, for each pair of predicted key point and
ground-truth one, we further prompt GPT to judge whether it matches or
not. Finally, based on GPT’s judgments, we calculate the precision,
recall, and F1 score ($F1^{gpt}$). The prompts used in these two steps
are shown in [tab:gpt_metric]. In particular,
during the keypoint extraction process, we prompt GPT to simultaneously
process both the prediction and the ground truth to better capture their
similarities and differences.
# Experiments
## Influence of Table Format
For developing a copilot capable of analyzing different formats of
diagrams during paper-writing, evaluates table understanding in both
image and Latex formats. As shown in
[tab:table_abla], for writing a
caption to summarize the table content, understanding Latex is much
easier than understanding the image because all data is well-organized
in text. However, the Latex format doesn’t bring significant improvement
for *Multimodal Diagram Anaylysis* and even a decrease in the CIDEr
score. This is because when provided latex code of a table, the model
tends to describe more rare prop nouns or numbers in the table, which
may not be necessary for the discussion and don’t appear in the
ground-truth analysis. This shows that generating diagram analysis is
more challenging at correlating $[Context]$, $[Outline]$, and
$[Diagrams]$, rather than mainly understanding the diagram content.
## More Qualitative Results
[fig:case_table_cap] and
[fig:case_figure_cap] show more
qualitative results of Multimodal Diagram Captioning, including multiple
sub-figures and tables in the image or latex code format. Besides, as
shown in
[fig:case_figure_analysis],
without the $[Outline]$, PaperOwl could generate analysis related to
diagrams but different from the author’s intention. With a concise
$[Outline]$, it generates a much better analysis with minor errors,
showing the necessity of utilizing $[Outline]$ as the control signal.
As mentioned in [sec:statistic], during outline
construction, the average length of the $[Outline]$ is around 36.43% of
the target diagram analysis to avoid leaking too much information about
diagrams. Although we perform such data preprocess to enforce the model
learning to describe more diagram details during training, sometimes
still makes little revisions based on the outline and doesn’t provide
informative analysis about the diagram, as presented in
[fig:case_analysis_bad].
Therefore, it is also a challenge of Multimodal Diagram Analysis to
encourage the model to follow the outline while giving more details by
understanding diagrams.
| |
|:---|
| Please provide the main point of the following paragraph which is from a scientific paper. The main point is the central issue in the paragraph and the format like some items in the outline, and it should be as concise and brief as possible!!!! |
| |
| Due to the paragraph being from a scientific paper, it can be like: the background of some tasks, or the challenge of previous methods, our methods involve A and B modules, etc for the paragraph from the Introduction section; or experiments results on some datasets for the paragraph from Experiments section, or the pipeline of feature extractor, or the detailed design of some network for the paragraph from Method section. |
| |
| Please provide a highly abstract writing purpose for this paragraph like an outline, rather than simply summarizing the content of the paragraph. |
| |
| And please generate the main point with less than 20 words! less than 20 words! less than 20 words!!! |
| |
| There are some examples of "Paragraph" and "Main Points" pairs. The examples are split by "##############################": |
| |
| \############################## |
| Paragraph: |
| \noindent \textbf{Low Reference Dependency} The Kendall and Spearman correlations between automatic metrics and human judgments with the different numbers of references are shown in Fig.\ref{fig:changing_reference_number}. Our EMScore without any references can achieve competitive results, compared with reference-based metrics which need at least 4 or 5 references, such as BLEU_1 and Improved_BERTScore. Besides, our EMScore_ref with only one reference can achieve comparable results with reference-based metrics, which need at least 8 or 9 references, such as CIDEr and BERTScore. The results show that our metric has lower reference dependency, which benefits from the introduction of video content in evaluation. |
| |
| Main Points: |
| Our metric has a lower reference dependency. |
| \############################## |
| Paragraph: |
| Fig.\ref{fig:fine_grained_matching} visualizes how fine-grained EMScore matches the most similar visual elements to the tokens (as the calculation of precision). For the first example, “bubbles” occurs in the 106th frame, “another boy” occurs in the 160th and 187th frames, and compared with other frames, “face paint” appears in a larger proportion in the 4th and 6th frames. For the second example, the visual concept “boy” appears as the main visual element in the 53rd frame, so the token ’boy’ matches this frame instead of 84th\$\sim\$298th frames where multiple visual elements appear. Compared with coarse-grained embedding matching, our fine-grained one can take into account the characteristics of the video, and provide more interpretability for EMScore. |
| |
| Main Points: |
| The visualization results of fine-grained EMScore. |
| \############################## |
| |
| Paragraph: $[Paragraph]$ |
| Main Points: $[Main~Points]$ |
Please use one or several concise
sentences to summarize the main points of the following paragraph which
is from a scientific paper.
And please note that:
(1) Each sentence should strive to express
one main point as succinctly as possible.
(2) Please summarize the most critical
points, preferably no more than 3. And one main point is enough for some
short paragraphs!!!
(3) If there are multiple main points, use
“1. 2. 3." to list them and use “\n" to split them.
There are some wrong formats with prefix
like this: “The article introduces xxx".
“The authors conduct experiments
xxx".
“They introduce xx".
“xxx proposed by the author".
Please directly generate the key points of
the paragraph, and don’t use the prefix like above.
There are some examples of "Paragraph" and
"Main Points" pairs. The examples are split by
"##############################":
##############################
Paragraph:
Video
Captioning\cite{DBLP:journals/tcsv/DengLZWZH22} aims to generate a text
describing the visual content of a given video. Driven by the neural
encoder-decoder paradigm, research in video captioning has made
significant progress \cite{DBLP:conf/iccv/VenugopalanRDMD15,
DBLP:conf/cvpr/ZhangSY0WHZ20}. To make further advances in video
captioning, it is essential to accurately evaluate generated captions.
The most ideal metric is human evaluation while carrying human judgments
is time-consuming and labor-intensive. Thus, various automatic metrics
are applied for video caption evaluation.
Main Points:
Accurately evaluating the generated
descriptions is necessary, and due to the time-consuming and
labor-intensive nature of human judgments, automatic evaluation metrics
are widely used.
##############################
Paragraph:
However, most of the widely applied video
caption metrics like BLEU\cite{DBLP:conf/acl/PapineniRWZ02},
ROUGE\cite{lin-2004-rouge}, CIDEr\cite{7299087}, and
BERTScore\cite{DBLP:conf/iclr/ZhangKWWA20} come from the other tasks,
such as machine translation, text summarization and image captioning,
which may neglect the special characteristic of video captioning and
then limit the development of video captioning. Furthermore, these
automatic metrics require human-labeled references — and thus they are
called reference-based metrics — and such requirements cause three
intrinsic drawbacks: (1) They can not be used when provided videos have
no human-labeled references, which is not uncommon in this age that
millions of reference-free videos are produced online every day. (2)
They may over-penalize the correct captions since references hardly
describe all details of videos due to the one-to-many
nature\cite{DBLP:conf/acl/YiDH20} of captioning task, especially when
the number of references is limited. Fig.\ref{fig:introductionexample}
(a) shows one such example where a candidate caption correctly describes
the “a rock” while reference-based metrics punish this word since
references do not contain it. (3) As pointed by
\cite{rohrbach-etal-2018-object}, these reference-based metrics may
under-penalize the captions with “hallucinating” descriptions since
these metrics only measure similarity to references, and the visual
relevance cannot be fully captured. For example, as shown in
Fig.\ref{fig:introductionexample} (b), due to the word “games” appearing
in the references, some reference-metrics return higher scores for
caption B than caption A, even though “different games” is a
“hallucinating” phrase which is not related to the video.
Main Points:
1. Commonly used video caption metrics
come from other tasks and may not fully capture the unique
characteristics of video captioning.
2. The requirement of reference causes
three intrinsic drawbacks: (1) Cannot be applied in real time. (2)
Over-penalize the correct captions. (3) Under-penalize the captions with
“hallucinating” descriptions.
##############################
Paragraph: [Paragraph]
Main Points: [MainPoints]
| **Multimodal Diagram Captioning** |
|:---|
| Describe $[object]$ concisely. |
| Write a caption of $[object]$. |
| Provide a brief description of $[object]$. |
| Write a short caption for $[object]$. |
| come up with a concise caption that captures the essence of $[object]$. |
| Encapsulate the key information presented in $[object]$ in a brief statement. |
| I need a succinct caption for $[object]$. |
| Please provide a pithy summary of $[object]$ that effectively communicates its message. |
| Can you provide a snappy caption that perfectly encapsulates the message conveyed by $[object]$? |
| Please write a brief but compelling caption that grabs the reader’s attention and draws them into $[object]$. |
| Give a short caption that accurately conveys the main idea of $[object]$. |
| **Multimodal Diagram Anaysis** |
| Based on the previous content and the outline, write a detailed and fluent paragraph analysis. |
| With reference to the preceding content and the given summary, compose a comprehensive and articulate paragraph analysis. |
| Considering the information provided earlier and following the provided outline, produce a detailed and fluent analysis in paragraph form. |
| Drawing from the preceding content and adhering to the outlined structure, write a thorough and coherent paragraph analysis. |
| Based on the previous content and guided by the summary, construct a detailed and fluid analysis in paragraph format. |
| Taking into account the preceding information and following the provided outline, generate a comprehensive and well-developed paragraph analysis. |
| Considering the content discussed earlier and following the provided outline, present a detailed and fluent analysis in paragraph form. |
| With reference to the previous content and the summary, provide a comprehensive and articulate paragraph analysis. |
| Based on the preceding discussion and in accordance with the outlined structure, compose a detailed and coherent paragraph analysis. |
| Considering the information presented earlier and adhering to the provided summary, formulate a thorough and seamless paragraph analysis. |
| **Outline Recommendation** |
| *more than 1 diagrams* |
| Based on the previous content and $[object]$, list some key points that should be covered in the next paragraph. |
| Considering the preceding text with $[object]$, the next paragraph needs to address these essential aspects. |
| Drawing from the preceding text and image information, what crucial points should be focused on in the ensuing paragraph? |
| Given the multimodal information provided earlier, write some key factors for the next paragraph. |
| With reference to the previous discussion and $[object]$, the next paragraph should discuss the following important elements. |
| In light of the preceding content with $[object]$, which significant points should be analyzed in the subsequent paragraph? |
| Based on the previous text and $[object]$, the next paragraph should delve into these core aspects. |
| Considering the text and vision information presented before, give some main factors that should be addressed in the ensuing paragraph. |
| Taking into account the preceding discussion and $[object]$, what primary points should be emphasized in the next paragraph? |
| Given the previous context with $[object]$, generate some key elements that should be discussed in the next paragraph should discuss. |
| *no diagrams* |
| Based on the previous content, list some key points that should be covered in the next paragraph. |
| Considering the preceding text, the next paragraph needs to address these essential aspects. |
| Drawing from the preceding information, what crucial points should be focused on in the ensuing paragraph? |
| Given the information provided earlier, write some key factors for the next paragraph. |
| With reference to the previous discussion, the next paragraph should discuss the following important elements. |
| In light of the preceding content, which significant points should be analyzed in the subsequent paragraph? |
| Based on the previous text, the next paragraph should delve into these core aspects. |
| Considering the information presented before, give some main factors that should be addressed in the ensuing paragraph. |
| Taking into account the preceding discussion, what primary points should be emphasized in the next paragraph? |
| Given the previous context, generate some key elements that should be discussed in the next paragraph should discuss. |
| **Prompt GPT for Extracting Key Points** |
|:---|
| Please summarize the main points of the prediction and ground truth. And strictly with the format: |
| 1\. xxx. |
| 2\. xxx. |
| ... |
| Please ensure that the generated main points comprehensively condense the information of the original text (prediction or ground truth). The number of generated main points can be as many as possible, but no more than 10. |
| |
| If there are parts of the prediction and ground truth that are the same, reflect that in main points, such as some main points of them are the same, and other main points summarize the unique content of themselves. |
| |
| Please note that if there are any overlapping contents between the prediction and ground truth, the main points for these contents should remain consistent. However, for different content of them, please provide separate main points for each. |
| |
| The format is as follows: |
| $\#\#\#\#\#\#\#$ |
| Predicted text: xxx. |
| |
| Ground Truth text: xxx. |
| |
| The main points of the predicted text: |
| 1\. xx |
| 2\. xx |
| ... |
| |
| The main points of the ground truth text: |
| 1\. xx |
| 2\. xx |
| ... |
| $\#\#\#\#\#\#\#$ |
| |
| Now, please generate the main points of the given prediction and ground truth, please strictly use the prompt ’The main points of the xxx’ in the response. |
| |
| Predicted text: $[Prediction]$ |
| Ground Truth text: $[Ground~Truth]$ |
| **Prompt GPT for Judging Semantic Matching** |
| Given a predicted text and a reference text, please judge whether the semantics of the predicted text can match the reference text. |
| And use Yes or No to represent match or mismatch. |
| The format is as follows: |
| Predicted text: xxx. |
| Reference text: xxx. |
| Yes/No |
| ———- |
| Predicted text: $[Predicted~Point]$ |
| Reference text: $[GT~Point]$ |
UniDoc: A Universal Large Multimodal Model for Simultaneous Text Detection, Recognition, Spotting and Understanding
2023-08-19
Hao Feng, Zijian Wang, Jingqun Tang, Jinghui Lu, Wengang Zhou, Houqiang Li, Can Huang
In the era of Large Language Models (LLMs), tremendous strides have been made in the field of multimodal understanding. However, existing advanced algorithms are limited to effectively utilizing the immense representation capabilities and rich world knowledge inherent to these large pre-trained models, and the beneficial connections among tasks within the context of text-rich scenarios have not been sufficiently explored. In this work, we introduce UniDoc, a novel multimodal model equipped with text detection and recognition capabilities, which are deficient in existing approaches. Moreover, UniDoc capitalizes on the beneficial interactions among tasks to enhance the performance of each individual task. To implement UniDoc, we perform unified multimodal instruct tuning on the contributed large-scale instruction following datasets. Quantitative and qualitative experimental results show that UniDoc sets state-of-the-art scores across multiple challenging benchmarks. To the best of our knowledge, this is the first large multimodal model capable of simultaneous text detection, recognition, spotting, and understanding.
Show Paper Content
# Introduction
Nowdays, considerable advancements have been observed in the domain of
Large Language Models (LLMs), such as ChatGPT, [^1]
BLOOM [scao2022bloom](http://arxiv.org/pdf/2106.06683v2), and
LLaMA [touvron2023llama](http://arxiv.org/pdf/2402.08075v1), [touvron2023llama2](http://arxiv.org/pdf/2403.00858v4). These
developments constitute significant strides towards the achievement of
artificial general intelligence (AGI) and exhibit superior zero-shot
proficiency across various linguistic applications. By employing these
LLMs as language decoders, their Multimodal counterparts (LMMs), which
include models like BLIP [li2023blip](http://arxiv.org/pdf/2301.12597v3),
MiniGPT-4 [zhu2023minigpt](http://arxiv.org/pdf/2402.17510v1),
LLaVA [liu2023visual](http://arxiv.org/pdf/2402.11690v1), and
mPLUG-Owl [ye2023mplug](http://arxiv.org/pdf/2405.00390v2), have showcased noteworthy
efficacy in understanding visual and linguistic data.
While these large multimodal models exhibit astonishing zero-shot
multimodal understanding capabilities, their comprehension of text-rich
images remains limited [liu2023hidden](http://arxiv.org/pdf/2305.07895v5). To address this
gap, LLaVAR [zhang2023LLaVAR](zhang2023LLaVAR) proposes incorporating a
text recognition pre-training task to enhance the understanding of
text-rich images. Besides, mPLUG-DocOwl [ye2023mplug](http://arxiv.org/pdf/2405.00390v2)
constructs a large-scale dataset about the document image understanding.
Although their text-rich scene understanding capabilities have shown
notable promise, the vast potential of these pretrained large visual and
language models remains largely unexplored and underutilized, analyzed
next.
Firstly, a salient absence of text detection capabilities is observed in
the current large multimodal models. Since these large visual and
linguistic models are pre-trained on extremely large-scale datasets,
they possess powerful representational capabilities and a wealth of
world knowledge, endowing them with the ability to localize objects/text
in images. Their potential can be further harnessed and explored.
Secondly, the training strategies of advanced methods suffer from data
distribution inconsistencies between the pre-training and fine-tuning
phases [brown2020language](http://arxiv.org/pdf/2112.07522v2), leading to suboptimal
performance. Typically, LLaVAR [zhang2023LLaVAR](zhang2023LLaVAR) solely
conducts text recognition tasks during the pre-training phase and
proceeds with document understanding training in the fine-tuning phase.
Thirdly, text detection and recognition inherently fall under the
umbrella of high-level scene understanding tasks, with the location and
content of the text being associated with scene semantics. Existing LMMs
for text-rich image understanding have not effectively capitalized on
these beneficial connections among OCR
tasks [li2017towards](http://arxiv.org/pdf/1707.03985v1) to enhance the performance on the
individual tasks.
Formally, we introduce UniDoc, a universal large multimodal model for
simultaneous text detection, recognition, spotting, and understanding.
UniDoc aims to establish comprehensive OCR and multimodal understanding
capabilities tailored for text-rich images. We integrate all these tasks
into a cohesive framework driven by natural language instructions for
multimodal understanding, as shown in
Fig. [fig1]. Based on such a unified multimodal
instruct tuning, not only have we endowed our UniDoc with various OCR
capabilities, but the beneficial interactions among these tasks have
also enhanced the performance across individual task. To implement our
UniDoc, we collected and annotated a large-scale instruction following
dataset for this tasks. Extensive quantitative and qualitative
experimental results demonstrate the superior performance of UniDoc and
its strong generalization ability. To our best knowledge, this is the
first large multimodal model capable of simultaneous text detection,
recognition, spotting, and understanding.
In summary, we make three-fold contributions as follows:
- We introduce UniDoc, the first large multimodal model capable of
simultaneous text detection, recognition, spotting, and multimodal
understanding of text-rich images.
- We contribute a large-scale multimodal instruction tuning dataset,
tailored for tasks of text detection, recognition, and spotting
within text-rich images.
- We achieve state-of-the-art performance on multiple publicly
available benchmark datasets. Moreover, we conduct extensive
quantitative and qualitative experiments to validate the
effectiveness of UniDoc.
# Related Work
In this section, we broadly review the recent research on instruction
tuning and multimodal instruction tuning.
## Instruction Tuning
Instruction tuning is an effective technique to align large language
models (LLMs) with human intents. It aims to teach language models to
follow natural language (including prompt, positive or negative
examples, and constraints etc.), to perform better multi-task learning
on training tasks and generalization on unseen tasks. Recently, models
like GPT-3 [brown2020language](http://arxiv.org/pdf/2112.07522v2) and others have
significantly leveraged instructional fine-tuning. Typically, Stanford’s
Alpaca [alpaca](https://github.com/tatsu-lab/stanford_alpaca) employs
self-instruction [wang2022self](http://arxiv.org/pdf/2311.00233v2) to provide a
cost-effective approach to obtain instruction data for fine-tuning
LLaMA. Vicuna [chiang2023vicuna](None) that is a instructional
fine-tuned LLaMA based on dialogues between users and ChatGPT, achieves
performance comparable to ChatGPT [zheng2023judging](https://arxiv.org/pdf/2306.05685).
## Multimodal Instruction Tuning
Recent advancements in the confluence of natural language processing and
computer vision have seen the rise of Large Multimodal Models (LMMs),
which integrate large language models and visual encoders to address
complex tasks involving both text and vision. Prominent works in this
domain include MiniGPT-4 [zhu2023minigpt](http://arxiv.org/pdf/2402.17510v1), which fuses
components from BLIP-2 [li2023blip](http://arxiv.org/pdf/2301.12597v3) and
Vicuna [chiang2023vicuna](None) for modality mapping and adopts
a two-stage fine-tuning strategy. The LLaVA model, on the other hand,
employs a supplementary linear layer to map visual features to the text
space and undergoes additional fine-tuning under multimodal
instructions. In the same vein, mPLUG-Owl from Alibaba’s DAMO Academy
incorporates Flamingo’s Perceiver Resampler structure to facilitate
visual and language modalities alignment. Another significant
contribution is from InstructBLIP, which introduces a novel multimodal
instruction dataset and uses Q-Former and Vicuna as an image encoder and
language model respectively. Finally, X-LLM has introduced a Chinese
multimodal instruction dataset and employs several adapters to map
different modalities to the text space. While these multimodal large
models exhibit promising visual-linguistic understanding capabilities,
their potential are yet to be fully harnessed in specific domains.
To bridge this divide, LLaVAR [zhang2023LLaVAR](zhang2023LLaVAR) puts
forward the inclusion of a text recognition pre-training task, thus
bolstering the comprehension of text-heavy imagery. In addition,
mPLUG-DocOwl [ye2023mplug](http://arxiv.org/pdf/2405.00390v2) has compiled an expansive
dataset designed specifically for the fine-tuning of document
comprehension tasks. Shikra [chen2023shikra](http://arxiv.org/pdf/2306.15195v2) integrates
LMMs with visual grounding ability by recasting detection task as a
prompt-guided seq2seq task. Although these approaches somewhat augment
the multimodal comprehension ability of models in text-rich scenarios,
they fall short in offering a comprehensive ability for text detection,
recognition and spotting. Moreover, they do not effectively harness the
potential reciprocal enhancements that could be achieved by learning
these capabilities in tandem.
# Methodology
## Model Architecture
Fig. [frame] presents an overview of our UniDoc.
Our design follows the paradigm established by
MiniGPT-4 [zhu2023minigpt](http://arxiv.org/pdf/2402.17510v1) and
LLaVA [liu2023visual](http://arxiv.org/pdf/2402.11690v1).
Specifically, given an input *RGB* image
$\bm{I} \in \mathbb{R}^{H\times W\times3}$ and a natural language
instruction $\bm{Q}$, UniDoc first abstracts the visual features from
$\bm{I}$ utilizing CLIP-ViT-L/14 [radford2021learning](http://arxiv.org/pdf/2404.19696v1) as
the visual encoder. Both pre- and post- Transformer layer grid features
are incorporated in our method. The extracted feature map is then
flattened into a sequence of visual embedding sequence and projected
into the embedding dimension of the LLM with a linear layer. The output
sequence $\bm{E}_v$ and then concatenated with embedding sequence
$\bm{E}_l$ tokenized from the language instruction $\bm{Q}$.
Thereafter, the concatenated embedding sequence are fed into
Vicuna [chiang2023vicuna](None), a large language model
originating from the LLaMA [touvron2023llama](http://arxiv.org/pdf/2402.08075v1) and
specifically tuned with the instruction following data.
Vicuna [chiang2023vicuna](None) then generates the response
based on the received visual and text cues. Note that the visual
embedding here can be considered as a soft prompt for LLM.
## Unified Multimodal Instruct Tuning
Our training process is divided into two stages. Both stages employ our
unified multimodal instruct tuning. The first pre-training phase aims to
align the output features from the pre-trained visual encoder with the
feature space of the large language model. During the second fine-tuning
stage, we further optimize the weights of the large language model.
Concretely, during the pre-training phase, we freeze both the
pre-trained large visual and language models, training only the linear
projector to align the visual and language features. Our instruction
following data involves four tasks: text detection, recognition,
spotting, and image captioning. We argue that detection, recognition,
and spotting inherently involve high-level semantic understanding, as
the position and content of text within an image often have a strong
correlation with their surrounding context. The image captioning task
enhances the model’s understanding of natural scene images. All of these
tasks were performed in a natural language instruction following manner.
In the fine-tuning phase, we unfreeze both the large language model and
the projector. Besides the training tasks involved in the pre-training
stage, we further incorporate an additional multimodal understanding
task for text-rich images which requires a more advanced level of
semantic comprehension. The learning of these tasks mutually enhance
each other. Through this unified multi-modal unified instruction
fine-tuning, UniDoc achieves a comprehensive recognition and
understanding capability for text-rich scenarios.
# Dataset Construction
To train the UniDoc, we construct a large-scale multimodal instruction
following dataset. We detail it in the following.
**Pre-training.** The pre-training data consists of two parts: one
portion includes 595K natural scene images along with their captions,
sourced from the CC3M dataset and filtered by
LLaVA [liu2023visual](http://arxiv.org/pdf/2402.11690v1); the other portion comprises 600K
image-text pairs from PowerPoint presentations that we created. The data
were collected from the “Common Crawl" dataset, a vast web corpus
containing publicly available web page. [^2] We opt for PowerPoint files
based on two primary considerations. On one hand, PowerPoint
presentations are characterized by a rich assortment of elements and
their complex combinations, such as various fonts, images, tables, as
shown in Fig. 1. These elements are interrelated, making
them highly conducive to training multimodal understanding tasks in
text-rich scenarios. On the other hand, the text within the slides is
relatively large, making it legible for existing pre-trained visual
models [radford2021learning](http://arxiv.org/pdf/2404.19696v1). In other words, if the text
in an image is too small, it becomes unrecognizable when input into the
model.
To ensure high-quality visuals suitable for our purposes, we conducted
rigorous quality assurance checks, eliminating the noisy data to avoid
any negative impact on training. Specifically, we first applied text
size optimization, excluding images with small-sized text. Then, an
in-house OCR tool accurately extracts the text and box annotations from
each image and we constructed OCR instruction based on them. The
instructions here are categorized into three types: text detection,
recognition, and understanding. Furthermore, we employed GPT-4 to
generate diverse expressions for each type of instruction. The data for
detection, recognition, and spotting each account for one-third of the
total.
**Fine-tuning.** During fine-tuning, we extend the 16K instruction
following data collected from
LAION-5B [schuhmann2022laion](http://arxiv.org/pdf/2312.15897v1) and constructed by
LLaVAR [zhang2023LLaVAR](zhang2023LLaVAR). Initially, we curated this
dataset, employing the same cleansing methodology as used for the
pre-training set. Subsequently, for each image, we constructed OCR
instruction following data, adhering to the approach established during
the pre-training phase. The data for detection, recognition, and
spotting each account for one-third of the total. Furthermore, we
further incorporated 150K OCR instruction data as the pre-training
stage, in which detection, recognition, and spotting each constitute
one-third of the total.
# Experiments
## Training Details
To implement UniDoc, we employed a one-cycle learning rate
policy [smith2019super](http://arxiv.org/pdf/1708.07120v3). During the pre-training phase,
the maximum learning rate was set to 1e-3, and for the fine-tuning
phase, it was reduced to 1e-5. Moreover, the batch size was 128 for the
pre-training and 32 for the fine-tuning phase, respectively. The
AdamW [loshchilov2017decoupled](http://arxiv.org/pdf/2311.11446v2) optimizer was chosen for
weight updates. Both the pre-training and fine-tuning phases were
executed using eight A100 GPUs. Each of these phases consisted of a
single epoch. In this study, for both the training and inference phases,
the default input image resolution is set at
224$\times$``{=html}224. It is noteworthy that larger input
resolutions are almost certain to yield better results due to the
presence of more discernible
text [zhang2023LLaVAR](zhang2023LLaVAR), [ye2023mplug-doc](http://arxiv.org/pdf/2403.14252v1). Unless otherwise
specified, the performance reported in this study is based on image
inputs with an input resolution of 224$\times$``{=html}224.
| Method | Detection | | |
|:----------:|:---------:|:---------:|:-----:|
| 2-4 | CTW1500 | TotalText | TD500 |
| **UniDoc** | 38.27 | 12.60 | 17.36 |
Quantitative performance of UniDoc (F-score) on several scene text
detection benchmark datasets. Here the input instruction is “Output all
the text locations in this photo".
## Evaluation Metrics
We evaluate our UniDoc in a series of text-rich scenes from three
perspectives (*i.e.,* detection, recognition, and multimodal
understanding). For the task of text detection, we employed the F-score
metric. For text recognition and visual question answering tasks, we
adopted the accuracy metric, where a response generated by the model is
considered correct if it contains the string present in the ground
truth [liu2023hidden](http://arxiv.org/pdf/2305.07895v5). In this paper, F-score and
accuracy are respectively denoted as $\mathcal{F}$ and $\mathcal{A}$.
| Training Task | | Detection | Recognition | Understanding |
|:--:|:--:|:--:|:--:|:--:|
| 1-2 (rl)3-3 (rl)4-4 (rl)5-5 Pre-train | Fine-tune | $\mathcal{F}$ | $\mathcal{A}$ | $\mathcal{A}$ |
| | | 0.00 | 20.01 | 35.78 |
| | | 0.00 | 84.13 | **41.28** |
| | | 27.89 | 88.93 | 40.46 |
| | | **38.27** | **90.60** | 40.72 |
Ablation studies about the training tasking settings. The “" indicates
that the corresponding training phase including the detection,
recognition, and spotting task.
| Experiment | Setting | Detection | Recognition | Understanding |
|:-------------------:|:-----------:|:-------------:|:-------------:|:-------------:|
| 3-3 (rl)4-4 (rl)5-5 | | $\mathcal{F}$ | $\mathcal{A}$ | $\mathcal{A}$ |
| index tokens | w/ | 31.28 | \- | \- |
| | w/o | **38.27** | \- | \- |
| instruction type | detection | 38.27 | \- | \- |
| | spotting | **43.33** | \- | \- |
| instruction type | recognition | \- | 90.60 | \- |
| | spotting | \- | **91.30** | \- |
Ablation studies about variations in detection task configurations, and
the impacts of the instruction type on text detection and recognition
during inference.
## Comparison with Other LMMs
We perform an exhaustive evaluation of publicly accessible large
multimodal models (LMMs) and our UniDoc, assessing their efficacy across
various benchmarks. In the following, we compare and analyze the
experimental results.
**Text Detection.** Compared with the existing large multimodal models
(LLMs), a unique capability of our UniDoc is its text detection ability.
This stems from our approach of incorporating text detection as part of
the unified multimodal instruction tuning. In
Table 2, we present the quantitative
performance of our method on multiple scene text detection datasets,
including CTW1500 [liu2019curved](http://arxiv.org/pdf/1712.02170v1),
TotalText [ch2017total](http://arxiv.org/pdf/1710.10400v1), and
TD500 [yao2012detecting](http://arxiv.org/pdf/1703.01086v3). Moreover, as illustrated in
Fig. [fig_spotting], we provide examples
showcasing UniDoc’s text detection performance on the CTW1500
dataset [liu2019curved](http://arxiv.org/pdf/1712.02170v1). It can be seen that the text is
consistently detected in these images. Notably, the words in these
images are located irregularly instead of in a straight horizontal line,
and our training phase also does not involve the text detection tasks
for such scene images. These findings validate our learning strategy and
underscore the substantial generalization ability of LLMs.
Quantitative comparison on multiple recognition datasets
based on the recognition instructions and spotting instructions. The
x-axis represents the
datasets. Spotting instruction consistently performs
better.
**Text Recognition.** Furthermore, we extend our evaluation to assess
the text recognition capacity of UniDoc. To commence, as shown in
Table [tab:text_reco], UniDoc achieves a
series of state-of-the-art scores across numerous benchmark datasets for
text recognition. It is noteworthy that these datasets encompass a
diverse array of text-rich images, including document text, artistic
text, handwritten text, scene text, and more. Moreover, as depicted in
Fig. [fig_spotting] and
Fig. [fig_recognize], we showcase
recognition results of UniDoc on CTW1500 [liu2019curved](http://arxiv.org/pdf/1712.02170v1),
WordArt [xie2022toward](http://arxiv.org/pdf/1812.05824v3) and
TotalText [ch2017total](http://arxiv.org/pdf/1710.10400v1) dataset. Although these images
involve varying fonts, styles, image blurriness, and non-horizontal text
distributions, UniDoc consistently manifests a remarkable ability to
accurately recognize the embedded text within them.
**Multimodal Understanding.** We conduct both quantitative and
qualitative assessments of UniDoc’s multimodal understanding
performance. Specifically, as presented in
Table [tab:text_reco_vqa_kie_res],
UniDoc achieves state-of-the-art and comparable performance on several
benchmark datasets. Besides, as illustrated in the
Fig. [fig_understanding], we provide
examples of multimodal question-answering focused on text-based
scenarios. It can be seen that UniDoc effectively integrates the visual
cues from the input image and the textual cues from both the image and
instructions. Leveraging the inherent world knowledge of the large
language model (LLM), it then engages in coherent reasoning to generate
corresponding responses.
## Ablation Studies
In this section, we conduct ablation studies to validate the efficacy of
core settings and components in our UniDoc. In all experiments, for the
tasks of text detection, recognition, and multimodal understanding, we
report the performance on the CTW1500 [liu2019curved](http://arxiv.org/pdf/1712.02170v1),
IIIT5K [mishra2012scene](http://arxiv.org/pdf/1907.09705v1), and
TextVQA [singh2019towards](http://arxiv.org/pdf/1811.11903v1) benchamrk datasets,
respectively.
**Impact of Unified Multimodal Instruct Tuning.** During the
pre-training phase, the instruction-following data we trained
encompasses text detection, recognition, and spotting tasks. In the
fine-tuning phase, the instruction-following data was further augmented
with tasks concerning multimodal understanding. we investigate the
impact of learning these tasks (ı.e., text detection, recognition, and
spotting) on the final performance. As illustrated in
Table 3, incorporating the learning of them
in individual phases led to enhancements not only in detection and
recognition performance, but also in multimodal understanding.
Furthermore, incorporating these tasks in both stages yielded the best
performance. These results demonstrate that there exists a beneficial
interplay and synergy among these tasks. We argue that such a multi-task
learning strategy not only endows Large Multimodal Models (LMMs) with
comprehensive capabilities, but also bolsters their inherent abilities.
**Impact of the Formulation of the Detection Task.** In our default
setting, we directly predict the integer coordinates of the text region
bounding boxes. Given that our input images are all of the size
224$\times$``{=html}224, these coordinates are normalized to the
range \[0, 223\]. An alternative approach is to set up an additional 224
tokens to represent both the horizontal and vertical coordinates in the
range \[0, 223\] [chen2021pix2seq](http://arxiv.org/pdf/2305.18279v1). As shown in
Table 4, in terms of text detection
capabilities, the introduction of additional positional index tokens did
not yield a performance gain.
**Impact of Instruction Template Type.** In our UniDoc, the detection
results can originate from either the detection or the spotting
instructions. Similarly, our recognition outcomes can be sourced from
either the recognition or the spotting instructions. Consequently, we
evaluate the impact of using different types of instructions on the
performance of detection and recognition. As shown in
Table 4, the text detection and recognition
performance based on the spotting instruction works better. This is
likely because in autoregressive generation, spotting instruction
template makes model provide explicit location information in its
responses, enhancing the recognition performance. The same applies to
detection tasks. The two tasks are mutually complementary. In
Fig. 2, we perform quantitative comparisons on
a broader range of recognition benchmarks. Besides, as shown in
Fig. 3, we further provide a case to
illustrate this finding.
# Conclusion
In this work, we introduce UniDoc, a universal large multimodal model
for simultaneous text detection, recognition, spotting, and
understanding. Through our proposed unified multimodal instruct tuning,
UniDoc effectively leverages the beneficial interactions among
text-based tasks, not only addressing the shortcomings of existing large
multimodal models, but also enhancing their original capabilities. To
implement UniDoc, we contribute a large-scale multimodal instruction
following dataset. Experiments show that our UniDoc sets
state-of-the-art scores across multiple benchmarks. Besides, we perform
extensive studies to validate its effectiveness. Currently, UniDoc is
unable to extract fine-grained visual features for detection and
recognition, and the resolution of input images remains a limitation. In
the future, we will consider addressing these issues.
[^1]: https://openai.com/blog/chatgpt
[^2]: https://commoncrawl.org/
mPLUG-DocOwl: Modularized Multimodal Large Language Model for Document Understanding
2023-07-04
Jiabo Ye, Anwen Hu, Haiyang Xu, Qinghao Ye, Ming Yan, Yuhao Dan, Chenlin Zhao, Guohai Xu, Chenliang Li, Junfeng Tian, Qian Qi, Ji Zhang, Fei Huang
Document understanding refers to automatically extract, analyze and comprehend information from various types of digital documents, such as a web page. Existing Multi-model Large Language Models (MLLMs), including mPLUG-Owl, have demonstrated promising zero-shot capabilities in shallow OCR-free text recognition, indicating their potential for OCR-free document understanding. Nevertheless, without in-domain training, these models tend to ignore fine-grained OCR features, such as sophisticated tables or large blocks of text, which are essential for OCR-free document understanding. In this paper, we propose mPLUG-DocOwl based on mPLUG-Owl for OCR-free document understanding. Specifically, we first construct a instruction tuning dataset featuring a wide range of visual-text understanding tasks. Then, we strengthen the OCR-free document understanding ability by jointly train the model on language-only, general vision-and-language, and document instruction tuning dataset with our unified instruction tuning strategy. We also build an OCR-free document instruction understanding evaluation set LLMDoc to better compare models' capabilities on instruct compliance and document understanding. Experimental results show that our model outperforms existing multi-modal models, demonstrating its strong ability of document understanding. Besides, without specific fine-tuning, mPLUG-DocOwl generalizes well on various downstream tasks. Our code, models, training data and evaluation set are available at https://github.com/X-PLUG/mPLUG-DocOwl.
Show Paper Content
# Introduction
Large language models (LLMs) like ChatGPT [chatgpt](https://openai.com/blog/chatgpt),
BLOOM [bloom](None), and LLaMA [llama](http://arxiv.org/pdf/2402.08075v1) have
undergone rapid development to enable the realization of general
artificial intelligence, boasting impressive zero-shot capabilities
across diverse linguistic applications. With the LLM as the language
decoder, Multimodal large language models (MLLMs) such as
MiniGPT-4 [minigpt4](http://arxiv.org/pdf/2402.17510v1), LLaVA [llava](http://arxiv.org/pdf/2402.11690v1), and
mPLUG-Owl [mplugowl](http://arxiv.org/pdf/2405.00390v2) have demonstrated remarkable
zero-shot performance in various open-ended vision-and-language tasks.
These models are trained to align text and images during the
pre-training phase, and then to promote diverse abilities during the
instruction tuning phase. Interestingly, these MLLMs exhibit superficial
OCR-free text recognition abilities without explicit training on visual
text understanding datasets [mplugowl](http://arxiv.org/pdf/2405.00390v2), [llmocr](http://arxiv.org/pdf/2305.07895v5).
Nevertheless, due to lacking specific training, these models still face
the challenge of comprehending intricate relationships between visual
text and objects in diverse types of images, such as charts, documents
and webpages.
By performing unified instruction tuning for Document Understanding upon
the mPLUG-Owl [mplugowl](http://arxiv.org/pdf/2405.00390v2), we further propose a
modularized MLLM [mplug](None), [mplug2](None), namely mPLUG-DocOwl.
Our approach utilizes a modularized framework similar to mPLUG-Owl
[mplugowl](http://arxiv.org/pdf/2405.00390v2), which incorporates a visual abstractor
module to link a pre-trained LLM with a visual knowledge module,
achieving the alignment of text and images. To enhance diverse document
understanding capabilities, we reorganize various downstream document
understanding tasks in the same form of instructions. To maintain
general uni/multi-modal abilities, we also include language-only and
general vision-and-language instruction datasets used by mPLUG-Owl to
train the mPLUG-DocOwl. During training, both the visual knowledge
module and LLM decoder are frozen, only the visual abstractor and the
Low-Rank Adaption (LoRA) [lora](https://openreview.net/forum?id=nZeVKeeFYf9) in LLM are fine-tuned.
mPLUG-DocOwl achieves ocr-free state-of-the-art performance on multiple
commonly used document understanding datasets. Furthermore, our
experiments on a carefully-built document instruction understanding
evaluation set LLMDoc shows that mPLUG-DocOwl achieves significantly
better visual text understanding performance on various domains than
existing MLMMs.
Our main contributions can be highlighted as follows:
- We propose a modularized MLLM, **mPLUG-DocOwl**, which is the first
one to balance language-only, general vision-and-language, and
document understanding based on unified instruction tuning.
- We carefully construct an instruction understanding test set with
human evaluation, dubbed **LLMDoc**, to assess diverse document
understanding capabilities.
- Empirical results demonstrate that our mPLUG-DocOwl surpasses
existing methods on ocr-free document understanding, including
multiple standard benchmarks and LLMDoc.
# Related Work
## Visual Text Understanding
There are two types of models for understanding images that contain rich
textual information. The first kind of
approaches [layoutlm](https://doi.org/10.1145/3394486.3403172), [layoutlmv3](None), [qctextcap](http://arxiv.org/pdf/2302.02124v2), [udop](http://arxiv.org/pdf/2212.02623v3), [tap](None)
utilize off-the-shelf OCR models or APIs to recognize text from images,
and then design pretraining tasks to facilitate cross-modality alignment
between visual and textual inputs. On the other hand, end-to-end
approaches [dessurt](http://arxiv.org/pdf/2203.16618v3), [donut](http://arxiv.org/pdf/2305.09520v1), [pix2struct](None) utilize a
high-resolution image encoder to learn text recognition during the
pretraining stage. Both two types of models rely on specific finetuning
on different downstream datasets and can’t achieve open-domain
instruction understanding performance like Multimodal Large Language
Models.
## Multimodal Large Language Model
Large Language Models (LLMs) have demonstrated impressive zero-shot
abilities across various open-ended tasks. Recent research has also
explored the application of LLMs for multi-modal generation, utilizing
two different paradigms: systematic collaboration and end-to-end trained
models. Systematic collaboration approaches, such as Visual ChatGPT
[visualchatgpt](None) and MM-REACT [mmreact](None),
leverage various vision experts or tools to express visual information
with text descriptions. Subsequently, LLMs, such as ChatGPT
[chatgpt](https://openai.com/blog/chatgpt), can act as agents and select appropriate
experts and tools for visual understanding. Finally, LLMs would
summarize the output of these experts to answer user queries. On the
other hand, some approaches, such as MiniGPT-4
[minigpt4](http://arxiv.org/pdf/2402.17510v1), LLaVA [llava](http://arxiv.org/pdf/2402.11690v1), and mPLUG-Owl
[mplugowl](http://arxiv.org/pdf/2405.00390v2), leverage LLMs to build unified models for
multi-modality with limited connected parameters. These methods show
superficial OCR-free text recognition abilities under the zero-shot
setting. However, for complicated document understanding, due to lacking
in-domain training, they encounter challenges in handling diverse image
types, recognizing rich texts and comprehending relationships between
visual semantic and text information. In this work, through unified
instruction tuning, mPLUG-DocOwl achieves much better document
understanding performance and maintains general uni/multi-modal
abilities.
# Conclusion
In this work, we infuse diverse ocr-free document understanding
capabilities into mPLUG-Owl by incorporating document understanding data
into instruction finetuning. Experiment results demonstrate that our
mPLUG-DocOwl achieves comparable or even better performance than
existing OCR-free methods. Besides, benefiting from language-only and
general vision-and-language instruction tuning, mPLUG-DocOwl can better
comprehend user instructions and intentions, enabling more complex
interactions. Moreover, human evaluation on LLMDoc reveals that
mPLUG-DocOwl still struggles with document-related commonsense
reasoning, mathematical calculations, and creative generation. This
provides valuable insights about developing stronger document
understanding abilities with the LLM in the future.
[^1]: Equal contribution
[^2]: Corresponding author
# Experiment
## LLMDoc
Existing benchmarks are hard to evaluate the open-ended instruction
understanding results given by MLMMs. For better compare the instruction
understanding performance in the document domain, we further construct a
test set with human evaluation, namely .
#### Data Collection
To comprehensively evaluate the model’s abilities, we consider five
scenarios to construct our evaluation dataset, including table (TabFact
[TabFact](http://arxiv.org/pdf/2311.06592v1)), chart (ChartQA [chartqa](None)),
document (DocVQA [docvqa](None)), natural image (TextVQA
[textvqa](None)) and webpage (VisualMRC
[visualmrc](http://arxiv.org/pdf/2101.11272v2)). Specifically, for each dataset, we sample
20 images from the test split. For 10 of these images, we adopt a raw
question as the instruction. While for the other 10, we ask annotators
to write instructions requiring stronger capabilities like
summarization, inference, and calculation. In total, we obtain 100 test
samples.
#### Human Evaluation
Following the rating criteria proposed in
Self-Instruct [self-instruct](https://doi.org/10.48550/arXiv.2212.10560), we perform the human
evaluation to score the model’s responses, where A \> B \> C \> D and A
represents ‘correct and satisfying response’, B means ‘acceptable
response with minor imperfections’, C refers to ‘response to the
instruction but has significant errors’ and D means ‘irrelevant or
invalid response’.
r0.5
We compare with other popular mult-modal large language models,
including mPLUG-Owl [mplugowl](http://arxiv.org/pdf/2405.00390v2) and
Mini-GPT4 [minigpt4](http://arxiv.org/pdf/2402.17510v1), on . As shown in
[fig:llm_comp], achieves significantly
better performance, with 37 responses being scored as “A”, demonstrating
the stronger understanding ability of in diverse document scenarios.
Besides, it’s worth noting that all models have some responses scored as
“C” or “D”, showing that instruction understanding performance in the
document domain is still far from promising and needs more endeavor.
## Benchmark Evaluation
Besides human evaluation, we also compare our with ocr-free
state-of-the-art document understanding models on public datasets.
[tab:due_eval] shows the comparison
with Dessurt [dessurt](http://arxiv.org/pdf/2203.16618v3), Donut [donut](http://arxiv.org/pdf/2305.09520v1)
and Pix2Struct [pix2struct](None) on
DUE-Benchmark [due](None), which mainly requires the text
recognition and layout understanding abilities on documents and tables.
Besides, [tab:other_eval] presents the
evaluation on the chart, natural image and webpage datasets, which ask
stronger ability to relate visual semantics and text information.
Without finetuning on each dataset, our achieves comparable or even
better performance.
## Qualitative Analysis
#### Benchmark Results.
Qualitative results on different types of images are shown in
1. Crucial regions and corresponding
responses are annotated with the same colors. Case (a) shows that can
accurately find the answer from a webpage screenshot with complex
contents. Case (b) shows that is even able to understand hand-drawn
tables and correctly recognize handwritten fonts. In case (c), can
summarize key points from a chart. It successfully understands that the
table is about internet usage and infers that “Never” means “Never used
internet”. However, it also generates illusory outputs, such as "in the
United States". The question in case (d) requires the model to
understand the “Result” column, compare the points and return the date
with the best results. Case (e) demonstrates that our model is capable
of processing scanned documents and distinguishing company and person
names. Case (f) shows that can not only recognize small and blurry text
but also perform simple calculations following the user intent.
#### Results
2 and
3 present the comparison between
and Mini-GPT4 on .
2 (a) requires models to convert
a table into JSON format. Our correctly understands the instruction and
return a string in JSON format, but misses the last row. Mini-GPT4 fails
to comprehend the instruction and doesn’t understand the content within
the table. In
2 (b), both and Mini-GPT4
correctly recognize the name of the shop. However, Mini-GPT4 overlooks a
smaller sign indicating clothes in this shop are medical uniforms. As
for chart understanding in
3 (c), Mini-GPT4 gives a wrong
answer and redundant response, while our gives a concise and correct
response. In
3 (d), Bernadette’s actual
purpose is to confirm with Suzy if she would like to have the copy sent
overnight. This not only requires the model to accurately recognize the
text, but also to understand the relationships between involved persons.
recognizes the phrase "request a copy of chapter," but misunderstands
the subject and object. Mini-GPT4 only comprehends that this image is a
mail scenario and provides a vague and hallucinatory response. In
3 (e), gives a correct summary of
the two latest news but Mini-GPT4 generates news irrelevant to the
webpage screenshot.
The contains many challenging instruction understanding cases in the
document domain.
4 and
5 show some wrong responses given by
. In 4 (a), only takes note of the three
names in the picture, but ignores the fact that the user itself is also
a speaker. In 4 (b), fails to perform multi-step
calculations on multiple elements in the image. In
5 (c), the model can understand the
scene and the text in it, but fantasizes about non-existent characters.
In 5 (d), fails to understand the
instruction for writing news and only read the texts in the tablet.
Instruction tuning unlocks the superior capability of Large Language Models (LLM) to interact with humans. Furthermore, recent instruction-following datasets include images as visual inputs, collecting responses for image-based instructions. However, visual instruction-tuned models cannot comprehend textual details within images well. This work enhances the current visual instruction tuning pipeline with text-rich images (e.g., movie posters, book covers, etc.). Specifically, we first use publicly available OCR tools to collect results on 422K text-rich images from the LAION dataset. Moreover, we prompt text-only GPT-4 with recognized texts and image captions to generate 16K conversations, each containing question-answer pairs for text-rich images. By combining our collected data with previous multi-modal instruction-following data, our model, LLaVAR, substantially improves the LLaVA model's capability on text-based VQA datasets (up to 20% accuracy improvement) while achieving an accuracy of 91.42% on ScienceQA. The GPT-4-based instruction-following evaluation also demonstrates the improvement of our model on both natural images and text-rich images. Through qualitative analysis, LLaVAR shows promising interaction (e.g., reasoning, writing, and elaboration) skills with humans based on the latest real-world online content that combines text and images. We make our code/data/models publicly available at https://llavar.github.io/.
Show Paper Content
# Introduction
Instruction tuning
[ouyang2022training](https://arxiv.org/pdf/2203.02155), [chung2022scaling](https://arxiv.org/pdf/2210.11416) improves
generalization to unseen tasks by formulating various tasks into
instructions. Such open-ended question-answering capability fosters the
recent chatbot boom since ChatGPT. Recently, visual instruction-tuned
models [liu2023visual](https://arxiv.org/pdf/2304.08485), [li2023otter](http://arxiv.org/pdf/2311.00233v2), [Li2023LargeMM](http://arxiv.org/pdf/2306.14895v1)
further augment conversation agents with visual encoders such as
CLIP-ViT [dosovitskiy2020image](https://arxiv.org/pdf/2010.11929), [radford2021learning](https://arxiv.org/pdf/2103.00020),
enabling human-agent interaction based on images. However, possibly due
to the dominance of natural images in training data (e.g., Conceptual
Captions [changpinyo2021conceptual](https://arxiv.org/pdf/2102.08981) and COCO
[lin2015microsoft](https://arxiv.org/pdf/1405.0312)), they struggle with understanding
texts within images [liu2023hidden](https://arxiv.org/pdf/2305.07895). However, textual
understanding is integral to visual perception in everyday life.
Fortunately, tools such as Optical Character Recognition (OCR,
`\citealp{156468}`{=latex}) allow us to recognize text in images. One
naive way to utilize this is to add recognized texts to the input of
visual instruction-tuned models [gao2023llamaadapterv2](https://arxiv.org/pdf/2304.15010).
However, such approach significantly increases the computation (longer
context lengths), and might not fully leverage the encoding capability
of visual encoders. To this end, we propose to enhance the end-to-end
visual instruction-tuned model by collecting instruction-following data
that require understanding texts within images.
Specifically, we first collect 422K noisy instruction-following data
using text-rich[^2] images by combining manually written instructions
(e.g., “Identify any text visible in the provided image.”) and the OCR
results. Such large-scale noisy-aligned data effectively improve feature
alignment between visual features and the language decoder. Furthermore,
we prompt text-only GPT-4 [openai2023gpt4](https://arxiv.org/pdf/2303.08774) with OCR
results and image captions to generate 16K conversations, where each
conversation can be multiple turns of question & answer pairs, as
high-quality instruction-following examples. This process requires GPT-4
to de-noise the OCR results and develop specific questions to create
complex instructions based on the input (Figure
[fig:highquality]).
To evaluate the effectiveness of the collected data, we use noisy and
high-quality examples to augment the pretraining and fine-tuning stages
of LLaVA [liu2023visual](https://arxiv.org/pdf/2304.08485) accordingly. We name our model
**LLaVAR**, signifying the LLaVA (Large Language and Vision Assistant)
that can **R**ead. Compared to the original LLaVA, we also conducted
experiments scaling the input resolution from $224^2$ to $336^2$ to
better encode small textual details. Empirically, we report the results
on four text-based VQA datasets following the evaluation protocol from
[liu2023hidden](https://arxiv.org/pdf/2305.07895). Moreover, we apply GPT-4-based
instruction-following evaluation to 30 natural images from COCO
[lin2015microsoft](https://arxiv.org/pdf/1405.0312), [liu2023visual](https://arxiv.org/pdf/2304.08485) and 50 text-rich
images from LAION [schuhmann2022laion](http://arxiv.org/pdf/2312.15897v1). We also provide
qualitative analysis (e.g., on posters, website screenshots, and tweets)
to test more complex instruction-following skills.
To sum up, our contributions are as follows:
- We collect 422K noisy instruction-following data and 16K
high-quality instruction-following data. Both are shown to be
effective in augmenting visual instruction tuning.
- Our model, LLaVAR, significantly enhances text understanding within
images while slightly improving the model’s performance on natural
images.
- The enhanced capability enables our model to provide end-to-end
interactions based on various forms of online content that combine
text and images.
- We open source the training and evaluation data together with the
model checkpoints.
# Related Work
#### Instruction Tuning
Following natural language instructions is the key capability for an
agent to interact with real-world users. Instruction tuning starts from
collecting human-preferred feedback for human written instructions
[ouyang2022training](https://arxiv.org/pdf/2203.02155) or formulating multi-task training
in a multi-task instruction-following manner
[chung2022scaling](https://arxiv.org/pdf/2210.11416), [wang2022supernaturalinstructions](https://arxiv.org/pdf/2204.07705).
However, large, capable instruction-tuned models are usually
closed-sourced and serve as commercial APIs only. Recently, Alpaca
[wang2022selfinstruct](https://arxiv.org/pdf/2212.10560), [alpaca](https://github.com/tatsu-lab/stanford_alpaca), Vicuna
[vicuna2023](https://lmsys.org/blog/2023-03-30-vicuna/), and Baize [xu2023baize](https://arxiv.org/pdf/2304.01196)
start the trend of generating high-quality instruction-following data
based on LLMs such as GPT-3.5 / ChatGPT / GPT-4 and finetuning the open
source LLaMA model [touvron2023llama](https://arxiv.org/pdf/2302.13971). However,
evaluating the ability to follow instructions remains a challenge. While
GPT-4 has demonstrated superior evaluation capabilities
[liu2023geval](https://arxiv.org/pdf/2303.16634), there are still a number of concerns,
such as bias toward response length [xu2023baize](https://arxiv.org/pdf/2304.01196) and
lack of robustness to the order of examples
[wang2023large](https://arxiv.org/pdf/2305.17926). Following
[vicuna2023](https://lmsys.org/blog/2023-03-30-vicuna/), [liu2023visual](https://arxiv.org/pdf/2304.08485), [dubois2023alpacafarm](https://arxiv.org/pdf/2305.14387), we
use GPT-4-based instruction-following evaluation in this work.
#### Multimodal Instruction Tuning
Recently, instruction tuning has been expanded to the multimodal
setting, including image, video
[zhang2023video](http://arxiv.org/pdf/2311.12919v2), [maaz2023videochatgpt](https://arxiv.org/pdf/2306.05424), and audio
[Huang2023AudioGPTUA](http://arxiv.org/pdf/2108.04325v2), [zhang2023speechgpt](https://arxiv.org/pdf/2305.11000). For
image-based instruction tuning, MiniGPT-4
[zhu2023minigpt4](https://arxiv.org/pdf/2304.10592) employs ChatGPT to curate and improve
detailed captions for high-quality instruction-following data. LLaVA
[liu2023visual](https://arxiv.org/pdf/2304.08485) generates multimodal
instruction-following data by prompting text-only GPT-4 with captions
and object’s bounding boxes. LLaMA-Adapter
[zhang2023llamaadapter](https://arxiv.org/pdf/2303.16199), [gao2023llamaadapterv2](https://arxiv.org/pdf/2304.15010) uses COCO
data for text-image feature alignment and utilizes textual data only for
instruction tuning. mPLUG-owl [ye2023mplugowl](https://arxiv.org/pdf/2304.14178) combines
more than 1000M image-text pairs for pretraining and a 400K mixture of
text-only/multimodal instruction-following data for finetuning. However,
according to [liu2023hidden](https://arxiv.org/pdf/2305.07895), most of these models
struggle to accomplish tasks requiring OCR capability. InstructBLIP
[dai2023instructblip](https://arxiv.org/pdf/2305.06500) transforms 13 vision-language
tasks (including OCR-VQA [mishra2019ocrvqa](http://arxiv.org/pdf/2010.02582v1)) into the
instruction-following format for instruction tuning. Cream
[kim2023cream](https://arxiv.org/pdf/2305.15080) applies multi-task learning that includes
predicting masked texts in images. A more comprehensive survey can be
found in [li2023multimodal](li2023multimodal). In this work, we select
LLaVA as our baseline, which is the most data-efficient and powerful
model, and demonstrate the effectiveness of our proposed pipeline.
# Data Collection
Starting from the LAION-5B [schuhmann2022laion](http://arxiv.org/pdf/2312.15897v1) dataset
[^3], our goal is only to keep images that are text-rich. Considering
that documents usually contain plenty of text, we first obtained a
binary classification dataset by combining natural images and document
data. Subsequently, we trained an image classifier using a DiT
[2022DIT](https://doi.org/10.1145/3503161.3547911)-base backbone, which was fine-tuned on the
RVL-CDIP dataset [harley2015evaluation](https://arxiv.org/pdf/1502.07058). Hopefully, such
a classifier can predict whether an image contains text or not. We first
build a subset by selecting images with a predicted probability greater
than 0.8 while also satisfying $p($watermark$) < 0.8$ and
$p($unsafe$) < 0.5$ [^4]. The derived subset is noisy due to the
limitation of the classifier. To further clean up the data and
incorporate human judgment,
r0.59
we randomly sampled 50K images and clustered them into 100 clusters
based on `CLIP-ViT-B/32` visual features. After inspecting the
clustering results, we carefully select 14 clusters (see Figure
[clusters] in the Appendix for examples)
containing diverse text-rich images ranging from posters, covers,
advertisements, infographics, educational materials, and logos. The
cluster model is then used as the filter to collect images for
constructing our instruction-following examples. As a reference, we
provide a CLIP [radford2021learning](https://arxiv.org/pdf/2103.00020)-based
categorization (see Appendix for details.) to illustrate the
distribution of images for both two types of data we collected in Figure
[fig:Data Collection]. We
summarize our collected data and LLaVA’s data in Table
1.
#### Noisy Instruction-following Data [para:Noisy Instruction-following Data]
Using the clustering model as a filter, we collect 422K deduplicated
images that belong to the 14 preferred clusters. To balance the examples
from different categories, we keep at most 52K examples for one cluster.
We run all images through PaddleOCR [^5]. Note that running OCR at the
original resolution (e.g.,$1024^2$) might recognize small fonts that are
not visible by visual encoders like CLIP ViT
(`\citealp{dosovitskiy2020image, radford2021learning}`{=latex},
resolution up to $336^2$). To ensure the recognition of visible fonts
while maintaining OCR accuracy, we perform OCR on the image after
downsampling (the short edge is resized to 384 pixels if longer than
that.) to extract the text. Then, based on the geometric relationships
between the recognized words, we merge them into paragraphs before
concatenating them. As a robust instruction-following model should react
similarly to instructions with similar meanings, we reword “Identify any
text visible in the provided image.” into ten distinct instructions
(Table 3 in Appendix). We then create a
single-turn conversation for a given image by **(i)** randomly sampling
an ***input instruction*** and **(ii)** using recognized texts as the
desired ***output response***. Such instruction-following data is noisy
because of the relatively limited performance of OCR tools on diverse
fonts and colorful backgrounds.
| **Data** | **Image** | **Instruction** | **\# Conv** | **Avg Ins Len** | **Avg Res Len** |
|:---|:--:|:--:|:--:|:--:|:--:|
| LLaVA pretraining | CC3M | CC3M | 595K | 15.9 | 15.4 |
| R~pretraining~ (Ours) | LAION | PaddleOCR | 422K | 17.2 | 48.8 |
| LLaVA finetuning | COCO | GPT-4 | 158K | 15.9 | 93.1 |
| R~finetuning~ (Ours) | LAION | GPT-4 | 16K | 15.1 | 40.5 |
Summary of data statistics. R~pretraining~ and R~finetuning~ denote the
additional pre-training / finetuning data we collected. The average
instruction and response length are calculated after LLaMA tokenization.
#### GPT-4-based Instruction-following Data
Compared to high-quality instruction-following data, there are mainly
two issues for the noisy data collected above. **(i)** Responses should
contain organized sentences instead of raw OCR results with missing
words and grammar errors. **(ii)** Instructions should be diverse,
suitable and specific to the given image instead of monotonously asking
for all visible texts. To address these issues, we follow
[liu2023visual](https://arxiv.org/pdf/2304.08485) to generate instruction-following data
by prompting text-only GPT-4 [openai2023gpt4](https://arxiv.org/pdf/2303.08774) with OCR
results and captions.
It is challenging to prompt GPT-4 with fragmented OCR results in a few
words to generate non-trivial instructions. To this end, we carefully
select 4 of the 14 previously mentioned clusters (the 3rd, 4th, 6th and
9th clusters in Figure [clusters]) to collect images with enough
visible and coherent sentences. As shown in Figure
[fig:Data Collection], such
filtering dramatically increases the percentage of book covers and quote
images. We randomly selected 4K examples from each cluster (no overlap
with images used for noisy instruction-following data), yielding a total
of 16K images. Following prior work
[wang2022selfinstruct](https://arxiv.org/pdf/2212.10560), [alpaca](https://github.com/tatsu-lab/stanford_alpaca), [liu2023visual](https://arxiv.org/pdf/2304.08485), we
provide the visualization of verb-noun pairs for instructions generated
by GPT-4 in Appendix Figure
7. For those instructions without
a verb-noun pair, we demonstrate the frequency of objects being asked in
Appendix Figure 8.
Furthermore, based on the system message and two in-context few-shot
examples (shown in Appendix ), we ask GPT-4 to generate conversational
data based on OCR results and image captions (Figure
[fig:highquality]). The generated
questions are used as ***input instructions***, and answers are used as
***output responses***. Concretely, for a given image, we first provide
two OCR results from EasyOCR and PaddleOCR, which can complement each
other. To illustrate visual elements other than texts within the image,
we also provide the result of BLIP-2 image captioning
[li2023blip2](https://arxiv.org/pdf/2301.12597). To prevent the caption from focusing on
the text, we use OCR bounding boxes to mask the text and then use the
inpainting [telea2004image](telea2004image) to refill the mask before
using generation captions. Note that captioning models might suffer from
hallucinations [rohrbach2018object](rohrbach2018object). We mention this
unreliability in our system message and ask GPT-4 only to generate
questions with sure answers. We leave the generation of more detailed
captions [rotstein2023fusecap](https://arxiv.org/pdf/2305.17718), [hu2022promptcap](https://arxiv.org/pdf/2211.09699) for
future work.
# Model Architecture and Training
#### Architecture
In most of our study, we use the same model architecture as LLaVA. For
the visual encoder $V$, we use `CLIP-ViT-L/14` for $224^2$ resolution
and `CLIP-ViT-L/14-336` for $336^2$ resolution. The grid features before
the last transformer layer are then transformed into the word embedding
space of the language decoder through a trainable projection matrix $W$.
We use Vicuna-13B [vicuna2023](https://lmsys.org/blog/2023-03-30-vicuna/), a LLaMA-based
[touvron2023llama](https://arxiv.org/pdf/2302.13971) instruction-tuned language model, as
the language decoder $D$ except the ablation study in Table
[table: ablation on
encoder/image].
In Section 5.1.0.3 and Appendix , we
extend the current architecture by adding an extra high-resolution
(high-res) visual encoder. Such a high-res encoder outputs thousands of
patch features, which means that the transformed features and
instruction tokens cannot fit in the context length of the language
decoder. To this end, we propose to add cross-attention modules to the
decoder, which attend to key-value pairs transformed from the high-res
patch features.
#### Training
We follow the two-stage training design of LLaVA (Figure
[fig:training]). The training
objectives of both stages are the same: generate ***output responses***
(*$<$res$>$*) for the ***input instructions*** (*$<$ins$>$*). The
transformed image tokens (*$<$img$>$*) are added before or after the
first input instruction. **(i)** During the first pre-training stage,
only the projection matrix $W$ is trained for feature alignment. Since
the decoder $D$ is frozen, training tolerates noisy data. In the
pre-training stage, we combine the 595K pre-training data from LLaVA
with our 422K noisy instruction-following data. **(ii)** Both the
projection matrix $W$ and the language decoder $D$ are trained during
the finetuning stage, where we merge our 16K instruction-following data
into the 158K instruction-following data from LLaVA as the training set.
Note that the visual encoder is frozen throughout the training period,
which might restrict text recognition performance, as CLIP is trained
for general-purpose text-image alignment. Better choices of the visual
encoder [tschannen2022clippo](https://arxiv.org/pdf/2212.08045) or CLIP-ViT finetuning
[ye2023mplugowl](https://arxiv.org/pdf/2304.14178) may further benefit the visual
understanding capability, which we leave for future work.
# Experiments
We use the same training hyperparameters as LLaVA[^6], except that
**(i)** We set the maximum sequence length to 1024 during pre-training.
**(ii)** We first pad any given image to a square shape before resizing
it to the desired input size, preventing some image content from
cropping during preprocessing. For both resolutions ($224^2$, $336^2$),
we reproduce the original LLaVA for a fair comparison. The GPT-4 model
used in this work refers to the `gpt-4-0314` version, while the cost to
collect finetuning data is around \$300. The temperature used to sample
GPT-4 is set to $1.0$ for the generation of training data, $0.7$ for the
generation of evaluation data, and $0.2$ for the evaluation based on
GPT-4. All experiments are run on NVIDIA A100 80GB GPUs. During the
evaluation, the temperature used to sample from our model is set at
$0.9$ for text-based VQA, $0.7$ for GPT-4-based instruction-following
evaluation, and $0.2$ for other qualitative demonstrations.
The book was written by Sandra Boyton. It
is a children’s book that features a family calendar with an
accompanying activity guide. The book provides information (...) The
cover of the book displays a picture of the family from the calendar,
which helps to visually represent the topic of the book.
Ablation study based an example from OCR-VQA. GT refers to
ground truth, and (1) - (6) are different model variants from Table [table: VQA ablation]. We
replace the excessively long response with (...).
## Quantitative Analysis
#### Text-based VQA
Following the evaluation protocol in [liu2023hidden](https://arxiv.org/pdf/2305.07895), we
evaluate the performance of LLaVAR on four text-based VQA datasets:
ST-VQA [STVQA](https://doi.org/10.1109/icdar.2019.00251), OCR-VQA
[mishra2019ocrvqa](http://arxiv.org/pdf/2010.02582v1), TextVQA [textvqa](https://doi.org/10.1109/cvpr.2019.00851),
and DocVQA [mathew2020docvqa](https://arxiv.org/pdf/2007.00398), representing various
domains (see Appendix for more details and Appendix for more datasets).
We present the results of the baseline models and our models in Table
[table: VQA result]. Note that
InstructBLIP includes OCR-VQA in its training sets, making it
incomparable with our settings. In both resolution settings and all four
datasets, LLaVAR substantially improves the LLaVA baseline,
demonstrating that our collected data can bring about a robust
improvement. Furthermore, the improvement is more significant in $336^2$
resolution compared to $224^2$, indicating that the collected data might
bring a greater improvement at even higher resolutions. Our best model,
$336^2$-based LLaVAR, performs best in 3 out of 4 evaluated datasets.
Note that this is not a fair comparison. Some key factors include
different language decoders, resolutions, and magnitudes of text-image
training data. We provide more discussions on the comparison with
mPLUG-Owl and the result of finetuning mPLUG-Owl using our data in
Appendix .
#### Ablation Study on pretraining/finetuning data
We report the result in Table
[table: VQA ablation] and
Figure 1. **(i)** Based on
variants (2) and (3), we find that the collected data can benefit the
pretraining stage (R~pretraining~) and finetuning stage (R~finetuning~)
separately while being complementary to each other in most cases [^7].
More importantly, enhancing the pretraining stage alone achieves the
second-best overall performance, indicating the potential to boost
textual detail understanding without dependence on GPT-4-generated
high-quality data. **(ii)** Using pretraining images, we obtain
C~pretraining~ by replacing the pretraining instructions with questions
& captions, the same pattern as LLaVA. As variant (4) is not as good as
(2), we can conclude that OCR is more advantageous than captions.
**(iii)** We further validate the value of GPT-4 generated data by
generating noisy finetuning data (N~finetuning~), similar to pretraining
data. Variant (5) achieves comparable accuracy as variant (3). However,
as shown in Figure
1, such noisy finetuning
data hurts the instruction-following capability: (5) responds with all
recognized texts while ignoring the questions.
#### Ablation Study on encoders/image resolution [Ablation: encoders/res]
While keeping finetuning data the same, we report the quantitative
results of adding an extra visual encoder and varying the pretraining
data in Table
[table: ablation on
encoder/image]. **(i)** Take `Pix2Struct-base` as an example, we
find that adding an extra high-res visual encoder with cross-attention
indeed improves the performance ((g) vs. (a)), especially achieving the
best zero-shot performance on DocVQA (15.3% accuracy). The performance
gain on other datasets is relatively limited, probably due to the extra
encoder we use being pretrained on web pages instead of natural images.
On the other hand, the performance of (e) and (f) remains poor, without
doubling the number of high-res examples in R~pretraining~. Given the
larger number of parameters initialized in the cross-attention module,
they may be underfitting when trained on the same data as the projection
matrix $W$ (e.g., (e) vs. (b)), similar to the finding in
[zeng2023matters](zeng2023matters). **(ii)** Considering (c) vs. (a) and
(d) vs. (b), while the images are resized to the same size after
preprocessing, high-res OCR results turn out to be not necessarily
better than the low-resolution version, suggesting the capability of the
visual encoder is almost saturated in (a) and (b). For more details and
results on the extra high-res encoder, please refer to Appendix .
#### GPT-4-based instruction-following evaluation
We also report the GPT-4 evaluation results on instruction-following
questions in Table 2. **(i)** **Natural Images**: 90
questions based on 30 COCO validation images from
[liu2023visual](https://arxiv.org/pdf/2304.08485), including three aspects: conversation,
detail description, and complex reasoning. This aims to test whether our
collected data will hurt, maintain, or improve the model’s performance
on natural images. First of all, using a higher resolution brings
improvement (+2.9) in the performance of detail description, which is
intuitive. Furthermore, LLaVAR achieves a better trade-off and increases
the performance of all three aspects (+1.6 on average). More details are
in Appendix . **(ii)** **Text-Rich Images**: Similar to collecting the
finetuning data, we leverage 50 text-rich images from LAION to collect
instruction-following questions based on OCR results and human-annotated
captions. We then collect responses from our trained model and use GPT-4
to calculate the relative score w.r.t GPT-4 responses. We add this as an
extra dimension “**Read**” to Table
2, where our model demonstrates a
significant (+3.8) improvement. The Appendix provides an example in
Table 11.
## Qualitative Analysis
We use a recent movie poster [^8] to demonstrate the difference between
LLaVA and LLaVAR when interacting with humans based on text-rich images.
LLaVA, without augmenting textual understanding within images, suffers
from hallucination when answering these questions. Some mentioned
movies, like “A Man Called Ove” and “The Ugly Truth”, are real movies,
suggesting that the language decoder is hallucinating its internal
knowledge, while the visual encoder cannot encode helpful information.
Alternatively, LLaVAR can correctly answer many of the provided
questions with **faithful** information, which is clearly grounded in
the image. However, some limitations remain, such as the spelling error
“ottol” (We provide more statistics related to such spelling errors in
Appendix ). Also, the final question asks for information that is not
observable from the given poster, where an expected response should
express such uncertainty instead of giving concrete answers.
Nevertheless, neither model correctly answers the question.
| | **Res** | **Conversation** | **Detail** | **Complex** | **Read** |
|:-----------------|:-------:|:----------------:|:----------:|:-----------:|:--------:|
| LLaVA (Original) | $224^2$ | 83.1 | 75.3 | 96.5 | \- |
| LLaVA | $336^2$ | 83.9 | 78.2 | 95.3 | 87.9 |
| LLaVAR | $336^2$ | 84.5 | 78.9 | 96.5 | 91.7 |
Relative scores (w.r.t. text-only GPT-4) for instruction-following
questions, where the first three dimensions are based on natural images,
the last dimension (“Read”) is based on text-rich images. In the first
row, we show the original results ($224^2$-based) fetched from
[liu2023visual](https://arxiv.org/pdf/2304.08485). We report our reproduced LLaVA on
$336^2$ resolution for a fair comparison.
H: When will
this movie be released?
L: The movie
"The Call of the Ottoman" starring Daniel Craig is expected to be
released on February 14th, 2023.
R: The movie
will be released on January 13.
H: Who starred
in the movie?
L: The movie
stars Tom Cruise and Cobie Smulders.
R: Tom Hanks
starred in the movie.
H: What is this
movie about?
L: The movie "A
Man Called Ove" is a comedy-drama film directed by Hannes Holm.
(...)
R: The movie is
about Tom Hanks, who is called Ottol, and it is an international
bestseller based on a true story. (...)
H: Can you
describe the given image?
L: The image is
a movie poster featuring a man and a cat. The man, who appears to be a
character from the movie “The Ugly Truth,” (...)
R: The image
features a man standing in front of a house with a cat beside him.
H: Who directed
the film?
L: The film was
directed by Florian Henckel von Donnersmarck.
R: The film was
directed by Tom Hanks, who made his directorial debut with this
movie.
Qualitative Comparison. We color the human inputs
(H) in blue, LLaVA’s responses
(L) in pink, and LLaVAR’s responses
(R) in green. Both are 3362-based models. We replace the
excessively long response with (...).
Case study of the recognizable font size, in which the
x-axis refers to the height of ground truth answers in the image and the
y-axis stands for the answer accuracy of models. We plot the results for
both 2242-based models and
3362-based
models.
## Case Study: Recognizable Font Size
We first collect 825 examples from OCR-VQA, which have answers directly
presented in the image and are detectable by the OCR tool. By rescaling
the images, we test the model’s performance in answering these questions
while the vertical heights of answers range from 3 pixels to 19 pixels.
We report the result in Fig
3. **(i)** For the baseline model
LLaVA, it struggles to provide correct answers in all scenarios, for
both $224^2$-based and $336^2$-based versions. **(ii)** Our model LLaVAR
achieves significantly better results in all scales. We observe a
threshold for recognizable texts for both $224^2$-based and
$336^2$-based versions as the accuracy sharply decreases when the height
is smaller than 7 pixels. More interestingly, the $224^2$-based version
achieves better performance on small texts with 3 pixels height while
the $336^2$-based achieves better performance on large texts with more
than 7 pixels height. We assume the extra training stage of CLIP $336^2$
makes it better on the larger scale but worse on the smaller scale.
## Transferred Instruction-following Capability
According to the dataset statistics (Table
1) and the visualization (Figure
7), our collected
instruction-following data is not as diverse and substantial as LLaVA.
This can be attributed to the relatively limited information given GPT-4
compared to five different human-written captions used in LLaVA. The
content of text-rich images is also less diverse than that of natural
images. While using more complex in-context examples can definitely
stimulate generating more complicated instruction-following examples, it
can also multiply the cost. In Appendix Figure
6, we demonstrate the transferred
instruction-following capability of LLaVA, potentially from both the
LLaVA data and the Vicuna backbone. While the extra data we add mainly
focuses on understanding the visible texts within images, LLaVAR manages
to build its reasoning, writing, and elaboration skills based on the top
of its text recognition capability in an end-to-end manner. This allows
users to interact with various online content based on simple
screenshots.
# Conclusion
In this work, we enhance visual instruction-tuned models in terms of
their capability to read texts in images. Using text-rich images from
the LAION dataset, we collect 422K noisy instruction-following examples
using OCR results only and 16K high-quality instruction-following data
based on text-only GPT-4. These two sets of data are leveraged to
augment the pretraining stage and finetuning stage of LLaVA accordingly.
Our model, LLaVAR, demonstrates superior performance in understanding
texts within images and following human instructions on both prior
benchmarks and real-world online content. Moreover, our analysis shows
that the same augmented data is more effective with higher resolution.
Additionally, using noisy instruction-following examples to augment
pretraining essentially boosts the model performance without prompting
GPT-4. For future work, we encourage exploration of **(i)** better image
selection criteria or domain reweighting strategy
[xie2023doremi](https://arxiv.org/pdf/2305.10429) and **(ii)** more data-efficient and
computation-efficient ways to augment instruction-following models with
multimodal capability, especially in the high-res scenario.
| **Instructions** |
|:-----------------------------------------------------------------------|
| Identify any text visible in the image provided. |
| List all the text you can see in the given image. |
| Enumerate the words or sentences visible in the picture. |
| Describe any readable text present in the image. |
| Report any discernible text you see in the image. |
| Share any legible words or sentences visible in the picture. |
| Provide a list of texts observed in the provided image. |
| Note down any readable words or phrases shown in the photo. |
| Report on any text that can be clearly read in the image. |
| Mention any discernable and legible text present in the given picture. |
Ten instructions asking for OCR results.
# A [CLIP-based categorization]
#### CLIP-based categorization
Based on the observation of selected clusters, we divide the images used
into 8 categories. For each category, we use one or multiple words as
labels.
- **Quote & Meme**: “quote”, “internet meme”.
- **Poster**: “movie poster”, “podcast poster”, “TV show poster”,
“event poster”, “poster”,
- **Book Cover**: “book cover”, “magazine cover”.
- **Game Cover**: “game cover”.
- **Ad & Product Packaging**: “ad”, “advertisement”, “food packaging”,
“product packaging”.
- **Infographic**: “chart”, “bar chart”, “pie chart”, “scatter plot”.
- **Educational Material**: “exam paper”, “quiz”, “certificate”, “book
page”.
- **Logo**: “logo”.
For each word, we use the following templates to achieve embedding-space
ensembling [radford2021learning](https://arxiv.org/pdf/2103.00020):
- “a photo of a {}.”
- “a blurry photo of a {}.”
- “a black and white photo of a {}.”
- “a low contrast photo of a {}.”
- “a high contrast photo of a {}.”
- “a bad photo of a {}.”
- “a good photo of a {}.”
- “a photo of a small {}.”
- “a photo of a big {}.”
For each image, we calculate the similarity between the image and all
words mentioned above using `CLIP-ViT-L/14`. If the highest similarity
is less than $0.15$, we then classify the image into **Other**,
otherwise we classify into the “super class” (e.g., **Poster**) of the
word (e.g., “movie poster”) with the highest similarity.
# B [context prompt]
#### System Message
adapted from [liu2023visual](https://arxiv.org/pdf/2304.08485).
You are an AI visual assistant, and you are seeing a single image. What
you see is provided with two OCR results and one image caption
describing the information within the same image you are looking at.
Image captions might include hallucinations, while OCR results are more
accurate. Answer all questions with definite answers as you are seeing
the image.
Design a conversation between you and a person asking about this photo.
The answers should be in a tone that a visual AI assistant is seeing the
image and answering the question. Ask diverse questions and give
corresponding answers.
Include questions asking about the visual content of the image (e.g.,
the man, the sunset, the ocean.) and the texts contained in the image.
Only include questions that have definite answers:
\(1\) one can see the content in the image that the question asks about
and can answer confidently;
\(2\) one can determine confidently from the image that it is not in the
image. Do not ask any questions that cannot be answered confidently;
\(3\) DO NOT mention OCR or image caption in your questions and answers;
\(4\) DO NOT ask about information from captions while it looks
unrelated to or contradicts OCR results.
Also include complex questions that are relevant to the content in the
image, for example, asking about background knowledge of the texts in
the image, asking to discuss about the design of the image, etc. Again,
do not ask about uncertain details. Provide detailed answers when
answering complex questions. For example, give detailed examples or
reasoning steps to make the content more convincing and well-organized.
You can include multiple paragraphs if necessary.
#### Few-shot Examples
**Human:**
WHAT F YOUR BLESSINGS COME THROUGH RAINDROPS PDf Induded LAURASTOR Y
DEVOHONAL BASED ON THE GRAAAMY VARD WIN ISONG mAT HAS INSEIRED MILLION
WHATIFYOUR BLESSINGS COMETHROUGHRAINDROPS PDF Included LAURASTORY A
DEVOTIONAL BASEDON THE GRAMMY AWARD WINNI PISONGTHATHASINSPIREDMILLIONSE
a girl is standing in a field with a rainbow
**GPT:**
Question: What is the name of the devotional mentioned in the image?
Answer: The devotional is called “What If Your Blessings Come Through
Raindrops” by Laura Story.
Question: What is special about the song mentioned in the image?
Answer: The song is special because it’s a Grammy Award-winning song
that has inspired millions of people."
**Human:**
One of the hardest things in life to accept is a called third strike
Robert Frost te
One of the hardest things in life to accept is a called third strike
Robert Frost quotefancy
a close up of a baseball glove
**GPT:**
Question: Why is the third strike hard to accept? Explain the quote to
me.
Answer: The quote Öne of the hardest things in life to accept is a
called third strikeättributed to Robert Frost is a metaphor for life
situations. In baseball, a called third strike is when the umpire
determines that a pitch was a strike, but the batter did not swing. This
can be frustrating for the batter because they missed an opportunity to
hit the ball due to either a lack of confidence or misjudgment.
In life, this metaphor refers to difficult moments where we might miss
opportunities or face setbacks because of our own inaction or
hesitation. The quote suggests that it is hard to accept these missed
opportunities or challenges, especially when they result from our own
choices or lack of action.
# C [Evaluation Dataset]
Details of evaluation datasets used in the main paper:
- ST-VQA [STVQA](https://doi.org/10.1109/icdar.2019.00251) contains 31791 questions that require
understanding the scene text, based on images from COCO
[lin2015microsoft](https://arxiv.org/pdf/1405.0312), Visual Genome
[krishna2016visual](https://arxiv.org/pdf/1602.07332), ImageNet
[imagenet](https://doi.org/10.1109/CVPR.2009.5206848), etc.
- TextVQA [textvqa](https://doi.org/10.1109/cvpr.2019.00851) contains 45,336 questions that
need reading and reasoning about the text in images to answer, based
on images from OpenImages [openimages](http://arxiv.org/pdf/1809.05929v7).
- OCR-VQA [mishra2019ocrvqa](http://arxiv.org/pdf/2010.02582v1) contains more than 1
million questions asking about information from book cover images
[iwana2016judging](https://arxiv.org/pdf/1610.09204).
- DocVQA [mathew2020docvqa](https://arxiv.org/pdf/2007.00398) contains 50000 questions
based on document images.
Details of extra datasets in Appendix:
- CT80 [risnumawan2014robust](risnumawan2014robust) contains 80 images for
curved text OCR evaluation. The formats of questions are: (1) “What
is written in the image?" for English words. (2) “What is the number
in the image?" for digit string.
- POIE [textvqa](https://doi.org/10.1109/cvpr.2019.00851) contains 3000 camera images collected
from the Nutrition Facts label of products, together with 111,155
text instances. The format of questions is “What is {entity name} in
the image?".
- ChartQA [masry2022chartqa](masry2022chartqa) includes 4,804 charts
with 9608 human-written questions.
# D [other metrics]
#### Results of other metrics
The metric used for text-based VQA in the main paper is the standard
practice in VQA benchmarks [VQA](VQA). For STVQA and DocVQA,
previous works use ANLS (Average Normalized Levenshtein Similarity) as
the metric [STVQA](https://doi.org/10.1109/icdar.2019.00251), [mathew2020docvqa](https://arxiv.org/pdf/2007.00398), which calculates
the average normalized edit distance and only works for supervised
models trained to output short and precise answers. It works badly for
instruction-following models that usually output long sequences instead
of brief answers. For reference, we provide more text-matching metrics
(METEOR, `\citealp[]{banerjee-lavie-2005-meteor}`{=latex}, ROUGE-L,
`\citealp[]{lin-2004-rouge}`{=latex}, CIDEr,
`\citealp[]{vedantam2014cider}`{=latex}) to demonstrate the improvement
of our model (Table
4,
5,
6,
7), which works well except
for OCR-VQA. We assume these metrics are not valuable for OCR-VQA since
the ground truth answers are usually too short.
# E [Extra datasets]
#### Results on extra datasets
In Table [table: extra VQA result],
we provide results on three extra datasets: CT80 (OCR,
`\citealp[]{risnumawan2014robust}`{=latex}), POIE (Information
Extraction, `\citealp[]{kuang2023visual}`{=latex}), and ChartQA
[masry2022chartqa](masry2022chartqa). We use the same VQA metric as other
text-based VQA datasets. We observe similar trends as the main paper
results: LLaVAR data significantly improves over the LLaVA baseline,
usually more considerably in a higher resolution.
# F [Finetune mPLUG]
#### Comparison with mPLUG-Owl
We find that LLaVAR usually performs similarly well with mPLUG-Owl in
the same $224^2$ resolution.We further clarify the setting differences
between mPLUG-Owl and ours: mPLUG-Owl is trained on 1000M+ text-image
pairs, while the original LLaVA is trained on about 0.6M text-image
pairs. Our model, LLaVAR, is trained on about 1M text-image pairs.
Within the same resolution, LLaVAR demonstrates a good performance with
decent data efficiency.
We presume that training on large-scale non-OCR data improves OCR
performance, as many of the captions in LAION datasets are equivalent to
incomplete OCR results (Texts in an online image will sometimes appear
in the captions). In the scale of our experiment, we observe similar
improvement that just training on captions of text-rich images can help
with text recognition capability: In Table
[table: VQA ablation], variant
(4) is better than variant (1). However, training on captions only
(variant (4)) is not as good as training on OCR-based data (variant
(2)(6)), at least in the scale of our experiments.
#### Results of finetuning mPLUG-Owl
To further validate the effectiveness of our collected data, we provide
the results of finetuning mPLUG-Owl using our 16K GPT-4-based
instruction-following data in Table
8. Though the mPLUG-Owl
checkpoint is extensively trained on 1000M+ text-image pairs, we find
that our data can boost performance in most cases, demonstrating the
effectiveness of our data.
# G [ScienceQA section]
#### ScienceQA Results
Starting from our pretrained LLaVAR ($336^2$-based, without finetuning),
we also report the results of further finetuning on the ScienceQA
dataset [lu2022learn](https://arxiv.org/pdf/2209.09513) in Table
[table:scienceqa], which is a
multimodal multi-choice QA dataset covering diverse domains. Our
motivation is that some images in this dataset contain text descriptions
and tables that require textual understanding within images. The LLaVAR
model finetuned on ScienceQA achieves an average accuracy of 91.42%,
better than LLaVA (90.92%), while the most considerable improvement
comes from natural science questions (+1.43%).
# H [High-Res section]
Illustration of the dual visual encoder system. Given an
image, it is simultaneously processed by visual encoders V1 and V2. V1 features are
transformed by transformation matrix W and directly used as input
embeddings to the language model. For V2 features, they are
transformed by transformation matrix K and V and used as keys and values to
calculate the cross attention in every transformer layer (assume there
are N layers), which uses the
transformed hidden states (through Q) from the self-attention module as
queries. For the language decoder D, the input is image tokens
(<img>) and instruction tokens (<ins>), while the target is response
tokens (<res>).
The original version of LLaVAR only supports up to $336^2$ resolution,
while our case study has also shown the threshold for the recognizable
font size. Both suggest the difficulty of processing real-world high-res
images without scaling and cutting. To this end, we test a dual visual
encoder system for the high-res variant of LLaVAR, where a high-res
visual encoder is added to work with the standard one. Ideally, the
standard visual encoder extracts general, high-level information, while
the high-res one specifically helps with detailed information.
#### Architecture
A high-res visual encoder usually outputs thousands of visual features.
Simply following LLaVA to feed the transformed visual features into the
context of the language decoder is impractical, as the maximum sequence
length of the language decoder is usually 2048/4096. To this end, we
propose to handle high-res visual features by cross-attention module and
standard visual features by feature transformation. We depict the
proposed system in Figure
4.
Specifically, given a standard visual encoder $V_1$, the extracted
features are transformed into the word embedding space of the language
decoder through a trainable projection matrix $W$. These transformed
features are then concatenated with the word embeddings to build the
input embeddings of the language decoder $D$. $$\begin{aligned}
\begin{split}
& \mathrm{emb}(\langle \mathrm{img}_1\rangle), \cdots, \mathrm{emb}(\langle \mathrm{img}_m \rangle) = WV_1(I) \\
\mathrm{input}\_\mathrm{emb} = \mathbf{concat}([ & \mathrm{emb}(\langle \mathrm{img}_1\rangle), \cdots, \mathrm{emb}(\langle \mathrm{img}_m \rangle), \mathrm{emb}(\langle \mathrm{ins}_1\rangle), \cdots, \mathrm{emb}(\langle \mathrm{ins}_n \rangle)])
\end{split}
\end{aligned}$$
where $I$ is the input image, $V_1$ denotes extracting the grid features
before the last transformer layer.
At the same time, we use the high-res visual encoder $V_2$ to extract
high-res visual features, which are then transformed into keys/values as
the inputs of the cross-attention module in transformer layers. Given
$h^j$ as the hidden state before the cross-attention module in layer
$j$, $$\begin{aligned}
\begin{split}
& \mathrm{CrossAttention}(h, V_2, I) = \mathrm{softmax}(\frac{Q^jh^j(K^jV_2(I))^T}{\sqrt{d}})V^jV_2(I)
\end{split}
\end{aligned}$$ where $Q^j, K^j, V^j$ denotes the query/key/value
projection matrix in the $j$-th transformers layer. In practice, there
is a pre-attention LayerNorm before calculating the attention and
another output projection matrix $O^j$ to project the aggregated values
back to the hidden space.
As the pretrained language decoder $D$ might only have self-attention
modules, we manually add another cross-attention module after the
original self-attention module in every transformer layer. Considering
the random initialization of cross-attention modules might hurt the
original language generation capability, we initialize the value
projection matrix $V^j$ as a zero matrix and the output projection
matrix $O^j$ as an identity matrix.
#### Implementation
We use `CLIP-ViT-L/14` as the standard visual encoder. For the
high-resolution encoder, we test two models: **(i)** `Pix2Struct-base`
[lee2022pix2struct](https://arxiv.org/pdf/2210.03347) is a visual encoder trained on
screenshot to HTML transformation. It supports up to 2048 patches with
size $16^2$, equivalent to $1024 * 512$. **(ii)** `ConcatCLIP` refers to
using 16 `CLIP-ViT-L/14` models to encode the $4 * 4$ grids of images
separately and then concatenate the extracted features together. In
other words, it supports $896^2$ resolution. We use Vicuna-7B as the
language decoder for the high-res version of LLaVAR.
#### Training
Only cross-attention modules and the projection matrix $W$ are trained
during pretraining, while visual encoders and the language decoder are
frozen. Cross-attention modules, the projection matrix $W$, and the
language decoder $D$ are trained during finetuning.
#### Data
To fully unlock the potential of the augmented visual encoder, we also
double the number of pretraining examples using the same criteria
mentioned in Section 3.0.0.1. This
corresponds to the variant (g) in Table
[table: ablation on
encoder/image].
#### Discussion
We report the performance of augmented architecture, using either LLaVA
or LLaVAR data in Table
[table: pix2struct and
clip]. By comparing the relative improvement in Table
[table: VQA result] and
[table: pix2struct and
clip], we find that higher-resolution models benefit more from our
collected data, suggesting our data is underutilized in the original
LLaVA architecture.
# I [OCR error analysis]
#### The impact of OCR spelling errors
We study such OCR errors by studying 1673 examples from OCR-VQA, which
have ground truth answers with more than ten characters. We (i) define
“correct” as the ground truth answers that are exactly in the
predictions, and (ii) define “partially correct” as there exists a
substring in the prediction that has high enough similarity with the
ground truth but not the same. Specifically, we look at all substrings
with the same length of the ground truth in the prediction to calculate
ANLS (Average Normalized Levenshtein Similarity) and regard the
prediction as “partially correct” if the highest ANLS is greater or
equal to 0.5 but smaller than 1.
We find that many predictions can be considered partially correct,
indicating the actual performance of tested models is better than the
reported accuracy numbers. However, the percentage of partially correct
predictions is highly correlated with the percentage of correct
predictions. Therefore, we believe that the current metrics can
effectively compare the performance of different models.
# J [ablation study on LLaVA benchmark]
#### Ablation Study on Instruction-following Evaluation
To provide a more detailed understanding of LLaVAR’s data, we provide
the ablation study results on 90 instruction-following questions from
LLaVA [liu2023visual](https://arxiv.org/pdf/2304.08485). We find that including
pretraining data improves the conversation capability, probably because
longer training data leads to generating longer responses (Table
1), which is favored by GPT-4
[xu2023baize](https://arxiv.org/pdf/2304.01196). On the other hand, including only
finetuning data hurts the conversation capability but increases complex
reasoning. Combining pretraining and finetuning data improves the
trade-off between conversation and complex reasoning. Such results prove
that incorporating our data will at least not harm the performance of
interacting with natural images.
lm8.8cmm1cm & Relative Score
| |
|:------------|
| GPT-4 |
| (Text-Only) |
An example for our collected evaluation data, corresponding to the
“**Read**” dimension of GPT-4-based instruction-following evaluation.
The corresponding image is Figure
5 in Appendix.
& From the title and image, it can be inferred that "Bo’s Lasting
Lessons" is a book about leadership lessons taught by a legendary coach,
likely in the context of sports. The image of men running suggests that
the book might be focused on a specific sport, such as football or track
and field. The target audience could be individuals interested in
coaching, sports, or leadership in general, looking to learn from the
experiences and teachings of a successful coach. & -
LLaVA & The book "Bo’s Lasting Lessons: The Timeless Teachings of Bo
Schembechler" is written by Bo Schembechler and Jim Harshaw. Given the
title and the image on the cover, which shows a football coach running
across the field with his players in pursuit, it can be inferred that
the content of the book is likely focused on football and the
strategies, techniques, or principles that can help players improve
their performance and achieve success in the sport. The potential target
audience for this book could be football players, coaches, and fans who
are interested in learning more about the game and the experiences and
insights of a seasoned coach like Bo Schembechler. & 75%
LLaVAR & "Bo’s Lasting Lessons" appears to be a book that shares the
legacy coach Bo Schembechler’s teachings on leadership and timeless
fundamentals. The image on the cover, featuring a football coach leading
his team, further supports this inference. The book might be targeted
towards sports enthusiasts, particularly fans of football, and people
interested in learning about leadership principles and fundamentals from
a renowned coach’s perspective. The audiobook, read by John H. Mayer and
featuring a foreword and conversation with John U. Bacon, suggests that
it could also appeal to audiences who prefer listening to books or want
to gain more insights from the author and other experts. & 129%
An example for the Read dimension of GPT-4-based
instruction-following evaluation.
Transferred instruction-following capability of
LLaVAR.
Visualization of collected instructions.Visualization of collected instructions.
[^1]: Collaborations through Adobe University Gift Program.
[^2]: In this work, we use the phrase “text-rich images” to describe
images with text in them, such as posters and book covers. In
contrast, we refer to images without text as “natural images”.
[^3]:
[^4]: Both probabilities are from the LAION dataset’s metadata.
[^5]:
[^6]:
[^7]: Since the metric only consider the recall, it might favor variant
(2)(4)(5) due to their longer outputs.
[^8]:
Classic VLMs combined with OCR tools to get fine-grained details (mainly text)
To tackle the lack of fine-grained details (mainly textual ones) from document images by traditional VLMs, some models have added the fine-grained details of the document image by using an OCR tools.
*An OCR (Optical Character Recognition) tool is a technology that extracts text and its bounding box positions from images.* The visual tokens from the visual encoder of the VLM and textual tokens (from the OCR and the input (question, instruction, ...)) are put together (eg. concatenated,) and given to the LLM decoder of the VLM
. The OCR tool adds not only textual elements, but also their position in the document. Some models like [Lyrics](https://arxiv.org/pdf/2312.05278) employ a "Visual Refiner" to extract fine-grained details from the image, which not only extracts text and their bbox within the image, but also local visual features.
Adding OCR output of the document to a VLM requires modality alignment during pretraining to ensure coherent learning and integration of different data types (image tokens from the Visual Encoder and textual and positional tokens from the OCR)
. Alignment ensures that the model can correlate the text with its corresponding visual elements and its position on the page, which is essential for a cohesive understanding of multimodal content.
A first alignment to be done is between the textual and the positional tokens.
The Masked Visual Language Modeling (MVLM) Pretraining Method
is used by [Hi-VT5](https://arxiv.org/pdf/2212.05935) and [LayoutLMv3](https://arxiv.org/pdf/2204.08387). MVLM is similar to Masked Language Modeling (MLM) from the NLP field, where some words in the text are masked (replaced by a special token) and the model is trained to predict these masked words. The difference relies on the fact that in MVLM, the tokens are masked but not their positions (bbox). This approach allows the model to leverage the spatial context provided by the bounding box coordinates. By preserving the positional information, MVLM facilitates the alignment of textual and position modalities, enabling the model to learn the relationship between text and its location on the page. Some methods select a random amount of tokens to mask. (hivt5, layoutlmv3)
Alignment must also be done between the textual and visual tokens.
This alignment can be done by Word-Region Alignment (WRA) and Word Patch Alignment (WPA) pretraining tasks
. The former was introduced by [UNITER](https://arxiv.org/pdf/1909.11740). WRA uses optimal transport (OT) to encourage precise alignment between specific words and corresponding image regions (extracted by a CNN) of the document, by focusing on minimizing the coupling cost of embeddings distributions of words and images, encouraging the model to learn which image regions correspond to which words in the text
. WPA, introduced by [LayoutLMv3](https://arxiv.org/pdf/2204.08387) does the same with patchs from ViTs rather than CNNs: it aims at determining the matching patchs and text tokens, and works by masking all patchs except one, and its corresponding token is labeled "aligned", while the others are labeled "unaligned". For each textual token, the model predicts if it is aligned or not with the unmasked patch.
Finally, alignment can between all types of data: the textual, positional and visual tokens.
Masked Image Modeling was implemented by [LayoutLMv3](https://arxiv.org/pdf/2204.08387) and aims at randomly masking some patchs of the image and predicting these masked patchs depending of the surrounded text and position tokens
. [DoCo: Document Object Contrastive Learning](https://arxiv.org/pdf/2402.19014) pretrains a ViT visual encoder using a Document Object Contrastive learning
method. Traditional contrastive learning methods work by comparing pairs of images and their summaries, encouraging the model to learn similar representations for related pairs and different representations for unrelated pairs. DoCo, on the other hand, aligns texts and bounding boxes from documents with the visual features produced by the vision encoder, rather than comparing images and summaries. This method helps the model to understand and integrate textual and spatial information within documents. [InstructDr](https://arxiv.org/pdf/2401.13313) implements a specialized connection layer called Document-Former
to integrate the outputs from a Vision Encoder (pretrained CLIP) and OCR into a Language Model (FlanT5), composed of cross-attention layers within Transformer blocks to align and merge the visual embeddings from the VLM with textual and positional data from the OCR.
To sum up, using an OCR tool to extract fine-grained details requires addition pretraining for modality alignment.
Some recent works ([LaRA](https://arxiv.org/pdf/2406.06730)) have opted for no alignment. Instead, they simply add the OCR words within the input given to the LLM
. Thus, the LLM decoder takes as input an instruction (), alongside OCR results (), and the transformed image tokens
() (image encoder followed by a projection layer) introduced randomly before or after the instruction.
##
2. Models using fine-grained vision model and a LLM as decoder
The computational complexity of LLMs in terms of the input sequence length \( n \) can be expressed as \( O(n^2) \)
, with the complexity arising from pairwise comparisons between elements in the sequence. However, the more fine-grained (high resolution) image the visual encoder takes, the longer will be its representation by the visual encoder
, so the input sequence length taken by the visual encoder increases, so the more time it takesat inference of the LLM, without saying that LLMs have input sequence length limit. However, the higher the resolution the image is, the better performance will have the vision language model on fine-grained tasks
. Here is this illustration made by [Pix2Struct's paper](https://arxiv.org/pdf/2210.03347) on Vision-Language model performance on DocVQA task (ANLS score) depending on the input sequence length (and so on the number of pixel of the image): 
This is why models using LLMs as decoder often use a smaller representation visual encoder than the vision-rich models.
However, some papers use some tips to use LLM as decoder and a fine-grained representation of the input image (document) by the model
.
And here is a summary of those tips:
Slicing high-resolution image into several crops
By dividing an image into multiple crops, a low-resolution Vision Transformer (ViT) can be utilized
, reducing the input size for the large language model (LLM) while still enabling fine-grained analysis.
**[SPHINX](https://ar5iv.labs.arxiv.org/html/2311.07575)** crops high-resolution documents into four 224x224 pixel sub-images and includes a low-resolution version of the entire image. These slices and the full image are encoded separately with four visual encoders (CLIP-ViT, CLIP-ConvNeXt, DINOv2-ViT, BLIP2) and then concatenated for the large language model (LLM) input: 
**[UReader](https://arxiv.org/pdf/2310.05126)** employs an adaptive cropping module to divide high-res images into local images based on predefined grids, selecting the best grid via resolution coherence and shape similarity calculations : 
**[Monkey](https://arxiv.org/pdf/2311.06607)** uses a Swin Transformer-inspired sliding window to split images into crops: 
**[TextMonkey](https://arxiv.org/pdf/2403.04473)** enhances this with shifted window attention and a token resampler for better slice connections within the Vision Transformer (ViT): 
**[mPLUG-DocOwl1.5](https://arxiv.org/pdf/2403.12895)** adopts adaptive cropping and adds textual tokens to visual features, using an H-Reducer projection matrix to maintain slice positions: 
**[LLaVA-UDH](https://arxiv.org/pdf/2403.11703)** introduces image-modularization, slicing images into variable-sized crops and selecting the optimal partition to align with ViT's standard configuration: 
**[InternLM-XComposer2-4KHD](https://arxiv.org/pdf/2404.06512)** dynamically partitions images into non-overlapping 336x336 pixel slices and adds a learnable newline token to preserve global structure: 
**[TextHawk](https://arxiv.org/pdf/2404.09204)** utilizes adaptive cropping similar to UReader but includes a Scalable Positional Embedding (SPE) module to adjust positional embeddings based on slice count, ensuring consistent positional information for downstream tasks.
**[Idefics2](https://arxiv.org/pdf/2405.02246)** employs a pooling layer, so that the sequence of visual tokens is pooled into a shorter sequence.
Reduction of Vision Embedding Sequence (post-processing)
Another method involves reducing the sequence length of the high-resolution image embedding after it has been generated by the visual encoder, thereby providing a smaller input size to the large language model (LLM)
.
Reduction of Vision Embedding Sequence (post-processing) by transforming the image into the frequency domain
One effective approach to reducing the sequence length of visual embeddings is transforming the image into the frequency domain
. [DocPedia](https://arxiv.org/pdf/2311.11810) implements this technique by converting high-resolution visual encoder outputs into the frequency domain, similar to a Fourier transformation. This method separates high-level information, such as object structures and contours crucial for semantic understanding, from low-level details like texture and noise. By emphasizing important features and minimizing noise, this approach streamlines visual data processing. For instance, [FrequencyViT](https://openaccess.thecvf.com/content/WACV2023/papers/Li_Discrete_Cosin_TransFormer_Image_Modeling_From_Frequency_Domain_WACV_2023_paper.pdf) uses the Discrete Cosine Transform (DCT) to convert images into the frequency domain before feeding them into the Vision Transformer. This process breaks down the image into blocks and measures the energy in each block. These measurements, or "DCT coefficients," provide a concise representation of the image's energy distribution across luminance and chrominance channels, allowing for high-resolution image processing with a shorter representation sequence.
Reduction of Vision Embedding Sequence (post-processing) by implementing a sampler-based module
Another effective approach involves implementing a sampler-based module to reduce the dimensionality of visual embeddings
. Many papers use a pooling layer
to reduce the sequence length of the visual embedding ([Kosmos 2.5](https://arxiv.org/pdf/2309.11419), [Idefics2](https://arxiv.org/pdf/2405.02246) and [TextHawk](https://arxiv.org/pdf/2404.09204)). Another method to reduce the image representation dimension involves the use of learnable tokens added to image patches. These tokens serve as summarizers of visual information
, allowing the model to obtain higher semantic visual representations while reducing computational load. In the Q-Former layer
, implemented in [BLIP-2](https://arxiv.org/pdf/2301.12597), [MiniGPT-4](https://arxiv.org/pdf/2304.10592) and [InstructDr](https://arxiv.org/pdf/2401.13313) as a "Document-Former", these learnable tokens are used to capture and distill essential visual features through a process of cross-attention with the image patches, helping to extract the most relevant visual information that aligns with the textual input. Similarly, the Perceiver Resampler layer
, implemented in [Flamingo](https://arxiv.org/pdf/2204.14198), [Kosmos 2.5](https://arxiv.org/pdf/2309.11419), and [Monkey](https://arxiv.org/pdf/2311.06607) as a "shared resampler", employs learnable tokens that directly interact with image patches via cross-attention mechanisms, summarizing the visual content into a smaller set of embeddings. Another method for dimensionality reduction of visual embedding is through the use of convolution techniques. [mPLUG-DocOwl1.5](https://arxiv.org/pdf/2403.12895) employs H-Reducer as projection layer, which uses convolutional techniques to shorten the sequence length while preserving horizontal semantic coherence
, making it particularly effective for text-heavy images, as presented in .
Reduction of Vision Embedding Sequence (post-processing) by implementing token selection
Another effective way to reduce the dimensionality of visual embeddings is through token selection techniques
. [Tinychart](https://arxiv.org/pdf/2404.16635) implements a visual token merging method, which is particularly useful for charts containing many similar color blocks and blank spaces. This method merges the \(r\) most similar token pairs
, reducing the vision feature sequence length by $ r $ in each layer. Following the token merging strategy from [ToMe](https://arxiv.org/pdf/2210.09461), similarity between tokens is measured using the cosine distance between Keys from self-attention
. Tokens are divided into two sets, with each token in one set paired with its most similar token in the other set, merging features through average pooling. When tokens representing multiple patches are merged, the attention mechanism is adjusted to account for the new token 'size'. This is done by adding $ \log s $ to the attention scores, where $ s $ is a vector indicating the size of each token. This adjustment ensures the attention mechanism reflects the actual information each token represents, maintaining balanced and accurate attention distribution.
Dual approach: high and low resolution images handled in parallel (the former by a small decoder, the latter by a LLM)
**[CogAgent](https://arxiv.org/pdf/2312.08914)** employs this by using large pretrained Vision-and-Language Models (VLMs) and high-resolution small Vision Transformers (ViTs). The document image is resized to high-resolution (1120×1120) and low-resolution (224×224), processed in parallel by different-sized image encoders. The low-resolution encoder is part of the pretrained large VLM, CogVLM, which includes an EVA2-CLIP-E encoder with an MLP adapter and uses Vicuna-7b as the decoder
. In parallel, the high-resolution input is handled by a smaller ViT and cross-attention layers
. Only the high-resolution module is trained, leveraging the small ViT's ability to process higher resolution images due to its quadratic memory complexity advantage.
**[Mini-Gemini](https://arxiv.org/pdf/2403.18814)** uses a pretrained CNN as the high-resolution encoder and a CLIP-pretrained ViT for low-resolution
. It combines low and high-resolution embeddings through a nPatch Info Mining modulen
using cross-attention:  
**[LLaVA-HR](https://arxiv.org/pdf/2403.03003)** adopts a similar approach, with MR-Adapters embedding high-resolution visual information into the low-resolution modeling
to capture fine-grained semantics, as presented in this picture: 
In the Mixture-of-Resolution Adapter (MR-Adapter), the high-resolution visual features are integrated into the low-resolution visual features in each block of the Vision Transformer (ViT). Doing so, the MR-Adapter enriches the semantic content of low-resolution features. This integration of high-resolution features into the low-resolution ones is achieved using the formula \(F'_{vl} = F_{vl} + f_l(F_{vl}) + g \cdot f_h(F_{vh})\)
where $ F_vl $ is low-resolution features and $ F_vh $ is high-resolution features, $ f_l $ and $ f_h $ are mapping modules where $ f_l $ is a convolutional block that processes low-resolution features
, and $ f_h $ is an $ MLP $ (Multi-Layer Perceptron) layer that processes high-resolution features
, and $ g $ is a dynamic score that adjusts the influence of the high-resolution information
.$ g $ is determined by the pooled visual features $ f_v $, calculated from both low and high-resolution features of the image, capturing the essential visual information from both high-resolution and low-resolution pathways, averaged across the entire image : \(f_v = \frac{1}{h \times w} \sum_{i}^{h} \sum_{j}^{w} [f_l(F_{vl})^{i,j}, f_h(F_{vh})^{i,j}]\)
. Then, this $ g $ score is controlled by activation functions $ Gelu $ and $ Tanh $, and projection matrices $ W_1 $ and $ W_2 $ : \(g = Tanh(W_2 Gelu(W_1 f_v))\)
.
**[Vary](https://arxiv.org/pdf/2312.06109)** adopts the same method, which consists of two components: a "vision vocabulary network" with a high-resolution visual encoder (Pretrained ViTDet) and a tiny decoder (OPT-125M)
, and a traditional MLLM comprising a low-resolution visual encoder (CLIP) and an LLM (Vicuna-7b)
. The fine-grained encoder and tiny decoder are trained autoregressively for next-token prediction, enhancing the high-resolution visual embedding. This high-resolution visual embedding is then integrated into the frozen encoder of the MLLM, a technique Vary calls "vocabulary expansion"
. This ensures that improvements to CLIP do not introduce noise when processing natural images, thereby expanding the model's capabilities in fine-grained perception tasks.

Papers we have cited in this section
Now that we have summed up the existing method to use a fine-grained vision encoder and a LLM as decoder in VLM, you can find below the different papers we talked about in this section:
ConvLLaVA: Hierarchical Backbones as Visual Encoder for Large Multimodal Models
2024-05-24
Chunjiang Ge, Sijie Cheng, Ziming Wang, Jiale Yuan, Yuan Gao, Jun Song, Shiji Song, Gao Huang, Bo Zheng
High-resolution Large Multimodal Models (LMMs) encounter the challenges of excessive visual tokens and quadratic visual complexity. Current high-resolution LMMs address the quadratic complexity while still generating excessive visual tokens. However, the redundancy in visual tokens is the key problem as it leads to more substantial compute. To mitigate this issue, we propose ConvLLaVA, which employs ConvNeXt, a hierarchical backbone, as the visual encoder of LMM to replace Vision Transformer (ViT). ConvLLaVA compresses high-resolution images into information-rich visual features, effectively preventing the generation of excessive visual tokens. To enhance the capabilities of ConvLLaVA, we propose two critical optimizations. Since the low-resolution pretrained ConvNeXt underperforms when directly applied on high resolution, we update it to bridge the gap. Moreover, since ConvNeXt's original compression ratio is inadequate for much higher resolution inputs, we train a successive stage to further compress the visual tokens, thereby reducing redundancy. These optimizations enable ConvLLaVA to support inputs of 1536x1536 resolution generating only 576 visual tokens, capable of handling images of arbitrary aspect ratios. Experimental results demonstrate that our method achieves competitive performance with state-of-the-art models on mainstream benchmarks. The ConvLLaVA model series are publicly available at https://github.com/alibaba/conv-llava.
Show Paper Content
[^1]: Corresponding author.
# Introduction
Large Multimodal Models (LMMs; [gpt4v](https://cdn.openai.com/papers/GPTV_System_Card.pdf), [gemini](http://arxiv.org/pdf/2405.12107v1), [claude3](https://www-cdn.anthropic.com/de8ba9b01c9ab7cbabf5c33b80b7bbc618857627/Model_Card_Claude_3.pdf))
have achieved notable advancements in recent years, demonstrating
superior performance in diverse domains, including image and video
understanding [ureader](http://arxiv.org/pdf/2311.13165v1), [xc2-4k](http://arxiv.org/pdf/2404.06512v1), digital agent
development [appagent](http://arxiv.org/pdf/2312.13771v2), and
robotics [roboflamingo](http://arxiv.org/pdf/2311.01378v3). The imperative to comprehend a
wide range of tasks and intricate scenes underscores the critical role
of the visual encoder, which is mostly a Vision
Transformer (ViT; [vit](http://arxiv.org/pdf/2105.15075v2)). However, ViT’s quadratic
spatial complexity and output of excessive visual tokens limit its
application in diverse and high-resolution
tasks [ureader](http://arxiv.org/pdf/2311.13165v1), [li2023otterhd](http://arxiv.org/pdf/1102.1442v1), [xc2-4k](http://arxiv.org/pdf/2404.06512v1), [cheng2023can](http://arxiv.org/pdf/1505.06659v1). The
excessive visual tokens lead to a significant computational burden in
the Large Language Model (LLM; [llama](None), [llama2](https://doi.org/10.48550/arXiv.2307.09288)), far
exceeding the computational cost imposed by the quadratic spatial
complexity in the visual encoder. Such redundancy in the visual tokens
not only sacrifices efficiency but also impedes the effective extraction
of visual information [llava-v1-6](https://llava-vl.github.io/blog/2024-01-30-llava-next/), [xc2-4k](http://arxiv.org/pdf/2404.06512v1). While a range
of methods (Tab. [tab:table-1]; [llava-v1-6](https://llava-vl.github.io/blog/2024-01-30-llava-next/), [li2023monkey](http://arxiv.org/pdf/2103.15488v1), [vary](http://arxiv.org/pdf/2312.06109v1))
have been proposed to remedy the quadratic spatial complexity of ViT,
they fail to mitigate the key problem, the redundancy in the visual
tokens [fastv](http://arxiv.org/pdf/2403.06764v2), [lin2023vila](http://arxiv.org/pdf/2306.16774v1).
Hierarchical visual backbones [resnet](http://arxiv.org/pdf/1608.05895v1), [senet](http://arxiv.org/pdf/2209.08294v1), [davit](http://arxiv.org/pdf/2108.01778v1), which
can be considered as counterparts to ViT, can well address the problem
of excessive visual tokens due to their inherent ***Information
Compression*** process. Specifically, features are sequentially
compressed across stages in hierarchical backbones. They compress visual
features by *32$\times$* [resnet](http://arxiv.org/pdf/1608.05895v1), [liu2022convnet](http://arxiv.org/pdf/2007.00649v1) compared
to ViT with only *14$\times$* [vit](http://arxiv.org/pdf/2105.15075v2). Therefore, at the
same resolution they generate fewer than *1/4* visual tokens compared to
ViT, significantly alleviating computational burdens on the LLM.
Moreover, hierarchical visual encoders, typically designed with linear
spatial complexity [liu2022convnet](http://arxiv.org/pdf/2007.00649v1), [davit](http://arxiv.org/pdf/2108.01778v1), [resnet](http://arxiv.org/pdf/1608.05895v1),
effectively tackle both the issue of excessive visual tokens and the
quadratic visual complexity.
We choose to employ ConvNeXt among the hierarchical visual encoders due
to its excellent performance [convnext-vs-vit](https://arxiv.org/pdf/2311.09215), [fc-clip](http://arxiv.org/pdf/2308.02487v2)
and the availability of off-the-shelf contrastive language-image
pretrained weights (CLIP; [clip](http://arxiv.org/pdf/2404.19696v1)), which mainstream
visual encoders of LMMs
adopt [blip2](http://arxiv.org/pdf/2301.12597v3), [llava-v1](http://arxiv.org/pdf/2402.11690v1), [qwen-vl](http://arxiv.org/pdf/2308.12966v3), [mm1](http://arxiv.org/pdf/2403.01757v1). However, directly
replacing ViT with ConvNeXt leads to inferior performance on general
capabilities
benchmarks (Section [sec:updating]). This can be
attributed to the fact that ConvNeXt is pretrained on low resolution,
whereas we directly apply it to
high-resolution [openclip](https://doi.org/10.5281/zenodo.5143773), [laion5b](http://arxiv.org/pdf/2312.15897v1). Moreover, the
pretraining data for ConvNeXt is considered to be of low
quality [metaclip](http://arxiv.org/pdf/2309.16671v4), [openclip](https://doi.org/10.5281/zenodo.5143773), [laion5b](http://arxiv.org/pdf/2312.15897v1) compared to ViT’s
pretraining data [clip](http://arxiv.org/pdf/2404.19696v1). To address these issues, we
propose to update the visual encoder rather than freezing it.
Surprisingly, updating the visual encoder enables ConvNeXt to perform
comparably to ViT on general benchmarks. On fine-grained benchmarks, we
observe that ConvNeXt outperforms ViT. These findings indicate that even
when compressing visual tokens to an equal quantity, the higher
resolution model’s features still contain more fine-grained information.
This observation inspires us to further scale up the resolution.
However, further scaling the resolution beyond 1024 leads to the
generation of excessive visual tokens. To mitigate this issue, we
further compress the visual information with an additional ConvNeXt
stage to enhance the inherent *information compression* of hierarchical
backbones. The visual inputs would be compressed by *64$\times$* rather
than *32$\times$* to further reduce the redundancy. Hence, ConvLLaVA
generates only 576 visual tokens when processing 1536 resolution inputs,
which is equivalent to the number of visual tokens generated by ViT when
processing 336 resolution
inputs (Section [sec:add-stage]).
In summary, we introduce ConvLLaVA whose visual encoder is a five-stage
ConvNeXt. ConvLLaVA compresses high-resolution images into
information-rich visual features, effectively avoiding the generation of
excessive visual tokens (in
Tab. [tab:table-1]; [llava-v1-6](https://llava-vl.github.io/blog/2024-01-30-llava-next/), [li2023monkey](http://arxiv.org/pdf/2103.15488v1), [minigemini](http://arxiv.org/pdf/2305.16318v2), [llava-hr](http://arxiv.org/pdf/2403.03003v1)).
Furthermore, thanks to the translation equivalence of convolution,
ConvLLaVA can be trained on low-resolution and evaluated on higher
resolutions, and it can also handle images of arbitrary aspect ratio.
Extensive experiments have demonstrated the effectiveness of our method.
ConvLLaVA 7B outperforms LLaVA-1.5-13B across various benchmarks,
including MME [mme](http://arxiv.org/pdf/2306.05179v2),
MMBench [liu2023mmbench](http://arxiv.org/pdf/2005.12661v2),
SEEDBench [li2023seed](http://arxiv.org/pdf/2311.15759v1),
RealWorldQA [grok1_5](https://x.ai/blog/grok-1.5v), TextVQA [textvqa](http://arxiv.org/pdf/2003.12462v2),
DocVQA [docvqa](http://arxiv.org/pdf/2111.05547v1), POPE [pope](http://arxiv.org/pdf/2402.15721v1), and
MMVet [mmvet](http://arxiv.org/pdf/2402.15896v1).
# Related Work
**Large Multimodal Models.** To harness the potential of Large Language
Models and incorporate visual information, BLIP series
models [blip2](http://arxiv.org/pdf/2301.12597v3), [dai2023instructblip](https://arxiv.org/pdf/2305.06500) propose the Q-former,
which generates visual tokens for LLMs to interpret visual data.
Meanwhile, LLaVA [llava-v1](http://arxiv.org/pdf/2402.11690v1) employs a single linear layer
to map visual features to the word embedding space, allowing LLMs to
perceive vision features. These approaches utilize the ViT as the visual
encoder [clip](http://arxiv.org/pdf/2404.19696v1), [vit](http://arxiv.org/pdf/2105.15075v2), [honeybee](http://arxiv.org/pdf/2312.06742v2), [lin2023vila](http://arxiv.org/pdf/2306.16774v1), [minigpt](http://arxiv.org/pdf/2402.17510v1),
primarily tailored for low-resolution visual data (e.g., 224 or 336
resolution). Moreover, Qwen-VL [qwen-vl](http://arxiv.org/pdf/2308.12966v3) and
mPLUG-owl2 [mplug-owl2](http://arxiv.org/pdf/2311.04257v2) scale the resolution of ViT to
448 by updating the weights of ViT. However, these methods fail to
further scale up resolution due to the quadratic spatial complexity of
ViT, while ConvNeXt can scale up the resolution with the linear cost
increase. Qwen-VL [qwen-vl](http://arxiv.org/pdf/2308.12966v3) and
mPLUG-owl2 [mplug-owl2](http://arxiv.org/pdf/2311.04257v2) also explore to reduce the visual
tokens via resampler. However, recent
studies [honeybee](http://arxiv.org/pdf/2312.06742v2), [xc2-4k](http://arxiv.org/pdf/2404.06512v1) show that convolution or simply
concatenation performs better than resampler.
**High-resolution LMMs with Cropping.** The representative cropping
method for high-resolution LMMs is introduced in
LLaVA-NExT [llava-v1-6](https://llava-vl.github.io/blog/2024-01-30-llava-next/), which partitions an image into
four patches, each encoded separately by ViT and subsequently
concatenated for LLM processing. A collection of methods have adopted
cropping to scale up
resolution [ureader](http://arxiv.org/pdf/2311.13165v1), [lin2023sphinx](http://arxiv.org/pdf/2311.07575v1), [li2023monkey](http://arxiv.org/pdf/2103.15488v1), [xc2-4k](http://arxiv.org/pdf/2404.06512v1).
While effective in reducing ViT complexity, cropping compromises the
structural integrity of the image, thus potentially impacting overall
performance. Moreover, the proliferation of visual tokens introduced by
cropping poses significant complexity on LLMs and challenges the
retrieval capabilities of LLMs [xc2-4k](http://arxiv.org/pdf/2404.06512v1).
**High-resolution LMMs with Extra Visual Encoders.** Incorporating an
auxiliary visual encoder for high-resolution image understanding would
not significantly increase the number of visual tokens.
Vary [vary](http://arxiv.org/pdf/2312.06109v1) and Deepseek-VL [deepseek-vl](http://arxiv.org/pdf/2402.17510v1)
utilize SAM [sam](http://arxiv.org/pdf/2305.01275v1) as a high-resolution visual encoder to
augment the feature of ViT. MiniGemini-HD [minigemini](http://arxiv.org/pdf/2305.16318v2)
and LLaVA-HR [llava-hr](http://arxiv.org/pdf/2403.03003v1) employ
ConvNeXt [openclip](https://doi.org/10.5281/zenodo.5143773) to process high-resolution images and
use cross-attention or adapters to extract features from the
high-resolution input. However, these methods introduce additional
complexity through supplementary visual encoders and associated
hyperparameters. Furthermore, extracting features from low-quality
representations (e.g., LAION-CLIP-ConvNeXt) may potentially compromise
LMMs’ performance [gadre2024datacomp](http://arxiv.org/pdf/2004.12070v2), [metaclip](http://arxiv.org/pdf/2309.16671v4).
# ConvLLaVA [sec:method]
We present ConvLLaVA, as illustrated in
Fig. 1 (b), whose visual encoder is a
five-stage ConvNeXt. We first introduce the overall architecture and the
advantages of our ConvLLaVA in
Section 1.1. The two major optimizations:
updating the visual encoder and training an additional stage are
introduced in Section 1.2 and
Section 1.3.
## ConvNeXt as Standalone Visual Encoder [sec:convllava]
The architecture of ConvLLaVA is identical to most popular general LMMs,
*e.g.*, LLaVA [llava-v1](http://arxiv.org/pdf/2402.11690v1), [llava-v1-5](http://arxiv.org/pdf/2310.19145v1),
Qwen-VL [qwen-vl](http://arxiv.org/pdf/2308.12966v3), and VILA [lin2023vila](http://arxiv.org/pdf/2306.16774v1).
These models comprise three components as shown in
Fig. 1 (a): a vision encoder $g()$, a
large language model $f()$, and a vision-language projector $h()$.
Specifically, the vision model encodes the visual inputs $\vx$ into
latent visual embeddings $g(\vx)$. The vision-language projector then
maps the latent visual embeddings into the embedding space of the
language model $\vz = h(g(\vx))$. Given the visual embeddings $\vz$ and
text embeddings $\vt$ encoded by the language tokenizer, these
embeddings are concatenated along the sequence dimension and then passed
to the language model. Finally, the vision language model is trained
with language modeling loss [gpt](http://arxiv.org/pdf/2310.01427v1). Considering that our
study mainly focuses on the visual encoder, we employ a two-layer MLP
and Vicuna-7B [vicuna](http://arxiv.org/pdf/2306.05685v4) as the projector and language
model following LLaVA-1.5 [llava-v1-5](http://arxiv.org/pdf/2310.19145v1). Rather than using
CLIP-VIT [clip](http://arxiv.org/pdf/2404.19696v1), we introduce
CLIP-ConvNeXt [liu2022convnet](http://arxiv.org/pdf/2007.00649v1), [openclip](https://doi.org/10.5281/zenodo.5143773) as the standalone
visual encoder.
r0.4
**ConvNeXt.** The basic block of ConvNeXt comprises a depth-wise
convolution and a feed-forward network [liu2022convnet](http://arxiv.org/pdf/2007.00649v1).
The depth-wise convolution has a *7$\times$``{=html}7* kernel
size, and the computation complexity is $\mathcal{O}(k^2CN)$, where $k$,
$C$, and $N$ are the kernel size, number of channels, and number of
visual tokens, respectively. In contrast, the complexity of
self-attention in ViT is $\mathcal{O}(4C^2N+2CN^2)$. Consequently, the
spatial complexity of ConvNeXt is significantly lower than ViT. The
input is initially processed by a *4$\times$``{=html}4*
non-overlapping convolution downsampling layer. Subsequently, the
features are successively fed into the four stages of ConvNeXt, while
each stage comprises several ConvNeXt blocks. Feature maps are
downsampled by *2$\times$*, and dimensions are expanded by *2$\times$*
between stages. The output of the ConvNeXt is downsampled by
*32$\times$*, rather than *14$\times$* of ViT-L. Hence, ConvNeXt
produces less than *1/4* visual tokens compared to ViT, which alleviates
the computation load of the language model. Benefiting from the linear
spatial complexity and fewer visual tokens, the computation reduction of
LMMs from ViT-L (red line) to ConvNeXt
(blue line) is almost *8$\times$* as
illustrated in Fig. [fig:quality].
**Five-stage ConvNeXt$\dag$.** Leveraging ConvNeXt as the visual encoder
is efficient for encoding 768 resolution images, while scaling
resolutions to higher than 768 produces excessive visual tokens.
Previous studies [llava-v1-6](https://llava-vl.github.io/blog/2024-01-30-llava-next/), [minigemini](http://arxiv.org/pdf/2305.16318v2) neglect to
explore compressing visual tokens, while compressing visual tokens has
been proven to be reasonable since there is redundancy in the visual
representation [lin2023vila](http://arxiv.org/pdf/2306.16774v1), [fastv](http://arxiv.org/pdf/2403.06764v2). These studies suggest
that we can further downsample visual features using ConvNeXt. We
propose to compress visual features by incorporating ConvNeXt blocks for
stage 5 into the original four-stage model. We prefer using ConvNeXt
blocks over other structures due to the following three reasons (1) The
five-stage ConvNeXt, as a whole, could be transferred as a visual
encoder for other LMMs, whereas downsampling in the projector does not
offer such flexibility (2) ConvNeXt blocks maintain translation
equivariance, allowing them to effectively process images of any aspect
ratio, unlike attention blocks. (3) The impact on performance from the
downsampling stage is minimal, except that the resampler consistently
underperforms compared to other methods, as evidenced
by [honeybee](http://arxiv.org/pdf/2312.06742v2), [xc2-4k](http://arxiv.org/pdf/2404.06512v1), [mm1](http://arxiv.org/pdf/2403.01757v1). Finally, we denote the overall
five-stage ConvNeXt as ConvNeXt$\dag$. At 1536 resolution,
ConvNeXt$\dag$ reduces the number of visual tokens to 576, equivalent to
that of ViT at 336 resolution. This would reduce the total computation
by *6$\times$* *w.r.t.* the original ConvNeXt
(blue line) to ConvNeXt$\dag$
(green line) as shown in
Fig. [fig:quality]. Our approach is more
computationally efficient than cropping methods, which often produce an
excessive number of visual
tokens [mm1](http://arxiv.org/pdf/2403.01757v1), [llava-v1-6](https://llava-vl.github.io/blog/2024-01-30-llava-next/), [li2023monkey](http://arxiv.org/pdf/2103.15488v1). Furthermore, by
eliminating the need for cropping and merging, ConvLLaVA avoids the
global view, thereby further reducing the number of visual tokens.
## Updating ConvNeXt is Essential [sec:updating]
The mainstream optimization
approach [llava-v1](http://arxiv.org/pdf/2402.11690v1), [lin2023vila](http://arxiv.org/pdf/2306.16774v1) freezes the vision
encoder during training, as it has better performance and is more
efficient than updating the visual encoder [prismatic](http://arxiv.org/pdf/2402.07865v1).
However, freezing ConvNeXt during training is sub-optimal. Hence, we
conduct depth analysis to prove that freezing the visual encoder (i.e.,
ConvNeXt) would inherit the defects from pretraining, and updating
ConvNeXt may both improve the quality of representations and adapt them
to high-resolution inputs.
**Setups of Freezing ConvNeXt.** The optimization procedure is the same
as LLaVA-1.5 [llava-v1-5](http://arxiv.org/pdf/2310.19145v1). For training the projector and
instruction tuning, we use the same 558k caption dataset and 665k
instruction data, respectively. Our visual encoder CLIP-ConvNeXt-L is
pretrained on 256 resolution and fine-tuned with 320 resolution based on
LAION-2B [liu2022convnet](http://arxiv.org/pdf/2007.00649v1), [openclip](https://doi.org/10.5281/zenodo.5143773). We directly increase
the resolution to 512 and 768 when applying ConvNeXt as the vision
encoder. As for the baseline, we use ViT which is pretrained on 336
resolution with OpenAI WIT dataset [clip](http://arxiv.org/pdf/2404.19696v1). The training
and inference speed for ConvNeXt on 768 resolution is on par with ViT on
336 resolution. Hence, we consider the comparison between 768-resolution
ConvNeXt and 336-resolution ViT to be fair. Detailed training procedure
is shown in Tab. [tab:hy-llava].
**Benchmarks.** We use four standard benchmarks to evaluate the results:
two general capability benchmarks,
MMbench [liu2023mmbench](http://arxiv.org/pdf/2005.12661v2),
SEEDBench [li2023seed](http://arxiv.org/pdf/2311.15759v1), and two fine-grained OCR
benchmarks, TextVQA [textvqa](http://arxiv.org/pdf/2003.12462v2) and
DocVQA [docvqa](http://arxiv.org/pdf/2111.05547v1). It is worth noting that our evaluation
procedure for TextVQA differs slightly from
LLaVA-1.5 [llava-v1-5](http://arxiv.org/pdf/2310.19145v1), as we use VLMEVALKIT which does
not include OCR tokens in the question.
**Results for Freezing the Visual Encoder.** As shown in
Tab. [tab:freezing-encoder], we
observe the following results:
\(1\) ConvNeXt has significant advantages over ViT on OCR benchmarks. On
TextVQA and DocVQA, both 512 and 768 resolution ConvNeXt outperforms ViT
due to their higher resolution [prismatic](http://arxiv.org/pdf/2402.07865v1), [mplug-owl2](http://arxiv.org/pdf/2311.04257v2).
Even with fewer visual tokens, the 512-resolution ConvNeXt still
outperforms the 336-resolution ViT.
\(2\) The overall general capability of ConvNeXt is inferior to ViT. For
general benchmarks, on SEEDBench, 768-resolution ConvNeXt performs
comparably with ViT. While on MMBench, ConvNeXt underperforms ViT. We
hypothesize that there are two reasons for the performance gap on
MMbench: First, ConvNeXt is pretrained on low resolution but directly
applied on high resolution. Such employment affects the quality of
visual features. Second, the pretrained representation for ConvNeXt may
be inferior to OpenAI’s ViT [clip](http://arxiv.org/pdf/2404.19696v1).
The results imply that increasing resolution without training could
affect the quality of representation and hamper the performance of LMMs.
However, studies have shown that simply updating the visual encoder
during instruction tuning can hinder
performance [prismatic](http://arxiv.org/pdf/2402.07865v1). To mitigate this issue,
ShareGPT4V [sharegpt4v](http://arxiv.org/pdf/1809.10312v1) provides an effective training
protocol and a high-quality dataset for updating the visual encoder.
Therefore, we adopt this effective method to update the visual encoder.
**Setups of Updating ConvNeXt.** To update the visual encoder, we first
leverage the 558k caption dataset for projector
initialization [llava-v1-5](http://arxiv.org/pdf/2310.19145v1). Then, we apply a
high-quality caption dataset, ShareGPT4V-PT [sharegpt4v](http://arxiv.org/pdf/1809.10312v1),
to train the entire vision-language model including the visual encoder.
Finally, the LLaVA 665k instruction tuning dataset is used for visual
instruction tuning. The detailed training procedure is shown
in Tab. [tab:hy-sharegpt4v]. The last 12
layers of ViT-L are trainable (according to
ShareGPT4V [sharegpt4v](http://arxiv.org/pdf/1809.10312v1)). For ConvNeXt, we update the
last 18 blocks (ConvNeXt-L has a total of 36 blocks).
**Results for Updating the Visual Encoder.** As shown in
Tab. [tab:ShareGPT4V], we observe the
following results:
\(1\) ConvNeXt has significant advantages over ViT on the OCR benchmark.
The improvement for 768 resolution ConvNeXt is larger than 336
resolution ViT (6.3/10.4 *v.s.* 4.6/5.2). These results demonstrate the
idea of compressing high-resolution visual inputs to a small
number (*e.g.*, 576) of information-rich visual tokens is feasible.
Compressing does not lead to great information loss. Even with the same
number of tokens, ConvNeXt preserves more fine-grained visual
information and significantly outperforms ViT.
\(2\) For general benchmarks, ConvNeXt performs on par with ViT.
Specifically, ConvNeXt outperforms ViT on SEEDBench and performs on par
with ViT on MMBench. Notably, the performance gap between the 768
resolution ConvNeXt and the 336 resolution ViT on MMBench is narrowed
from 3.3 to 0.3 compared with freezing the visual encoder. This implies
that updating the visual encoder is essential. To further support this,
we show the results of updating the visual encoder with more data in
Appendix [app:more-data].
Generally, the updated ConvNeXt performs better than ViT on these 4
benchmarks. This evidences that updating the ConvNeXt significantly
enhances the performances, underscoring its critical importance.
Previous methods employ ConvNeXt as an auxiliary visual encoder and
directly increase the resolution to 1024 [llava-hr](http://arxiv.org/pdf/2403.03003v1) or
1536 [minigemini](http://arxiv.org/pdf/2305.16318v2). They fail to identify the problem that
scaling up the resolution without updating ConvNeXt would compromise the
performance. Our method, delving deeper into the root of the issue,
provides a simple yet effective solution to scaling up the resolution.
## Training with Stage 5 Scales up Resolution to 1536 [sec:add-stage]
As we mentioned in
Section 1.1, scaling resolution to higher
than 768 would generate excessive visual tokens. To reduce the
redundancy and mitigate the excessive computational demands on the large
language model (LLM), we propose training stage 5 for the ConvNeXt model
to compress the visual information (training protocol shown in
Fig. 1 (c)).
**Implementation Details.** We employ a three-stage training protocol.
In the projector initialization stage, we train the fifth stage layers
and the projector with the ShareGPT4V-PT
data [sharegpt4v](http://arxiv.org/pdf/1809.10312v1). In the second stage, we train the
entire model with the ShareGPT4V-PT data. For instruction tuning, we
utilize the 665k LLaVA instruction data to train the LLM and the
projector. The training protocol is similar to the protocol for updating
the visual encoder. The only difference is that we train the fifth stage
and projector with ShareGPT4V-PT data, while experiments in
Section 1.2 train the projector with the 558k
caption data in the first training stage. We add 6 layers in stage 5 and
tune the last three stages in the second training phase. Ablation
studies on these hyper-parameters are included in
Appendix [app:stage-add-layers].
**Results for ConvNeXt$\dag$.** We present the results of adding stage 5
to ConvNeXt in Tab. [tab:add-stage]. Scaling up the
resolution consistently improves performance on SEEDBench, TextVQA, and
DocVQA, which require fine-grained understanding and benefit from the
higher resolution. These results highlight the effectiveness of our
method of training stage 5. However, on MMBench, the performance of
ConvNeXt$\dag$ exhibits a slight drop when scaling the resolution from
1024 to 1536. The resolution of 1536 is approximately six times higher
than the pretraining resolution (256). Adapting the pretrained visual
encoder to effectively extract global information from such a
significant increase in resolution requires a substantial amount of
training data. In Section [sec:exp], we verify this hypothesis by
providing sufficient data to the visual encoder in the second training
stage.
Comparisons of ConvNeXt and ConvNeXt† on SEEDBench and DocVQA. The marked number
above the line shows the resolution of the model.
**On Scaling Resolution.** When we increase the resolution, the number
of visual tokens also increases. These two factors are entangled, and
there has been a lack of in-depth investigation into the relationship
between them. Previous work claims that raw resolution matters more than
the number of visual tokens [lin2023vila](http://arxiv.org/pdf/2306.16774v1). We experiment
on the general benchmark SEEDBench and OCR benchmark DocVQA to
investigate these assumptions. Our method provides control experiments
to reveal the relationship between resolution and the number of visual
tokens. We compare the results of ConvNeXt (trained in
Section 1.2) and ConvNeXt$\dag$ (trained in
Section 1.3) as the visual encoder for LMMs
under the same number of visual tokens. The two series of models are
pretrained with ShareGPT4V-PT and instruction-tuned with 665k LLaVA
instruction data. ConvNeXt$\dag$ has an additional stage to compress the
number of visual tokens to 1/4. Hence, the differences between these two
series models have been largely reduced. Our control experiments reveal
novel findings:
\(1\) When the number of visual tokens is the same, the higher
resolution model exhibits better performance on SEEDBench and DocVQA. In
the Fig.2, the green line
consistently outperforms the blue line. This is because that
high-resolution model provides finer-grained and higher-quality visual
features even if the output number of visual tokens is the same.
Previous work [llava-v1-6](https://llava-vl.github.io/blog/2024-01-30-llava-next/), [li2023monkey](http://arxiv.org/pdf/2103.15488v1), [xc2-4k](http://arxiv.org/pdf/2404.06512v1) which
scales up the resolution by splitting the image into patches would
generate excessive visual tokens. Such cropping methods significantly
sacrifice efficiency and challenge the retrieval capability of LLM. Our
core discovery presents a promising approach to enrich the information
contained in visual features without compromising efficiency.
Compressing high-resolution images into information-rich visual tokens
is more efficient than the cropping method. Training a stage to further
compress visual features provides a manner to increase resolution and
maintain a moderate computational cost.
\(2\) The importance of the number of visual tokens varies across
different benchmarks at equivalent resolution. For general benchmarks
like SEEDBench, the performance drop brought by compressing visual
tokens for the 768-resolution models is marginal (0.9 on SEEDBench).
However, for OCR benchmarks like DocVQA, the performance drop for the
model with fewer visual tokens is substantial (9.1 on DocVQA). Overall,
these results demonstrate that while compressing visual tokens causes
only slight information loss on general benchmarks, but leads to
significant information loss on fine-grained OCR benchmarks.
# Experiments [sec:exp]
Our results demonstrate that scaling up the resolution of ConvNeXt and
updating the visual encoder are two effective approaches to training an
advanced, high-resolution Language-Multimodal Model. However, we found
that the available training data was insufficient to fully unleash the
potential of these approaches. Consequently, we scaled up the
high-quality training data to address this limitation.
## Training Setups
**Training Stages.** We adopt a three-stage training protocol to train
ConvLLaVA as shown in
Fig. [fig:structure] (c). The training
process is categorized into three stages: (1) *Projector
Initialization.* We train the fifth stage of the ConvNeXt model and the
vision-language projector. We utilize caption data including
ShareGPT4V-PT [sharegpt4v](http://arxiv.org/pdf/1809.10312v1),
ShareGPT4V [sharegpt4v](http://arxiv.org/pdf/1809.10312v1), and ALLaVA
captions [allava](http://arxiv.org/pdf/2112.07133v2), totaling approximately 2M examples.
(2) *Vision-Language Pretraining.* We employ caption data including
ShareGPT4V-PT [sharegpt4v](http://arxiv.org/pdf/1809.10312v1),
ShareGPT4V [sharegpt4v](http://arxiv.org/pdf/1809.10312v1), ALLaVA [allava](http://arxiv.org/pdf/2112.07133v2),
and a 190k open-sourced subset of VFLAN [vflan](http://arxiv.org/pdf/2403.04343v1),
amounting to 2.9M data. (3) *Visual Instruction Tuning.* We fine-tune
the model with the 665k LLaVA instruction
dataset [llava-v1-5](http://arxiv.org/pdf/2310.19145v1). In each stage, we train the model
for 1 epoch with the AdamW optimizer. The cosine learning rate schedule
is also applied.
**Implementation Details.** We utilize the LAION-2B pretrained
ConvNeXt-L model as our visual encoder [openclip](https://doi.org/10.5281/zenodo.5143773). In the
three training stages, the resolution is scaled up to a fixed value. We
train ConvLLaVA at 768, 1024, and 1536 resolutions. The learning rates
in the three training stages are 3e-4, 2e-5, and 2e-5, respectively.
Meanwhile, the batch sizes are 256, 256, and 128. Training the ConvLLaVA
768 resolution model takes approximately 18 hours on 2 A800 machines.
The instruction tuning costs 20 hours for LLaVA-NExT 7B on an A100
machine [llava-v1-6](https://llava-vl.github.io/blog/2024-01-30-llava-next/), while it tasks only 9 hours for our
1536 resolution ConvLLaVA on a single machine.
**Evaluation Benchmarks.** To systematically investigate the performance
of our model, we include more benchmarks for evaluation, including
MME [mme](http://arxiv.org/pdf/2306.05179v2), MMBench [liu2023mmbench](http://arxiv.org/pdf/2005.12661v2),
SEEDBench [li2023seed](http://arxiv.org/pdf/2311.15759v1),
MMMU [yue2023mmmu](http://arxiv.org/pdf/2311.16502v3), MMVet [mmvet](http://arxiv.org/pdf/2402.15896v1),
RealWorldQA [grok1_5](https://x.ai/blog/grok-1.5v), TextVQA [textvqa](http://arxiv.org/pdf/2003.12462v2),
DocVQA [docvqa](http://arxiv.org/pdf/2111.05547v1), and POPE [pope](http://arxiv.org/pdf/2402.15721v1). Our
results are measured by VLMEVALKIT. We also assess the performance on
grounding benchmarks, including RefCOCO [refcoco](http://arxiv.org/pdf/1808.08754v1),
RefCOCO+, and RefCOCOg [refcocog](http://arxiv.org/pdf/1511.02283v3).
## Quantitative Results
We perform a comprehensive comparison with state-of-the-art models on 7
different benchmarks (Tab. [tab:main]). Our model achieves consistent
improvements compared to LLaVA-1.5. Our 7B model even exhibits
comparable performance with LLaVA-1.5 13B and LLaVA-NExT
7B [llava-v1-6](https://llava-vl.github.io/blog/2024-01-30-llava-next/). On OCR benchmarks like TextVQA and
DocVQA, our model outperforms the LLaVA-1.5 7B and 13B models. Since OCR
benchmarks are sensitive to resolution, our ConvLLaVA series models
demonstrate consistent improvement on TextVQA and DocVQA with higher
resolution, showcasing the effectiveness of scaling up resolution.
Notably, our model surpasses Qwen-VL-Chat on DocVQA which has millions
of document training data. While there is only a limited number of
document data in our training dataset. This shows the benefits of the
high-resolution design of our model. ConvLLaVA outperforms LLaVA-NExT on
MMBench, TextVQA, POPE, and MMVet.
For grounding benchmarks, our model and LLaVA are trained with the same
set of grounding data. The comparison between them is fair. On RefCOCO,
RefCOCO+, and RefCOCOg, ConvLLaVA exhibits consistent improvement when
increasing
resolution (Tab. 1). ConvLLaVA outperforms LLaVA-7B
and 13B model on all 8 test splits. This demonstrates the benefits of
higher resolution for grounding tasks. Our 7B model also surpasses 13B
LLaVA model on all 8 benchmarks.
## Understanding Any Aspect Ratio Images and Highre Resolutions
Thanks to the translation equivalence of convolution neural network, our
model could be trained on a fixed resolution but inference on higher
resolution and with an arbitrary aspect ratio. We test such ability on
our 1536 resolution model ConvLLaVA.
The original image preprocessing process is padding the image to a
square, resizing the image to 1536, and center
cropping [llava-v1-5](http://arxiv.org/pdf/2310.19145v1). We canceling padding and center
cropping. Hence, the short side of the image should just be resized to
1536 and keep the original aspect ratio. This is the setting of how we
test images of any aspect ratio. The results are shown in
Tab. [tab:shape]. We observe that on the
general benchmark, SEEDBench, the performance slightly decreases. On OCR
benchmarks, especially on DocVQA, the performance is improved. The
reason for this we think is that the image aspect ratio in DocVQA is not
1:1, forcely transforming the image into a square would lower the
resolution of the image.
We also test ConvLLaVA when resizing the short side of images to 1664
resolution which is higher than its pretrained 1536 resolution. We
observe that on DocVQA the performance could be further improved to
65.7.
## Discussions [sec:discussions]
**Architectures and data.** While we have demonstrated the effectiveness
of our method, there remains room for further improvement. The ConvNeXt
architecture we use is tailored for low-resolution image understanding
(e.g., 256), with a kernel size of 7 optimized for such resolutions.
However, as the resolution increases to 1536, the relatively small
kernel size may limit the model capacity when the resolution is
extremely high. Besides, the number of layers in the ConvNeXt four
stages (3, 3, 27, 3) is designed for a 4-stage model and may not be
optimal for our 5-stage model. Therefore, a potential future direction
could involve designing a five-stage, linear spatial complexity,
hierarchical high-resolution vision encoder. We emphasize the critical
role of the five-stage visual encoder since it is fit for
high-resolution LMM. It compresses visual features by *64$\times$*,
greatly reducing the redundancy in its visual tokens. In contrast,
four-stage visual encoders, designed for traditional computer vision
tasks, output excessive tokens when resolution is high.
**Linear spatial complexity and information compression.** We identify
*linear spatial complexity* and *information compression* procedure as
two critical properties for future visual encoders of LMMs. These
properties ensure the efficiency of both the visual encoder and the LLM,
respectively. Furthermore, they are crucial for multi-image, interleaved
image and text, and video understanding tasks, as these tasks commonly
result in numerous visual tokens. We anticipate that future research
will focus more on these two directions to further advance the research
of LMMs.
**Trade-off between compression and retrieval for high-resolution
understanding.** Our method, ConvLLaVA, compresses a 1536-resolution
image to 576 visual tokens with a 64$\times$ compression ratio. While
concurrent work [xc2-4k](http://arxiv.org/pdf/2404.06512v1), [internvl1.5](http://arxiv.org/pdf/2404.16821v2) explores retrieving
fine-grained image information from long visual token sequences. In the
context of high-resolution image understanding, compressing visual
information maintains computational efficiency, but excessive
compression may lead to information loss. Conversely, retaining a large
number of visual tokens avoids information loss but sacrifices
efficiency and challenges the retrieval capabilities of LLMs.
Consequently, a trade-off emerges between visual information compression
and retrieval capabilities for high-resolution understanding. Future
research should explore an optimal balance between these two factors.
# Conclusion
In this paper, we have critically examined the limitations of the visual
encoder for current LMMs: quadratic spatial complexity and numerous
visual tokens. The excessive visual tokens are the more fundamental
problem. These drawbacks hinder LMMs from efficiently understanding
high-resolution images. Consequently, we propose ConvLLaVA, whose visual
encoder is a hierarchical backbone, ConvNeXt, to mitigate this issue.
ConvLLaVA compresses high-resolution visual information into
information-rich visual representation rather than preserving all the
redundancy in the visual representation. Extensive experimental results
have demonstrated the efficacy of our proposed method. Our 7B parameter
model exhibits superior performance compared to the LLaVA-1.5 13B model.
Furthermore, our method is flexible in encoding images with arbitrary
shapes and resolutions. Our work highlights the advantages of
hierarchical visual backbones for LMMs, addressing critical challenges
while maintaining simplicity and efficiency.
# Acknowledgments [acknowledgments]
This work is supported in part by the National Natural Science
Foundation of China under Grants 62321005 and 62276150.
# Training Visual Encoder with More Data [app:more-data]
In Section [sec:updating], we observe that
updating the visual encoder is essential for ConvNeXt as the standalone
encoder. We compare the two visual encoders with more training data in
Tab. [tab:allava-sharegpt4v]. For
the visual language training stage, we use ALLaVA and ShareGPT4V-PT. We
train the last two stages for ConvNeXt and the last 12 layers for ViT.
With more training data, ConvNeXt outperforms ViT on all the 4
benchmarks. These results validate the advantages of ConvNeXt over ViT.
This ConvNeXt model even outperforms the 768-resolution ConvLLaVA model
on some benchmarks due to its higher number of visual tokens. However,
the training and inference speed is much slower than the 768-resolution
ConvLLaVA model due to the increased number of visual tokens. The 1536
resolution ConvLLaVA, featuring outputting the same number of visual
tokens, outperforms this model. This shows higher resolution model may
have a higher model capacity to learn from data.
# Hyperparameters for 5-stage ConvNeXt [app:stage-add-layers]
We discuss the choice of hyperparameters in this section.
**Number of Trained Stages.** We conduct an ablation study to determine
the optimal number of stages for vision-language pretraining at 768
resolution. We find that fine-tuning from stage 3 yields better results
than fine-tuning from stage 4
(Tab. [tab:stages-high]). While the
performances of fine-tuning from stage 2 and stage 3 are comparable, we
opt for fine-tuning from stage 3 due to its fewer trainable parameters.
**Number of Layers in Stage 5.** We ablate on the number of ConvNeXt
layers in stage 5. Given that the number of layers in each stage is a
multiple of 3 in ConvNeXt-L, we experiment with 3, 6, and 9 layers in
stage 5. For simplicity, we perform the experiments on ConvNeXt 768. We
observe a slight decrease in performance when adding 9 layers in stage 5
(Tab. [tab:ablation-layers]).
However, it’s hard to determine whether adding 3 or 6 layers is more
beneficial for these four benchmarks. Hence, we conduct experiment on
the 1536 resolution to further investigate this
hyperparameter (Tab. [tab:add-layers-1536]). The
results show that adding 6 layers could be better. We opt for 6 layers
in our experiments.
# Training protocol for each experiment [app:implementations]
The detailed training hyper-parameters are shown in the following
tables.
| Training Stage | 1 | 2 |
|:---------------:|:--------------:|:--------------:|
| Visual Encoder | | |
| Projector | | |
| LLM | | |
| data | LLaVA LCS-558K | LLaVA SFT 665k |
| lr | 1e-3 | 2e-5 |
| batch size | 256 | 128 |
| lr schedule | cosine decay | cosine decay |
| lr warmup ratio | 0.03 | 0.03 |
| epoch | 1 | 1 |
| optimizer | AdamW | AdamW |
The training protocol for
Tab. [tab:freezing-encoder].
Modern LVLMs still struggle to achieve fine-grained document understanding, such as OCR/translation/caption for regions of interest to the user, tasks that require the context of the entire page, or even multiple pages. Accordingly, this paper proposes Fox, an effective pipeline, hybrid data, and tuning strategy, that catalyzes LVLMs to focus anywhere on single/multi-page documents. We introduce a novel task to boost the document understanding by making LVLMs focus attention on the document-level region, such as redefining full-page OCR as foreground focus. We employ multiple vision vocabularies to extract visual hybrid knowledge for interleaved document pages (e.g., a page containing a photo). Meanwhile, we render cross-vocabulary vision data as the catalyzer to achieve a full reaction of multiple visual vocabularies and in-document figure understanding. Further, without modifying the weights of multiple vision vocabularies, the above catalyzed fine-grained understanding capabilities can be efficiently tuned to multi-page documents, enabling the model to focus anywhere in both format-free and page-free manners. Besides, we build a benchmark including 9 fine-grained sub-tasks (e.g., region-level OCR/summary, color-guided OCR) to promote document analysis in the community. The experimental results verify the superiority of our model.
Show Paper Content
# Introduction [intro]
Recently, research on Large Vision-Language
Models [GPT4](https://arxiv.org/pdf/arXiv preprint arXiv:2303.08774), [minigpt4](http://arxiv.org/pdf/2402.17510v1), [Flamingo](http://arxiv.org/pdf/2205.07065v1) has been an attractive
direction. These models not only easily handle some conventional vision
tasks (*e.g.*, Image Caption [coco_text](http://arxiv.org/pdf/1707.08831v1),
OCR [OCRVQA](http://arxiv.org/pdf/2010.02582v1)), but also demonstrate powerful reasoning
capabilities like humans.
The LVLMs mostly give responses by leveraging large language
models [OPT](http://arxiv.org/pdf/2405.04515v2), [vicuna](https://lmsys.org/blog/2023-03-30-vicuna/), [T5](http://arxiv.org/pdf/1910.10683v4) to follow language instructions
while referring to the vision vocabulary to understand the input image.
Some researchers attempt to adopt LVLMs to advance the understanding of
large-resolution (*e.g.*, 833$\times$``{=html}1132) document
pages. For example, UReader [ye2023ureader](http://arxiv.org/pdf/2311.13165v1) crops the
input image into smaller patches to align with a CLIP-style vision
vocabulary of input size 224$\times$``{=html}224. Later,
TextMonkey [liu2024textmonkey](http://arxiv.org/pdf/2403.14252v1) divides the input image
into 448$\times$``{=html}448 patches and uses Openclip’s
ViT-bigG [openclip_ilharco_2024_10469088](openclip_ilharco_2024_10469088) along with a
resampling strategy to retain useful image tokens.
LLaVA-NeXT [liu2024llavanext](https://llava-vl.github.io/blog/2024-01-30-llava-next/) adopts CLIP-ViT-L-336px to
perform visual perception and splits the input image into smaller
patches to encode independently.
InternVL-V1.5 [chen2024far_intervl1.5](http://arxiv.org/pdf/2404.16821v2) proposes a
stronger vision vocabulary InternViT-6B with the input size of
448$\times$``{=html}448. Similarly, to capture more details of
the input image, InternVL-V1.5 [chen2024far_intervl1.5](http://arxiv.org/pdf/2404.16821v2)
dynamically divides the input image into 1 to 12 tiles. Different from
the methods above, without cropping patches,
Vary [wei2023vary](http://arxiv.org/pdf/2312.06109v1) writes an extra
SAM-style [SAM](http://arxiv.org/pdf/2305.01275v1) vision vocabulary specific to document
and chart data, running in parallel with the CLIP branch. Vary can
directly encode 1024$\times$``{=html}1024 page into 256 image
tokens with a high compression ratio.
The patch-based
models [ye2023ureader](http://arxiv.org/pdf/2311.13165v1), [liu2024textmonkey](http://arxiv.org/pdf/2403.14252v1), [liu2024llavanext](https://llava-vl.github.io/blog/2024-01-30-llava-next/), [chen2024far_intervl1.5](http://arxiv.org/pdf/2404.16821v2)
mostly employ CLIP-style vision vocabulary with small resolution, so a
large-scale document needs to be decomposed into many patches/tiles. A
patch/tile is independently encoded to 256 image tokens, and
InternVL-V1.5 [chen2024far_intervl1.5](http://arxiv.org/pdf/2404.16821v2) even produces
3,328 image tokens during training. However, numerous image tokens are
difficult to extend to multi-page documents for contextual
understanding. More importantly, there may still be dense characters on
these cropped patches, but CLIP-style vision vocabulary compresses
limited sparse information of small input images via global contrastive
learning, preventing these models from losslessly recovering the content
of the original document (, full-page OCR). Although
Vary [wei2023vary](http://arxiv.org/pdf/2312.06109v1) enjoys a high compression ratio and
avoids cropping patches by directly encoding the document page, the lack
of full collaboration across multiple vision vocabularies limits the
performance. For example, given an input document page,
Vary [wei2023vary](http://arxiv.org/pdf/2312.06109v1) tends to only activate the SAM-style
ViT branch due to the specific-vocabulary visual bias. In addition, the
above models are sensitive to document format (*e.g.*, multi-column) and
do not support fine-grained user interaction on specific regions on
documents.
Another key point for the document understanding is how to carry out
fine-grained interaction, such as OCR/summarizing/captioning a region of
interest. Actually, LVLMs with human-like referential dialogue
capability for natural scenes have been investigated, such as
Shikra [chen2023shikra](http://arxiv.org/pdf/2306.15195v2) and
ChatSpot [zhao2023chatspot](http://arxiv.org/pdf/2307.09474v1). They introduce referring
spatial coordinates to refer to the special region of the input natural
image, lifting the user experience and leading to more precise
conversations. But these models can not handle the document images due
to vision vocabulary CLIP-ViT [CLIP_radford2021learning](http://arxiv.org/pdf/2404.19696v1)
which is specific to natural scenes and has low input resolution.
Besides, CLIP-style pre-training method based on
Laion-COCO [schuhmann2021laion](http://arxiv.org/pdf/2111.02114v1) (image-phrase pairs) only
weakly write sparse visual knowledge, leading to a gap in understanding
the dense document. Thus, we may ask: *Can we devise an effective and
efficient pipeline for LVLMs to achieve the fine-grained multi-page
document understanding?*
In this paper, we propose Fox, an effective pipeline, hybrid data, and
tunning strategy, giving a pleasing answer to the above question. The
proposed Fox efficiently catalyzes the LVLM’s attention to anywhere on
single/multi-page documents in a user-friendly manner. Our solution has
three highlights: 1) *Focusing anywhere:* We introduce a novel task that
boosts document understanding by focusing on the region of interest via
fine-grained position-aware prompts, *i.e.*, click points, dragged
bounding boxes, and drawn color boxes. Notably, the dense full-page OCR
sub-task can be further optimized by being redefined as foreground
focus. 2) *Full reaction across multiple vision vocabularies:* To fully
interpret hybrid visual knowledge on interleaved document pages, we
synthesize cross-vocabulary vision data to activate multiple visual
vocabularies simultaneously to break down the specific-vocabulary bias
of visual content, catalyzing multiple vision vocabularies to a full
reaction. 3) *Supporting multi-column format and multiple pages:* With
the position-aware prompts, the pipeline of focusing anywhere can yield
robust performance regardless of document format. Moreover, benefiting
from the high compression ratio (one 1024$\times$``{=html}1024
page to 256 image tokes), we demonstrate the Fox can be efficiently
tuned to achieve the above fine-grained capabilities on multi-page
documents without modifying parameters of vision vocabulary.
As a result of the focusing catalytic process, the proposed Fox can not
only give specific-vocabulary responses (*e.g.*, page foreground OCR,
region/line-level OCR/translation) but also gain the noticeable ability
to utilize the cross-vocabulary visual knowledge (*e.g.*, color-guided
OCR, in-document figure caption). Furthermore, for more impressive
multi-page document features, Fox can give the OCR results of $region_1$
on $page_1$ and $region_n$ on $page_n$ by only one question. Note that
tasks like this with reference to cross-page content are of great
research significance. We encourage researchers to rethink the framework
design for LVLM-based document understanding and not be limited to
conventional single-page sparse QA tasks. Our contributions can be
summarized as follows:
- We introduce a series of novel tasks to boost document understanding
by enabling LVLMs to focus on document-level regions of interest. We
propose an effective and efficient solution named Fox to focus
anywhere on single/multi-page documents.
- To catalyze multiple vision vocabularies for figure-text interleaved
documents, we provide methods for generating hybrid data containing
cross-vocabulary visual elements.
- Fox is robust to documents of various formats due to the flexible
position-aware prompts. Without training vision vocabulary, our Fox
can be easily tuned to multi-page documents and gain cross-page
parsing capabilities.
- We build a fine-grained document benchmark, including 9 sub-tasks,
such as dense page OCR, region-level OCR/translation/summary,
color-guided OCR, multi-page OCR/VQA. Experimental results show that
our Fox outperforms other LVLMs by a large margin.
# Related Works
## Visual Document Understanding
Visual document understanding is widely investigated in the research
field of computer vision. Optical Character Recognition (OCR) is a basic
task, which plays a key role in document
digitalization [smith2007overview](http://arxiv.org/pdf/1003.5893v1), [moysset2017full](http://arxiv.org/pdf/1704.08628v1). The
layout analysis task [zhong2019publaynet](http://arxiv.org/pdf/1908.07836v1) aims to detect
various document elements and facilitate to understanding of spatial
relationships between them. We believe that OCR is a good task to test
whether LVLMs can compress documents losslessly. Besides, for
translation and
summary [vaswani2017attention](http://arxiv.org/pdf/2107.08000v1), [dong2019unified](http://arxiv.org/pdf/2212.06742v2) tasks, the
proposed Fox can directly give answers for document images via the
multimodal framework.
## Large Language Models
In recent times, the success of LLMs has ignited the fields of natural
language processing (NLP) and artificial general intelligence (AGI). The
LLMs are built with the popular transformer framework which is explored
by earlier NLP research, *e.g.*, BERT [Bert](http://arxiv.org/pdf/1810.04805v2),
GPT-2 [GPT-2](http://arxiv.org/pdf/2203.12926v1), T5 [T5](http://arxiv.org/pdf/1910.10683v4), and so on.
Afterward, it is discovered that when the model parameters are expanded
to a certain size, the language model will be greatly boosted due to the
so-called "emergent ability" [wei2022emergent](http://arxiv.org/pdf/2403.15796v2). Further,
the "GPT time" comes with amazing dialogue robots optimized by
Reinforcement Learning with Human
Feedback [RLHF_christiano2017deep](http://arxiv.org/pdf/2007.12904v2), *e.g.*,
InstructGPT [InstructGPT](http://arxiv.org/pdf/2302.05206v1) and
ChatGPT [ChatGPT](https://openai.com/blog/chatgpt/). Following that,
OPT [OPT](http://arxiv.org/pdf/2405.04515v2), LLaMA [llama](http://arxiv.org/pdf/2402.08075v1), and
GLM [GLM](http://arxiv.org/pdf/2004.13270v1) are accessible to the community to pursue the
performance like the GPT family. Based on the open-source LLMs, for more
specific requirements, some fine-tuned models have merged, such as
Alphaca [alpaca](https://github.com/tatsu-lab/stanford_alpaca) and Vicuna [vicuna](https://lmsys.org/blog/2023-03-30-vicuna/),
which also play critical roles in later Large Vision-Language Models.
## Large Vision-Language Models
For vision-centric tasks, Large Vision-Language Models
(LVLMs) [llava](http://arxiv.org/pdf/2402.11690v1), [Flamingo](http://arxiv.org/pdf/2205.07065v1), [lu2024deepseek](http://arxiv.org/pdf/2402.17510v1) have been
developed by connecting the vision networks to LLMs.
CLIP-ViT [CLIP_radford2021learning](http://arxiv.org/pdf/2404.19696v1) is a mature
pre-trained vision vocabulary widely used to inject visual modality into
language models. To ensure that LLMs can understand the visual context,
LLaVA [llava](http://arxiv.org/pdf/2402.11690v1) places the linear layers to project visual
tokens into text space. Later, beyond natural scenes, LVLMs for
large-resolution documents have emerged.
UReader [ye2023ureader](http://arxiv.org/pdf/2311.13165v1) is developed based on the LVLM
mPLUG-Owl [ye2023mplug](http://arxiv.org/pdf/2405.00390v2).
UReader [ye2023ureader](http://arxiv.org/pdf/2311.13165v1) devise a shape-adaptive approach
to crop input images into 224$\times$``{=html}224 patches and
feed them into CLIP vision encoder. Following
Qwen-VL [Qwen-VL](http://arxiv.org/pdf/2308.12966v3),
TextMonkey [liu2024textmonkey](http://arxiv.org/pdf/2403.14252v1) uses a more powerful
vision vocabulary Openclip’s
ViT-bigG [openclip_ilharco_2024_10469088](openclip_ilharco_2024_10469088) with
448$\times$``{=html}448 input size to endoce each cropped patch.
With the strategy of cropping patches,
LLaVA-NeXT [liu2024llavanext](https://llava-vl.github.io/blog/2024-01-30-llava-next/) adopts CLIP-ViT-L-336px to
perform visual perception. Similarly, to capture more details,
InternVL-V1.5 [chen2024far_intervl1.5](http://arxiv.org/pdf/2404.16821v2) dynamically
divides the input image into 1 to 12 tiles of
448$\times$``{=html}448. In contrast, without cropping patches,
Vary [wei2023vary](http://arxiv.org/pdf/2312.06109v1) writes an extra
SAM-style [SAM](http://arxiv.org/pdf/2305.01275v1) 1024$\times$``{=html}1024 vision
vocabulary specific to document and chart data, running in parallel with
the CLIP branch.
Compared to the above models, we believe that document understanding
should move towards more fine-grained (*e.g.,* region-level
OCR/translation) and multi-page tasks. Imagine how cool it would be if
we could use the LVLM like a reading pen! In this paper, we introduce
Fox which can achieve fine-grained features by focusing anywhere on
multi-page documents.
# Methods
In this section, we will elaborate on the details of the proposed Fox.
First, we introduce the flexible pipeline which supports
single/multi-page document understanding. Second, we provide the
strategy to produce the data containing hybrid visual elements to
activate multiple vocabularies concurrently. Last, we unify multi-task
data with position-aware prompts to conduct the focusing process.
## Framework for Focusing Anywhere
As illustrated in
Figure 2, the architecture of the
proposed Fox is built with two vision vocabularies, a large language
model, and embedding linear layers. Specifically, to better handle
figure-text interleaved large-resolution documents, there are two vision
vocabularies, including natural content-aware
CLIP-ViT [CLIP_radford2021learning](http://arxiv.org/pdf/2404.19696v1) and artificial
content-aware Vary-tiny [wei2023vary](http://arxiv.org/pdf/2312.06109v1). The overall
framework is neat and provides more user-friendly fine-grained
interactions, which can focus on the entire page and more specific
regions of interest (RoI). Impressively, the proposed Fox also supports
users to select RoIs on multiple pages at the same time, enabling
cross-page contextual understanding.
Given a set of input document pages $I=\{p_i\}_{i=1}^N$, users can
further indicate regions of interest $r_i$ on each page by clicking a
point, dragging boxes, or drawing color boxes, and then give some
language instructions $L^{instruct}$ about the questioning RoIs. $N$ is
the number of input pages. The spatial coordinates or color information
of $\{r_i\}_{i=1}^N$ is transformed into position-aware prompts and
combined with $L^{instruct}$ to produce complete referential
instructions. Meanwhile, two vision vocabularies will produce 256 image
tokens $v^C_i \in \mathbb{R}^{256\times1024}$ and
$v^S_i \in \mathbb{R}^{256\times1024}$ for each page $p_i$. These image
tokens $\{v^C_i\}_{i=1}^N$ and $\{v^S_i\}_{i=1}^N$ are sent into linear
layers $W^C$ and $W^S$ to align with linguistic space. Then, the final
image tokens $v_i \in \mathbb{R}^{256\times2048}$ can be obtained by
concatenation. Note that $v_i$ is compressed into cross-vocabulary
content, including dense characters and figures. Finally, with the
projected image tokens and referential instructions, LLM will generate
the response sequence $Q$ in an auto-regressive manner. The above
process can be formulated as follows:
$$\{v_i\}_{i=1}^N = \left[ W^C \circ \{v^C_i\}_{i=1}^N || W^S \circ \{v^S_i\}_{i=1}^N\right]$$
$$Q = \mathcal{LLM} \left( \{v_i\}_{i=1}^N, \left(L^{instruct}, \Psi \left(\{r_i\}_{i=1}^N \right)\right) \right)$$
where $\left[\cdot || \cdot \right]$ is the concatenation operation.
$\Psi(\cdot)$ denotes the normalization for spatial coordinates. Note
that multi-page ($N$ pages) image tokens $\{v_i\}_{i=1}^N$ are unified
into a sequence for cross-page contextual understanding. With the causal
masked sequence modeling, the training objective can be expressed as:
$$\mathcal{L}_t=-E_{(Q, V)\sim D}\operatorname{log} P_{\theta} \left( q_m | q_{
$$\label{eq1}
\left\{ \begin{aligned}
W_{new}^n & = \operatorname{randint}\left(\left[\alpha \cdot W^d \right], \left[\beta \cdot W^d\right] \right), H_{new}^n = \left[W_{new}^n/W^n \cdot H^n \right], & \text{if} \ W^n/H^n > W^d/H^d \\
H_{new}^n & = \operatorname{randint}\left(\left[\eta \cdot H^d \right], \left[\gamma \cdot H^d\right] \right), W_{new}^n = \left[H_{new}^n/H^n \cdot W^n \right], & \text{if} \ W^n/H^n \leq W^d/H^d\\
\end{aligned} \right.$$
where $W_{new}^n$/$H_{new}^n$ denote the desired width/height of the
scaled natural image. $\left[\cdot\right]$ means the integral function.
$\alpha$, $\beta$, $\eta$, and $\gamma$ are the hyperparameters that
control the scaling ratio, and they are set to 0.3, 0.9, 0.4, and 0.9,
respectively. Then, we randomly pick a suitable location
$(x^n_1, y^n_1, x^n_2, y^n_2)$ on the page to place the scaled natural
image. What’s more, to make the interleaved data reasonable and delete
the occluded text on this page, we calculate the intersection of union
(IoU) between $(x^n_1, y^n_1, x^n_2, y^n_2)$ and the vanilla text boxes
$\left\{ (x^d_{i,1}, y^d_{i,1}, x^d_{i,2}, y^d_{i,2}) \right\}_{i=1}^{N_d}$,
and fill the text boxes overlapped by the natural image with the white
color. $N_d$ is the number of text boxes on this document page. So, we
can obtain cross-vocabulary image-text pairs for in-document figure
caption. The text for each interleaved page includes the filtered
optical characters and the description of the pasted natural image.
#### Color-text hybrid data.
CLIP is written with the knowledge for recognizing colors, while the
Vary-tiny is not. We produce color-text hybrid data to further activate
multiple vocabularies, which is the key to enabling Fox to support the
conversations for users’ color-guided RoI. We randomly select three text
boxes and paint them directly on the document page in red, blue, and
green colors. The proposed Fox is expected to directly give the OCR
results in the area with the questioning color.
## Triggering Focusing Process via Fine-grained Instruction-following Tasks
We devise fine-grained instructions based on several position-aware text
prompts, such as points, boxes, and colors, to catalyze Fox to focus any
fine-grained region on single/multi-page documents.
#### Fine-grained document understanding.
We define several novel sub-tasks to drive the model to focus on
fine-grained regions for flexible document-level understanding: 1)
Foreground OCR. We redefine the page OCR task as the foreground focus to
further boost the dense perception. The instruction can be “*Give the
OCR results of the box $(x^f_{i,1}, y^f_{i,1}, x^f_{i,2}, y^f_{i,2})$*”.
The foreground box can be obtained by some simple operations. 2)
Region-level OCR. Based on the obtained text boxes, we transform the
content of one page into multiple region-level OCRs via multi-turn
conversations. An example can be “*Give the OCR results of the box
$(x^d_{i,1}, y^d_{i,1}, x^d_{i,2}, y^d_{i,2})$*”. 3) Line-level OCR. We
pick a point near the left side of each line as the position prompt.
Then, we construct the line-level multi-turn conversations and an
example can be like “*OCR the line $(x^d_{j}, y^d_{j})$*”. 4)
Color-guided OCR. Using the color-text hybrid data in
Section 3.2, we define the corresponding
cross-vocabulary task by some color-guided questions, such as “*OCR red
box*” and “*OCR blue box*”. 5) Region-level translation and summary. We
filter and retain the boxes with text lengths over 400 on each page.
Then, we employ GPT-3.5 [ChatGPT](https://openai.com/blog/chatgpt/) to generate the
translation and summary for each long in-box text as the corresponding
annotations. The instruction can be “*Translate/Summarize the content of
the box $(x^d_{i,1}, y^d_{i,1}, x^d_{i,2}, y^d_{i,2})$*”. 6) Document
layout: We convert the 330K high-quality annotations of
PubLayNet [zhong2019publaynet](http://arxiv.org/pdf/1908.07836v1) to the unified
conversation format. Further, we sample 1M extra PDF pages and use
PaddleOCRv2 [paddleocrv2_du2021pp](http://arxiv.org/pdf/2109.03144v2) tools to generate
pseudo layout annotations.
#### In-document figure understanding.
Based on the synthetic interleaved data, we organize the
cross-vocabulary image-text pairs into two sub-tasks: 1) In-document
figure caption. As a result of the added position-aware prompts, an
example language instruction is as follows: “*Give a brief description
for the region $(x^n_1, y^n_1, x^n_2, y^n_2)$ of the image*”. The box
denotes the boundary of the figure. 2) In-document in-figure chat. The
RegionChat [zhao2023chatspot](http://arxiv.org/pdf/2307.09474v1) dataset is built for
referential dialogue on natural images. After rendering it on PDF pages,
with spatial coordinates of the referring region, we can ask the
proposed Fox the following question: “*What can you see in this region?
$(x^n_1, y^n_1, x^n_2, y^n_2)$*”. At a more fine-grained level, the RoI
can be the box within the figure on the document page.
#### Extension for multi-page documents.
The proposed Fox can be easily tuned to focus on multiple regions of
multi-page documents using simple instructions. As a forerunner, we
define two basic yet interesting multi-page sub-tasks and give
position-aware instruction examples. 1) Multi-page region-level OCR:
“*OCR boxes on multiple pages. Page 1: $(x^1_1, y^1_1, x^1_2, y^1_2)$,
Page 2: $(x^2_1, y^2_1, x^2_2, y^2_2)$, $\dots$ Page N:
$(x^N_1, y^N_1, x^N_2, y^N_2)$*”. 2) Cross-page VQA: “*Which page’s box
contains more characters? Page 1: $(x^1_1, y^1_1, x^1_2, y^1_2)$, Page
2: $(x^2_1, y^2_1, x^2_2, y^2_2)$, $\dots$ Page N:
$(x^N_1, y^N_1, x^N_2, y^N_2)$*”.
It is worth noting that all the above methods are independent of
document format. The PDF data with any format or layout, such as
single-column, double-column, interleaved, *etc.*, can be parsed to
extract positional prompts and formulated into the corresponding
conversations. With the fine-grained position-aware instructions, the
vision query pipeline enjoys high human-AI interactivity and is robust
to different formats (multi-column) and multi-page documents.
## Catalyzing Fox by Multi-page and Multi-grained Data Engine
The data engine is a key part of the proposed Fox. To ensure the
performance on multiple tasks, We carefully control the quantity and
ratio of training data, and more details are reported in
Table [tab:data].
#### Pre-training data.
In the pre-training stage, we formulate a large number of multimodal
task-driven data. Specifically, for hybrid images of in-document caption
and chat sub-tasks, we render the BLIP558K [llava](http://arxiv.org/pdf/2402.11690v1) data,
1M natural images sampled in
Laion-COCO [schuhmann2021laion](http://arxiv.org/pdf/2111.02114v1) and
RegionChat100K [zhao2023chatspot](http://arxiv.org/pdf/2307.09474v1) data into an equal
amount of document pages sampled in prepared PDF data. For fine-grained
optical character understanding, we formulate 6 types of 4.6M document
image-text pairs, containing box/line/color position-aware prompts and
OCR/translation/summary interactive task forms. Further, we generate
800K multi-page data, including multi-page multi-region OCR and
cross-page QA. In addition, to maintain the general conversational
capabilities of our model, we sample 1M natural data from
Laion-COCO [schuhmann2021laion](http://arxiv.org/pdf/2111.02114v1) and NLP dialogue data
from Alpaca [alpaca](https://github.com/tatsu-lab/stanford_alpaca), Baize [xu2023baize](http://arxiv.org/pdf/2404.02406v1)
and ShareGPT.
#### SFT data.
In the supervised fine-tuning stage, To make the conversation experience
more comfortable, we sample 10K image-text pairs for each data type of
the above pre-training data, and adopt GPT3.5 [ChatGPT](https://openai.com/blog/chatgpt/)
to rewrite prompts ten times more diversified. Besides,
LLaVA80K [llava](http://arxiv.org/pdf/2402.11690v1) is also added to further tune our model
to generate pleasing answers.
#### Input and Conversation Format
For each input image, we resize it with a fixed resolution
1024$\times$``{=html}1024 before feeding it into the
SAM-style [SAM](http://arxiv.org/pdf/2305.01275v1) ViT branch and we perform a resize
operation to obtain a new image of 224$\times$``{=html}224 as
the input of the CLIP vision network. We choose
Qwen-1.8B [qwen](http://arxiv.org/pdf/2309.16609v1) with rich linguistic vocabulary as our
language model. Following the
LLaVA-MPT [llava](http://arxiv.org/pdf/2402.11690v1), [team2023introducing](http://arxiv.org/pdf/2311.16429v1) dialogue style, the
input conversation format can be summarized as follows:
\<\|im_start\|\>user: \"\"\ "*human question
\[position-aware prompts\]*"\<\|im_end\|\> \<\|im_start\|\>assistant:
"*AI responses*" \<\|im_end\|\>.
# Experiments
## Implementation Details
During the multi-task pre-training and SFT phase, the multiple vision
vocabularies (CLIP and SAM-style ViT) are frozen and only the parameters
of the embedding linear layers and language model are optimized. We
train our model using the optimizer AdamW [AdamW](http://arxiv.org/pdf/2311.11446v2) and a
cosine annealing scheduler [loshchilov2016sgdr](http://arxiv.org/pdf/1608.03983v5). The
learning rate is set to 1e-4 in pretraining and then to 2e-5 in SFT. In
both stages, we use 48 A800 GPUs with a per device batch of 4 and the
data epoch is set to 1.
## Multi-grained Benchmark and Metrics
To advance fine-grained document understanding, we build a bilingual
benchmark including 9 sub-tasks. We collect 112 English pages and 100
Chinese pages, including single/multi-column formats. The number of
words per page exceeds 1,000. These images are used to evaluate page
OCR, line-level OCR, color-guided OCR, region-level
OCR/translation/summary, multi-page multi-region OCR, and cross-page
VQA. Besides, to monitor the performance of interleaved data, we render
200 natural images sampled from
Laion-COCO [schuhmann2021laion](http://arxiv.org/pdf/2111.02114v1) onto 200 PDF pages to
evaluate the document-level in-figure caption task. The comprehensive
evaluation metrics contain normalized edit distance, F1-score,
BLEU [papineni2002bleu](http://arxiv.org/pdf/2202.11027v1),
METEOR [banerjee2005meteor](http://arxiv.org/pdf/2312.00536v1),
ROUGE [lin2004rouge](http://arxiv.org/pdf/2209.06517v2), and *etc*.
## Evaluation Results
#### Foreground focus for dense text recognition on a single page.
For the dense text recognition on the entire page, we directly input the
normalized box $\left[2, 2, 998, 998\right]$ as the foreground prompts.
As shown in Table 1 and
2, Fox showcases strong English and
Chinese dense OCR ability by almost lossless compression for the
document page. Specifically, Fox achieves the best edit distance of
0.046 and 0.061 in English and Chinese, respectively. Compared to
Vary-toy using the image-level prompts, the proposed Fox lifts the
English F1-score by 2.8% by redefining the task as foreground focus.
Note that the performance of LLaVA-NeXT and InternVL-ChatV1.5 which use
the CLIP-style vocabulary is bottle-necked, indicating that the dense
texts of each patch are not completely encoded.
#### Region focusing performance of in-document fine-grained tasks.
As shown in Table [tab:boxline], Fox can yield excellent
OCR results on various metrics under several
color-guided/region-level/line-level settings, indicating that our model
can accurately recognize the content in these randomly sampled RoIs. In
Table 3, for the region-level
translation, Fox yields an acceptable METEOR of 0.366 due to the smaller
language model of 1.8B parameters. In addition, we evaluate our model on
the fine-grained summary task and obtain a decent ROUGE-L-F score of
0.282. It is worth mentioning that this kind of usage similar to a
reading pen is exactly what users need more.
| **Fine-grained Translation** | | **Fine-grained Summary** | | | **Fine-grained Caption** | |
|:--:|:--:|:--:|:--:|:--:|:--:|:--:|
| 1-2 (rl)3-5 (rl)6-7 BLEU | METEOR | ROUGE-L R | ROUGE-L P | ROUGE-L F | METEOR | ROUGE-L F |
| 0.138 | 0.366 | 0.261 | 0.316 | 0.282 | 0.359 | 0.396 |
The performance of in-document fine-grained understanding tasks. The
fine-grained translation/summary/caption tasks are targeted at
interpreting in-document text/figure regions.
#### Cross-vocabulary focusing tasks on interleaved pages.
The color-guided task requires cross-vocabulary visual knowledge,
*i.e.*, CLIP for recognizing colors and Vary-tiny for capturing texts.
Table [tab:boxline] shows that the decent
results (0.940 and 0.884 on English and Chinese F1-score) meet our
expectations due to the collaboration across multiple vision
vocabularies. For the in-document figure caption task, we render natural
images onto document pages and ask our model “*What is this in the box
$$?*”, where $$ is the boundary of the natural image that is
pasted into the document page. As shown in
Table 3, when handling
interleaved data, Fox reaches the METEOR of 0.359 and ROUGE-L-F of 0.396
due to the full reaction of activating multiple vocabularies.
#### Exploration for focusing on multiple pages.
To verify the focusing capability of Fox on multi-page documents, we
report two relevant results in
Table 4. For the multi-page OCR task, we
ask the model to output the OCR results of 8 boxes on 8 complex pages
(in mixed English/Chinese and mixed single/multi-column formats) in a
single-turn conversation. Our Fox still performs an amazing F1-score of
0.946 and achieves true focus anywhere by parsing the entire 8-page
document simultaneously. For the cross-page visual question-answering
task which requires the model to answer which box has the largest number
of characters in multiple cross-page boxes, Fox yields a high accuracy
of 0.827, demonstrating that it is easier to perform VQA reasoning based
on successfully perceiving dense text of multiple pages.
#### Visualization.
Figure 3 shows our Fox can perform impressive
features with high human-AI interactivity. For the figure on the
academic page, Fox gives the response “global seismic hazards” which is
relevant to the content of the document. Fox can also give precise OCR
results by dense text perception. For the cartoon book, Fox can
recognize the interesting “lion” and can read the story texts for users.
This indicates that our Fox enjoys fine-grained focusing capabilities in
various scenarios.
# Conclusion and Limitations [discussion]
This paper proposes a user-friendly LVLM named Fox, which enjoys amazing
fine-grained capabilities of focusing anywhere on single/multi-page
documents. Further, after catalyzing the multiple vision vocabularies
into a full reaction, Fox gains impressive cross-vocabulary features on
figure-text interleaved pages. To advance the fine-grained document
understanding, we provide a benchmark containing comprehensive
sub-tasks. Our Fox can achieve promising scores in these experiments,
making a successful step to high human-AI interactivity on dense-content
documents. We believe that the proposed method has considerable room for
improvement (*e.g.*, the low-resolution CLIP), and we encourage more
researchers to focus on more reasonable multi-page document-level tasks.
# Appendix
We show more amazing output results of our model Fox. All testing images
are from the Internet.
[^1]: This work was done when the first author was interning at Megvii
Technology Inc.
TextHawk: Exploring Efficient Fine-Grained Perception of Multimodal Large Language Models
2024-04-14
Ya-Qi Yu, Minghui Liao, Jihao Wu, Yongxin Liao, Xiaoyu Zheng, Wei Zeng
Multimodal Large Language Models (MLLMs) have shown impressive results on various multimodal tasks. However, most existing MLLMs are not well suited for document-oriented tasks, which require fine-grained image perception and information compression. In this paper, we present TextHawk, a MLLM that is specifically designed for document-oriented tasks, while preserving the general capabilities of MLLMs. TextHawk is aimed to explore efficient fine-grained perception by designing four dedicated components. Firstly, a ReSampling and ReArrangement (ReSA) module is proposed to reduce the redundancy in the document texts and lower the computational cost of the MLLM. We explore encoding the positions of each local feature by presenting Scalable Positional Embeddings (SPEs), which can preserve the scalability of various image sizes. A Query Proposal Network (QPN) is then adopted to initialize the queries dynamically among different sub-images. To further enhance the fine-grained visual perceptual ability of the MLLM, we design a Multi-Level Cross-Attention (MLCA) mechanism that captures the hierarchical structure and semantic relations of document images. Furthermore, we create a new instruction-tuning dataset for document-oriented tasks by enriching the multimodal document data with Gemini Pro. We conduct extensive experiments on both general and document-oriented MLLM benchmarks, and show that TextHawk outperforms the state-of-the-art methods, demonstrating its effectiveness and superiority in fine-grained document perception and general abilities.
Show Paper Content
The results of MLLMs on general and document-oriented
benchmarks. Best viewed in colors.The mean count of compressed visual tokens per image in
MLLMs. Best viewed in colors.
# Introduction [sec:intro]
Multimodal Large Language Models
(MLLMs) [blip2](None), [instructblip](None), [llava](http://arxiv.org/pdf/2402.11690v1) have received a lot of
attention and made great progress recently. They use Large Language
Models (LLMs) as the core and extend the powerful capabilities of LLMs
to other modalities, such as visual modalities. Thanks to the wide range
of application scenarios of document image understanding, it has a
pivotal position in the field of visual perception. Document image
understanding ability as one of the core abilities of MLLMs, makes more
cutting-edge applications easy to achieve, such as MLLM-based smartphone
application agents, rich text-assisted reading, etc. However, document
images pose unique challenges for MLLMs, as they differ from natural
images in several aspects. Document images typically have higher
resolution and higher information density than natural images, which
means that MLLMs need to overcome two key difficulties when processing
them. The first difficulty is to achieve strong fine-grained visual
perception of the document content. The second difficulty is to compress
document image information efficiently.
Previous works on document-oriented MLLMs have attempted to solve the
difficulties mentioned above. To achieve stronger fine-grained visual
perception abilities, Qwen-VL [qwen-vl](None) increased the
input resolution of the vision encoder from $224\times224$ to
$448\times448$ and UReader [ureader](None) introduced a
shape-adaptive cropping module. To compress the document information,
mPLUG-DocOwl [mplugdocowl](None) employed a visual abstractor
and Qwen-VL utilized a vision-language adapter. These well-designed
methods significantly advanced the development of document-oriented
MLLMs. Nevertheless, there is still room for further exploration and
improvement in fine-grained visual perception and document information
compression. Besides, most of the current MLLMs find it difficult to
balance both general and document capabilities. Specifically, general
MLLMs usually do not focus on improving visual fine-grained perception
and information compression, while document-oriented MLLMs may sacrifice
general capabilities in their design.
In this paper, we propose TextHawk, a multimodal large model that excels
at complex document tasks and demonstrates outstanding general
capabilities across vision and language domains, as shown in
Fig. 1. Considering that simply enlarging the
input size of the images can not fit the diverse resolutions of the
document images, we follow Ureader [ureader](None) to crop the
images into sub-images adaptively according to the image shapes. Based
on this, we devise a ReSampling and ReArrangement (ReSA) module that
compresses and rearranges the visual information, which greatly reduces
the number of visual tokens, as shown in
Fig 2. Due to the introduction of the
sub-images, we propose Scalable Positional Embeddings (SPEs) to encode
the positions of sub-images while maintaining the scalability across
different image sizes. Considering the differences among the sub-images,
a Query Proposal Network (QPN) is then adopted to initialize the queries
dynamically among local features. Moreover, we introduce a Multi-Level
Cross-Attention (MLCA) module that leverages the hierarchical structure
and semantic relations of document images to enhance the fine-grained
visual perceptual capability. This enables our vision encoder to extract
detailed information from dense document images. In addition, we enrich
the multimodal document data with Gemini Pro, a commercial MLLM engine,
to mitigate the problem of insufficient instruction tuning data.
We address the challenges of fine-grained visual perception and visual
information compression for document-oriented MLLMs and propose a new
MLLM, named TextHawk, that can handle both document-oriented tasks and
general vision-language tasks with high performance. The contributions
of this paper are as follows:
1. We design the ReSA to compress the visual information which
significantly reduces the number of visual tokens.
2. We propose the SPEs and the QPN to fit sub-image representations and
enhance the model’s fine-grained perception.
3. We introduce the MLCA that can improve the fine-grained visual
perception ability by capturing the global and local information and
leveraging the hierarchical structure.
4. We enrich the multimodal instruction-tuning data of different
document-oriented tasks with Gemini Pro. These data can facilitate
the fine-tuning of TextHawk and benefit the research community.
5. We demonstrate that TextHawk achieves state-of-the-art results on
both document benchmarks and general benchmarks, showing its
superior fine-grained visual perception and general vision-language
abilities.
# Related Works
## MLLM
Multimodal Large Language Models (MLLMs) are a class of models that can
process and generate multimodal information, mainly including natural
language and visual information. They have been shown to achieve
remarkable performance on various tasks, such as image captioning,
visual question answering, and visual dialog. Current MLLMs usually
consist of a vision encoder, a vision-language adapter, and a large
language model.
BLIP-2 [blip2](None) proposed a querying transformer (Q-Former)
to bridge the frozen image encoder and the frozen large language model.
It first learned vision-language representation from a frozen image
encoder and then applied vision-to-language generative learning from a
frozen language model. InstructBLIP [instructblip](None)
performed vision-language instruction tuning based on the pre-trained
BLIP-2 by introducing an instruction-aware query transformer.
LLaVA [llava](http://arxiv.org/pdf/2402.11690v1) followed a similar architecture while
employing a simple linear layer to connect vision and language. It
converted image-text pairs into an instruct-following format with
ChatGPT/GPT-4 for better fine-tuning results.
MiniGPT-4 [minigpt4](None) adopted a frozen Q-former and a
single linear projection layer to align the visual modal and the
language modal. LLaVA1.5 [llava-1.5](http://arxiv.org/pdf/2310.19145v1) is an improved
version of LLaVA, which adopted a vision encoder with larger input
images and a two-layer MLP to improve performance.
mPLUG-Owl [mplugowl](http://arxiv.org/pdf/2405.00390v2) proposed a new training paradigm
that enabled the vision encoder and visual abstractor training in the
pre-training stage and enabled LoRA with LLM in the instruction tuning
stage. mPLUG-Owl2 [mplugowl2](None) further designed a
modality-adaptive module based on mPLUG-Owl and enabled all modules for
training. Qwen-VL [qwen-vl](None) employed a three-stage
training pipeline, including pre-training with image-text pairs,
multi-task pre-training with multi-task and interleaved data, and
supervised fine-tuning with chat interleaved VL data.
These methods can understand text images to some extent, but they have
limited visual perception for dense documents, especially those with
high-resolution images.
## Document-Oriented MLLM
Document-oriented MLLMs are multimodal large language models that can
understand text from various types of documents, such as charts, tables,
web pages, and scientific papers. They usually incorporate some specific
adaptations for document images based on general MLLMs.
mPLUG-DocOwl [mplugdocowl](None) followed the mPLUG-Owl model
and added some document instruction tuning data, including document,
table, webpage, and chart. UReader [ureader](None) proposed a
shape-adaptive cropping module to obtain better fine-grained visual
perceptual ability of document images, based on the pre-trained
mPLUG-Owl model. UniDoc [unidoc](None) was equipped with text
detection and text recognition tasks in its instruction tuning to
enhance the ability of text understanding.
Monkey [monkey](None), a MLLM with special designs for document
images, supported larger resolutions and introduced multi-level
description data based on the pre-trained Qwen-VL model.
Current document-oriented MLLMs mainly focus on adaptation to higher
image resolutions and leveraging more document-specific fine-tuning
data. Our proposed TextHawk also concentrates on the fine-grained visual
perception of high-resolution document images and the document data
generation, with our novel designs. Moreover, we pay attention to the
information compression and the preservation of the general
capabilities.
# Method
Our model is designed with two objectives: to effectively process visual
inputs of varying resolutions and to compress visual tokens.
## Architecture [ssec:arch]
The architecture of TextHawk is depicted in
Fig. [fig:arch] (a). It consists of a frozen
visual encoder, a resampler, and a large language model with a LoRA and
a detection head.
.5em 1ex .1ex -.5em Visual Encoder. To accelerate image encoding, we
prefer a relatively lightweight visual encoder instead of a giant or
enormous model. SigLIP [siglip](http://arxiv.org/pdf/2303.15343v4), a variant of
CLIP [clip](http://arxiv.org/pdf/2404.19696v1) which adopts Sigmoid loss for vision-language
pre-training instead of contrastive learning with Softmax normalization,
achieves better zero-shot accuracy in multiple tasks than its
competitors. Hence, we employ the Vision Transformer (ViT) from the
efficient SigLIP-SO model as our visual encoder for demonstration, which
has different transformer layer configurations but a similar
computational cost to the standard ViT-L model. However, all kinds of
visual encoders should be feasible in our framework, including models
pre-trained in different styles or built with different architectures.
.5em 1ex .1ex -.5em Resampler. Similar to
Q-Former [blip2](None), our visual token resampler mostly
consists of a non-causal transformer decoder which adopts a group of
learnable weights as the initial queries and naturally reduces the
length of visual features multiple times. For the sake of architecture
flexibility, we randomly initialize the resampler instead of
initializing it from a pre-trained BERT model or existing resamplers of
other MLLMs. Intuitively, we keep the hidden dimension of the
intermediate resampler layers equal to that of the visual encoder
layers. The resampler has 8 layers and self-attention is removed in the
first layer. In order to enhance the awareness of position information
during cross-attention, we employ sinusoidal positional encodings and
learned positional embeddings for the visual encoder output and the
queries respectively at every cross-attention layer.
.5em 1ex .1ex -.5em Large Language Model. To facilitate pre-training and
take advantage of the interleaved vision-language training, we
initialize our 7B LLM with the weights of
InternLM-XComposer [xcomposer](None). Similar to BLIP-2,
InternLM-XComposer adopts a visual token resampler named perceive
sampler to bridge the visual encoder and LLM, but it is anchored on
another multi-lingual LLM named InternLM [internlm](https://github.com/InternLM/InternLM). The
architecture of InternLM is almost the same as
LLaMA [llama](http://arxiv.org/pdf/2402.08075v1) except for keeping biases in the attention
modules. Specifically, InternLM-XComposer is trained in a two-stage
style: The first stage is vision-language pre-training, which
incorporates image-text pairs as well as interleaved image-text data.
Both the perceived sampler and the LLM are updated in this stage. The
second stage is multi-task supervised fine-tuning, in which only the
perceived sampler and the LoRA modules are updated. To avoid potential
data leakage from the fine-tuning datasets of InternLM-XComposer, we
only keep the weights of the LLM from the first pre-training stage and
drop all the weights from the vision encoder, perceive sampler, and LoRA
modules.
## Efficient Fine-Grained Perception [ssec:efgp]
.5em 1ex .1ex -.5em Shape-Adaptive Cropping. The pre-trained visual
encoder standardizes image resolution to a fixed and lower size,
disregarding the original aspect ratio. Such processing diminishes the
ability to perceive fine-grained content in high-resolution images and
introduces notable distortions in aspect ratio.
Following [ureader](None), we augment the frozen ViT by
incorporating a dynamic cropping strategy, enabling effective handling
of images with arbitrary aspect ratios and resolutions. Specifically, an
input image $\boldsymbol{v}$ with shape $(h\times w)$ will be cropped
into multiple sub-images to align with one of the predefined grids
$\{\boldsymbol{g}=(r\times c)|r,c\in\{1,2,\dots,l\},r\cdot c\leq n\}$,
where $r$ and $c$ denotes the rows and columns of the grid
$\boldsymbol{g}$, $l$ denotes the maximum *side-length* (number of
sub-images in one row or column), and $n$ denotes the maximum
*area* (number of sub-images in the whole image). The grid alignment is
regulated by both regular and shape-oriented Intersection over
Union (IoU) measures. Let us denote the image box as
$\text{box}(\boldsymbol{v})=(0,0,h,w)$, the grid box as
$\text{box}(\boldsymbol{g})=(0,0,rH,cW)$, and the shape-oriented box as
$\text{box}_\text{s}(\boldsymbol{v},\boldsymbol{g})=(0,0,\frac{wr}{h}H,cW)$,
where $(H\times W)$ is the input shape of ViT. The IoU values are
defined as: $$\begin{aligned}
S_\text{r}(\boldsymbol{v},\boldsymbol{g})&=\text{IoU}(\text{box}(\boldsymbol{v}),\text{box}(\boldsymbol{g})),\\
S_\text{s}(\boldsymbol{v},\boldsymbol{g})&=\text{IoU}(\text{box}_\text{s}(\boldsymbol{v},\boldsymbol{g}),\text{box}(\boldsymbol{g})),\\
S(\boldsymbol{v},\boldsymbol{g})&=S_\text{r}(\boldsymbol{v},\boldsymbol{g})+S_\text{s}(\boldsymbol{v},\boldsymbol{g}).
\end{aligned}$$ We select the final grid with the highest summed IoU
value $S$, from the top $k$ grids with the highest regular IoU values
$S_\text{r}$.
.5em 1ex .1ex -.5em ReSampling and ReArrangement (ReSA). Upon enabling
the visual encoder to accept variable resolution input, the number of
image tokens can grow exponentially with the image resolution. Without
token compression, the maximum number of tokens for a single image
reaches $nHW/p^2$ given patch size $p$. In specific terms, a standard
document image aligned with a $5\times4$ grid will consume up to 5,120
tokens. Previous open-source MLLMs with fine-grained perception
capability usually exhibit an image token compression ratio of 4. For
instance, Qwen-VL and Monkey reduce the number of image tokens from
1,024 to 256 for each $448\times448$ sub-image, while UReader compresses
it from 256 to 64 for each $224\times224$ sub-image. In this case, the
consumption of image tokens is still significant. To further explore the
possibility of a higher compression ratio, we propose a method combining
the advantages of resampling and rearrangement, named ReSA. As shown in
Fig. [fig:arch] (b), similar to previous MLLMs,
ReSA first resamples the image features with a cross-attention
mechanism. The hidden dimension of the cross-attention output mirrors
that of the visual encoder output, typically being several times smaller
than the hidden dimension of the LLMs. Capitalizing on this
characteristic, we introduce an additional rearrangement step to further
condense the number of image tokens. Following resampling, multiple
resampled tokens are concatenated into a single token and then
transformed into the latent space of LLMs through a linear projection.
In our experiments, each step of ReSA possesses a compression ratio of
4, resulting in a notably higher compression ratio of 16.
.5em 1ex .1ex -.5em Multi-Level Cross-Attention (MLCA). As mentioned in
previous works [blip2](None), [llava](http://arxiv.org/pdf/2402.11690v1), visual encoders are
pre-trained on specific tasks thus the features from their last layers
may focus more on those tasks. It has been proven that the features from
the second last layer yield better performance than the last
layer [llava](http://arxiv.org/pdf/2402.11690v1). Moreover, it is possible to merge features
from multiple layers. In the field of object detection, Feature Pyramid
Network (FPN) [fpn](http://arxiv.org/pdf/2108.00580v3) is well known for merging multi-level
features, which improves perception capability on fine-grained objects.
As for MLLMs, COMM [comm](None) has proved that merging deep
and shallow features is beneficial for reducing hallucination and
improving performance on fine-grained tasks, even when there is no
pyramid structure. Drawing inspiration from FPN, we propose a
multi-level feature merging strategy named MLCA. As shown in
Fig. [fig:arch] (b), MLCA enables the resampler
to absorb features from deep as well as shallow visual encoder layers
with a predefined routing table. As long as the total number of
resampler layers is not changed, MLCA has no extra computational cost
compared to the standard cross-attention. Empirically, we adopt 4 visual
encoder stages, extracting features from the 14th, 18th, 22nd, and 26th
encoder layers respectively.
Illustration of (a) scalable positional embeddings
interpolation and (b) query proposal network.
.5em 1ex .1ex -.5em Scalable Positional Embeddings (SPEs). The relative
positional relations among sub-images are ambiguous without the
inclusion of additional positional embeddings. To handle a variable
number of image patches, previous
works [pix2struct](None), [ureader](None) proposed to learn 2-D or
factorized absolute positional embeddings covering the maximum
positional index presented in the training data. Not only do they lack
effectiveness in extrapolation to out-of-domain shapes, but certainly
learned embeddings also exhibit under-fitting due to the non-uniform
distribution of training input shapes. To overcome the aforementioned
obstacles, we propose a novel method named SPEs, extending *factorized*
(where row and column are decomposed) positional embeddings to arbitrary
shapes. To be clear, the row and column embeddings are handled in the
same manner in SPEs, hence their specification is omitted in the
following part.
Assume the learned positional embeddings are initialized from a normal
distribution $\mathcal{N}(0, 1)$. Each positional embedding
$\boldsymbol{e}\in\mathbb{R}^d$ is a vector with $\ell_2$-norm
$\sqrt{d}$, indicating that the positional embeddings are distributed
across the surface of a hypersphere. In practice, the $\ell_2$-norm of
learned positional embeddings typically remains within a narrow range
during the whole training process, preserving the hypersphere
distribution characteristics. Spherical linear interpolation (Slerp), a
commonly employed technique in computer graphics, interpolates any
intermediate vector between two unit vectors, emerging as a potential
alternative to conventional interpolation methods for positional
embeddings.
To strictly meet the requirement of Slerp, we apply normalization and
scaling before interpolation for each attention *head*, ensuring uniform
$\ell_2$-norm across all positional embeddings: $$\begin{aligned}
\boldsymbol{e}_i&=s\frac{\tilde{\boldsymbol{e}}_i}{\|\tilde{\boldsymbol{e}}_i\|},
\end{aligned}$$ where $\tilde{\boldsymbol{e}}_i$ $(i\in\{0,1\})$ denotes
two learnable endpoint positional embeddings, and $s$ is a learnable
scaling factor initialized as $\sqrt{d}$.
As shown in Fig 3 (a), we employ Slerp to generate
arbitrary positional embeddings spanning between the endpoints:
$$\begin{aligned}
\theta&=\arccos\frac{\boldsymbol{e}_0\boldsymbol{e}_1}{\|\boldsymbol{e}_0\|\|\boldsymbol{e}_1\|},\\
\boldsymbol{e}(t)&=\frac{\sin(\theta-t\theta)}{\sin\theta}\boldsymbol{e}_0+\frac{\sin(t\theta)}{\sin\theta}\boldsymbol{e}_1,
\end{aligned}$$ where $t\in[0,1]$ is the fractional position, which can
be the relative position of a sub-image or an image patch.
.5em 1ex .1ex -.5em Query Proposal Network (QPN). Despite the
satisfactory performance of Q-Former observed on fixed resolution MLLMs,
the way of initializing the resampler queries from a fixed number of
learned parameters lacks flexibility under the variable resolution
settings. Reusing the initial queries on different sub-images might lead
to redundancy and undesired attention patterns, wherein resampled image
tokens corresponding to distinct sub-images but identical resampler
queries exhibit strong similarities and receive improperly higher
attention scores. To eliminate the side-effect of shared initial
queries, we propose a lightweight module called QPN for generating the
queries dynamically. As shown in
Fig 3 (b), the structure of QPN consists of
a 2-layer MLP with GELU activation, a max pooling layer, and a linear
projection layer. The output of the visual encoder is fed into QPN and
the number of proposed queries is hereby controlled by the stride of the
max pooling layer. For a fair comparison, our experiments adopt a stride
of $2\times2$ so that the compression ratio remains 4. The output
dimension of the MLP layers and the input dimension of the projection
layer are set to 4 times the hidden dimension of the visual encoder.
.5em 1ex .1ex -.5em Detection Head. Previous
works [shikra](http://arxiv.org/pdf/2306.15195v2), [qwen-vl](None), [llava-1.5](http://arxiv.org/pdf/2310.19145v1) on applying MLLMs for
localizing target objects mostly adopt plain text for representing
coordinates, which is intuitive since pre-trained LLMs work well on
regular text strings. However, plain text-based coordinates are
token-consuming, lowering both the training throughput and inference
efficiency. We propose to expand the vocab of MLLMs with special tokens
for normalized coordinates. Specifically, employing a regular text
string to depict a bounding box utilizes a total of $2+4\times5+3=25$
tokens, encompassing 2 trigger marks, 4 floating-point numbers, and 3
commas. However, by substituting multiple digit tokens of each
floating-point number with a unique coordinate token and remaining only
1 comma, we can lower the number of tokens to just $2+4+1=7$.
However, solely training the newly appended word embeddings with
language modeling loss on a small amount of data is not effective. In
our experiments, the model occasionally collapses, producing meaningless
coordinates. To alleviate the problem of inefficient training of
coordinate tokens, we aim to introduce an auxiliary training target.
Taking inspiration from DETR [detr](http://arxiv.org/pdf/2306.13526v1), we incorporate a
straightforward 2-layer MLP with ReLU activation function and a linear
projection layer as the auxiliary detection head, which runs in parallel
with the original output layer of the LLM. The output of the detection
head is normalized by the Sigmoid activation function. We evaluate the
error between the prediction and the ground truth by $\ell_1$ loss:
$$\begin{aligned}
\mathcal{L}_\text{box}&=\frac{1}{|\mathcal{B}|}\sum_{i\in \mathcal{B}}\|b_i-b^*_i\|_1,
\end{aligned}$$ where $b_i$ and $b^*_i$ are the predictions and the
ground truth of normalized bounding box coordinates at position $i$
respectively, and $\mathcal{B}$ is the set of coordinate token positions
in the output sequence.
.5em 1ex .1ex -.5em Loss Function. All of the data is organized into
multi-turn conversations, with each turn formatted as: $$\begin{aligned}
\text{User: }\mathcal{I}^t\text{Assistant: }\mathcal{R}^t\text{}
\end{aligned}$$ where \ and \ are special tokens denoting the
beginning and end of conversation messages. $\mathcal{I}^t$ and
$\mathcal{R}^t$ are the instruction tokens and response tokens at the
$t$-th turn. Unlike language instruction tuning which only involves text
tokens, $\mathcal{I}^t$ might consist of text, image, or both modality
tokens. The training of MLLMs is mainly based on the language modeling
loss over the response tokens: $$\begin{aligned}
\mathcal{L}_\text{lm}=-\frac{1}{\sum \alpha_i}\sum_{i\in \mathcal{M}}\alpha_i\log(p(x_i|\boldsymbol{x}_{
## Datasets
.5em 1ex .1ex -.5em Data Concatenation. Creating data batches with
sequences of varying lengths requires padding, resulting in the waste of
tokens. To mitigate this inefficiency and increase training throughput,
we combine multiple native samples into a single training sample.
Specifically, we select and concatenate samples from the dataset
randomly until the combined sequence length reaches a predefined maximum
value. It is worth noting that we carefully mask the native samples so
that they are *mutually invisible* from each other.
.5em 1ex .1ex -.5em Conceptual Captioning. To bridge basic perception
capability as well as align concept between visual encoder and LLM, 96M
image-text pairs are collected from image captioning datasets, including
CC3M [cc3m](None), CC12M [cc12m](None),
SBU [sbu](http://arxiv.org/pdf/2204.00679v1) and a subset of
LAION-400M [laion400m](None). In this task, the model generates
a short caption for the given image, as required by the prompt "*Briefly
describe the image*".
.5em 1ex .1ex -.5em Grounding Captioning. To empower MLLM with basic
grounding capability, a subset of GrIT [kosmos2](http://arxiv.org/pdf/2305.16103v1)
including 16M image-text pairs is adopted. In this task, the model
generates a short caption as well as the normalized bounding boxes of
referring objects in the image, as required by the prompt "*Briefly
describe the image, highlighting the key objects with normalized
bounding boxes*".
.5em 1ex .1ex -.5em OCR. Except for natural images, we are particularly
interested in document-oriented images. To enhance the perception
capability of MLLM for optical characters, 1.28M images from
IIT-CDIP [iit_cdip](http://arxiv.org/pdf/2305.06148v1) are collected. Three kinds of
queries, "*List the text content in the image*", "*List the text
bounding boxes in the image*" and "*List the text content along with
their bounding boxes in the image*", are used to prompt the model to
generate the text content, bounding boxes, or both of them for a given
image, of which the coarse labels are collected with a commercial OCR
system.
.5em 1ex .1ex -.5em Markdown. Inspired by
Nougat [nougat](http://arxiv.org/pdf/2308.13418v1), we collect 1.28M PDF pages and
corresponding Markdown content of scientific papers from arXiv source
files, which contain more layout information such as reading order than
regular OCR data. We use a simple instruction, "*Transcribe the content
of the document image*", to ask the model to convert a PDF page of
scientific paper into Markdown.
.5em 1ex .1ex -.5em Instruction. Following LLaVA-1.5, we build our
fine-tuning data based on existing datasets to enhance the
instruction-following and chatting capability of MLLMs on nature and
document-oriented tasks. Specifically, we adopt multiple datasets
including VQAv2 [vqav2](None), OK-VQA [okvqa](None),
GQA [gqa](None), A-OKVQA [aokvqa](None),
TextCaps [textcaps](None), OCR-VQA [ocrvqa](None),
RefCOCO [refcoco](http://arxiv.org/pdf/1808.08754v1), PointQA [pointqa](http://arxiv.org/pdf/2011.13681v4),
Flickr [flickr](http://arxiv.org/pdf/1903.05854v1), DocVQA [docvqa](None),
ChartQA [chartqa](None),
InfographicVQA (InfoVQA) [infovqa](http://arxiv.org/pdf/2104.12756v2),
TabFact [tabfact](None),
WikiTableQuestions (WTQ) [wtq](http://arxiv.org/pdf/2009.13845v2), VG [vg](None),
VisualMRC [visualmrc](http://arxiv.org/pdf/2101.11272v2), and
SlideVQA [slidevqa](None). The same prompts from LLaVA-1.5 are
adopted to regularize the response style of MLLMs. For each dataset, we
concatenate all of the QA pairs corresponding to the same training image
to create multi-turn conversations and improve data efficiency. Except
for the original tasks, we additionally introduce multiple tasks to help
the MLLMs recognize text and understand document layout, including OCR
task for DocVQA, InfoVQA, VisualMRC and SlideVQA, chart-to-table task
for ChartQA, and image-to-markdown task for TabFact and WTQ. To develop
a MLLM for general purpose, we make use of several dialogue datasets
including ShareGPT, ShareGPT-4V [sharegpt4v](http://arxiv.org/pdf/1809.10312v1),
ALLaVA [allava](None), LLaVA [llava](http://arxiv.org/pdf/2402.11690v1),
SVIT [svit](None), and Shikra [shikra](http://arxiv.org/pdf/2306.15195v2).
.5em 1ex .1ex -.5em DocGemini. To address the scarcity of high-quality
document-oriented dialogue datasets, we leverage the native visual
capabilities of Gemini-Pro for data augmentation. For each training
sample from DocVQA, ChartQA, and InfoVQA, we provide Gemini-Pro the
image and original QA pairs along with a query for generating: (1) a
brief summary of the document topics; (2) extra short QA pairs, up to
10; (3) insights behind each answer. In summary, the generated dataset
*DocGemini* consists of 30K images and 195K QA pairs with insights.
## Training [sec:train]
For all of the training stages, we adopt AdamW as the optimizer, with
$\beta_1=0.9$, $\beta_2=0.95$, and a weight decay of 0.05.
.5em 1ex .1ex -.5em Fixed Resolution Pre-Training. Inspired by BLIP-2,
we adopt large-scale conceptual captioning datasets to align a
pre-trained and frozen visual encoder with LLM. Specifically, 96M
image-text pairs are used in this stage. Each conceptual caption is a
brief description summarizing the overall information portrayed in an
image, rarely related to the fine-grained details. To accelerate
training, all images undergo resizing to $224\times224$. The maximum
sequence length is 4,096 and the batch size is 96, resulting in an
effective batch size of nearly 8,000 after data concatenation. We
pre-train the model for 12,000 steps, equivalent to almost 1 epoch
across the entire dataset. During pre-training, we freeze the visual
encoder and LLM and train the randomly initialized resampler and LoRA
modules. The learning rate linearly warmup to $3e^{-4}$ in the first 3%
steps, followed by cosine decay to $1e^{-5}$ in the remaining steps. It
takes 1 day to finish training on 48 NVIDIA V100 GPUs.
.5em 1ex .1ex -.5em Mixed Resolution Pre-Training. In this stage, we
adapt the resampler to variable resolution input. Images with different
native sizes and aspect ratios from the grounding captioning, OCR, and
Markdown datasets are used. The size of each sub-image is
$224\times224$. The maximum area $n$ is set to $36$ and the maximum
side-length $l$ is set to $12$. To accelerate the grid matching for
shape-adaptive cropping, $k$ is set to 9. The effective batch size is
nearly 1,500 and the number of training steps is 12,000, equivalent to
almost 1 epoch across the entire dataset. Except for the resampler and
LoRA, a detection head is randomly initialized and updated in this
stage. The weight $\alpha$ for coordinate tokens is set to $0.25$ (4
tokens per bounding box) and the weight $\lambda$ for $\ell_1$ loss is
set to 1. The visual encoder and LLM are kept frozen. The learning rate
linearly warmup to $1.5e^{-4}$ in the first 3% steps, followed by cosine
decay to $5e^{-6}$. It takes 3 days to finish training on 40 NVIDIA V100
GPUs.
.5em 1ex .1ex -.5em Mixed Resolution Supervised Fine-Tuning. During
fine-tuning, we merge LoRA weights into LLM and seamlessly train the
resampler, LLM, and detection head together, while keeping the visual
encoder frozen. The hyper-parameters for the shape-adaptive cropping and
the detection head are inherited from mixed resolution pre-training. The
maximum sequence length is 2,048. We train the model on
instruction-following data for 1 epoch with a batch size of 64. The
learning rate linearly warmup to $2e^{-5}$ in the first 3% steps,
followed by cosine decay to $0$. It takes 1 day to finish training on 32
NVIDIA V100 GPUs.
## Results on Standard Benchmarks
To demonstrate the effectiveness of our methods, we conduct a comparison
among TextHawk, two specialist models for document-oriented tasks, and
recent MLLMs on a wide range of benchmarks. Some qualitative results are
shown in Fig. [fig:visu]. Each benchmark targets a group
of general-purpose tasks or fined-grained tasks. Firstly, we evaluate
the models on comprehensive benchmarks including
MME [mme](None), MMBench [mmb](http://arxiv.org/pdf/2005.12661v2),
SEED-Bench [seedbench](http://arxiv.org/pdf/2311.15759v1), and GQA [gqa](None).
Since the image resolutions of these benchmarks are relatively low, we
further evaluate the capability of fined-grained perception on document
understanding and referring tasks, including
DocVQA [docvqa](None), ChartQA [chartqa](None),
InfoVQA [infovqa](http://arxiv.org/pdf/2104.12756v2), TabFact [tabfact](None),
WTQ [wtq](http://arxiv.org/pdf/2009.13845v2), and RefCOCO [refcoco](http://arxiv.org/pdf/1808.08754v1).
As depicted in Table [tab:benchmark], TextHawk excels in
both general and document-oriented benchmarks, securing the top spot in
6 out of 9 benchmarks. In all the general benchmarks, TextHawk not only
surpasses LLaVA-1.5-7B [llava-1.5](http://arxiv.org/pdf/2310.19145v1), but also achieves
comparable results with InternLM-XComposer [xcomposer](None),
despite the latter sharing the same foundational LLM but utilizing a
larger visual encoder. When compared to previous document-oriented
MLLMs, such as Ureader [ureader](None) and
TextMonkey [textmonkey](http://arxiv.org/pdf/2403.14252v1), TextHawk demonstrates superior
performance on document-oriented benchmarks. Specifically, TextHawk
achieves performance gains of $11.0\%$, $7.3\%$, $8.4\%$, $3.5\%$, and
$5.3\%$ on DocVQA, ChartQA, InfoVQA, TabFact, and WTQ, respectively,
when compared to Ureader. Remarkably, TextHawk even surpasses
TextMonkey, which employs a larger visual encoder, on DocVQA and WTQ
benchmarks. It is worth mentioning that the introduction of our
DocGemini data can further improve the performance on the
document-oriented benchmarks. Besides, TextHawk achieves competing
results on the RefCOCO dataset, showing its good capabilities on the
referring task.
## Ablation Study
We adopt two faster training configurations for the ablation study. The
fixed resolution pre-training is exactly the same as what is described
in Sec 4.2. Subsequently, fixed resolution
models are fine-tuned only on the training data of LLaVA-1.5 for 1
epoch, while variable resolution models are fine-tuned on the training
data of LLaVA-1.5, DocVQA, ChartQA, InfoVQA, TabFact, and WTQ.
.5em 1ex .1ex -.5em ReSampling and ReArrangement (ReSA). To demonstrate
the effectiveness of ReSA, we conduct fixed resolution experiments with
different compression configurations, and the results are shown in
Table 1. Compared to the resampling-only
strategy, incorporating ReSA which divides the compression procedure
into two stages improves performance on all benchmarks, especially on
RefCOCO as the referring comprehension task exhibits a great demand for
preserving more fine-grained information.
.5em 1ex .1ex -.5em Multi-Level Cross-Attention (MLCA). Empirically,
deep layers within visual encoders primarily capture global semantic
information, while shallow layers tend to retain local, intricate
details. To explore the effect of the routing strategy of MLCA, we
conduct experiments with different routing tables, shown in
Table 2. For the sake of simplicity, we use R1
to R5 to denote different routing tables. R1 is a special case that only
includes encoder stage 3, degrading to the vanilla cross-attention
settings. Comparing R1 and R2, we can find the latter significantly
improves the performance on fine-grained tasks, while slightly
sacrificing the performance on the general benchmarks. Comparing R2 and
R3/R4, we can find routing features from shallower encoder layers to
deeper resampler layers demonstrate higher accuracy on RefCOCO, compared
to routing them to intermediate resampler layers. Among all experimental
settings, R5 achieves a good balance between general tasks and
fine-grained tasks, hence we adopt it as the default routing table.
.5em 1ex .1ex -.5em Query Proposal Network (QPN). To validate the
importance of high-quality resampler queries, we compare initializing
queries from learned parameters and generating queries with QPN, as
shown in Table 3. For a fair comparison, the number of
queries is 64 in both experiments. We can find incorporating QPN
improves model performance on most benchmarks, especially on RefCOCO.
| PE | Granularity | $\text{RefCOCO}^\text{val}$ | DocVQA | ChartQA | InfoVQA |
|:----:|:-----------:|:---------------------------:|:------:|:-------:|:-------:|
| \- | \- | 79.13 | 67.68 | 61.04 | 39.77 |
| APEs | cell | 82.03 | 68.55 | 61.02 | 43.28 |
| SPEs | cell | 82.65 | 69.63 | 61.32 | 43.03 |
| SPEs | patch | 83.74 | 69.65 | 61.96 | 43.85 |
Effect of incorporating positional embeddings, where *APEs* denotes
absolute positional embeddings, and *SPEs* denotes scalable positional
embeddings. In the field of granularity, *cell* and *patch* mean
applying different embeddings for each sub-image and patch respectively.
.5em 1ex .1ex -.5em Scalable Positional Embeddings (SPEs). To explore
the effect of additional positional embeddings, we conduct experiments
with variable resolution settings. The results on fine-grained
benchmarks are shown in
Table 4. Apparently, the absence of additional
positional embeddings leads to performance degradation on most
benchmarks. Compared with absolute positional embeddings used in
previous works, SPEs further improve fine-grained performance.
Meanwhile, the granularity of SPEs can be extended from cell to patch
without increasing the number of parameters. It is confirmed that using
finer and smoother positional embeddings at the image patch level
further improves the overall performance.
| Head | $\text{RefCOCO}^\text{val}$ | $\text{RefCOCO}^\text{test-A}$ | $\text{RefCOCO}^\text{test-B}$ |
|:---|:--:|:--:|:--:|
| Language | 85.6 | 90.2 | 80.6 |
| Detection | 87.3 | 90.9 | 83.3 |
Comparison of heads on decoding coordinates.
.5em 1ex .1ex -.5em Detection Head. Both the original language modeling
head and the additional detection head are capable of generating
coordinates. Whenever the former produces a coordinate token, we can
seamlessly substitute it with the output from the latter. In
Table 5, we compare the results of different
heads on RefCOCO. It is obvious that the detection head demonstrates
higher accuracy on all splits, proving its superiority on the grounding
tasks.
# Limitations
The visual encoder in TextHawk is frozen during training, which means it
does not learn from the training data. This could limit the model’s
ability to adapt to new or unseen visual data that significantly differs
from the data it was initially trained on. In the future, we will train
the vision encoder to further improve the perception capabilities.
# Conclusion
In this paper, we have presented TextHawk, a novel Multimodal Large
Language Model (MLLM) that is specifically designed to address the
unique challenges posed by document-oriented tasks. TextHawk introduces
several innovative components. These components work in synergy to
enhance the model’s fine-grained visual perception and information
compression capabilities, thereby enabling it to handle the high
resolution and information density characteristic of document images.
Our extensive experiments on both document-oriented and general MLLM
benchmarks demonstrate that TextHawk outperforms state-of-the-art
methods, showcasing its superior fine-grained document perception and
general vision-language abilities.
InternLM-XComposer2-4KHD: A Pioneering Large Vision-Language Model Handling Resolutions from 336 Pixels to 4K HD
2024-04-09
Xiaoyi Dong, Pan Zhang, Yuhang Zang, Yuhang Cao, Bin Wang, Linke Ouyang, Songyang Zhang, Haodong Duan, Wenwei Zhang, Yining Li, Hang Yan, Yang Gao, Zhe Chen, Xinyue Zhang, Wei Li, Jingwen Li, Wenhai Wang, Kai Chen, Conghui He, Xingcheng Zhang, Jifeng Dai, Yu Qiao, Dahua Lin, Jiaqi Wang
The Large Vision-Language Model (LVLM) field has seen significant advancements, yet its progression has been hindered by challenges in comprehending fine-grained visual content due to limited resolution. Recent efforts have aimed to enhance the high-resolution understanding capabilities of LVLMs, yet they remain capped at approximately 1500 x 1500 pixels and constrained to a relatively narrow resolution range. This paper represents InternLM-XComposer2-4KHD, a groundbreaking exploration into elevating LVLM resolution capabilities up to 4K HD (3840 x 1600) and beyond. Concurrently, considering the ultra-high resolution may not be necessary in all scenarios, it supports a wide range of diverse resolutions from 336 pixels to 4K standard, significantly broadening its scope of applicability. Specifically, this research advances the patch division paradigm by introducing a novel extension: dynamic resolution with automatic patch configuration. It maintains the training image aspect ratios while automatically varying patch counts and configuring layouts based on a pre-trained Vision Transformer (ViT) (336 x 336), leading to dynamic training resolution from 336 pixels to 4K standard. Our research demonstrates that scaling training resolution up to 4K HD leads to consistent performance enhancements without hitting the ceiling of potential improvements. InternLM-XComposer2-4KHD shows superb capability that matches or even surpasses GPT-4V and Gemini Pro in 10 of the 16 benchmarks. The InternLM-XComposer2-4KHD model series with 7B parameters are publicly available at https://github.com/InternLM/InternLM-XComposer.
Show Paper Content
# Introduction [sec:intro]
In recent years, the progress in Large Language Models
(LLMs) [openai2020chatgpt](https://openai.com/blog/chatgpt), [touvron2023llama](http://arxiv.org/pdf/2402.08075v1), [touvron2023llama2](https://arxiv.org/pdf/2307.09288), [jiang2023mistral](https://arxiv.org/pdf/2310.06825), [2023internlm](https://github.com/InternLM/InternLM), [cai2024internlm2](http://arxiv.org/pdf/2403.17297v1), [qwen7b](http://arxiv.org/pdf/2305.05352v6), [du2022glm](http://arxiv.org/pdf/2103.10360v2), [vicuna2023](https://lmsys.org/blog/2023-03-30-vicuna/)
has provoked the development of Large Vision-Language Models (LVLMs).
These models have demonstrated proficiency in tasks such as image
captioning [chen2015microsoft](https://arxiv.org/pdf/1504.00325), [chen2023sharegpt4v](http://arxiv.org/pdf/1809.10312v1) and
visual-question-answering
(VQA) [MMBench](http://arxiv.org/pdf/2005.12661v2), [fu2023mme](http://arxiv.org/pdf/2306.05179v2), [seed_2023](http://arxiv.org/pdf/2307.08041v2), [yue2023mmmu](http://arxiv.org/pdf/2311.16502v3).
Nevertheless, due to their limited resolution, they struggle with
processing images containing fine details, such as
charts [masry2022chartqa](http://arxiv.org/pdf/2203.10244v1),
tables [textvqa](http://arxiv.org/pdf/1811.11903v1), documents [docvqa](http://arxiv.org/pdf/2111.05547v1), and
infographics [infovqa](http://arxiv.org/pdf/2104.12756v2). This limitation constrains their
practical applicability in real-world scenarios.
Recent advancements have aimed at enhancing the resolution of Large
Vision-Language Models (LVLMs). Some
approaches [lv2023kosmos25](https://arxiv.org/pdf/2309.11419), [cogagent](http://arxiv.org/pdf/2402.11941v2), [wei2023vary](None), [li2024mini](None)
involve adapting high-resolution vision encoders directly. However, the
Vision Transformer (ViT) architecture falls short when dealing with
images of varying resolutions and aspect ratios, thereby restricting its
ability to handle diverse inputs effectively. Alternatively, some
methods [li2023monkey](http://arxiv.org/pdf/2103.15488v1), [monkeytext](http://arxiv.org/pdf/2403.14252v1), [docowl](http://arxiv.org/pdf/2307.02499v1), [lin2023sphinx](http://arxiv.org/pdf/2311.07575v1), [llavauhd](http://arxiv.org/pdf/2403.11703v1), [llavanext](https://llava-vl.github.io/blog/2024-01-30-llava-next/), [li2023otterhd](https://arxiv.org/pdf/2311.04219)
maintain the vision encoder’s resolution, segmenting high-resolution
images into multiple low-resolution patches. Yet, these methods are
constrained by an inadequate resolution, typically around 1500 $\times$
1500, which does not satisfy the demands of daily content, , website
screenshots [si2024design2code](https://arxiv.org/pdf/2403.03163), document
pages [docvqa](http://arxiv.org/pdf/2111.05547v1), and blueprints [infovqa](http://arxiv.org/pdf/2104.12756v2).
Furthermore, they are confined to either a few predefined
high-resolution
settings [cogagent](http://arxiv.org/pdf/2402.11941v2), [wei2023vary](None), [li2024mini](None), [li2023monkey](http://arxiv.org/pdf/2103.15488v1), [lin2023sphinx](http://arxiv.org/pdf/2311.07575v1), [llavanext](https://llava-vl.github.io/blog/2024-01-30-llava-next/), [li2023otterhd](https://arxiv.org/pdf/2311.04219), [lv2023kosmos25](https://arxiv.org/pdf/2309.11419), [monkeytext](http://arxiv.org/pdf/2403.14252v1)
or a limited range of resolutions [docowl](http://arxiv.org/pdf/2307.02499v1), [llavauhd](http://arxiv.org/pdf/2403.11703v1),
thereby restricting their utility across a variety of applications.
In this work, we introduce InternLM-XComposer2-4KHD, a pioneering model
that for the first time expands the resolution capabilities of Large
Vision-Language Models (LVLMs) to 4K HD and even higher, thereby setting
a new standard in high-resolution vision-language understanding.
Designed to handle a broad range of resolutions,
InternLM-XComposer2-4KHD supports images with any aspect ratio from 336
pixels up to 4K HD, facilitating its deployment in real-world contexts.
InternLM-XComposer2-4KHD follows patch
division [li2023monkey](http://arxiv.org/pdf/2103.15488v1), [li2023otterhd](https://arxiv.org/pdf/2311.04219) paradigm and
enhances it by incorporating an innovative extension: dynamic resolution
with automatic patch configuration. To be specific, scaling the
resolution of Large Vision-Language Models (LVLMs) to 4K HD and even
higher standard is far beyond merely increasing the number of patches.
It involves a nuanced approach to overcoming specific challenges: (1)
**Dynamic Resolution and Automatic Patch Configuration**: Addressing the
scarcity of high-resolution training data, our framework introduces a
strategy that dynamically adjusts resolution alongside an automatic
layout configuration. During training, it maintains the original aspect
ratios of images while adaptively altering patch (336 $\times$ 336)
layouts and counts. This results in a training resolution that exceeds
the original image resolutions, reaching up to 4KHD, addressing the
shortfall of high-resolution data. (2) **Handling Variability in Patch
Configurations**: Despite the apparent simplicity of dynamic resolution
training, the variability in patch configurations can heavily confuse
LVLMs. To mitigate this, we introduce a newline token after each row of
patch tokens to clearly delineate patch layouts, reducing training
ambiguity and significantly boosting performance. (3) **Inference Beyond
4K Resolution:** Our observations reveal that, even when trained on
images up to 4K resolution, the model can achieve additional performance
improvements during inference by processing images at higher
resolutions.
Furthermore, scaling the training resolution up to 4K standard results
in a consistent improvement in performance, highlighting the potential
for training even beyond 4K resolution. This underscores the capacity
for further enhancing model capabilities and suggests a promising
trajectory for advancing the frontiers of high-resolution image
processing within the domain of large vision-language models.
We evaluate our InternLM-XComposer2-4KHD on 16 diverse benchmarks
spanning various domains, including 5 challenging HD-OCR datasets
(DocVQA[docvqa](http://arxiv.org/pdf/2111.05547v1),
ChartQA[masry2022chartqa](http://arxiv.org/pdf/2203.10244v1),
InfographicVQA[infovqa](http://arxiv.org/pdf/2104.12756v2), TextVQA[textvqa](http://arxiv.org/pdf/1811.11903v1)
and OCRBench[ocrbench](https://arxiv.org/pdf/2305.07895)). Compared to previous open-source
LVLM models and closed-source APIs, our approach achieves SOTA results
in 6 of 16 benchmarks, demonstrating competitive performance despite
only 7B parameters. As shown in
Figure 1, InternLM-XComposer2-4KHD even
surpasses the performance of GPT4V [openai2023gpt4](https://arxiv.org/pdf/2303.08774) and
Gemini Pro [geminiteam2023gemini](https://arxiv.org/pdf/2312.11805) across ten benchmarks.
Notably, our method exhibits excellent performance on 5 HD-OCR datasets,
over existing open-source LVLMs by a substantial margin.
# Related Works [sec:related]
Large Language Models
(LLMs) [brown2020language](http://arxiv.org/pdf/2112.07522v2), [ouyang2022training](http://arxiv.org/pdf/2302.05206v1), [openai2020chatgpt](https://openai.com/blog/chatgpt), [chowdhery2022palm](http://arxiv.org/pdf/2209.05735v4), [kaplan2020scaling](http://arxiv.org/pdf/1906.09379v1), [touvron2023llama](http://arxiv.org/pdf/2402.08075v1), [touvron2023llama2](https://arxiv.org/pdf/2307.09288), [jiang2023mistral](https://arxiv.org/pdf/2310.06825), [2023internlm](https://github.com/InternLM/InternLM), [zeng2023glm-130b](https://openreview.net/forum?id=-Aw0rrrPUF), [baichuan2023baichuan2](https://arxiv.org/abs/2309.10305), [qwen7b](http://arxiv.org/pdf/2305.05352v6), [cai2024internlm2](http://arxiv.org/pdf/2403.17297v1)
have gained significant attention due to their impressive performance in
various language-related tasks such as text generation and question
answering. Following this enthusiasm, recent Large Vision-Language
Models (LVLMs) have
emerged[openai2023gpt4](https://arxiv.org/pdf/2303.08774), [chen2023pali](https://arxiv.org/pdf/2209.06794), [chen2023palix](https://arxiv.org/pdf/2305.18565), [chen2023pali3](https://arxiv.org/pdf/2310.09199), [driess2023palme](http://arxiv.org/pdf/2302.14030v3), [fu2023gemini](http://arxiv.org/pdf/2312.12436v2), [zhu2023minigpt](http://arxiv.org/pdf/2402.17510v1), [dai2023instructblip](https://arxiv.org/pdf/2305.06500), [zhang2023internlm](http://arxiv.org/pdf/2309.15112v5), [fuyu-8b](https://www.adept.ai/blog/fuyu-8b), [li2023otter](http://arxiv.org/pdf/2311.00233v2), [peng2023kosmos](http://arxiv.org/pdf/2305.16103v1), [ye2023mplug](http://arxiv.org/pdf/2405.00390v2), [awadalla2023openflamingo](http://arxiv.org/pdf/2402.17510v1),
combining LLMs with vision
encoders [radford2021learning](http://arxiv.org/pdf/2404.19696v1), [zhang2024long](None), [sun2023alpha](None)
to leverage the complementary strengths of language and vision
modalities. By fusing textual and visual representations, LVLMs can
ground language in visual contexts, enabling a more comprehensive
understanding and generation of multimodal
content [chen2023sharegpt4v](http://arxiv.org/pdf/1809.10312v1), [chen2023internvl](http://arxiv.org/pdf/2312.14238v3), [lin2023sphinx](http://arxiv.org/pdf/2311.07575v1), [bai2023qwen](http://arxiv.org/pdf/1412.3919v1), [wang2023cogvlm](https://arxiv.org/pdf/2311.03079), [internlmxcomposer2](http://arxiv.org/pdf/2402.17510v1), [cao2024dualfocus](None), [liu2024rar](None).
**LVLMs for High-Resolution Understanding.** Large Vision-Language
Models (LVLMs) often employ CLIP-ViT as the visual encoder for
vision-dependent tasks. However, the visual encoder’s reliance on low
resolutions, such as 224 $\times$ 224 or 336 $\times$ 336 pixels, limits
its effectiveness for high-resolution tasks like OCR and document/chart
perception. To enhance high-resolution understanding, recent works have
primarily employed the following strategies: (1) High-resolution (HR)
visual encoders or dual encoders catering to HR and low-resolution (LR)
inputs [lv2023kosmos25](https://arxiv.org/pdf/2309.11419), [wei2023vary](None), [cogagent](http://arxiv.org/pdf/2402.11941v2), [li2024mini](None).
For instance, Vary [wei2023vary](None) introduces a new image
encoder supporting HR inputs, which are then concatenated with LR
embeddings from the original CLIP visual encoder. Similarly,
CogAgent [cogagent](http://arxiv.org/pdf/2402.11941v2) and
Mini-Gemini [li2024mini](None) also separate HR and LR images
using distinct vision encoders, subsequently merging their features
using a cross-attention module. In contrast, our approach offers a more
simplified solution and shows advantages for varying resolutions and
aspect ratio inputs. (2) Cropped image
patches [li2023monkey](http://arxiv.org/pdf/2103.15488v1), [monkeytext](http://arxiv.org/pdf/2403.14252v1), [llavauhd](http://arxiv.org/pdf/2403.11703v1), [ureader](http://arxiv.org/pdf/2311.13165v1), [docowl](http://arxiv.org/pdf/2307.02499v1), [lin2023sphinx](http://arxiv.org/pdf/2311.07575v1), [li2023otterhd](https://arxiv.org/pdf/2311.04219).
For example, Monkey [li2023monkey](http://arxiv.org/pdf/2103.15488v1) employs sliding
windows to segment images into patches, subsequently processing them
with LoRA fine-tuning. TextMonkey [monkeytext](http://arxiv.org/pdf/2403.14252v1) further
proposes shifted window attention and token resampler to consider the
connections among different patches. These approaches are confined to
either a few predefined high-resolution
settings [cogagent](http://arxiv.org/pdf/2402.11941v2), [wei2023vary](None), [li2024mini](None), [li2023monkey](http://arxiv.org/pdf/2103.15488v1), [lin2023sphinx](http://arxiv.org/pdf/2311.07575v1), [llavanext](https://llava-vl.github.io/blog/2024-01-30-llava-next/), [li2023otterhd](https://arxiv.org/pdf/2311.04219), [lv2023kosmos25](https://arxiv.org/pdf/2309.11419), [monkeytext](http://arxiv.org/pdf/2403.14252v1)
or a limited range of resolutions [docowl](http://arxiv.org/pdf/2307.02499v1), [llavauhd](http://arxiv.org/pdf/2403.11703v1).
Conversely, our method devises a dynamic image partition strategy to
support the scaling from 336 pixels to 4K resolution, and the maximum
resolution is larger than previous approaches (, 1.5k for
Monkey [li2023monkey](http://arxiv.org/pdf/2103.15488v1) and 2k for
UReader [ureader](http://arxiv.org/pdf/2311.13165v1)).
**LVLMs for Document Understanding.** Document understanding involves
analyzing and comprehending various digital documents, such as figures,
tables, and academic papers. Many document understanding tasks require
models to handle high-resolution inputs, complex layouts, various aspect
ratios, and diverse document formats. To enhance the capabilities of
LVLMs for document understanding, several works have collected and
constructed high-quality document instruction tuning data, including
LLaVAR [zhang2023llavar](None),
mPLUG-DocOwl [ye2023mplug-doc](None) and
TGDoc [wang2023towards](http://arxiv.org/pdf/2311.13194v2).
DocPediaDocPedia [feng2023docpedia](None) processes document
inputs in the frequency domain. Some previous works have improved
document understanding ability by designing special modules for
high-resolution inputs, such as HR and LR
encoders [cogagent](http://arxiv.org/pdf/2402.11941v2), [wei2023vary](None) or cropped image
patches [ureader](http://arxiv.org/pdf/2311.13165v1), [monkeytext](http://arxiv.org/pdf/2403.14252v1), [llavauhd](http://arxiv.org/pdf/2403.11703v1). Our
InternLM-XComposer2-4KHD first scales to 4K resolution inputs and
demonstrates strong document understanding ability on OCR-related
benchmarks. Also, our approach also achieves comparable results on other
general LVLM benchmarks like perception and
reasoning [lu2024mathvista](http://arxiv.org/pdf/2310.02255v3), [MMBench](http://arxiv.org/pdf/2005.12661v2), [seed_2023](http://arxiv.org/pdf/2307.08041v2), [mmstar](http://arxiv.org/pdf/2006.11910v3).
# Method
## Model Architecture.
The model architecture of InternLM-XComposer2-4KHD mainly follows the
design of InternLM-XComposer2[internlmxcomposer2](http://arxiv.org/pdf/2402.17510v1)
(XComposer2 in the following for simplicity.), including a light-weight
Vision Encoder OpenAI ViT-Large/14, Large Language Model InternLM2-7B,
and Partial LoRA for efficient alignment. We recommend the readers to
the XComposer2 paper for more details.
## High-Resolution Input.
**Dynamic Image Partition.** Utilizing a static input image size for
processing high-resolution images, particularly those with varying
aspect ratios, is neither efficient nor effective. To overcome this
limitation, we introduce a dynamic image partitioning approach, as shown
in Figure 1. Our method strategically segments
the image into smaller patches, while maintaining the integrity of the
original image’s aspect ratio.
Given a maximum partition number $\mathcal{H}$, the image $x$ with size
$[h,w]$ is resized and padded to the new image $\hat{x}$ with size
$[p_h \times 336, p_w \times 336 ]$. This process is subject to the
following constraints:
$$p_w \times p_h \leq \mathcal{H}; \; p_h = \lceil p_w \times h / w \rceil$$
here $p_w$ and $p_h$ represent the number of patches in each row and
column, respectively. We then split the $\hat{x}$ into $p_h \times p_w$
non-overlapped patches. Each patch is a small image with $336\times336$
size and we treat these patches as individual inputs for the ViT.
In the following, we use ‘HD-$\mathcal{H}$’ to represent our
high-resolution setting with the constraint of $\mathcal{H}$ patches.
For example, the ’HD-9’ allows up to 9 patches, including a range of
resolutions such as $1008\times1008$, $672\times1344$, $336\times3024$,
.
**Global-Local Format.** For each input image, we present it to the
model with two views. The first is the global view, where the image is
resized to a fixed size (in our case, 336 × 336). This provides a macro
understanding of the image. Empirically, we have found this to be
crucial for the LVLM to correctly understand the image. The second view
is the local view. We divide the image into patches using the previously
mentioned Dynamic Image Partition strategy and extract features from
each patch. Following feature extraction, the patches are reassembled
into a large feature map. The feature map is then flattened to the final
local features after a straightforward token merging process.
**Image 2D Structure Newline Indicator.** Given that an image has a 2D
structure and the image ratio is dynamic, the number of tokens for each
row can vary across different images. This variation can potentially
confuse the LVLM, making it difficult to determine which tokens belong
to the same row of the image and which ones belong to the next row. This
confusion may hinder the LVLM’s ability to understand the 2D structure
of the image, which is crucial for comprehending structural image
content such as documents, charts, and tables. To address this issue, we
introduce a learnable newline (‘$\backslash$n’) token at the end of each
row of the image features before the flattening. Finally, we concatenate
the global and local views, inserting a special ‘separate’ token between
them to distinguish the two views.
## Pre-Training
During the pre-training phase, the LLM is frozen while both the vision
encoder and Partial LoRA are fine-tuned to align the visual tokens with
the LLM. The pre-training data mainly follow the design in XComposer2
which is curated with **three objectives** in mind: 1) general semantic
alignment, 2) world knowledge alignment, 3) vision capability
enhancement. In this paper, we focus on high-resolution and structural
image understanding. Therefore, we have collected more related data to
enhance this specific capability. As shown in
Table.[tab:pretrain_data], we have
utilized a diverse OCR dataset for this purpose.
In practice, we employ the OpenAI CLIP ViT-L-14-336 as the vision
encoder. Different from XComposer2, We keep the ViT resolution as
$336\times336$ and increase the input resolution with more patches. For
the Dynamic Image Partition strategy, we use ‘HD-25’ for the pertaining.
For each image or patch, the image token number is decreased to $1/4$
with a simple **merge operation**. We concatenate the nearby 4 tokens
into a new token through the channel dimension, then align it with the
LLM by an MLP. The ‘separate’ and ‘$\backslash$n’ token are randomly
initialized. For the Partial LoRA, we set a rank of $256$ for all the
linear layers in the LLM decoder block. Our training process involves a
batch size of 4096 and spans across 2 epochs. The learning rate linearly
increases to $2 \times 10^{-4}$ within the first $1\%$ of the training
steps. Following this, it decreases to $0$ according to a cosine decay
strategy. To preserve the pre-existing knowledge of the vision encoder,
we apply a layer-wise learning rate (LLDR) decay strategy, and the decay
factor is set to $0.90$.
## 4KHD Supervised Fine-tuning
After the pre-training, we empower the model to understand
high-resolution images and solve diverse challenges. Different from
previous perception tasks (, VQAv2, GQA) which typically answer
questions based on the noticeable object in the image. OCR-related tasks
depend on a detailed understanding of text within a high-resolution
image. For instance, in InfoVQA, the length of the longer side of 50% of
the images exceeds 2000 pixels. Low-resolution inputs can distort the
dense text information, causing the model to fail in its understanding.
However, we have observed a resolution saturation problem with the
aforementioned perception tasks, where the influence of resolution
becomes negligible.
To address this, we introduce a mixed-resolution training strategy for
more efficient training. For tasks requiring high resolution, we employ
the ‘HD-55’ setting during training. This allows for the input of 4K
($3840\times1600$) images without necessitating additional image
compression. These tasks are referred to as the HD-OCR QA tasks in
Table [tab:sft data]. For other tasks, we
implement a dynamic-resolution strategy. Images are resized to fall
within a range between their original size and the size specified by the
‘HD25’ setting. This dynamic approach enhances the robustness of the
LVLM against differences in input resolution, thereby enabling the LVLM
to utilize a larger resolution during inference. For instance, we have
observed that using the ‘HD30’ setting yields better results on most
OCR-related tasks when the LVLM is trained under the ‘HD25’ setting.
In practice, we jointly train all the components with a batch size of
2048 over 3500 steps. Data from multiple sources are sampled in a
weighted manner, with the weights based on the number of data from each
source. As the ‘HD-55’ setting has double image tokens than the ‘HD-25’,
we adjust the data loader to enable different batch sizes for them and
adjust their weight accordingly. The maximum learning rate is set to
$5 \times 10^{-5}$, and each component has its own unique learning
strategy. For the vision encoder, we set the LLDR to $0.9$, which aligns
with the pretraining strategy. For the LLM, we employ a fixed learning
rate scale factor of $0.2$. This slows down the update of the LLM,
achieving a balance between preserving its original capabilities and
aligning it with vision knowledge.
# Experiments
In this section, we validate the benchmark performance of our
InternLM-XComposer2-4KHD (IXC2-4KHD in the following for simplicity)
after supervised fine-tuning.
## LVLM Benchmark results.
In Table [tab:sota_comp] and Table
[tab:entire_comp], we compare our
IXC2-4KHD on a list of benchmarks with both SOTA open-source LVLMs and
closed-source APIs. Here we report results in
DocVQA[docvqa](http://arxiv.org/pdf/2111.05547v1), ChartQA[masry2022chartqa](http://arxiv.org/pdf/2203.10244v1),
InfographicVQA[infovqa](http://arxiv.org/pdf/2104.12756v2), TextVQA[textvqa](http://arxiv.org/pdf/1811.11903v1),
OCRBench[ocrbench](https://arxiv.org/pdf/2305.07895), MMStar[mmstar](http://arxiv.org/pdf/2006.11910v3),
MathVista[lu2024mathvista](http://arxiv.org/pdf/2310.02255v3),
MMMU[yue2023mmmu](http://arxiv.org/pdf/2311.16502v3),
AI2D[kembhavi2016diagram](http://arxiv.org/pdf/1603.07396v1), MME
[fu2023mme](http://arxiv.org/pdf/2306.05179v2), MMBench (MMB) [MMBench](http://arxiv.org/pdf/2005.12661v2),
MMBench-Chinese (MMB$^{CN}$) [MMBench](http://arxiv.org/pdf/2005.12661v2), SEED-Bench Image
Part (SEED$^{I}$)[li2023seedbench](https://arxiv.org/pdf/2307.16125), QBench-Testset
(QBench$^{T}$)[wu2023q](http://arxiv.org/pdf/2301.05065v2), MM-Vet
[yu2023mmvet](http://arxiv.org/pdf/2402.15896v1), HallusionBench
(HallB)[guan2023hallusionbench](https://arxiv.org/pdf/2310.14566). The evaluation is mainly
conducted on the OpenCompass VLMEvalKit[2023opencompass](https://github.com/open-compass/opencompass)
for the unified reproduction of the results.
**Comparison with Closed-Source APIs.** As demonstrated in Table
[tab:sota_comp], IXC2-4KHD exhibits
competitive performance across a variety of benchmarks, rivaling that of
Closed-Source APIs. Owing to its high-resolution input, IXC2-4KHD
achieves a score of $90.0\%$ on DocVQA and $81.0\%$ on ChartQA, thereby
surpassing GPT-4V and Gemini-Pro with a non-trivial margin. In the
challenging InfographicVQA task, our model is the first open-source
model that is close to the performance of Closed-Source APIs, exceeding
the performance of previous open-source models by nearly $20\%$. In
addition to OCR-related tasks, IXC2-4KHD is a general-purpose Large
Vision-Language Modal that excels in semantic-level tasks, demonstrating
competitive results.
**Comparison with Open-Source Models.** We also conduct a comprehensive
comparison with open-source LVLMs under a similar model scale. As shown
in Table [tab:entire_comp], our model
significantly outperforms existing open-source models, achieving
competitive results across all benchmarks. Notably, the
InternLM-XComposer2 series is the only method that achieves a higher
than $50\%$ score on the challenging MMStar benchmark.
**High-resolution Understanding Evaluation.** Then we compare IXC2-4KHD
with models that are specifically designed for high-resolution
understanding tasks. We report the results of 5 high-resolution
benchmarks in Table [tab:high-reso], as a general LVLM,
IXC2-4KHD shows superb performance on these tasks and outperforms
competitors with a large margin. For example, IXC2-4KHD gets $68.6\%$ on
InfographicVQA, surpassing recent DocOwl 1.5 with $+17.9\%$. For the
OCRBench, IXC2-4KHD gets $67.5\%$, outperforms CogAgent with $+8.5\%$.
## Dive into Resolution
**High-Resolution Training is Critical for HD-OCR tasks.** We study four
resolution settings: HD-9 (1561 image tokens at most, we simply the
statement if the following), HD-16 (2653 tokens), HD-25 (4057 tokens),
and 4KHD (8737 tokens). Here we report the validation set of InfoVQA,
DocVQA, and TextVQA, test set of ChartQA and AI2D, MMBench EN-Test, and
a 2k subset of SEEDBench (we denote it as SEED$^*$). In the following
experiments, we report results on the above benchmarks by default.
As illustrated in Fig.[fig:reso], we note a significant
improvement in the HD-OCR tasks as the resolution increases. For
instance, the model achieves only a $50.5\%$ score on the InfographicVQA
with the HD-9 setting. However, when we switch to the HD-16 setting, we
observe a performance gain of $+10.2\%$. The performance continues to
improve as the resolution increases, with saturation not observed even
for the 4KHD setting. Due to computational constraints, we defer the
exploration of the upper bound of improvement to future work. In terms
of other OCR-related tasks, the performance gain attributable to
increased resolution is relatively minor. For the perception-related
benchmarks, performance is saturated on the resolution that only has
negligible difference between the four settings.
**Higher Inference Resolution Leads to better results on Text-related
Tasks.** An intriguing observation from our experiments is that our
model, when inferring with a slightly higher resolution, tends to yield
improved results on text-related tasks. We present the results of HD-9,
HD-16, and HD-25 in Table
[tab:eval_resolution]. For
instance, IXC2-HD9 achieves a $50.5\%$ score on InfographicVQA. When we
infer with HD16, we see a performance gain of $+8.1\%$, without
additional training. Similar improvements are also observed with
IXC2-HD16 and IXC2-HD25. We posit that the dynamic image token length
used in training enhances the robustness of the LVLM, leading to better
results when the text in the image is more ‘clear’ in the higher
resolution input. Conversely, the results on ChartQA consistently
degrade under this setting. This could be due to the model becoming
confused about the chart structure when the resolution is altered.
Additionally, similar to the observation from Figure
[fig:reso], the impact of resolution on
perception-related benchmarks appears to be quite minor.
**Visualization Results.** We provide the visualization results on
ultra-high HD images in Figure
[fig:teaser1] and Figure
[fig:teaser2]. Please refer to the
appendix for more results.
## High-Resolution Strategy Ablation
**The Role of Global-View.** We first examine the impact of the global
view in our Global-Local Format. As indicated in Table
[tab:global_view], we find that the
global view is essential for the LVLM to accurately comprehend the input
image. When it is removed, the model performs worse across all
benchmarks. For instance, the model experiences a $-4.4\%$ drop in
performance on the MMBench EN-Test without the global view. We contend
that the global view offers a general macro understanding of the image,
which the model struggled to derive from the large number of tokens in
the local view.
**The Role of the Newline Token.** We incorporate a special newline
token at the end of each row of the image features before the flattening
operation. This token serves as an indicator of the image’s 2D
structure. We examine its impact on both the HD-9 and 4KHD strategies in
Table [tab:gang_n]. When a fixed
high-resolution strategy HD-9 is employed, we observe that the benefit
derived from the newline token is minor. This could be attributed to the
LVLM’s ability to handle limited differences in image ratios after
training. However, when we implement a more challenging 4KHD (HD-25 +
HD-55) strategy, which exhibits significant diversity in both image
ratio and token number, the LVLM demonstrates a notable decline in
performance on OCR-related tasks without the newline indicator. This
finding supports our hypothesis that the LVLM struggles to comprehend
the shape of the image when the image tokens are directly flattened into
a 1D sequence. The newline token can assist the model in better
understanding the structure of the image.
**Influence of Token Merging Strategy.** In practice, we employ a simple
merging strategy that concatenates four adjacent tokens along the
channel dimension. We have found this approach to be effective in
reducing the number of image tokens efficiently. Here we study the
influence of different token-merging strategies under the 4KHD setting.
In Table [tab:merge], we study two additional
strategies: Re-Sampler[bai2023qwen](http://arxiv.org/pdf/1412.3919v1) and
C-Abstractor[cha2023honeybee](http://arxiv.org/pdf/2312.06742v2), with their default setting
and the same compressing rate $0.25$, , reducing an image with 576
tokens to 144 tokens. Results show that both concatenation and
C-Abstractor work well and get similar results on most benchmarks, this
observation is also consistent with the study in
MM-1[mckinzie2024mm1](http://arxiv.org/pdf/2403.01757v1) that the influence of the connector
is minor. However, the Re-Sampler performs worse than the other methods
with a noticeable margin. We argue this is caused by the learnable
queries used for gathering information requiring a great number of data
for training, our pre-training data is somewhat lightweight for it to
converge fully.
# Conclusion
In this paper, we propose the InternLM-Xcomposer2-4KHD that exceeds the
performance of previous open-source models on OCR-related tasks and also
achieves competitive results on general-purpose LVLM benchmarks. Thanks
to our dynamic resolution and automatic patch configuration, our model
supports a maximum training resolution of up to 4K HD. We also integrate
a global view patch to support the macro understanding and a learnable
newline token to handle the various input image resolutions. Our model’s
performance continues to improve as the training resolution increases
for HD-OCR tasks. Notably, we do not observe any performance saturation
even for the 4KHD setting, and we have not explored the upper bound due
to the computational burden increasing with higher-resolution inputs. In
future work, we plan to explore efficient solutions for accurate LVLM
training and inference, enabling our model to handle even higher
resolutions while maintaining computational efficiency.
Ferret-UI: Grounded Mobile UI Understanding with Multimodal LLMs
2024-04-08
Keen You, Haotian Zhang, Eldon Schoop, Floris Weers, Amanda Swearngin, Jeffrey Nichols, Yinfei Yang, Zhe Gan
Recent advancements in multimodal large language models (MLLMs) have been noteworthy, yet, these general-domain MLLMs often fall short in their ability to comprehend and interact effectively with user interface (UI) screens. In this paper, we present Ferret-UI, a new MLLM tailored for enhanced understanding of mobile UI screens, equipped with referring, grounding, and reasoning capabilities. Given that UI screens typically exhibit a more elongated aspect ratio and contain smaller objects of interest (e.g., icons, texts) than natural images, we incorporate "any resolution" on top of Ferret to magnify details and leverage enhanced visual features. Specifically, each screen is divided into 2 sub-images based on the original aspect ratio (i.e., horizontal division for portrait screens and vertical division for landscape screens). Both sub-images are encoded separately before being sent to LLMs. We meticulously gather training samples from an extensive range of elementary UI tasks, such as icon recognition, find text, and widget listing. These samples are formatted for instruction-following with region annotations to facilitate precise referring and grounding. To augment the model's reasoning ability, we further compile a dataset for advanced tasks, including detailed description, perception/interaction conversations, and function inference. After training on the curated datasets, Ferret-UI exhibits outstanding comprehension of UI screens and the capability to execute open-ended instructions. For model evaluation, we establish a comprehensive benchmark encompassing all the aforementioned tasks. Ferret-UI excels not only beyond most open-source UI MLLMs, but also surpasses GPT-4V on all the elementary UI tasks.
Show Paper Content
is able to perform referring tasks (e.g., widget classification, icon recognition, OCR) with flexible input formats
(point, box, scribble) and grounding tasks (e.g., find widget, find icon, find text, widget listing) on mobile UI
screens. These elementary tasks equip the model with rich visual and
spatial knowledge, enabling it to distinguish UI types at both coarse
and fine levels, such as between various icons or text elements. This
foundational knowledge is crucial for performing more advanced tasks.
Specifically, is able to not only discuss visual elements in detailed description and perception conversation, but also
propose goal-oriented actions in interaction conversation and deduce the
overall function of the screen via function inference.
# Introduction
Mobile applications have become an important part of daily life, serving
as tools for individuals to achieve personal goals including searching
for information, making reservations, and seeking entertainment. In this
usage, we inspect the current screen visually, and perform the desired
actions based on our goals. Automating this process of perception and
interaction has the potential to help users achieve their goals with
relative ease. Moreover, it is also a valuable building block for
accessibility [edwards1995access](http://arxiv.org/pdf/2306.06811v1), multi-step UI
navigation
[hong2023cogagent](http://arxiv.org/pdf/2402.11941v2), [zhang2023appagent](https://arxiv.org/pdf/2312.13771), [wang2024mobileagent](https://arxiv.org/pdf/2401.16158),
app testing [amalfitano2011gui](http://arxiv.org/pdf/1911.05403v2), [linares2017continuous](http://arxiv.org/pdf/1801.06267v1),
usability studies [jiang2018usability](http://arxiv.org/pdf/2305.03271v2), and many others.
To facilitate seamless automation of perception and interaction within
user interfaces, a sophisticated system endowed with a set of key
capabilities is essential. Such a system must possess the ability to not
only comprehend the entirety of a screen but also to concentrate on
specific UI elements within that screen. With visual understanding as
the foundation, it should further be able to map natural language
instructions to corresponding actions within a given UI, execute
advanced reasoning, and provide exhaustive details concerning the
screens it interacts with. These requirements necessitate the
development of a vision-language model adept at both referring and
grounding in relation to UI screens. Here, *referring* requires the
system to utilize particular regional image information in the screen
input, while *grounding* involves the model’s capacity to identify and
denote precise locations on the screen in its outputs.
Existing approaches are insufficient in fully addressing these key
capabilities. On one hand, while Multimodal Large Language Models
(MLLMs) like Ferret [you2023ferret](https://arxiv.org/pdf/2310.07704),
Shikra [chen2023shikra](http://arxiv.org/pdf/2306.15195v2), and
Kosmos2 [peng2023kosmos](http://arxiv.org/pdf/2305.16103v1) demonstrate strong referring and
grounding capabilities, their scope is mainly restricted to natural
images. Directly adapting these models to UI screens can be limiting,
since UI screens typically exhibit more elongated aspect ratios and
contain smaller objects of interests (*e.g.*, icons and texts) than
natural images. Relying solely on a directly resized, low-resolution
global image could lead to loss of important visual signals that are
essential for screen understanding and interaction. On the other hand,
other works targeting directly at UI tasks have primarily focused on
processing entire screens as singular inputs (*e.g.*,
Pix2Struct [lee2023pix2struct](http://arxiv.org/pdf/2210.03347v2),
ILuvUI [jiang2023iluvui](https://arxiv.org/pdf/2310.04869),
CogAgent [hong2023cogagent](http://arxiv.org/pdf/2402.11941v2)), only supports referring
tasks with one bounding box in the input (*e.g.*,
Spotlight [li2023spotlight](https://arxiv.org/pdf/2209.14927)), and leveraging
GPT-4V [yang2023dawn](https://arxiv.org/pdf/2309.17421) to navigate UI screens, as seen in
MM-Navigator [yan2023gpt](http://arxiv.org/pdf/2311.07562v1),
AppAgent [zhang2023appagent](https://arxiv.org/pdf/2312.13771), and
MobileAgent [wang2024mobileagent](https://arxiv.org/pdf/2401.16158). Furthermore, the tasks
studied in these work do not comprehensively cover all dimensions of UI
screen understanding.
In this paper, we present Ferret-UI, the first MLLM designed to execute
precise referring and grounding tasks specific to UI screens, while
adeptly interpreting and acting upon open-ended language instructions.
We address the aforementioned limitations by focusing on three pivotal
dimensions: ($i$) improved model architecture, ($ii$) data curation, and
($iii$) benchmark establishment. For model architecture, we base our
approach on Ferret [you2023ferret](https://arxiv.org/pdf/2310.07704), an MLLM known for its
strong performances in referring and grounding with natural images. We
posit that such capabilities provide a solid foundation in interactive
UI-centric tasks. For flexible adaptation of UI screen aspect ratios, we
integrate “any resolution” (anyres) into Ferret similar to
[liu2024llavanext](https://llava-vl.github.io/blog/2024-01-30-llava-next/), [lin2023sphinx](https://arxiv.org/pdf/2311.07575), [gao2024sphinxx](https://arxiv.org/pdf/2402.05935), but
with pre-defined grid configurations to divide the full image into
sub-images so that both portrait and landscape screens can be
accommodated. As later shown in Fig.
[fig:ferret-ui-architecture],
sub-image features are used in addition to global image features to help
magnify details and provide enhanced visual features.
To train Ferret-UI, we generate data at different granularities,
covering basic semantic and spatial tasks for UI primitives to advanced
reasoning tasks. We first generate training samples for elementary UI
tasks using a template-based approach. This encompasses *referring*
tasks such as *widget classification*, *icon recognition*, *OCR*, and
*grounding* tasks like *find widget*, *find icon*, *find text*, and
*widget listing*. These tasks are instrumental in teaching the model to
understand the semantics and spatial positioning of UI elements,
enabling the model to make distinctions at both a broad level (among
various UI types) and a more detailed level (within specific UI types,
such as icons or text). For advanced tasks, we use
GPT-4 [openai2024gpt4](https://arxiv.org/pdf/2303.08774) to generate data, including
*detailed description*, *conversation perception*, *conversation
interaction*, and *function inference*. These advanced tasks prepare the
model to engage in more nuanced discussions about visual components,
formulate action plans with specific goals in mind, and interpret the
general purpose of a screen. Fig.
1 illustrates examples of
Ferret-UI’s proficiency in handling the 11 tasks ranging from basic to
advanced.
To assess these capabilities, we develop a comprehensive test benchmark
featuring 14 diverse mobile UI tasks in terms of referring and
grounding. This includes 3 tasks from
Spotlight [li2023spotlight](https://arxiv.org/pdf/2209.14927) (*screen2words*, *widget
captions*, and *taperception*), and dual versions of the 11 UI tasks
previously described, tailored for both iPhone and Android screens. We
conduct comprehensive evaluation of a variety of UI understanding
models, including both open-source MLLMs (*e.g.*, CogAgent
[hong2023cogagent](http://arxiv.org/pdf/2402.11941v2) and Fuyu [fuyu-8b](https://www.adept.ai/blog/fuyu-8b)) and
GPT-4V. We observe that Ferret-UI significantly surpasses the base
Ferret model, illustrating the importance of domain-specific model
training. Compared to GPT-4V, Ferret-UI demonstrates superior
performance in elementary UI tasks. Notably, in the context of advanced
tasks, Ferret-UI surpasses both Fuyu and CogAgent.
Our contributions are summarized as follows. ($i$) We propose Ferret-UI
with “any-resolution” (anyres) integrated to flexibly accommodate
various screen aspect ratios. It represents the first UI-centric MLLM
that is capable of effectively executing referring, grounding, and
reasoning tasks. ($ii$) We define a set of elementary and advanced UI
tasks, for which we have meticulously gathered training samples for
model training. ($iii$) We develop a comprehensive test benchmark
encompassing all the tasks under investigation. Through careful
experiments and analysis, we offer insights into the model’s
capabilities and limitations.
# Related Work [sec:related_work]
Earlier works
[shi2017world](http://arxiv.org/pdf/2401.03546v1), [liu2018reinforcement](http://arxiv.org/pdf/1802.08802v1), [gur2018learning](http://arxiv.org/pdf/2103.01991v1), [li2020mapping](http://arxiv.org/pdf/2005.03776v2), [burns2022dataset](http://arxiv.org/pdf/2202.02312v3)
in the area focus on studying simplified web and mobile screens. With
recent advances in both
LLMs [touvron2023llama](http://arxiv.org/pdf/2402.08075v1), [openai2024gpt4](https://arxiv.org/pdf/2303.08774), [gu2023mamba](http://arxiv.org/pdf/2403.16371v1), [jiang2023mistral](http://arxiv.org/pdf/2401.13565v3), [huang2023language](https://arxiv.org/pdf/2302.14045), [driess2023palm](http://arxiv.org/pdf/2302.14030v3), [anil2023palm](http://arxiv.org/pdf/2305.10403v3)
and
MLLMs [liu2023llava](https://arxiv.org/pdf/2304.08485), [zhu2023minigpt](http://arxiv.org/pdf/2402.17510v1), [ye2023mplug](http://arxiv.org/pdf/2405.00390v2), [li2023otter](http://arxiv.org/pdf/2311.00233v2), [dai2023instructblip](http://arxiv.org/pdf/2311.00233v2), [sun2023generative](http://arxiv.org/pdf/2203.15788v1), [mckinzie2024mm1](http://arxiv.org/pdf/2403.01757v1), [li2023multimodal](http://arxiv.org/pdf/2309.10020v1),
the approaches to many research problems have been transformed,
including UI understanding. Several works have explored the use of MLLMs
for UI tasks. Specifically, ILuvUI [jiang2023iluvui](https://arxiv.org/pdf/2310.04869) and
Spotlight [li2023spotlight](https://arxiv.org/pdf/2209.14927) concentrate on single-screen
UI tasks while exploring various UI tasks by fine-tuning on
GPT-generated data and delving into UI tasks such as screen
summarization and widget interaction.
MobileAgent [wang2024mobileagent](https://arxiv.org/pdf/2401.16158) and AppAgent
[zhang2023appagent](https://arxiv.org/pdf/2312.13771) represent a different approach,
utilizing MLLMs as agents for UI screen navigation, with MobileAgent
employing external detection modules for action generation and AppAgent
leveraging overlaid UI element IDs and screen XML files for predefined
actions. CogAgent [hong2023cogagent](http://arxiv.org/pdf/2402.11941v2), built upon CogVLM
[wang2023cogvlm](http://arxiv.org/pdf/2210.00066v1), shifts the focus towards using only
screen images for complex UI navigation, eliminating the need for
UI-specific modules. Here are some more examples among other works that
utilize LLMs
[kim2023language](https://arxiv.org/pdf/2303.17491), [zheng2024synapse](https://arxiv.org/pdf/2306.07863), [deng2024mind2web](http://arxiv.org/pdf/2306.06070v3), [gur2023real](http://arxiv.org/pdf/2307.12856v4)
and MLLMs
[shaw2024pixels](http://arxiv.org/pdf/2306.00245v2), [zhan2023you](http://arxiv.org/pdf/2401.05851v1), [yan2023gpt](http://arxiv.org/pdf/2311.07562v1), [gao2023assistgui](http://arxiv.org/pdf/2401.10935v2), [zheng2024gpt](http://arxiv.org/pdf/2401.01614v2), [cheng2024seeclick](https://arxiv.org/pdf/2401.10935), [baechler2024screenai](http://arxiv.org/pdf/2402.04615v2)
in the space.
In this work, we focus on fine-grained mobile UI understanding with
MLLMs. Naturally, our work also aligns with the recent burgeoning
literature focused on empowering MLLMs for referring and grounding
tasks [zhang2023gpt4roi](http://arxiv.org/pdf/2309.12109v1), [chen2023shikra](http://arxiv.org/pdf/2306.15195v2), [peng2023kosmos](http://arxiv.org/pdf/2305.16103v1), [lai2023lisa](http://arxiv.org/pdf/2404.08767v1), [zhao2023bubogpt](http://arxiv.org/pdf/2405.17104v2), [you2023ferret](https://arxiv.org/pdf/2310.07704), [zhang2023llava](http://arxiv.org/pdf/2312.02949v1).
Overview of Ferret-UI-anyres architecture. While
Ferret-UI-base closely follows Ferret’s architecture, Ferret-UI-anyres
incorporates additional fine-grained image features. Particularly, a
pre-trained image encoder and projection layer produce image features
for the entire screen. For each sub-image obtained based on the original
image aspect ratio, additional image features are generated. For text
with regional references, a visual sampler generates a corresponding
regional continuous feature. The LLM uses the full-image representation,
sub-image representations, regional features, and text embeddings to
generate a response.
# Method
Ferret-UI is built upon Ferret [you2023ferret](https://arxiv.org/pdf/2310.07704), which is
a MLLM that excells in spatial referring and grounding within natural
images of diverse shapes and levels of detail. It can interpret and
interact with regions or objects, whether they are specified as points,
boxes, or any free-form shapes. Ferret contains a pre-trained visual
encoder (*e.g.*, CLIP-ViT-L/14) [radford2021learning](http://arxiv.org/pdf/2404.19696v1) and
a decoder-only language model (*e.g.*,
Vicuna [zheng2023judging](https://arxiv.org/pdf/2306.05685)). Furthermore, Ferret
incorporates a unique hybrid representation technique that transforms
specified regions into a format suitable for processing by the LLM. At
its core, a spatial-aware visual sampler is designed to adeptly manage
continuous features of region shapes in different sparsity levels.
To instill UI expert knowledge into Ferret, we make two extensions to
develop Ferret-UI: ($i$) the definition and construction of UI referring
and grounding tasks
(Section [sec:dataset]); and ($ii$) model
architecture adjustment to better deal with screen data. Specifically,
Ferret-UI includes a broad range of UI referring tasks (*e.g.*, OCR,
icon recognition, widget classification) and grounding tasks (*e.g.*,
find text/icon/widget, widget listing) for model training, building up a
strong UI understanding foundation for advanced UI interactions. Unlike
previous MLLMs that require external detection modules or screen view
files, Ferret-UI is self-sufficient, taking raw screen pixels as model
input. This approach not only facilitates advanced single-screen
interactions, but also paves the way for new applications, such as
improving accessibility. Initial explorations of the dataset result in
two modeling insights: ($i$) UI screens are predominantly characterized
by aspect ratios that are more extended compared to those found in
natural images, as evidenced in
Tab. [tab:screen_num_distribution];
($ii$) the tasks involve many objects of interest (*i.e.*, UI widgets
like icons and texts) that are significantly smaller than the objects
typically observed in natural images. For example, many questions focus
on icons that occupy less than 0.1% of the entire screen. Thus, relying
solely on a single directly resized, low-resolution global image could
lead to significant loss of visual details.
To address this problem, we apply the idea of “any resolution” (anyres),
as advocated in SPHINX [lin2023sphinx](https://arxiv.org/pdf/2311.07575), [gao2024sphinxx](https://arxiv.org/pdf/2402.05935),
LLaVA-NeXT [liu2024llavanext](https://llava-vl.github.io/blog/2024-01-30-llava-next/), and
Monkey [li2023monkey](http://arxiv.org/pdf/2103.15488v1), to Ferret-UI. Specifically, we opt
for two grid configurations, 1x2 and 2x1, which are chosen based on the
aspect ratios of the original screens as depicted in
Tab. [tab:screen_num_distribution].
Given a screen, the grid configuration that most closely matches its
original aspect ratio is selected. Subsequently, the screen is resized
to fit the selected grid configuration and is then partitioned into
sub-images. Intuitively, portrait screens are divided horizontally,
whereas landscape screens are divided vertically. All sub-images are
encoded separately using the same image encoder, and the LLM uses all
visual features of varying granularity with both the full image context
as well as the enhanced details. The overall architecture of Ferret-UI,
including the any-resolution adjustments, is illustrated in
Fig. 1.
# Dataset and Task Formulation [sec:dataset]
In this section, we detail the process of generating datasets for model
training and evaluation. Specifically, we describe the UI detection data
collection process in
Section 1.1, and we outline how we create
task-specific data from raw detections in
Section 1.2.
## UI Data Collection [sec: ui_data]
**UI Screens.** To build a model capable of perceiving and interacting
with mobile screens, it is crucial to gather a varied collection of such
screens. This study examines screens from both iPhone and Android
devices.
For Android screens, we use a subset of the RICO dataset
[deka2017rico](http://arxiv.org/pdf/1607.07515v3). Specifically, we consider the tasks in
Spotlight [li2023spotlight](https://arxiv.org/pdf/2209.14927), whose data is publicly
available, including *screen2words*, *widgetcaptions*, and
*taperception*. We aggregate unique images for each split (train and
test) among the tasks to form our own data splits. In total, there are
26,527 train images and 3,080 test images.
For iPhone screens, we use the AMP dataset
[zhang2021screenrecognition](https://arxiv.org/pdf/2101.04893), which spans a broad
spectrum of applications. A subset is randomly selected and divided into
training and test splits. The iPhone screens come in various sizes,
resulting in a total of 84,685 training images and 9,410 test images.
The breakdown of image sizes is summarized in Tab.
[tab:screen_num_distribution].
**UI Screen Elements Annotation.** After collecting Android and iPhone
screens, we further collect fine-grained element annotation from screens
using a pre-trained pixel-based UI detection
model [zhang2021screenrecognition](https://arxiv.org/pdf/2101.04893). For each detected UI
element, the output includes a UI type (Button, Text, Icon, Picture,
*etc.*), the corresponding bounding box, and the text displayed on it,
if any, identified by the Apple Vision Framework[^1]. We further use
heuristics from Screen
Recognition [zhang2021screenrecognition](https://arxiv.org/pdf/2101.04893) to group
individual detections into larger units, *e.g.*, multiple lines of text
are merged into one group, an image is grouped with its caption, *etc*.
## Task Formulation [sec: task_formulation]
This section describes how we convert the UI screens along with the
associated detection data to a format that can be used to train an MLLM.
We elaborate three different approaches devised for the construction of
the dataset.
Elementary task data generation overview. A
UI detector outputs all detected elements, with each element’s
type, text, and bounding boxes. These
detections are used to create training samples for elementary tasks. For
grounding tasks, we use all element detections to create one
sample for widget listing whereas the remaining tasks focus on one
element at a time. We separate the elements into icons,
text, and non-icon/text widgets. For each type, we
create one referring and one grounding sample.
**Reformatting Spotlight.** We first take *screen2words*,
*widgetcaptions*, and *taperception* from the existing Spotlight
tasks [li2023spotlight](https://arxiv.org/pdf/2209.14927), and format them into
conversational QA pairs. Specifically, GPT-3.5 Turbo is used to create a
varied set of prompts from base prompts we author for respective tasks:
- **Screen2words***: Provide a summary of this screenshot*;
- **Widget Captions***: For the interactive element \[bbox\], provide
a phrase that best describes its functionality*;
- **Taperception***: Predict whether the UI element \[bbox\] is
tappable*.
For each training example, we sample a prompt for the corresponding task
and pair it with the original source image and ground-truth answer.
**Elementary Tasks.** In addition to the Spotlight tasks, we use paired
screens and UI elements mentioned in Section
1.1 to generate data for novel UI
tasks that rely on grounding and referring capabilities. We introduce 7
tasks using this approach, one set for each of Android and iPhone
screens: *OCR*, *icon recognition*, and *widget classification* for
*referring*; and *widget listing*, *find text*, *find icon*, and *find
widget* for *grounding*. We define *referring tasks* as the ones with
bounding boxes in the inputs, while *grounding tasks* are the ones with
bounding boxes in the outputs.
For each task, we also use GPT-3.5 Turbo to expand a base prompt to
introduce variants of the task question. Details for data generation are
illustrated in Fig.
1. The number of
training samples for each task is summarized in Tab.
[tab:task_data_num_distribution].
The number of test samples for all tasks are 5K. In experiments, we
sample from this pool of training data with different ratios to
construct our training data mixture.
Advanced task data generation overview. We
first normalize bounding box coordinates from the detection outputs,
then we send the detections, prompts, and optional one-shot example to
GPT-4. For detailed description and function inference, we pair the
generated response with a pre-selection of prompts to train Ferret-UI.
For conversation tasks, we directly transform GPT-4 output to multi-turn
conversations.
**Advanced Tasks.** To incorporate reasoning abilities into our model,
we follow LLaVA [liu2023llava](https://arxiv.org/pdf/2304.08485), and additionally collect
data of 4 more formats using GPT-4. We focus on iPhone screens for this
part of the data collection, filtering our examples to those with more
than 2 but fewer than 15 detections. These examples are sent together
with prompts to GPT-4 to create data of the desired format—the actual
images are not used. Fig.
2 illustrates the
training data generation process for advanced tasks.
The four tasks are *detailed description*, *conversation perception*,
*conversation interaction*, and *function inference*. Among these, we
expand base prompts for detailed description and function inference to
pair them with the GPT-4 response as the input data in our model
training. For conversations, we provide an in-context example for GPT-4
to better follow bounding box formats in its output. From the raw GPT-4
output, we parse the bounding boxes and transform them into the correct
multi-turn conversation format for our model. In total, we have created
40K valid conversations from GPT-4 generated data. More details about
our data collection pipeline and detailed analysis of our collected data
are provided in the Appendix.
While our training data collection primarily targets iPhone screens, we
assemble test sets for both iPhone and Android platforms. For each task,
we select 25 test screens from iPhone and 5 from Android. Due to
overlaps in images across different tasks, the total number of unique
images amounts to 56 for iPhone and 13 for Android. For evaluation, we
randomly select 2 QA pairs for the conversational tasks, creating two
distinct test instances with precisely one question in each input.
Utilizing these test images, we formulate 20/40/38/20 questions for
iPhone and 5/10/10/10 questions for Android, for the four tasks,
respectively.
[^1]: https://developer.apple.com/documentation/vision
# Experiments
We first present our main results in
Section 1.1, followed by ablation studies
in Section 1.2. Then, detailed analysis
of results on elementary and advanced UI tasks is provided in
Section 1.3 and
1.4, respectively.
**Setup.** In this section, Ferret-UI-anyres refers to the version with
any-resolution integrated, Ferret-UI-base refers to the version directly
following the Ferret architecture, and Ferret-UI refers to both
configurations. During training, both the decoder and the projection
layer are updated while the vision encoder is kept frozen. All the
training data is formatted into the instruction-following format, and
the training objective is the same as in Ferret. In total, our training
mixture has 250K samples. Ferret-UI-base takes 1 day to train while
Ferret-UI-anyres takes about 3 days on 8 A100 GPUs.
## Results [sec:main_results]
We compare the performances of Ferret-UI-base, Ferret-UI-anyres,
Ferret[^1], and GPT-4V for all tasks. We also include
Fuyu [fuyu-8b](https://www.adept.ai/blog/fuyu-8b) and
CogAgent’s [hong2023cogagent](http://arxiv.org/pdf/2402.11941v2) performance on advanced
tasks.[^2] Results are summarized in Tab.
[tab:main_results], where the
average performance within a category is reported. Performance breakdown
for elementary and advanced tasks is shown in Fig.
1 and Tab.
1, respectively.
Elementary task performance comparison. Numerous small
widgets present on the Android screen make it more challenging for
referring and grounding, while Ferret-UI continues to outperform Ferret
and GPT-4V on almost all the elementary tasks.
**Public Benchmark from Spotlight [li2023spotlight](https://arxiv.org/pdf/2209.14927).**
Compared to Spotlight, Ferret-UI demonstrates superior performance in
*S2W* and *WiC*, even though Spotlight uses 80M web page screenshots and
2.69M mobile screenshots for pre-training. Ferret-UI performance falls
short on *TaP* but is still competitive; our studies further suggest
that this could be due to the noisiness of the taperception labels.
Detailed analysis is provided in the Appendix.
**Results on Elementary UI Tasks.** The average performance of all
referring and grounding tasks is summarized in Tab.
[tab:main_results], and the
performance breakdown for each task is shown in Fig.
1. For referring tasks, we
report exact match accuracy for OCR and accuracy for icon recognition
and widget classification. For each grounding task, we also report the
accuracy, where a correct bounding box is one that has an
Intersection-over-Union (IoU) with the label greater than the threshold
(0.5). Widget listing performance is not included in the average as we
treat it as an auxiliary task.
Ferret-UI outperforms Ferret and GPT-4V in most elementary tasks except
for iPhone *find text*. While GPT-4V demonstrates decent performance on
iPhone tasks, its performances on Android tasks, especially grounding
tasks, are significantly worse. Examining the predictions shows that
Android screens have more numerous and smaller widgets, making the
grounding tasks more challenging. Furthermore, Ferret-UI’s zero-shot
performance on the Referring Expression Comprehension task from
UIBert [bai2021uibert](https://arxiv.org/pdf/2107.13731) is 76% when we frame it as the
*find widget* task. Notably, with anyres added to Ferret-UI-base, iPhone
referring and grounding tasks improve by 2 points.
**Results on Advanced Tasks.** The breakdown of task performance for
advanced tasks is shown in Tab.
1. As the advanced tasks
require open-ended responses, we use GPT-4 to score both the label and
the prediction. We report *score for prediction* over *score for label*
as a percentage.
Ferret-UI exhibits commendable performance on advanced tasks for both
platforms, despite the absence of Android-specific data in its training
dataset. This suggests a notable transferability of UI knowledge across
different operating systems. While Fuyu [fuyu-8b](https://www.adept.ai/blog/fuyu-8b) tends
to generate answers that are generally relevant, its responses lack the
detail and precision exhibited by Ferret-UI. Conversely, GPT-4V secures
higher scores across all tasks by consistently delivering more detailed
responses than Ferret-UI, a characteristic that aligns with the
preferences of the model evaluator (GPT-4). With Ferret-UI-anyres,
iPhone advanced tasks see a huge performance boost of 20 points while
Android advanced tasks see a performance drop. As Android advanced task
data is not included in the training mix, it could be that as the model
gains enriched knowledge about iPhone screen understanding, it loses a
bit of generalizability.
## Ablation Studies [sec:ablation_studies]
**Ablation on Advanced Tasks.** The design motivation behind elementary
tasks is to enhance the model’s visual and spatial understanding of
basic UI elements. We propose that this enhanced understanding can aid
in performing more complex tasks. This hypothesis is examined by
investigating how elementary tasks influence the model’s ability to
handle advanced tasks, with findings detailed in Tab.
[advanced_task_ablation]. We
see that with only advanced task data, the performance is 64% for both
platforms. The performance of advanced tasks on iPhone shows a
consistent improvement of 5% with the addition of either iPhone or
Android elementary tasks. Similarly, adding elementary tasks from the
iPhone enhances Android’s performance on advanced tasks by about 4%,
whereas incorporating Android elementary tasks boosts this performance
by 9%. Including both iPhone and Android elementary tasks further
improves performance by 3% and 5% for iPhone and Android advanced tasks,
respectively, beyond the improvements seen with a single set of
elementary tasks. These observations support our hypothesis that
elementary tasks provide the model with enhanced visual and spatial
understanding that facilitates advanced tasks.
0.45
| | **iPhone** | **Android** |
|:---|:--:|:--:|
| Adv. task only | 64.6 | 64.3 |
| \+ iPhone elem. | 70.3 | 68.6 |
| \+ Android elem. | 70.2 | 75.3 |
| \+ both as in [tab:main_results] | **73.4** | **80.5** |
Ablation studies on the factors that impact performance on (a) Advanced
tasks and (b) Spotlight tasks.
0.45
| | S2W | WiC | TaP |
|:---|:--:|:--:|:--:|
| Spotlight [li2023spotlight](https://arxiv.org/pdf/2209.14927) | 106.7 | 141.8 | **88.4** |
| Balanced TaP labels | 111.7 | 133.8 | 76.5 |
| Spotlight tasks only | 111.3 | 138.7 | 77.6 |
| \+ Android elem. tasks | 111.3 | 138.0 | 76.8 |
| \+ iPhone elem. tasks | 112.4 | 138.9 | 74.8 |
| \+ both | 111.3 | 138.7 | 76.0 |
| Full mixture from [tab:main_results] | **113.4** | **142.0** | 78.4 |
Ablation studies on the factors that impact performance on (a) Advanced
tasks and (b) Spotlight tasks.
**Ablation on Spotlight Tasks.** Motivated by a desire to explore the
impact of different data configurations on Spotlight task performance,
we specifically investigate whether adding elementary task data could
enhance the model performance, given that these tasks are designed to
improve the visual and spatial comprehension of screens. As shown in
Tab. [tab:spotlight_tasks_ablation],
the addition of elementary task data—whether exclusively from Android,
iPhone, or a combination of both—does not significantly alter
performance across the three Spotlight tasks. This may be attributed to
the short and highly specialized UI-centric vocabulary used in responses
in elementary tasks, contrasting with the response style demanded by
Spotlight tasks. Optimal results for Spotlight tasks were observed when
data from advanced tasks were integrated alongside all elementary tasks,
even though the advanced task data was exclusively derived from iPhone
screens. Notably, this yields a 4-point boost in CIDEr score for the
widget captions with the inclusion of advanced task data. We postulate
that the free-response format of advanced task answers, which
necessitates a more sophisticated set of skills for execution, aligns
more closely with the requirements of Spotlight tasks. These tasks
demand a comprehensive understanding beyond that of recognizing
individual UI elements, as is common in elementary tasks. Moreover,
executing advanced tasks requires more sophisticated skills than
understanding one specific UI element on the screen as in elementary
tasks. Thus, it stands to reason that the skill set honed through
advanced tasks would be advantageous for tackling Spotlight tasks, which
occupy a middle ground in complexity between elementary and advanced
tasks. In one word, the structure of the task assumes greater importance
than the source platform of the data incorporated.
OCR Analysis.Left: predict nearby
text instead of a targeted region in the base model, corrected in
anyres. Middle: a tendency to predict valid words.
Right: Ferret-UI correctly reads cut-off text, while the
detection model produces wrong labels.
## Result Analysis: Elementary UI Tasks [sec:analysis_1]
**Referring Tasks.** In analyzing Ferret-UI’s referring capabilities, we
specifically focus on OCR and widget classification predictions. The OCR
analysis reveals three notable observations, as depicted in Fig.
2. First, the model predicts a
neighboring text instead of the text in the targeted region. This is
common for smaller texts and texts very close to other texts.
Remarkably, with anyres integrated, such cases are alleviated,
indicating that inputting enlarged sub-images helps the model with
smaller visual details. Second, the model exhibits a tendency to predict
actual words rather than merely deciphering characters displayed on the
screen. This observation is in line with the semantic-reliance
observation of LLMs made in some existing
work [liu2024LMMOCR](https://arxiv.org/pdf/2305.07895). On UI screens, phonetically crafted
words that are commonly used as brand titles largely fall under this
category. Third, Ferret-UI demonstrates the ability to accurately
predict text that is partially cut-off, even in instances where the OCR
model returns incorrect texts.
Widget Classification Analysis.Left: a large Button consists of a Picture, Icon, and Text
misclassified as a Picture. Middle: a button seated on top of a
row of Tabs misclassified as a Tab. Right: a small,
text-surrounded icon being classified as text in the base model, but
correctly classified with anyres.
Similar to OCR analysis, we show three interesting observations in Fig.
3. First, the
model struggles when it needs to understand relationships among widgets.
For example, if a large button is made up of a few sub-elements,
including Picture, Icon, and text, the model cannot see it as a unified
widget but tends to predict it as the sub-element that occupies the
largest space. In line with the first observation, when a Tab or an Icon
is seated on top of a row of tabs, it is highly likely to be considered
part of the tabs. Finally, we discover a common case where small icons
surrounded by texts are likely to be predicted as Text, and this is
consistent with the observation that small texts tend to be predicted as
neighboring texts. With anyres added, such cases are more likely to be
predicted correctly, in line with the observation made in OCR.
**Grounding Tasks.** Using *find text* predictions, as depicted in Fig.
4, we further elucidate
observations from grounding tasks. Echoing the initial observation from
the *OCR* analysis, the model may erroneously highlight a piece of text
adjacent to the targeted area. Additionally, the occurrence of multiple
instances of identical texts suggests the potential for expanding future
methods to encompass a range of answers from a singular box to multiple
boxes, thereby enhancing the model’s utility and accuracy in complex
text-finding scenarios.
Find Text Analysis.Left: a
neighboring text is mis-identified as the target. Middle:
multiple occurrences of the same text. Right: predicted boxes
not precise.Visualization results of advanced tasks (top to bottom:
function inference, conversation interaction,
conversation perception) to illustrate the differences among
various models (Fuyu vs. CogAgent vs. GPT-4V vs.
Ferret-UI).
## Result Analysis: Advanced UI Tasks [sec:analysis_2]
**Grounded Conversation.** Engaging in grounded conversation is Ferret’s
unique capability. To better understand the quality of the output
bounding boxes in terms of correctness and relevance, we manually grade
all output boxes in both Ferret-UI and GPT-4V’s *converation
interaction* outputs. The accuracies for Ferret-UI and GPT-4V are 91.7%
and 93.4%, respectively. Considering Ferret-UI generates raw coordinates
whereas GPT-4V chooses from a set of pre-defined boxes, Ferret-UI’s
grounding ability on UI screens is noteworthy. Even though Ferret-UI’s
received evaluation score falls short of GPT-4V, from inspecting the
predictions as in Fig.
5, we notice that GPT-4V
tends to provide extra information that may not be relevant to the
question. However, these detailed answers are more favored in scoring
than Ferret-UI’s concise answers.
**UI detection model is a bottleneck.** Given that both our elementary
and advanced tasks are predicated upon the detection of UI elements,
Ferret-UI is not able to learn aspects of screens that are not detected,
such as colors, design, usability, and UI elements that the detection
model misses (*e.g.*, topmost time, WIFI, battery). For example, in
generating detailed descriptions, GPT-4V is capable of noting “The
overall design conforms to Apple’s aesthetic with a minimalistic, clean,
dark theme”, a level of insight Ferret-UI is not trained to offer due to
its reliance on detected elements alone.
**Set-of-Mark (SoM) Prompting of GPT-4V.** In our analysis of GPT-4V,
the Set-of-Mark (SoM) prompting approach [yang2023set](http://arxiv.org/pdf/2310.11441v2) is
employed, revealing several limitations. First, its effectiveness
diminishes in scenarios involving a multitude of small UI elements, a
common occurrence in Android detection tasks. The small size of some UI
components means that the addition of labels may obscure original
content or even extend beyond the intended areas. Second, limiting the
assessment to a specified collection of candidate regions restricts the
model’s ability to reference any given region freely. In the middle
example shown in Fig.
5, the UI detection model
treats the entire middle section as one element, covering the texts,
image, and the Buy button. Therefore, the model is not able to refer to
the “BUY” button on its own in its responses, since it is considered
part of a collective detection group.
[^1]: For Ferret, we include the pre-defined classes for icon
classification and widget classification in the prompts while the
remaining prompts are the same as Ferret-UI.
[^2]: For GPT-4V, we sample a random subset of 100 instances for the
Spotlight and elementary tasks for cost efficiency. For GPT-4V
evaluation, we follow [yang2023set](http://arxiv.org/pdf/2310.11441v2) by overlaying
indexed bounding boxes of UI elements as visual prompts.
Consequently, in grounding tasks, GPT-4V is enabled to make
selections from among these candidate boxes. We detail the effort in
the Appendix.
# Conclusion
In this paper, we introduce Ferret-UI, a specialized MLLM designed to
enhance comprehension and interaction with mobile UI screens. Through
careful design of “anyres” to accommodate various screen aspect ratios
and curation of training samples that encompass a diverse range of basic
and advanced UI tasks, Ferret-UI demonstrates remarkable proficiency in
referring, grounding, and reasoning. The advent of these enhanced
capabilities promises substantial advancements for a multitude of
downstream UI applications, thereby amplifying the potential benefits
afforded by Ferret-UI in this domain.
# Elementary Task Data Generation Details [datagen_details]
Additional details in elementary task data generation are as follows:
- In our data generation process, we merge the two distinct
classes—“Checked” and “Unchecked”—found in the original detection
labels for both *Checkboxes* and *Toggles*.
- For widget listing, the answer starts with a common phrase: *UI
widgets present in this screen include*. Each element is formatted
as “{displayed text} {UI type}” (*e.g.*, “login button”), except for
text elements, which are formatted as “Text displaying {displayed
text}”.
- For OCR, we consider text with fewer than 10 tokens. If the text is
exactly one token, the length needs be to 2 or greater to be
included.
- For tasks such as *find text*, *find icons*, and *find widget*, it
is common to encounter screens containing multiple instances of the
same UI element (e.g., multiple login buttons). We employ a
filtering mechanism that excludes samples involving UI elements with
multiple occurrences within a single screen.
- The size of the test set is determined by selecting the smaller
value between 5k and the total number of generated test instances.
# Advanced Task Data Quality Analysis [appendix:conv_analyses]
We conduct a thorough analysis of the quality of our collected data for
advanced tasks and provide comprehensive statistics. The vocabulary size
for each task is as follows: 30,866 for *detailed description*, 15,666
for *conversation perception*, 12,092 for *conversation interaction*,
and 14,896 for *function inference*.
In the realm of *conversation interaction*, we observe 33,649 question
turns and 29,933 answer turns. Among these, 15 question turns include
bounding boxes, whereas all answer turns include bounding boxes. We
compile the most frequently occurring tri-grams for questions and
answers in both conversation tasks. Notably, in *conversation
perception* questions, the top tri-grams include phrases like *are there
any”*, *where is the”*, and *what is the”*, while those for interactions
comprise phrases like *How can I”*, *I want to”*, and *Can I do”*.
Similarly, in perception answers, prominent tri-grams consist of
expressions such as *“bottom of the”*, *“at the top”*, and *“there is
a”*, while interaction answers primarily feature tri-grams like *“by
tapping on”*, *“tapping on the”*, and *“can tap on”*.
We present detailed distributions of tri-grams in conversation data
questions and answers in Fig.
5. This observation is
consistent with our intended objectives for each conversation category,
with perception focusing on visual elements and interaction emphasizing
actions. Notably, from the interaction conversation answers, we observe
that *tap* emerges as the predominant action. In future work, we aim to
explore interactions involving other actions, such as scrolling,
long-clicking, and entering text. The inclusion of two conversation
categories aims to diversify conversation topics, although a clear-cut
distinction between the two is not always feasible, and overlap between
the categories may occur.
Conversation perceptionquestions
trigrams distribution.Conversation perceptionanswers
trigrams distribution.Conversation interactionquestions
trigrams distribution.Conversation interactionanswers
trigrams distribution.Trigrams for collected conversation data questions and
answers.
# Taperception Label Analysis [appendix:taperception_analysis]
We meticulously label 30 test samples for *taperception* and conduct a
study on the correlation among our labels, *taperception* ground-truth
labels, Ferret-UI outputs, and GPT-4V outputs. Among the 30 samples, 5
pose challenges in deciphering without direct interaction with the
screen.
In Tab. 8, we present the percentage
of agreement among different sources of predictions and labels. The term
“filtered” denotes the set of 25 instances that are unambiguous, while
“unfiltered” encompasses the entire 30 instances. Our labels exhibit a
high correlation with GPT-4V predictions, but differing significantly
from the *taperception* dataset labels. This discrepancy underscores the
complexity of predicting *tappability* solely based on single images,
highlighting the inherent challenges in obtaining clear-cut labels for
this task.
Filtered.Unfiltered.Agreement between different sources of taperception
predictions and labels. In unfiltered, we make the best educational
guess for the one that are ambiguous. We observe that our human
annotation correlate with GPT-4V (%76) far more than with taperception
label (%8). Even though Ferret-UI’ performance on taperception falls
behind compared to Spotlight, it could be due to the noisiness of
labels.
# Advanced Task Generation Prompts [appendix:gpt4v_prompts]
We present the prompts to collect advanced task data from GPT-4 in Fig.
9.
Prompts for GPT-4 in advanced task data
generation.GPT-4V input image examples. Left: used in referring task,
where the question concerns one specific UI element. Right: used in
grounding task, where GPT-4V refers to the UI elements by their assigned
numeric labels.
# GPT-4V Evaluation Details [gpt4v_eval]
We detail the process of creating input for GPT-4V to tackle the UI
tasks under scope.
#### \[Input Images\]
We first annotate the screenshots tailored to each specific task,
ensuring that GPT-4V has sufficient contextual information to answer the
questions. For tasks without any bounding boxes in input or output
(*screen2words*, *widget captions*, and *Advanced Tasks*), we use the
original images as the input. For tasks that refer to **one** specific
UI element using bounding box in the input, we put a magenta-colored
bounding box on the image as the input, as shown in Fig.
10 left. For tasks that expect one
or more bounding boxes in the output, our initial explorations confirm
that GPT-4V is not able to provide bounding boxes in the output as it
gives the answer, *"Unfortunately, I’m not able to provide the exact
bounding box coordinates, as my capabilities are currently limited to
describing images and discussing the content rather than interacting
directly with the image to extract detailed metadata such as pixel
coordinates.")* and proceed to answer the question in natural language.
Therefore, for those tasks, we create an easier version where we ask
GPT-4V to choose from a fixed set of candidates. Particularly, we follow
Set-of-Mark prompting [yang2023set](http://arxiv.org/pdf/2310.11441v2) where for each UI
detection from our UI detection model, we use a magenta-colored bounding
box to mark it in the screen and inside each box we assign a numeric
label so that GPT4-V can refer to it. An example input image is shown in
Fig. 10 right.
#### \[Prompts\]
With the input images ready, we further modify the prompts to provide
GPT-4V with all the necessary information to perform all the tasks
successfully. For taperception, we instruct it to answer *“Yes.”* or
*“No.”* only without any explanations. For widget captions, we instruct
it to *“Answer in a few words.”* For *icon recognition* and *widget
classification*, we provide the list of all possible classes, and
instruct it to output the class only without any explanations. For
*OCR*, we instruct it to output the identified text only. For *find
widget*, *find text*, *find icons*, we add to the prompt *“Candidate
choices are indicated using magenta bounding boxes in the image and each
box is associated with a numeric label. Output the numeric label as your
answer, no need to explain."*
# More Example Outputs
VL-Mamba: Exploring State Space Models for Multimodal Learning
2024-03-20
Yanyuan Qiao, Zheng Yu, Longteng Guo, Sihan Chen, Zijia Zhao, Mingzhen Sun, Qi Wu, Jing Liu
Multimodal large language models (MLLMs) have attracted widespread interest and have rich applications. However, the inherent attention mechanism in its Transformer structure requires quadratic complexity and results in expensive computational overhead. Therefore, in this work, we propose VL-Mamba, a multimodal large language model based on state space models, which have been shown to have great potential for long-sequence modeling with fast inference and linear scaling in sequence length. Specifically, we first replace the transformer-based backbone language model such as LLama or Vicuna with the pre-trained Mamba language model. Then, we empirically explore how to effectively apply the 2D vision selective scan mechanism for multimodal learning and the combinations of different vision encoders and variants of pretrained Mamba language models. The extensive experiments on diverse multimodal benchmarks with competitive performance show the effectiveness of our proposed VL-Mamba and demonstrate the great potential of applying state space models for multimodal learning tasks.
Show Paper Content
# Introduction [sec:intro]
Multimodal large language models (MLLM) have received widespread
attention from the research community in recent years. It inherits the
advanced capabilities of Large Language Models (LLMs) such as powerful
language expression and logical reasoning. The integration of visual and
textual information not only enhances the understanding of visual
content but also provides a more comprehensive context for language
understanding and generation. MLLM has shown great potential in solving
visual problems in the real world and has rich applications in the
fields of vision and language, such as image
captioning `\cite{Karpathy2014DeepVA,Vinyals2014ShowAT}`{=latex},
referring expression comprehension
(REC) `\cite{yu2018mattnet,qiao2020referring}`{=latex}, visual question
answering (VQA) `\cite{Agrawal2015VQAVQ,Schwenk2022AOKVQAAB}`{=latex},
etc. Leveraging Transformer-based
architectures `\cite{Vaswani2017AttentionIA}`{=latex} and large amounts
of training data from web sources, MLLM has become a fundamental
component in artificial intelligence research.
Although Transformers improve the ability of long-range dependencies and
greatly enhance the performance of the model, this architecture is
usually very computationally intensive. This is due to the inherent
computational and memory complexity of the self-attention mechanism used
by Transformer. The computational burden and memory requirements
increase quadratically with the sequence length.
To solve the bottleneck of long sequence modeling, the state space model
(SSM) has been widely studied `\cite{LSSL, s5}`{=latex}. It can be seen
as a blend of recurrent neural networks (RNNs) and convolutional neural
networks (CNNs). Among these studies, the representative works are
structured state space (S4) `\cite{s4}`{=latex} and its
variants `\cite{s5, gupta2022diagonal-dss, S4D}`{=latex}. The latest
work Mamba `\cite{gu2023mamba}`{=latex} further improves S4, with a
selection mechanism that allows the model to select relevant information
in an input-dependent manner, combined with a hardware-aware
implementation to achieve efficient training and inference. Mamba
outperforms Transformer on large-scale data and enjoys linear scaling in
sequence length, which has proven to be a promising alternative to
Transformer for language modeling. Some concurrent works extended this
architecture from 1D language to 2D vision
domain `\cite{Ma2024UMambaEL,Liu2024VMambaVS,Yang2024VivimAV}`{=latex}
such as image classification, biomedical image segmentation, To the best
of our knowledge, no work has explored how to utilize this efficient
architecture to solve multimodal tasks.
Inspired by the successes of SSM, in the paper, we introduce VL-Mamba,
the first work that utilizes state space models for multimodal learning
tasks. To be specific, as illustrated in
Fig. [fig:vl-mamba], we leverage the
pre-trained Mamba language model as our backbone language model instead
of conventional Transformer-based language models such as
LLama `\cite{Touvron2023LLaMAOA}`{=latex} or
Vicuna `\cite{vicuna2023}`{=latex}. Furthermore, we empirically explore
the way to apply 2D vision selective scan mechanisms for VL-Mamba and
introduce a novel MultiModal Connector (MMC) architecture, comprising a
Vision Selective Scan (VSS) module and two linear layers, tailored to
enrich the 2D-causal modeling of visual sequences. For the VSS module,
we explore two distinct scan mechanisms: the Bidirectional-Scan
Mechanism (BSM) and the Cross-Scan Mechanism (CSM). The BSM conducts
scans of visual sequences in both forward and backward directions, while
the CSM extends scanning capability to four directions. In addition, we
study the combinations of different vision encoders, variants of
pretrained Mambe language models, and multimodal connectors to find the
effect of different components for VL-Mamba. Extensive experiments are
conducted on various multimodal learning benchmarks to verify the
effectiveness of VL-Mamba. Our model achieves competitive performance
with other small MLLMs of similar size and even outperforms large MLLMs
(e.g., 7B and 13B versions of
LLaVA-1.5 `\cite{liu2023improvedllava}`{=latex}) on some popular
benchmarks.
In summary, our contributions are as follows:
- We propose VL-Mamba, which is the first work to explore and exploit
the state space model in solving multimodal learning tasks, which
provides a novel framework option for multimodal large language
models other than transformer-based architectures.
- We empirically explore the effect of different components for
VL-Mamba and introduce a novel MultiModal Connector containing a
Vision Selective Scan (VSS) module to improve the representational
capabilities.
- We conduct extensive experiments on diverse multimodal learning
benchmarks. The experiments demonstrate that VL-Mamba achieves
competitive performance compared to existing multimodal large
language models.
- We make the code open source to promote the research of applying
state space models for multimodal learning.
# Related Work [sec:related work]
## State Space Models (SSMs)
Modern state space models (SSMs) are derived from the classical state
space model `\cite{kalman1960new}`{=latex} and have become an efficient
building block for constructing deep networks, thereby achieving
cutting-edge performance in analyzing continuous long-sequence data.
They particularly excel at capturing long-range dependencies (LRDs) and
leveraging parallel training methods to increase efficiency. Initiated
by a HiPPO matrix `\cite{gu2020hippo}`{=latex}, Linear State Space Layer
(LSSL) `\cite{LSSL}`{=latex} combines the advantages of continuous-time
models (CTMs), RNNs, and CNNs, which demonstrates the potential of deep
SSMs to solve long-range dependencies. However, the practical
feasibility of LSSL is hampered by the large computational and memory
requirements imposed by the state representation. Subsequently, the
Structured State Space (S4) `\cite{s4}`{=latex} addresses the main
computational bottleneck in prior research. This is achieved through
novel parameterizations catering to continuous-time, recurrent, and
convolutional views of the state space model, thereby effectively
modeling long-range dependencies. S4 has subsequently seen some
variants `\cite{s5, gupta2022diagonal-dss, S4D}`{=latex}, such as the
Diagonal State Space (DSS) model `\cite{gupta2022diagonal-dss}`{=latex},
which forces the state matrix to be a diagonal matrix, making it easier
to formulate, implement, and analyze, and can be proven to be as
expressive as a general state space, while S4D `\cite{S4D}`{=latex}
provides a new mathematical analysis for DSS initialization, making it
simpler and more efficient.
A recent work, named Mamba `\cite{gu2023mamba}`{=latex}, further
improves S4 with a selection mechanism that incorporates time-varying
parameters into SSM, allowing the model to select relevant information
in an input-dependent manner. It proposes a hardware-aware algorithm to
achieve efficient training and inference. Mamba’s superior scaling
performance shows that it is a promising alternative to the Transformer
in long-sequence modeling. Many works extend Mamba from Natural Language
Processing (NLP) to other
fields `\cite{Yang2024VivimAV, Xing2024SegMambaLS,ruan2024vm}`{=latex}.
Vision Mamba (Vim) `\cite{Zhu2024VisionME}`{=latex} applies Mamba to the
Vision Transfomer (ViT) architecture, and combines bidirectional SSM for
data-dependent global visual context modeling and position embedding for
location-aware visual understanding. Visual State Space Model
(VMamba) `\cite{Liu2024VMambaVS}`{=latex} designs a cross-scan mechanism
to bridge the gap between 1-D array scanning and 2-D plain traversing.
U-Mamba `\cite{Ma2024UMambaEL}`{=latex} proposes a hybrid CNN-SSM
architecture to capture both localized fine-grained features and
long-range dependencies in images, to solve the biomedical image
segmentation task. In this work, we explore how to transfer the success
of Mamba to solve the more challenging multimodal learning tasks, which
often require modeling of both vision and language modalities and
complex reasoning.
## Multimodal Large Language Model (MLLM)
With the development of the powerful Large Language Models
(LLMs) `\cite{Touvron2023LLaMAOA,Zhang2022OPTOP,Chowdhery2022PaLMSL}`{=latex},
many
studies `\cite{achiam2023gpt4,Driess2023PaLMEAE,chen2023minigptv2,Qwen-VL,ye2023mplug,Chu2023MobileVLMA}`{=latex}
extend LLMs to multimodal domains by combining visual input with LLM to
build the multimodal large language model (MLLM).
Flamingo `\cite{alayrac2022flamingo}`{=latex} freezes pre-trained visual
encoders and large language models and fuses visual and language
modalities with gated cross-attention, demonstrating excellent few-shot
learning performance. BLIP `\cite{Li2022BLIPBL}`{=latex} uses a dataset
bootstrapped from large-scale noisy image-text pairs to pre-train a
multi-modal mixture of encoder-decoder models by injecting different
synthetic captions and removing noisy captions. Based on this,
BLIP-2 `\cite{Li2023BLIP2BL}`{=latex} uses Querying Transformer
(Q-Former) to bridge the modal gap.
InstructBLIP `\cite{instructblip}`{=latex} further proposes an
instruction-aware visual feature extraction mechanism that can flexibly
and effectively extract visual information features according to the
given instructions.
LLaVA `\cite{liu2023improvedllava, liu2023llava}`{=latex} leverages
advanced LLMs (LLaMA `\cite{Touvron2023LLaMAOA}`{=latex} and
Vicuna `\cite{vicuna2023}`{=latex}) as the language model and
CLIP `\cite{Radford2021LearningTV}`{=latex} as the visual encoder, it
transforms visual tokens into language tokens with a simple MLP layer.
MiniGPT-4 `\cite{zhu2023minigpt}`{=latex} directly aligns visual
information with the language model to accomplish diverse
vision-language tasks without using external vision models. Usually, the
training of MLLMs contains two stages, of which the first stage is to
pretrain the model on a large collection of image-text pairs to acquire
the alignment of vision-language knowledge, and the second stage is to
finetune the model with a smaller but high-quality multimodal
instruction tuning dataset with a designed conversational template.
These MLLM works have greatly advanced research in the fields of
computer vision and natural language processing. However, since the main
framework of these models relies on Transformers, the attention
mechanism in Transformers inherently has high computational complexity
in inference for long sequences. To alleviate the abovementioned issues
related to modeling long-range sequences in the area of multi-modal
learning, we propose the VL-Mamba, which is based on the state space
model. To be specific, we utilize pretrained
Mamba `\cite{gu2023mamba}`{=latex} language model as our backbone
language model, rather than Transformer-based LLMs such as
LLama `\cite{Touvron2023LLaMAOA}`{=latex} or
Vicuna `\cite{vicuna2023}`{=latex}. Moreover, we empirically explore the
effective application of 2D selective scan mechanism in the multimodal
VL-Mamba and the combination of different vision encoders and variants
of Mamba language models.
# Method [sec:method]
In this section, we first introduce the preliminary concepts of state
space models (Sec. 1.1). Then, we describe the details of
our proposed VL-Mamba (Sec.
1.2), which mainly includes the Vision
Encoder, MultiModal Connector, and the Mamba LLM.
## Preliminaries [subsec:pre]
State space models (SSMs) are commonly considered linear time-invariant
systems that map stimulation $x(t) \in \mathbb{R}^L$ to response
$y(t) \in \mathbb{R}^M$ through a hidden state $h(t) \in \mathbb{R}^N$.
Mathematically, these models are typically formulated as linear ordinary
differential equations (ODEs), where the parameters include
$\mathbf{A} \in \mathbb{C}^{N \times N}$,
$\mathbf{B} \in \mathbb{C}^{N}$ for a state size $N$, and the skip
connection $\mathbf{D} \in \mathbb{C}^1$. The system dynamics and output
equations are given by:
$$\begin{aligned}
\label{eq:lti}
h'(t) &= \mathbf{A}h(t) + \mathbf{B}x(t), \\
y(t) &= \mathbf{C}h(t) + \mathbf{D}h(t).
\end{aligned}$$
Subsequently, the process of discretization is commonly employed to
incorporate Eq. [eq:lti] practical deep learning algorithms.
In this context, $\mathbf{\Delta}$ represents the timescale parameter
that is used to convert the continuous parameters
$\mathbf{A}, \mathbf{B}$ into discrete parameters,
$\mathbf{\bar{A}}, \mathbf{\bar{B}}$. The zero-order hold (ZOH) method
is commonly utilized for this discretization, and it is described as
follows: $$\begin{aligned}
\label{eq:zoh}
\mathbf{\overline{A}} &= \exp{(\mathbf{\Delta}\mathbf{A})}, \\
\mathbf{\overline{B}} &= (\mathbf{\Delta} \mathbf{A})^{-1}(\exp{(\mathbf{\Delta} \mathbf{A})} - \mathbf{I}) \cdot \mathbf{\Delta} \mathbf{B}.
\end{aligned}$$
Once discretized, Eq. [eq:zoh] can be reformulated with the step
size $\Delta$ as: $$\begin{aligned}
\label{eq:discrete_lti}
h_t &= \mathbf{\overline{A}}h_{k-1} + \mathbf{\overline{B}}x_{k}, \\
y_t &= \mathbf{C}h_k + \mathbf{D}x_k.
\end{aligned}$$
Nevertheless, the formulation in
[eq:discrete_lti] is predicated on
a Linear Time Invariance (LTI) system where parameters are invariant
despite changes in the input. To address this constraint, the recent
work Mamba `\cite{gu2023mamba}`{=latex} explored integrating a selective
scan technique, in which the matrices $\mathbf{\overline{B}}$,
$\mathbf{C}$, and $\mathbf{\Delta}$ are derived from the input data.
This change equipped Mamba with the ability to dynamically focus on
information from the input sequence, which increased the model’s
capability.
## VL-Mamba Model [subsec:model]
### Overall Architecture [subsubsec:all]
The architecture of VL-Mamba consists of a pretrained vision encoder, a
randomly initialized MultiModal Connector (MMC) which incorporates the
2D vision selective scan mechanism, and a pretrained Mamba Large
Language Model (Mamba LLM), as illustrated in
Fig. 1. Taking an image as input, we first
obtain visual features through the visual encoder, then feed the visual
sequences into MMC, and then this output vector combined with a
tokenized text query is fed into Mamba LLM to generate the corresponding
response.
### Vision Encoder
The vision encoder of VL-Mamba uses the Vision Transformer
(ViT) `\cite{vit}`{=latex} architecture that generates a sequence of
patch features from raw images. The vision encoder ${f_V}$, takes an
image $I$ as input and produces a sequence of the visual patch features
$V_{img}$, as follows:
$$\begin{aligned}
\label{eq:vit}
V_{img} = {f_V}(I).
\end{aligned}$$
### MultiModal Connector (MMC)
Since the state space models are designed to process 1D sequential data
such as language sequences that have causal relationships, but the
visual sequences generated by the vision encoder are non-causal data, 2D
vision selective scan mechanisms are proposed to solve computer vision
tasks. In this work, we try to apply the 2D vision selective scan
mechanisms for multimodal learning by ensembling them in the multimodal
connector of VL-Mamba. Specifically, we explore three variants of
multimodal connectors:
- **MLP**: a two-layer Multi-Layer Perceptron (MLP), which is depicted
in Fig. 2(a).
- **VSS-MLP**: a Vision Selective Scan (VSS) module combined with an
MLP. The architecture is shown in
Fig. 2(b).
- **VSS-L2**: a VSS module combined with two linear layers, which is
depicted in Fig. 2(c).
The VSS module aims to bridge the gap between the 1D sequential
processing capabilities inherent in the SSM and the 2D non-causal visual
information. Specifically, the VSS module consists of a 2D vision scan
mechanism and one mamba layer. In this work, we utilize two 2D scan
mechanisms: Bidirectional-Scan Mechanism and Cross-Scan Mechanism, as
follows:
- **Bidirectional-Scan Mechanism (BSM)** scans the image patch
features in both forward and backward directions, which aims to
capture a broader context without increasing computational
complexity, as illustrated in the top of
Fig. 3.
- **Cross-Scan Mechanism (CSM)** unfolds image patch features into
sequences along rows and columns and scans them in four directions
(diagonally across the image), as shown in the bottom of
Fig. 3.
After the scan process, these sequences are passed through the mamba
layer and reshaped back into the original image patch order, and all
such features are merged to form a comprehensive representation.
As shown in Fig. 2(b), the input of the multimodal connector
is the sequential image patch features $V_{img}$ extracted from the
input images via the transformer-based vision encoder. These feature
vectors are then passed through a Vision Selective Scan (VSS) module to
obtain the visual scanned feature $V_{scan}$. After the VSS module, the
output vectors $V_{scan}$ are combined with the original image patch
features $V_{img}$ through a skip connection. The combined vector is
then passed into a norm layer and a two-layer Mult-Layer (MLP):
$$\begin{aligned}
\label{eq:mmc}
V_{scan} &= \mathbf{VSS}(V_{img}), \\
V_{out} &= \mathbf{MLP}(\mathbf{Norm}(V_{scan} + V_{img})).
\end{aligned}$$
And for the variant MMC in
Fig. 2(c), the feed-forward pass progress can be
formulated as follows:
$$\begin{aligned}
\label{eq:mmc}
V_{img}^{'} &= \mathbf{Linear}(V_{img}), \\
V_{scan} &= \mathbf{VSS}(\mathbf{GELU}(V_{img}^{'})), \\
V_{out} &= \mathbf{Linear}(\mathbf{Norm}(V_{scan} + V_{img}^{'})).
\end{aligned}$$
### Mamba LLM
We use the pre-trained Mamba Large Language Model (Mamba
LLM) `\cite{gu2023mamba}`{=latex} ${f_{L}}$ as our language model. Given
a natural language query $Q$, we utilize the tokenizer and embedding
module $f_T$ to map the text input into the embedding space. Then the
visual vector $V_{out}$ and textual $T$ are concatenated and put into
the MambaLLM to obtain the response $R$.
$$\begin{aligned}
\label{eq:llm}
R = {f_{L}}(V_{out}, f_T(Q)).
\end{aligned}$$
# Experiment [sec:expri]
In this section, we first introduce our experimental setup including
implementation details and MLLM benchmarks in
Sec. 1.1. Then we present the quantitative
comparison and qualitative results in
Sec. 1.2 and
Sec. 1.3. Finally, we conduct ablation
studies in Sec. 1.4.
## Experimental Setup [subsec:setup]
### Implementation details
Following `\cite{liu2023llava,liu2023improvedllava}`{=latex}, the
training process contains two stages: vision-and-language alignment
pre-training and multimodal instruction tuning. During the pretraining
stage, we freeze the vision encoder and Mamba LLM and only keep the
multimodal connector updated. Then we finetune both the multimodal
connector and the Mamba LLM in the instruction tuning stage. Our model
is trained on 8 NVIDIA Tesla A800 GPUs.
### MLLM Benchmarks
We evaluate our model on a diverse set of 8 benchmarks:
VQA-v2 `\cite{goyal2017vqav2}`{=latex},
GQA `\cite{hudson2019gqa}`{=latex},
ScienceQA-IMG `\cite{lu2022learn}`{=latex},
TextVQA `\cite{singh2019textvqa}`{=latex},
POPE `\cite{li2023pope}`{=latex}, MME `\cite{fu2023mme}`{=latex},
MMBench `\cite{Liu2023MMBenchIY}`{=latex},
MM-Vet `\cite{yu2023mmvet}`{=latex}.
VQA-v2 `\cite{goyal2017vqav2}`{=latex} evaluates models’ ability to
understand and reason about images and questions.
GQA `\cite{hudson2019gqa}`{=latex} assesses spatial understanding and
multi-step inference in real-world images.
ScienceQA `\cite{lu2022learn}`{=latex} offers multimodal multiple-choice
questions on scientific topics, requiring common sense reasoning. The
questions in TextVQA `\cite{singh2019textvqa}`{=latex} are related to
the text in an image, it evaluates the model’s optical character
recognition (OCR) and inference capabilities.
POPE `\cite{li2023pope}`{=latex} provides a benchmark for evaluating
object hallucinations, which is a binary classification task that
prompts the model to answer whether an object exists.
MME `\cite{fu2023mme}`{=latex} evaluates perceptual and cognitive
abilities, including OCR, object recognition, common sense reasoning,
numerical calculations, text translation, and code reasoning.
MMBench `\cite{Liu2023MMBenchIY}`{=latex} features 3,000 single-choice
questions across 20 dimensions, using a CircularEval strategy for robust
evaluation, with ChatGPT matching model predictions to choices.
MM-Vet `\cite{yu2023mmvet}`{=latex} identifies 16 emergent tasks from
core visual and linguistic (VL) capabilities, including Recognition,
Knowledge, OCR, Spatial awareness, Language generation, and Math.
## Quantitative Evaluation [subsec:sota]
As is shown in Table [tab:results], we compare our proposed
model VL-Mamba with some SoTA multimodal large language models. Compared
with the MobileVLM-3B `\cite{Chu2023MobileVLMA}`{=latex} model with
similar scale parameters and the same amount of multimodal training
data, our model surpasses the performance on SQA$^\text{I}$ (65.4 v.s.
61.2), VQA$^\text{T}$ (48.9 v.s. 47.5), and MME (1369.6 v.s. 1288.9),
though the Mamba LLM uses much less pretrained tokens (627B) than the
backbone MobileLLaMA (1.3T) of MobileVLM. Compared with the
LLaVA-Phi `\cite{zhu2024llavaphi}`{=latex} model with a SoTA language
model Phi-2-2.7B with 1.4T pretrained tokens, our performance shows
superior on VQA-v2 (76.6 v.s. 71.4), MME (1369 v.s. 1335.1), and MM-Vet
(32.6 v.s. 28.9). It is worth noting that though our proposed model has
fewer parameters and limited training data, it also achieves comparable
performance compared with some models with a larger number of
parameters. Its performance on the POPE benchmark is similar to
LLaVA-1.5 `\cite{liu2023improvedllava}`{=latex}, where the LLM
parameters are 13B, which is approximately 4.6 times larger than the
Mamba LLM. These promising results demonstrate the effectiveness of our
proposed VL-Mamba and show the potential of utilizing the state space
models in multimodal learning tasks.
## Qualitative Result [subsec:vis]
We present some examples to see the qualitative results of the VL-Mamba.
As shown in Fig. 1, the VL-Mamba could well understand the
user’s question and respond accurately.
## Ablation Study [subsec:abla]
### The Effect of Variants of Language Model
Table [tab:lang] shows the ablation experiment
of evaluating the effectiveness of different variants of the language
model. We conduct experiments on three different variants, Mamba-1.4B
which has 1.4B parameters and is trained on
Pile `\cite{gao2020pile}`{=latex} with 300B tokens, Mamba-2.8B-Pile with
2.8B parameters and trained on Pile 300B tokens and Mamba-2.8B-Slimpj
trained on SlimPajama with 627B tokens. Specifically, we construct the
baseline models by using the same variant CLIP-ViT as the vision
encoder, Mamba language models as backbone large language models, and
vanilla MLP MultiModal Connectors without 2D vision selective scan
modules. We can see with the increase of model scale and training
tokens, Mamba-2.8B-Slimpj outperforms the other two variants on all
benchmarks. Thus, we choose Mamba-2.8B-Slimpj for other experiments.
### The Effect of Different Vision Encoders
To evaluate the effectiveness of different vision encoders, we conduct
an ablation study which is shown in
Table [tab:visenc]. We study two different
vision encoders, CLIP-ViT-L `\cite{Radford2021LearningTV}`{=latex} and
SigLIP-SO `\cite{Zhai2023SigmoidLF}`{=latex}. The baseline models
utilize Mamba-2.8B-Slimpj as LLM and vanilla MLP multimodal connectors.
We can see that the CLIP-based model falls behind the SigLIP-based model
in most benchmarks except the MME benchmark, where the CLIP-based model
surpasses the SigLIP-based model by a large margin. Considering the
comprehensive performance, we choose SigLIP-SO as the vision encoder to
build the final VL-Mamba.
### Ablation on Different MMC Architectures
We also explore the impact of different architectures of Multimodal
Connector (MMC). We evaluate three different MMC variants: MLP, VSS-MLP,
and VSS-L2. As shown in
Table [tab:arch-mmc], by comparing the three
architectures, we observe that VSS-L2 shows relatively better
performance on most benchmarks, especially on the VQA$^\text{T}$, MME,
MMB, and MM-Vet. The scores are 48.9, 1369.6, and 32.6 respectively,
which proves the effectiveness of the VSS module combined with linear
layers. Note that these models utilize SigLIP-SO as the vision encoder,
Mamba-2.8B-Slimpj as the language model and Bi-directional selective
scan mechanism.
### Ablation on Different Scan Mechanisms
We compare two scan mechanisms Bidirectional-Scan Mechanism (BSM) and
Cross-Scan Mechanism (CSM) in the MMC module. As shown in
Table [tab:scan], although BSM and CSM perform
similarly in some benchmarks, such as they all score 76.6 in the
VQA$^\text{v2}$, BSM exhibits superior performance in most benchmarks.
Especially on the MMB benchmark, BSM scored 1369.6, 5.6 points higher
than CSM, highlighting its strength in processing 2D vision information
for multimodal learning tasks.
# Limitation
In this paper, we are focusing on effectively applying the 2D selective
scan for multi-modal connector in the VL-Mamba, without exploring the
training data that would significantly affect the benchmark performance.
In the future, we will study how to utilize higher-quality training data
to further improve the performance of VL-Mamba.
# Conclusion
In this paper, we introduce VL-Mamba, the first work that explores the
state space model Mamba to solve multimodal learning tasks. The VL-Mamba
consists of a language model, a vision encoder, and a multimodal
connector. To be specific, we utilize the pre-trained Mamba Large
Language Model (Mamba LLM) as the language model. Then, we study three
architectures of MultiModal Connector (MMC) and introduce a Vision
Selective Scan (VSS) module in MMC to bridge the gap between 2D
non-causal image information and the inherent causal modeling
capabilities of state space models (SSMs). In the VSS module, we propose
two 2D scan mechanisms: the Bidirectional Scanning Mechanism (BSM) and
Cross Scanning Mechanism (CSM). We conduct extensive experiments on
eight multimodal benchmarks and achieve comparable performance with some
SoTA MLLMs, and we also conduct ablation studies to evaluate the
effectiveness of language variants, different vision encoders, different
MMC architectures, and different scan mechanisms. The results
demonstrate the effectiveness of our proposed model and prove the
potential of the SSMs applied to multimodal learning.
mPLUG-DocOwl 1.5: Unified Structure Learning for OCR-free Document Understanding
2024-03-19
Anwen Hu, Haiyang Xu, Jiabo Ye, Ming Yan, Liang Zhang, Bo Zhang, Chen Li, Ji Zhang, Qin Jin, Fei Huang, Jingren Zhou
Structure information is critical for understanding the semantics of text-rich images, such as documents, tables, and charts. Existing Multimodal Large Language Models (MLLMs) for Visual Document Understanding are equipped with text recognition ability but lack general structure understanding abilities for text-rich document images. In this work, we emphasize the importance of structure information in Visual Document Understanding and propose the Unified Structure Learning to boost the performance of MLLMs. Our Unified Structure Learning comprises structure-aware parsing tasks and multi-grained text localization tasks across 5 domains: document, webpage, table, chart, and natural image. To better encode structure information, we design a simple and effective vision-to-text module H-Reducer, which can not only maintain the layout information but also reduce the length of visual features by merging horizontal adjacent patches through convolution, enabling the LLM to understand high-resolution images more efficiently. Furthermore, by constructing structure-aware text sequences and multi-grained pairs of texts and bounding boxes for publicly available text-rich images, we build a comprehensive training set DocStruct4M to support structure learning. Finally, we construct a small but high-quality reasoning tuning dataset DocReason25K to trigger the detailed explanation ability in the document domain. Our model DocOwl 1.5 achieves state-of-the-art performance on 10 visual document understanding benchmarks, improving the SOTA performance of MLLMs with a 7B LLM by more than 10 points in 5/10 benchmarks. Our codes, models, and datasets are publicly available at https://github.com/X-PLUG/mPLUG-DocOwl/tree/main/DocOwl1.5.
Show Paper Content
Compared with similar-size generalists, our DocOwl
1.5 achieves state-of-the-art OCR-free performance on 10 Visual Document
Understanding benchmarks.
[^1]: Corresponding authors
# Introduction
Leveraging the strong language understanding and generation ability of
Large Language Models
(LLM) [gpt3](http://arxiv.org/pdf/2112.07522v2), [llama](http://arxiv.org/pdf/2402.08075v1), [vicuna](https://github.com/lm-sys/FastChat), [llm_survey](http://arxiv.org/pdf/2310.12321v1), some recent
works [mplugowl](http://arxiv.org/pdf/2405.00390v2), [mplug-owl2](None), [llava](http://arxiv.org/pdf/2402.11690v1), [llava1.5](http://arxiv.org/pdf/2310.19145v1), [minigpt4](http://arxiv.org/pdf/2402.17510v1), [blip2](None)
have developed Multimodal Large Language Models (MLLMs) for general
vision-and-language understanding. By aligning a pre-trained visual
encoder (e.g. the ViT/L-14 [vit2021](http://arxiv.org/pdf/2105.15075v2) from
CLIP [clip](http://arxiv.org/pdf/2404.19696v1)) and the LLM with a Vision-to-Text (V2T)
module, these models present promising performance on understanding
general images. However, they still face great challenges with images
with rich text information, such as documents, webpages, tables, and
charts [llmocr](http://arxiv.org/pdf/2305.07895v5). This is mainly because the visual
encoder and V2T module are trained on general image-text pairs and not
specifically optimized to represent the textual and structural
information in text-rich images.
Textual information in images manifests with a multitude of visual
structures, spanning the simplicity of plain text to the systematic grid
layouts of tables and incorporating a spectrum of graphical
representations such as pie, line, and bar charts. These elements may
appear in isolation or be intricately interwoven within the framework of
documents and webpages, reflecting a rich diversity of informational
architecture across posters, invoices, infographics, scientific reports,
academic and news websites, etc. As shown in
[fig:intro], besides the basic textual
content, structure information also plays a big role in Visual Document
Understanding [layoutlmv2](http://arxiv.org/pdf/2310.16527v1), [layoutlmv3](None), [udop](http://arxiv.org/pdf/2212.02623v3), [pix2struct](None).
With basic abilities to understand general images and comprehend
structured texts through the LLM decoder, MLLM has the potential to
achieve unified structure learning on text-rich images. For better
Visual Document Understanding with MLLMs, some
works [docowl](None), [ureader](None), [qwenvl](http://arxiv.org/pdf/2308.12966v3), [docpedia](http://arxiv.org/pdf/2311.11810v3) attempt to design
text-reading tasks to strengthen the text recognition ability, but
either ignore the structure comprehension or only cover limited domains
of text-rich images, such as just webpages [pix2struct](None)
or documents [docpedia](http://arxiv.org/pdf/2311.11810v3). In this work, we first propose
to perform unified structure learning on text-rich images for MLLMs
across 5 domains: document, webpage, table, chart, and natural image.
For better structural understanding, we first design a simple and
effective vision-to-text module, namely . Unlike the
Resampler [Alayrac2022FlamingoAV](http://arxiv.org/pdf/2205.07065v1) or
Q-former [blip2](None) which fuses visual features with
learnable queries but affects spatial information, the accumulates
neighborhood visual features through convolution to keep the relative
positional relationships. Compared with V2T modules with only linear
layers [llava](http://arxiv.org/pdf/2402.11690v1), [llava1.5](http://arxiv.org/pdf/2310.19145v1), it produces much fewer visual
features, which is more efficient for LLM to understand high-resolution
document images. Considering texts in document images are most organized
from left to right, merges visual features at the horizontal level. Our
Unified Structure Learning comprises structure-aware parsing tasks and
multi-grained text localization tasks. To learn the organization of text
contents, the former mainly teaches the model to parse the texts in the
image in a structure-aware style, such as using line feeds and spaces to
represent the structure of documents or webpages, and using extended
Markdown syntax to represent the structure of tables and charts.
Multi-grained text localization tasks further enhance the ability to
correlate visually situated texts and concrete positions in the image.
To support unified structure learning, based on publicly available
datasets, we carefully build a comprehensive training set by
constructing structure-aware sequences and multi-grained pairs of text
and bounding boxes. The is trained in a two-stage framework, starting
with the Unified Structure Learning and then followed by the Multi-task
Tuning among downstream tasks. Finally, to trigger the reasoning ability
of MLLM in Visual Document Understanding, we construct a high-quality
instruction tuning dataset . By performing joint training on and
downstream datasets, -Chat well balance giving a simple answer or
detailed explanations.
Our contributions in this work are four-fold:
- We first propose Unified Structure Learning on text-rich images for
MLLMs and design both structure-aware parsing tasks and
multi-grained text localization tasks across 5 domains. A
comprehensive dataset is carefully built to support Unified
Structure Learning.
- We design a simple and effective vision-to-text module for structure
learning and perform extensive experiments to validate its
effectiveness.
- We construct a high-quality instruction tuning set to trigger the
reasoning ability of MLLMs on Visual Document Understanding.
- and -Chat achieves state-of-the-art OCR-free performance on 10
Visual Document Understanding tasks, achieving improvement of more
than 10 points on 5/10 tasks among similar-sized models.
# Related Work
(VDU), also known as Visually-situated Language
Understanding [pix2struct](None), [ureader](None), aims to comprehend
images with rich text information. Such images range from
documents [docvqa](None), [infovqa](http://arxiv.org/pdf/2104.12756v2), [deepform](http://arxiv.org/pdf/2303.13839v1), [klc](None), [mpmqa](None),
tables [wikitableqa](http://arxiv.org/pdf/2009.13845v2), [TabFact](http://arxiv.org/pdf/2311.06592v1), [pubtabnet](http://arxiv.org/pdf/2402.04297v1),
charts [chartqa](None), [dvqa](None), [plotqa](http://arxiv.org/pdf/1906.04124v2), [chart2text](None), [vistext](None), [paperowl](http://arxiv.org/pdf/2311.18248v2),
natural images [textcaps](None), [textvqa](None), [qctextcap](http://arxiv.org/pdf/2302.02124v2) to webpage
screenshots [visualmrc](http://arxiv.org/pdf/2101.11272v2), [websrc](http://arxiv.org/pdf/2004.14797v1), where diverse
composition of text and visual objects contains a wealth of information.
To evaluate the multimodal document understanding performance, the task
formats include low-level recognition, e.g. information
extraction [deepform](http://arxiv.org/pdf/2303.13839v1), [klc](None), and high-level semantic
understanding, such as visual question
answering [docvqa](None), [infovqa](http://arxiv.org/pdf/2104.12756v2), [wikitableqa](http://arxiv.org/pdf/2009.13845v2), [chartqa](None), [visualmrc](http://arxiv.org/pdf/2101.11272v2), [textvqa](None),
image captioning [textcaps](None), [chart2text](None), [vistext](None), and
natural language inference [TabFact](http://arxiv.org/pdf/2311.06592v1). According to
whether relying on an off-the-shelf OCR system to recognize texts in the
image, models for Visual Document Understanding can be categorized into
OCR-dependent models [udop](http://arxiv.org/pdf/2212.02623v3), [layoutlmv2](http://arxiv.org/pdf/2310.16527v1), [layoutlmv3](None), [tap](None)
and OCR-free ones [donut](http://arxiv.org/pdf/2305.09520v1), [pix2struct](None). To leverage
recognized texts from an OCR system, OCR-dependent models are always
trained to align textual and visual inputs. For example,
UDOP [udop](http://arxiv.org/pdf/2212.02623v3) is pre-trained to recover masked text and
layout information given image and retained text as inputs. As for
OCR-free methods, training with tasks about text recognition is
indispensable. Dount [donut](http://arxiv.org/pdf/2305.09520v1) design the text reading
task to output continuous text sequences that ignore structure
information. To leverage structure information,
Pix2Struct [pix2struct](None) designs a Screenshot Parsing
Task to generate the HTML DOM tree for webpage screenshots but is hard
to apply to other types of images. In this work, we first propose
Unified Structure Learning for all image types and carefully build a
comprehensive dataset to support layout learning.
(MLLM) have shown strong vision understanding and open-ended
conversation
abilities [mplugowl](http://arxiv.org/pdf/2405.00390v2), [mplug-owl2](None), [minigpt4](http://arxiv.org/pdf/2402.17510v1), [instructblip](None), [qwenvl](http://arxiv.org/pdf/2308.12966v3), [cogagent](None), [mmllm_survey](http://arxiv.org/pdf/2306.14895v1)
for natural images. They follow the architecture paradigm of connecting
a vision encoder,e.g. ViT [vit2021](http://arxiv.org/pdf/2105.15075v2), [clip](http://arxiv.org/pdf/2404.19696v1), with a Large
Language Model(LLM) [llama](http://arxiv.org/pdf/2402.08075v1), [vicuna](https://github.com/lm-sys/FastChat), [qwen](http://arxiv.org/pdf/2309.16609v1) by a
vision-to-text module, such as simple linear
layers [llava](http://arxiv.org/pdf/2402.11690v1), [llava1.5](http://arxiv.org/pdf/2310.19145v1) or a
Q-Former [blip2](None)/Resampler [Alayrac2022FlamingoAV](http://arxiv.org/pdf/2205.07065v1)/Abstractor [mplugowl](http://arxiv.org/pdf/2405.00390v2), [mplug-owl2](None)
with learnable queries. To enable MLLMs to comprehend images with rich
texts, there are major two challenges: how to encode high-resolution
images and how to understand visually-situated texts. To tackle
high-resolution images, most works choose to further
train [qwenvl](http://arxiv.org/pdf/2308.12966v3), [docpedia](http://arxiv.org/pdf/2311.11810v3) or extraly add a high-resolution
vision encoder [cogagent](None).
UReader [ureader](None) first proposes to keep the
low-resolution vision encoder and use a shape-adaptive cropping module
to crop raw images into multiple sub-images with low resolution. To
enhance the visually-situated text understanding, some work design tasks
of reading texts from top-left to bottom-right without taking into
account the importance of structure [ureader](None), [qwenvl](http://arxiv.org/pdf/2308.12966v3).
CogAgent [cogagent](None) and
DocPedia [docpedia](http://arxiv.org/pdf/2311.11810v3) further try strengthening the layout
understanding for documents, webpages, and natural images with text
grounding tasks. However, the comprehension of the overall structure is
ignored, and tables and charts are not covered. In this work, we follow
UReader to process high-resolution images. To strengthen structure
understanding, we design structure-aware praising and multi-grained text
localization tasks for all types of images, covering documents, tables,
charts, webpages, and natural images. We propose a vision-to-text
architecture to better maintain spatial information of visual features
by convolution. Finally, to support unified structure learning, we build
a comprehensive training dataset and greatly improve the visual
document understanding performance.
# DocOwl 1.5
follows the typical architecture of Multimodal Large Language Models,
which consists of a visual encoder, a vision-to-text module, and a large
language model as the decoder. To better keep the textual and layout
information in text-rich images of high resolution, we design an as the
vision-to-text module to ensemble horizontal visual features. As shown
in [fig:overall_arch](a), to enhance
the text recognition and structure understanding abilities, we first
perform Unified Structure Learning with structure-aware parsing and
multi-grained text localization tasks for all types of images. Then, the
model is jointly tuned on multiple downstream tasks of Visual Document
understanding.
## Model Architecture
**High-resolution Image Encoding.** As proved by previous
works [donut](http://arxiv.org/pdf/2305.09520v1), [pix2struct](None), [ureader](None), the ability to encode
high-resolution images is critical to ensuring that the decoder can use
rich text information from document images. As shown in
[fig:overall_arch](b), following
UReader [ureader](None) , we utilize a parameter-free
Shape-adaptive Cropping Module to crop a shape-variable high-resolution
image $I$ into multiple fixed-size sub-images $(I_1, I_2,...,I_C)$,
where $C$ is the number of crops. To keep the overall layout
information, the raw image is also resized to a low-resolution one as
the global image $I_0$. Then, each image $I_i$ in $(I_0,I_1,...,I_C)$ is
independently encoded to a sequence of visual features
$V_i = (v_i^1, v_i^2,...,v_i^L), 0 \leq i \leq C$ by a transformer-based
Visual Encoder, where $v_i^j, 1 \leq j \leq L$ is a $D$-dimension
vector, $L$ is the length of visual features for each image.
**Spatial-aware Vision-to-Text Module: .** There are two kinds of
popular vision-to-text modules for Multimodal Large Language Models: a
MLP [llava](http://arxiv.org/pdf/2402.11690v1), [llava1.5](http://arxiv.org/pdf/2310.19145v1), [minigpt4](http://arxiv.org/pdf/2402.17510v1) or a cross-attention
module with learnable
queries [mplugowl](http://arxiv.org/pdf/2405.00390v2), [qwenvl](http://arxiv.org/pdf/2308.12966v3), [Alayrac2022FlamingoAV](http://arxiv.org/pdf/2205.07065v1), [blip2](None).
Both two are not quite suitable for representing high-resolution
text-rich images. The former projects complete visual features into the
language embedding space. It maintains all spatial information in the
document image but keeps the sequence length of raw visual features,
which is too long when processing high-resolution images. For example,
encoding a 1,344x1,344 image with the ViT/L-14 results in 9,216 visual
tokens. The cross-attention module could greatly reduce the length of
the visual sequence to the number of learnable queries, but may lose
spatial information during semantic fusion.
In this work, we design a more appropriate vision-to-text module for
Visual Document Understanding, namely , which not only reduces visual
sequence length but also keeps the spatial information. As shown in
[fig:overall_arch](b), the is
comprised of a convolution layer to reduce sequence length and a
fully-connected layer to project visual features to language embedding
space. Since most textual information in document images is arranged
from left to right, the horizontal text information is usually
semantically coherent. Thus, the kernel size and stride size in the
convolution layer are set as 1x4 to ensemble horizontal 4 visual
features. The output channel is set equal to the input channel $D$. The
convolution calculation is as follows: $$\begin{gathered}
V_i = (v_i^1, v_i^2,...,v_i^L)\\
\overline{v}_i^j = f(v_i^{4j-3},v_i^{4j-2},v_i^{4j-1},v_i^{4j}), 1 \leq j \leq L/4, \\
\overline{V}_i = (\overline{v}_i^1, \overline{v}_i^2,...,\overline{v}_i^{L/4}),
\end{gathered}$$ where $f$ represents the dot product with kernel
weights on multiple channels. After the convolution layer, the visual
features of image $I_i$ are converted to the $\overline{V}_i$, the
feature length of which is $L/4$.
Then, with a fully connected layer to align visual features to the
language embedding space, the $\overline{V}_i$ are transferred to
$\hat{V}_i = (\hat{v}_i^1, \hat{v}_i^2,...,\hat{v}_i^{L/4})$.
**Multimodal Modeling with LLM.** As the decoder of MLLM, large language
models should understand both the visual features of images and the
textual features of language instructions. Following
mPLUG-Owl2 [mplug-owl2](None), we apply the Modality-adaptive
Module(MAM) in LLM to better distinguish visual and textual inputs.
During self-attention, MAM utilizes two sets of linear projection layers
to separately perform the key/value projection for visual features and
textual features. To help the LLM correlate multiple cropped sub-images,
UReader [ureader](None) designs learnable crop position
embeddings to denote the row and column position in the raw image. In
this work, we simply add special textual tokens `‘’` before
the visual features of each cropped image, where $x$ and $y$ refer to
the row and column index respectively. For the global image, the textual
indicator token is `‘’`. This design eliminates the need to
introduce additional parameters and is more friendly to the LLM decoder.
Our experiments validate that it achieves comparable effects as the crop
position embedding. Overall, the decoding of the LLM is as follows:
$$\begin{gathered}
Y = \rm{LLM}([T_0;\hat{V}_0, T_1;\hat{V}_1, ...,T_C; \hat{V}_C;X])
\end{gathered}$$ where $[;]$ means the concatenation operation, $C$ is
the crop number of the image, $T_j, 0 \leq j \leq C$ is the textual
embeddings of the special textual indicator for the global image or
positions of cropped images, $\hat{V}_j$ is the visual features of a
global or cropped image, $X$ is the textual embeddings of the
instruction, $Y$ is the predicted answer.
## Unified Structure Learning
Most Multimodal Large Language
Models [llava](http://arxiv.org/pdf/2402.11690v1), [mplug-owl2](None), [cogvlm](http://arxiv.org/pdf/2210.00066v1) are trained with
image-text pairs of natural images to align the visual encoder with the
LLM, such as Conceptual Captions [ConceptualCaption](None),
LAION [laion](None) and COYO [coyo](https://github.com/kakaobrain/coyo-dataset).
Initializing from such models could inherit the shallow text recognition
ability, but is far from understanding complex textual and structural
information in various text-rich images. In this work, to empower the
comprehensive document understanding abilities of MLLM, we design a
Unified Structure Learning across 5 domains, including natural images,
documents, tables, charts, and webpages. It involves both
structure-aware parsing tasks and multi-grained text localization tasks,
as shown in [fig:layout_tasks].
**Document Parsing.** For representing the structure information,
Pix2Struct [pix2struct](None) parses webpage screenshots with
condensed HTML DOM trees, which are built based on the HTML source codes
and are not available for other formats of documents or webpage
screenshots, e.g. PDF. In documents or webpages, horizontal and vertical
distances between texts form the main layout information. Therefore, to
make the structure-aware parsing task applicable to most documents and
webpage screenshots, we choose to add extra line
feeds(`‘\textbackslash n’`) and spaces into the text sequence to denote
different lines and horizontal distances. The greater the horizontal
distance, the more space characters.
We choose CCpdf [ccpdf](http://arxiv.org/pdf/2304.14953v2),
RVL-CDIP [rvlcdip](http://arxiv.org/pdf/1502.07058v1),
VisualMRC [visualmrc](http://arxiv.org/pdf/2101.11272v2) and datasets encapsulated in
DUE-Benchmark [due](None) (DocVQA [docvqa](None),
InfoVQA [infovqa](http://arxiv.org/pdf/2104.12756v2), DeepForm [deepform](http://arxiv.org/pdf/2303.13839v1),
KLC [klc](None), WTQ [wikitableqa](http://arxiv.org/pdf/2009.13845v2),
TabFact [TabFact](http://arxiv.org/pdf/2311.06592v1)) to support the Document Parsing task.
CCpdf [ccpdf](http://arxiv.org/pdf/2304.14953v2) is a multi-lingual PDF dataset built upon
webpages from Common Cramwl[^1], covering diverse domains of documents,
such as industry, academic, and medical. In this work, we mainly focus
on English Document Understanding and drop PDFs detected as other
languages. RVL-CDIP contains 16 categories of industry documents, such
as ‘letter’, ‘email’, and ‘scientific reports’. We further remove some
categories with flipping and blurring texts, such as ‘handwritten’ and
‘form’. DUE-Benchmark is a collection of available and reformulated
datasets over various document domains and layouts featuring tables,
graphs, lists, and infographics. VisualMRC is a webpage screenshot
dataset across 35 websites. OCR annotations in VisualMRC are aligned
with local regions, thus, we follow them to utilize crops of a
screenshot as input for this parsing task. For CCpdf and DUE-Benchmark,
a PDF-parsing tool pdfplumber[^2] can be directly used to generate
structure-aware text sequence with a PDF page as the input. For RVL-CDIP
and VisualMRC, there are no PDF files, just annotations of bounding
boxes of texts. As an alternative, akin to the
LATIN-Prompt [latin](None), we insert the line feeds and
spaces by calculating and comparing the horizontal and vertical
distances of bounding boxes. To avoid too many space characters
resulting in sparse texts, we further limit the maximum number of
consecutive spaces to 4. This strategy allows us to construct
structure-aware text sequences in the same style as pdfplumber.
**Table Parsing.** Different from documents or webpages, tables are
structured in a more standardized way, where row and column
correspondences represent key-value pairs. HTML and Markdown codes are
mainly two kinds of text sequences used to represent a table. HTML codes
can represent all kinds of tables, with or without cells spanning
multiple rows and grids, but they contain too many paired labels (e.g.
`‘
’` and `‘
’`), causing text sequences to be too long.
Markdown codes can represent a table with concise text sequence, but
they cannot represent cells spanning multiple rows and columns. To
represent all tables with concise text sequence, we follow the main
grammar of Markdown to represent table structure with `‘|’` and line
feeds(`‘\textbackslash n’`). To represent cells spanning multiple rows
and columns, we add special text tokens `‘’` and
`‘’` before the value, as shown in
[fig:layout_tasks].
We choose TURL [turl](None) and
PubTabNet [pubtabnet](http://arxiv.org/pdf/2402.04297v1) to do the structure-aware table
parsing task, where tables are collected from Wikipedia pages and
scientific articles, respectively. Without cells across rows and
columns, tables in TURL can be directly represented with Markdown codes.
Due to lacking table images in TURL, we transfer tables into HTML codes
and render table images with variations in background color and font
size. PubTabNet contains pairs of table images and HTML codes. We
convert HTML codes into Markdown style and add `‘’` or
`‘’` before the value when attributes `‘rowspan=x’` or
`‘colspan=y’` are set in the `‘
’` label.
**Chart Parsing.** Unlike documents and tables, organizing texts in
reading order cannot represent the structure of charts. Considering that
the chart is a visualization form of the table, parsing charts to tables
could best maintain the mathematical characteristics of the chart. This
requires the model to understand the structure of the chart and the
alignment of the x/y axis. Besides, to keep consistent with the Table
Parsing task, we also use Markdown codes to represent the data tables of
charts, as shown in
[fig:layout_tasks].
We adopt PlotQA [plotqa](http://arxiv.org/pdf/1906.04124v2),
FigureQA [figureqa](http://arxiv.org/pdf/2109.02226v1), DVQA [dvqa](None), and
ChartQA [chartqa](None) to support the structure-aware chart
parsing task. These datasets cover charts on both
synthetic [figureqa](http://arxiv.org/pdf/2109.02226v1), [dvqa](None) data and data from real-world
sources [plotqa](http://arxiv.org/pdf/1906.04124v2), [chartqa](None). Chart types include vertical
bar, horizontal bar, line, dot line, and pie chart. Source data of the
chart is provided in the JSON [plotqa](http://arxiv.org/pdf/1906.04124v2), [figureqa](http://arxiv.org/pdf/2109.02226v1), [plotqa](http://arxiv.org/pdf/1906.04124v2)
or CSV format [chartqa](None), both can be conveniently
converted to Markdown codes. However, some raw values are not suitable
as standard answers for parsing because there are too many significant
digits to be represented on the chart. Therefore, to reduce the
difficulty of estimating values and make the model focus more on
structural understanding, we keep 4 significant digits for all values.
**Natural Image Parsing.** Quite different from text-dominant images
mentioned above, the semantics of natural images is a combination of
natural objects and scene texts. Thus, parsing natural images is
necessary to organize scene texts and mention the main image content.
Manually annotating captions to describe the relationship between
objects and scene texts is labour- and financial-intensive. Like
TAP [tap](None), we concatenate the general caption with OCR
texts to form the target parsing sequence.
We utilize OCR-CC [tap](None) to support the Natural Image
Parsing task. OCR-CC is a subset of Conceptual
Caption [cc2018](None), which contains images with scene texts
detected by the Microsoft Azure OCR system.
**Multi-grained Text Localization.** As proved in previous
works [e2evlp](None), [ofa](None), [kosmos2](http://arxiv.org/pdf/2305.16103v1) on general image
understanding, semantic comprehension and object grounding tasks can be
well unified in a single model. For Visual Document Understanding,
structure-aware parsing tasks mainly focus on organizing texts according
to the overall structure, while neglecting the correspondence between
specific texts and local positions. Correlating texts with the concrete
position in images is another basic structure understanding ability for
visual documents. To support text position learning, we design two
symmetrical tasks, namely Multi-grained Text Grounding and Multi-grained
Text Recognition. The former aims to predict the bounding box given the
visually-situated texts, while the latter does the opposite. We set four
granularities of texts for these two tasks: word, phrase, line, and
block. The ‘word’ is the smallest granularity of the bounding box,
referring to only 1 word. To ensure that the word is visible and the
answer is unique, words that are too small (normalized area \< 0.001)
and words that appear multiple times in the same image are excluded from
candidates. The ‘line’ consists of texts that are judged to be
horizontally parallel by vertical distance, and the ‘phrase’ is
comprised of multiple adjacent words within the same line. The ‘block’
is a combination of multiple successive lines, ranging from 2 to half of
the total lines. The text sequences of word-level and phrase-level
question answering are much shorter than the other two. Therefore, in
order to learn localization more efficiently, each word-level or
phrase-level sample consists of up to 5 question-answer pairs for the
same image. As for the representation of bounding boxes, we transfer
each continuous value in the normalized bounding box into a discrete
position token, ranging from 0 to 999.
The bounding box annotation is necessary for constructing samples for
Multi-grained Text Localization tasks. Therefore, we take DocVQA,
InfoVQA, WTQ, TabFact, DeepForm, KLC, ChartQA, VisualMRC, and
TextVQA [textvqa](None) for this task, across domains of the
document, table, chart, webpage, and natural image.
Overall, to support the unified structure learning for text-rich images,
we build a dataset by ensembling multiple training sets of publicly
available datasets and constructing structure-aware text sequences or
text-position pairs as the targets. The form of instructions for each
task is very diverse for developing the general instruction-following
ability of the model.
[fig:data_distri] shows the
detailed statistics of .
## Multi-task Fine-tuning
Through Unified Structure Learning, models could well understand the
structure of diverse document images but cannot follow users’
instructions to do different types of tasks, such as information
extraction or image captioning. So, we further perform multi-task
fine-tuning to train a generalist of visual document understanding as
UReader [ureader](None).
## Training Paradigm
As shown in [fig:overall_arch](a), is trained
in a two-stage framework. Considering the LLM has strong comprehension
abilities for structured text [latin](None), [tablellama](http://arxiv.org/pdf/2311.09206v3), we
argue that the main limitation of MLLM in visual document understanding
is the representation ability of the Visual Encoder and Vision-to-Text
module for visually-situated text and structure information. Thus,
during the Unified Structure Learning, we freeze the LLM parameters and
tune the Visual Encoder and . The MAM is also optimized to help the LLM
better distinguish visual features and texts parsed from the image.
During the stage of Multi-task Fine-tuning, the model mainly learns how
to follow the user’s instructions to give answers based on
visually-situated text and structure understanding capabilities acquired
in the first stage. Therefore, the Visual Encoder is frozen and other
modules are tuned.
# -Chat
Existing benchmarks mainly evaluate the document understanding ability
by answering the question with simple phrases and neglect detailed
explanations. In this work, to better leverage the strong language
reasoning ability of Large Language Models on Visual Document
Understanding, we build a small instruction-tuning set with detailed
explanations on text-rich image understanding, namely . Based on raw
questions from DocVQA [docvqa](None),
InfoVQA [infovqa](http://arxiv.org/pdf/2104.12756v2), WTQ [wikitableqa](http://arxiv.org/pdf/2009.13845v2),
VisualMRC [visualmrc](http://arxiv.org/pdf/2101.11272v2), ChartQA [chartqa](None)
and TextVQA [textvqa](None), we collect detailed explanations
with ChatGPT[^3]. Text contents are dominant information on documents,
tables or webpage screenshots. Therefore, for DocVQA, InfoVQA, WTQ, and
VisualMRC, we take the structure-aware text sequence of the image as the
input to `gpt-3.5-turbo-0301` and prompt it to answer the question with
simple answers and detailed explanations. As for ChartQA and TextVQA, we
take the image as the input and utilize the `gpt-4-vision-preview` to
answer the question with detailed explanations. In order to filter out
samples where ChartGPT answers incorrectly, we further prompt
`gpt-3.5-turbo-0301` to judge whether the answer given by ChartGPT is
consistent with the concise human-annotated ground-truth answer.
Compared with raw questions in benchmark datasets, questions in are
added with a prompt `‘Answer the question with detailed explanation’`.
Detailed statistics of are presented in
[tab:instruct_set]. -Chat is
trained by combining downstream datasets with and performing multi-task
tuning after Unified Structure Learning.
[^1]:
[^2]:
[^3]:
# Experiments
## Implementation Details
is initialized from mPLUG-Owl2 [mplug-owl2](None), which
utilizes the ViT/L-14 [vit2021](http://arxiv.org/pdf/2105.15075v2) as the Visual Encoder
and a 7B Large Langauge Model with the Modality Adaptive Module as the
language decoder. According to the aspect ratio and resolution, each
image is cropped into up to 9 sub-images with a fixed resolution of
448x448. Each sub-image is encoded to 1,024 features by the ViT/L-14 and
then reduced to 256 features by the . The model is trained with 12,000
iterations on , with the learning rate and batch size set as 1e-4 and
1,024. It costs about 128 A100 days. During the Multi-task finetuning,
the model is trained for 6,500 iterations with the batch size set as 256
and the learning rate set as 2e-5. This further costs about 24 A100
days.
## Main Results
We evaluate the Visual Document Understanding performance on 10
text-rich image benchmarks, covering documents
(DocVQA [docvqa](None), InfoVQA [infovqa](http://arxiv.org/pdf/2104.12756v2),
DeepForm [deepform](http://arxiv.org/pdf/2303.13839v1), KLC [klc](None)), tables
(WTQ [wikitableqa](http://arxiv.org/pdf/2009.13845v2), TabFact [TabFact](http://arxiv.org/pdf/2311.06592v1)),
charts (ChartQA [chartqa](None)), natural images
(TextVQA [textvqa](None),
TextCaps [textcaps](None)), and webpage screenshots
(VisualMRC [visualmrc](http://arxiv.org/pdf/2101.11272v2)). We compare with
state-of-the-art OCR-free models, including both Multimodal Large
Language Models adapted for recognizing texts and much smaller models
trained only for document understanding. The detailed comparison of
model settings can be found in
[tab:model_setting]. As shown in
[tab:main], previous MLLMs with more than
7B parameters underperform domain-specific models with less than 1B
parameters, showing that the document understanding is still a
shortcoming for existing MLLMs. Our outperforms both domain-specific
models and MLLMs with similar sizes on all 10 benchmarks. This validates
that is much stronger on visual document understanding across 5
domains, covering visual question answering, information retrieval,
natural language inference, and image captioning tasks. Besides, with
much fewer unnatural data (3M vs 9M) and parameters (8.1B vs 17.3B),
outperforms CogAgent [cogagent](None) on InfoVQA and ChartQA,
and achieves comparable performance on DocVQA. This suggests that our
unified structure learning with is more efficient in learning printed
text recognition and how to analyze documents. However, our model still
underperforms CogAgent on TextVQA, which requires the ability of scene
text recognition and general knowledge about natural objects. The
primary reason is that scene texts are more diverse in shapes than
printed texts and CogAgent is trained on 98M samples of scene text
recognition from LAION-2B [laion](None) and
COYO-700M [coyo](https://github.com/kakaobrain/coyo-dataset), much more than the natural images (1M)
in . In this work, we mainly focus on improving the unified structure
comprehension of visual documents and leave further scaling up data on
natural scenes as future work. Finally, -Chat can also be evaluated on
these concise-answer benchmarks by removing the prompt of detailed
explanation. It achieves comparable or slightly better performance than
, showing that a small amount of detailed explanatory data may better
help the model understand the semantics of text-rich images.
## Ablation Study
As shown in [tab:ablation], we further perform a
comprehensive ablation study to validate the effectiveness of our and
Unified Structure Learning.
Firstly, initializing from a stronger general MLLMs brings better
performance on text-rich images (r2 vs r1), showing general
vision-and-language knowledge benefits visual document understanding.
Tuning the visual encoder during multi-task fine-tuning significantly
improves the document understanding performance (r3 vs r2). This
suggests that the visual representation of document images may be the
main shortcoming of MLLMs and inspires us to design Unified Structure
Learning to enhance the representation ability of the visual encoder for
visually situated texts and structure.
**Effectiveness of .** When using the Shape-adaptive Cropping Module,
the image resolution supported by the MLLM is the product of the
cropping number and basic resolution of each crop. With the Abstractor
as the vision-to-text module, reducing the cropping number causes an
obvious performance decrease (r4 vs r3) on documents. However, with a
smaller cropping number, the achieves better performance than the
Abstractor (r5 vs r3), showing that $448^2\times9\approx2^{21}$ is an
acceptable resolution for existing benchmarks and the is stronger on
maintaining rich text information during vision-and-language feature
alignment. Besides, we further compare different settings of the merging
shape in the convolution layer. With the same number of merged tokens,
the model with the 1x4 merging shape achieves better performance than
the one with the 2x2 merging shape on document and table datasets but
slightly worse performance on chart understanding (r6 vs r5). This is
consistent with the common sense that documents and tables mainly
organize texts in the left-to-right order while the semantic structures
of charts are much more flexible. A square merging shape is more suited
to encode visual features in the form of bars, lines, or pies while the
1x4 merging shape is more appropriate for general document
understanding. As shown in r7-r9, further extending the 1x4 merging
shape horizontally and vertically decreases the length of visual
features but at the cost of performance degradation. Considering the
overall performance on all text-rich images, we finally choose the 1x4
as the merging shape in .
**Effectiveness of Unified Structure Learning.** After determining the
vision-to-text module, we perform two-stage training with Unified
Structure Learning. With only the structure-aware parsing tasks, there
is significant improvement across different domains (r10 vs r5). This
validates that fine-tuning the visual encoder and with structure-aware
parsing tasks greatly helps MLLMs understand text-rich images. Further
tuning the parameters of LLM brings slight improvement (r11 vs r10),
suggesting that general language knowledge is not the main obstacle to
visual document understanding. By replacing the learnable crop position
embeddings with special textual tokens, the model achieves better
performance (r12 vs r11), showing that the LLM can well understand the
relative positions of multiple cropped images with just simple textual
indicators. Finally, by introducing Multi-grained Text Localization
tasks, achieves the best performance, validating that correlating
visually situated texts with concrete positions helps comprehend
documents more accurately.
**Effectiveness of the Two-stage Training.** As shown in
[tab:two_stage], instead of two-stage
training, we also try one-stage joint training of the structure learning
and downstream tasks and gradually increase the samples from . The epoch
is gradually reduced because we didn’t observe performance improvements
with more iterations. For joint training, the model improves
significantly on DocVQA as the samples of Unified Structure Learning
increase when it is below 1M. However, as the Unified Structure Learning
samples are further increased, the improvement of the model becomes
subtle and its performance is not as good as the one using two-stage
training. This shows that the two-stage training could better enhance
basic text recognition and structure parsing abilities and is more
beneficial and efficient for downstream document understanding.
## Text Localization Evaluation
Besides proving the effectiveness of through downstream text-rich image
understanding performance in
[tab:ablation], we further directly
compare the text localization performance after the Unified Structure
Learning to validate its superiority in preserving spatial features. We
build a text localization evaluation set with 4,250 samples balanced on
4 granularities and covering both text recognition and text grounding
tasks. The detailed statistics of are shown in
[tab:eval_set]. Considering that
document images are much more diverse and complex than other images,
there are more samples in this domain than others. The IOU@0.5 is used
to evaluate the text grounding performance. As for text recognition, the
word, phrase, line, and block granularity is evaluated with BLEU1,
BLEU2, BLEU3, and BLEU4 [bleu](http://arxiv.org/pdf/2202.11027v1), respectively. As shown
in [tab:grounding], when trained with
the same iterations, the achieves much better performance on both Text
Recognition and Text Grounding tasks, showing that with the 1x4 merging
shape helps the LLM better understand concrete positions in images.
## Qualitative Results
Besides quantitative results, we further present some qualitative
results of visual document understanding on different domains of images.
As shown in [fig:qa_case](a) and (b), both models
answer the question with texts in the image. can better understand the
structure of two documents and give correct answers. In
[fig:qa_case](c), due to the learning
of parsing chart with Markdown codes, can better understand the chart
and successfully correlate the x/y axis.
[fig:qa_case](d) shows that although
inconsistent with the ground truth, gives another correct answer with
the help of stronger structure understanding on tables.
[fig:instruct_case_1] and
[fig:instruct_case_2] present
qualitative results of detailed explanations. Through a small amount of
reasoning training, -Chat can well inherit the reasoning ability of LLM
and provide detailed explanations about the answer. However, as
presented in
[fig:instruct_case_2](c), like
most general Multimoal large Language
Models [mplugowl](http://arxiv.org/pdf/2405.00390v2), [mplug-owl2](None), [qwenvl](http://arxiv.org/pdf/2308.12966v3), -Chat may also
suffer from the hallucination problem in Visual Document Understanding.
In this work, we mainly focus on enhancing the unified structure
understanding ability of MLLMs and leave how to resolve the
hallucination problem in OCR-free document understanding as future work.
**Structure-aware Parsing.** As shown in
[fig:doc_parse], could parse a
document image by using line feeds and spaces to represent the structure
of text contents. Besides parsing the whole document, as shown in
[fig:doc_parse2], it could also
parse texts from the middle of the image according to human instruction.
[fig:table_parse1] presents
qualitative results of structure-aware table parsing through extended
Markdown syntax on tables with cells spanning multiple columns or not.
Furthermore, [fig:chart_parse1] shows some
cases of parsing different types of charts into Markdown codes,
including vertical bar, horizontal bar, pie, and line charts. When all
data points are presented in the chart, can accurately align statistic
objects with corresponding numbers. It makes some mistakes in
[fig:chart_parse1](d) because
estimating the concrete numbers is quite challenging when no data points
are provided. Finally, as shown in
[fig:natural_parse1], can both
describe the content of natural images and read scene texts.
**Multi-grained Text Localization.**
[fig:ground] and
[fig:recognize] show qualitative
results of text grounding and text recognition at granularities of word,
phrase, line and block. The image domains range from documents,
webpages, charts, and tables to natural images.
# Conclusion
To enhance the Visual Document Understanding performance of Multimodal
Large Language Models, we first propose Unified Structure Learning
across 5 domains of text-rich images, including both structure-aware
parsing tasks and multi-grained text localization tasks. To better
maintain structure and spatial information during vision-and-language
feature alignment, we design a simple and effective vision-to-text
module, named . It mainly utilizes a convolution layer to aggregate
horizontally neighboring visual features. To support the Unified
Structure Learning, we build a training dataset by collecting publicly
available images and carefully constructing structure-aware text
sequences and multi-grained pairs of texts and bounding boxes. With
Unified Structure Learning, our model achieves state-of-the-art
OCR-free performance on 10 visual document understanding benchmarks.
LLaVA-UHD: an LMM Perceiving Any Aspect Ratio and High-Resolution Images
2024-03-18
Ruyi Xu, Yuan Yao, Zonghao Guo, Junbo Cui, Zanlin Ni, Chunjiang Ge, Tat-Seng Chua, Zhiyuan Liu, Maosong Sun, Gao Huang
Visual encoding constitutes the basis of large multimodal models (LMMs) in understanding the visual world. Conventional LMMs process images in fixed sizes and limited resolutions, while recent explorations in this direction are limited in adaptivity, efficiency, and even correctness. In this work, we first take GPT-4V and LLaVA-1.5 as representative examples and expose systematic flaws rooted in their visual encoding strategy. To address the challenges, we present LLaVA-UHD, a large multimodal model that can efficiently perceive images in any aspect ratio and high resolution. LLaVA-UHD includes three key components: (1) An image modularization strategy that divides native-resolution images into smaller variable-sized slices for efficient and extensible encoding, (2) a compression module that further condenses image tokens from visual encoders, and (3) a spatial schema to organize slice tokens for LLMs. Comprehensive experiments show that LLaVA-UHD outperforms established LMMs trained with 2-3 orders of magnitude more data on 9 benchmarks. Notably, our model built on LLaVA-1.5 336x336 supports 6 times larger (i.e., 672x1088) resolution images using only 94% inference computation, and achieves 6.4 accuracy improvement on TextVQA. Moreover, the model can be efficiently trained in academic settings, within 23 hours on 8 A100 GPUs (vs. 26 hours of LLaVA-1.5). We make the data and code publicly available at https://github.com/thunlp/LLaVA-UHD.
Show Paper Content
# Introduction
Recent progress in Large Multimodal Models
(LMMs) [2023llava1.6](https://llava-vl.github.io/blog/2024-01-30-llava-next/), [instructblip2023](None), [li2023monkey](http://arxiv.org/pdf/2103.15488v1), [liu2024llava](http://arxiv.org/pdf/2402.11690v1), [bai2023qwen](None)
has witnessed a significant surge in vision-language understanding,
reasoning, and interaction capabilities. This is achieved by projecting
visual signals into Large Language Models (LLMs) to enable their visual
perception of the world, where visual encoding strategy plays a
fundamental
role [li2023blip2](None), [Alayrac2023Flamingo](http://arxiv.org/pdf/2205.07065v1), [liu2024llava](http://arxiv.org/pdf/2402.11690v1).
Real-world images are known to reside in a wide range of aspect ratios
and resolutions, presenting significant challenges for LMMs in various
applications.
However, most existing
LMMs [chen2023shikra](http://arxiv.org/pdf/2306.15195v2), [instructblip2023](None), [liu2024llava](http://arxiv.org/pdf/2402.11690v1)
perceive images in a fixed aspect ratio (i.e., 1:1) and a low resolution
(i.e., 224$\times$``{=html}224). The compromise to this
simplified setting typically leads to severe shape distortion and blur
of image contents. The problem significantly hurts the capabilities of
LMMs, especially for fine-grained capabilities, such as small object
understanding [li2023otterhd](None) and optical character
recognition [ye2023ureader](None), [bai2023qwen](None), [hong2023cogagent](None).
Moreover, the issue also exacerbates hallucination problems (i.e.,
producing textual responses not factually grounded in images), since
models can only learn to make best guesses to blurred
images [sun2023aligning](None), [yu2023rlhf](None).
To achieve image perception in varied aspect ratios and high resolutions
for LMMs, there are two main challenges: (1) Adaptivity. Since visual
encoders (e.g., CLIP-ViT [radford2021clip](http://arxiv.org/pdf/2404.19696v1)) are
pretrained in fixed resolutions, it can be difficult to deal with images
in a wide range of aspect ratios and resolutions. Simple image
interpolation that deviates far from the pretraining scenarios can
result in out-of-distribution issues. (2) Efficiency. Directly encoding
high-resolution images using vision
Transformers [dosovitskiy2020vit](http://arxiv.org/pdf/2105.15075v2) requires quadratic
computation cost with respect to image sizes. In addition, it can be
even more costly for LLMs to process the large number of visual tokens
from high-resolution images (e.g., 4096 tokens for
896$\times$``{=html}896 images in ViT-L/14).
Moreover, careless visual encoding strategies can even result in
systematic flaws in correctness. For example, despite its powerful
capabilities in various aspects, it has been commonly reported that
GPT-4V [achiam2023gpt4](None) can surprisingly struggle in
some basic capabilities, such as identifying the number of
objects [yang2023dawn](None). The mechanistic cause for such
embarrassment remains largely unknown. In this work, we perform the
first mechanistic investigation of GPT-4V flaws from the perspective of
visual encoding strategy. Our controlled experiments in probing GPT-4V
show that the problem can be partially rooted in its visual encoding
strategy in dealing with high-resolution images. Investigation on
LLaVA-1.5 [liu2023llava1.5](http://arxiv.org/pdf/2310.19145v1), a representative
open-source LMM also shows systematic issues in correctness, indicating
their potential vulnerability for adversarial attacks.
To address the challenges, we present LLaVA-UHD, a large multimodal
model that efficiently perceives any aspect ratio and high-resolution
images. The model has three key components: (1) At the core of LLaVA-UHD
is an image modularization strategy that divides native-resolution
images into smaller variable-sized slices for efficient and extensible
encoding. In comparison to recent works that fit images into several
fixed aspect ratios and
resolutions [SPHINX2023](None), [li2023monkey](http://arxiv.org/pdf/2103.15488v1), the
variable-sized slices in LLaVA-UHD enable full adaptivity to
native-resolution images without padding or shape-distorting resizing.
This is in analogy to the better adaptivity of using water drops vs. ice
cubes in full-filling variable-sized glasses. We also show that the
strategy guarantees minor deviation from the pretraining setting of
visual encoders to maximally retain their capabilities. (2) The visual
tokens are condensed by a compression layer to modest lengths, largely
reducing the computation for LLMs. (3) Finally, the compressed slice
tokens are organized in a spatial schema to inform LLMs about the slice
positions in the image.
Comprehensive experiments on 9 benchmarks show that LLaVA-UHD
significantly improves the capabilities of LMMs, outperforming
established counterparts trained with 2-3 orders of magnitude more data.
Notably, our model built on LLaVA-1.5$_{336\times336}$ supports
672$\times$``{=html}1088 resolution images using only 94%
inference computation, and achieves 6.4 accuracy improvement on TextVQA
and 3.2 accuracy improvement on POPE. The advantage enlarges with more
extreme aspect ratios. We also show that instruction tuning on ViT
parameters is sufficient for adaptation to a broad range of images.
Moreover, the model can be efficiently trained in academic settings,
within 23 hours (vs. 26 hours of LLaVA-1.5) on 8 A100 GPUs.
The contribution of this work can be summarized as threefold: (1) We
perform the first mechanistic investigation of GPT-4V from the
perspective of visual encoding strategy and expose systematic flaws. (2)
We present LLaVA-UHD, a large multimodal model that can efficiently
perceive any aspect ratio and high-resolution images. (3) We conduct
comprehensive experiments to demonstrate the effectiveness of LLaVA-UHD
on 9 popular benchmarks, and also provide analysis for deeper
understanding of the model.
# Pilot Experiments [sec:pilot_exp]
We start with a pilot experiment on the visual encoding strategies of
existing LMMs, taking GPT-4V [achiam2023gpt4](None) and
LLaVA-1.5 [liu2023llava1.5](http://arxiv.org/pdf/2310.19145v1) as representative examples.
GPT-4V is a powerful and most recognized proprietary LMM, while
LLaVA-1.5 is one of the most influential open-source LMMs. Despite their
strong performance in many aspects, it has been commonly reported that
dilemmas can be encountered in some basic
capabilities [yang2023dawn](None). For example, GPT-4V is
prone to miscounting the object numbers in images, whereas the causes
remain largely unknown.
In this work, we perform the first mechanistic investigation of GPT-4V
flaws from the perspective of visual encoding strategy. The key idea is
that by using synthetic images as continuous probes, we can evaluate the
behaviors of GPT-4V in a highly controlled manner, thereby identifying
the underlying causes. Our experimental results indicate that, some
systematic flaws of GPT-4V are likely to be rooted in its visual
encoding strategy, which can be potentially exploited for adversarial
attacks.
## GPT-4V Experiments
**Preliminary.** According to the publicly available information from
OpenAI,[^2] GPT-4V employs two image processing modes: low resolution
and high resolution. (1) In low-resolution mode, for an original image
with dimensions W and H, the model processes only a low-resolution
overview image. (2) In high-resolution mode, besides the overview image,
GPT-4V processes additional slices of the original high-resolution
image, where each slice has $512\times512$ resolution, resulting in
$\lceil \frac{W}{512} \rceil \times \lceil \frac{H}{512} \rceil$ slices
in total. In our experiments on GPT-4V’s new high-resolution mode,
interesting error patterns are observed, prompting an exploration into
GPT-4V’s underlying visual encoding logic.
**How do positions in images influence GPT-4V’s behavior?** Our
experiments start with a simple instance: Given the image as shown in
Fig. [fig:gpt4v_exp1](a), we ask GPT-4V:
“How many circles are there in the image?” We synthesize a series of
image variants by changing the positions of circles in the image, and
keep the text prompt unchanged. For better reliability, we also
synthesize images using other colors and shapes as well, in
$\{\text{red}, \text{green}, \text{white}\} \times\{ \text{circle}, \text{triangle}, \text{square}\}$.
For each instance, we query 15 times to better approximate the true
response distribution.
We calculate the average number answered by GPT-4V for each position in
the image, and report the heatmap in
Fig. [fig:gpt4v_exp1](b). We can observe
that the result is highly correlated with object positions in images.
Specifically, the patterns are split by $256\times256$ squares, and
three interesting patterns can be identified: (1) The central square
exhibits the highest response number, (2) the middle edges show a lower
number, and (3) the corners are the closest to ground truth.
To investigate the cause, we further separate the model responses by
number, and report the distribution across positions for each response
in Fig. [fig:gpt4v_exp1](c), (d), (f), (g)
and (h). Interestingly, besides the correct answers (4: 66.1%) and close
answers (5: 16.6%, 3: 10.2%), it turns out that the remaining two
abnormal answers (8: 5.2%, 16: 1.9%), which doubles and quadruples the
ground truth, account for the error pattern in
Fig. [fig:gpt4v_exp1](b). Combining the
results with the public information from OpenAI, we hypothesize the most
likely cause is that, there are overlaps in the slices of GPT-4V when
the image resolution is not divisible by 512.[^3] As illustrated in
Fig. [fig:gpt4v_exp1](e), the overlapping
areas between two slices will double the number, and the overlapping
areas between four slices will quadruple the number.[^4]
**How do image resolutions influence GPT-4V’s behavior?** To verify the
hypothesis, we further probe GPT-4V through continuously changing image
resolutions. Specifically, we proportionally resize the image in
Fig. [fig:gpt4v_exp2](a) into different
resolutions, and query about the object number in the same way. For each
resolution, we repeatedly query 30 times for better reliability.
We report the experimental results in
Fig. [fig:gpt4v_exp2](b). We observe that
the model responses show a significant phase change with image
resolutions: (1) In phase 1, since there are no image slices, most
answers are correct; (2) In phase 2, answer 12 dominates the responses
possibly due to the incomplete circles in each slice. (3) Phase 3 shows
mixed answers of 9, 12 and 16. Note that 16 can be well explained by the
error pattern in
Fig. [fig:gpt4v_exp1](e). We refer
readers to
Section 7 for a more detailed
illustration of each phase. Besides, we also notice that many abnormal
phenomenons in Fig. [fig:gpt4v_exp2](b) cannot be
perfectly explained yet, which we leave for future work.
In conclusion, these experimental findings shed light on GPT-4V’s
potential vulnerabilities in high-resolution image processing,
warranting further investigation into the implications of these
weaknesses and the development of strategies to counter potential
adversarial attacks on LMMs.
## LLaVA-1.5 Experiments
To deal with images with varied aspect ratios, LLaVA-1.5 pads the input
images into squares before feeding them into the visual encoder. This
encoding method results in a waste of computation for non-square images.
For example, a 1:4 image has only 25% effective computation after
padding into squares. To quantify the influence, we train an unpadded
version of LLaVA-1.5, by fitting the ViT position embedding into the
aspect ratio of input images using 2D interpolation. The resultant image
tokens remain no more than 576 as in LLaVA-1.5 (see
Section 3.1). From the experimental results in
Table [tab:module_ablations], we
observe that adaptive aspect ratio encoding without padding consistently
improves the performance of LLaVA-1.5.
Another issue of padding is that, the model essentially cannot know
whether the padding-like pixels come from image pre-processing or an
actual part of the original input image. To demonstrate this issue, we
synthesize a series of input images as in
Fig. [fig:llava_exp](right), where
blue/green/red rectangles in various aspect ratios are surrounded by
grey (i.e., the color of LLaVA-1.5’s padding RGB value). Given the input
image, we prompt: “What is the color of the left/right/top/bottom most
area?” From the results in
Fig. [fig:llava_exp](left), we observe
that LLaVA-1.5 neglects the grey input areas (considering them as
padding), and faithfully responds with the color of the central
rectangle.
## Conclusions on Pilot Experiments
In summary, both powerful proprietary LMMs such as GPT-4V and
open-source LLaVA-1.5 have systematic issues in their underlying visual
encoding strategies. The results show that visual strategies must be
designed with caution. Common practices such as padding,
shape-distorting resizing, and repetitive slicing can result in a waste
of computation, a loss of model capability, and even vulnerability to
adversarial attacks. Therefore, there is an urgent need for more
adaptive and efficient visual encoding methods.
# Method
Based on the principles learned from the pilot experiments, we propose
LLaVA-UHD, a large multimodal model that can efficiently perceive any
aspect ratio and high-resolution images. As shown in
Fig. [fig:framework], the model includes
three key components: (1) An image modularization strategy that divides
native-resolution images into smaller variable-sized slices for
efficient and extensible encoding, (2) a compression module that further
condenses image tokens from visual encoders, and (3) a spatial
decoration schema to organize slice tokens for LLMs.
## Modularized Visual Encoding [sec:encoding]
To deal with high-resolution images with varied aspect ratios, a naive
approach is to interpolate the position embeddings of ViT to the target
shape for direct encoding as a whole. However, this approach is
sub-optimal due to the quadratic computation cost and the performance
degradation from out-of-distribution issues. To address the challenge,
we present a modularized visual encoding strategy. The basic idea is to
divide native-resolution images into smaller variable-sized slice
slices, where the shape of each slice does not deviate too far from the
standard pretraining setting of ViT. With variable-sized slice slices,
LLaVA-UHD can achieve full adaptivity to native-resolution images
without padding or shape-distorting reshaping.
**High-Resolution Image Partition Strategy.** The goal of image slicing
strategy is to determine a split of high-resolution images, with minimal
changes to the resolutions of each slice. Given an image in resolution
$(W_I, H_I)$ and a ViT pretrained in resolution $(W_v, H_v)$, we first
determine the number of slices (i.e., the ideal computation) needed to
process the image:
$N=\lceil \frac{W_I\times H_I}{W_v\times H_v} \rceil$. Then we factorize
the slice number $N$ into $m$ columns and $n$ rows:
$\mathbb{C}_N= \{(m, n)| m\times n = N, m\in \mathbb{N}, n\in \mathbb{N} \}$.
To select the most appropriate partition, we define a score function to
measure the deviation from the standard pretraining setting of ViT:
$$\small
S(W_I, H_I, W_v, H_v, m, n)= -\left| \log \frac{W_I \times n}{H_I \times m} - \log \frac{W_v}{H_v}\right|,$$
where higher score $S(\cdot)$ indicates a smaller deviation from the
standard setting of ViT, and is thus preferred. Therefore the partition
can be obtained as follows:
$$\small
m^*, n^* = \mathop{\mathrm{arg\,max}}_{(m,n)\in \bar{\mathbb{C}}} S(W_I, H_I, W_v, H_v, m, n),
\label{equ:partition}$$ where the candidate set
$\bar{\mathbb{C}} = \mathbb{C_N}$. In practice, we notice that in some
cases, there might be only a few possible factorization schemes for $N$,
especially for prime numbers, which can lead to limited choices and
therefore extreme partitions of images. For example, $N=7$ has only two
extreme partition choices, 1:7 and 7:1. To address the issue, in
addition to the ideal slice number $N$, we also allow a modest change of
slice numbers $N-1, N+1$ to incorporate more plausible partition
choices. Therefore, the final partition is given by
Equation [equ:partition], where
$\bar{\mathbb{C}} = \mathbb{C}_{N-1} \cup \mathbb{C}_{N} \cup \mathbb{C}_{N+1}$.
Theoretically, we show that the partition strategy guarantees minor
expected changes and modest worst-case changes with respect to standard
pretraining resolution $(W_v, H_v)$ for each slice. Specifically, we
show that for input images where $N \leq 20$ and aspect ratio in
$[1:6, 6:1]$, the aspect ratio of each slice resides within
$[1:2, 2:1]$, and the area of each slice resides within
$[0.33W_IH_I, 1.5W_IH_I]$. We refer readers to
Section 8 for full proof details.
**Arbitrary Aspect Ratio Slice Encoding.** Most existing LMMs utilize a
static resolution for image slice
encoding [bai2023qwen](None), [liu2023llava1.5](http://arxiv.org/pdf/2310.19145v1), [instructblip2023](None).
This essentially prevents full adaptivity to native resolutions, since
only several predefined fixed-shape slices are available. Moreover, the
static slice resolution inevitably incurs padding or shape-distorting
resizing, which hurts the performance, efficiency, and even correctness
as discussed in
Section 2.
To address the problem, we propose to encode image slices in aspect
ratios given by the partition strategy as is. Specifically, we
proportionally resize the original image following the aspect ratio,
such that the number of patches maximally fits within the pretraining
budget $M$ (i.e., the number of position embeddings in ViT). Then we
reshape the pretrained 1D position embedding sequence of ViT into 2D
format $P \in \mathbb{R}^{q\times q \times l}$ following its pretraining
setting, where $M=q\times q$, and $l$ is the dimension of position
embeddings. After that, we 2D-interpolate $P$ to fit the slice
resolution given by the partition strategy for visual encoding. In our
experiments, we show that ViT and position embedding parameters can be
kept frozen during pretraining, and updating these parameters during the
instruction-tuning stage is sufficient for good performance. In addition
to slices, we also provide a low-resolution overview image in native
aspect ratio. The overview image can provide coarse-grained information
and global semantic connections in images.
## Compression Layer
High-resolution images require LLMs to process significantly more visual
tokens, which accounts for a major part of the computation. For example,
a $672\times 1008$ resolution image will produce 3,456 visual tokens for
LLaVA-1.5 [liu2023llava1.5](http://arxiv.org/pdf/2310.19145v1). To address the issue, we
compress the visual tokens of each image slice using a shared perceiver
resampler layer [Alayrac2023Flamingo](http://arxiv.org/pdf/2205.07065v1). Specifically,
image tokens output by the visual encoders are resampled to a lower
number using a set of query vectors via cross-attention (from $576$ to
$64$ in our experiments). Compared with the prevalent MLP-based visual
projection
approaches [liu2023llava1.5](http://arxiv.org/pdf/2310.19145v1), [2023llava1.6](https://llava-vl.github.io/blog/2024-01-30-llava-next/), [wang2023cogvlm](None),
perceiver resampler maintains a fixed and affordable number of visual
tokens regardless of image resolutions, and is therefore more compatible
with high-resolution image understanding. As a result, LLaVA-UHD can
encode $672\times1008$ resolution images using an even lower computation
cost than LLaVA-1.5 in encoding $336\times336$ resolution images.
## Spatial Schema for Image Slices
Since the image partition is dynamic across different images, it is
necessary to inform LLM of the spatial organizations of image slices.
Inspired by [fuyu2023](adept.ai/blog/fuyu-8b), we design a spatial schema to
inform the relative positions of image slices using two special tokens.
Specifically, we use “,” to separate the slice representations in a row,
and use “\n” to separate different rows. In our experiments, we find
that the simple schema can effectively inform the dynamic partition to
yield good performance.
# Experiments
In this section, we empirically investigate the effectiveness of
LLaVA-UHD. We first provide the implementation details, and report the
evaluation results on 9 common benchmarks compared with strong
baselines. Then we provide analytic results for better understanding of
the model.
## Implementation Details
**Model Configuration.** In this work, we built LLaVA-UHD following the
implementation of LLaVA-1.5 [liu2023llava1.5](http://arxiv.org/pdf/2310.19145v1).
Specially, we use the CLIP-ViT-L/14 as visual encoder (default
resolution ${336\times336}$),
Vicuna-13B [chiang2023vicuna](None) as LLM, and a shared
visual resampler [bai2023qwen](None) as the projector to
connect the visual encoder and LLM. During the encoding of image slices,
a minor reshape within half patches (maximum 7-8 pixels) could be
performed to fit the slice into patches. The number of learnable queries
in resampler is set to 64. For the image partitioned as $N$ sub-patches,
the number of visual tokens fed into LLM is $64\times(N+1)$, with tokens
of the low-resolution overview image. We set the maximum $N$ to be 6 in
experiments, which supports a maximum of $672\times1008$ resolution
images. Following LLaVA-1.5, we perform a two-stage training as follows.
**Stage 1: Pretraining details.** During this stage, only the perceiver
resampler is tuned, with the CC-595K
dataset [liu2024llava](http://arxiv.org/pdf/2402.11690v1) for 1 epoch, using AdamW
optimizer with a learning rate of $1e^{-3}$ and the cosine learning rate
schedule. The global batch size is set to 256. The training cost of this
stage is $\sim$``{=html}5 hours using 8$\times$A100 GPUs.
**Stage 2: Instruction-tuning details.** During this stage, the visual
encoder is frozen and we fine-tune the visual resampler and LLM, with a
656K mixture dataset [liu2023llava1.5](http://arxiv.org/pdf/2310.19145v1) which contains
LLaVA-Instruct [liu2024llava](http://arxiv.org/pdf/2402.11690v1),
TextVQA [singh2019textqa](None),
GQA [hudson2019gqa](None),
OCR-VQA [mishra2019ocrvqa](None), and Visual
Genome [krishna2017vg](None). The learning rate is 2$e^{-5}$
and batch size is 128. Other settings are the same as stage 1. The
training cost of this stage is $\sim$``{=html}18 hours using
8$\times$A100 GPUs.
## Experimental Setting
We introduce experimental settings, including the benchmarks, evaluation
metrics, and baselines.
**Benchmarks.** We adopt 9 popular benchmarks to evaluate our model,
including: (1) General visual question answering benchmarks such as
VQA-V2 [antol2015vqa](None),
GQA [hudson2019gqa](None),
ScienceQA [lu2022scienceqa](http://arxiv.org/pdf/2209.09513v2), and
VizWiz [gurari2018vizwiz](None); (2) Optical character based
visual question answering benchmark such as
TextVQA [singh2019textqa](None); (3) Hallucination benchmark
such as POPE [li2023pope](http://arxiv.org/pdf/2402.15721v1); (4) Comprehensive benchmarks
such as MME [fu2023mme](None),
MMBench [liu2023mmbench](None), and
MMBench-CN [liu2023mmbench](None).
**Evaluation Metrics.** In addition to the performance on popular
benchmarks, we also report the computation cost (TFLOPs) in processing
an image in the maximum supported resolution. The computation cost is
aggregated from the visual encoder, projector, and LLM. We also report
the accumulated multimodal training data volume for reference, which
includes image-text pairs used during pertaining and instruction tuning.
For models post-trained on existing multimodal models as backbones, this
also includes the training data of the backbones.
**Baselines.** We compare our model with strong baselines. (1) General
baselines. We adopt Qwen-VL [bai2023qwen](None),
LLaVA-1.5 [liu2023llava1.5](http://arxiv.org/pdf/2310.19145v1),
MiniGPT-v2 [chen2023minigptv2](None),
Shikra [chen2023shikra](http://arxiv.org/pdf/2306.15195v2),
BLIP-2 [li2023blip2](None) and
InstructBLIP [instructblip2023](None) as representative
general baselines. Since the implementation of LLaVA-UHD is highly
aligned with LLaVA-1.5, it serves as the most direct baseline. (2)
High-resolution LMMs. SPHINX [SPHINX2023](None) and
mPLUG-Owl2 [ye2023owl2](http://arxiv.org/pdf/2311.04257v2) encode images in fixed
resolutions; Ureader [ye2023ureader](None) and
Monkey [li2023monkey](http://arxiv.org/pdf/2103.15488v1) support enumerated resolution
types (several predefined fixed-shape slices);
Fuyu-8B [fuyu2023](adept.ai/blog/fuyu-8b) and
OtterHD-8B [li2023otterhd](None) can encode images in any
resolutions.
## Main Results
We report the main experimental results in
Table [tab:sota], from which we have the
following observations: (1) LLaVA-UHD outperforms strong baselines on
popular benchmarks. This includes strong general baselines trained on
2-3 orders of magnitude more data such as Qwen-VL and InstructBLIP, and
also high-resolution LMMs that require significantly more computation
such as Fuyu-8B, OtterHD-8B, Monkey and SPHINX-2k. The results show that
LLaVA-UHD can properly deal with native-resolution images for strong
performance, as well as good data and computation efficiency. (2)
LLaVA-UHD achieves significant improvements over the LLaVA-1.5 backbone.
Notably, by simply perceiving images in native high-resolution,
LLaVA-UHD achieves 6.4 accuracy improvement on TextVQA and 3.2 accuracy
improvement on POPE. The reason is that the blurred content in
low-resolution images can prevent LMMs from accurately identifying the
challenging fine-grained objects and optical characters. The results
demonstrate the fundamental role of perceiving native high-resolution
images in various multimodal tasks, and the effectiveness of LLaVA-UHD
in addressing the problem. (3) In terms of resolution and efficiency,
compared with LLaVA-1.5 associated fixed $336\times336$ resolution,
LLaVA-UHD supports 672$\times$``{=html}1088 resolution images in
any aspect ratio using only 94% inference computation. The results
indicate promising scalability of LLaVA-UHD to potentially larger
resolutions in future.
## Analytic Results
We provide further analytic results, including ablation on alternative
components, evaluation on images with more extreme aspect ratios, best
practice for frozen/trainable parameters, and case study.
**Ablation Study.** In
Table [tab:module_ablations], we
conduct ablation studies on alternative components. (1) We replace the
padding strategy of LLaVA-1.5 with the adaptive encoding strategy of
LLaVA-UHD, supporting arbitrary aspect ratios while maintaining
identical maximum resolutions. We can observe consistent improvement
since wasted computation from padding is avoided. (2) We replace the
perceiver resampler of LLaVA-UHD with the 2-layer MLP of LLaVA-1.5. We
observe that perceiver resampler achieves comparable or better
performance than MLP, using only 12.9% computation cost. (3) We further
replace the LLaVA-UHD image partition strategy with the naive partition
strategy [SPHINX2023](None) (i.e., fixed $2\times2$ slices).
Results show that LLaVA-UHD can more properly divide images into slices
for better performance. (4) We remove the spatial schema from LLaVA-UHD.
The performance degradation demonstrates the effectiveness and necessity
of spatial schema in informing the dynamic slice positions for LMMs.
**LLaVA-UHD generalizes to images with extreme aspect ratios.** We
further investigate the generalization capability of LLaVA-UHD by
constructing an extended version of existing benchmarks. Specifically,
we expand the aspect ratio of an image by doubling the length of its
longer side through padding. From the results in
Table [tab:padding_evaluation], we
can see that the advantage of LLaVA-UHD increases as compared with
LLaVA-1.5 and alternatives. The reason is that LLaVA-UHD perceives
images in native aspect ratios. In comparison, LMMs that encode images
in fixed aspect ratios will suffer from significant distortion in the
content shapes. Moreover, this also causes the computation to be
unevenly distributed along the width and height of the image content.
**Instruction-tuning ViT parameters is sufficient for adaptation.** We
investigate the effect of tuning ViT parameters at different training
stages, including pretraining and instruction-tuning. From the results
in Table 1, we observe that: (1) Updating
ViT during instruction-tuning is sufficient to achieve good performance.
In fact, we find that LLaVA-UHD can improve over LLaVA-1.5 even when ViT
parameters are frozen in both pretraining and instruction tuning. (2)
Further updating ViT during pretraining does not lead to better results.
We hypothesize the reason is that jointly training ViT and resampler
(from scratch) on limited pretraining data can lead to instability
issues.
**Case Study.** To provide a more intuitive understanding of the
capabilities of LMMs in dealing with high-resolution images, we provide
qualitative results for LLaVA-UHD and LLaVA-1.5 in
Fig. [fig:case]. We can see that LLaVA-UHD can
correctly identify the dense content in the timetable (Case 1), the text
on the small poster (Case 2), and icons and text on the phone (Case 3)
for fine-grained recognition and reasoning. In comparison, LLaVA-1.5 can
only perceive coarse-grained information, and therefore tends to provide
either uninformative (Cases 1 and 2) or incorrect/hallucinated answers
(Case 3) in these challenging scenarios. The results demonstrate the
effectiveness and advantage of LLaVA-UHD in perceiving native aspect
ratio and high-resolution images for fine-grained multimodal
capabilities.
# Related Work
**Visual Encoding in LMMs.** The advent of
ChatGPT [ChatGPT2022](None) and
GPT-4 [achiam2023gpt4](None) has spurred the development of
numerous open-source large language models
(LLMs) [chiang2023vicuna](None), [touvron2023llama](None), [Chung2022Flan5](http://arxiv.org/pdf/2202.03371v1).
Utilizing an LLM as a language encoder and decoder, there springs up
plenty of
LMMs [li2023blip2](None), [instructblip2023](None), [Alayrac2023Flamingo](http://arxiv.org/pdf/2205.07065v1), [liu2024llava](http://arxiv.org/pdf/2402.11690v1), [bai2023qwen](None), [hong2023cogagent](None),
with aim at understanding visual image. Therefore, how to encode vision
features into LLMs becomes the core problem in the community.
Fortunately, CLIP [radford2021clip](http://arxiv.org/pdf/2404.19696v1) proposes to
respectively extract language embeddings using language models like
BERT [Devlin2018BERT](None) and visual features using vision
models like ViT [dosovitskiy2020vit](http://arxiv.org/pdf/2105.15075v2) and
CNN [he2016resnet](http://arxiv.org/pdf/1608.05895v1), and align them in contrastive
learning fashion using considerable image-text
pairs [schuhmann2022laion](None), so that visual embeddings
are well aligned towards the language.
Existing visual projection approaches towards LLMs can be divided into
three categories. (1) Flamingo [Alayrac2023Flamingo](http://arxiv.org/pdf/2205.07065v1)
proposes perceiver resampler, which utilizes a fixed number of queries
to capture visual features by cross-attention operation and feeds them
into LLMs for image/video understanding. (2)
BLIP-2 [li2023blip2](None) pretrains Q-Former to bridge the
image encoder and LLMs. (3) LLaVA [liu2024llava](http://arxiv.org/pdf/2402.11690v1) just
leverages an MLP module to connect language and vision feature space.
Beyond them, SPHINX [SPHINX2023](None) mixes many kinds of
visual features, including DINO-V2 [oquab2023dinov2](None),
CLIP-ViT [radford2021clip](http://arxiv.org/pdf/2404.19696v1) and
CLIP-CNN [radford2021clip](http://arxiv.org/pdf/2404.19696v1), and Q-Former to augment
visual representation. Vary [wei2023vary](http://arxiv.org/pdf/2312.06109v1) pretrains a
visual model tailored for document/chart recognition and understanding,
and integrates it with visual features of
LLaVA [liu2024llava](http://arxiv.org/pdf/2402.11690v1) for further feature enhancement.
However, since these LMMs rely on CLIP-ViT that requires fixed
resolution image as input, it hinders LMMs from handling images with
higher resolution or any aspect ratio, and undermines fine-grained
downstream tasks like optical character recognition or small object
understanding.
**High-resolution LMMs.** To perceive images with higher resolutions,
recent work can be divided into four categories. (1) Up-Resize.
Qwen-VL [bai2023qwen](None) interpolates the positional
embedding of ViT from 224$\times$``{=html}224 to
448$\times$``{=html}448 and additionally executes a training
stage to fine-tune the ViT. CogAgent [hong2023cogagent](None)
and LLaVA-HR [luo2024feast](http://arxiv.org/pdf/2403.03003v1) marries a large
low-resolution encoder with a small high-resolution image.
MiniGPT-v2 [chen2023minigptv2](None) only resizes the
positional embeddings without fine-tuning the visual encoder during
instruction tuning. These methods dramatically change the original
visual position encoding of CLIP-ViT [radford2021clip](http://arxiv.org/pdf/2404.19696v1),
which can cause sub-optimal visual representation. (2) Fix+Crop. To
address the above issue, SPHINX [SPHINX2023](None) utilizes a
fixed window size (224$\times$``{=html}224) to crop a padded
image (448$\times$``{=html}448) into four slices, and
concatenates them with a down-sampled 224$\times$``{=html}224
image as visual inputs. Monkey [li2023monkey](http://arxiv.org/pdf/2103.15488v1) follows
this idea yet increases the accessible image size to
896$\times$``{=html}1344, and converts each slice using a shared
resampler. (3) Fix+Enumerated-Crop.
UReader [ye2023ureader](None),
LLaVA-1.6 [2023llava1.6](https://llava-vl.github.io/blog/2024-01-30-llava-next/) and
infiMM-HD [liu2024infimm](None) enumerate a similar aspect
ratio to resize, rather than using a fixed square ratio (e.g.,
2$\times$``{=html}2 as in SPHINX [SPHINX2023](None)).
The unavoidable image resizing and padding operation might cause image
deformation and waste of computation, respectively. (4) Any.
Fuyu-8B [fuyu2023](adept.ai/blog/fuyu-8b) and
Otter-HD [li2023otterhd](None) directly utilize LLMs to encode
visual features instead of vision transformers. They just split images
into patches and project them using linear layers before feeding into
the LLM. Regarding image patches as a sequence enables itself to process
images with continuous resolution. However, the removal of an image
encoder means insufficient visual representation, which makes these
methods limited in unsatisfactory performance.
In comparison, LLaVA-UHD supports images in any aspect ratios and high
resolutions. By integrating the advantages of modularized and adaptive
image encoding, as well as perceiver resampler, LLaVA-UHD can achieve
strong performance with improved computation efficiency.
# Conclusion
In this work, we present LLaVA-UHD, a large multimodal model that
efficiently perceives any aspect ratio and high-resolution images.
Comprehensive experimental results on 9 popular benchmarks demonstrate
the effectiveness of LLaVA-UHD, especially in fine-grained multimodal
capabilities. Analytical evaluation results are provided for deeper
understanding of the model. In this work, we limit the resolution of
LLaVA-UHD to maximum $672\times1008$. In future, considering the
promising efficiency and scalability, we will explore higher-resolution
images and more challenging tasks such as small object detection and
segmentation. Besides, image slices are currently independently encoded,
with interactions only in LLMs. We plan to establish efficient
connections between image slices via improved visual encoding strategies
for fine-grained global information interaction.
# Detailed Illustration on GPT-4V Phases [sec:GPT-4V-illustration]
From the pilot experimental results in
Fig. [fig:gpt4v_exp2_appendix],
we observe that the GPT-4V responses show a significant phase change
with image resolutions. Here we provide detailed illustrations of the
hypothesized cause from the perspective of visual encoding:
\(1\) In phase 1, since there is only one image slice, most answers are
correct. More specifically, when dealing with input images under 512
resolution, if the images are resized to 512, the behavior will be the
same within phase 1. However, since the behavior changes significantly
within phase 1, we suspect that the input images are most likely to be
padded into 512 resolutions, as shown in
Fig. [fig:illustration](a).
\(2\) In phase 2, answer 12 dominates the responses possibly due to the
incomplete circles in each slice, as shown in
Fig. [fig:illustration](b).
\(3\) Phase 3 shows mixed answers of 9, 12 and 16. Among these
responses, answer 16 can be well explained by the slice strategy in
Fig. [fig:illustration](c). Besides, we
also notice that many abnormal phenomenons in
Fig. [fig:gpt4v_exp2](b) cannot be
perfectly explained yet, which we leave for future work.
# Proofs [sec:proofs]
In this section, we provide proofs for the image partition strategy. We
show that the slice resolution exhibits modest changes to the original
resolution of ViT.
**Range of Slice Aspect Ratios.** The aspect ratio of the slice can be
represented by: $$\frac{W_v}{H_v} = \frac{W_I}{m} : \frac{H_I}{n},$$
where $W_v$, $H_v$ are the width and height of the slice, $W_I$, $H_I$
are the sizes of the original image, and (m, n) is the best partition.
Restricting the aspect ratio $r = \frac{W_v}{H_v} \in [\frac{1}{2} , 2]$
is equivalent to
$\left|\log(\text{r})\right| \leq \left| \log 2 \right|$, which is also
equivalent to
$\left| \log\left(\frac{W_I}{H_I}\right) - \log(\frac{n}{m}) \right| \leq \left| \log(2) \right|$.
We need to prove:
$$\forall \frac{W_{I}}{H_{I}} \in [\frac{1}{6}, 6], N \leq 20$$
$$\exists (\mbox{m, n}) \in \bar{\mathbb{C}}, \left| \log\left(\frac{W_{I}}{H_{I}}\right) - \log(\frac{n}{m}) \right| \leq |\log(2)|,$$
which is equivalent to
$$\forall N \leq 20, (n_{i}, m_{i}) \in \bar{\mathbb{C}}$$
$$\exists (n_{j}, m_{j}) \in \bar{\mathbb{C}}, \left| \left(\log\left(\frac{n_{i}}{m_{i}}\right) - \log\left(\frac{n_{j}}{m_{j}}\right) \right) \right| \leq 2 \cdot \left|\log(2)\right|,$$
which can be verified by enumerating all possible factorizations of
$\bar{\mathbb{C}} = \mathbb{C}_{N-1} \cup \mathbb{C}_{N} \cup \mathbb{C}_{N+1}$
for $N \leq 20$. The results show that the aspect ratio of each slice
resides within $[\frac{1}{2}, 2]$.
**Expected Aspect Ratio.** We assume that the ratio of the original
image is greater than 1 (i.e., $H_I > W_I$). The situation is the same
for $H_I < W_I$. Assuming that the sizes of the images are uniformly
distributed for $N\in [0, 20]$, while the aspect ratio of the original
images $\frac{W_I}{H_I} \in [1, 6]$, we have
$P(W_I,W_H,n,m) = \frac{1}{20} \cdot \frac{1}{5}$. The expected aspect
ratio can be obtained by:
$$\small
{\textrm{E}}(\frac{m \times W_I}{n \times H_I}) = \iint_{{\begin{array}{c}
\frac{W_I}{H_I} \in [1, 6] \\
W_I \cdot H_I \in [0, 20s] \\
n,m = \mathop{\mathrm{arg\,max}}S(\cdot)
\end{array}}} (\frac{m \times W_I}{n \times H_I}) \cdot P(W_I,H_I,n,m) \ dW_I dH_I,$$
where $s$ is the area of a standard resolution of ViT. After
calculation, we obtain ${\textrm{E}}(r) = 1.258$,
${\textrm{Var}}(r) = 0.048$. The results show that the expected aspect
ratio of the slices is 1:1.258, which is close to the standard
pertaining setting of ViT. More commonly assuming that images are
uniformly distributed between $[1, 3]$, and the aspect ratio is
uniformly distributed between $[1, 2]$, we have
${\textrm{E}}(r) = 1.147$, ${\textrm{Var}}(r) = 0.011$, indicating even
smaller changes.
**Range of Slice Area.** Let
$n = \frac{W_I}{W_v} \times \frac{H_I}{H_v}$, which leads to
$N= \lceil n \rceil$. We consider dividing the image into
$\{N-1, N, N+1\}$ slices. Therefore, the maximum value of each slice
$\text{S}_\text{max} = \frac{n}{N-1}$ (when $N \neq 2$), and
$\text{S}_\text{max} = \frac{n}{N}$ (when $N = 2$). The minimum value
$\text{S}_\text{min} = \frac{n}{N+1}$. As $n$ approaches $3^-$, where
$N = 3$, $\text{S}_\text{max}$ achieves the maximum value of $1.5$.
Similarly, as $n$ approaches $1^+$, where $N = 2$, $\text{S}_\text{min}$
achieves the minimum value of $0.33$.
**Expected Slice Area.** Still assuming that the sizes of the images are
uniformly distributed within $N \in [0, 20]$, while the aspect ratio of
the images $\frac{W_{I}}{H_{I}} \in [\frac{1}{6}, 6]$. The expected area
of slice can be obtained by:
$${\textrm{E}}(\frac{W_I \times H_I}{n \times m}) = \iint_{{\begin{array}{c}
\frac{W_I}{H_I} \in [1, 6] \\
W_I \cdot H_I \in [0, 20s] \\
n,m = \mathop{\mathrm{arg\,max}}S(\cdot)
\end{array}}} (\frac{W_I \times H_I}{n \times m}) \cdot P(W_I,H_I,n,m) d W_I d H_I.$$
After calculation, we obtain
${\textrm{E}}(\frac{W_I \times H_I}{n \times m})= 1.057$,
${\textrm{Var}}(\frac{W_I \times H_I}{n \times m})= 0.016$. This shows
that our slice areas are relatively concentrated, similar to the
original resolution of ViT.
# Discussions
We provide discussions on limitations and potential negative impact of
this work.
**Limitations and Future Work.** (1) Higher resolutions. In this work,
we limit the resolution of LLaVA-UHD to maximum $672\times1008$.
Although this resolution increases the standard LLaVA-1.5 resolution by
6 times, higher-resolution images such as 4K images and remote sensing
images are still out of reach. In future, considering the promising
efficiency and scalability, we will explore higher-resolution images and
more challenging tasks such as small object detection and segmentation.
(2) Joint slice encoding. Currently image slices are currently
independently encoded, with interactions only in LLMs. We plan to
establish efficient connections between image slices via improved visual
encoding strategies for fine-grained global information interaction.
**Potential Negative Impact.** In this work, we investigate the failure
pattern and the underlying cause for GPT-4V and LLaVA-1.5. The mechanism
can be potentially used for adversarial attacks on these models. It is
worth noting that the goal of this work is to raise attention to the
vulnerability of LMMs and provide a deeper understanding of the
importance of visual encoding strategies. This work calls for further
efforts to mitigate the revealed issues to ensure the robustness and
safety of LMMs.
[^1]: Corresponding Authors
[^2]:
[^3]: Note that the issue is different from the overlapping sliding
windows in CNNs, since the overlaps in GPT-4V is inconsistent across
different resolution images.
[^4]: Note that besides visual encoding strategies, model behaviors are
also influenced by the accumulated training dynamics and RLHF.
Therefore the double/quadruple effect does not dominate the results.
All results are from GPT-4V on 03-05-2024.
TextMonkey: An OCR-Free Large Multimodal Model for Understanding Document
2024-03-07
Yuliang Liu, Biao Yang, Qiang Liu, Zhang Li, Zhiyin Ma, Shuo Zhang, Xiang Bai
We present TextMonkey, a large multimodal model (LMM) tailored for text-centric tasks. Our approach introduces enhancement across several dimensions: By adopting Shifted Window Attention with zero-initialization, we achieve cross-window connectivity at higher input resolutions and stabilize early training; We hypothesize that images may contain redundant tokens, and by using similarity to filter out significant tokens, we can not only streamline the token length but also enhance the model's performance. Moreover, by expanding our model's capabilities to encompass text spotting and grounding, and incorporating positional information into responses, we enhance interpretability. It also learns to perform screenshot tasks through finetuning. Evaluation on 12 benchmarks shows notable improvements: 5.2% in Scene Text-Centric tasks (including STVQA, TextVQA, and OCRVQA), 6.9% in Document-Oriented tasks (such as DocVQA, InfoVQA, ChartVQA, DeepForm, Kleister Charity, and WikiTableQuestions), and 2.8% in Key Information Extraction tasks (comprising FUNSD, SROIE, and POIE). It outperforms in scene text spotting with a 10.9 % increase and sets a new standard on OCRBench, a comprehensive benchmark consisting of 29 OCR-related assessments, with a score of 561, surpassing previous open-sourced large multimodal models for document understanding. Code will be released at https://github.com/Yuliang-Liu/Monkey.
Show Paper Content
key information from a variety of sources, including documents like
tables, forms, and invoices, as well as text in the wild is crucial for
industries and academic research, aiming to automate and refine
document-based and scene-text workflows. This field requires text
detection and recognition in both document images and real-world scenes,
language comprehension, and the integration of vision and language.
Many early methods `\cite{tang2023udop,huang2020layoutlmv3}`{=latex}
attempt to address the task using a two-stage approach: 1) Detect and
recognize the text using external systems; 2) Document understanding
based on the fusion of text results and images. However, the individual
step of text reading in the processing pipeline may lead to the
accumulation of errors. Moreover, relying on off-the-shelf OCR
Models/APIs (OCR-Models) introduces additional engineering complexity,
limits the connection between the text and its surrounding context, and
can potentially increase computational costs. To alleviate the drawbacks
of external systems before understanding, OCR-Free
solutions `\cite{kim2022donut,lee2023pix2struct}`{=latex} have attracted
increasing attention recently.
Comparisons to the existing pipelines for document
understanding. Compared to (a) Resize based methods, (b) Crop based
methods, and (c) frequency based methods, our model can efficiently
process high-resolution text-related images with various tasks.
The field of large multimodal models
(LMMs) `\cite{liu2023llava,zhu2023minigpt4}`{=latex} is advancing
rapidly due to its powerful ability to handle diverse types of data.
However, they still have limitations when it comes to addressing
text-related tasks. As depicted in
Fig. 1 (a), several methods, including
LLaVAR `\cite{zhang2023llavar}`{=latex},
UniDoc `\cite{feng2023unidoc}`{=latex},
TGDoc `\cite{wang2023TGDoc}`{=latex}, and
mPLUG-DocOwl `\cite{ye2023mplug-docowl}`{=latex} heavily rely on a
pre-trained CLIP `\cite{radford2021clip}`{=latex} for visual encoding.
Nevertheless, these encoders have input resolutions of 224 or 336, which
are insufficient to meet the demands of documents containing numerous
small texts `\cite{liu2023hidden}`{=latex}. Therefore, they can only
recognize large text and struggle with small text in images. To address
the limitations of tiny text, UReaer `\cite{ye2023UReader}`{=latex} and
Monkey `\cite{li2023monkey}`{=latex} take a cropping strategy to expand
the input resolution, as shown in
Fig. 1 (b). However, this crop strategy may
inadvertently split related words, resulting in semantic incoherence.
For example, the word "Backup" may be divided into "Back" and "up,"
making it impossible to restore its original meaning even after fusion
has been performed. Besides, the spatial separation caused by this
splitting also makes it challenging to handle text position-related
tasks, such as text grounding. As shown in
Fig. 1 (c),
DocPedia `\cite{feng2023docpedia}`{=latex} directly processes visual
input in the frequency domain rather than the pixel space. Due to the
characteristics of the frequency domain, it can quickly expand the
resolution without losing information. However, due to the
transformation of the feature space, it is difficult to leverage
existing pretrained models, increasing the demand for training
resources.
We want to inherit the efficient image resolution scaling feature of
Monkey `\cite{li2023monkey}`{=latex} but address the missing
cross-window context for the documents mentioned above. For this
purpose, we introduce TextMonkey, as shown in
Fig. 1 (d). TextMonkey utilizes a Split Module
that divides high-resolution images into window patches using a sliding
window method. Inspired by `\cite{liu2021swin}`{=latex}, we treat every
self-attention layer in the CLIP as self-attention in non-overlapped
windows. To introduce cross-window relationships while maintaining
efficient computation, we use Shifted Window Attention with
zero-initialization to build cross-window connections. This approach
allows us to maintain the training data distribution for the encoder and
deal with high-resolution document images while reducing the
computational cost of training from scratch. On the other hand, the
utilization of the Split Module still poses a significant challenge as
it leads to a notable increase in token length. We have observed that
there are numerous repetitive image features that align with the
language space, similar to certain repeated elements in the language
itself. Thus, we propose a token resampler to compress these features
while keeping as many of the most important features as possible. We
employ important tokens as queries and the original features as
key-value pairs, facilitating the reaggregation of features. On the
basis of reducing the number of tokens, our module can also
significantly improve the performance compared to random queries.
On the other hand, due to the self-explanatory nature of the text, in
most cases, humans are able to locate the position of the answer itself.
To alleviate the issue of hallucination in large language models
further, we require the model not only to provide accurate answers but
also to locate specific visual evidence supporting its response. We also
introduce a variety of text-related tasks to deepen the connection
between text information and visual information, such as text spotting
and text grounding. Besides, incorporating positional cues into the
answers can further enhance the model’s reliability and
interpretability.
We summarize the advantages of our method as follows:
- **Enhancing cross-window relations**. We adopt Shfited Window
Attention to successfully incorporate cross-window connectivity
while expanding the input resolutions. Besides, we introduce zero
initialization in the Shifted Window Attention mechanism, enabling
the model to avoid drastic modifications to early training.
- **Token compression**. We show enlarging resolution results in some
redundant tokens. By using similarity as a criterion, we are able to
find significant tokens that serve as queries for the token
resampler. This module not only reduces the token length but also
improves the model’s performance. Additionally, it significantly
improves the performance compared to the use of random queries.
- **Support text grounding**. We expand our scope to include tasks
beyond text-based question answering, encompassing reading text,
text spotting, and text grounding. Additionally, we found that
incorporating positional information into the answers can improve
the model’s interpretability. TextMonkey can also be finetuned to
understand the command of screen-shot clicking.
- We evaluated TextMonkey’s performance across 12 recognized
benchmarks, observing significant improvements in several areas.
Firstly, in scene text-centric tasks such as STVQA, TextVQA, and
OCRVQA, TextMonkey achieved a 5.2% increase in performance. For
document-oriented tasks, including DocVQA, InfoVQA, ChartVQA,
DeepForm, Kleister Charity, and WikiTableQuestions, it showed a 6.9%
improvement. In the domain of key information extraction tasks, like
FUNSD, SROIE, and POIE, we noted a 2.8% uplift. Particularly notable
was its performance in scene text spotting tasks (Total-Text,
CTW1500, and ICDAR 2015) focused on transcription accuracy, where it
improved by 10.9%. Additionally, TextMonkey set a new high score of
561 on OCRBench, a comprehensive benchmark encompassing 29
OCR-related evaluations, significantly surpassing the performance of
previous open-source, large-scale multimodal models designed for
document understanding. This achievement underscores TextMonkey’s
effectiveness and advances in the field of document analysis and
understanding.
# Related works [sec:rela]
Models designed to comprehend images with text information can be
broadly categorized into two types: OCR-Model-Driven and OCR-Free
methods.
## OCR-Model-Driven Methods
OCR-Model-Driven methods use OCR tools to acquire text and bounding box
information. Subsequently, they rely on the models to integrate text,
layout, and visual data. Meanwhile, diverse pre-training tasks are
devised to enhance cross-modal alignment between visual and text inputs.
StrucTexT `\cite{li2021structext}`{=latex} pays attention to the
fine-grained semantic information and global layout information within
the image in the design of pre-training tasks. Based on layout knowledge
enhancement technology, ERNIE-Layout `\cite{peng2022ernie}`{=latex}
innovatively proposes two self-supervised pre-training tasks: reading
order prediction and fine-grained image-text matching. The
LayoutLM `\cite{xu2020layoutlm,xu2020layoutlmv2,huang2020layoutlmv3}`{=latex}
series continuously improves by integrating pre-trained text, layout,
and visual features and introducing a unified model architecture and
pre-training goals. This enhances the model’s performance in various
document understanding tasks and simplifies overall design.
UDOP `\cite{tang2023udop}`{=latex} unifies vision, text, and layout
through VTL Transformer and a unified generative pre-training task.
Wukong-reader `\cite{bai2023wukong-reader}`{=latex} proposes the
Textline-Region Contrastive Learning and specially crafted pre-training
tasks to extract fine-grained text line information.
DocFormerv2 `\cite{appalaraju2023docformerv2}`{=latex} designs an
asymmetric pre-training method and a simplified visual branch for visual
document understanding. DocLLM `\cite{wang2023docllm}`{=latex} focuses
exclusively on position information to incorporate the spatial layout
structure, using a decomposed attention mechanism to build a
cross-alignment between text and spatial modalities.
While advancements have been achieved, OCR-Model-Driven methods depend
on text extraction from external systems, which necessitates increased
computational resources and extends processing durations. Additionally,
these models may inherit OCR inaccuracies, presenting challenges to
document understanding and analysis tasks.
## OCR-Free Methods
OCR-Free methods do not require off-the-shelf OCR engines/APIs.
Donut `\cite{kim2022donut}`{=latex} first proposes an end-to-end
training method based on a Transformer without OCR.
Dessurt `\cite{davis2022dessurt}`{=latex}, based on an architecture
similar to Donut, incorporates two-way cross-attention and employs
distinct pre-training methods.
Pix2Struct `\cite{lee2023pix2struct}`{=latex} is pre-trained by learning
to parse masked screenshots of web pages into simplified HTML,
introducing a variable-resolution input representation and a more
flexible way to integrate language and visual input.
StrucTexTv2 `\cite{yu2021structextv2}`{=latex} introduces a novel
self-supervised pre-training framework, employing text region-level
document image masking to learn end-to-end visual-textual
representations.
Although these methods do not require OCR tool limitations, they still
need fine-tuning for specific tasks. In the fast-growing era of
Multi-Modal Large Language Models (MLLMs), some models are explicitly
trained on visual text understanding datasets and fine-tuned with
instructions. LLaVAR `\cite{zhang2023llavar}`{=latex},
mPLUG-DocOwl `\cite{ye2023mplug-docowl}`{=latex} and
UniDoc `\cite{feng2023unidoc}`{=latex} create novel
instruction-following datasets to enhance the tuning process and improve
the comprehension of text-rich images. Additional efforts have been
undertaken to capture more intricate textual details.
UReader `\cite{ye2023UReader}`{=latex} designs a shape-adaptive cropping
module that utilizes a frozen low-resolution visual encoder to process
high-resolution images. DocPedia `\cite{feng2023docpedia}`{=latex}
processes visual input in the frequency domain rather than pixel space
to process higher-resolution images with limited visual tokens. By
training a visual vocabulary on a large amount of data,
Vary `\cite{wei2023vary}`{=latex} expands its resolution and achieves
impressive results. Recently, TGDoc `\cite{wang2023TGDoc}`{=latex} uses
text-grounding to enhance document understanding, suggesting that
textual grounding can improve the model’s ability to interpret textual
content, thereby enhancing its understanding of images rich in textual
information.
# Methodology [sec:method]
The method presented in
Fig. [fig:method] begins by dividing the
input image into non-overlapping patches using a sliding window module,
with each patch sized at 448x448 pixels. These patches are further
subdivided into smaller patches of 14x14 pixels, each considered as a
token. Utilizing Transformer blocks that inherit from the pre-trained
CLIP model, we process these tokens on each window patch separately. To
establish connections among various window patches, Shifted Window
Attention is integrated at specific intervals within the Transformer
blocks. To generate a hierarchical representation, the input image is
resized to 448x448 and fed into CLIP to extract a global feature, as
suggested by `\cite{li2023monkey}`{=latex}. This global feature,
alongside features from sub-images, is then processed by a shared image
resampler to align with the language domain. Then, a Token Resampler is
employed to further minimize redundancy in the language space by
compressing the length of tokens. Ultimately, these processed features,
combined with the input question, are analyzed by a Large Language Model
(LLM) to produce the required answers.
## Shifted Window Attention
Previous studies have underscored the significance of input resolution
for precise document understanding
`\cite{feng2023docpedia,liu2023hidden}`{=latex}. To enhance training
efficiency, recent methods `\cite{li2023monkey,ye2023UReader}`{=latex}
have adopted a sliding window technique to enhance image resolution.
While effective in analyzing natural scenes due to their localized
content, this strategy may lead to the fragmentation of connected text
in document analysis, disrupting semantic continuity. Additionally, the
spatial disjunction poses challenges for tasks that rely on text
positioning, such as text grounding.
To alleviate the issue mentioned above, we adopt Shifted Window
Attention `\cite{liu2021swin}`{=latex} to augment the CLIP model’s
visual processing capabilities. Specifically, for an input image
$I \in \mathbb{R}^{H\times W \times 3}$, our approach slices the image
into non-overlapping windows. This slice is achieved using a sliding
window $W \in \mathbb{R}^{H_v\times W_v}$, where $H_v$ and $W_v$
indicate the window’s size. Within each window, we independently apply a
transformer block from the CLIP architecture, which initially does not
account for cross-window relationships. To incorporate interactions
between different windows and enhance the model’s contextual
understanding of the image, we adopt the Shifted Window Attention (SWA)
mechanism. As mentioned in `\cite{liu2021swin}`{=latex}, the sliding
window is cyclic-shifting toward the top-left direction, resulting in
new windows. The self-attention computation by a masking mechanism,
which limits self-attention computation to within new windows.
To achieve smoother training initialization, we have made modifications
to the shifted window attention by allowing them to start learning from
zero initialization, avoiding excessive transformation of early features
during the initial stages. In particular, we modify the regular
initialization in MLP to zero initialization to achieve smoother
training, inspired by `\cite{hu2021lora}`{=latex}:
$$x = \textbf{BA}\hat{x},$$ where **B** and **A** refer to the weight of
two linear layers. We use a random Gaussian initialization for **A** and
zero initialization for **B**. This approach ensures that the image
encoder’s parameters remain stable in the initial phase, facilitating a
smoother training experience.
Image token similarity comparisons. We randomly select 20
ordered tokens from image tokens and use cosine similarity as the metric
for measuring similarity.
## Image Resampler
To reduce the redundancy in image features initially, we inherited the
image resampler from Qwen-VL `\cite{bai2023qwen-vl}`{=latex}, which is
using upon every window. The module employs a set of trainable
parameters as query vectors and utilizes the image features from the
visual encoder as keys and values for cross-attention operations. This
process helps compress the visual feature sequence to a fixed length of
256. Furthermore, to preserve positional information crucial for
fine-grained image comprehension, 2D absolute positional encodings are
integrated into the query-key pairs of the cross-attention mechanism.
## Token Resampler
As the resolution increases, the number of tokens also significantly
increases, using the slide window mechanism. However, due to limitations
in the input length of some language models and training time
constraints, reducing the number of tokens becomes necessary. In common
visual scenarios, the previous method `\cite{bolya2022token}`{=latex}
has demonstrated the feasibility of merging token approaches.
For natural language, redundant information could be repeated linguistic
elements. Assuming that by expanding the resolution of the image,
redundant visual information will exist. When determining the similarity
between two linguistic elements, we often measure their embeddings’
similarity. To assess the redundancy of image features, we measure the
similarity of image tokens already mapped to the language space. We
randomly select 20 ordered features after the image resampler and
compare pairwise similarities using cosine similarity, as shown in
Fig. 2. Through the comparison of image tokens’
similarity, we can observe a pattern where many image tokens exhibit
multiple similar tokens. Furthermore, we quantitatively compared the
redundancy of tokens at different resolutions, as shown in
Fig. 3. Empirically, we selected a threshold
value of 0.8 as the similarity threshold, At resolutions of 448, 896,
and 1334, we observed 68/256 (26.6%), 571/1024 (55.8%), and 1373/2304
(59.5%) redundant tokens, respectively. As presented in
Fig. 3, with an increase in resolution, there is
a higher occurrence of repeated tokens. This validates our hypothesis
that while expanding the resolution can achieve clearer visibility, it
also introduces some redundant features.
Quantitative analysis on specific redundant tokens. Using
the maximum cosine similarity between each token and other tokens as a
criterion for identifying redundant tokens, we plotted the threshold on
the x-axis and the number of redundant tokens at different resolutions
on the y-axis.
However, how can we identify important tokens and eliminate redundant
ones? We have observed that certain tokens are highly unique and lack
closely similar counterparts, such as the fifth token in
Fig. 2. This suggests that this token is
distinct. We hypothesize that these tokens carry crucial and distinctive
information, which is further validated in subsequent experiments.
Therefore, we utilize similarity as a metric to identify significant
tokens.
Hence, we propose a Token Resampler to compress redundant tokens, as
shown in the left part of
Fig. [fig:method]. As shown in Algor.
[algor:1], we utilize a token filter
algorithm to select the most valuable tokens.
tokens $\in \mathbb{R}^{L \times D}$, r (remain token numbers)
CMX (calculate max similarity) importances = \[\]
for token in tokens:
max_similarity = CMX(token, other_tokens)
importances.append(1-max_similarity)
top_tokens = select_top_tokens(tokens, importances, r)
sorted_tokens = sort_by_original_order(top_tokens)
Return sorted_tokens.
To avoid information loss caused by directly discarding other tokens, we
utilize important tokens as queries and employ cross-attention to
further aggregate all the features. Based on the reduction of the token
count, our module can also significantly improve the performance
compared to random queries.
## Position-Related Task
To alleviate the issue of hallucinations in Large Language Models
(LLMs), where they can produce incorrect responses not related to the
provided image, we aim to enhance their capability to analyze and
incorporate visual information into their replies. Considering that
answers to text-based tasks are often found within the image itself, we
anticipate that the large model will not only produce precise responses
but also identify the particular visual proof that underpins its answer.
Moreover, we have undertaken modifications to existing
question-answering datasets. Specifically, we have found the positions
with the majority of answers in the images. These positional cues have
been extracted and seamlessly integrated into the answers themselves. To
preserve the original capability of direct dialogue, we have also
retained the original question-answering task.
For better perception of the spatial positions of the text, it requires
the model to have a strong spatial understanding. Building upon the
aforementioned model designs, we add additional training tasks to
improve the model’s perception of text positions, such as text spotting
and reading text. Specific tasks and prompts are shown in
Tab. 1. To guarantee a strong connection
between text and location data, we strictly maintain their alignment,
ensuring that text information always comes before any associated
location details.
To standardize images of different ratios, we use a scale of (0, 1000)
to represent positional information. Therefore, in an image with
resolutions of ($H_r\times W_r$), the text coordinates (x, y) will be
normalized to $[ (x/H_r*1000)]$, and the same applies to y. The
restoration process involves the inverse operation.
| Type | Prompt |
|:----------------:|:--------------------------------------------:|
| Read All Text | Read all the text in the image. |
| Text Spotting | OCR with grounding: |
| Original Tasks | {Question}. Answer: |
| Position of text | \text\ |
| Text Recognition | \This\ |
| | \(x1,y1),(x2,y2)\is |
| VQA Grounding | {Question}. Provide the location coordinates |
| | of the answer when answering the question. |
Prompts for a variety of tasks.
## Dataset Construction [subsec:dc]
During our training process, we solely utilize open-source data and
apply various task-specific augmentations to different datasets. By
integrating various datasets and employing different instructions for
different tasks, we enhance the model’s learning ability and training
efficiency. For scene text scenario, we select
COCOText `\cite{veit2016cocotext}`{=latex},
TextOCR `\cite{singh2021textocr}`{=latex},
HierText `\cite{long2022towards}`{=latex},
TextVQA `\cite{singh2019towards}`{=latex}, and
MLT `\cite{nayef2019icdar2019}`{=latex} for training. For document
images, we select IIT-CDIP `\cite{lewis2006building}`{=latex},
DocVQA `\cite{mathew2021docvqa}`{=latex},
ChartQA `\cite{masry2022chartqa}`{=latex},
InfoVQA `\cite{infovqa}`{=latex}, DeepForm `\cite{deepform}`{=latex},
Kleister Charity (KLC) `\cite{stanislawek2021kleister}`{=latex}, and
WikiTableQuestions (WTQ) `\cite{pasupat2015compositional}`{=latex}. To
accelerate the training speed, we have transformed single-image question
answering into multi-turn image-based question answering, significantly
improving the utilization of image features, following the successful
approach introduced in LLaVA `\cite{liu2023llava}`{=latex}. The details
of our training data are shown in
Tab. 2. We have a total of 409.1k pairs of
dialogue data and 2.1M question-answering pairs in our dataset to train
our model.
To further strengthen the model’s ability to handle structured text, we
fine-tune one epoch on TextMonkey with structured data to enhance its
structured capabilities, resulting in TextMonkey. The fine-tuning data
primarily consisted of 5% of the data from the previous stage, as well
as a portion of structured data, including documents, tables, and
charts. The structured data images are also sourced from publicly
available datasets and are generated using their structure information.
Therefore, we have a total of 55.7k of data in structured data.
## Loss
Since TextMonkey is trained to predict the next tokens like other LLMs,
it only requires maximizing the likelihood of loss at training time.
$$\label{eq_objective}
\mathcal{L} = {\rm max} \sum_{i=1}^{L} \log
P(\tilde{{{\bf s}}}_i | {{\bf I}},{{\bf Q}}, {{\bf s}}_{1:i}),$$
where $\textbf{I}$ is the input image, $\textbf{Q}$ is the question
sequence, $\tilde{\textbf{s}}$ is the output sequence, $\textbf{s}$ is
the input sequence, $L$ is the length of the output sequence.
# Experiments [sec:experiments]
## Implementation Details
**Model Configuration.** In our experiments, we utilized the
well-trained Vit-BigG and LLM from
Qwen-VL `\cite{bai2023qwen-vl}`{=latex}, which is a pre-trained large
multimodal model. We configured the height and width ($H_v$, $W_v$) of
the image inputs to 448 to align with the encoder specifications of
Qwen-VL. Our image resampler is equipped with 256 learnable queries, and
the token resampler’s ratio (r) was set to 512 for images with a
resolution of 896 and increased to 1024 for images with a resolution of
1344. To maximize training efficiency, our primary experimental focus
was on using TextMonkey and evaluating outcomes at the 896 resolution
setting.
TextMonkey consists of a large language model with 7.7B parameters, an
image resampler module with 90M parameters, a token resampler module
with 13M, an encoder with 1.9B parameters, and Shifted Window Attention
with 45M parameters. Overall, TextMonkey has a total of 9.7B parameters.
**Training.** During the training phase, we utilized the
AdamW `\cite{adamw}`{=latex} optimizer, setting the learning rate to
1e-5 for the initial stage and reducing it to 5e-6 for the subsequent
stage, while adopting a cosine learning rate schedule. The parameters
$\beta_1$ and $\beta_2$ were configured to 0.9 and 0.95, respectively. A
warmup period comprising 150 steps was incorporated, and we processed
the data in batches of 128. To mitigate the risk of overfitting, we
applied a weight decay factor of 0.1. The comprehensive training
procedure spanned across 12 A800 days to complete one epoch.
**Evaluation.** To facilitate a more equitable comparison with other
approaches, we adopted the accuracy metric, where a response produced by
our model is considered correct if it encompasses the ground truth. The
selection of test datasets and the formulation of evaluation criteria
were carried out in accordance with the methodology described
in `\cite{liu2023hidden}`{=latex}. To ensure an even fairer comparison
with other methods, we also performed supplementary evaluations on
certain datasets utilizing their original metrics, such as F1 score and
ANLS (Average Normalized Levenshtein Similarity).
## Results
**OCRBench Results.** We conduct a comparative analysis of our approach
with recent large multimodal models. For our evaluation, we utilize
three Scene Text-Centric VQA datasets: STVQA `\cite{STVQA}`{=latex},
TextVQA `\cite{singh2019towards}`{=latex}, and
OCRVQA `\cite{mishra2019ocr}`{=latex}; three Document-Oriented VQA
datasets: DocVQA `\cite{mathew2021docvqa}`{=latex},
InfoVQA `\cite{infovqa}`{=latex}, and
ChartQA `\cite{masry2022chartqa}`{=latex}; and three Key Information
Extraction (KIE) datasets: FUNSD `\cite{FUNSD}`{=latex},
SROIE `\cite{SROIE}`{=latex}, and POIE `\cite{kuang2023visual}`{=latex}.
For a comprehensive assessment of performance, our evaluation includes
OCRBench `\cite{liu2023hidden}`{=latex}, a recent benchmark specifically
developed to evaluate the Optical Character Recognition (OCR)
capabilities of Large Multimodal Models. OCRBench spans a wide range of
text-related visual tasks, encompassing 29 datasets, and is designed to
generate an overall score.
As shown in Tab. [tab:result], our model demonstrates
superior performance compared to existing large multimodal models,
particularly in scenarios where the text is dense and small. Our method
inherently enhances many current evaluation datasets, resulting in
average performance improvements with numerous baseline methods by 5.2%,
6.9%, and 2.8% for Scene Text-Centric VQA, Document Oriented VQA and
KIE, respectively. TextMonkey can achieve 64.3% on DocVQA and 58.2% on
ChartQA. Specifically, our model achieved a score of 561 on OCRBench.
The performance on both two challenging downstream tasks and OCRBench
demonstrates its effectiveness in text-related tasks. We have found that
our model tends to provide numerical answers without units, which
results in a performance decrease on POIE.
| | | | | | | |
|:--:|:--:|:--:|:--:|:--:|:--:|:--:|
| Method | Total-Text `\cite{ch2017total}`{=latex} | | CTW1500 `\cite{liu2019curved}`{=latex} | | ICDAR 2015 `\cite{karatzas2015icdar}`{=latex} | |
| | Trans | Pos | Trans | Pos | Trans | Pos |
| TOSS `\cite{tang2022you}`{=latex} | 61.5 | 65.1 | 51.4 | 54.2 | 47.1 | 52.4 |
| TTS `\cite{kittenplon2022towards}`{=latex} | \- | 75.1 | \- | \- | \- | 70.1 |
| SPTS v2 `\cite{liu2023spts}`{=latex} | 64.7 | **75.5** | 55.4 | 63.6 | 55.6 | **72.6** |
| TextMonkey | **78.2** | 61.4 | **63.2** | 57.5 | **66.9** | 45.1 |
Quantitative accuracy of text spotting. The “Total-Text” and “CTW1500”
datasets do not use a specific vocabulary for evaluation, while the
“ICDAR 2015” dataset uses a general vocabulary for evaluation of other
models. Note TTS only uses synthetic location data. TextMonkey is not
fine-tuned by the downstream text spotting datasets without any
vocabulary.
**Document Benchmarks results.** To further compare and assess the
capabilities of our method, we conduct tests on additional datasets
utilizing the specific evaluation metric provided in their paper:
F1-score for Deepform and KLC, accuracy for WTQ, relaxed accuracy
measure for ChartQA, ANLS for DocVQA, and VQA score for TextVQA.
The results, shown in Tab. 3, indicate that our model leads in
performance on these datasets, outperforming other models. Across
different domains, TextMonkey achieves a score of 71.5 in DocVQA, 30.6
in WTQ, 65.5 in ChartQA and 68.0 in TextVQA. It shows our model’s
capability to handle documents, tables, charts, and scene text.
**Text spotting results.** To show the extensive capabilities of our
model, we assessed its performance on text spotting datasets without
finetuning, as detailed in
Tab. 4. Given our model’s focus on identifying
complete text passages, we segmented the predicted content into
individual words for analysis. We employed two evaluation methodologies
to evaluate our model’s performance. In the “Trans” mode, text is
considered correct if the answer contains this word. Conversely, the
“Pos” mode requires the consideration of positional information in
accordance with previous methods `\cite{liu2021abcnetv2}`{=latex}. For
both metrics, due to granularity issues of the output (TextMonkey often
produces an integrated paragraph while others only produce desired
words), the metric can not strictly follow the evaluation setup;
however, both should be quite similar, as both the error and correct
situations match in calculations.
To maintain TextMonkey’s consistent performance, we refrained from
fine-tuning it with downstream text spotting data, unlike other methods
that were optimized for either the “Trans” or “Pos” metrics. Our results
reveal that, for the “Trans” metric, TextMonkey outperformed SPTS v2 by
a margin of 10.9%. Regarding the “Pos” metric, it demonstrated competent
text spotting capabilities, showing its ability in understanding both
text content and spatial positioning.
## Visualization
We conduct a qualitative evaluation of TextMonkey across various
scenarios, including natural scenes and document images. As shown in the
left part of Fig. [fig:show], TextMonkey accurately locates
and identifies text in both scene and document images. Besides, natural
images in Fig. [fig:show] (a), documents in
Fig. [fig:show] (b), charts in
Fig. [fig:show] (c), and tables in
Fig. [fig:show] (d) exemplify TextMonkey’s
adeptness at discerning and interpreting visual and textual information
within a wide range of scenarios. Overall, TextMonkey’s performance
across diverse scenarios demonstrates its effectiveness in perceiving
and comprehending textual information in various visual contexts.
| Zero Initialization | SROIE | DocVQA | TextVQA | ChartVQA |
|:-------------------:|:--------:|:--------:|:--------:|:--------:|
| $\times$ | 46.8 | 64.1 | 65.7 | 57.6 |
| $\checkmark$ | **47.0** | **64.3** | **65.9** | **58.2** |
Ablation study on zero initialization.
## Ablation Study
**Ablation study on zero initialization.** Since CLIP is already
pretrained, it is advisable to avoid drastic changes in features during
the early training stages. As shown in
Tab. 5, incorporating this zero initialization
method can yield 0.6% performance gain on ChartQA.
**Ablation study on different components.** As shown in
Tab. 6, by introducing cross-window
connections, we achieved an improvement of 0.1% on SROIE, 1.5% on
DocVQA, and 2.4% on TextVQA. It can be observed that cross-window
connections partially compensate for the discontinuity caused by
chunking and contribute to a better understanding of the images. Based
on the Token Resampler, our method demonstrates better performance,
achieving 1.0%, 0.2%, and 1.1% performance gain on the SROIE, DocVQA,
and TextVQA. This suggests that our approach effectively preserves
essential information while eliminating redundant tokens, thereby
simplifying the learning process for the model.
**Ablation study on strategies of reducing token length.** As
demonstrated in Tab. 7, substituting important tokens with
random ones (without token filter) leads to an average decline in
performance by roughly 12.7%. This decline is attributed to the
increased complexity of optimizing random queries, which necessitates
more datasets to achieve a generalized representation compared to
utilizing significant tokens. Solely focusing on pivotal features
(without resampler) and directly eliminating features incurs a loss of
some information, showing a decrease in performance, such as a 2.1% drop
in SROIE. Additionally, neglecting the order of tokens (with unsorted
token filter) does not markedly impair performance, owing to the
language model’s inherent ability to organize unordered tokens.
Nevertheless, the lack of token order can still lead to decrease,
especially evident in the result of DocVQA, with a 2.2% decrease in
performance.
**Interaction between input resolution and the number of tokens
remained.** As shown in
Tab. 8, Directly increasing the resolution
without compressing tokens can actually lead to consistent worse
performance, especially with a decrease of 9.2% performance in DocVQA.
We speculate that the increase in resolution results in a significant
increase in redundant tokens, making it more difficult to find crucial
information in our setting. Therefore, compressing tokens reasonably can
lead to higher performance. Considering the sparsity of information in
large-sized images, it is also necessary to consider selecting an
appropriate value of “r” for different input resolutions. Besides,
increasing the input resolution brings benefits to the dataset, which
contains many large-sized images, with 0.2% performance gain for DocVQA
and 3.2% performance gain for InfoVQA. However, for datasets like
TextVQA and SROIE, which contain much smaller images, increasing the
input resolution directly does not yield any gains.
| Resolution | r | SROIE | DocVQA | TextVQA | InfoVQA |
|:----------:|:----:|:--------:|:--------:|:--------:|:--------:|
| 896 | \- | 46.0 | 64.1 | 64.8 | 29.1 |
| 896 | 256 | **47.0** | 60.9 | 65.2 | 25.9 |
| 896 | 512 | **47.0** | 64.3 | **65.9** | 28.2 |
| 1344 | \- | 42.9 | 54.9 | 62.5 | 28.9 |
| 1344 | 512 | 44.9 | 59.7 | 64.2 | 28.0 |
| 1344 | 1024 | 46.0 | **64.5** | 65.1 | **31.4** |
Interaction between resolution and the number of tokens remained “r”.
“-” in “r” means do not use token resampler and keep all the remaining
tokens.
## Structuralization
The structuralization of charts and tables holds substantial practical
value. Structured charts and tables present data in a clear format, and
by extracting structural information from images, computers can
accurately parse and extract the data. This makes data analysis,
statistics, and modeling more efficient and precise. It also helps
reduce the complexity of information and improves its comprehensibility.
As depicted in Fig. 4, our model is capable of structuring
charts and tables into JSON format, demonstrating its potential for
downstream applications. According to
Tab. 3, TextMonkey exhibits a performance
improvement of 1.3% and 1.4% on tables and charts, respectively. This
underscores that high-quality data not only enables the model’s
structuralization capabilities but also amplifies the effectiveness of
the related benchmarks. However, it is worth noting that this type of
data will primarily benefit the data within its own domain, thus leading
to a performance decrease for cross-domain TextVQA.
## App Agent
Recently, there has been a lot of attention on using LMMs for the task
of acting as agents for smartphone applications
`\cite{yang2023appagent,wang2024mobile,niu2024screenagent}`{=latex}.
Unlike existing intelligent phone assistants like Siri, which operate
through system back-end access and function calls, this agent interacts
with smartphone applications in a human-like manner, using low-level
operations such as clicking and swiping on the graphical user interface
(GUI). It eliminates the need for system back-end access, enhancing
security and privacy as the agent does not require deep system
integration. The GUI primarily consists of icons and text, and we
explore the feasibility of TextMonkey on this aspect. We transformed 15k
user click data from the Rico `\cite{deka2017rico}`{=latex} dataset and
performed downstream fine-tuning using TextMonkey. As qualitatively
shown in Fig. [fig:agent], our model is able to
understand user intent and click on the corresponding icons, which
suggests the potential of the model to serve as an app agent by using
downstream data.
| Method | DocVQA | SROIE | ChartQA | InfoVQA |
|:-------------|:--------:|:--------:|:--------:|:--------:|
| w position | **64.5** | **47.2** | 57.8 | 27.7 |
| w/o position | 64.3 | 47.0 | **58.2** | **28.2** |
Effect of incorporating the position of answer
# Discussion
## Interpretability
By examining the grounding information, we can identify the reasons
behind the model’s errors, enhancing a better understanding of the
model’s behavior. As shown in
Fig. 5 (a), we ground to the white region,
indicating that the model might be engaging in hallucination. We
correctly identify the location but recognize it wrongly in
Fig. 5 (b).
Fig. 5 (c) highlights a scenario where the model
grounds to incorrect text but still provides the correct answer. This
could imply that there is some level of randomness or uncertainty in the
model’s responses at this point. In
Fig. 5 (d), the alignment between the position
and text indicates that the model is more confident in its predictions.
Therefore, based on these analyses, we can gain a better understanding
of the model’s behavior and have a better awareness of the model’s
hallucination, thus reducing the model’s hallucination.
## Chain-of-Thought
We also conduct experiments on several datasets and observe inconsistent
improvements if we require a model to provide the answer’s position, as
shown in Tab. 9. In datasets where the majority of
answers are based on information within the images, such as DocVQA and
SROIE, there is a noticeable benefit in requiring the model to provide
the answer’s position. However, for datasets that involve reasoning
tasks, such as ChartQA and InfoVQA, where questions require comparisons
or quantitative analysis (e.g., "How much more is A than B?"), demanding
positional answers can actually result in a detrimental effect. Upon
further examination of the wrong answer, we consider that the
requirement of grounding might have partially affected certain reasoning
needs. Hence, it is essential to consider the nature of the dataset and
the type of questions being asked when deciding whether to impose the
requirement of positional answers.
Additionally, we believe that automating the process of constructing a
thinking chain `\cite{wei2022chain}`{=latex} in subsequent steps could
be a promising direction for future research. By developing mechanisms
to generate a coherent chain of reasoning automatically, we can
potentially enhance the overall performance and reasoning capabilities
of our models.
## Comparison Between Different Representations of Position
Recently, some methods `\cite{liu2023spts}`{=latex} have used points to
represent positions instead of rectangles and polygons. Firstly,
intuitively, the cost of generating points during inference would be
lower compared to generating rectangles and polygons, as generating Nx
points is required for other forms of bounding boxes. We aim to further
investigate and experimentally validate which form is more suitable for
LMMs to learn. To maintain strict consistency in our experiments, we
only applied transformations to the data while keeping the other
training hyperparameters the same. For the points, we selected the
center points of the bounding boxes that were the most meaningful.
As demonstrated in Table 10, employing points as visual cues
significantly enhances performance over rectangles. In the case of
Docvqa, there was an improvement of 0.7%, while for SROIE, the
enhancement reached 0.9%. Furthermore, rectangles often surpass polygons
in performance. This might be attributed to the previously discussed
issue that redundant image tokens could increase the complexity of the
model’s learning process. Similarly, extensive position representations
might face comparable obstacles. Given these considerations, along with
the associated inference costs, utilizing points as representations can
be a viable strategy for appropriate tasks.
# Conclusion
This paper introduces TextMonkey to address the challenges associated
with text-heavy tasks such as document question answering and
fine-grained text analysis. We adopt Shifted Window Attention with zero
initialization to help establish relationships while increasing input
resolutions using a sliding window. Increasing the resolution
simultaneously increases the number of tokens. Through analyzing the
redundancy of tokens, our proposed Token Resampler effectively reduces
the number of tokens. Furthermore, by engaging in multiple text-oriented
tasks simultaneously, TextMonkey enhances its perception and
understanding of spatial relationships, leading to improved
interpretability and support for clicking screen-shots. By comparing our
model with various LMMs, our model achieved excellent results on
multiple benchmarks. It is worth mentioning that we also find that
directly increasing the input resolution does not always lead to
improvements, particularly for much smaller images. This underscores the
necessity of creating an efficient method for scaling resolution in
documents where size changes can be dramatic.
[^1]: Y. Liu and B. Yang contributed Equally. Corresponding author: X.
Bai.
Feast Your Eyes: Mixture-of-Resolution Adaptation for Multimodal Large Language Models
2024-03-05
Gen Luo, Yiyi Zhou, Yuxin Zhang, Xiawu Zheng, Xiaoshuai Sun, Rongrong Ji
Despite remarkable progress, existing multimodal large language models (MLLMs) are still inferior in granular visual recognition. Contrary to previous works, we study this problem from the perspective of image resolution, and reveal that a combination of low- and high-resolution visual features can effectively mitigate this shortcoming. Based on this observation, we propose a novel and efficient method for MLLMs, termed Mixture-of-Resolution Adaptation (MRA). In particular, MRA adopts two visual pathways for images with different resolutions, where high-resolution visual information is embedded into the low-resolution pathway via the novel mixture-of-resolution adapters (MR-Adapters). This design also greatly reduces the input sequence length of MLLMs. To validate MRA, we apply it to a recent MLLM called LLaVA, and term the new model LLaVA-HR. We conduct extensive experiments on 11 vision-language (VL) tasks, which show that LLaVA-HR outperforms existing MLLMs on 8 VL tasks, e.g., +9.4% on TextVQA. More importantly, both training and inference of LLaVA-HR remain efficient with MRA, e.g., 20 training hours and 3$ times$ inference speed than LLaVA-1.5. Source codes are released at: https://github.com/luogen1996/LLaVA-HR.
Show Paper Content
# Introduction [submission]
Driven by the remarkable success of large language models
(LLMs) [llama](http://arxiv.org/pdf/2402.08075v1), [gpt3](http://arxiv.org/pdf/1602.02887v1), research on multi-modal large
language models (MLLMs) also receives an influx of interest in the
machine learning
community [llava](http://arxiv.org/pdf/2402.11690v1), [lavin](http://arxiv.org/pdf/2210.09175v1), [alayrac2022flamingo](http://arxiv.org/pdf/2205.07065v1), [chen2022pali](http://arxiv.org/pdf/2210.02807v1), [chen2023pali](http://arxiv.org/pdf/2310.09199v2).
Numerous efforts have been recently devoted to extending LLMs to more
modalities, achieving breakthroughs on various vision-language
tasks [goyal2017vqav2](http://arxiv.org/pdf/1612.00837v3), [singh2019textvqa](http://arxiv.org/pdf/1811.11903v1), [hudson2019gqa](http://arxiv.org/pdf/2112.05136v1).
Despite advances, existing MLLMs still fall short of granular visual
recognition. For instance, the powerful GPT4-V also suffers from
hallucinations when identifying small and occluded
objects [visshortcoming](http://arxiv.org/pdf/2401.06209v2). This shortcoming inevitably
limits the practical use of MLLMs.
To compensate for this shortcoming, practitioners often resort to
scaling up model size and increasing per-training data
size [alayrac2022flamingo](http://arxiv.org/pdf/2205.07065v1), [li2023blip](http://arxiv.org/pdf/2301.12597v3), [bai2023qwen](http://arxiv.org/pdf/1412.3919v1). For
instance, InstructBLIP [dai2023instructblip](http://arxiv.org/pdf/2311.00233v2) adopts over
129M image-text pairs for vision-language (VL) alignments, and shows
that a larger visual encoder is beneficial for MLLMs. Motivated by this,
Qwen-VL [bai2023qwen](http://arxiv.org/pdf/1412.3919v1) further increases the parameters of
visual encoder to 1.9 billion and uses 1.5 billion pre-training data.
Despite progress, this paradigm is prohibitively expensive, which often
consumes about thousands of GPU hours.
Orthogonal to these works, we study the visual shortcoming of MLLMs from
the perspective of input image resolutions. As revealed in previous VL
research [indefense](http://arxiv.org/pdf/2001.03615v2), [visshortcoming](http://arxiv.org/pdf/2401.06209v2), [simrec](http://arxiv.org/pdf/2204.07913v2), increasing
the resolution of input images is a straightforward solution to improve
visual recognition, which becomes more important for MLLMs that involve
*visual chain-of-thought* [rose2023visual](http://arxiv.org/pdf/2305.02317v3). As shown in
Fig. 1,
increasing the resolution of LLaVA-1.5 [llava1.5](http://arxiv.org/pdf/2310.19145v1) from
384 $\times$ 384 to 672 $\times$ 672 can bring obvious performance gains
(+4.6%) on TextVQA [singh2019textvqa](http://arxiv.org/pdf/1811.11903v1). However, the use
of high-resolution images will greatly exacerbate the already high
computational cost of MLLMs. For instance, $448\times448$ resolution
will increase the computation complexity of LLaVA by about 1.4 times
compared with the default $336\times 336$. In addition, due to the
complex structure of MLLMs, the training will become unstable as the
resolution is greatly increased, *e.g.*, a sharp drop at
$1,022\times 1,022$ resolution, as shown in
Fig. 1.
We assume that the length of visual sequences greatly exceeds the
pre-trained context length, leading to training instability.
In this paper, we propose a novel and efficient method for the
high-resolution image adaptation of MLLMs, namely *mixture-of-resolution
adaptation* (MRA). As shown in
Fig. 1,
MRA adopts an innovative dual visual pathway design to process the input
images of high- and low-resolutions simultaneously. Specifically, one
pathway aims to encode global information of low-resolution images,
while the other one serves to capture fine-grained semantics from
high-resolution images. Meanwhile, these two pathways are closely
interacted via the novel *mixture-of-resolution adapters* (MR-Adapters),
which embeds the high-resolution visual information into the
low-resolution modeling. In this way, we can use a much fewer number of
visual tokens to represent the input images from macro- to micro-views.
With the careful design of dual-pathway structure, MRA can easily
increase the image resolution up to 1,536 $\times$ 1,536 pixels while
maintaining high efficiency.
To validate MRA, we apply it to a recent MLLLM called
LLaVA [llava](http://arxiv.org/pdf/2402.11690v1), [llava1.5](http://arxiv.org/pdf/2310.19145v1), and term the new model as
LLaVA-HR. We conduct extensive experiments on 11 vision-language (VL)
tasks, including common VL tasks like
VQA2.0 [goyal2017vqav2](http://arxiv.org/pdf/1612.00837v3) and emerging benchmarks such as
POPE [li2023pope](http://arxiv.org/pdf/2402.15721v1). Experimental results show that
LLaVA-HR outperforms existing MLLMs on 8 of 11 VL tasks, *e.g.,* +9.6%
over LLaVA-1.5 on TextVQA. More importantly, the training and inference
of LLaVA-HR are cost-effective. The pre-training and instruction tuning
of LLaVA-HR (7B, 1,024 $\times$ 1,024) only take a total of 20.7 hours
on 8 A800 GPUs, which is ***hundreds of times cheaper*** than
InstructBLIP [dai2023instructblip](http://arxiv.org/pdf/2311.00233v2) and
Qwen-VL [bai2023qwen](http://arxiv.org/pdf/1412.3919v1). With the same resolution, its
inference speed is ***3 times faster*** than
LLaVA-1.5 [llava1.5](http://arxiv.org/pdf/2310.19145v1).
In summary, our contributions are three folds:
- We reveal the significance of image resolution for MLLMs and propose
a novel and efficient adaptation scheme, termed
*mixture-of-resolution adaption* (MRA), which adopts a novel dual
visual pathway design to obtain the benefits of high-resolution
visual information while keeping training and inference efficient.
- We propose a novel *mixture-of-resolution adapter* (MR-Adapter) for
MRA, which can embed the high-resolution information into the
low-resolution visual pathway to improve visual descriptive power.
- Based on MRA, we propose a powerful MLLM, coined LLaVA-HR, which
outperforms existing MLLMs on 8 of 11 VL tasks and spends much
cheaper training expenditure than most MLLMs.
# Related Work
## Multimodal Large Language Models
Driven by the great successes of large language models
(LLMs) [gilardi2023chatgpt](http://arxiv.org/pdf/2303.15056v2), [llama](http://arxiv.org/pdf/2402.08075v1), [gpt3](http://arxiv.org/pdf/1602.02887v1), growing interest
has been aroused in building end-to-end multimodal large language models
(MLLMs) [llava](http://arxiv.org/pdf/2402.11690v1), [zhu2023minigpt](http://arxiv.org/pdf/2402.17510v1), [lavin](http://arxiv.org/pdf/2210.09175v1), [fuyu](https://www.adept.ai/blog/fuyu-8b), [peng2023kosmos](http://arxiv.org/pdf/2305.16103v1), [liu2023llavaplus](https://arxiv.org/pdf/2311.05437).
In particular, most existing MLLMs adopt a modular
structure [lavin](http://arxiv.org/pdf/2210.09175v1), [llava](http://arxiv.org/pdf/2402.11690v1), which utilizes an intermediate
network to project the visual features into the word embedding space of
the LLM. Then, the LLM is used to accomplish various VL tasks in an
autoregressive manner. Based on the modular structure, existing MLLMs
can be distinguished by the designs of the intermediate network. Popular
MLLMs represented by LLaVA [llava](http://arxiv.org/pdf/2402.11690v1) often adopt a linear
projection layer or an MLP layer to connect the visual encoder and the
LLM [llava](http://arxiv.org/pdf/2402.11690v1), [llava1.5](http://arxiv.org/pdf/2310.19145v1), [chen2023shikra](http://arxiv.org/pdf/2306.15195v2), [chen2023pali](http://arxiv.org/pdf/2310.09199v2), [peng2023kosmos](http://arxiv.org/pdf/2305.16103v1).
The other works employ sampler-based modules to bridge the gap between
the visual encoder and the
LLM [bai2023qwen](http://arxiv.org/pdf/1412.3919v1), [alayrac2022flamingo](http://arxiv.org/pdf/2205.07065v1), [li2023blip](http://arxiv.org/pdf/2301.12597v3), [dai2023instructblip](http://arxiv.org/pdf/2311.00233v2).
These sampler-based modules can effectively reduce the number of visual
tokens, but often requires a large-scale pre-training to achieve a
promising performance [bai2023qwen](http://arxiv.org/pdf/1412.3919v1), [li2023blip](http://arxiv.org/pdf/2301.12597v3). Despite
the effectiveness, most existing MLLMs still adopt a low visual
resolution, *e.g.,* 336 $\times$ 336, which greatly limits their
performance in fine-grained tasks.
## Visual Representations for MLLMs
The pursuit of better visual representations has been a popular research
trend in the VL
community [lu2019vilbert](http://arxiv.org/pdf/2005.07486v3), [indefense](http://arxiv.org/pdf/2001.03615v2), [radford2021learning](http://arxiv.org/pdf/2404.19696v1), [ren2024grounded](https://arxiv.org/pdf/2401.14159).
Early endeavors mainly explore the object-level features for VL
models [lu2019vilbert](http://arxiv.org/pdf/2005.07486v3), [zhang2021vinvl](http://arxiv.org/pdf/2402.17510v1). Driven by the
large-scale image-text pre-training, grid features from
CLIP [radford2021learning](http://arxiv.org/pdf/2404.19696v1) have demonstrated the great
efficiency and generalization in
MLLMs [llava](http://arxiv.org/pdf/2402.11690v1), [chen2022pali](http://arxiv.org/pdf/2210.02807v1), [alayrac2022flamingo](http://arxiv.org/pdf/2205.07065v1). Based on
grid features, existing researchers mainly improve visual
representations by scaling up the visual encoder. For example,
PaLI [chen2022pali](http://arxiv.org/pdf/2210.02807v1) increases the parameters of visual
encoder to 3 billions and shows the significant performance boost of
MLLMs. In contrast to these works, we improve the visual representations
for MLLMs from the perspective of image resolution, and propose a novel
and efficient solution, namely mixture-of-resolution adaptation.
# Preliminary [sec:limitation]
We first recap the structure of multimodal large language models
(MLLMs), which consists of an image encoder $\mathcal{F_I(\cdot)}$, an
intermediate network $\mathcal{F_P(\cdot)}$ and an LLM
$\mathcal{F_{L}(\cdot)}$.
In particular, given an input image
$I \in \mathbb{R}^{H \times W \times 3}$ and a textual instruction
$T \in \mathbb{R}^{L}$, the visual tokens
$\textbf{F}_v \in \mathbb{R}^{ (h \times w) \times d}$ are obtained via
the image encoder, and the text tokens
$f_t \in \mathbb{R}^{ l \times d}$ are represented by the corresponding
word embeddings. Based on the visual and textual tokens, the LLM will
decode the target word step by step, formulated as $$\begin{aligned}
p_t=\prod_{s=1}^{S+1}\mathcal{F_{L}}(R_s|\mathcal{F_P}(\textbf{F}_v),f_t,R_{0:s-1}).
\end{aligned}
\label{eq_mllm}$$ Here, $p_t\in \mathbb{R}^{m}$ denotes the
probabilities of the predicted word and $m$ is the size of word
vocabulary.
In some MLLMs [llava](http://arxiv.org/pdf/2402.11690v1), [llava1.5](http://arxiv.org/pdf/2310.19145v1), $\mathcal{F_P}(\cdot)$ is
often a stack of simple linear layers, which are used to directly
project the visual tokens onto the semantic space of LLMs. Although
simple and effective, this strategy inevitably leads to a longer visual
sequence as the resolution increases, *e.g.,* 5,329 tokens for 1,022
$\times$ 1,022 resolution in LLaVA-1.5. In practice, processing such a
large number of tokens is computationally expensive in MLLMs. To further
reduce the number of visual tokens, recent advances adopt the
sampler-based module for **$\mathcal{F_P}(\cdot)$** , *e.g.,*
*QFormer* [li2023blip](http://arxiv.org/pdf/2301.12597v3), which aggregates visual features
into several tokens that LLM can directly handle. Nevertheless, these
methods often require large-scale pre-training to achieve VL
alignments [bai2023qwen](http://arxiv.org/pdf/1412.3919v1), [li2023blip](http://arxiv.org/pdf/2301.12597v3).
Based on the above analyses, we conclude that the main difficulty of
high-resolution image adaptation lies in the rapidly growing visual
sequence. This issue motivates us to further explore how to efficiently
encode richer visual information with fewer visual tokens.
# Mixture-of-Resolution Adaptation
## Overview
To address the above issues, we propose a novel and efficient method for
MLLMs, termed *mixture-of-resolution adaptation* (MRA), of which
structure is depicted in Fig. [fig2]. The core idea of MRA is to embed
high-resolution information into the low-resolution one via a dual
pathway design. In this case, MRA can keep a smaller number of visual
tokens while encoding richer visual information.
Particularly, given the input images of two resolutions
$I_{l} \in \mathbb{R}^{H_l\times W_l \times 3}$ and
$I_{h} \in \mathbb{R}^{H_h\times W_h \times 3}$, the process of MRA can
be formulated as $$\begin{aligned}
&\textbf{F}_v=\mathcal{F}_{\mathcal{I}_l}(I_l,\mathcal{F_{A}}(\textbf{F}_{vh} )) + \textbf{F}_{vh},\\
&\textbf{F}_{vh}=\mathcal{F}_{\mathcal{I}_h}(I_h).
\end{aligned}
\label{eq_framework}$$ Here,
$\textbf{F}_{vh} \in \mathbb{R}^{h_h\times w_h \times d_h}$ and
$\textbf{F}_v \in \mathbb{R}^{h\times w \times d}$ denote the
high-resolution features and the final visual features, respectively.
And $\mathcal{F}_{\mathcal{I}_l}$ and $\mathcal{F}_{\mathcal{I}_h}$ are
the visual encoders for high-resolution and low-resolution images,
respectively. $\mathcal{F_{A}}$ denotes the *mixture-of-resolution
adapter* (MR-Adapter). In
Eq. [eq_framework], MRA adopts dual visual
pathways to process high- and low- resolution images simultaneously.
Then, a novel MR-Adapter is used to fuse the high-resolution information
from the slow pathway to the fast one. Finally, the visual features of
two resolutions are combined and processed by the LLM based on
Eq. [eq_mllm].
## Dual Visual Pathways
As shown in Fig. [fig2], dual visual pathways are the key
design of MRA, and their benefits are maximized from two aspects.
**Visual functionality.** Firstly, the dual visual pathways process
images from macro- and micro-views, which is inspired by the visual
system of human
being [merigan1993parallel](http://arxiv.org/pdf/2401.05030v1), [robertson1991neuropsychological](http://arxiv.org/pdf/2105.11909v2).
Particularly, [robertson1991neuropsychological](http://arxiv.org/pdf/2105.11909v2) find
that the visual system processes local and global semantics via
different pathways. Based on this finding, we adopt a similar mechanism
to our MRA. Specifically, one visual pathway aims to capture
fine-grained semantics from high-resolution images *i.e.*, processing
images from local view. In contrast, the other pathway is designed to
encode global information from low-resolution images, achieving a larger
receptive field.
**Visual alignment.** Due to different resolutions, these two pathways
often produce visual features of different shapes, impeding their quick
alignments [yu2019multimodal](http://arxiv.org/pdf/1905.07841v1). To overcome this
limitation, we adopt different downsampling rates for the low- and
high-resolution pathways, respectively. Thus, their output features can
keep the same spatial shape.
Based on the above observations, we design the dual visual pathways with
a convolutional network (CNN) [convnext](http://arxiv.org/pdf/2007.00649v1) and a vision
transformer (ViT) [dosovitskiy2020image](http://arxiv.org/pdf/2105.15075v2). Specifically,
CNN is equipped with a downsampling stride of 32 to process
high-resolution images. ViT encodes low-resolution images with a
downsampling stride of 14. Notably, such designs also ensure the
efficiency of MLLMs, where the high-resolution images are processed by
the efficient CNN, and the number of visual tokens is also kept small
via the large downsampling stride.
## Mixture-of-Resolution Adapter
To better collaborate the feature learning of two pathways, we propose a
*mixture-of-resolution adapter* (MR-Adapter) for the fusion of visual
information from different resolution images. In particular, given the
visual features $\textbf{F}_{vh} \in \mathbb{R}^{h\times w \times d_h}$
extracted from a high-resolution image, we embed them into the
low-resolution visual pathway by $$\begin{aligned}
\textbf{F}_{vl}'= \textbf{F}_{vl} + f_l(\textbf{F}_{vl} )+ g \cdot f_h(\textbf{F}_{vh} ).
\end{aligned}
\label{adapter}$$ Here,
$\textbf{F}_{vl} \in \mathbb{R}^{h\times w \times d_l}$ are the
features from the low-resolution pathway. $f_l(\cdot)$ and $f_h(\cdot)$
denote two mapping modules, which are designed as a convolutional block
and an MLP layer, respectively. $g$ is a dynamic score to control the
weights of high-resolution information, defined by $$\begin{aligned}
g &=\delta(W_2\sigma(W_1f_v)),\\
f_v &= \frac{1}{h\times w}\sum_i^{h}\sum_j^{w} [f_l(\textbf{F}_{vl} )^{i,j}, f_h(\textbf{F}_{vh} )^{i,j}].
\end{aligned}$$ Here, $[\cdot]$ denotes the concatenation operation,
and $W_1\in \mathbb{R}^{2d\times\frac{d}{2}}$ and
$W_2\in \mathbb{R}^{\frac{d}{2}\times d}$ are two projection matrices.
$f_v \in \mathbb{R}^{d}$ is the pooled visual features. $\sigma$ and
$\delta$ denote the activation function of *GELU* and *Tanh*,
respectively.
As shown in Fig. [fig2], high-resolution information can be
fused with the features in each block of ViT. In this case, the
low-resolution features of ViT also contain rich semantics, improving
the visual descriptive power of MLLMs.
## The Deployment on MLLM
We apply MRA to a popular MLLM called
LLaVA-1.5 [llava1.5](http://arxiv.org/pdf/2310.19145v1), and construct a new model, namely
LLaVA-HR. Its training consists of two stages, *i.e.*, low-resolution
pre-training and high-resolution instruction tuning.
**Stage 1: Low-Resolution Pre-training.** Similar to
LLaVA [llava](http://arxiv.org/pdf/2402.11690v1) and LLaVA-1.5 [llava1.5](http://arxiv.org/pdf/2310.19145v1),
this stage aims to optimize the projector to align the visual features
with the word embeddings of LLM. Therefore, the image encoder and the
LLM are frozen during pre-training. Besides, we adopt low resolutions
for two pathways. In this stage, the MR-Adapter is not inserted, and
output features of dual pathways are directly combined.
**Stage 2: High-Resolution Instruction Tuning.** During instruction
tuning, we greatly increase the resolution of the high-resolution
pathway, *e.g.,* from 384$\times$ 384 to 1,024$\times$ 1,024. And the
low-resolution one is also accordingly adjusted to ensure the visual
alignment of two pathways, *e.g.,* from 336$\times$ 336 to 448$\times$
448. Meanwhile, the MR-Adapter is then applied to connect two visual
pathways. Different from the first training stage, the entire MLLM will
be fully optimized to better accommodate high-resolution images.
# Experiments
## Evaluations and Metrics
**Multimodal benchmarks for MLLM.** We evaluate LLaVA-HR on four
emerging multimodal benchmarks for MLLMs, including
MME [fu2023mme](http://arxiv.org/pdf/2306.05179v2), POPE [li2023pope](http://arxiv.org/pdf/2402.15721v1),
SEED [li2023seed](http://arxiv.org/pdf/2311.15759v1) and
MM-VET [yu2023mmvet](http://arxiv.org/pdf/2402.15896v1). In particular, MME and MM-VET
evaluate the multimodal perception and cognition abilities of MLLMs.
SEED extends the modalities of evaluation to images and videos. POPE
aims to evaluate the visual hallucinations of MLLMs. The metrics used in
our paper follow their default settings. For MME, we follow LLaVA-1.5 to
report the perception score.
**Common vision-language benchmarks.** We also evaluate LLaVA-HR on
seven VL datasets, including VQAv2 [goyal2017vqav2](http://arxiv.org/pdf/1612.00837v3),
GQA [hudson2019gqa](http://arxiv.org/pdf/2112.05136v1), OKVQA [okvqa](http://arxiv.org/pdf/1906.00067v2),
OCRVQA [mishra2019ocrvqa](http://arxiv.org/pdf/2010.02582v1),
ScienceQA [lu2022learn](http://arxiv.org/pdf/2209.09513v2),
VizWiz [gurari2018vizwiz](http://arxiv.org/pdf/1802.08218v4) and TextVQA. In particular,
ScienceQA [lu2022learn](http://arxiv.org/pdf/2209.09513v2),
VizWiz [gurari2018vizwiz](http://arxiv.org/pdf/1802.08218v4) and TextVQA are three
**zero-shot tasks**, and their samples are not appeared in our training
data. We report the accuracy on the *test* set of OCRVQA, the *test* set
of VizWiz, and the *val* set of OKVQA. We organize samples of these
tasks in instruction formats of LLaVA-1.5 [llava1.5](http://arxiv.org/pdf/2310.19145v1).
## Implementation Details
In LLaVA-HR, we use
CLIP-ViT-L [radford2021learning](http://arxiv.org/pdf/2404.19696v1), [openclip](https://doi.org/10.5281/zenodo.5143773) and
CLIP-ConvNeXt-L [convnext](http://arxiv.org/pdf/2007.00649v1) as the dual visual paths to
encode low- and high-resolution images, respectively. In LLaVA-HR-X, the
CLIP-ConvNeXt-L is replaced with the stronger CLIP-ConvNeXt-XXL. The
MR-Adapter is applied into the last three stages of ViT. Following
LLaVA-1.5, we first pre-train LLaVA-HR on
LCS-558K [llava](http://arxiv.org/pdf/2402.11690v1), which contains 558*k* image-text pairs.
During the pre-training stage, both the visual encoder and the LLM are
frozen, and only the MLP projector is fine-tuned.
AdamW [kingma2014adam](http://arxiv.org/pdf/1810.00553v1) is used as the optimizer, and the
learning rate and batch size are set to 1e-3 and 256, respectively.
Visual resolutions are set to 336$\times$``{=html}336 and
384$\times$``{=html}384 for the ViT and the CNN, respectively.
During instruction tuning, we follow LLaVA-1.5 to use 665*k* VL
instruction data. At this stage, the entire model is updated with a
learning rate of 2e-5. Besides, we increase the resolution of ViT and
CNN to 448$\times$``{=html}448 and
1,024$\times$``{=html}1,024, respectively. The training epoch is
set to 1 for pre-training and instruction tuning.
## Experimental Results
### Quantitative Analysis
**Comparison with baselines.** In
Tab. [tab1], we compare the performance and
efficiency of LLaVA-HR with LLaVA-1.5 [llava1.5](http://arxiv.org/pdf/2310.19145v1) with
different image resolutions. From this table, we observe that increasing
image resolution obviously improves the performance of two models on
four tasks, *e.g.,* +4.8% of LLaVA-1.5 on TextVQA. However, the
performance of LLaVA-1.5 drops significantly at the resolution of
1,024$\times$``{=html}1,024. To explain, the number of visual
tokens greatly exceeds the pre-trained context length of the LLM, which
easily causes the instability during training. In contrast, the
performance of LLaVA-HR is consistently improved from 384 $\times$ 384
resolution to 1,024 $\times$ 1,024 resolution. Besides, the total gain
of LLaVA-HR is more obvious than that of
LLaVA-1.5 [llava1.5](http://arxiv.org/pdf/2310.19145v1), *e.g.,* +8.33% of LLaVA-HR *vs.*
+4.82% of LLaVA-1.5, greatly confirming the effectiveness of MRA.
In
Tab. 1,
we further compare four common baselines with the similar resolution,
*i.e.,* $\sim$``{=html}760$\times$``{=html}760.
“ViT+MLP” is the default setting of LLaVA-1.5 as the reference.
“Conv+MLP” replaces the visual backbone with
ConvNeXt [convnext](http://arxiv.org/pdf/2007.00649v1), which uses a larger downsampling
rate to reduce the number of visual tokens. “ViT+Resampler” and
“ViT+Pooling+MLP” refer to the two pooling strategies for reducing the
number of visual tokens. As can be seen, all compared methods are
inferior to LLaVA-HR. In particular, using a convolutional network as
the visual backbone greatly improves efficiency, but its performance
still lags behind LLaVA-HR by a large margin, *e.g.,* -108.9 on
MME [fu2023mme](http://arxiv.org/pdf/2306.05179v2). Similarly, “ViT+Resampler” and
“ViT+Pooling+MLP” also sacrifice performance for efficiency. Overall,
these comparisons further confirm the designs of MRA.
Despite effectiveness, the expenditure of LLaVA-HR is also
cost-effective. In particular, increasing resolution from 384 $\times$
384 to 1,024 $\times$ 1,024 slows down the training and inference of
LLaVA-1.5 by 344.8% and 325%, respectively. However, these costs are
reduced to only 17.6% and 20.8% in LLaVA-HR. Despite better performance,
the training and inference speeds of LLaVA-HR are three times faster
than LLaVA-1.5. Besides, the costs of GPU memory also remain cheap for
LLaVA-HR. For example, adapting the resolution of 1,536 $\times$ 1,536
for LLaVA-HR only consumes 52G GPU memory, but the same settings for
LLaVA-1.5 will cause GPU memory overflow. These results greatly confirm
the efficiency of our MRA and LLaVA-HR.
**Ablation studies.** In Tab. [tab3], we conduct comprehensive ablation
studies for MRA on four VL benchmarks. Firstly, we validate the
different designs of the dual visual pathways. From these results, we
find that removing one pathway will lead to significant performance
drops, *e.g.,* -1.5% on VQAv2. Besides, scaling up the high-resolution
encoder brings more gains than that of the low-resolution one, *e.g.,*
+2.1% *vs.* +0.9% on TextVQA. We assume that the stronger
high-resolution image encoder can better capture the fine-grained visual
information. Then, we ablate different fusion directions and strategies
in MRA. Specifically, changing the fusion direction obviously
degenerates the performance, *e.g.,* -61.3 on MME. Finally, we ablate
the designs of the mixture-of-resolution adapter. Specifically, the best
choices of mapping modules for the low- and high-resolution pathways are
convolution blocks and MLP blocks, respectively. Besides, the choices of
gating function also affect performance and the *tanh* function perform
the best. These ablations further confirm the designs of MR-Adapter.
**Comparison with existing MLLMs.** In
Tab. [tab4] -
[tab5], we compare LLaVA-HR with existing
MLLMs on 11 VL tasks. On the four MLLM benchmarks, we observe
comprehensive advantages of LLaVA-HR against existing MLLMs. In
particular, LLaVA-HR achieves 1554.9 scores in MME benchmark,
outperforming LLaVA-1.5 by +23.6. On POPE, a benchmark including video
evaluations, LLaVA-HR-X still outperforms existing MLLMs by a large
margin, *i.e.,* +3.7% gains. Besides, LLaVA-HR achieves the best
performance on the benchmark for visual hallucinations, *i.e.,* POPE,
suggesting that its visual hallucinations are greatly alleviated.
Notably, Fuyu-8b [fuyu](https://www.adept.ai/blog/fuyu-8b) is capable of high-resolution
images, but its performance is much inferior to LLaVA-HR, *e.g.,* 728.6
*vs.* 1554.9 on MME.
Tab. [tab5] gives the performance comparison on
common VL tasks. On in-domain tasks, LLaVA-HR achieves the best results
on three tasks, *e.g.,* 82.6 on VQAv2 and 61.5 on OKVQA. On OCRVQA,
Qwen-VL-Chat collects more in-domain data for training, so it performs
better than LLaVA-HR. Under the zero-shot setting, we can observe more
significant advantages of LLaVA-HR on the fine-grained tasks, *e.g.,*
VizWiz and TextVQA. Most notably, even Qwen-VL-Chat is pre-trained with
24.8M OCR samples, it still performs worse than LLaVA-HR-X on TextVQA.
These results suggest the significance of high resolution for these
tasks. In contrast, most images of ScienceQA are synthetic and of low
resolution, so the advantages of LLaVA-HR are not obvious. Overall,
these results greatly confirm the effectiveness and generalization of
LLaVA-HR and our MRA.
### Qualitative Experiments
In Fig [fig6] (a), we compare the predictions of
LLaVA-HR with different resolutions. The visualizations show that higher
image resolution obviously improves the capability of MLLMs on
fine-grained tasks. For example, LLaVA-HR with a resolution of 1,024
$\times$ 1,024 can well capture granular visual content, *e.g.,* the
tiny boat in the first example. Besides, high image resolution also
enables LLaVA-HR a stronger ability of text recognition. For instance,
the small and blurred phrase of “*wo ich wohne*” in the second example
are correctly identified by the high-resolution LLaVA-HR. These results
greatly confirm the significance of high image resolution in addressing
visual shortcoming. In Fig [fig6] (b), we further compare the predictions
of LLaVA-HR-X, LLaVA-1.5 [llava1.5](http://arxiv.org/pdf/2310.19145v1) and
GPT4-V [gpt4v](https://cdn.openai.com/papers/GPTV_System_Card.pdf) in visual information extraction. Notably,
LLaVA-HR-X shows a comparable ability with GPT4-V on this challenging
task. As shown in Fig [fig6] (b), LLaVA-HR-X and GPT4-V can
correctly extract almost all visual content of the driver license and
organize it in JSON format. Compared to GPT4-V, LLaVA-HR-X also
correctly identifies the hair color of the person, which requires
fine-grained visual reasoning. In contrast, LLaVA-1.5 can only recognize
simple visual content like “*class*” and “*SEX*”, and fail to extract
most visual information. These results further validate the
effectiveness of MRA in addressing visual shortcoming of MLLMs.
# Conclusion
In this paper, we study the visual shortcoming of MLLMs from the
perspective of image resolution, and propose a novel and efficient
method for high-resolution adaptations of MLLMs, namely
*mixture-of-resolution adaptation* (MRA). MRA adopts dual visual
pathways to process images of both high and low resolutions, where
high-resolution information is embeded into the low-resolution modeling
via the novel *mixture-of-resolution adapters* (MR-Adapters). We apply
MRA to a popular MLLM called LLaVA-1.5, and construct a new
high-resolution MLLM, termed LLaVA-HR. Experimental results not only
validate the effectiveness of LLaVA-HR in addressing visual shortcoming,
but also confirm its remarkable efficiency against existing MLLMs.
#### Acknowledgements.
This work was supported by National Key R&D Program of China
(No.2022ZD0118201) , the National Science Fund for Distinguished Young
Scholars (No.62025603), the National Natural Science Foundation of China
(No. U21B2037, No. U22B2051, No. 62176222, No. 62176223, No. 62176226,
No. 62072386, No. 62072387, No. 62072389, No. 62002305 and No.
62272401), the Natural Science Foundation of Fujian Province of China
(No.2021J01002, No.2022J06001), and the China Fundamental Research Funds
for the Central Universities (Grant No. 20720220068).
CogAgent: A Visual Language Model for GUI Agents
2023-12-14
Wenyi Hong, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wenmeng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yuxuan Zhang, Juanzi Li, Bin Xu, Yuxiao Dong, Ming Ding, Jie Tang
People are spending an enormous amount of time on digital devices through graphical user interfaces (GUIs), e.g., computer or smartphone screens. Large language models (LLMs) such as ChatGPT can assist people in tasks like writing emails, but struggle to understand and interact with GUIs, thus limiting their potential to increase automation levels. In this paper, we introduce CogAgent, an 18-billion-parameter visual language model (VLM) specializing in GUI understanding and navigation. By utilizing both low-resolution and high-resolution image encoders, CogAgent supports input at a resolution of 1120*1120, enabling it to recognize tiny page elements and text. As a generalist visual language model, CogAgent achieves the state of the art on five text-rich and four general VQA benchmarks, including VQAv2, OK-VQA, Text-VQA, ST-VQA, ChartQA, infoVQA, DocVQA, MM-Vet, and POPE. CogAgent, using only screenshots as input, outperforms LLM-based methods that consume extracted HTML text on both PC and Android GUI navigation tasks -- Mind2Web and AITW, advancing the state of the art. The model and codes are available at https://github.com/THUDM/CogVLM .
Show Paper Content
### Acknowledgments [acknowledgments]
We thank Xiaohan Zhang from Zhipu AI for managing the data annotation
team, and Zhao Xue, Aohan Zeng, Yifan An, Chenxu Guo from Zhipu AI and
Tsinghua for data management.
[^1]: Work was done when interned at Zhipu AI.
[^2]: Corresponding authors
# Introduction
Autonomous agents in the digital world are ideal assistants that many
modern people dream of. Picture this scenario: You type in a task
description, then relax and enjoy a cup of coffee while watching tasks
like booking tickets online, conducting web searches, managing files,
and creating PowerPoint presentations get completed automatically.
Recently, the emergence of agents based on large language models (LLMs)
is bringing us closer to this dream. For example,
AutoGPT [autogpt](https://github.com/Significant-Gravitas/AutoGPT), a 150,000-star open-source project,
leverages ChatGPT [openai2022chatgpt](https://openai.com/blog/chatgpt) to integrate
language understanding with pre-defined actions like Google searches and
local file operations. Researchers are also starting to develop
agent-oriented
LLMs [zeng2023agenttuning](http://arxiv.org/pdf/2310.12823v2), [chen2023fireact](http://arxiv.org/pdf/2402.01469v1). However, the
potential of purely language-based agents is quite limited in real-world
scenarios, as most applications interact with humans through Graphical
User Interfaces (GUIs), which are characterized by the following
perspectives:
- Standard APIs for interaction are often lacking.
- Important information including icons, images, diagrams, and spatial
relations are difficult to directly convey in words.
- Even in text-rendered GUIs like web pages, elements like canvas and
iframe cannot be parsed to grasp their functionality via HTML.
Agents based on visual language models (VLMs) have the potential to
overcome these limitations. Instead of relying exclusively on textual
inputs such as HTML [nakano2021webgpt](http://arxiv.org/pdf/2310.03184v2) or OCR
results [rawles2023android](http://arxiv.org/pdf/1209.0687v1), VLM-based agents directly
perceive visual GUI signals. Since GUIs are designed for human users,
VLM-based agents can perform as effectively as humans, as long as the
VLMs match human-level vision understanding. In addition, VLMs are also
capable of skills such as extremely fast reading and programming that
are usually beyond the reach of most human users, extending the
potential of VLM-based agents. A few prior studies utilized visual
features merely as auxiliaries in specific scenarios. e.g.
WebShop [yao2022webshop](http://arxiv.org/pdf/2207.01206v4) which employs visual features
primarily for object recognition purposes. With the rapid development of
VLM, can we naturally achieve universality on GUIs by relying solely on
visual inputs?
In this work, we present CogAgent, a visual language foundation model
specializing in GUI understanding and planning while maintaining a
strong ability for general cross-modality tasks. By building upon
CogVLM [wang2023cogvlm](http://arxiv.org/pdf/2210.00066v1)—a recent open-source VLM,
CogAgent tackles the following challenges for building GUI agents:
- **Training Data.** Most current VLMs are pre-trained on datasets
like LAION [schuhmann2022laion](http://arxiv.org/pdf/2312.15897v1), consisting of
natural images on the Web. However, we notice that the GUI images
share a different distribution from natural images. We thus
construct a large-scale annotated dataset about GUIs and OCR for
continual pre-training.
- **High-Resolution vs. Compute.** In GUIs, tiny icons and text are
ubiquitous, and it is hard to recognize them in commonly-used
$224\times224$ resolution. However, increasing the resolution of
input images results in significantly long sequence length in
language models. For example, a $1120\times 1120$ image corresponds
to a sequence of $6400$ tokens if the patch size is $14$, demanding
excessive training and inference compute. To address this, we design
a cross-attention branch that allows for a trade-off between the
resolution and the hidden size within a proper computation budget.
Specifically, we propose to combine the original large
ViT [dosovitskiy2020image](http://arxiv.org/pdf/2105.15075v2) (4.4B parameters) used in
CogVLM [wang2023cogvlm](http://arxiv.org/pdf/2210.00066v1) and a new small
*high-resolution cross-module* (with image encoder of 0.30B
parameters) to jointly model visual features.
Our experiments show that:
- CogAgent tops popular GUI understanding and decision-making
benchmarks, including AITW [rawles2023android](http://arxiv.org/pdf/1209.0687v1) and
Mind2Web [deng2023mind2web](http://arxiv.org/pdf/2306.06070v3). To the best of our
knowledge, this is the first time that a generalist VLM can
outperform LLM-based methods with extracted structured text.
- Though CogAgent focuses on GUIs, it achieves state-of-the-art
generalist performance on nine visual question-answering benchmarks
including VQAv2 [antol2015vqa](http://arxiv.org/pdf/1309.1125v1),
OK-VQA [marino2019ok](http://arxiv.org/pdf/1906.00067v2),
TextVQA [singh2019towards](http://arxiv.org/pdf/1811.11903v1),
ST-VQA [biten2019scene](http://arxiv.org/pdf/2304.01603v1),
ChartQA [masry2022chartqa](http://arxiv.org/pdf/2203.10244v1),
infoVQA [mathew2022infographicvqa](http://arxiv.org/pdf/2104.12756v2),
DocVQA [mathew2021docvqa](http://arxiv.org/pdf/2111.05547v1),
MM-Vet [yu2023mm](http://arxiv.org/pdf/2402.15896v1), and
POPE [li2023evaluating](http://arxiv.org/pdf/2402.15721v1).
- The separated design of high- and low-resolution branches in
CogAgent significantly lows the compute cost for consuming
high-resolution images, e.g., the number of the floating-point
operations (FLOPs) for CogAgent-18B with $1120 \times 1120$ inputs
is less than half that of CogVLM-17B with its default
$490\times 490$ inputs.
CogAgent is open-sourced at . It
represents an effort to promote the future research and application of
AI agents, facilitated by advanced VLMs.
# Method
In this section, we will first introduce the architecture of CogAgent,
especially the novel high-resolution cross-module, and then illustrate
the process of pre-training and alignment in detail.
## Architecture
The architecture of CogAgent is depicted in
1. We build our model based on a
pre-trained VLM (on the right side of the image), and propose to add a
cross-attention module to process high-resolution input (on the left
side of the image). As our base VLM, We select
CogVLM-17B [wang2023cogvlm](http://arxiv.org/pdf/2210.00066v1), an open-sourced and
state-of-the-art large vison-language model. Specifically, We employ
EVA2-CLIP-E [sun2023eva](http://arxiv.org/pdf/2303.15389v1) as the encoder for
low-resolution images (224$\times$``{=html}224 pixels),
complemented by an MLP adapter that maps its output into the feature
space of the visual-language decoder. The decoder, a pre-trained
language model, is enhanced with a visual expert module introduced by
[wang2023cogvlm](http://arxiv.org/pdf/2210.00066v1) to facilitate a deep fusion of visual
and language features. The decoder processes a combined input of the
low-resolution image feature sequence and text feature sequence, and
autoregressively outputs the target text.
Similar to most VLMs, the original CogVLM can only accommodate images of
relatively low resolution (224 or 490), which hardly meets the demands
of GUI where the screen resolution of computers or smartphones is
typically 720p ($1280\times720$ pixels) or higher. It is a common
problem among VLMs, e.g. LLaVA [liu2023visual](http://arxiv.org/pdf/2402.11690v1) and
PALI-X [chen2023pali](http://arxiv.org/pdf/2109.04653v1) are pre-trained at a low resolution
of $224\times224$ on the general domain. The primary reason is that
high-resolution image brings prohibitive time and memory overhead: VLMs
usually concatenate text and image feature sequence as input to the
decoder, thus the overhead of self-attention module is quadratic to the
number of visual tokens (patches), which is quadratic to the image’s
side length. There are some initial attempts to reduce costs for
high-resolution images. For instance,
Qwen-VL [bai2023qwen](http://arxiv.org/pdf/1412.3919v1) proposes a position-aware
vision-language adapter to compress image features, but only reduces
sequence length by four and has a maximum resolution of $448\times448$.
Kosmos-2.5 [lv2023kosmos](http://arxiv.org/pdf/2309.11419v1) adopts a Perceiver Resampler
module to reduce the length of the image sequence. However, the
resampled sequence is still long for self-attention in the large
visual-language decoder (2,048 tokens), and can only be applied to
restricted text recognition tasks.
Therefore, we propose a novel *high-resolution cross-module* as a potent
complement to the existing structure for enhancing understanding at high
resolutions, which not only maintains efficiency confronting
high-resolution images, but also offers flexible adaptability to a
variety of visual-language model architectures.
## High-Resolution Cross-Module
The structural design of *high-resolution cross-module* is mainly based
on the following observations:
1. At a modest resolution such as $224\times224$, images can depict
most objects and layouts effectively, yet the resolution falls short
in rendering text with clarity. Hence, our new high-resolution
module should emphasize text-related features, which are vital for
understanding GUIs.
2. While pre-trained VLMs in general domain often need large hidden
sizes (e.g. 4,096 in PALI-X and CogVLM, 5,120 in LLaVA), VLMs
tailored for text-centered tasks like document OCR require smaller
hidden sizes to achieve satisfying performance (e.g. 1,536 in
Kosmos-2.5 and Pix2Struct [lee2023pix2struct](http://arxiv.org/pdf/2210.03347v2)). This
suggests that text-related features can be effectively captured
using smaller hidden sizes.
As shown in 1, the high-resolution cross-module acts
as a new branch for higher-resolution input, which accepts images of
size $1120\times1120$ pixels in our implementation. Different from the
original low-resolution input branch, the high-resolution cross-module
adopts a much smaller pre-trained vision encoder (visual encoder of
EVA2-CLIP-L [sun2023eva](http://arxiv.org/pdf/2303.15389v1) in our implementation, 0.30B
parameters), and uses cross-attention of a small hidden size to fuse
high-resolution image features with every layer of VLLM decoder, thus
reducing the computational cost. To be concrete, for an input image, it
is resized to $1120\times1120$ and $224\times224$ and fed into the
high-resolution cross-module and the low-resolution branch respectively,
then encoded into image feature sequences $X_{\text{hi}}$ and
$X_{\text{lo}}$ with two distinct-sized image encoders in parallel. The
visual language decoder retains its original computations, while the
only change is to integrate a cross-attention between $X_{\text{hi}}$
and hidden states in every decoder layer.
Formally, suppose that the input hidden states of the i-th attention
layer in the decoder are
$X_{\text{in}_i} \in \mathbb{R}^{B\times (L_{I_{\text{lo}}}+L_T) \times D_{\text{dec}}}$,
and the output hidden states of cross-module’s image encoder are
$X_{\text{hi}} \in \mathbb{R}^{B\times (L_{I_{\text{hi}}}) \times D_{\text{hi}}}$,
where B is the batch size, $L_{I_{\text{lo}}}$, $L_{I_{\text{hi}}}$ and
$L_T$ are the lengths of the low-resolution image, high-resolution image
and text sequences, $D_{\text{dec}}$ and $D_{\text{hi}}$ is the hidden
size of the decoder and high-resolution encoder’s output respectively.
Each layer’s attention procedure can be formulated as $$\begin{aligned}
X_{i}' &= \text{MSA}(\text{layernorm}(X_{\text{in}_i})) + X_{\text{in}_i}, \label{msa} \\
X_{\text{out}_i} &= \text{MCA}(\text{layernorm}(X_{i}'), X_{\text{hi}}) + X_{i}', \label{eq:mca}
\end{aligned}$$ where MSA and MCA represent multi-head self-attention
with visual expert and multi-head cross-attention, while $X_{i}'$ and
$X_{\text{out}_i}$ represent their respective output features with the
residual connection. To implement cross-attention between them, we add
learnable transformation matrices
$W_{K_{\text{cross}}}^i, W_{V_{\text{cross}}}^i \in \mathbb{R}^{D_{\text{hi}} \times D_{\text{cross}}}$
to get $K_{\text{cross}}^i=X_{\text{hi}} W_{K_{\text{cross}}}^i$,
$V_{\text{cross}}^i=X_{\text{hi}} W_{V_{\text{cross}}}^i \in \mathbb{R}^{L_{I_{\text{hi}}} \times D_{\text{cross}}}$,
and
$W_{Q_{\text{cross}}}^i \in \mathbb{R}^{D_{\text{dec}} \times D_{\text{cross}}}$
to get
$Q_{\text{cross}}^i=X_i' W_{Q_{\text{cross}}}^i \in \mathbb{R}^{(L_{I_{\text{lo}}}+L_T) \times D_{\text{cross}}}$
in every decoder layer. With the residual connection in
Eq. [eq:mca], the cross-attention with
high-resolution images can be perceived as a complement to the features
of low-resolution images, thereby effectively utilizing the previous
pre-trained model in low resolution.
**Computational complexity.** Let the number of attention head be
$H_{\text{cross}}$ and $H_{\text{dec}}$ in cross-attention and
self-attention, and the dimension of each head be
$d_{\text{cross}} = D_{\text{cross}}/{H_{\text{cross}}}$ and
$d_{\text{dec}} = D_{\text{dec}}/{H_{\text{dec}}}$. If using our
high-resolution cross-module, the computational complexity of attention
is $$\begin{split}
\text{T}_{\text{improved}} = \mathbf{O}\bigl( &(L_{I_{\text{lo}}} + L_T) L_{I_{\text{hi}}} H_{\text{cross}} d_{\text{cross}} \\
&+ (L_{I_{\text{lo}}} + L_T)^2 H_{\text{dec}} d_{\text{dec}} \bigr).
\end{split}$$ Note that $d_{\text{cross}}$ and $H_{\text{cross}}$ can be
flexibly adjusted according to computational budget and model
performance. If not utilizing the high-resolution cross-module and
directly substituting low-resolution images with high-resolution ones,
the computational complexity would be $$\begin{aligned}
\text{T}_{\text{original}} = \mathbf{O}\bigl((L_{I_{\text{hi}}} + L_T)^2 H_{\text{dec}} d_{\text{dec}} \bigr).
\end{aligned}$$
In our implementation, $d_{\text{cross}}=32$, $H_{\text{cross}}=32$, and
we inherits $d_{\text{dec}}=128$, $H_{\text{dec}}=32$ from CogVLM-17B.
Both high- and low-resolution encoders patchify images with
$14\times14$-pixel patches, thus $L_{I_{\text{hi}}}=6400$,
$L_{I_{\text{lo}}}=256$. Our method leads to at least
$\frac{L_{I_{\text{hi}}}+L_{T}}{L_{I_{\text{lo}}}+L_{T}} = \frac{6400+L_{T}}{256+L_{T}} \times$
acceleration which is a stringent lower bound (refer to Appendix for
detailed derivation), and reduces memory overhead at the same time.
## Pre-training
To enhance the model’s ability to comprehend high-resolution images and
adapt it for GUI application scenarios, we focus our pre-training
efforts on the following aspects: the capability to recognize texts of
various sizes, orientations, and fonts in high-resolution images, the
grounding ability of text and objects in the image, and a specialized
understanding capability for GUI imagery such as web page. We divide our
pre-train data into three parts based on the aforementioned aspects,
with samples in the Appendix. All the pre-training data are derived from
publicly available datasets. The construction methods are detailed
below.
**Text recognition.** Our data includes (1) Synthetic renderings with
text from language pre-training dataset (80M). This is similar to the
Synthetic Document Generator in [kim2022ocr](http://arxiv.org/pdf/2305.09520v1), with text
of varying font, size, color and orientation, and diverse image
background from LAION-2B [schuhmann2022laion](http://arxiv.org/pdf/2312.15897v1). (2)
Optical Character Recognition (OCR) of natural images (18M). We collect
natural images from COYO [kakaobrain2022coyo-700m](https://github.com/kakaobrain/coyo-dataset) and
LAION-2B [schuhmann2022laion](http://arxiv.org/pdf/2312.15897v1) and employ
Paddle-OCR [du2020pp](http://arxiv.org/pdf/2109.03144v2) to extract the texts and their
bounding boxes, and filter out images with no text boxes. Paddle-OCR may
introduce some errors, which can be ameliorated through integration with
other pre-training datasets and subsequent fine-tuning processes. (3)
Academic documents (9M). We follow
Nougat [blecher2023nougat](http://arxiv.org/pdf/2308.13418v1) to construct image-text pairs
including text, formula and tables from the source code (LaTeX) release
on arXiv. For (1)(3), we apply the same data augmentation as Nougat
which includes erosion, gaussian noise, gaussian blur, image
compression, and elastic transform, etc. For (2), we additionally
employed more aggressive rotation and flipping data augmentation
techniques, thereby enhancing the model’s robustness in recognizing
text.
**Visual grounding.** It is imperative for GUI agents to possess the
capability to accurately comprehend and locate diverse elements within
images. Therefore, we incorporated a range of grounding data into
pre-training. We follow CogVLM [wang2023cogvlm](http://arxiv.org/pdf/2210.00066v1) to use a
constructed visual grounding dataset of 40M images with image-caption
pairs sampled from LAION-115M [li2023blip](http://arxiv.org/pdf/2301.12597v3), which
associate entities in the caption with bounding boxes to indicate their
positions. The format of the bounding box is $[[x_0, y_0, x_1, y_1]]$,
where $(x_0, y_0)$ and $(x_1, y_1)$ represent the coordinates of
upper-left and lower-right corners which are normalized to $[000, 999]$.
If multiple objects are indicated by a single noun phrase, their boxes
are separated by semicolons in double square brackets. We have also
collected grounding data on web page elements, which will be introduced
in the next part.
**GUI imagery.** Our approach innovatively addresses the scarcity and
limited relevance of GUI images in datasets like LAION and COYO, which
predominantly feature natural images. GUI images, with their distinct
elements such as input fields, hyperlinks, icons, and unique layout
characteristics, require specialized handling. To boost the model’s
capability in interpreting GUI imagery, we have conceptualized two
pioneering GUI grounding tasks: (1) GUI Referring Expression Generation
(REG) – where the model is tasked with generating HTML code for DOM
(Document Object Model) elements based on a specified area in a
screenshot, and (2) GUI Referring Expression Comprehension (REC) – which
involves creating bounding boxes for given DOM elements. To facilitate
robust training in GUI grounding, we have constructed the CCS400K
(Common Crawl Screenshot 400K) dataset. This extensive dataset is formed
by extracting URLs from the latest Common Crawl data, followed by
capturing 400,000 web page screenshots. Alongside these screenshots, we
compile all visible DOM elements and their corresponding rendered boxes
using Playwright[^1], supplementing the dataset with 140 million REC and
REG question-answer pairs. This rich dataset ensures comprehensive
training and understanding of GUI elements. To mitigate the risk of
overfitting, we employ a diverse range of screen resolutions for
rendering, selected randomly from a list of commonly used resolutions
across various devices. Additionally, to prevent the HTML code from
becoming overly extensive and unwieldy, we perform necessary data
cleaning by omitting redundant attributes in the DOM elements, following
the method outlined in [lee2023pix2struct](http://arxiv.org/pdf/2210.03347v2).
We also incorporate publicly available text-image datasets including
LAION-2B and COYO-700M (after removing the broken URLs, NSFW images, and
images with noisy captions and political bias) during pre-training.
We pre-train our CogAgent model for a total of 60,000 iterations with a
batch size of 4,608 and a learning rate of 2e-5. We freeze all
parameters except the newly added high-resolution cross-module for the
first 20,000 steps, resulting in a total number of 646M (3.5%) trainable
parameters, then additionally unfreeze the visual expert in CogVLM for
the next 40,000 steps. We warm up with curriculum learning by first
training on easier text recognition (synthetic renderings and OCR on
natural images) and image captioning, then sequentially incorporating
harder text recognition (academic document), grounding data and web page
data, as we observed that it leads to faster convergence and more stable
training in our preliminary experiments.
## Multi-task Fine-tuning and Alignment
To enhance our model’s performance for diverse tasks and ensure it
aligns with free-form human instructions in the GUI setting, we further
fine-tune our model on a broad range of tasks. We manually collected
over two thousand screenshots from mobile phones and computers, each
annotated with screen elements, potential tasks, and methods of
operation in the question-answering format by human annotators (details
illustrated in the Appendix). We also utilize
Mind2Web [deng2023mind2web](http://arxiv.org/pdf/2306.06070v3) and
AITW [rawles2023android](http://arxiv.org/pdf/1209.0687v1), datasets focusing on web and
Android behaviors which comprise tasks, sequences of actions and
corresponding screenshots, and convert them into a natural language
question-and-answer format using GPT-4. Besides, we incorporate multiple
publicly available visual question-answering (VQA) datasets encompassing
a variety of tasks into our alignment dataset. We unfreeze all model
parameters during this stage and train for 10k iterations with a batch
size of 1024 and a learning rate of 2e-5.
[^1]:
# Experiments
To evaluate the foundational capabilities and GUI-related performance of
our model, we conduct extensive experiments on a broad range of
datasets. First, we conduct evaluations on eight VQA benchmarks, as well
as MM-Vet [yu2023mm](http://arxiv.org/pdf/2402.15896v1) and
POPE [li2023evaluating](http://arxiv.org/pdf/2402.15721v1), which validate our model’s
enhanced ability in visual understanding, especially on those that are
reliant on text recognition. Then we evaluate our model on Mind2Web and
AITW datasets, as the representative of two major GUI scenarios —
computers and smartphones.
## Foundational Visual Understanding
We first extensively evaluate CogAgent’s foundational visual
understanding capability across eight VQA benchmarks, covering a wide
range of visual scenes. The benchmarks can be divided into two
categories: general VQA, including VQAv2 [antol2015vqa](http://arxiv.org/pdf/1309.1125v1)
and OK-VQA [marino2019ok](http://arxiv.org/pdf/1906.00067v2), and text-rich VQA, including
TextVQA [singh2019towards](http://arxiv.org/pdf/1811.11903v1),
OCR-VQA [mishra2019ocr](http://arxiv.org/pdf/2010.02582v1),
ST-VQA [biten2019scene](http://arxiv.org/pdf/2304.01603v1),
DocVQA [mathew2021docvqa](http://arxiv.org/pdf/2111.05547v1),
InfoVQA [mathew2022infographicvqa](http://arxiv.org/pdf/2104.12756v2) and
ChartQA [masry2022chartqa](http://arxiv.org/pdf/2203.10244v1). The latter category
emphasizes the understanding of visually-situated text, including
documents, charts, photographs containing text, etc. Contrary to models
individually fine-tuned for optimal performance on each downstream task,
our model is fine-tuned collectively on all datasets simultaneously,
yielding a single generalist model which is then evaluated across all
datasets. The goal of generalist evaluation is to better mirror
real-world situations of visual agents where typically a single model is
used, and to demonstrate the model’s versatility and robustness across
tasks.
The results are presented in
[table:vqa]. For general VQA, CogAgent
achieves state-of-the-art generalist results on both datasets. For
text-rich VQA, CogAgent achieves state-of-the-art results on 5 out of 6
benchmarks, significantly surpassing generalist competitors
(TextVQA+8.0, ChartQA+2.1, InfoVQA+2.3, DocVQA+16.2), even outperforming
the task-specific state-of-the-art models on TextVQA(+4.7), STVQA(+0.6)
and DocVQA(+1.6). Notably, compared to the generalist results of CogVLM
which CogAgent is initially based on, CogAgent demonstrates certain
improvements on both general and Text-rich VQA tasks, suggesting the
efficacy of our proposed model architecture and training methods.
Furthermore, we conducted zero-shot tests of our model on the
challenging MM-Vet [yu2023mm](http://arxiv.org/pdf/2402.15896v1) and
POPE [li2023evaluating](http://arxiv.org/pdf/2402.15721v1) datasets, both of which are
instrumental in gauging the multi-modal capabilities and the
generalization performance in complex tasks including conversation
question-answering, detailed descriptions, complex reasoning tasks.
MM-Vet is designed with six core tasks to assess multi-modal models’
proficiency in handling intricate assignments, and POPE-adversarial
models on their susceptibility to hallucinations. Our experimental
results, as detailed in
Table [tab:LLaVA_results], showcase
that our model significantly outperforms other existing models in both
datasets. Notably, on the MM-Vet dataset, our model achieved a
remarkable score of 52.8, surpassing the closest competitor, LLaVA-1.5,
by a substantial margin (+16.5). On the POPE-adversarial evaluation, our
model attained a score of 85.9, demonstrating superior handling of
hallucinations compared to other models.
These results indicate CogAgent’s robust performance in foundational
visual understanding, especially in the interpretation of images with
embedded text. With these core competencies, the model can be feasibly
applied to various visual agent tasks across different GUI environments.
## GUI Agent: Computer Interface
We evaluate CogAgent on Mind2Web, a dataset for web agents that includes
over 2,000 open-ended tasks collected from 137 real-world websites
across 31 domains. Each entry in the dataset comprises a high-level task
description, a sequence of actions, and webpage snapshots in a variety
of formats, including HTML and screenshots. Given task description,
current webpage snapshot and previous actions as inputs, agents are
expected to predict the subsequent action. We follow the setting of
[deng2023mind2web](http://arxiv.org/pdf/2306.06070v3) in our experiments, and report step
success rate (step SR) metric. Further details are attached in the
Appendix.
Several language models were evaluated on this benchmark. For instance,
AgentTuning [zeng2023agenttuning](http://arxiv.org/pdf/2310.12823v2) and
MindAct [deng2023mind2web](http://arxiv.org/pdf/2306.06070v3) evaluated Llama2-70B and
Flan-T5-XL in a fine-tuned setting, and GPT-3.5 and GPT-4 in a
in-context learning setting. However, limited by the input modality of
language models, these models could only use heavily cleansed HTML as
the representation of screen inputs. To the best of our knowledge, no
visually-based web agents have been experimented with on this benchmark.
We fine-tune our model on the train set and evaluate on three
out-of-domain subsets, i.e. cross-website, cross-domain, and cross-task.
We additionally fine-tune LLaMA2-7B and LLaMA2-70B as the baseline of
fine-tuned LLMs, and adopt the same HTML cleansing process as
[deng2023mind2web](http://arxiv.org/pdf/2306.06070v3) to construct HTML input. The results
are presented in [tab:mind2web]. Compared to other
methods, our approach achieved significant performance improvements
across all three subsets, surpassing LLaMA2-70B, which is nearly
4$\times$ the scale of CogAgent, by 11.6%, 4.7%, and 6.6%, respectively.
This reflects not only the capability of our model but also the
advantages of employing a visual agent in computer GUI scenarios.
## GUI Agent: Smartphone Interface
To evaluate our model on diverse smartphone interfaces and tasks, we
utilize Android in the Wild (AITW)
dataset [rawles2023android](http://arxiv.org/pdf/1209.0687v1) , a large-scale dataset for
Android device agents. It comprises 715k operation episodes, covering
30k distinct task instructions, four Android versions, and eight device
types featuring varying screen resolutions. Each episode in the dataset
consists of a goal described in natural language, followed by a sequence
of actions and corresponding screenshots. The training target is to
predict the next action based on the given goal, historical actions, and
the screenshot. AITW considers a wide range of action types, including
tapping, swiping, typing, going home, going back, entering, etc. For
each action, models are required to predict the exact action type; for
tap, swipe and type, models are further required to predict the
position, direction, and content to be typed, respectively.
We conduct comparisons with two kinds of baselines: language models
using the textual description of UI elements provided by the original
dataset (text OCR and icon) as the representations of screen inputs[^1],
and visual-language models using images as the screen inputs. We
simultaneously fine-tuned on all the subsets, yielding a unified model
which is then evaluated on all test sets. As the GoogleApps subset is
10-100 times larger than other subsets, we downsample it to 10% to avoid
data imbalance.
Results are shown in [tab:aitw]. CogAgent achieves
state-of-the-art performance compared to all previous methods. In
comparison to language-based methods, our model surpasses both baselines
by a large margin. In comparison to the visual-language baseline,
Auto-UI, our model achieves +2.61 improvements in the overall
performance. In instances of inaccuracies, we randomly sample hundreds
of cases, and upon reassessment, more than 40% are determined to be
correct (refer to the appendix for details). This diversity arises from
the multiple valid pathways inherent in mobile interactions, resulting
in a range of responses.
[^1]: Some Android applications may have View Hierarchy which is more
friendly to language-based agents, but most of them tend to be poor
quality or missing altogether. Therefore, as a large-scale,
general-purpose dataset, AITW retained the results of OCR detection
and icon detection as textual representations of screenshots.
# Ablation Study [subsec:ablation]
To thoroughly comprehend the impact of various components in the
methodology, we conduct ablation studies on two aspects, model
architecture and training data. The evaluation is conducted on diverse
datasets, including multiple VQA datasets (STVQA, OCRVQA, DocVQA) and a
web agent dataset (Mind2Web). For VQA datasets, we fine-tune the model
on four datasets together for 3,000 iters with a batch size of 1,280,
and report the generalist score; for Mind2Web, models are fine-tuned for
2,400 iters with a batch size of 128 and use top-10 setting. Training
iterations are fewer than those in the main experiment, aiming to
control variables within the constraints of a limited budget.
## Model Architecture
To ascertain the efficacy of the high-resolution cross-module, we
compare it with directly increasing the resolution using the original
model architecture of CogVLM, and ablate on two perspectives:
computational efficiency and model performance.
To measure computational overhead, we use floating point operations
(FLOPs) as the metric, and conduct experiments on multiple resolutions
including 224, 490, 756, and 1120. From
1 we can see that, as the image resolution
increases, models that use a high-resolution cross-module experience
only a modest rise in computational overhead, demonstrating an almost
linear relationship with the number of image patches. In contrast, using
the original model structure, i.e. CogVLM, leads to a significant
increase in the number of FLOPs at higher resolutions. Its FLOPs can
even be more than 10 times higher compared to employing a cross-module
at a resolution of 1120, which is the resolution utilized by CogAgent.
We further compare the model performance in
[tab:ablation-architecture],
which indicates that models with high-resolution cross-module at the
resolution of 756 require only 1/2 of the computational resources used
by the original structure at the resolution of 490, while delivering
significantly better performance. Additionally, the high-resolution
cross-module allows for further increasing models’ acceptable resolution
within a limited computational budget, thereby yielding additional
performance improvements.
## Pre-train Data
We further conduct an ablation study on pre-training data, which is an
integral part of training visual agents. Building upon the image-caption
data commonly used in visual-language training, we sequentially add OCR
data (denoted as Cap+OCR), as well as GUI and grounding data (denoted as
All). The results in
[tab:ablation-data] indicate that
each part of data broadly contributes to enhanced performance. Notably,
web and grounding data have a significant impact on the Mind2Web
dataset, underscoring the importance of constructing domain-specific
pre-train data in the training of GUI agents.
# Conclusion
We introduce CogAgent, a VLM-based GUI agent with enhanced pre-train
data construction and efficient architecture for high-resolution input.
CogAgent achieves state-of-the-art performance on a wide range of VQA
and GUI benchmarks, and will be open-sourced.
CogAgent is an initial exploration of VLM-based GUI agent, and still has
some shortcomings, e.g. imprecise output coordinates and incapability of
processing multiple images, necessitating further research.
Vary: Scaling up the Vision Vocabulary for Large Vision-Language Models
2023-12-11
Haoran Wei, Lingyu Kong, Jinyue Chen, Liang Zhao, Zheng Ge, Jinrong Yang, Jianjian Sun, Chunrui Han, Xiangyu Zhang
Modern Large Vision-Language Models (LVLMs) enjoy the same vision vocabulary -- CLIP, which can cover most common vision tasks. However, for some special vision task that needs dense and fine-grained vision perception, e.g., document-level OCR or chart understanding, especially in non-English scenarios, the CLIP-style vocabulary may encounter low efficiency in tokenizing the vision knowledge and even suffer out-of-vocabulary problem. Accordingly, we propose Vary, an efficient and effective method to scale up the vision vocabulary of LVLMs. The procedures of Vary are naturally divided into two folds: the generation and integration of a new vision vocabulary. In the first phase, we devise a vocabulary network along with a tiny decoder-only transformer to produce the desired vocabulary via autoregression. In the next, we scale up the vanilla vision vocabulary by merging the new one with the original one (CLIP), enabling the LVLMs can quickly garner new features. Compared to the popular BLIP-2, MiniGPT4, and LLaVA, Vary can maintain its vanilla capabilities while enjoying more excellent fine-grained perception and understanding ability. Specifically, Vary is competent in new document parsing features (OCR or markdown conversion) while achieving 78.2% ANLS in DocVQA and 36.2% in MMVet. Our code will be publicly available on the homepage.
Show Paper Content
# Introduction [intro]
Recently, research into vision dialogue
robots [BLIP2](http://arxiv.org/pdf/2301.12597v3), [Flamingo](http://arxiv.org/pdf/2205.07065v1), [llava](http://arxiv.org/pdf/2402.11690v1), [minigpt4](http://arxiv.org/pdf/2402.17510v1), [InstructGPT](http://arxiv.org/pdf/2302.05206v1) has
been gaining significant traction. These human-like models, mainly
relying on two components (large language models
(LLMs) [GPT-2](http://arxiv.org/pdf/2203.12926v1), [GPT3](http://arxiv.org/pdf/2112.07522v2), [OPT](http://arxiv.org/pdf/2405.04515v2), [llama](http://arxiv.org/pdf/2402.08075v1), [GPT4](https://arxiv.org/pdf/arXiv preprint arXiv:2303.08774) and vision vocabulary
networks), can not only converse based on user’s input image but also
perform well on simple downstream tasks, such as
VQA [COCO](None), [TextVQA](http://arxiv.org/pdf/1811.11903v1), Image
caption [coco_text](http://arxiv.org/pdf/1707.08831v1), OCR [OCRVQA](http://arxiv.org/pdf/2010.02582v1), and so
on. Hence, it is undeniable that large vision-language models (LVLMs)
are driving the AI community towards the direction of artificial general
intelligence (AGI).
Popular GPT-4 [GPT4](https://arxiv.org/pdf/arXiv preprint arXiv:2303.08774)-like LVLMs, *e.g.*,
BLIP2 [BLIP2](http://arxiv.org/pdf/2301.12597v3),
MiniGPT4 [minigpt4](http://arxiv.org/pdf/2402.17510v1),LLaVA [llava](http://arxiv.org/pdf/2402.11690v1),
Qwen-VL [Qwen-VL](http://arxiv.org/pdf/2308.12966v3), and
*etc*. [dong2023dreamllm](http://arxiv.org/pdf/2309.11499v2), [zhao2023chatspot](http://arxiv.org/pdf/2307.09474v1), [yu2023merlin](http://arxiv.org/pdf/2312.00589v1)
enjoy a stunning performance in multiple aspects with their own
programming paradigm: Based on an LLM [OPT](http://arxiv.org/pdf/2405.04515v2), [T5](http://arxiv.org/pdf/1910.10683v4), BLIP-2
proposes the Q-former, a BERT [Bert](http://arxiv.org/pdf/1810.04805v2) like network as a
vision input embedding layer, aiming to align the image tokens to a text
special. Inherited the structure of BLIP-2, MiniGPT-4 introduces 3500
high-quality image-text pairs as self-supervised fine-tuning (SFT) data,
allowing it can “talk” like GPT-4. Unlike BLIP-2, LLaVA utilizes a
linear layer as the vision embedding layer, which is similar with the
text input embedding layer in the text tokenizer, ensuring the
consistency in the structure of image and text branches. For Qwen-VL, it
utilizes a cross-attention layer to sample and align the image tokens,
making the model can accept larger input resolution. Although the above
LVLMs’ vision input embedding networks are variable (*e.g.*, MLP,
Qformer, Perceiver [Flamingo](http://arxiv.org/pdf/2205.07065v1)), their vision vocabulary
is almost identical (a CLIP-based [radford2021learning](http://arxiv.org/pdf/2404.19696v1)
VIT) which we argue maybe a bottle-neck.
It is recognized that CLIP-VIT is a tremendous general vision
vocabulary, which is trained via contrastive learning upon more than
400M [schuhmann2021laion](http://arxiv.org/pdf/2111.02114v1) image-text pairs, covering most
natural images and vision tasks. However, for some special scenarios,
*e.g.*, high-resolution perception, Non-English OCR, Document/Chart
understanding, and so on, the CLIP-VIT may regard them as a “foreign
language”, leading to inefficient tokenizing, *i.e.*, difficulty in
encoding all vision information into a fixed number (usually 256) of
tokens. Although mPlug-Owl [ye2023mplug](http://arxiv.org/pdf/2403.14252v1) and Qwen-VL
alleviate the above issues by unfreeze its vision vocabulary network (a
CLIP-L or CLIP-G), we argue that such manner may not be reasonable due
to three aspects: 1) it may overwrite the knowledge of the original
vocabulary; 2) the training efficiency of updating a vision vocabulary
upon a relative large LLM (7B) is low; 3) it can not allow the vision
vocabulary network to “see” an image multiple times (train a dataset
with multiple epochs) due to the strong memory ability of LLMs.
Therefore, a natural question is: *Is there a strategy that can simplify
and effectively intensify the visual vocabulary?*
In this paper, we propose Vary, an efficient and user-friendly approach,
to answer the above question. Vary is inspired by the text vocabulary
expansion manner in vanilla LLMs [vicuna](https://lmsys.org/blog/2023-03-30-vicuna/), *i.e.*, when
transferring an English LLM to another foreign language, such as
Chinese, it’s necessary to expand the text vocabulary to lift the
encoding efficiency and model performance under the new language.
Intuitively, for the vision branch, if we feed the “foreign language”
image to the model, we also need to scale up the vision vocabulary. In
Vary, the process of vocabulary scaling up can be divided into two
steps: 1) generate a new vision vocabulary that can make up the old one
(CLIP); 2) integrate the new and old vocabularies. As shown in
Figure 1,
we build a small-size pipeline which is consisting of a vocabulary
network and a tiny decoder-only transformer in the first step to train
the vocabulary model via predicting the next token. It is worth noting
that the autoregressive-based process of generating a vocabulary is
perhaps more suitable for dense perception tasks than that based on
contrastive learning like CLIP. On the one hand, the next-token way can
allow the vision vocabulary to compress longer texts. On the other hand,
the data formats that can be used in this manner are more diverse, such
as VQA [STVQA](http://arxiv.org/pdf/2309.17133v2), [DocVQA](http://arxiv.org/pdf/2111.05547v1) data with prompt. After preparing
the new vision vocabulary, we add it to the vanilla LVLMs to introduce
new features. In this process, we freeze both the new and old
vocabularies networks to avoid the visual knowledge being overwritten.
Afterward scaling up the vision vocabulary, our LVLM can achieve more
fine-grained vision perception, such as document-level Chinese/English
OCR, book image to markdown or *LaTeX*, Chinese/English chart
understanding, and so on, while ensuring its original capabilities
(conversation, VQA, caption, *etc*.). Besides, we provide methods for
producing synthetic data and validate its importance in document/chart
understanding. More importantly, Vary is a useful strategy to strengthen
the visual vocabulary of LVLMs, which can be utilized at arbitrary
downstream visual tasks that CLIP is not good at. In addition to the
document and chart parsing mentioned in this paper, we believe that Vary
still enjoys more fine-grained tasks and we appeal to researchers to
rethink the design ideas of LVLMs from the perspective of visual
vocabulary construction.
# Related Works
## Large Language Models
Over the past year, significant attention has been drawn to large
language models (LLMs) in the fields of both natural language processing
(NLP) and computer vision (CV). This heightened attention stems from
LLMs’ outstanding performance in diverse aspects, especially the
powerful world knowledge base and universal capabilities. Current LLMs
enjoy a unified transformer architecture which is exemplified by
BERT [Bert](http://arxiv.org/pdf/1810.04805v2), GPT-2 [GPT-2](http://arxiv.org/pdf/2203.12926v1),
T5 [T5](http://arxiv.org/pdf/1910.10683v4), *etc*. Subsequently, researchers have uncovered
the concept of an "emergent ability" [wei2022emergent](http://arxiv.org/pdf/2403.15796v2) in
LLMs. This implies that as language model sizes reach a certain
threshold, there may be a qualitative leap in their capabilities.
Furthermore, InstructGPT [InstructGPT](http://arxiv.org/pdf/2302.05206v1) and
ChatGPT [ChatGPT](https://openai.com/blog/chatgpt/) find that Reinforcement Learning with
Human Feedback (RLHF) [christiano2017deep](http://arxiv.org/pdf/2007.12904v2) can further
lift the performance of the "talk robot”. Motivated by the tremendous
success of the GPT series, a multitude of other open-source LLMs have
emerged, including OPT [OPT](http://arxiv.org/pdf/2405.04515v2),
LLaMA [llama](http://arxiv.org/pdf/2402.08075v1), GLM [GLM](http://arxiv.org/pdf/2004.13270v1), and so on.
Building upon these openly available LLMs, numerous tailored fine-tuned
models have been introduced to develop LLMs for diverse applications,
especially LLaMA-driven models,*e.g.*, Alphaca [alpaca](https://github.com/tatsu-lab/stanford_alpaca),
Vicuna [vicuna](https://lmsys.org/blog/2023-03-30-vicuna/), which have become the de-facto component
for a Large Vision-Language Model (LVLM).
## LLM-based Large Vision-Language Models
LLM’s robust zero-shot capabilities and logical reasoning make it play
the central controller role within an LVLM. There are two primary
pipeline styles: plugin-based and end-to-end model. Plugin-based
methods [VisualChatGPT](http://arxiv.org/pdf/2303.04671v1), [MMREACT](http://arxiv.org/pdf/2303.11381v1), [Hugginggpt](http://arxiv.org/pdf/2303.17580v4), [taskmatrix](http://arxiv.org/pdf/2303.16434v1), [yang2023gpt4tools](http://arxiv.org/pdf/2401.15328v2)
typically regard LLMs as an agent to invoke various plugins from other
foundational or expert models, executing specific functions in response
to human instructions. While such methods offer versatility, they have
limitations in terms of plugin invocation efficiency and performance.
Conversely, end-to-end LVLMs usually rely on a single large multimodal
model to facilitate interactions. Following this approach,
Flamingo [Flamingo](http://arxiv.org/pdf/2205.07065v1) introduces a gated cross-attention
mechanism trained on billions of image-text pairs to align vision and
language modalities, demonstrating strong performance in few-shot
learning. BLIP-2 [BLIP2](http://arxiv.org/pdf/2301.12597v3) introduces Q-Former to enhance
the alignment of visual features with the language space. More recently,
LLaVA [llava](http://arxiv.org/pdf/2402.11690v1) proposes using a simple linear layer to
replace Q-Former and designed a two-stage instruction-tuning procedure.
Despite the remarkable performance of existing methods, they are
confined to the same and limited vision vocabulary –
CLIP-VIT [radford2021learning](http://arxiv.org/pdf/2404.19696v1). For an LVLM, CLIP-VIT is
a tremendous general vision vocabulary that is trained via contrastive
learning upon million-level image-texts pairs, which can cover most
nature images and vision tasks, *e.g.*, VQA, Caption, Easy English OCR.
However, some images under special scenarios, *e.g.*, high-resolution
image, Non-English OCR, Document/Chart understanding, and so on, will
still be regarded as a “foreign language” by CLIP-VIT, leading to vision
out-of-vocabulary problem, which will in turn become a bottleneck for
LVLMs.
# Method [methods]
## Architecture
Vary enjoys two conformations: Vary-tiny and Vary-base, as shown in
Figure 2.
We devise the Vary-tiny to “write” a new vision vocabulary and the
Vary-base to make use of the new vocabulary. Specifically, Vary-tiny is
mainly composed of a vocabulary network and a tiny
OPT-125M [OPT](http://arxiv.org/pdf/2405.04515v2). Between the two modules, we add a linear
layer to align the channel dimensions. There is no text input branch in
Vary-tiny due to it is a primary focus on fine-grained perception. We
hope the new vision vocabulary network can excel in processing
artificial images, *i.e.*, documents, and charts, to compensate for
CLIP’s shortcomings. At the same time, we also expect that it will not
be a noise for CLIP when tokenizing natural images. Accordingly, during
generating, we feed the manual document and chart data as positive
samples and natural images as negatives to train Vary-tiny. After
completing the above process, we extract the vocabulary network and add
it to a large model to build the Vary-base. As shown in the lower half
of
Figure 2,
the new and old vocabulary networks enjoy independent input embedding
layers and are integrated before the LLM. In such a stage, we freeze
both weights of new and old vision vocabulary networks and unfreeze the
weights of other modules.
## Towards Generating a New Vision Vocabulary
### The new vocabulary network
We use the SAM [kirillov2023segment](http://arxiv.org/pdf/2305.01275v1) pretrained
ViTDet [li2022exploring](http://arxiv.org/pdf/2203.16527v2) image encoder (base scale) as
the main part of the new vocabulary network of Vary. Due to the input
resolution of the SAM-base is (1024$\times$``{=html}1024) while
the output stride is 16, the feature shape of the last layer is
(64$\times$``{=html}64$\times$``{=html}256 for
H$\times$W$\times$C) that can not be aligned to the output of CLIP-L
(256$\times$``{=html}1024 for N$\times$C). Hence, we add two
convolution layers, which we found is a good token merging unit, behind
the last layer of the SAM initialized network, as shown in
Figure [fig3]. The first convolution layer possesses
a kernel size of 3, aiming to transfer the feature shape to
32$\times$``{=html}32$\times$``{=html}512. The setting
of the second conv layer is the same as the first one, which can further
convert the output shape to
16$\times$``{=html}16$\times$``{=html}1024. After that,
we flattened the output feature to 256$\times$``{=html}1024 to
align the image token shape of CLIP-VIT.
r0.5
### Data engine in the generating phrase [data1]
**Documnet data.** We select the high-resolution document image-text
pairs as the main positive dataset used for the new vision vocabulary
pretrain due to the dense OCR can effectively validate the fine-grained
image perception ability of the model. To our knowledge, there is no
publicly available dataset of English and Chinese documents, so we
create our own. We first collect pdf-style documents from open-access
articles on arXiv and CC-MAIN-2021-31-PDF-UNTRUNCATED for the English
part and collect from e-books on the Internet for the Chinese part. Then
we use *fitz* of PyMuPDF to extract the text information in each pdf
page and convert each page into a PNG image via *pdf2image* at the same
time. During this process, we construct 1M Chinese and 1M English
document image-text pairs for training.
**Chart data.** We find current LVLMs are not good at chart
understanding, especially Chinese charts, so we choose it as another
main knowledge that needs to be “written” into the new vocabulary. For
chart image-text pair, we all follow the rendering way. We select both
the *matplotlib* and *pyecharts* as the rendering tools. For
matplotlib-style chart, we built 250k in both Chinese and English. While
for pyecharts, we build 500k for both Chinese and English. Besides, we
convert the text ground truth of each chart to a python-dict form. The
texts used in the chart, *e.g.*, title, x-axis, and y-axis, are randomly
selected from the Natural Language Processing (NLP) corpus downloaded
from the Internet.
**Negative natural image.** For natural image data that CLIP-VIT is good
at, we need to ensure that the newly introduced vocabulary does not
cause noise. Consequently, we construct negative natural image-text
pairs to enable the new vocabulary network to encode correctly when
seeing natural images. We extract 120k images in the
COCO [COCO](None) dataset with each image corresponding to a
text. The text part is randomly selected from follows sentences: "It’s
an image of nature"; "Here’s a nature picture"; "It’s a nature photo";
"This is a natural image"; "That’s a shot from nature".
### Input format
We train all parameters of the Vary-tiny with image-text pairs by
autoregression. The input format follows popular
LVLMs [KOSMOS](http://arxiv.org/pdf/2302.14045v2), *i.e*, the image tokens are packed with
text tokens in the form of a prefix. Specifically, we use two special
tokens "\" and "\" to indicate the position of the image
tokens as the input of an interpolated OPT-125M (4096 tokens). During
training, the output of Vary-tiny is only text, and "\" is regarded
as the *eos* token.
## Towards Scaling Up the Vision Vocabulary
### The structure of Vary-base
After completing the training of the vocabulary network, we introduce it
to our LVLM – Vary-base. Specifically, we parallelize the new vision
vocabulary with the original CLIP-VIT. Both two vision vocabularies
enjoy an individual input embedding layer, *i.e.*, a simple linear. As
shown in
Figure 2,
the input channel of the linear is 1024 and the output is 2048, ensuring
the channel of image tokens after concatenating is 4096, which exactly
aligns the input of LLM (Qwen-7B [qwen](http://arxiv.org/pdf/2309.16609v1) or
Vicuna-7B [vicuna](https://lmsys.org/blog/2023-03-30-vicuna/)).
### Data engine in the scaling up phrase
***LaTeX* rendering document**. Except for the collecting document data
in Section 3.2.2, we also need data to enjoy some
format, *e.g.*, supporting formula, and table. To this end, we create
document data through *LaTeX* rendering. Firstly, we collected some
*.tex* source files on arxiv, and then extracted tables, mathematical
formulas, and plain texts using regular expressions. Finally, we
re-render these contents with the new template we prepared by
*pdflatex*. We collect 10+ templates to perform batch rendering.
Besides, we transfer the text ground truth of each document page to a
*mathpix* markdown style to unify the format. By this construction
process, we acquired 0.5 million English pages and 0.4 million Chinese
pages. Some samples are shown in
Figure 3.
**Semantic association chart rendering**. In
Section 3.2.2, we batch render chart data to train
the new vocabulary network. However, the texts (title, x-axis values,
and y-axis values) in those rendered charts suffer low correlation
because they are randomly generated. This issue is not a problem in the
vocabulary-generating process as we only hope that the new vocabulary
can efficiently compress visual information. However, in the training
stage of the Vary-base, due to unfreezing the LLM, we hope to use higher
quality (strongly correlated content) data for training. Therefore, we
use GPT-4 [GPT4](https://arxiv.org/pdf/arXiv preprint arXiv:2303.08774) to generate some charts using relevant
corpus and then we utilize the high-quality corpus to addition render
200k chart data for the Vary-base training.
**General data**. The processes of training Vary-base follows popular
LVLMs, *e.g.*, LLaVA [llava](http://arxiv.org/pdf/2402.11690v1), including the pretrain and
SFT phases. Different from the LLaVA, we freeze all the vocabulary
networks and unfreeze both the input embedding layer and LLM, which is
more like the pretrain setting of a pure LLM. We use natural image-text
pair data to introduce the general concepts to the Vary-base. The
image-text pairs are randomly extracted from
LAION-COCO [schuhmann2021laion](http://arxiv.org/pdf/2111.02114v1) with the amount of 4
million. In the SFT stage, we use the LLaVA-80k or
LLaVA-CC665k [liu2023improvedllava](http://arxiv.org/pdf/2310.19145v1) along with the train
set of DocVQA [DocVQA](http://arxiv.org/pdf/2111.05547v1) and
ChartQA [masry2022chartqa](http://arxiv.org/pdf/2203.10244v1) as the fine-tuning dataset.
### Conversation format
When we use the Vicuna-7B as our LLM, the conversation format follows
the Vicuna v1 [vicuna](https://lmsys.org/blog/2023-03-30-vicuna/), *i.e.*, USER:
\"\"\ "texts input" ASSITANT: "texts output"
\. Due to the low efficiency in the text vocabulary of Vicuna to
process Chinese, we choose Qwen-7B [qwen-chat](https://github.com/QwenLM/Qwen-7B) as the LLM
for Chinese processing. When we use the Qwen-7B, we design the
conversation style following the
LLaVA-MPT [team2023introducing](http://arxiv.org/pdf/2311.16429v1), [llava](http://arxiv.org/pdf/2402.11690v1), which can be
described as: \<\|im_start\|\>user: \"\"\ "texts
input"\<\|im_end\|\> \<\|im_start\|\>assistant: "texts output"
\<\|im_end\|\>.
# Experiments [exp]
## Datasets and Evaluation Metrics
We evaluate the proposed Vary on multiple datasets, including 1) a
document-level OCR test set we created to explore the performance of
dense visual perception; 2) DocVQA [DocVQA](http://arxiv.org/pdf/2111.05547v1) and
ChartQA [masry2022chartqa](http://arxiv.org/pdf/2203.10244v1) to test the improvement on
downstream tasks; 3) MMVet [yu2023mm](http://arxiv.org/pdf/2402.15896v1) to monitor changes
in the general performance of the model. Our own document test set
contains pure OCR and markdown conversion tasks. In a pure OCR task, the
test split includes 100 pages in both Chinese and English, which are
randomly extracted from arxiv and ebook. In the markdown conversion
task, the test set obtains 200 pages, of which 100 pages contain tables
and another 100 pages have mathematical formulas.
We report Normalized Edit
Distance [levenshtein1966binary](http://arxiv.org/pdf/2007.09075v4), [blecher2023nougat](http://arxiv.org/pdf/2308.13418v1) and
F1-score along with the precision and recall for document parsing. For
DocVQA, ChartQA, and MMVet, we use their vanilla metrics for a fair
comparison with other LVLMs.
## Implementation Details
During the vision vocabulary generating process, we optimize all
parameters of Vary-tiny with a batch size of 512 and train the model for
3 epochs. We utilize the AdamW [AdamW](http://arxiv.org/pdf/2311.11446v2) optimizer and a
cosine annealing scheduler [loshchilov2016sgdr](http://arxiv.org/pdf/1608.03983v5) along
with the learning rate of 5e-5 to train Vary-tiny.
In the training stage of the Vary-base, we freeze the weights of both
new and vanilla (CLIP-L) vision vocabulary networks and optimize the
parameters of input embedding layers and LLM. The initial learning rate
is 5e-5 in pretrain while 1e-5 in SFT. Both the pretrain and SFT enjoy a
batch size of 256 and an epoch of 1. Other settings are the same as
Vary-tiny.
## Fine-grained Perception Performance
We measure the fine-grained perception performance of Vary through the
dense text recognition ability. As shown in
Table [tab:1], Vary-tiny gathers both Chinese and
English dense OCR ability by the process of vision vocabulary
generating. Specifically, it achieves 0.266 and 0.197 edit distance for
Chinese and English documents (plain texts) OCR respectively, proving
the new vision vocabulary enjoys good fine-grained text encoding
capacity. For Vary-base, it can achieve an on-par performance with
nougat [blecher2023nougat](http://arxiv.org/pdf/2308.13418v1) (a special document parsing
model) on English plain text documents. Besides, with different prompts
(*e.g.*, Convert the image to markdown format.), Vary-base can realize
the document image-markdown format conversion. It is worth noting that
in such a task, Vary-base (with 0.181 edict distance and 81.10% F1 on
math and table average) is better than nougat (with 0.245 edict distance
and 79.97% F1 on average) to some extent, which may be due to the super
strong text correction ability of the 7B LLM (Qwen). All the above
results indicate that by scaling up the vision vocabulary, the new LVLM
can lift its fine-grained perception performance.
| **Method** | DocVQA | | ChartQA | | |
|:---|:--:|:--:|:--:|:--:|:--:|
| 2-3 (rl)4-6 | **val** | **test** | **human** | **augmented** | **Average** |
| Dessurt [davis2022end](http://arxiv.org/pdf/2203.16618v3) | 46.5 | 63.2 | \- | \- | \- |
| Donut [kim2022ocr](http://arxiv.org/pdf/2305.09520v1) | \- | 67.5 | \- | \- | 41.8 |
| Pix2Sturct [lee2023pix2struct](http://arxiv.org/pdf/2210.03347v2) | \- | 72.1 | 30.5 | 81.6 | 56.0 |
| mPLUG-DocOwl [ye2023mplug](http://arxiv.org/pdf/2403.14252v1) | \- | 62.2 | \- | \- | 57.4 |
| Matcha [liu2022matcha](http://arxiv.org/pdf/2212.09662v2) | \- | \- | 38.2 | 90.2 | 64.2 |
| Qwen-VL [qwen](http://arxiv.org/pdf/2309.16609v1) | \- | 65.1 | \- | \- | 65.7 |
| Vary-base (80k) | 78.2 | 76.3 | 43.2 | 87.3 | 65.3 |
| Vary-base (665k) | 78.1 | 76.3 | 43.8 | 88.3 | 66.1 |
Comparison with popular methods on DocVQA and ChartQA. 80k represents
that the SFT data is LLaVA-80k while 665k is the LLaVA-CC665k. The
metric of DocVQA is ANLS while the ChartQA is relaxed accuracy following
their vanilla papers.
## Downstream Task Performance
We test the performance improvement on downstream VQA tasks with
DocVQA [DocVQA](http://arxiv.org/pdf/2111.05547v1) and
ChartQA [masry2022chartqa](http://arxiv.org/pdf/2203.10244v1). We use the addition prompt:
"Answer the following questions using a single word or
phrase:" [liu2023improvedllava](http://arxiv.org/pdf/2310.19145v1) to allow the model to
output short and precise answers. As shown in
Table 1,
Vary-base (with Qwen-7B as LLM) can achieve 78.2% (test) and 76.3% (val)
ANLS on DocVQA upon LLaVA-80k [llava](http://arxiv.org/pdf/2402.11690v1) SFT data. With
LLaVA-665k [liu2023improvedllava](http://arxiv.org/pdf/2310.19145v1) data for SFT, Vary-base
can reach 66.1% average performance on ChartQA. The performance on both
two challenging downstream tasks is comparable to or even better than
Qwen-VL [Qwen-VL](http://arxiv.org/pdf/2308.12966v3), demonstrating the proposed vision
vocabulary scaling-up method is also promising for downstream.
## General Performance
We monitor the general performance of Vary through
MMVet [yu2023mm](http://arxiv.org/pdf/2402.15896v1) benchmark. As shown in
table 2,
with the same LLM (Vicuna-7B) and SFT data (LLaVA-CC665k), Vary lifts
2.4% (32.9% vs. 30.5%) of the total metric than LLaVA-1.5, proving that
our data and training strategy do not hurt the model’s general ability.
Besides, Vary with Qwen-7B and LLaVA-80k can achieve 36.2% performance,
further demonstrating the effectiveness of our vision vocabulary
scaling-up manner.
# Conclusion [discussion]
This paper highlights that scaling up the vocabulary in the visual
branch for an LVLM is quite significant and we successfully devise a
simple method to prove such a claim. According to the experiments, the
provided model, Vary, achieves promising scores in multiple tasks, which
is mainly profited by the new vocabulary we generated. Despite the
satisfactory performance of Vary, we believe that how to effectively
scale up the visual vocabulary still enjoys much improvement rooms,
especially compared to the mature and relatively simple means of
expanding text vocabulary. We hope that the useful and efficient design
of Vary will attract more research attention to such a direction.
# Appendix
In this appendix, we present the output results of our model to provide
a more intuitive understanding of its performance.
[^1]: Equal contribution
[^2]: Project leader
DocPedia: Unleashing the Power of Large Multimodal Model in the Frequency Domain for Versatile Document Understanding
2023-11-20
Hao Feng, Qi Liu, Hao Liu, Wengang Zhou, Houqiang Li, Can Huang
This work presents DocPedia, a novel large multimodal model (LMM) for versatile OCR-free document understanding, capable of parsing images up to 2,560$ times$2,560 resolution. Unlike existing work either struggle with high-resolution documents or give up the large language model thus vision or language ability constrained, our DocPedia directly processes visual input in the frequency domain rather than the pixel space. The unique characteristic enables DocPedia to capture a greater amount of visual and textual information using a limited number of visual tokens. To consistently enhance both perception and comprehension abilities of our model, we develop a dual-stage training strategy and enrich instructions/annotations of all training tasks covering multiple document types. Extensive quantitative and qualitative experiments conducted on various publicly available benchmarks confirm the mutual benefits of jointly learning perception and comprehension tasks. The results provide further evidence of the effectiveness and superior performance of our DocPedia over other methods.
Show Paper Content
# Introduction
Document understanding [srihari1986document](http://arxiv.org/pdf/2304.06447v5) is a
critical and challenging task that sits at the intersection of computer
vision and natural language processing. It involves the *perception* and
*comprehension* in terms of visual and textual content embedded within
document images. The difficulty of this task stems from the diverse and
complex formats of high-resolution documents, where the sparse or dense
texts are intertwined with graphics and tables. The accurate parsing of
documents not only propels the digitization of archival materials but
also facilitates the document automation in current data-rich world,
such as information
extraction [hwang2019post](None), [kim2022ocr](None), [luo2023geolayoutlm](None)
and visual question
answering [ye2023mplug](None), [feng2023unidoc](None), [ye2023ureader](None), [lv2023kosmos](None).
Many early
attempts [xu2021layoutxlm](None), [xu2020layoutlm](None), [huang2022layoutlmv3](None), [hong2022bros](http://arxiv.org/pdf/2108.04539v5), [bai2022wukong](None), [tang2023unifying](http://arxiv.org/pdf/2212.02623v3), [li2021structext](None), [peng2022ernie](None), [appalaraju2021docformer](None)
in the field follow a perceive-then-comprehend paradigm, initially
involving Optical Character
Recognition (OCR) [liao2020real](http://arxiv.org/pdf/1911.08947v2), [shi2016end](http://arxiv.org/pdf/1507.05717v1) of document
images, followed by the fusion of textual, layout, and visual features
for content parsing. However, the individual processing step of OCR may
precipitate the accumulation of errors. Furthermore, considering the
intrinsic interweaving of visual elements and textual segments within
documents, the reciprocity between perception and comprehension awaits
further exploration.
To attack the issue, OCR-free solutions have emerged as recent
prevailing approaches in the field. Among them, most models commonly
generate a sequence of tokens that can be converted into a target
string [ye2023mplug](None), [feng2023unidoc](None), [ye2023ureader](None), [zhang2023llavar](None), [ye2023mplug-doc](None)
or a structured format
data [kim2022ocr](None), [lv2023kosmos](None), [lee2023pix2struct](None). Such
generative models are skilled at synthesizing and rephrasing
information, which naturally can unveil the implicit content or purpose
behind the source material, as well as provide deeper insights and more
versatile responses to inquiries. As depicted in
Fig. 1,
they can be mainly categorized into three groups, namely (a)
*vision-constrained*, (b) *language-constrained*, and (c)
*unconstrained* types, described next.
Specifically, in vision-constrained methodologies such as
LLaVAR [zhang2023llavar](None),
mPLUG-DocOwl [ye2023mplug-doc](None), and
UniDoc [feng2023unidoc](None), the visual encoders largely rely
on a pre-trained CLIP-ViT [radford2021learning](http://arxiv.org/pdf/2404.19696v1),
operating at input resolutions of 224 or 336. These resolutions are
designed for images featuring texts in medium or large font sizes,
*e.g.*, scene text, but prove inadequate for text-intensive
high-resolution documents where more details are
indispensable [liu2023hidden](None). As shown in
Fig. 1 (a),
when a high-resolution supermarket receipt is downscaled to 224 for
model input, the text becomes unreadable, rendering these methods
incapable of answering the three presented instructions. In contrast,
language-constrained approaches, including
Donut [kim2022ocr](None),
KOSMOS-2.5 [lv2023kosmos](None), and
Pix2Struct [lee2023pix2struct](None), employ high-resolution
input for training their models with a vision encoder. They abandon the
use of large language models (LLMs) in vision-constrained
methods [zhang2023llavar](None), [ye2023mplug-doc](None), [feng2023unidoc](None),
and instead opt for a lightweight language
decoder [vaswani2017attention](http://arxiv.org/pdf/2107.08000v1). While these approaches
demonstrate promising perception ability, their comprehension
performance is often compromised. This is because the vital components
of robust logical reasoning and extensive world knowledge, typically
provided by the LLM, are not adequately incorporated. Taking
Fig. 1 (b)
for example, in response to the instruction Q2, these models falter in
providing accurate answers due to a deficiency in pertinent knowledge.
The *status quo* triggers a question: *Is there a feasible approach to
maintain both perception and comprehension abilities without
compromising vision and language?*
To mitigate the problem in above both categories, unconstrained
method [ye2023ureader](None) (Fig. 1 (c))
takes a further step by proposing a shape-adaptive cropping strategy.
This strategy involves cropping high-resolution images into patches,
which are then used in conjunction with a frozen low-resolution
CLIP-ViT [radford2021learning](http://arxiv.org/pdf/2404.19696v1) and LLM. However, this
heuristic-based crop strategy may lead to semantic discontinuities, even
after fusion is performed. Furthermore, the features extracted by
CLIP-ViT [radford2021learning](http://arxiv.org/pdf/2404.19696v1) are not well-suited for
tasks that require fine-grained local detail, such as text
detection [feng2023unidoc](None) or grounding (refer to Q3 in
Fig. 1
(c)).
To answer the question aforementioned, this work reinspects the problem
through the lens of frequency and proposes DocPedia, a novel yet
effective Large Multimodal Model (LMM), aiming to achieve versatile
OCR-free document understanding. DocPedia is capable of parsing
high-resolution document images up to
2,560$\times$``{=html}2,560, and harnessing the extensive world
knowledge and powerful inference capabilities offered by
LLMs [touvron2023llama](None), [chiang2023vicuna](None). This
integration aims to enhance both perception and comprehension aspects.
Technically, contrasting with previous LMMs in the filed, DocPedia
directly processes visual input in the frequency
domain [ahmed1974discrete](http://arxiv.org/pdf/1109.0337v1), [wallace1991jpeg](http://arxiv.org/pdf/1305.0020v1), [liu2023devil](http://arxiv.org/pdf/2204.08227v1), [liu2022nommer](None)
rather than the pixel space. This unique characteristic of the frequency
domain enables DocPedia to capture a greater amount of visual and
textual information using a limited number of visual tokens.
Employing this effective architecture, we train our DocPedia with two
phases: i) *text-aware pre-training* and ii) *context-aware
fine-tuning*. During the pre-training stage, the vision encoder is
trained to align the frequency domain features with a
LLM [chiang2023vicuna](None), incorporating various perception
tasks across both document and natural scene contexts, such as text
detection [liao2020real](http://arxiv.org/pdf/1911.08947v2),
spotting [liu2018fots](http://arxiv.org/pdf/1801.01671v2), paragraph reading, image
captioning [hossain2019comprehensive](http://arxiv.org/pdf/1810.04020v2), and *etc*. In the
subsequent fine-tuning stage, the focus shifts to the simultaneous
learning of perception and comprehension, *e.g.*, lower-level
reading-related tasks and higher-level document understanding. To ensure
the robustness of the model as well as a consistent response style, we
enrich the instructions and annotations of all these tasks with
GPT [brown2020language](http://arxiv.org/pdf/2112.07522v2). Extensive quantitative and
qualitative experiments are performed on this constructed large-scale
instruction tuning dataset covering multiple document types. The results
demonstrate the mutual benefits of jointly learning perception and
comprehension tasks.
The contributions are summarized as follows:
- To the best of our knowledge, we are the first to scale a large
multimodal model for document understanding tasks to the resolution
of 2,560$\times$``{=html}2,560.
- We innovatively transform image domain inputs into frequency ones,
enabling capturing more visual and textual information using a
limited number of visual tokens.
- We achieved superior performance on multiple publicly available
benchmark datasets and conducted extensive experiments to validate
the effectiveness of DocPedia.
# Related Work
In the following, we provide an overview of existing research in the
field of document understanding. This body of work is categorized into
two distinct types: OCR-driven and OCR-free methodologies, discussed
next.
## OCR-driven Document Understanding
This section outlines methods that initiate with text extraction from
document images, followed by the integration of textual, layout, and
visual features for thorough content analysis. Prominent among these are
the LayoutLM
series [xu2021layoutxlm](None), [xu2020layoutlm](None), [huang2022layoutlmv3](None),
which enhance text and layout modeling and integrate complex multimodal
pre-training for richer representation learning.
Wukong-Reader [bai2022wukong](None) employs pre-training
objectives to exploit the structural knowledge of document textlines,
incorporating textline-region contrastive learning for advanced visual
document understanding. StrucTexT [li2021structext](None)
combines a segment-token aligned encoder with diverse pre-training
tasks, targeting enhanced structured text analysis in visually rich
documents. DocFormer [appalaraju2021docformer](None) fuses
text, vision, and spatial information using a distinct transformer
architecture. However, the dependence of these methods on Optical
Character Recognition (OCR) can result in error accumulation, raising
efficacy concerns regarding the segregation of OCR in the context of the
intertwined nature of visual and textual elements in documents.
## OCR-free Document Understanding
To address this issue, prevailing OCR-free models excel in generating
token sequences for varied responses and structured information
synthesis, thereby offering enhanced insights and versatility in content
creation and inquiry response. Typically,
LLaVAR [zhang2023llavar](None) enhances document understanding
by improving interaction skills with humans and boosting performance on
text-rich image tasks, building upon its predecessor
LLaVA [liu2023visual](http://arxiv.org/pdf/2402.11690v1) with advanced visual instruction
tuning techniques. Based on the large multimodal model
mPLUG-Owl [ye2023mplug](None),
mPLUG-DocOwl [ye2023mplug-doc](None) integrates a unified
instruction tuning strategy across diverse document data.
UniDoc [feng2023unidoc](None) combines foundational OCR
learning with text-rich image comprehension tasks, markedly boosting
text scene image understanding. Despite their strong representational
skills and world knowledge from extensively pre-trained
CLIP-ViT [radford2021learning](http://arxiv.org/pdf/2404.19696v1) and large language models,
these methods are limited to processing images with larger, sparser text
due to the pre-trained visual models’ lower resolution constraints.
StrucTexTv2 [yu2023structextv2](None) employs self-supervised
pre-training for document images, adeptly integrating masked image and
language modeling [he2022masked](http://arxiv.org/pdf/2208.00173v1), [devlin2018bert](None) to
enhance performance. Donut [kim2022ocr](None) introduces an
end-to-end trainable model that overcomes OCR limitations by using a
synthetic document image generator for pre-training, enhancing
performance in document understanding tasks.
Pix2Struct [lee2023pix2struct](None) through its unique
pretraining on web page screenshots parsed into HTML, introduces a
variable-resolution input and integrated language-vision approach. As an
evolution of Kosmos-2 [peng2023kosmos](None),
Kosmos-2.5 [lv2023kosmos](None) processes text-rich images,
skillfully blending spatial text block creation and structured markdown
generation in a streamlined, decoder-only model.
UReader [ye2023ureader](None) innovatively employs a
shape-adaptive cropping module for high-resolution image processing.
While these work exhibit outstanding outcomes in various aspects, they
either struggle with handling high-resolution input or face challenges
due to a lack of world knowledge. This underscores the future research
endeavors: the development of an intelligent system adept at handling
documents of various types and resolutions.
# Method
Fig. [fig:overview] presents an overview of
DocPedia. It consists of two training phases: (a) text-aware
pre-training to align the visual features from the frequency domain to
the large language model, and (b) context-aware fine-tuning for learning
the parsing of documents. In the following, we first delineate the
network architecture of DocPedia, followed by a detailed exposition of
its two training phases.
## Architecture of DocPedia
Given an input RGB document image, we first resize it to our designated
training scale of $H\times W$ to obtain the image $\bm{I}$. By default,
both $H$ and $W$ are set as 2,560. Here we preserve the aspect ratio
during the resizing process to prevent distortion of textual elements.
Then, as shown in Fig. 2, we apply the JPEG DCT
extraction [ahmed1974discrete](http://arxiv.org/pdf/1109.0337v1), [wallace1991jpeg](http://arxiv.org/pdf/1305.0020v1) to
retrieve the DCT coefficients for the $\bm{Y}$, $\bm{Cb}$, and $\bm{Cr}$
channels. The DCT coefficients are scaled down due to
8$\times$``{=html}8 block processing for the luminance component
($\bm{Y}$) and additional chroma subsampling for color components
($\bm{Cb}$ and $\bm{Cr}$), resulting in $\frac{1}{8}$ and $\frac{1}{16}$
scales respectively. Each of them features $C$ channels. After that, we
upscale $\bm{Cb}$ and $\bm{Cr}$ to a $\frac{1}{8}$ scale based on
bilinear interpolation, followed by a concatenation along the channel
dimension. Subsequent to this is a 1$\times$``{=html}1
convolutional layer, employed to map the channel dimension of the
concatenated map to that of the following backbone’s input. Through
these operations, we acquire the frequency domain counterpart of image
$\bm{I}$, denoted as $\bm{F}$.
Next, we feed $\bm{F}$ into the Swin
Transformer [liu2021swin](http://arxiv.org/pdf/2306.13776v1), a visual backbone that
leverages shifted windowing schemes to efficiently model spatial
hierarchies. In our implementation, we remove the 1/4 scale downsampling
module originally present before stage 1. The output of the visual
backbone is a feature map downsampled by a factor of 1/64. It is
subsequently flattened, resulting in $\frac{H}{64}\times \frac{W}{64}$
tokens, each with a dimensionality of 1,024. Drawing inspiration from
the paradigms of advanced large multimodal
models [zhu2023minigpt](None), [liu2023visual](http://arxiv.org/pdf/2402.11690v1), we employ a linear
layer to align these tokens with the input token dimension of the
following large language model [chiang2023vicuna](None).
Finally, the dimensionally aligned visual tokens are concatenated with
the tokens transformed from the language instructions. This concatenated
sequence is then fed into the LLM, generating the output response.
## Text-aware Pre-training [sec:pre]
To develop a vision encoder capable of processing frequency domain
representation input and align it with the feature space of the
following large language model [chiang2023vicuna](None), we
first undertook extensive text-aware pre-training. During this stage, we
freeze the large language model, focusing on the optimization of the
vision encoder and its subsequent linear projector, as illustrated in
Fig. [fig:overview].
Specifically, our pre-training encompassed a variety of perception
tasks, including text detection [liao2020real](http://arxiv.org/pdf/1911.08947v2),
recognition [wang2011end](http://arxiv.org/pdf/1811.10003v1),
spotting [liu2018fots](http://arxiv.org/pdf/1801.01671v2), paragraph reading, full-text
reading [kim2022ocr](None), and image
captioning [hossain2019comprehensive](http://arxiv.org/pdf/1810.04020v2). The first three
tasks are foundational OCR tasks. “Paragraph reading" denotes the
reading of the text within a specified bounding box (see bottom case in
Fig. 3), whereas “full-text reading"
refers to deciphering all text in the image. It is worth noting that the
first five tasks focus on a diverse array of document images, while the
final task targets natural scene images. This comprehensive pre-training
enables the vision encoder of our DocPedia to effectively perceive
textual and visual information from both document and natural scene
images.
| **Stage** | **Image** | **Instruction** | **Task** | **\# Conv** | |
|:--:|:--:|:--:|:--:|:--:|:--:|
| Pre-training | Scene | LLaVA [liu2023visual](http://arxiv.org/pdf/2402.11690v1) | $\mathcal{C}$ | 595K | |
| | PDF | OCR | $\mathcal{D},\mathcal{R},\mathcal{S},\mathcal{R}_p,\mathcal{R}_f$ | 325K | |
| | PPT | OCR | $\mathcal{D},\mathcal{R},\mathcal{S},\mathcal{R}_p,\mathcal{R}_f$ | 600K | |
| Fine-tuning | PDF | OCR | $\mathcal{D},\mathcal{R},\mathcal{S},\mathcal{R}_p,\mathcal{R}_f$ | 325K | |
| | PPT | OCR | $\mathcal{D},\mathcal{R},\mathcal{S},\mathcal{R}_p,\mathcal{R}_f$ | 600K | |
| | Scene | LLaVA [liu2023visual](http://arxiv.org/pdf/2402.11690v1) | $\mathcal{U}$ | 158K | |
| | Benchmark | GPT | $\mathcal{U}$ | 370K | |
Summary of the training data statistics across two stages. The symbols
represent various instruction-following tasks as follows: $\mathcal{D}$
for text detection, $\mathcal{R}$ for text recognition, $\mathcal{S}$
for text spotting, $\mathcal{R}_p$ for paragraph reading,
$\mathcal{R}_f$ for full-text reading, $\mathcal{C}$ for image
captioning, and $\mathcal{U}$ for document understanding.
## Context-aware Fine-tuning
In the fine-tuning phase, we concurrently cultivate the perception and
comprehension capabilities of DocPedia. Concretely, within each batch of
training data, one half is dedicated to the five types of OCR tasks
outlined in the pre-training phase, while the other half comprises tasks
that demand a higher level of semantic understanding related to
document [mathew2021docvqa](None) and
scene [liu2023visual](http://arxiv.org/pdf/2402.11690v1). We argue that the concurrent
learning of lower-level perceptual abilities and the cultivation of
higher-level understanding capabilities can maximize the performance of
the model. During this stage, we unfreeze the LLM and fine-tune the
entire model.
# Dataset Construction
To train our DocPedia, we construct a large-scale multimodal instruction
following dataset. The statistical data employed during the pre-training
and fine-tuning phases are summarized in
Table 1. We detail them in the
following.
| **Type** | **Example** |
|:---|:---|
| Detection | “Where are the texts located in the photo?" |
| Recognition | “Recognize all the text in this image." |
| Spotting | “Identify all the text in the shot return their coordinates in the format of \[x1,y1,x2,y2\]." |
| Paragraph Reading | “Tell me about the content in the area marked as \[0.124,0.276,0.353,0.487\] of the frame." |
| Full Text Reading | “Convey the entire content of this pic to me." |
Different types of OCR instructions and their examples.
## Pre-training
During the pre-training phase, our focus was on the learning of
perceptual abilities, particularly in the context of text perception. As
illustrated in Table 1, we amassed a dataset comprising 600,000
PowerPoint (PPT) images and 325,000 PDF images. The PowerPoint images
are sourced from the “Common Crawl" dataset[^3], an extensive web corpus
encompassing publicly accessible web pages. The PDF images are sourced
from arXiv[^4], an established online platform for scientists to publish
pre-print research papers.
For each of these images, we randomly selected an Optical Character
Recognition (OCR) task type as described in
Sec. 3.2 and then constructed corresponding
instructions and responses [feng2023unidoc](None). On one hand,
to ensure instruction diversity, we generated multiple variations of
instructions for each OCR task using
GPT-3.5 [brown2020language](http://arxiv.org/pdf/2112.07522v2). In
Table 2, we present one exemplar for
each of the five text-aware perceptual tasks. For further examples,
please refer to the supplementary materials. On the other hand, for
their responses, we employed a standardized format (see
Fig. 3). In addition to the aforementioned
data, we enriched our dataset with 595,000 caption entries from
LLaVA [liu2023visual](http://arxiv.org/pdf/2402.11690v1), aiming to enhance the DocPedia’s
perceptual abilities in natural scenes.
## Fine-tuning
Furthermore, during the fine-tuning phase, we first employed the same
data utilized during the pre-training phase, comprising 325,000 PDF and
600,000 PPT images. Building upon this, we introduced an extra 370,000
entries from seven visual question answering benchmark datasets,
including DocVQA [mathew2021docvqa](None),
OCRVQA [mishra2019ocr](None),
TextVQA [singh2019towards](None),
InfoVQA [mathew2022infographicvqa](None),
ChartVQA [masry2022chartqa](None),
FigureVQA [kahou2017figureqa](None), and PlotVQA. Notably, as
the responses in these datasets are typically concise, containing only
the answer itself, we employed
GPT-3.5 [brown2020language](http://arxiv.org/pdf/2112.07522v2) to expand these responses
into complete sentences. This adaptation was done to align with the
characteristic comprehensive and detailed response style of large
language models [chiang2023vicuna](None). Besides, we
supplemented the training data with 158,000 instruction tuning data for
natural scene understanding from LLaVA [liu2023visual](http://arxiv.org/pdf/2402.11690v1).
Our experiments demonstrate the effectiveness of a fine-tuning strategy
that concurrently learns perceptual and understanding abilities.
# Experiment
## Implementation Details
To implement DocPedia, we adopted a one-cycle learning rate
strategy [smith2019super](http://arxiv.org/pdf/1708.07120v3). For the pre-training phase,
the peak learning rate was established at 1e-3, which was set as 1e-5
during the subsequent fine-tuning phase. We maintained batch sizes of 64
and 8 for the pre-training and fine-tuning stages, respectively. We
employ the AdamW optimizer [loshchilov2017decoupled](http://arxiv.org/pdf/2311.11446v2) and
both training stages were performed on eight A100 GPUs, each spanning
just a single epoch.
For performance assessment, a temperature parameter of 0.2 was utilized
in both quantitative and qualitative evaluations. We adopted the
accuracy metric, where a response generated by the model is considered
correct if it contains the string present in the ground
truth [liu2023hidden](None).
## Results
We further conducted both quantitative and qualitative evaluations of
the current state-of-the-art multimodal large-scale models in comparison
to our proposed method.
**Qualitative results.** We qualitatively evaluate DocPedia’s perception
and comprehension capabilities on high-resolution scene text and
document images. Firstly, in terms of the perception capabilities, as
illustrated in Fig. 3, our DocPedia can accurately locate
and identify text in both scenes and high-resolution documents, which is
attributed to the training of fundamental OCR tasks in
Table 1. Secondly, regarding
comprehension abilities, as demonstrated in
Fig. [fig:demo], the examples in the first two
rows indicate that DocPedia can perceive and understand the visual and
textual information in images to provide accurate responses, based on
the intention of the instructions. Moreover, the examples in the bottom
row illustrate that DocPedia is capable of integrating the content of
instructions, visual and textual information within images, and its
large language model’s rich world knowledge to formulate responses.
These results demonstrate DocPedia’s robust multimodal comprehension
capabilities. For additional examples, please refer to the supplementary
materials.
**Quantitative results.** Furthermore, we conduct a quantitative
evaluation of existing large multimodal models and our DocPedia. The
results are summarized in
Table [tab:per_com]. The benchmarks used for
this assessment consist of 3 Key Information Extraction (KIE) datasets,
including FUNSD [jaume2019funsd](http://arxiv.org/pdf/1905.13538v2),
SROIE [huang2019icdar2019](None) as well as
POIE [kuang2023visual](http://arxiv.org/pdf/2102.06732v1), and 6 Visual Question Answering
(VQA) datasets, including DocVQA [mathew2021docvqa](None),
ChartVQA [masry2022chartqa](None),
STVQA [biten2019icdar](None),
OCRVQA [mishra2019ocr](None),
TextVQA [singh2019towards](None), and
InfoVQA [mathew2022infographicvqa](None).
As we can see, on several high-resolution document image
benchmarks [jaume2019funsd](http://arxiv.org/pdf/1905.13538v2), [huang2019icdar2019](None), [kuang2023visual](http://arxiv.org/pdf/2102.06732v1), [mathew2021docvqa](None), [masry2022chartqa](None),
where the text is dense and tiny, our DocPedia demonstrates significant
performance improvements over existing state-of-the-art multimodal large
models. Notably, compared to the state-of-the-art LMMs, DocPedia
achieved an increase in accuracy by 40.20$\%$ on
DocVQA [mathew2021docvqa](None) and 28.67$\%$ on
FUNSD [jaume2019funsd](http://arxiv.org/pdf/1905.13538v2), respectively. These results
underscore the distinct advantages of our approach. Moreover, our method
also achieved considerable improvements on high-resolution scene text
benchmarks [biten2019icdar](None), [mishra2019ocr](None), [singh2019towards](None), [mathew2022infographicvqa](None),
though the enhancements were less pronounced. This can be attributed to
two primary factors: firstly, our pre-trained vision encoder was not
exposed to large-scale natural scene data as extensively as pre-trained
Vision Transformer (ViT) [radford2021learning](http://arxiv.org/pdf/2404.19696v1) employed
in previous
LMMs [feng2023unidoc](None), [zhu2023minigpt](None), [liu2023visual](http://arxiv.org/pdf/2402.11690v1);
secondly, in such images, the text often appears more sparsely and is
generally larger compared to the dense and tiny textual content in
document images.
## Ablation Studies
We further conduct ablation studies to validate the efficacy of core
settings and components in DocPedia. Note that all experiments were
conducted on two benchmark datasets:
DocVQA [mathew2021docvqa](None) and
TextVQA [singh2019towards](None).
DocVQA [mathew2021docvqa](None) is centered around document
comprehension, whereas TextVQA [singh2019towards](None) focuses
on scene text image understanding. Both datasets are notable for their
substantial sample sizes, comprising 5,000 and 5,349 test samples,
respectively.
| Method | | | VQA | |
|:--:|:--:|:--:|:--:|:--:|
| 1-3(lr)4-5 Input | Resolution | Tokens | DocVQA [mathew2021docvqa](None) | TextVQA [singh2019towards](None) |
| RGB | 640$\times$``{=html}640 | 400 | 13.78 | 27.56 |
| RGB | 960$\times$``{=html}960 | 900 | 21.15 | 41.18 |
| RGB | 1280$\times$``{=html}1280 | 1600 | 29.54 | 48.80 |
| DCT | 1280$\times$``{=html}1280 | 400 | 21.09 | 45.05 |
| DCT | 1920$\times$``{=html}1920 | 900 | 37.83 | 53.35 |
| DCT | 2560$\times$``{=html}2560 | 1600 | **47.08** | **60.18** |
Ablation experiments regarding the use of various resolutions in the RGB
domain and frequency domain as inputs for the vision encoder in
DocPedia. “Tokens" refers to the number of tokens outputted by the
vision encoder.
| Pre-training | Fine-tuning | | VQA | |
|:--:|:--:|:--:|:--:|:--:|
| 2-3(lr)4-5 | Perception | Understanding | DocVQA [mathew2021docvqa](None) | TextVQA [singh2019towards](None) |
| | | | 21.59 | 34.17 |
| | | | 27.13 | 48.47 |
| | | | **37.83** | **53.35** |
Ablation experiments concerning the training strategies of DocPedia
during the pre-training and fine-tuning phases. All ablations are
conducted at a resolution of 1,920$\times$``{=html}1,920.
**Impact of training in the frequency domain.** One of the significant
contributions of our DocPedia lies in utilizing the frequency domain
representation of images as the input for the vision encoder. In
Table 3,
we evaluate our method’s performance using image inputs and frequency
domain inputs on varying scales. For image inputs, three resolution
settings were evaluated: 640, 960, and 1,280. Given that the backbone
Swin [liu2021swin](http://arxiv.org/pdf/2306.13776v1) downsamples input by a factor of 32,
the resultant token counts are 400, 900, and 1,600, respectively. In
experiments with our frequency domain inputs, we tested image
resolutions of 1,280, 1,920, and 2,560 for the DCT, resulting in token
counts corresponding to the three image-based experimental settings.
As we can see, with the same number of visual tokens, our DocPedia
yields better performance. This is attributed to the increased
resolution enabling enhanced perception of texture content within
images. In experiments where the input resolution is constant (1,280 in
Table 3),
we observe a slightly enhanced performance with image inputs compared to
frequency ones. Note that the number of visual tokens for the latter is
only a quarter of that used for the former. This is likely because our
frequency-based approach retains a limited number of tokens, leading to
some information loss. However, this constraint simultaneously
facilitates the incorporation of higher-resolution inputs, up to
2,560$\times$``{=html}2,560.
In Fig. 4, we further compare the responses of
DocPedia to the same academic image and instruction under varying input
resolutions. It is observed that the response becomes accurate when the
input resolution reaches 2,560.
**Impact of the training strategy.** We further study the impact of our
training strategies. Initially, we omitted the pre-training phase,
opting instead for a random initialization of the vision encoder. In
Table 4,
significant performance degradation was observed in the absence of
pre-training, underscoring the critical role of feature alignment
between the vision encoder and subsequent
LLM [chiang2023vicuna](None).
Additionally, we examined the fine-tuning strategies. Under default
settings, we concurrently learn perceptual and understanding
capabilities, incorporating tasks OCR, image captioning, document
understanding, and scene comprehension. Subsequently, we eliminated the
OCR and image captioning from the fine-tuning. The results clearly
indicated a notable decline in performance, affirming the efficacy of
our joint training strategy. This implies that the simultaneous
development of foundational perceptual skills augments the acquisition
of comprehension abilities.
## Limitation Discussion
Furthermore, we discuss the limitations of our DocPedia. Firstly, as
illustrated in Table [tab:per_com], we observe minimal
performance improvements on the InforVQA
dataset [mathew2022infographicvqa](None). This highlights one
of the constraints of DocPedia. Many images in
InforVQA [mathew2022infographicvqa](None) possess extremely
high aspect ratios, akin to vertically concatenating multiple pages of
images, with some even reaching dimensions of
6,400$\times$``{=html}800. In addition, our DocPedia currently
lacks the capability to process multi-page document
images [tito2023hierarchical](None) and also exhibits a
deficiency in multilingual proficiency [Qwen-VL](None).
# Conclusion
This work introduces DocPedia, an innovative Large Multimodal Model
tailored for versatile OCR-free document understanding, capable of
handling images with high resolutions. Unlike existing methods, DocPedia
directly processes visual input in the frequency domain, where more
visual and textual information is captured in a limited number of visual
tokens. Thanks to the dual-stage training strategy designed and the
polished instructions/annotations for all tasks, DocPedia shows superior
performance on several public datasets. In conclusion, we provide a
successful attempt at pathways for handling complex high-resolution
documents. We expect our success in exploring LMM dealing with
high-resolution images from frequency perspective could trigger more
insights for the community.
[^1]: Equal contribution. $\spadesuit$ $\ddag$
[^2]: Corresponding authors: Wengang Zhou and Can Huang.
[^3]: https://commoncrawl.org/
[^4]: https://arxiv.org/
Monkey: Image Resolution and Text Label Are Important Things for Large Multi-modal Models
2023-11-11
Zhang Li, Biao Yang, Qiang Liu, Zhiyin Ma, Shuo Zhang, Jingxu Yang, Yabo Sun, Yuliang Liu, Xiang Bai
Large Multimodal Models (LMMs) have shown promise in vision-language tasks but struggle with high-resolution input and detailed scene understanding. Addressing these challenges, we introduce Monkey to enhance LMM capabilities. Firstly, Monkey processes input images by dividing them into uniform patches, each matching the size (e.g., 448x448) used in the original training of the well-trained vision encoder. Equipped with individual adapter for each patch, Monkey can handle higher resolutions up to 1344x896 pixels, enabling the detailed capture of complex visual information. Secondly, it employs a multi-level description generation method, enriching the context for scene-object associations. This two-part strategy ensures more effective learning from generated data: the higher resolution allows for a more detailed capture of visuals, which in turn enhances the effectiveness of comprehensive descriptions. Extensive ablative results validate the effectiveness of our designs. Additionally, experiments on 18 datasets further demonstrate that Monkey surpasses existing LMMs in many tasks like Image Captioning and various Visual Question Answering formats. Specially, in qualitative tests focused on dense text question answering, Monkey has exhibited encouraging results compared with GPT4V. Code is available at https://github.com/Yuliang-Liu/Monkey.
Show Paper Content
# Introduction [sec:intro]
The field of large multimodal models (LMMs) is advancing quickly because
of their skill in handling different types of data, like images and
text. Their success in various tasks, including image captioning and
visual question answering, is attracting attention in the academic
community.
Training LMMs benefits greatly from high-resolution images
[bai2023qwen-vl](http://arxiv.org/pdf/1412.3919v1), because higher resolution allows these
models to detect more nuanced visual details, leading to accurate
recognition of objects, their interrelationships, and the broader
context within the image. Additionally, the improved visual clarity of
high-resolution images aids in effectively capturing and representing
complex details essential for detailed captioning. Despite advancements,
handling the wide range of image resolutions and training data quality
is still challenging, especially in complex situations. Solutions
include using pre-trained visual modules with larger input resolution
(like LLaVA1.5 [liu2023llava1.5](http://arxiv.org/pdf/2310.19145v1) ) and gradually
increasing the resolution of the training process through curriculum
learning (like Qwen-VL [bai2023qwen-vl](http://arxiv.org/pdf/1412.3919v1),
PaLI-3 [chen2023pali-3](http://arxiv.org/pdf/2310.09199v2) and
PaLI-X [chen2023pali-x](http://arxiv.org/pdf/2109.04653v1)) have been explored, but they
demand significant training resources and still face challenges in
handling larger image sizes. To fully leverage the benefits of large
input resolution, it is crucial to have more detailed image
descriptions, which can enhance the understanding of image-text
relationships. However, the short captions in widely used datasets such
as COYO [kakaobrain2022coyo-700m](https://github.com/kakaobrain/coyo-dataset) and
LAION [schuhmann2022laion](http://arxiv.org/pdf/2312.15897v1) are usually intuitively
insufficient.
We introduce Monkey, a resource-efficient approach to increase input
resolution within the Large Multimodal Model frameworks. Compared to the
approach of directly interpolating the ViT to increase input resolution,
Monkey utilizes a new module that divides high-resolution images into
smaller patches using a sliding window method. Each patch is processed
independently by a static visual encoder, enhanced with
LoRA [hu2021lora](http://arxiv.org/pdf/2402.11485v1) adjustments and a trainable visual
resampler. This technique leverages existing LMMs while circumventing
the need for extensive pre-training. The key idea is that these encoders
are typically trained on smaller resolutions (like
448$\times$``{=html}448), which is costly to train from scratch.
By resizing each patch to its supported resolution, we maintain the
training data distribution for the encoder. Our method, which uses
various trainable patches to enhance resolution, shows a clear advantage
over traditional interpolation techniques for positional embedding, as
demonstrated by our quantitative analysis.
To further leverage the advantage of large resolution, we have also
proposed an automatic multi-level description generation method. This
method is designed to produce high-quality, abundant caption data by
seamlessly combining insights from multiple generators. It utilizes the
strengths of a diverse array of advanced systems:
BLIP2 [li2023blip2](http://arxiv.org/pdf/2301.12597v3), known for its nuanced image-text
understanding; PPOCR [du2020pp](http://arxiv.org/pdf/2109.03144v2), a robust optical
character recognition system; GRIT [wu2022grit](https://arxiv.org/pdf/2212.00280), which
excels in granular image-text alignments; SAM [sam](http://arxiv.org/pdf/2305.01275v1), a
dynamic model for semantic alignment; and
ChatGPT [chatgpt](https://openai.com/blog/chatgpt/), an AI renowned for its contextual
understanding and language generation capabilities. By integrating the
unique capabilities of these systems, our method offers a comprehensive
and layered approach to caption generation, capturing a wide spectrum of
visual details.
We summarize the advantages of the Monkey as follows:
1. **Support resolution up to 1344$\times$``{=html}896 without
pretraining**. By going beyond the usual
448$\times$``{=html}448 resolution used in LMMs, the higher
resolution helps to better identify and understand small or closely
grouped objects and dense text.
2. **Contextual associations**. We introduce a multi-level description
generation method that improves the model’s ability to grasp the
relationships among multiple targets and more effectively utilize
common knowledge in generating text descriptions.
3. **Performance enhancements on many evaluation datasets**. As shown
in Fig. 1, we carried out testing across 18
diverse datasets, leading to a very competitive performance by our
Monkey model in tasks such as Image Captioning, General Visual
Question Answering, Scene Text-centric Visual Question Answering,
and Document-oriented Visual Question Answering. In particular,
during qualitative evaluations centered on dense text question
answering, Monkey has shown promising results, comparing with GPT4V.
# Related Work [sec:related]
The Large Multimodal Models (LMMs) field has seen significant progress,
particularly in enhancing visual and language processing. Methods like
Flamingo [alayrac2022flamingo](http://arxiv.org/pdf/2205.07065v1) and
OpenFlamingo [awadalla2023openflamingo](http://arxiv.org/pdf/2402.17510v1) have advanced
visual representation by integrating a Perceiver Resampler with vision
encoders. BLIP2 [li2023blip2](http://arxiv.org/pdf/2301.12597v3) employs a Q-Former to link
the frozen LLM and vision encoder.
Unified-IO [lu2022unified](http://arxiv.org/pdf/2309.13885v1) demonstrates versatility by
training across over 80 diverse datasets, widening its domain
applicability. PaLM-E [driess2023palm-e](http://arxiv.org/pdf/2302.14030v3) adopts a unique
approach by treating images and text as “multimodal sentences” to
improve visual-language tasks. MiniGPT4 [zhu2023minigpt4](http://arxiv.org/pdf/2402.17510v1)
bridges visual modules and LLMs, enhancing multimodal capabilities.
InstructBLIP [dai2023instructblip](None), starting from BLIP2,
adds instructional inputs to the Q-Former for task-relevant visual
features. MME [fu2023mme](http://arxiv.org/pdf/2306.05179v2) introduces a benchmark for
evaluating LMMs’ perception and cognition.
Additionally, there has been significant progress in leveraging large
language models. The LLaVA series, including
LLaVA [liu2023llava](http://arxiv.org/pdf/2402.11690v1) and
LLaVA1.5 [liu2023llava1.5](http://arxiv.org/pdf/2310.19145v1), align vision encoders and
LLMs for better image-text understanding.
mPLUG-Owl [ye2023mplug](http://arxiv.org/pdf/2405.00390v2) focuses on fine-tuning with mixed
text and visual-text data. mPLUG-Owl2 [ye2023mplugowl2](https://arxiv.org/pdf/2311.04257)
introduces shared modules for better modality collaboration.
KOSMOS-2 [peng2023kosmos2](http://arxiv.org/pdf/2305.16103v1) enables visual answers like
detection boxes. Shikra [chen2023shikra](http://arxiv.org/pdf/2306.15195v2) specializes in
Referential Dialogue, adept at processing positional inputs and outputs.
BLiVA [hu2023bliva](http://arxiv.org/pdf/2308.09936v3) combines task-related and global
features for enhanced multimodal task processing.
Qwen-VL [bai2023qwen-vl](http://arxiv.org/pdf/1412.3919v1) improves visual module
resolution to 448. OtterHD [li2023otterhd](https://arxiv.org/pdf/2311.04219) fine-tunes
Fuyu-8B [fuyu-8b](https://www.adept.ai/blog/fuyu-8b) with instruction/response pairs,
maintaining the original image size during inference.
Despite these advancements, challenges remain in extracting finer image
features, as noted by [liu2023hidden](http://arxiv.org/pdf/2305.07895v5), [xu2023lvlm](http://arxiv.org/pdf/2308.14353v1), which
indicate the need for ongoing development in the field.
# Methods
Fig. [fig:architecture] illustrates the
comprehensive architecture of Monkey. Initially, the input image is
segmented into patches. These patches are then processed through a
shared Vision Transformer (ViT) equipped with distinct adapters.
Subsequently, both local and global features, along with the question,
are processed using the shared resampler and the Large Language Model
(LLM), resulting in the generation of the desired answers.
## Enhancing Input Resolution
Input resolution is crucial for accurately interpreting text and
detailed image features. Previous
studies [bai2023qwen-vl](http://arxiv.org/pdf/1412.3919v1), [chen2023pali-3](http://arxiv.org/pdf/2310.09199v2) have shown the
effectiveness of starting with smaller resolutions and progressively
advancing to larger ones through curriculum learning. However, this
approach can be highly resource-demanding, often necessitating
comprehensive pretraining with large-scale data (as seen in Qwen-VL,
which supports resolutions up to 448$\times$``{=html}448). To
address these issues and efficiently enhance resolution, we introduce a
simple yet more effective technique.
Given an image $I \in \mathbb{R}^{H\times W \times 3}$, we employ a
sliding window $W \in \mathbb{R}^{H_v\times W_v}$ (where $H_v, W_v$
denote the supported resolution of the original LMM) to partition the
image into smaller, local sections. We also leverage
LoRA [hu2021lora](http://arxiv.org/pdf/2402.11485v1) within each shared encoder to address
the varied visual elements in different parts of an image. This
integration of LoRA is to help our encoders to recognize and assimilate
detail-sensitive features from each image area effectively, which
enhances the understanding of spatial and contextual relationships
without a substantial increase in parameters or computational demand.
To preserve the overall structural information of input image, we resize
the original image to dimensions ($H_v, W_v$), maintaining it as a
global image. Following this, both the individual patches and the global
image are processed through the visual encoder and resampler
concurrently. Here, the visual resampler, inspired by
Flamingo [alayrac2022flamingo](http://arxiv.org/pdf/2205.07065v1), is a mechanism that
performs two main functions: summarizing visual information and
obtaining higher semantic visual representations in a language feature
space. It achieves this by leveraging a cross-attention module. The
module employs trainable vectors (embeddings) as query vectors, along
with image features from the visual encoder serving as keys for
cross-attention operations.
This approach strikes a balance between detailed and holistic
perspectives of the images, thereby enhancing the model performance
while avoiding a substantial increase in computational demand.
## Multi-level Description Generation
Previous models such as LLaVA [liu2023llava](http://arxiv.org/pdf/2402.11690v1) and
Qwen-VL [bai2023qwen-vl](http://arxiv.org/pdf/1412.3919v1) used large datasets like
LAION [schuhmann2022laion](http://arxiv.org/pdf/2312.15897v1),
COYO [kakaobrain2022coyo-700m](https://github.com/kakaobrain/coyo-dataset), and
CC3M [sharma-etal-2018-conceptual](https://doi.org/10.18653/v1/P18-1238) for their initial
training. However, these datasets often offer image-text pairs that are
too simple (e.g., one short sentence to describe a complicated image),
lacking in detailed imagery. As a result, even when these models are
trained with high-resolution images, they struggle to accurately link
visual features with basic captions. This limitation affects the models
to effectively combine visual processing with language understanding.
To bridge this gap, we develop a novel approach for generating
multi-level descriptions automatically. This technique is designed to
create rich and high-quality caption data by effectively blending the
outputs from various generators. We utilize a combination of several
advanced systems, each bringing its own strength to the process:
BLIP2 [li2023blip2](http://arxiv.org/pdf/2301.12597v3), which provides a deep understanding
of the relationship between images and text;
PPOCR [du2020pp](http://arxiv.org/pdf/2109.03144v2), a strong performer in optical character
recognition; GRIT [wu2022grit](https://arxiv.org/pdf/2212.00280), specializing in detailed
image-text matching; SAM [sam](http://arxiv.org/pdf/2305.01275v1), focused on semantic
alignment; and ChatGPT [chatgpt](https://openai.com/blog/chatgpt/), known for its
exceptional ability in contextual language generation.
As shown in Fig. [fig:generation], the image
description process begins with BLIP2 creating overall captions using a
Q-former for tight integration with the vision encoder and LLM, while
retaining original CC3M annotations for context. Next, GRIT, a
region-to-text model, generates detailed descriptions of specific
regions, objects, and their characteristics. PPOCR extracts text from
the images, and SAM segments and identifies objects and their parts.
These objects are then individually described by BLIP2. However, to
counter potential inaccuracies from these tools, especially in zero-shot
settings, we find it essential to further use BLIP2 to check for
consistency between image areas, objects, and their descriptions,
filtering out low-scoring matches. Finally, all data, including global
captions, localized descriptions, text extracts, and object details with
spatial coordinates, are fed into the ChatGPT API for fine-tuning,
enabling ChatGPT to generate accurate and contextually rich image
descriptions.
By merging the unique features of these systems, our approach achieves a
layered and comprehensive style of caption creation. It captures an
extensive range of visual and textual nuances, resulting in captions
that are not just elaborate, but also contextually diverse and engaging.
## Multi-task Training
Our goal is to train a model that is both cost-effective and capable of
understanding different types of images for various tasks. By
integrating various datasets and employing uniform instructions for all
tasks, as guided by [bai2023qwen-vl](http://arxiv.org/pdf/1412.3919v1), we enhance the
model’s learning ability and training efficiency.
We focus on tasks such as creating image captions, responding to
image-based questions, and other activities requiring the model to
process both text and images. For captioning, we instruct the model with
“Generate the caption in English:” for basic captions, and “Generate the
detailed caption in English:” for more intricate ones. When it comes to
answering questions about images, we use a straightforward format:
“{question} Answer: {answer}.”
In our training process, we use a variety of public datasets tailored to
specific tasks. For image captioning, we include both our own detailed
captions and established datasets like COCO
caption [karpathy2015coco](http://arxiv.org/pdf/1412.2306v2) and
TextCaps [textcaps](https://arxiv.org/pdf/2003.12462). For general Visual Question
Answering (VQA), we utilize datasets such as
VQAV2 [goyal2017making](http://arxiv.org/pdf/1612.00837v3),
OKVQA [marino2019ok](http://arxiv.org/pdf/1906.00067v2), GQA [hudson2019gqa](http://arxiv.org/pdf/2112.05136v1),
ScienceQA [lu2022learn](http://arxiv.org/pdf/2209.09513v2), and
VizWiz [gurari2018vizwiz](http://arxiv.org/pdf/1802.08218v4). For Text-centric VQA tasks, we
select TextVQA [singh2019towards](http://arxiv.org/pdf/1811.11903v1),
OCRVQA [mishra2019ocr](http://arxiv.org/pdf/2010.02582v1), and
AI2D [kembhavi2016diagram](http://arxiv.org/pdf/1603.07396v1); while for document-related
VQA, we employ datasets like DocVQA [mathew2021docvqa](http://arxiv.org/pdf/2111.05547v1),
ChartQA [masry2022chartqa](http://arxiv.org/pdf/2203.10244v1),
InfoVQA [mathew2022infographicvqa](http://arxiv.org/pdf/2104.12756v2),
DeepForm [deepform](http://arxiv.org/pdf/2303.13839v1), Kleister Charity
(KLC) [stanislawek2021kleister](http://arxiv.org/pdf/2003.02356v2), WikiTableQuestions
(WTQ) [pasupat2015compositional](http://arxiv.org/pdf/2009.13845v2),
TableFact [chen2019tabfact](http://arxiv.org/pdf/2311.06592v1), and
VisualMRC [tanaka2021visualmrc](http://arxiv.org/pdf/2101.11272v2). To ensure balanced
training, we control the image count for each task as detailed in
Tab. [tab:data]. Our compiled dataset, with
around 1.44 million examples, is designed to train our model effectively
in understanding and executing various instructions.
# Experiment
We evaluate our model by testing it across a spectrum of standard
vision-language tasks, including the generation of image descriptions,
answering diverse visual questions, and comprehending targeted phrases
in images.
## Implementation Details
**Model Configuration.** We conduct experiments based on the
well-trained Vit-BigG [ilharco_gabriel_2021_5143773](ilharco_gabriel_2021_5143773) and
LLM from Qwen-VL [bai2023qwen-vl](http://arxiv.org/pdf/1412.3919v1), the pre-trained large
multimodal model. Since the vision encoder has already been well
pretrained, we proceed directly to the instruction-tuning stage. During
instruction tuning, $H_v$, $W_v$ are set to 448 to match the encoder of
Qwen-VL. We employ a consistent resampler across all crops. The
learnable queries engage with local features, utilizing the same set of
256 learnable queries for each crop. Due to limitations in training
time, our main experiments were mainly conducted using images of size
896$\times$``{=html}896 unless specify. For LoRA, we set the
rank to 16 for the attention module and 32 for MLP in the encoder.
Monkey includes 7.7B parameters for a large language model, with 90M
parameters for the resampling module, an encoder with 1.9B parameters,
and 117M parameters for LoRA. The overall parameters for Monkey is 9.8B.
**Training.** We use our multi-level description generation method to
regenerate around 427k image-text pairs from the CC3M dataset,
previously used in LLaVA’s pretraining. During the training process, we
utilize the AdamW optimizer [adamw](http://arxiv.org/pdf/2311.11446v2) with a learning rate
of 1e-5 and the cosine learning rate schedule. Additionally, we set the
values of $\beta_1$ and $\beta_2$ to 0.9 and 0.95, respectively. We
incorporate a warmup period of 100 steps and employ a batch size of
1024. To control overfitting, we apply a weight decay of 0.1. The whole
training process takes 40 A800 days for one epoch.
## Results
We report the results on Image Caption, General VQA, Scene Text-centric
VQA, and Document-oriented VQA. We also conduct testing on the MME
benchmark and achieve a perception score of 1505.3, ranking second, as
shown in Fig. 1. The details of each dataset can be
found in Appendix 6.
**Image Caption.** Image captioning is vital for connecting visual
content with the understanding of natural language. In our study, we
select Flickr30K [young2014image](http://arxiv.org/pdf/2208.09596v1) and
TextCaps [textcaps](https://arxiv.org/pdf/2003.12462) as the benchmark for testing the
image captioning task. TextCaps challenges the model to interpret and
reason text within images effectively. We present our model’s
performance on Flickr30K and TextCaps in
Tab. [General VQA], where the results
indicate that Monkey demonstrates enhanced performance on these
datasets. We also qualitatively show effectiveness of our method in
offering detailed image descriptions in
Sec. 4.4 and Appendix
79.
**General VQA.** General visual question answering (VQA) requires
ability to learn visual and textual information, showing a deep
understanding of how they interrelate. For General VQA, we validate on
five benchmarks: VQAv2 [goyal2017making](http://arxiv.org/pdf/1612.00837v3),
OKVQA [marino2019ok](http://arxiv.org/pdf/1906.00067v2), GQA [hudson2019gqa](http://arxiv.org/pdf/2112.05136v1),
ScienceQA [lu2022learn](http://arxiv.org/pdf/2209.09513v2), and
VizWiz [gurari2018vizwiz](http://arxiv.org/pdf/1802.08218v4). The performance results are
shown in Tab. [General VQA]. Our model shows
remarkable proficiency in VQAV2, OKVQA, ScienceQA, and VizViz,
surpassing the nearest competing method by an average of 1.62%. These
results highlight the effectiveness of our method, emphasizing its use
of high input resolution and detailed data.
**Scene Text-centric VQA.** Text information is commonly found in
real-world scenes, making the ability to answer questions about text in
images a crucial aspect of question-answering tasks. For our evaluation,
we employ four datasets: TextVQA [singh2019towards](http://arxiv.org/pdf/1811.11903v1),
AI2D [kembhavi2016diagram](http://arxiv.org/pdf/1603.07396v1), STVQA [STVQA](http://arxiv.org/pdf/2304.01603v1),
and ESTVQA [ESTVQA](http://arxiv.org/pdf/2002.10215v2). The results, shown in
Tab. 1, indicate that our model leads in
performance on these datasets, outperforming the nearest competitor by
an average of 4.35%. Based on our observation, this enhanced performance
is mainly attributed to the increased image resolution, which brings
smaller text and finer details into clearer view. Moreover, the
inclusion of detailed caption data during training provides valuable
textual context, further boosting the robustness of the model.
**Document-oriented VQA.** Despite the clean backgrounds of documents,
their densely packed text poses distinct challenges. To effectively
evaluate our model, we select representative benchmarks including
DocVQA [mathew2021docvqa](http://arxiv.org/pdf/2111.05547v1),
ChartQA [masry2022chartqa](http://arxiv.org/pdf/2203.10244v1),
InfographicVQA [mathew2022infographicvqa](http://arxiv.org/pdf/2104.12756v2),
DeepForm [deepform](http://arxiv.org/pdf/2303.13839v1),
KLC [stanislawek2021kleister](http://arxiv.org/pdf/2003.02356v2), and
WTQ [pasupat2015compositional](http://arxiv.org/pdf/2009.13845v2). The results, as detailed
in Tab. [DocVQA], show that Monkey surpasses Qwen-VL
in most Document-oriented VQA tasks, achieving an averagely significant
improvement of 9.77%. The higher resolution of documents reveals more
intricate details and a denser concentration of information. Monkey’s
capability to process larger input resolutions enhances its spatial
perception, thereby improving its recognition and comprehension of
various document elements like text, charts, infographics, and forms.
## Ablation Study [subsec:ab]
We conduct thorough experiments to validate the effectiveness of our
designs.
**Ablation study on strategies of enhancing input resolution.** We first
evaluate the existing technique of improving input resolution, as
illustrated in Tab. [SizeAblation]. Resizing the visual
encoder using traditional positional position interpolation to a size of
896 results in worse performance compared with our method under the same
settings (r1 vs. r9). Interestingly, applying LoRA to the encoder for
this traditional interpolation method appears to be less effective than
not using it (r1 vs. r2). This may due to the inherited parameters from
the previous encoder are specifically tuned by lower resolution,
changing it by force may necessitate more training resources.
For our method (r3-r9), as we increase the input size, there is a
noticeable boost in performance, especially demonstrated in the DeepForm
dataset. It can be observed that adding LORA does not significantly
increase FLOPs and the use of one LORA or four LORAs results in a
minimal difference in throughput (r7-r9). The model’s ability to discern
intricate details and sharper images enhances its understanding of
visual aspects such as objects, shapes, and textures, thereby improving
its overall visual perception. When we further push the input resolution
to 1344$\times$``{=html}896, which is the highest resolution the
device can support, the model shows further improvements on
high-resolution datasets like DeepForm, InfoVQA, and WTQ, as detailed in
Tab. [SizeAblation]. However, we can note
that for some datasets, such as TextVQA, using the largest resolution
results in a slight decline in performance; nevertheless, the original
average resolution in the TextVQA dataset is around 950 pixels in width
and 811 pixels in height, further increasing its input resolution seems
unnecessary for these images.
Furthermore, as shown in
Tab. [Tab:llava15_ablation], we
consistently demonstrate the effectiveness of our method on LLaVA1.5.
Impressively, we noticed significant improvements when we increased the
input resolution from 224 to 448, demonstrating the efficiency of our
approach.
**Trainable Adapters.** As shown in
Tab. [SizeAblation], reducing the LoRA
number causes a performance decrease. Using one LoRA for all patches
compared to not using LoRA provides a better perception of local details
(r7 vs. r8), especially with a significant improvement in STVQA.
Utilizing four LoRA modules leads to a better performance, which may
because this approach enables the model to learn a better understanding
of the spatial relationships and contextual information within distinct
image regions.
**Collaboration between High Resolution and Multi-level Description.**
To validate the collaboration between High Resolution and Multi-level
Description, we conduct ablation studies on LLaVA1.5. We employ a ViT-L
as our vision encoder and Vicuna13B [vicuna2023](https://lmsys.org/blog/2023-03-30-vicuna/) as the
language model. By replacing the original annotation from CC3M with our
generated annotations in the pretraining, we consistently achieved
better results on GQA, TextVQA and MMVet [yu2023mm](http://arxiv.org/pdf/2402.15896v1), as
demonstrated in
Tab. [Tab:llava15_ablation].
Furthermore, we have observed that detailed descriptions consistently
yield greater performance enhancements at resolutions of 336 and 448,
compared to a resolution of 224. In Appendix
10, we provide visualization
results for Monkey at different resolutions. These results show that
models with high resolution shines when trained with more comprehensive
descriptions.
## Visualization [subsec:vis]
In a side-by-side qualitative analysis, we compared Monkey with GPT4V
and other LMMs on a task of generating detailed captions. The results,
illustrated in
Fig. [Densecap_vs_GPT4V], demonstrate
Monkey’s superior capability in providing exhaustive descriptions of
images. For instance, in the image from
Fig. [Densecap_vs_GPT4V], both Monkey
and GPT4V successfully identified an “Emporio Armani” store in the
background. Moreover, Monkey went further in detailing various elements
in the scene, such as describing “another woman in a red coat and black
pants carrying a black purse”.
Additionally, as shown in
Fig. [Doc_Chart], we qualitatively observe
that in many cases for understanding complex text-based inquiries,
Monkey has shown impressive performance when compared to GPT4V. More
visualization results of Monkey can be found in Appendix.
## Limitation
The capability of our method to process input images is constrained to a
maximum of six patches due to the limited input length of the language
model. This restriction hampers the further expansion of input
resolution.
Moreover, for the multi-level description generation approach, it is
capable of describing only the scene presented in the image and its
scope is bound by the world knowledge encapsulated in BLIP2 and the
original CC3M annotations. For instance, when provided with a photo of a
location in a country, the method can describe the visual aspects of the
scene, but it lacks the ability to identify and specify that the scene
is indeed in which country.
# Conclusion
This paper proposes a training-efficient approach to effectively improve
the input resolution capacity up to 1344$\times$``{=html}896
pixels without pretraining from the start. To bridge the gap between
simple text labels and high input resolution, we propose a multi-level
description generation method, which automatically provides rich
information that can guide the model to learn the contextual association
between scenes and objects. With the synergy of these two designs, our
model achieved excellent results on multiple benchmarks. By comparing
our model with various LMMs, including GPT4V, our model demonstrates
promising performance in image captioning by paying attention to textual
information and capturing fine details within the images; its improved
input resolution also enables remarkable performance in document images
with dense text.
# Acknowlegement [acknowlegement]
This research is supported by NSFC (No. 62225603).
# Summary of the Evaluation Benchmarks [append:details]
We present a comprehensive overview of the evaluation benchmarks
utilized, along with their corresponding metrics Tab.
[tab:benchmark]. For the Image
Caption task, we selected two datasets:
Flickr30K [young2014image](http://arxiv.org/pdf/2208.09596v1), which is an image caption
dataset for natural images, and TextCaps [textcaps](https://arxiv.org/pdf/2003.12462),
which is an image caption dataset for natural images with text. For
general Visual Question Answering (VQA), we chose five commonly used
datasets. VQAV2 [goyal2017making](http://arxiv.org/pdf/1612.00837v3) is an open-ended VQA
dataset focused on natural images, while
OKVQA [marino2019ok](http://arxiv.org/pdf/1906.00067v2) requires additional world knowledge.
GQA [hudson2019gqa](http://arxiv.org/pdf/2112.05136v1) is a dataset designed for real-world
visual reasoning and compositional question answering.
ScienceQA [lu2022learn](http://arxiv.org/pdf/2209.09513v2) involves multimodal
multiple-choice VQA on science topics, and
VizWiz [gurari2018vizwiz](http://arxiv.org/pdf/1802.08218v4) aims to answer questions from
blind individuals. In the domain of Scene Text-centric VQA, our
selection includes TextVQA [singh2019towards](http://arxiv.org/pdf/1811.11903v1),
AI2Diagram [kembhavi2016diagram](http://arxiv.org/pdf/1603.07396v1),
STVQA [STVQA](http://arxiv.org/pdf/2304.01603v1), and ESTVQA [ESTVQA](http://arxiv.org/pdf/2002.10215v2). AI2D
is a multiple-choice VQA dataset that focuses on science diagrams, while
the others involve reading and reasoning about text in natural images.
For the STVQA and ESTVQA datasets, we followed the split provided by
[liu2023hidden](http://arxiv.org/pdf/2305.07895v5). Regarding Doc-oriented VQA, we
encompass various document images, including documents, charts,
infographics, reports, and HTML tables. In the case of
DeepForm [deepform](http://arxiv.org/pdf/2303.13839v1) and
KLC [stanislawek2021kleister](http://arxiv.org/pdf/2003.02356v2), we transform the Key
Information Extraction task into a Visual Question Answering (VQA) task.
Additionally, we evaluate Monkey on the MME
benchmark [fu2023mme](http://arxiv.org/pdf/2306.05179v2), which measures perception and
cognition abilities. Furthermore, for the ablation study on LLaVA1.5
[liu2023llava1.5](http://arxiv.org/pdf/2310.19145v1), we adhere to the evaluation settings
specified by LLaVA1.5.
# More Visualization Results [append:visualization]
We presented additional visualization results, where
Fig. [QA_ability] demonstrates Monkey’s
capabilities in various VQA tasks. Monkey analyzes the question,
identifies the key elements in the image relevant to answering the
question, and exhibits the ability to perceive even minute text within
the image. Moreover, Monkey can reason about the objects present in the
scene and possesses a strong understanding of visual charts. In
addition, Fig. [QA_ability] also showcases Monkey’s
impressive captioning ability, accurately describing various objects in
the image and providing appropriate summaries.
# More Examples of our Generated Data
In Fig. [dense_text], we present the detailed
captions generated by our method. Compared to the original annotations
from the CC3M [sharma-etal-2018-conceptual](https://doi.org/10.18653/v1/P18-1238), our
generated descriptions cover many more details of the image, providing a
more detailed description of the image.
# Comparison with other LMMs. [append:comparison]
The comparison results of the VQA task in Fig.
[QA_compare] indicate that after
applying our method of scaling up the model size, Monkey has achieved
significant performance advantages in tasks related to dense text. It
not only surpasses the performance of QwenVL-Chat
[bai2023qwen-vl](http://arxiv.org/pdf/1412.3919v1), LLaVA-1.5
[liu2023llava1.5](http://arxiv.org/pdf/2310.19145v1), and mPLUG-Owl2
[ye2023mplugowl2](https://arxiv.org/pdf/2311.04257) but also achieves promising results
compared to GPT-4V [openai2023gpt4](https://arxiv.org/pdf/2303.08774) in tasks related to
dense text. This clearly demonstrates the importance of scaling up the
model size for performance improvement in multimodal large models. It
further validates the effectiveness of our method in enhancing the
performance of multimodal large models.
In Fig. [Caption_compare], the comparison
between Monkey and GPT-4V, QwenVL-Chat, LLaVA-1.5, and mPLUG-Owl2 on
Detailed Caption task is shown. It can be observed that Monkey
accurately describes the content of the image and exhibits high
sensitivity to the text within the image. It provides detailed
descriptions of the image while ensuring accuracy.
# Visualization results for models at different resolutions. [sec:resolutions]
In Fig. [QA_res], we performed VQA tasks testing at
three different resolutions: 896, 784, and 672. The visual results
obtained further validate the importance of our size expansion method
for improving the performance of LMMs. While using a resolution of 896
for VQA tasks testing yielded correct results, using resolutions of 784
and 672 resulted in errors, with the smallest size of 672 showing more
errors.
In Fig. [Caption_res], we conducted tests at
three different resolutions: 896, 784, and 672. It can be observed that
as the resolution decreases, the details in the images gradually become
less visible to the model.
# Data Generation.
**Hyperparameter Control in Data Generation Pipeline.** The appropriate
selection of hyperparameters is crucial. We empirically selected them
based on qualitative results, finding SAM’s default threshold and a 0.5
Image-Text Matching Score to be effective. We conducted a quantitative
validation on 80 samples using the GPT-4V evaluation. The results shown
in Tab. [Tab:hyper] reveal that SAM’s threshold
is relatively robust, and the 0.5 threshold for Image-Text Matching
Score offers a better performance.
**Comparison with LLaVA’s GPT4 Method.** While the GPT4 method in LLaVA
is dependent on using manually annotated captions from the COCO dataset
as a foundational basis for data generation, our approach focuses on
generating original, detailed captions autonomously. Additionally, our
detectors are skilled in revealing a spectrum of details in images, from
text to nuanced object characteristics, which enables to enrich
unlabeled data by extracting complex, multi-level details, paving the
way for the creation of both cost-effective and accurate image
descriptions.
**Why choose BLIP2?** We found that the performance is very similar in
the GPT-4V evaluation when utilizing brief descriptions of local areas
from other VLMs, as shown in
Tab. [Tab:othervlm]. However, for
generating approximately 5M descriptions, using BLIP2 takes
approximately 3 days, while LLaVA and mPLUG-Owl require about 21 days
and 32 days, respectively. For the sake of saving time, we choose BLIP2.
# Ablation study on Global Feature.
We conducted experiments on the presence or absence of global features
at a resolution of 896. By adding global features, the results showed a
7.5% performance gain on TextVQA, a 0.6% performance gain on GQA, and a
6.2% performance gain on DocVQA. This demonstrated that global features
contribute to enhancing the overall performance.
[^1]: $^\dagger$equal contribution; $^*$corresponding authors
UReader: Universal OCR-free Visually-situated Language Understanding with Multimodal Large Language Model
2023-10-08
Jiabo Ye, Anwen Hu, Haiyang Xu, Qinghao Ye, Ming Yan, Guohai Xu, Chenliang Li, Junfeng Tian, Qi Qian, Ji Zhang, Qin Jin, Liang He, Xin Alex Lin, Fei Huang
Text is ubiquitous in our visual world, conveying crucial information, such as in documents, websites, and everyday photographs. In this work, we propose UReader, a first exploration of universal OCR-free visually-situated language understanding based on the Multimodal Large Language Model (MLLM). By leveraging the shallow text recognition ability of the MLLM, we only finetuned 1.2% parameters and the training cost is much lower than previous work following domain-specific pretraining and finetuning paradigms. Concretely, UReader is jointly finetuned on a wide range of Visually-situated Language Understanding tasks via a unified instruction format. To enhance the visual text and semantic understanding, we further apply two auxiliary tasks with the same format, namely text reading and key points generation tasks. We design a shape-adaptive cropping module before the encoder-decoder architecture of MLLM to leverage the frozen low-resolution vision encoder for processing high-resolution images. Without downstream finetuning, our single model achieves state-of-the-art ocr-free performance in 8 out of 10 visually-situated language understanding tasks, across 5 domains: documents, tables, charts, natural images, and webpage screenshots. Codes and instruction-tuning datasets will be released.
Show Paper Content
[^1]: Equal contribution
[^2]: $^{\dagger}$ Corresponding authors
# Introduction
Leveraging strong Large Language Models as the language decoder, some
recent works propose Multimodal Large Language Models (MLLMs)
[minigpt4](http://arxiv.org/pdf/2402.17510v1), [llava](http://arxiv.org/pdf/2402.11690v1), [mplugowl](http://arxiv.org/pdf/2405.00390v2), [blip2](None) and achieve promising
vision-and-language understanding performance. Surprisingly, without
in-domain training, these MLLMs exhibit shallow zero-shot visual text
recognition ability when fed a low-resolution image with salient text
information [mplugowl](http://arxiv.org/pdf/2405.00390v2), [llmocr](http://arxiv.org/pdf/2305.07895v5). However, due to the
variety of image types and the wide range of image sizes, they are still
far from universal visually-situated language understanding, such as
extracting information from documents, reading texts from webpages, and
visual question and answering on tables, as shown in
[fig:intro_case].
Existing works for visually-situated language understanding can be
categorized into two-stage [layoutlmv2](http://arxiv.org/pdf/2310.16527v1), [layoutlmv3](None), [tap](None)
and end-to-end [dessurt](http://arxiv.org/pdf/2203.16618v3), [donut](http://arxiv.org/pdf/2305.09520v1), [pix2struct](None) methods
according to whether relying on an off-the-shelf OCR model or API. These
works all follow a domain-specific pretraining and finetuning paradigm,
thus leading to high training costs, e.g. end-to-end model Donut
[donut](http://arxiv.org/pdf/2305.09520v1) costs more than 192 A100 days.
Inspired by the shallow text recognition ability of existing MLLMs, in
this work, we propose for universal OCR-free visually-situated language
understanding, which leverages the multimodal Large Language Model via
low-cost instruction tuning [instructblip](None). Different
from previous works, we forgo pretraining tasks by leveraging the
existing MLLM and directly finetune MLLM by taking full advantage of
various Visually-situated Language Understanding datasets. To make the
most of the strong language understanding ability of MLLM, we convert
all tasks into the vision-language instruction tuning format. Besides,
to enhance text recognition and semantic understanding ability across
diverse domains, we design auxiliary text reading and key points
generation tasks in the same instruction format. To utilize the
low-resolution encoder of MLLM for processing high-resolution images and
avoid blurry and distortion problems due to resizing, we propose a
shape-adaptive cropping module to cut a high-resolution image into
multiple local images. Each image is firstly independently encoded with
the frozen visual encoder and a trainable visual abstractor and then
concatenated to feed into the language decoder. Moreover, we add
learnable crop position encoding to help the model correlate local
images and add a resized global image to alleviate salient information
loss due to cropping.
Our contributions in this work are four-fold: =0.1em
- We first propose instruction tuning with Multimodal Large Language
Models for OCR-free Visually-situated Language Understanding.
- We build an instruction-tuning dataset covering 5 domains of
visually-situated language understanding: document, table, chart,
natural image, and webpage screenshot.
- We design a shape-adaptive cropping module to utilize the frozen
low-resolution vision encoder for processing high-resolution images.
- achieves state-of-the-art OCR-free performance in 8 out of 10
tasks, across 5 domains.
# Related Work
aims to comprehend images containing rich text information. The image
types are quite diverse, covering document
[docvqa](None), [infovqa](http://arxiv.org/pdf/2104.12756v2), [klc](None), [deepform](http://arxiv.org/pdf/2303.13839v1), [mpmqa](None), table
[wikitableqa](http://arxiv.org/pdf/2009.13845v2), [TabFact](http://arxiv.org/pdf/2311.06592v1), chart
[chartqa](None), [plotqa](http://arxiv.org/pdf/1906.04124v2), [dvqa](None), [figureqa](http://arxiv.org/pdf/2109.02226v1), natural image
[textvqa](None), [ocrvqa](None), [stvqa](http://arxiv.org/pdf/2304.01603v1), [qctextcap](http://arxiv.org/pdf/2302.02124v2), webpage screenshot
[visualmrc](http://arxiv.org/pdf/2101.11272v2), [websrc](http://arxiv.org/pdf/2004.14797v1), etc. Tasks of Visually-situated
Language Understanding range from visual question answering, image
captioning, information extraction to natural language inference.
According to whether using off-the-shelf OCR models or APIs to recognize
texts from images, existing work can be divided into two-stage models
[layoutlmv2](http://arxiv.org/pdf/2310.16527v1), [layoutlmv3](None), [udop](http://arxiv.org/pdf/2212.02623v3), [tap](None) and end-to-end models
[donut](http://arxiv.org/pdf/2305.09520v1), [dessurt](http://arxiv.org/pdf/2203.16618v3), [pix2struct](None). Two-stage work always
designs pretrianing tasks to learn cross-modality alignment between
visual inputs and text inputs. For example, for document understanding,
UDOP [udop](http://arxiv.org/pdf/2212.02623v3) design a Joint Text-Layout Reconstruction
task to recover masked texts and layout information given the visual
inputs and retained text inputs. LayoutLMv3 [layoutlmv3](None)
applies a Masked Image Modeling task to recover masked image tokens with
the context of their surrounding text and image tokens. Without the help
of an off-the-shelf OCR model, end-to-end models need to learn text
recognition with a high-resolution image encoder during the pretraining
stage. For example, Pix2Struct [pix2struct](None) proposes a
Screenshot Parsing pretraining task, where the model needs to generate
the complete HTML DOM tree with only a masked webpage screenshot as the
input. Donut [donut](http://arxiv.org/pdf/2305.09520v1) designs a pretraining task to
generate all texts in the document image. These work all follow a
domain-specific pretraining and finetuning paradigm and therefore ask
for high training costs, e.g. Donut is trained for more than 192 A100
days. In this work, by leveraging the shallow text recognition ability
of Multimodal Large Language Models, we propose to directly perform
instruction tuning across various types of images and greatly reduce the
training cost for universal visually-situated Language Understanding.
is developed to empower the Large Language Model with multi-modality
understanding ability, especially for vision information. These work
[kosmos](http://arxiv.org/pdf/2302.14045v2), [minigpt4](http://arxiv.org/pdf/2402.17510v1), [llava](http://arxiv.org/pdf/2402.11690v1), [mplugowl](http://arxiv.org/pdf/2405.00390v2), [blip2](None), [instructblip](None)
mainly connect a pre-trained vision encoder (usually CLIP VIT-L/14
[clip](http://arxiv.org/pdf/2404.19696v1)) with a strong large language model, such as LLaMA
[llama](http://arxiv.org/pdf/2402.08075v1). These MLLMs show some emergent abilities,
including shallow zero-shot text recognition ability
[llmocr](http://arxiv.org/pdf/2305.07895v5). However, they are still far from universal
visually-situated language understanding. Firstly, due to the
pretraining data for the vision encoder being mostly natural images,
MLLMs show barely acceptable text understanding performance on natural
images but bad performance on other types, such as document
[llmocr](http://arxiv.org/pdf/2305.07895v5). Secondly, most images for visuall-situated
language understanding are high-resolution. Rescaling them to low
resolution to adapt to the vision encoder can cause the texts blurry and
distorted. In this work, we propose to fully leverage the shallow text
recognition ability of MLLMs and perform instruction tuning to enhance
its universal understanding ability across 5 domains. Besides, we design
a shape-adaptive cropping module to alleviate the text blur and
distortion problem.
#
The primary goal of is to efficiently utilize existing MLLMs for
Visually-situated Language Understanding tasks. In this work, we utilize
but are not limited to, the mPLUG-Owl [mplugowl](http://arxiv.org/pdf/2405.00390v2) as our
basic MLLM. 1 presents an overall
architecture of . The input image is firstly pre-processed by a
shape-adaptive cropping module (in
[sec:crop]). The resulting sub-images are
then simultaneously passed through the visual encoder and visual
abstractor. To enable the large language model to correlate multiple
cropped sub-images, we apply a crop position encoding module to
introduce spatial information across sub-images. (in
1.2).
## Shape-Adaptive Cropping Module
Images with texts have various aspect ratios and a great range of
resolutions. Simply resizing the image to $H_v, W_v$ (raw resolution of
the MLLM) can result in text being blurred, distorted, and
unrecognizable. Thus we propose a shape-adaptive cropping module.
Specifically, as shown in
2, we pre-define grids
$\{g=(n_h\times n_w)|n_h\cdot n_w\le N_c, n_h \in \mathbb{N}, n_w \in \mathbb{N}\}$
with various shapes, where $n_h$ and $n_w$ denote the number of rows and
columns of the grid $g$ and $N_c$ denotes the maximum number of the
cells (sub-images). To select a suitable grid for an image $I$ with
shape $H \times W$, two rules should be followed: (1) The grid should
preserve the resolution of the image as much as possible, and (2) the
grid should fit the aspect ratio of the input image. To measure the
resolution coherence and shape similarity between the image and each
grid, we calculate the resolution-related and resolution-agnostic
insection over union $\mathrm{S_{rr}}$ and $\mathrm{S_{ra}}$ as follows:
$$\begin{aligned}
\mathrm{S_{rr}}(I, g)&=\mathrm{IoU}\left((H,W),(n_hH_v,n_wW_v)\right) \\
\mathrm{S_{ra}}(I, g)&=\mathrm{IoU}\left((\frac{n_wH}{W},n_w),(n_h, n_w)\right)
\end{aligned}$$ where $\mathrm{IoU}$ denotes the insection over the
union between two rectangles centered and aligned with each other. The
matched grid is selected by maximizing the matching score:
$$g^{*}=\argmax_{g} {\mathrm{S_{ra}}(I, g)+\mathrm{S_{rr}}(I, g)}$$
where $g^{*}$ is the selected grid. Then, we resize the input image to
$(n_hH_v,n_wW_v)$ and crop it to $n_h \cdot n_w$ local images. To
maintain the global structure information of the image, we also resize
the input image to $(H_v,W_v)$ as a global image. All images are then
passed on to the visual encoder and visual abstractor in parallel.
The visual encoder extracts visual feature
$V\in \mathbb{R}^{N \times (H'\cdot W')\times d_v}$ from the input
images $\mathbf{I}\in \mathbb{R}^{N\times H\times W \times 3}$, where
$N=(n_h\cdot n_w)+1$, $H'\cdot W'$ and $d_v$ denote the number and
dimension of the extracted visual features, respectively. The visual
abstractor further summarizes visual information and obtains higher
semantic visual representations
$V^{l} \in \mathbb{R}^{N\times N_q\times d_l}$ in language feature space
by several learnable queries, where $d_l$ denotes the dimension of
language feature space and $N_q$ denotes the number of learnable
queries.
## Cropped Images Modeling with LLM [sec:modelling]
MLLMs are mostly trained with a single image as the input. Due to the
cropping module, we need to input visual features from multiple images
into the language model. The 1-dimensional position embeddings of LLM
can not reflect the spatial position of each sub-image, which is
critical to correlate local images. Therefore, we incorporate a
2-dimensional crop position encoding to help the language model to
understand the spatial relationship between cropped images.
Specifically, we assign a location index $(i, j)$ for each cell of the
selected grid and obtain their row embedding and column embedding by two
auxiliary embedding layers as follows: $$\begin{aligned}
\mathbf{e}^{row}_{i,j}&=\mathrm{Embedding_{row}}(i) \\
\mathbf{e}^{column}_{i,j}&=\mathrm{Embedding_{column}}(j) \\
\mathbf{e}_{i,j}&=\mathbf{e}^{row}_{i,j} + \mathbf{e}^{column}_{i,j}
\end{aligned}$$ where $\mathbf{e}_{i,j}\in \mathbb{R}^{D_l}$ denotes the
crop position embedding of the cell $(c_i, c_j)$. We add the embedding
to the visual feature of each cell in the language space via
broadcasting along the dimension of learnable queries:
$\bar{V}^l_{i,j}=V^l_{i,j}+\mathbf{e}_{i,j}$. We then reshape the visual
features into
$\bar{\mathbf{V}}^l\in \mathbb{R}^{(N\cdot N_q)\times d_l}$. The
resulting spatial-aware visual features and word embeddings of the input
sentences are concatenated at sequence dimension and sent to the large
language model.
In order to enhance the language model’s ability to effectively model
multiple images while keeping low training costs, we freeze the origin
language model and adopt the low-rank adaptation approach (LoRA)
[hu2022lora](https://openreview.net/forum?id=nZeVKeeFYf9).
# Instruction Tuning
For developing a universal visually-situated language understanding
model that could process various types of images and perform different
comprehension tasks, we conduct low-cost instruction tuning with a
Multimodal Large Language Model. Without introducing any large-scale
pretraining datasets, we directly ensemble multiple downstream datasets
and perform joint training. Different downstream tasks are all
reorganized to the unified instruction format
[instructblip](None). Besides, we design auxiliary text reading
and key points generation tasks to enhance text recognition and semantic
understanding ability.
## Tuning Tasks
Downstream tasks of Visuall-situated Language Understanding cover Visual
Question Answering, Information Extraction, Natural Language Inference,
and Image Captioning. For developing a universal model, we reorganize
all tasks into the instruction tuning format
[instructblip](None). Concretely, for the Visual Question
Answering task, the question is directly used as the instruction:
"Human: {question} AI: {answer}". For the Information Extraction task,
each category and value pair is expressed with a prompt as "Human: What
is the value for the {category}? AI: {value}". If some categories don’t
exist in the image, the value is ‘None’. In the raw annotation of the
Natural Language Inference task, ‘1’ means ‘Entailed’ and ‘0’ means
‘Refuted’. We reorganize the NLI task by constructing the instruction
"Human: {statement}, Yes or No? AI: {answer}", where ‘Yes’ means
‘Entailed’. For the Image captioning task, we refer to 11 prompts from
LLaVa [llava](http://arxiv.org/pdf/2402.11690v1) to instruct the model to briefly describe
the image and randomly choose 1 prompt for each caption, such as "Human:
Provide a brief description of the given image. AI: {caption}".
Text Recognition is a basic ability for OCR-free Visuall-situated
Language Understanding. Therefore, we apply an auxiliary Text Reading
task to strengthen text recognition ability across different domains.
With the text and position information in the image, we organize the
texts in the common reading order: from top to down, from left to right.
Directly utilizing all texts as targets [donut](http://arxiv.org/pdf/2305.09520v1) will
result in the model focusing on generating the starting texts and
neglecting others to reduce the loss. Instead, we randomly choose a
split position $p$ from
$\{0, \frac{L}{6},\frac{2L}{6}, ...,\frac{5L}{6}\}$, where $L$ is the
text sequence length. The left part is used as the input and the right
one is the target. $p=0$ means to generate all texts while other cases
ask the model to continue reading following the input texts. Such a
design could enforce the model to read different parts of texts with the
context. Starting texts always convey key information about the image,
such as the chart title. Therefore, we apply a bigger sample rate (0.5)
for the ‘0’ position and 0.1 for other positions. To distinguish reading
from the beginning and continuing reading, we design two groups of
prompts and randomly choose 1 prompt for each sample. For example, an
instruction of reading from the beginning can be "Human: Recognize text
in the image. AI: {all texts}" and an instruction of continuing reading
can be "Human: The words on this picture are {left texts}. Continue
reading the text. AI: {right texts}".
Large Language Models learn strong understanding ability from the tough
language modeling task. Therefore, for stronger vision-and-language
semantic comprehension ability, we propose to design an auxiliary Key
Points Generation task, which requires the model to give some key points
about the image. To support this task, we collect QA pairs of each image
and convert them to declarative sentences with Vicuna
[vicuna](https://github.com/lm-sys/FastChat). These declarative sentences are finally
regarded as key points about the image. We also build a set of templates
to instruct this task, such as "Human: Identify some key points in this
picture. AI: {key points}".
All templates for Text Reading and Key Points Generation tasks can be
found in Appendix
[sec:appendix_template].
## Instruction Data Resources
DocVQA [docvqa](None) comprises 50k question and answer(QA)
paris on 12k document images from UCSF Industry Documents Library.
InfographicsVQA (InfoVQA) [infovqa](http://arxiv.org/pdf/2104.12756v2) collects 5k diverse
infographics from the internet and annotates 30k QA pairs.
DeepForm$^*$[^1] [deepform](http://arxiv.org/pdf/2303.13839v1) and Kleister Charity (KLC)
[klc](None) are two Information Extraction datasets.
DeepForm$^*$ contains 1.1k documents related to election spending. 2.7k
documents of KLC come from published reports of charity organizations.
WikiTableQuestions (WTQ$^*$) [wikitableqa](http://arxiv.org/pdf/2009.13845v2) comprises 2.1k
table images from Wikipedia and is annotated with 23k question and
answer pairs demanding comparison and arithmetic operations. TabFact$^*$
[TabFact](http://arxiv.org/pdf/2311.06592v1) is a Natural Language Inference dataset, which
contains 112k ‘entailed’ or ‘refuted’ statements about 16k Wikipedia
tables.
ChartQA [chartqa](None) collects various topics and types of
charts from four sources: Statista (statista.com), The Pew research
(pewresearch.org), OWID (ourworldindata.org) and OECD (oecd.org). It
totally contains 21k chart images and 32k QA pairs.
TextVQA [textvqa](None) filters 28k natural images with texts
from Open Images V3 [openimages](http://arxiv.org/pdf/1809.05929v7) and annotates 45k QA
pairs. To support image captioning with reading comprehension, TextCaps
[textcaps](None) further collects 145k captions based on
TextVQA.
VisualMRC [visualmrc](http://arxiv.org/pdf/2101.11272v2) collects 5k full screenshots of
webpages from 35 websites. There are 30k annotated QA pairs where
answers are expressed in fluent sentences (avg. 9.53 words) and much
longer than the ones of QA datasets mentioned above.
[^1]: Superscript $^*$ means the reformulated or modified version in
DUE-benchmark [due](None)
# Experiments
## Implementation Details
We conduct experiments on a recently proposed MLLM named
mPLUG-Owl [mplugowl](http://arxiv.org/pdf/2405.00390v2) without modifying its
hyperparameters. The number of learnable queries of visual abstractor is
$65$. The dimension of hidden states $d_v$ and $d_l$ are 1024. For the
shape-adaptive cropping module, we set the maximum number of cells $N_c$
to 20 by default. During instruction tuning, the maximum sequence length
is limited to 2048, and $H_v, W_v$ are set to 224 to match the
pretrained resolution of the visual encoder. For LoRA, we set the rank
$r=8$. The learning rate schedule uses a linear warmup of 36 steps to
$1e^{-4}$, followed by cosine decay to 0. The batch size is set to 256.
For better convergence of each dataset, DocVQA is up-sampled 3 times,
InfoVQA, WTQ, DeepForm, and KLC are up-sampled 2 times. The total number
of training samples including Text Reading and Key Points Generation is
514,764. The instruction tuning process takes 16 A100 days for 20k
training steps (10 epochs).
## Evaluation
We use official training splits as tuning data and evaluate models on
test splits. Following previous works [due](None), [pix2struct](None),
DocVQA and InfoVQA are evaluated by ANLS [stvqa](http://arxiv.org/pdf/2304.01603v1),
DeepForm and KLC are evaluated by F1 score. WTQ, TabFact and TextVQA are
evaluated by accuracy. ChartQA is evaluated with the relaxed accuracy
[plotqa](http://arxiv.org/pdf/1906.04124v2). TextCaps and VisualMRC are measured by CIDEr
[cider](http://arxiv.org/pdf/2106.15553v1). Evaluation of TextVQA and TextCaps are performed
with the official challenge website.
p0.02\|p0.02p0.02\|p0.04\
## Main Results
We first compare with state-of-the-art ocr-free models on 10 datasets.
For fair and consistent comparison across all datasets, we finetune the
strong and accessible baseline Dount on unreported datasets. As shown in
Table [tab:main], achieves state-of-the-art
performance in 8 tasks across 5 domains, covering Visual Question
Answering, Information Extraction, Natural Language Inference and Image
Captioning tasks. With much fewer trainable parameters (86M vs 1.3B) and
without a specific finetuning stage, outperforms the strong
pretriaining model Pix2Struct$_{large}$ in InfoVQA, ChartQA, and
TextCaps. Considering that Pix2Struct$_{large}$ is trained more than
170k steps with a batch size of 1024 on 128 TPUs, this validates that
with the help of open-domain Multimodal Large Language Models, learning
costs for universal visually-situated language understanding can be
greatly reduced. More detailed analysis can be found in
[sec:main_weak].
## Ablation Study
We perform comprehensive ablation experiments to validate the
contribution of two auxiliary tasks, trainable architectures,
cross-domain joint training and the design of shape-adaptive cropping
module.
#### Auxiliary Tasks.
As shown in Table [tab:ablation], dropping the Key
Points Generation task (r10 vs r2) causes a performance decrease on all
domains of datasets, demonstrating that this task helps the model better
understand the vision-and-language semantic. Further removing the Text
Reading task (r2 vs r1) causes more significant performance degradation,
which validates the importance of enhancing text recognition ability
across different domains.
#### Trainable Architectures.
Both the visual abstractor and LoRA in LLM are finetuned in (r10).
Freezing either the visual abstractor (r3) or LoRA (r4) causes
performance decrease, which demonstrates that both the vision and
language parts should be finetuned for adjusting to Visually-situated
Language Understanding.
Visualization of the frequency of selected grid with
shape-adaptive cropping module. The cell at row i and column j denotes the selected frequency of
grid (nh = i, nw = j).
Deeper colors represent higher selection frequencies.
#### Cross-domain Joint Training.
After removing 4 document datasets from the training data, achieves
worse performance (r10 vs r5) on the table, natural image, and webpage
domains, validating that images of different domains share some common
characteristics and cross-domain joint training improves the universal
performance. Besides, although trained without document data, our model
achieves a 46.2 score on the DocVQA dataset, showing the potential
out-of-domain understanding ability of our training paradigm.
#### Shape-adaptive Cropping.
The r6 in Table [tab:ablation] represents directly
tuning the mPLUG-Owl without any model revisions. With the
shape-adaptive cropping, achieves significantly better performance (r7
vs r6), showing that our cropping module is indispensable to leverage
pretrained low-resolution vision encoder for universal visually-situated
language understanding. Besides, increasing the cropping numbers (r8 vs
r7) improves the model’s performance. Due to the resolution of each
local image being constant (224x224), more crops mean higher overall
resolution and therefore achieves better performance. Furthermore,
adding a resized global image bring a slight improvement in most
datasets (r10 vs r8), validating that a complete image could alleviate
possible information loss due to image cropping. Finally, dropping crop
position encoding also hurts the model’s performance (r10 vs r9),
proving the effectiveness of crop position encoding for correlating
local images.
For alleviating the distortion problem due to resizing, we propose to
crop images according to their raw aspect ratio.
1 shows the frequency distribution of
grids selected by our shape-adaptive cropping module on DocVQA,
VisualMRC and WikiTableQuestions (the distribution on more datasets can
be found in the Appendix
[sec:appendix_grid]). For
aesthetic purposes, we present the distribution with $N_c=9$.
Apparently, different domains of images have different shape
distributions. For most document images in DocVQA, their height is
greater than the width, while table images are the opposite. As webpages
are scrollable, their screenshots are always in the form of a long
rectangular shape. With the shape-adaptive cropping design, our model
can easily adapt to various image shapes without domain-specific
fine-tuning.
Text distortion may pose little influence on visual question answering
because they are always about partial text information. But it is
harmful for reading texts in the image because every text matters. For
quantitative analysis of the influence of shape-adaptive design, we
directly evaluate the performance of reading all texts. We choose the
Bleu [bleu](http://arxiv.org/pdf/2202.11027v1) as the metric because it directly measures
the n-gram overlap between the ground-truth and predicted text sequence.
The evaluation set is built by combining 100 randomly-selected test
images from each dataset. As shown in
1, compared with cropping all images
with a fixed grid, could better recognize texts in the image due to our
shape-adaptive design that alleviates the text distortion problem.
| **Model** | **Bleu1** | **Bleu2** | **Bleu3** | **Bleu4** |
|:-----------|:----------|:----------|:----------|:----------|
| w/o adapt | 21.4 | 15.4 | 12.0 | 9.7 |
| | **24.9** | **18.1** | **14.3** | **11.7** |
The Text Reading performance of under the condition of $N_c=9$. ‘w/o
adapt means removing the shape-adaptive design and cropping the image
with a fixed grid $3 \times 3$.
## Qualitative Results [sec:quali_analysis]
[fig:case] show some qualitative results
produced by our on different types of images. could not only extract
information from the document (case a), but also understand different
instructions and provide corresponding answers by attending to different
regions (case b). Table understanding always involves layout
comprehension and statistics. As shown in case c, given a table image,
could well relate different columns to answer the ‘first movie’ and
perform simple statistics about the ‘total number’. As for images with
multiple paragraphs of text, e.g. webpage screenshot in case e, could
also locate the relevant paragraph, understand the texts and answer the
question accurately. Case d shows the text reading performance. With the
help of the Text Reading task, is able to read texts from top left to
bottom right. But, due to the language decoding manner, when given an
image with rich texts, such as a page of a book, the model often reads
the beginning texts and then continues writing without watching the
image. More qualitative results can be found in
[sec:appendix_case]. Finally, as
shown in case f, is able to list some key points about the chart by
combining the title and line information. Listing key points in this
work is just a superficial attempt at open-ended generation, and its
performance is far from promising, e.g., makes a mistake about the
lowest line. More effort is needed towards a comprehensive understanding
of images with rich text.
# Conclusion
We first propose to leverage existing Multimodal Large Language Models
for universal ocr-free visually-situated language understanding through
low-cost instruction tuning. All downstream tasks are reorganized into a
unified instruction-tuning format. Besides, we design the Text Reading
task and Key Points Generation task to enhance text recognition and
vision-and-language semantic comprehension abilities. To utilize the
pre-trained vision encoder for processing high-resolution images, we
design a shape-adaptive cropping module, which cuts the image into
multiple local images considering its raw aspect ratio and resolution.
achieve state-of-the-art ocr-free performance in 8 out of 10 datasets,
ranging from documents, tables, charts, and natural images to webpage
screenshots.
# Limitations [limitations]
Our experiments validate that is able to correlate local images after
cropping a high-resolution image. However, struggles to understand
multi-page documents (e.g. books and papers) due to lacking ability to
correlate different pages and the limited sequence length of the
decoder. Besides, feeds an equal number of features for each local
image into the language decoder. But, not all local images contain rich
vision or text information. In the future, we will explore a more
efficient way to encode different crops. Furthermore, the open-ended
generation about Visually-situated Language understanding is far from
well studied. We try developing key points generation ability in this
work but more difficult generation tasks are not currently considered,
such as giving the chain-of-the-thought of the answer. How to simulate
such abilities through instruction tuning is a topic worth studying.
Finally, the Text Reading task helps the model recognize texts, but the
text reading performance with the LLM as the decoder is far from
satisfactory due to the hallucination problem. Instructing the LLM to
read texts strictly according to images is a challenging topic.
# Ethics Statement [ethics-statement]
Our relies on multi-modal large language models that are trained on
large-scale image and text data from the web and therefore may be
subject to issues such as toxic language and
bias [bender2021dangers](http://arxiv.org/pdf/1705.07451v1). However, our model is further
fine-tuned on publicly available datasets and is used specifically in
the domain of visually-situated language understanding, where these
issues have minimal impact.
# Grid Distribution on Downstream Datasets [sec:appendix_grid]
We visualize the frequency distribution of grids selected by our
shape-adaptive cropping module on all ten datasets in
[fig:cut_map_full]. The wide
variety of image shapes in downstream tasks highlights the crucial role
of the shape-adaptive cropping module.
# Detailed Analysis on Performance [sec:main_weak]
## Underperforms Ocr-Free Baselines on DocVQA and DeepForm
It can be seen that underperforms ocr-free baselines on DocVQA and
DeepForm. There are two main factors: (1) Donut performs the pretraining
on large-scale document dataset IIT-CDIP (11M document images), which is
the same domain as DocVQA and DeepForm. But UReader does no have a
pretraining process and is just instruction finetuned on ensembled
datasets (less than 0.5M assorted images). Training with more document
images brings better performance. (2) The pretraining task of Pix2struct
is to predict the HTML dom tree of a masked web screenshot, which
requires the model to fully understand the layout information of the
image. But UReader is trained to read texts from top to down, from left
to right, which requires a weaker layout understanding ability. The
pretraining on layout understanding also leads to improved performance
on DocVQA.
The conclusion can also be substantiated by the observations on the
other two datasets (i.e., InfoVQA and KLC) included in the document
domain as previous work [udop](http://arxiv.org/pdf/2212.02623v3). For the InfoVQA dataset,
the image is poster style and the layout is not as important as DocVQA
and DeepForm but the relationship between text and vision objects
matters more, like natural image and chart image. As for the KLC
dataset, ocr-free models are only fed with the first page (always the
cover of a report) , where the layout is much simpler than DocVQA and
DeepForm. Therefore, can outperform baselines on these two document
datasets.
In summary, compared with ocr-free model Donut and Pix2Struct, due to
the pretrianing of MLMM on open-domain datasets, is better at
understanding cross-modality relationships in the image but weaker at
comprehending text layout information without large-scale document
pretraining and specific layout understanding tasks.
## Compared with Pipeline Methods
We list the performance of state-of-the-art pipeline models in
[tab:pipeline]. We can summarize from
the results that there are two distinct aspects. Firstly, our model
achieves comparable or slightly worse results compared to the pipeline
methods on TextVQA, ChartQA, InfoVQA, TextCaps and TabFact. Secondly,
there is a obvious gap between our model and pipeline methods on DocVQA,
DeepForm, KLC, WTQ and VisualMRC.
For the first aspect, there are two reasons for the similarity
performance: (1) Modeling the diverse relationship between visual
objects and text presents challenges for both pipeline-based methods and
OCR-free methods. TextVQA, TextCaps and InfoVQA requires the relation
understanding between text and visual objects (i.e. logos, icons and
common objects). ChartQA asks for trend comprehension of lines.
Understanding such complex cross-modality relation is challenging for
both ocr-free and pipeline methods. (2) The simplicity of task formats
can reduces performance gaps. Tabfact is a simply binary classification
task resulting the small performance gap.
For this second aspect, the main performance gap appears in three
categories of datasets: document, table, and webpage screenshot. The
reasons are two folds: (1) The gap in terms of text recognition and
layout extraction. In document, table and website, text is the dominant
information source and the layout(e.g. row and column layout in table)
is relatively uniformer than the chart and natural images. Therefore,
with pre-extracted texts and layout information, it is more easy to
understand the image. But for OCR-Free models, such as our UReader and
Donut, it’s still challenging to fully recognize all texts. (2) The gap
in terms of modeling capacity on multi-page document input. for
multiple-page document datasets KLC (98% \> 4 pages) and DeepForm (75%
\> 1 pages), OCR-Free models only input the first page and lose much
information.
## Zero-shot Performance
We test the zero-shot performance of UReader on unseen dataset OCR-VQA.
With the same evaluation metrics, UReader outperforms mPLUG-Owl (41.1 vs
28.6) and a recent work UniDoc [Feng2023UniDocAU](https://api.semanticscholar.org/CorpusID:261065237) (41.1
vs 34.5) with the training of layout prediction. The results show that
the zero-shot performance of our method on unseen domains is acceptable.
# More Qualitative Results [sec:appendix_case]
## Downstream Results
More qualitative results on natural images, charts, tables, documents
and webpage screenshots are shown in Figure
[fig:natural_case]-[fig:web_case].
[fig:web_case] show a sample of Text
Reading and Visual Question Answering about a webpage screenshot from
VisualMRC. As mentioned in
[sec:quali_analysis], when given
an instruction about reading all texts in the image, can read the
beginning texts but sometimes is easy to continue to generate
vision-irrelevant texts. With appropriate instructions, could indeed
recognize texts in other regions, such as ‘exercise increases cellular
recycling’. Therefore, the hallucination problem during text reading is
not because cannot recognize texts, but the generating manner of LLM
decoder. When beginning texts are read from the image, the decoder may
generate the following texts according to the closer text context rather
than the image.
## Open-domain Results
We present open-domain examples in
[fig:open_domain_case]. We use
randomly collected images and freely ask questions to the model based on
the content of these images. The original mPLUG-Owl is used for
comparison.
In [fig:open_domain_case] (a),
is able to accurately recognize and answer questions about the small
text in natural images ("Name of passenger" and "MORRIS/KARLA"). In
contrast, mPLUG-Owl does not respond with the name in the first round
and gives an incorrect answer even with a prompt in the second round.
In [fig:open_domain_case] (b), we
raise a query consisting of two cascaded questions, which requires the
model to simultaneously understand the spatial position of the
non-textual objects referred to by the query and locate the
corresponding fields. It can be seen that the completes this task well,
while mPLUG-Owl answers incorrectly in both object recognition and price
extraction.
In [fig:open_domain_case] (c), we
conduct multi-turn conversions with on a screenshot. The questions
included references to the history of the conversation. Some questions
also require a certain amount of common sense. For example, the time of
account creation is equivalent to the time of joining Twitter, and the
inactive state of the Follow button indicates that the user has not
followed Iron Musk. answers these questions well. mPLUG-Owl can
correctly recognize the Iron Mush, but is it prone to generating content
that is unrelated to the image, leading to some erroneous statements.
In [fig:open_domain_case] (d), we
ask the about the price and its components based on an image consisting
of multiple forms. Although wrongly includes the header in the answer
and does not list the prices for each component, we notice that it
proactively filters out the components with a price of \$0, making the
answer more consistent with the user’s intention. It indicates that can
find the form related to the question and comprehensively understand the
meaning of each field in the form. In contrast, mPLUG-Owl generates
responses that are full of illusions due to the loss of textual
information in the image.
These results reveal that maintains some interactive ability of MLMM in
the open domain and shows stronger visually-situated language
understanding ability.
# Instruction Templates [sec:appendix_template]
The instruction templates of the auxiliary Text Reading and Key Points
Generation tasks are shown in
[tab:instruct_templates].
c\|c\|l **Task** & **Part** &**Instruction Template**
\*text reading from the beginning & \*- & \Human: what words are
in the image? AI: {all texts}.
& & \Human: what texts are in the picture? AI: {all
texts}.
& & \Human: what does the image read? AI: {all texts}.
& & \Human: what does the picture say? AI: {all texts}.
& & \Human: what is written in the image? AI: {all texts}.
& & \Human: list the words in the image. AI: {all texts}.
& & \Human: list the texts in the picture. AI: {all
texts}.
& & \Human: Recognize text in the image. AI: {all texts}.
& & \Human: Identify text in the picture. AI: {all texts}.
& & \Human: Deciphering written content in the photo. AI:
{all texts}.
& & \Human: Extract words from the graphic. AI: {all
texts}.
& & \Human: Parse text from imagery. AI: {all texts}.
& & \Human: Read written language in the visuals. AI: {all
texts}.
& & \Human: Decode text from the snapshot. AI: {all
texts}.
& & \Human: Translate text in the picture. AI: {all
texts}.
& & \Human: Retrieve written information from the image. AI:
{all texts}.
& & \Human: Detect words in the photograph. AI: {all
texts}.
\*continue reading & \*A & \Human: The picture reads {left
texts}.
& & \Human: The image says {left texts}.
& & \Human: There are words {left texts} in the image.
& & \Human: Words {left texts} are in the picture.
& & \Human: The texts in this image read {left texts}.
& & \Human: The words on this picture are {left texts}.
& & \Human: The script depicted in this image reads {left
texts}.
& & \Human: The writing on this visual representation states
{left texts}.
& & \Human: The content presented in this diagram states
{left texts}.
& & \Human: The language used in this photograph says {left
texts}.
& & \Human: The inscription on this picture explain {left
texts}.
& \*B & Continue reading the text. AI: {right texts}.
& & Read the following text. AI: {right texts}.
& & Read the text behind. AI: {right texts}.
& & What is the following text? AI: {right texts}.
\*key points generation & \*- & \Human: Identify some key points
in this picture. AI: {key points}.
& & \Human: Point out several critical features in this
image. AI: {key points}.
& & \Human: Highlight a few significant elements in this
photo. AI: {key points}.
& & \Human: Give some essential details in this
illustration. AI: {key points}.
& & \Human: Draw attention to some important aspects in this
diagram. AI: {key points}.
& & \Human: Mention a couple of crucial points in this
snapshot. AI: {key points}.
& & \Human: Indicate a few pertinent items in this graphic.
AI: {key points}.
& & \Human: Outline some significant characteristics in this
image. AI: {key points}.
& & \Human: Specify some key components in this picture. AI:
{key points}.
& & \Human: List a handful of essential elements in this
visual. AI: {key points}.
##
3. Models using fine-grained vision model and a small Language Model as decoder
Kosmos-2.5: A Multimodal Literate Model
2023-09-20
Tengchao Lv, Yupan Huang, Jingye Chen, Lei Cui, Shuming Ma, Yaoyao Chang, Shaohan Huang, Wenhui Wang, Li Dong, Weiyao Luo, Shaoxiang Wu, Guoxin Wang, Cha Zhang, Furu Wei
We present Kosmos-2.5, a multimodal literate model for machine reading of text-intensive images. Pre-trained on large-scale text-intensive images, Kosmos-2.5 excels in two distinct yet cooperative transcription tasks: (1) generating spatially-aware text blocks, where each block of text is assigned its spatial coordinates within the image, and (2) producing structured text output that captures styles and structures into the markdown format. This unified multimodal literate capability is achieved through a shared Transformer architecture, task-specific prompts, and flexible text representations. We evaluate Kosmos-2.5 on end-to-end document-level text recognition and image-to-markdown text generation. Furthermore, the model can be readily adapted for any text-intensive image understanding task with different prompts through supervised fine-tuning, making it a general-purpose tool for real-world applications involving text-rich images. This work also paves the way for the future scaling of multimodal large language models.
Show Paper Content
# Introduction
Over the past several years, large language models (LLMs) have emerged
as a critical area of research in artificial intelligence. These models
are designed to learn from massive amounts of natural language data,
allowing them to perform a wide range of language-related tasks with
impressive accuracy. This development has been fueled by advancements in
model scaling that enabled researchers to create models with
unprecedented complexity. As a result, LLMs have become increasingly
prevalent across various industries and applications, from customer
service chatbots to virtual assistants and automated content creation.
One notable trend in recent years has been the focus on building larger
and more complex models, such as
GPT-3 [https://doi.org/10.48550/arxiv.2005.14165](https://doi.org/10.48550/ARXIV.2005.14165) and
GPT-4 [openai2023gpt4](https://arxiv.org/pdf/2303.08774), which has hundreds/thousands of
billion parameters and can generate compelling language outputs. While
these models require significant computing resources to train and
operate, they hold enormous potential for revolutionizing how we
interact with and understand natural language.
Current LLMs primarily focus on textual information and cannot
understand visual information. However, advancements in the field of
multimodal large language models (MLLMs) aim to address this limitation.
MLLMs combine visual and textual information within a single
Transformer-based model, enabling the model to learn and generate
content based on both modalities. MLLMs have shown promise in a variety
of real-world applications, including natural image understanding and
text image understanding. These models leverage the power of language
modeling as a general interface for multimodal problems, allowing them
to process and generate responses based on textual and visual inputs.
While existing MLLMs have mainly focused on natural images with lower
resolutions, the exploration of text images is an area that requires
further investigation. Taking advantage of large-scale multimodal
pre-training for text images is an important direction for MLLM
research. By incorporating text images into the training process and
developing models based on textual and visual information, we can unlock
new possibilities for multimodal applications involving high-resolution
text-intensive images.
In this study, we present **Kosmos-2.5**,
a multimodal literate model that takes advantage of
Kosmos-2 [peng2023kosmos](http://arxiv.org/pdf/2305.16103v1)
designed to tackle machine reading of text-intensive images, which is
shown in [fig:introduction].
Kosmos-2.5 performs two closely related
transcription tasks in a unified multimodal model. The first task
generates spatially-aware text blocks, assigning text lines their
corresponding spatial coordinates within the original text-rich image.
The second task produces structured text output, capturing styles and
structures in the markdown format. Both tasks are conducted under a
unified framework, leveraging a shared Transformer architecture,
task-specific prompts, and flexible text representations. Specifically,
our model architecture combines a ViT-based vision encoder and a
Transformer-based language decoder linked by a resampler module. Our
model is pre-trained on a large corpus of text-intensive images, whose
text representations include text lines with bounding boxes and plain
markdown texts. By employing this dual-task training strategy,
Kosmos-2.5 enhances its general-purpose
multimodal literate capabilities. We assess the performance of
Kosmos-2.5 on two tasks: end-to-end
document-level text recognition and markdown-formatted image-to-text
generation. Experiment results have demonstrated strong literate
performance on several text-intensive image understanding tasks. In
addition, Kosmos-2.5 also demonstrates
promising capabilities in few-shot and zero-shot learning scenarios,
offering a universal interface for real-world applications that involve
text-rich images.
The contributions of this work are summarized as follows:
- Kosmos-2.5 represents a significant
paradigm shift in text image understanding, transitioning from
encoder-only/encoder-decoder models to a decoder-only model. It is
pre-trained by incorporating dual transcription tasks
(spatially-aware text block generation and structured markdown text
generation) into a single, unified model architecture.
- This innovative method streamlines the application interface by
integrating generative multimodal language modeling, simplifying the
traditionally complex cascaded pipelines used for various downstream
tasks.
- Furthermore, Kosmos-2.5 demonstrates
impressive multimodal literate capabilities, thus setting the stage
for future scaling of multimodal large language models.
# Kosmos-2.5
## Model Architecture
The model architecture of Kosmos-2.5
consists of a pre-trained vision encoder and a language decoder
connected with a resampler module, shown in
[fig:model_arch]. We adopt the
pre-trained vision encoder based on the Vision Transformer
(ViT) [vit](http://arxiv.org/pdf/2105.15075v2). We further adapt a Perceiver Resampler
module with an attentive pooling mechanism to reduce the size of image
embeddings [alayrac2022flamingo](http://arxiv.org/pdf/2205.07065v1). The language decoder is
built upon the Transformer-based decoder to condition on image and text
context for the next token prediction.
## Image and Text Representations
Kosmos-2.5 takes a composite input
consisting of an image and a text representation. **The image
representation** is uniform across various configurations and leverages
a variable-resolution input strategy following
Pix2Struct [lee2023pix2struct](http://arxiv.org/pdf/2210.03347v2). Precisely, we extract the
maximum number of fixed-size patches ($16 \times 16$) that can fit
within a predefined sequence length $L$. In addition,
Resampler [alayrac2022flamingo](http://arxiv.org/pdf/2205.07065v1) is used as an attentive
pooling mechanism to reduce the number of image embeddings. **The text
representation**, however, is more versatile and can be one of two
types: text lines with bounding boxes or plain markdown texts.
**Text lines with bounding boxes:** For the layout-based document
representation, text lines and their associated bounding boxes are
extracted. Inspired by
Kosmos-2 [peng2023kosmos](http://arxiv.org/pdf/2305.16103v1),
we ground the text lines to their spatial positions in images by
aligning their representations. The coordinates of these bounding boxes
are then converted into discrete location tokens. Given that $L$ also
represents the maximum length for each image dimension, we introduce a
set of $2L+2$ specialized tokens. These tokens, ``,
``, …, ``, ``, …, ``,
``, and ``, correspond to the coordinates and the start and
end of a bounding box. The coordinates are obtained by rounding down the
actual position after resizing images. Consider a document $T$ that
comprises $N$ text lines. Each line is represented as
$\mathbf{T}_n = \{ w_1^{(n)}, w_2^{(n)}, \ldots, w_{M_n}^{(n)} \}$,
where $M_n$ is the number of words in the $n$-th text line. The bounding
box for $\mathbf{T}_n$ is then denoted by
$\mathbf{B}_n = \texttt{<} x_{\text{tl}}^{(n)} \texttt{><} y_{\text{tl}}^{(n)} \texttt{><} x_{\text{br}}^{(n)} \texttt{><} y_{\text{br}}^{(n)} \texttt{>}$,
which includes coordinates for its top-left and bottom-right corners.
**Markdown texts:** For the markup-based document representation where
the output text is in the markdown format, the text component captures
both content and formatting markup. Unlike layout-based documents,
markdown text does not require bounding boxes. Instead, the text is
directly tokenized, retaining all special characters and formatting
indicators.
To facilitate these diverse input types, we employ different composite
representations. For image-text pairs with text lines and bounding
boxes, the input is denoted as `Image Embedding`
$\bigcup_{n=1}^{N}$ ($\mathbf{B}_n \oplus \mathbf{T}_n)$ ``. The
operator $\oplus$ represents the concatenation of the text line
$\mathbf{T}_n$ and its bounding box $\mathbf{B}_n$. Conversely, when the
text is in the markdown format, the input simplifies to
`Image EmbeddingMarkdown Text`. In both cases,
`` and `` signify the sequence boundaries, while `` and
`` indicate the beginning and end of image embeddings. This
flexibility in text representation allows
Kosmos-2.5 to apply to various document
analysis tasks.
## Pre-training Data
The pre-training process enables
Kosmos-2.5 to learn versatile
representations suitable for various text-intensive image understanding
tasks. The model is pre-trained on a rich array of datasets from diverse
sources. Traditional Optical Character Recognition (OCR) task is
primarily geared towards generating text content and its 2D positions
within an image. However, they often neglect the need to maintain the
order and structural integrity of the original document, which is
essential for text-intensive image understanding tasks involving
structured information.
To address this, we steer Kosmos-2.5 to
excel in two distinct yet cooperative transcription tasks: (1)
generating spatially-aware text blocks, where each block of text is
assigned its spatial coordinates within the image, and (2) producing
structured text output that captures styles and structures into the
markdown format. Markdown provides an advantage over plain text by
explicitly distinguishing different structural elements, such as tables
and lists, with specific tokens. For example, table cells can be denoted
with vertical bars (\|) and list items with bullets (\*, -, or +). It
also standardizes the representation of typographic emphases like bold
(\*\*bold\*\*) and italics (\*italics\*), integrating the learning of
document structure with natural language understanding in a unified
model.
For spatially-aware text blocks, we use:
- **IIT-CDIP:** The IIT-CDIP dataset is a large-scale public
collection comprising scanned document images. We used approximately
27.6 million pages to train our model.
- **arXiv papers:** arXiv, an open-access research-sharing platform,
provides another significant data source, accounting for roughly
20.9 million pages. We downloaded a bulk of data, consisting of PDF
and LaTeX source files, from the official arXiv repository[^2].
- **PowerPoint slides:** A corpus of 6.2 million pages is collected
from various web pages containing PowerPoint documents,
significantly enhancing the diversity of our training data.
- **General PDF:** Additionally, we crawled the web for diverse
open-domain digital PDF files, leading to the collection of a large
corpus comprising approximately 155.2 million pages.
- **Web screenshots:** A subset of the mC4 webpages is scraped and
rendered as screenshots containing almost 100 million pages.
For structured text output in markdown format, we use:
- **README:** We collect 2.9 million “README.md” files from
open-source GitHub projects, primarily written in markdown format.
- **DOCX:** We also extract 1.1 million DOCX pages from millions of
WORD files crawled from the web. The DOCX pages are converted to
markdown format, and each page corresponds to its markdown
information.
- **LaTeX:** A subset of the entire arXiv papers is used to extract
the mapping of PDF pages and its corresponding markdown information
converted from the LaTeX code, which contains a total of 3.7 million
pages.
- **HTML:** We obtain 6.3 million HTML files from the aforementioned
mC4 subset and convert them into markdown format.
## Data Processing [section:dp]
The pre-training data has a wide coverage, and each type of data
requires a different processing workflow, which is introduced as
follows:
#### IIT-CDIP
The IIT-CDIP dataset mainly consists of scanned document images. We use
the Microsoft Read API [^3] to extract text and layout information.
#### arXiv papers, PowerPoint slides, General PDF
We first compile and convert arXiv papers and PowerPoint slides into PDF
files. Together with other general PDFs, we employed the PyMuPDF parser
[^4] to extract text and layout information efficiently.
#### Web screenshots
We also include webpage screenshots in the model pre-training to
diversify the layout distribution further. We collect the webpage URLs
from the English portion of the mC4 dataset. Playwright [^5] is used to
access a specified URL and open the webpage. The HTML content of the
page is extracted and parsed using the lxml library [^6] to obtain a
Document Object Model (DOM) tree representation. This DOM tree is
traversed, examining the XPath of each element within it. This traversal
aims to determine whether each element is visible and retrieve
information about its bounding boxes.
#### README (markdown)
In addition to layout-based data, we collect markup-based data for the
pre-training. We collect “README.md” files from many GitHub projects and
convert these files into HTML using Pandoc [^7]. Then, wkhtmltopdf [^8]
is used to obtain the images from the generated HTML content.
#### DOCX (markdown)
The Microsoft Office WORD files have been extensively used in existing
research like TableBank [li2020tablebank](https://arxiv.org/pdf/1903.01949) and
ReadingBank [wang2021layoutreader](http://arxiv.org/pdf/2108.11591v2). We collect WORD DOCX
files and convert them into texts with markdown. First, we use Pandoc to
convert the XML content within the DOCX files into markdown files. As
Pandoc keeps the “\” tags to represent the tabular cells in the
generated markdown, we further identify all the tables and use
markdownify [^9] to convert them into the markdown formats. Finally, the
original DOCX files are converted into PDF files, and each page is
aligned to the corresponding span of the markdown content based on a
heuristic method.
#### LaTeX (markdown)
LaTeX documents from arXiv have been used to generate PDF files to
obtain texts with bounding boxes. Meanwhile, we also convert the
LaTeX content into the markdown texts. Similar to
Nougat [blecher2023nougat](https://arxiv.org/pdf/2308.13418), LaTeXML [^10] is used to
convert the LaTeX code into the HTML sequence, which is further
transformed into the markdown format. Different from Nougat, we keep all
the tables at the beginning of the page as most LaTeX users prefer to
position tables with “\[t\]” or “\[h\]” instead of “\[b\]”. Meanwhile,
we also convert the table content from the LaTeX format into the
markdown format.
#### HTML (markdown)
The most straightforward way to obtain markdown resources from HTML
webpages is through web scraping. However, webpages are often cluttered
with various layouts and styles, resulting from the misuse of HTML tags.
Moreover, HTML pages may include extraneous elements, such as
advertisements, navigation menus, or formatting elements, making
extracting clean and meaningful content challenging. To overcome these
obstacles, we employ Playwright, a fast and reliable end-to-end testing
framework for the web. The library allows us to navigate the HTML
structure, filter out non-essential elements, and extract the relevant
text content. We also apply custom rules and regular expressions to
further refine the extracted text and format it as markdown, ensuring
that the resulting markdown files are coherent and readable.
## Filtering and Quality Control
We employ fastText for language identification (with a threshold of 0.5)
to filter out non-English documents from the entire pre-training
dataset. To ensure content diversity within each source, we utilize the
MinHash [broder1997resemblance](http://arxiv.org/pdf/2103.07007v1) to identify and remove
redundant pages. We use the same parameters
as [lee2021deduplicating](http://arxiv.org/pdf/2107.06499v2) and a document pair with
similarity 0.8 will be marked as duplicate. A comprehensive breakdown of
the pre-training data, along with their respective sampling ratios, is
provided in
1. When dealing with
image-to-markdown data from README, DOCX, LaTeX, and HTML sources, we
observe discrepancies between the content in text images and their
corresponding markdown sequences due to conversion issues. Consequently,
we refine the data by evaluating token overlap between images and
markdown files, requiring a token intersection-to-union ratio greater
than 0.95 for inclusion.
Section 6.2 shows some of the training samples.
# Experiments
## Evaluation
#### Text Recognition
We utilize word-level *precision* (# or correct matches over the number
of detected words), *recall* (# of correct matches over the number of
ground truth words), and *f1* as the metrics to evaluate the text
recognition performance. If there are repeated words in the ground
truth, they are expected to be repeated in the prediction. Text
recognition is evaluated on three benchmark datasets, including
FUNSD [jaume2019funsd](https://arxiv.org/pdf/1905.13538),
SROIE [huang2019icdar2019](http://arxiv.org/pdf/2103.10213v1) and
CORD [park2019cord](http://arxiv.org/pdf/2103.10213v1). We compare
Kosmos-2.5 to the text recognition
results from Document OCR in Google Document AI [^11].
#### Image-to-markdown Generation
In light of the unique nature of the image-to-markdown conversion task,
assessing the quality of the generated markdown necessitates specialized
metrics. We adopt a two-fold evaluation scheme: Normalized Edit Distance
(NED) and Normalized Tree Edit Distance (NTED), considering both the
lexical accuracy and the preservation of the original structural
elements.
The NED is formulated as
$$\textit{NED} = 1-\frac{1}{N} \sum_{i=1}^N D\left(s_i, \hat{s}_i\right) / \max \left(\mathrm{len}(s_i), \mathrm{len}(\hat{s}_i\right))$$
where $N$, $s$, and $\hat{s}$ denote the number of samples, prediction,
and ground truth, respectively. $D(\cdot,\cdot)$ and
$\mathrm{len}(\cdot)$ represent the edit distance function and the
length of a string. The *NED* value ranges from 0 to 1, with a higher
*NED* value indicating the prediction is closer to the ground truth.
However, given the hierarchical structure inherent to markdown, relying
solely on a string-based comparison metric like NED can be insufficient.
Thus, we adopt NTED as an additional evaluation metric for structural
differences. NTED is a tree edit distance normalized by the number of
nodes in the tree, considering the structural discrepancies between
parse trees. Specifically, the predicted markdown sequence is first
transformed into an HTML tree. Then, the tree edit distance between the
prediction and the ground truth is calculated using the ZSS algorithm
[zhang1989simple](http://arxiv.org/pdf/1703.08940v1). The NTED is formulated as
$$\textit{NTED} = 1-\frac{1}{N} \sum_{i=1}^N \mathrm{TD}\left(t_i, \hat{t}_i\right) / \max \left(\mathrm{node}(t_i), \mathrm{node}(\hat{t}_i\right))$$
where $N$, $t$, and $\hat{t}$ signify the number of samples, the HTML
tree of prediction, and the HTML tree of ground truth, respectively.
Besides, $\mathrm{TD}(\cdot,\cdot)$ and $\mathrm{node}(\cdot)$ stand for
the tree edit distance function and the number of nodes in a tree.
We create three datasets to evaluate the image-to-markdown task from
different data sources, including document-level markdown generation,
README markdown generation and table markdown generation. Each dataset
includes 1,000 $\langle$image, markdown$\rangle$ pairs, which are held
out from the pre-training data. We compare
Kosmos-2.5 to the markdown generated by
the Nougat [blecher2023nougat](https://arxiv.org/pdf/2308.13418) base and small models.
## Implementation Details
We employ the AdamW optimizer [loshchilov2017decoupled](http://arxiv.org/pdf/2311.11446v2)
with $\beta=(0.9,0.98)$ for optimization, setting the weight decay to
0.01 and the dropout rate to 0.1. The learning rate is warmed up to
$2 \times 10^{-4}$ during the initial 375 steps, followed by a linear
decay to zero throughout the remaining training steps. The batch size is
adjustable to align with the available computational resources and
specific training requirements.
Kosmos-2.5 contains a total of 1.3
billion parameters. The vision encoder is initialized from the encoder
of the Pix2Struct-Large model. The language decoder includes 24
Transformer layers with a hidden size of 1,536, an FFN intermediate size
of 6,144, and 16 attention heads.
Section 6.1 shows more details of the training
hyperparameters.
Due to the substantially larger quantity of available layout-based data
than markup-based data, we initially trained the model for 100k steps
exclusively using the layout-based dataset. Subsequently, the two
datasets were combined for further training of 140k steps. Additionally,
we incorporate the training split of the evaluation dataset into the
entire pre-training data, extending the process by an additional 10k
steps. For text tokenization, we utilize
SentencePiece [kudo2018sentencepiece](http://arxiv.org/pdf/1808.06226v1) and adopt the
“full-sentence” format [liu2019roberta](http://arxiv.org/pdf/1907.11692v1). This approach
packs each input sequence with full sentences, continuously sampled from
one or multiple documents. Newly added word embeddings of location
tokens are randomly initialized, with all parameters updated during
training. We also leverage the data augmentation approaches from
TrOCR [li2022trocr](https://arxiv.org/pdf/2109.10282) in the training to make models more
robust.
Throughout the evaluation process, model inference is conducted using a
single model checkpoint across various evaluation datasets with the
corresponding task prompt respectively, demonstrating that our approach
does not necessitate individualized model fine-tuning for each dataset.
## Results
Kosmos-2.5 is a flexible framework that
facilitates multitasking, with tasks determined by the provided task
prompts. Experimental results are demonstrated in Table
2 and Table
3. Specifically, for the text
recognition task, our Kosmos-2.5
outperforms Google Document OCR by 0.33%, 2.45%, and 1.35% in terms of
the F1 score, showcasing its effectiveness. For the image-to-markdown
task, it is worth noting that our method significantly outperforms the
Nougat [blecher2023nougat](https://arxiv.org/pdf/2308.13418). For example,
Kosmos-2.5 achieves a notable improvement
of 33.68% (95.09% vs 61.41%) over $\text{Nougat}_{\text{\,BASE}}$ in
terms of NED on the README dataset. Besides, regarding NTED,
Kosmos-2.5 also boosts the performance by
33.38% (82.08% vs 48.70%) compared with $\text{Nougat}_{\text{\,BASE}}$
on the Documents dataset. We attribute the performance boost to the
increased diversity of our training data compared to Nougat, which
primarily focuses on the academic paper domain. Notably, the greater
diversity in our training data significantly enhances our model’s
comprehension of different document types and strengthens its
generalization capabilities. In summary, the experimental results
validate the remarkable capabilities of
Kosmos-2.5 in various tasks.
| **Dataset** | **FUNSD** | **SROIE** | **CORD** |
|:--:|:--:|:--:|:--:|
| 2-4 | **P / R / F1** | **P / R / F1** | **P / R / F1** |
| Commercial OCR | **85.12** / 80.86 / 82.93 | 89.68 / 89.69 / 89.69 | 81.95 / 86.87 / 84.34 |
| Kosmos-2.5$^\dagger$ | 83.88 / **82.66** / **83.26** | **91.72 / 92.57 / 92.14** | **83.64 / 87.83 / 85.69** |
Experimental results on text recognition using Precision (%), Recall
(%), F1 (%), where model inference is conducted with the layout task
prompt. $^\dagger$Kosmos-2.5 does not
require task-specific fine-tuning.
| **Dataset** | **General Documents** | **README** | **Tables** |
|:--:|:--:|:--:|:--:|
| 2-4 | **NED / NTED** | **NED / NTED** | **NED / NTED** |
| $\text{Nougat}_{\text{\,SMALL}}$ [blecher2023nougat](https://arxiv.org/pdf/2308.13418)$^\dag$ | 82.80 / 48.96 | 58.58 / 35.49 | 68.33 / 61.52 |
| $\text{Nougat}_{\text{\,BASE}}$ [blecher2023nougat](https://arxiv.org/pdf/2308.13418)$^\dag$ | 83.75 / 48.70 | 61.41 / 36.41 | 68.53 / 61.60 |
| Kosmos-2.5$^\ddagger$ | **91.59** / **82.08** | **95.09** / **91.18** | **85.14** / **90.64** |
Experimental results on image-to-markdown using NED (%) and NTED (%),
where model inference is conducted with the markup task prompt.
$^\dag$Nougat [blecher2023nougat](https://arxiv.org/pdf/2308.13418) generates the table
content in the LaTeX format, which is converted to the markdown format
for fair comparison.
$^\ddagger$Kosmos-2.5 does not require
task-specific fine-tuning.
## Discussion
Input
Using the layout prompt
Using the markup promptModel outputs from Kosmos-2.5
with different task prompts given the same input text
image.
We illustrate an example in
4, showcasing the model outputs produced by
Kosmos-2.5 with various task prompts when
presented with the same input text image. As shown in the figure, the
model generates distinct outputs depending on the task prompts it
receives. When given the layout task prompt, the model produces the
following text sequence, which includes textual content and
corresponding bounding boxes:
```
[x_52] [y_113] [x_756] [y_145]: NYC Department of Education School Year Calendar 2023-2024
[x_52] [y_159] [x_826] [y_181]: This is the 2023-24 school year calendar for all 3K-12 NYCDOE public schools. If your child attends a private,
[x_52] [y_180] [x_820] [y_202]: parochial, charter school, NYC Early Education Center (NYCEEC) or Family Childcare Program, please contact
[x_52] [y_201] [x_639] [y_223]: your child's school for information about their calendar. Please note the following:
[x_65] [y_223] [x_77] [y_245]: $\bullet$
[x_92] [y_223] [x_825] [y_245]: On days when school buildings are closed due to inclement weather or other emergencies, all students
...
```
With the markup task prompt, the model generates another text sequence
that follows the markdown format:
```
# NYC Department of Education School Year Calendar 2023-2024
This is the 2023-24 school year calendar for all 3K-12 NYCDOE public schools. If your child attends a private, parochial, charter school, NYC Early Education Center (NYCEEC) or Family Childcare Program, please contact your child's school for information about their calendar. Please note the following:
...
- On this schedule, **elementary schools** are defined as programs that serve kindergarten (K) through grade 8, including schools with 3-K and Pre-K programs, as well as those that end in grade 5. **Middle schools** are defined as programs that serve grades 6-8, and **high schools** are defined as programs that serve grades 9-12.
...
```
It is apparent that Kosmos-2.5 excels in
precisely identifying text positions and recognizing text content.
Moreover, it adeptly captures the styles and structures present within
the text image, including elements like titles, bullet points, tables,
and bold text. Section 6.3 provides the full output sequence
using different task prompts for this example.
Kosmos-2.5 provides a unified
architecture and interface for text image understanding, making it
versatile for various application scenarios. Firstly, it can be
fine-tuned as a single model for a wide range of text image
understanding tasks, including information extraction, layout detection
and analysis, visual question answering, screenshot understanding, UI
automation, and many others. This unified model interface significantly
streamlines downstream task training and enables the model to
effectively follow instructions in real-world applications. Secondly,
our solution is compatible with more powerful LLMs like GPT-3.5 or
GPT-4. The output from our model can serve as contexts for LLMs,
enhancing their capabilities through further prompt engineering. This
approach empowers LLMs with robust text image understanding
capabilities. Thirdly, we have the potential to augment the pre-training
with textual data, transforming it into a general-purpose MLLM. This
expanded model not only processes visual signals but also possesses
strong language understanding capabilities.
# Related Work
## Multimodal Large Language Models
The flourishing blossom of large language models (LLM), represented by
ChatGPT [chatgpt](https://openai.com/blog/chatgpt), has revolutionized artificial
intelligence and significantly impacted numerous downstream tasks such
as text translation, code generation, question answering, etc. Despite
the rapid development, it is significant to recognize that the human
perception of the world is not limited to language alone but encompasses
a wide range of modalities, with particular emphasis on the visual
modality. Many research works attempt to “bring eyes” to LLM and develop
multimodal large language models (MLLM), which can be categorized into
LLM-centric scheduling systems and end-to-end trainable multimodal
systems.
The LLM-centric scheduling system
[wu2023visual](http://arxiv.org/pdf/2303.04671v1), [yang2023mm](http://arxiv.org/pdf/2303.11381v1), [liang2023taskmatrix](http://arxiv.org/pdf/2303.16434v1), [shen2023hugginggpt](http://arxiv.org/pdf/2303.17580v4), [liu2023internchat](http://arxiv.org/pdf/2012.09130v1), [suris2023vipergpt](http://arxiv.org/pdf/1905.11127v1), [chen2023language](http://arxiv.org/pdf/2310.15166v1)
takes advantage of many vision foundation models (e.g., Stable Diffusion
[rombach2022high](http://arxiv.org/pdf/2307.10094v1), ControlNet
[zhang2023adding](http://arxiv.org/pdf/2210.12192v1), BLIP [li2022blip](http://arxiv.org/pdf/2311.01038v2),
etc.), and schedules these models in a language-centric manner. For
example, Visual ChatGPT [wu2023visual](http://arxiv.org/pdf/2303.04671v1) develops a set of
prompts to incorporate visual information into ChatGPT, enabling users
to draw or edit images through chatting. MM-REACT
[yang2023mm](http://arxiv.org/pdf/2303.11381v1) leverages vision experts to augment its
multimodal capabilities by incorporating a textual prompt design that
can effectively represent various visual signals, including text
descriptions, coordinates, and aligned file names, for images and
videos. HuggingGPT [shen2023hugginggpt](http://arxiv.org/pdf/2303.17580v4) connects LLMs
with extensive AI models in machine learning communities, tackling user
requests through ChatGPT’s task planning, model selection, and response
summarization capabilities. Further, TaskMatrix.AI
[liang2023taskmatrix](http://arxiv.org/pdf/2303.16434v1) largely extends the scale and
connects foundation models with millions of APIs for solving tasks in
both digital and physical domains. Differently, InternGPT
[liu2023internchat](http://arxiv.org/pdf/2012.09130v1) incorporates pointing instructions
(e.g., clicking and dragging) for better communication between chatbots
and users, while also improving the accuracy of chatbots in performing
vision-centric tasks. Nevertheless, this approach has several
limitations, such as the expenses associated with API calls or the
storage space required for the pre-trained weights of foundation models.
End-to-end trainable multimodal system
[metalm](http://arxiv.org/pdf/0911.2327v1), [alayrac2022flamingo](http://arxiv.org/pdf/2205.07065v1), [huang2023language](http://arxiv.org/pdf/2302.14045v2), [peng2023kosmos](http://arxiv.org/pdf/2305.16103v1), [huang2021seeing](http://arxiv.org/pdf/2402.17510v1), [xue2021probing](http://arxiv.org/pdf/1911.03875v3), [zhu2023minigpt](http://arxiv.org/pdf/2402.17510v1), [huang2023sparkles](http://arxiv.org/pdf/2308.16463v2), [li2023blip](http://arxiv.org/pdf/2301.12597v3), [dai2023instructblip](https://arxiv.org/pdf/2305.06500), [liu2023visual](http://arxiv.org/pdf/2402.11690v1), [luo2023cheap](http://arxiv.org/pdf/2210.09175v1), [wang2023visionllm](http://arxiv.org/pdf/2312.13503v1), [su2023pandagpt](http://arxiv.org/pdf/1808.10000v1), [zhang2023llama](http://arxiv.org/pdf/2207.10858v1), [gao2023llama](http://arxiv.org/pdf/2303.16199v2), [koh2023grounding](http://arxiv.org/pdf/2401.13388v2), [li2023otter](http://arxiv.org/pdf/2311.00233v2)
integrates vision and language models into a unified model, which are
further trained on multimodal datasets. For instance, Flamingo
[alayrac2022flamingo](http://arxiv.org/pdf/2205.07065v1) leverages gated cross-attention to
fuse pre-trained vision and language models, showing impressive ability
in downstream multimodal tasks. Besides, BLIP-2
[li2023blip](http://arxiv.org/pdf/2301.12597v3) utilized Q-Former to align the visual
features with a large language model. Furthermore, Instruct-BLIP
improves the training of Q-Former by introducing a novel
instruction-aware visual feature extraction method. Based on this
design, MiniGPT-4 [zhu2023minigpt](http://arxiv.org/pdf/2402.17510v1) uses Vicuna
[vicuna2023](https://lmsys.org/blog/2023-03-30-vicuna/) as the text encoder and fine-tunes detailed
image descriptions to better match user intent. Sparkles unlocks
multimodal instruction-following models’ capabilities in open-ended
dialogues involving multiple images [huang2023sparkles](http://arxiv.org/pdf/2308.16463v2).
LLaVA [liu2023visual](http://arxiv.org/pdf/2402.11690v1) injects visual features into the
language model by treating image tokens as a foreign language, and uses
conversation generated by GPT-4 [gpt4](https://openai.com/gpt-4) for fine-tuning.
Kosmos-1
[huang2023language](http://arxiv.org/pdf/2302.14045v2) is trained from scratch using
web-scale corpora while showing impressive performance in zero-shot,
few-shot, and multimodal chain-of-thought prompting settings.
Analogously, Kosmos-2
[peng2023kosmos](http://arxiv.org/pdf/2305.16103v1) incorporates grounding and referring
abilities and can accept image regions users select using bounding boxes
as input. mPLUG-Owl [ye2023mplug](http://arxiv.org/pdf/2405.00390v2) efficiently fine-tunes
the language model using low-rank adaption with multimodal instruction
datasets. Otter [li2023otter](http://arxiv.org/pdf/2311.00233v2) is built using Flamingo and
aims to explore multimodal in-context learning capabilities.
## Text Image Understanding
Text image understanding is a cutting-edge technology that harnesses the
power of artificial intelligence, including natural language processing
and computer vision, to automatically comprehend, categorize, and
extract information from documents [cui2021document](https://arxiv.org/pdf/2111.08609). Any
file containing written or printed characters can be considered a
document, including web pages, slides, posters, and even scene text
images. Documents are ubiquitous in our daily lives, so the research on
documents is significant.
Before the deep learning era, researchers used rule-based heuristic
approaches for document analysis
[wong1982document](http://arxiv.org/pdf/2402.11048v1), [o1993document](http://arxiv.org/pdf/2305.08719v2). They manually observed
layout information and summarized heuristic rules, but these methods are
not scalable and require enormous labour costs. Subsequently, the rise
of deep learning has led to significant advancements in the field of
Document AI
[xu2020layoutlm](http://arxiv.org/pdf/2305.18721v2), [xu-etal-2021-layoutlmv2](https://doi.org/10.18653/v1/2021.acl-long.201), [xu2021layoutxlm](https://arxiv.org/pdf/2104.08836), [huang2022layoutlmv3](http://arxiv.org/pdf/2204.08387v3), [chen2022xdoc](http://arxiv.org/pdf/2310.16527v1), [li2021markuplm](http://arxiv.org/pdf/2110.08518v2), [li2022dit](http://arxiv.org/pdf/2310.16527v1), [li2021selfdoc](http://arxiv.org/pdf/2009.14457v2), [appalaraju2021docformer](http://arxiv.org/pdf/2309.05503v1), [wang2022lilt](http://arxiv.org/pdf/2202.13669v1), [gu2022xylayoutlm](http://arxiv.org/pdf/2203.13530v2), [li2021structurallm](http://arxiv.org/pdf/2311.01038v2), [yu2023structextv2](http://arxiv.org/pdf/2310.16527v1).
For example, LayoutLM series
[xu2020layoutlm](http://arxiv.org/pdf/2305.18721v2), [xu-etal-2021-layoutlmv2](https://doi.org/10.18653/v1/2021.acl-long.201), [huang2022layoutlmv3](http://arxiv.org/pdf/2204.08387v3)
employs large-scale document data for pre-training and incorporates
text, layout, and image information into the model, showing impressive
performance in downstream tasks like key information extraction and
document question answering. Similarly, DocFormer
[appalaraju2021docformer](http://arxiv.org/pdf/2309.05503v1) introduces an additional task
to reconstruct the document image during pre-training.
Donut [kim2021donut](http://arxiv.org/pdf/2202.00470v1) introduces an OCR-free document
understanding Transformer, directly mapping an input document image to
the desired output with OCR. MarkupLM [li2021markuplm](http://arxiv.org/pdf/2110.08518v2)
takes advantage of large-scale webpages from Common Crawl and uses
node-level hierarchical structure information as the pre-training
objective. XDoc [chen2022xdoc](http://arxiv.org/pdf/2310.16527v1) introduces a unified
framework for tackling multiple document formats in one model for
parameter efficiency. UDOP [tang2023unifying](http://arxiv.org/pdf/2212.02623v3) designs a
unified model that integrates text, image, and layout modalities,
showing impressive performance on diverse document understanding tasks.
Pix2Struct [lee2023pix2struct](http://arxiv.org/pdf/2210.03347v2) is a pre-trained
image-to-text model trained to parse masked screenshots of web pages
into simplified HTML.
Despite significant progress in text image understanding, most models
are designed for specific tasks and lack generalizability. On the
contrary, the proposed Kosmos-2.5
represents an important step forward in this field, demonstrating the
potential of MLLM in achieving robust and generalizable performance
across a wide range of text image types.
# Conclusion and Future Work
We introduced Kosmos-2.5, a multimodal
literate model built on the strengths of
Kosmos-2, designed to enhance machine
understanding of text-intensive images. This model shifted from
conventional encoder-only/encoder-decoder models to a more unified,
decoder-only architecture. The shift to generative multimodal language
modeling simplifies task interfaces, eliminating the need for complex,
task-specific pipelines. Moreover,
Kosmos-2.5 demonstrated potential in
few-shot and zero-shot learning capabilities, laying a foundation for
future advances and scalability in multimodal literate models.
Despite these promising results, our current model faces some
limitations, offering valuable future research directions. For instance,
Kosmos-2.5 currently does not support
fine-grained control of document elements’ positions using natural
language instructions, despite being pre-trained on inputs and outputs
involving the spatial coordinates of text. Instruction tuning could
offer a promising route to enhance this aspect of the model, leading to
broader application capabilities. Furthermore, documents spanning
multiple pages pose a challenge as they typically demand holistic
processing and comprehension. Meanwhile, it is also feasible that
Kosmos-2.5 allows for multiple image
pages interleaved with text as input; however, managing long context
windows remains a vital issue we aim to address in future work.
In the broader research landscape, a significant direction lies in
furthering the development of model scaling capabilities. With an
expanding spectrum of tasks and rising complexities, scaling up the
model to handle larger volumes of data is crucial for the progression of
multimodal literate models. Ultimately, our goal is to develop a model
that effectively interprets both visual and textual data, and
generalizes smoothly across an expanded array of text-intensive
multimodal tasks.
# Acknowledgement [acknowledgement]
We would like to acknowledge Zhiliang Peng for the helpful discussions.
# Supplementary Material
## Hyperparameters [supp:para]
The settings of hyperparameters are demonstrated in
5.
## Data Samples [supp:data]
We demonstrate some of the training samples in
Kosmos-2.5, which include the input and
output from IIT-CDIP, arXiv papers, PowerPoint slides, general PDFs, web
screenshots, README, DOCX, LaTeX and HTML.
Input
Rendered outputA training sample for the layout-based task from
IIT-CDIPInput
Rendered outputA training sample for the layout-based task from arXiv
papers (single-column)Input
Rendered outputA training sample for the layout-based task from arXiv
papers (two-column)Input
Rendered outputA training sample for the layout-based task from PowerPoint
slidesInput
Rendered outputA training sample for the layout-based task from
PDFsInput
Rendered outputA training sample for the layout-based task from web
screenshotsInput
Rendered outputA training sample for the markup-based task from
READMEInput
Rendered outputA training sample for the markup-based task from
DOCXInput
Rendered outputA training sample for the markup-based task from
LaTeX (single-column)Input
Rendered outputA training sample for the markup-based task from
LaTeX (two-column)Input
Rendered outputA training sample for the markup-based task from
HTMLs
## Examples of Model Inference [supp:example]
```
[x_52] [y_113] [x_756] [y_145]: NYC Department of Education School Year Calendar 2023-2024
[x_52] [y_159] [x_826] [y_181]: This is the 2023-24 school year calendar for all 3K-12 NYCDOE public schools. If your child attends a private,
[x_52] [y_180] [x_820] [y_202]: parochial, charter school, NYC Early Education Center (NYCEEC) or Family Childcare Program, please contact
[x_52] [y_201] [x_639] [y_223]: your child's school for information about their calendar. Please note the following:
[x_65] [y_223] [x_77] [y_245]: $\bullet$
[x_92] [y_223] [x_825] [y_245]: On days when school buildings are closed due to inclement weather or other emergencies, all students
[x_92] [y_244] [x_525] [y_266]: and families should plan on participating in remote learning.
[x_65] [y_265] [x_77] [y_287]: $\bullet$
[x_92] [y_265] [x_846] [y_287]: Individual schools' Parent-Teacher Conference dates might be different from the dates below. Your child's
[x_92] [y_286] [x_491] [y_308]: teacher will work with you to schedule your conference.
[x_65] [y_308] [x_77] [y_330]: $\bullet$
[x_92] [y_307] [x_845] [y_330]: On this schedule, elementary schools are defined as programs that serve kindergarten (K) through grade
[x_92] [y_329] [x_826] [y_351]: 8, including schools with 3-K and Pre-K programs, as well as those that end in grade 5. Middle schools
[x_92] [y_350] [x_810] [y_372]: are defined as programs that serve grades 6-8, and high schools are defined as programs that serve
[x_92] [y_371] [x_186] [y_393]: grades 9-12.
[x_60] [y_414] [x_106] [y_436]: DATE
[x_318] [y_414] [x_399] [y_436]: WEEKDAY
[x_605] [y_414] [x_659] [y_436]: EVENT
[x_60] [y_437] [x_155] [y_459]: September 7
[x_297] [y_437] [x_366] [y_459]: Thursday
[x_432] [y_437] [x_565] [y_459]: First day of school
[x_60] [y_470] [x_164] [y_492]: September 14
[x_297] [y_470] [x_366] [y_492]: Thursday
[x_432] [y_459] [x_804] [y_481]: Evening Parent-Teacher Conferences for elementary
[x_432] [y_480] [x_622] [y_503]: schools and Pre-K Centers
[x_60] [y_514] [x_164] [y_536]: September 21
[x_297] [y_514] [x_366] [y_536]: Thursday
[x_432] [y_504] [x_832] [y_526]: Evening Parent-Teacher Conferences for middle schools
[x_432] [y_525] [x_553] [y_547]: and D75 schools
[x_60] [y_548] [x_164] [y_570]: September 25
[x_297] [y_548] [x_360] [y_570]: Monday
[x_432] [y_548] [x_630] [y_570]: Yom Kippur, schools closed
[x_60] [y_581] [x_164] [y_603]: September 28
[x_297] [y_581] [x_366] [y_603]: Thursday
[x_432] [y_570] [x_818] [y_593]: Evening Parent-Teacher Conferences for high schools,
[x_432] [y_592] [x_601] [y_614]: K-12, and 6-12 schools
[x_60] [y_625] [x_135] [y_647]: October 9
[x_297] [y_625] [x_360] [y_647]: Monday
[x_432] [y_614] [x_786] [y_636]: Italian Heritage/Indigenous Peoples' Day, schools
[x_432] [y_636] [x_482] [y_658]: closed
[x_60] [y_679] [x_152] [y_701]: November 2
[x_297] [y_679] [x_366] [y_701]: Thursday
[x_432] [y_658] [x_829] [y_680]: Afternoon and Evening Parent-Teacher Conferences for
[x_432] [y_679] [x_833] [y_701]: elementary schools; students in these schools dismissed
[x_432] [y_700] [x_556] [y_723]: three hours early
[x_60] [y_727] [x_152] [y_749]: November 7
[x_297] [y_727] [x_360] [y_749]: Tuesday
[x_432] [y_727] [x_745] [y_749]: Election Day, students do not attend school
[x_60] [y_775] [x_152] [y_797]: November 9
[x_297] [y_775] [x_366] [y_797]: Thursday
[x_432] [y_754] [x_829] [y_776]: Afternoon and Evening Parent-Teacher Conferences for
[x_432] [y_775] [x_793] [y_797]: middle schools and D75 schools; students in these
[x_432] [y_796] [x_687] [y_818]: schools dismissed three hours early
[x_60] [y_829] [x_161] [y_851]: November 16
[x_297] [y_829] [x_366] [y_851]: Thursday
[x_432] [y_819] [x_818] [y_841]: Evening Parent-Teacher Conferences for high schools,
[x_432] [y_840] [x_601] [y_862]: K-12, and 6-12 schools
[x_60] [y_884] [x_161] [y_906]: November 17
[x_297] [y_884] [x_344] [y_906]: Friday
[x_432] [y_863] [x_773] [y_885]: Afternoon Parent-Teacher Conferences for high
[x_432] [y_884] [x_791] [y_906]: schools, K-12, and 6-12 schools; students in these
[x_432] [y_905] [x_687] [y_927]: schools dismissed three hours early
[x_60] [y_928] [x_186] [y_950]: November 23-24
[x_297] [y_928] [x_416] [y_950]: Thursday-Friday
[x_432] [y_928] [x_692] [y_950]: Thanksgiving Recess, schools closed
[x_60] [y_960] [x_234] [y_983]: December 25-January 1
[x_297] [y_950] [x_368] [y_972]: Monday-
[x_297] [y_971] [x_360] [y_994]: Monday
[x_432] [y_960] [x_646] [y_983]: Winter Recess, schools closed
[x_60] [y_999] [x_140] [y_1021]: January 15
[x_297] [y_999] [x_360] [y_1021]: Monday
[x_432] [y_999] [x_789] [y_1021]: Rev. Dr. Martin Luther King Jr. Day, schools closed
[x_60] [y_1027] [x_170] [y_1049]: January 23- 26
[x_297] [y_1027] [x_410] [y_1049]: Tuesday-Friday
[x_432] [y_1027] [x_603] [y_1049]: Regents Administration
[x_52] [y_1099] [x_311] [y_1118]: NYCDOE School Year Calendar 2023-24
```
```
# NYC Department of Education School Year Calendar 2023-2024
This is the 2023-24 school year calendar for all 3K-12 NYCDOE public schools. If your child attends a private, parochial, charter school, NYC Early Education Center (NYCEEC) or Family Childcare Program, please contact your child's school for information about their calendar. Please note the following:
- On days when school buildings are closed due to inclement weather or other emergencies, all students and families should plan on participating in remote learning.
- Individual schools' Parent-Teacher Conference dates might be different from the dates below. Your child's teacher will work with you to schedule your conference.
- On this schedule, **elementary schools** are defined as programs that serve kindergarten (K) through grade 8, including schools with 3-K and Pre-K programs, as well as those that end in grade 5. **Middle schools** are defined as programs that serve grades 6-8, and **high schools** are defined as programs that serve grades 9-12.
| DATE | WEEKDAY | EVENT |
| --- | --- | --- |
| September 7 | Thursday | First day of school |
| September 14 | Thursday | Evening Parent-Teacher Conferences for elementary schools and Pre-K Centers |
| September 21 | Thursday | Evening Parent-Teacher Conferences for middle schools and D75 schools |
| September 25 | Monday | Yom Kippur, schools closed |
| September 28 | Thursday | Evening Parent-Teacher Conferences for high schools, K-12, and 6-12 schools |
| October 9 | Monday | Italian Heritage/Indigenous Peoples' Day, schools closed |
| November 2 | Thursday | Afternoon and Evening Parent-Teacher Conferences for elementary schools; students in these schools dismissed three hours early |
| November 7 | Tuesday | Election Day, students do not attend school |
| November 9 | Thursday | Afternoon and Evening Parent-Teacher Conferences for middle schools and D75 schools; students in these schools dismissed three hours early |
| November 16 | Thursday | Evening Parent-Teacher Conferences for high schools, K-12, and 6-12 schools |
| November 17 | Friday | Afternoon Parent-Teacher Conferences for high schools, K-12, and 6-12 schools; students in these schools dismissed three hours early |
| November 23-24 | Thursday-Friday | Thanksgiving Recess, schools closed |
| December 25-January 1 | Monday- Monday | Winter Recess, schools closed |
| January 15 | Monday | Rev. Dr. Martin Luther King Jr. Day, schools closed |
| January 23- 26 | Tuesday-Friday | Regents Administration |
```
[^1]: Equal contribution. $\dagger$ Corresponding author.
[^2]:
[^3]:
[^4]:
[^5]:
[^6]:
[^7]:
[^8]:
[^9]:
[^10]:
[^11]:
Nougat: Neural Optical Understanding for Academic Documents
2023-08-25
Lukas Blecher, Guillem Cucurull, Thomas Scialom, Robert Stojnic
Scientific knowledge is predominantly stored in books and scientific journals, often in the form of PDFs. However, the PDF format leads to a loss of semantic information, particularly for mathematical expressions. We propose Nougat (Neural Optical Understanding for Academic Documents), a Visual Transformer model that performs an Optical Character Recognition (OCR) task for processing scientific documents into a markup language, and demonstrate the effectiveness of our model on a new dataset of scientific documents. The proposed approach offers a promising solution to enhance the accessibility of scientific knowledge in the digital age, by bridging the gap between human-readable documents and machine-readable text. We release the models and code to accelerate future work on scientific text recognition.
Show Paper Content
# Introduction
The majority of scientific knowledge is stored in books or published in
scientific journals, most commonly in the Portable Document Format
(PDF). Next to HTML, PDFs are the second most prominent data format on
the internet, making up 2.4% of common crawl
[sebastian_spiegler_statistics_2013](https://docs.google.com/file/d/1_9698uglerxB9nAglvaHkEgU-iZNm1TvVGuCW7245-WGvZq47teNpb_uL5N9). However, the
information stored in these files is very difficult to extract into any
other formats. This is especially true for highly specialized documents,
such as scientific research papers, where the semantic information of
mathematical expressions is lost.
Existing Optical Character Recognition (OCR) engines, such as Tesseract
OCR [smith_overview_2007](https://doi.org/10.1109/ICDAR.2007.4376991), excel at detecting and
classifying individual characters and words in an image, but fail to
understand the relationship between them due to their line-by-line
approach. This means that they treat superscripts and subscripts in the
same way as the surrounding text, which is a significant drawback for
mathematical expressions. In mathematical notations like fractions,
exponents, and matrices, relative positions of characters are crucial.
Converting academic research papers into machine-readable text also
enables accessibility and searchability of science as a whole. The
information of millions of academic papers can not be fully accessed
because they are locked behind an unreadable format. Existing corpora,
such as the S2ORC dataset [lo_s2orc_2020](https://doi.org/10.18653/v1/2020.acl-main.447), capture the
text of 12M[^2] papers using GROBID [lopez_grobid_2023](https://github.com/kermitt2/grobid),
but are missing meaningful representations of the mathematical
equations.
To this end, we introduce Nougat, a transformer based model that can
convert images of document pages to formatted markup text.
The primary contributions in this paper are
- Release of a pre-trained model capable of converting a PDF to a
lightweight markup language. We release the code and the model on
GitHub[^3]
- We introduce a pipeline to create dataset for pairing PDFs to source
code
- Our method is only dependent on the image of a page, allowing access
to scanned papers and books
# Related Work
Optical Character Recognition (OCR) is an extensively researched field
in computer vision for a variety applications, such as document
digitalization
[moysset_full-page_2017](http://arxiv.org/abs/1704.08628), [smith_overview_2007](https://doi.org/10.1109/ICDAR.2007.4376991),
handwriting recognition and scene text recognition
[bautista_scene_2022](http://arxiv.org/abs/2207.06966), [li_trocr_2022](https://doi.org/10.48550/arXiv.2109.10282), [diaz_rethinking_2021](http://arxiv.org/abs/2104.07787).
More concretely, recognizing mathematical expressions is a heavily
researched subtopic. Grammar based methods
[maclean_new_2013](https://doi.org/10.1007/s10032-012-0184-x), [awal_global_2014](http://arxiv.org/pdf/1707.03088v2), [alvaro_recognition_2014](https://doi.org/10.1016/j.patrec.2012.09.023)
for handwritten mathematical expressions were improved upon by different
encoder-decoder models. The fully convolutional model
[yan_convmath_2020](http://arxiv.org/abs/2012.12619) was succeeded by various RNN decoder
models
[deng_image--markup_2016](https://doi.org/10.48550/arXiv.1609.04938), [le_training_2017](https://doi.org/10.1109/ICDAR.2017.175), [singh_teaching_2018](http://arxiv.org/abs/1802.05415), [zhang_multi-scale_2018](https://doi.org/10.48550/arXiv.1801.03530), [wang_translating_2019](https://doi.org/10.48550/arXiv.1908.11415),
both for handwritten and printed formulas. Recently, the decoder
[zhao_handwritten_2021](http://arxiv.org/abs/2105.02412), [mahdavi_icdar_2019](https://doi.org/10.1109/ICDAR.2019.00247) as well as the
encoder [blecher_pix2tex_2023](https://github.com/lukas-blecher/LaTeX-OCR) were replaced with the
Transformer [vaswani_attention_2017](https://doi.org/10.48550/arXiv.1706.03762) architecture.
Visual Document Understanding (VDU) is another related topic of deep
learning research and focuses on extracting relevant information of a
variety of document types. Previous works depend on pre-trained models
that learn to extract information by jointly modeling text and layout
information using the Transformer architecture. The LayoutLM model
family
[xu_layoutlm_2020](https://doi.org/10.1145/3394486.3403172), [xu_layoutlmv2_2022](http://arxiv.org/abs/2012.14740), [huang_layoutlmv3_2022](http://arxiv.org/abs/2204.08387)
uses masked layout prediction task to capture the spatial relationships
between different document elements.
Open source solutions with a related goal as ours include GROBID
[lopez_grobid_2023](https://github.com/kermitt2/grobid), which parses digital-born scientific
documents to XML with a focus on the bibliographic data and `pdf2htmlEX`
[lu_wang_online_2013](https://www.tug.org/TUGboat/tb34-3/tb108wang.pdf), that converts digital-born PDFs to
HTML while preserving the layout and appearance of the document.
However, both solutions can not recover the semantic information of
mathematical expressions.
# Model
Previous VDU methods either rely on OCR text from a third party tool
[xu_layoutlm_2020](https://doi.org/10.1145/3394486.3403172), [xu_layoutlmv2_2022](http://arxiv.org/abs/2012.14740), [appalaraju_docformer_2021](https://doi.org/10.48550/arXiv.2106.11539)
or focus on document types such as receipts, invoices or form-like
documents [majumder_representation_2020](https://doi.org/10.18653/v1/2020.acl-main.580). Recent studies
[kim_ocr-free_2022](https://doi.org/10.48550/arXiv.2111.15664), [davis_end--end_2022](http://arxiv.org/abs/2203.16618) show that an
external OCR engine is not necessarily needed to achieve competitive
results in VDU.
The architecture is a encoder-decoder transformer
[vaswani_attention_2017](https://doi.org/10.48550/arXiv.1706.03762) architecture, that allows for an
end-to-end training procedure. We build on the Donut
[kim_ocr-free_2022](https://doi.org/10.48550/arXiv.2111.15664) architecture. The model does not
require any OCR related inputs or modules. The text is recognized
implicitly by the network. See Fig.
1 for an overview of the approach.
**Encoder** The visual encoder receives a document image
$\mathbf x\in \mathbb R^{3\times H_0\times W_0}$, crops the margins and
resizes the image to fit in a fixed rectangle of size $(H,\,W)$. If the
image is smaller than the rectangle, additional padding is added to
ensure each image has the same dimensionality. We use a Swin Transformer
[liu_swin_2021](https://doi.org/10.48550/arXiv.2103.14030), a hierarchical vision transformer
[dosovitskiy_image_2021](https://doi.org/10.48550/arXiv.2010.11929) that splits the image into
non-overlapping windows of fixed size and applies a series of
self-attention layers to aggregate information across these windows. The
model output a sequence of the embedded patches
$\mathbf z\in \mathbb R^{d\times N}$ where $d$ is the latent dimension
and $N$ is the number of patches.
**Decoder** The encoded image $\mathbf z$ is decoded into a sequence of
tokens using a transformer decoder architecture with cross-attention.
The tokens are generated in an auto-regressive manner, using
self-attention and cross-attention to attend to different parts of the
input sequence and encoder output respectively. Finally, the output is
projected to the size of the vocabulary $v$, yielding the logits
$\boldsymbol\ell \in \mathbb R^v$.
Following Kim et al. [kim_ocr-free_2022](https://doi.org/10.48550/arXiv.2111.15664), we use the
implementation of the mBART [lewis_bart_2019](https://doi.org/10.48550/arXiv.1910.13461) decoder. We
use the same tokenizer as Taylor et al.
[taylor_galactica_2022](https://doi.org/10.48550/arXiv.2211.09085) because their model is also
specialized in the scientific text domain.
## Setup
We render the document images at a resolution of 96 DPI. Due to the
restrictive possible input dimensions of the Swin Transformer we choose
the input size $(H,\,W) = (896,\,672)$. The aspect ratio is in between
the US letter and Din A4 format $\frac{22}{17}<\frac43<\sqrt 2$. The
document images are resized and then padded to achieve the desired input
size. This input size allows us to use the Swin base model architecture
[liu_swin_2021](https://doi.org/10.48550/arXiv.2103.14030). We initialize the model with the
pre-trained weights.
The Transformer decoder has a maximal sequence length of $S=4096$. This
relatively large sizing is due to the fact that the text of academic
research papers can be dense and the syntax for tables in particular is
token intensive. The BART decoder is a decoder-only transformer with 10
layers. The entire architecture has a total of 350M parameters.
We also test experiment with a smaller model (250M parameters) with a
slightly smaller sequence length of $S=3584$ and only 4 decoder layers,
where we start from the pre-trained base model.
During inference the text is generated using greedy decoding.
**Training** We use an AdamW optimizer
[loshchilov_decoupled_2019](http://arxiv.org/abs/1711.05101) to train for 3 epochs with an
effective batch size of 192. Due to training instabilities, we choose a
learning rate of $\mathrm{lr}_{\rm init}=5\cdot10^{-5}$ which is reduced
by a factor of $0.9996$ every 15 updates until it reaches
$\mathrm{lr}_{\rm end}=7.5\cdot10^{-6}$.
## Data Augmentation
In image recognition tasks, it is often beneficial to use data
augmentation to improve generalization. Since we are only using
digital-born academic research papers, we need to employ a number of
transformations to simulate the imperfections and variability of scanned
documents. These transformations include erosion, dilation, gaussian
noise, gaussian blur, bitmap conversion, image compression, grid
distortion and elastic transform [simard_best_2003](https://doi.org/10.1109/ICDAR.2003.1227801). Each
has a fixed probability of being applied to a given image. The
transformations are implemented in the *Albumentations*
[buslaev_albumentations_2020](https://doi.org/10.3390/info11020125) library. For an overview of
the effect of each transformation, see Fig.
2.
During training time, we also add perturbations to the ground truth text
by randomly replacing tokens. We found this to reduce the collapse into
a repeating loop significantly. For more details, see Section
5.4.
# Datasets
To the best of our knowledge there is no paired dataset of PDF pages and
corresponding source code out there, so we created our own from the open
access articles on arXiv.[^4] For layout diversity we also include a
subset of the *PubMed Central* [^5] (PMC) open access non-commercial
dataset. During the pretraining, a portion of the *Industry Documents
Library* [^6] (IDL) is included. See Table
2 for the dataset
composition.
**arXiv** We collected the source code and compiled PDFs from 1,748,201
articles released on arXiv. To ensure consistent formatting, we first
process the source files using *LaTeXML*[^7] and convert them into HTML5
files. This step was important as it standardized and removed ambiguity
from the LaTeX source code, especially in mathematical expressions. The
conversion process included replacing user-defined macros, standardizing
whitespace, adding optional brackets, normalizing tables, and replacing
references and citations with their correct numbers.
We then parse the HTML files and convert them into a lightweight markup
language that supports various elements such as headings, bold and
italic text, algorithms, LaTeX inline and display math and LaTeX tables.
This way, we ensure that the source code is properly formatted and ready
for further processing.
The process is visualized in Fig.
3.
**PMC** We also processed articles from PMC, where XML files with
semantic information are available in addition to the PDF file. We parse
these files into the same markup language format as the arXiv articles.
We chose to use far fewer articles from PMC because the XML files are
not always as rich in semantic information. Often times equations and
tables are stored as images and these cases are not trivial to detect,
which leads to our decision to limit the use of PMC articles to the
pre-training phase.
The XML files are parsed into the same markup language as described
above.
**IDL** The IDL is a collection of documents produced by industries that
have an impact on public health and is maintained by the University of
California, San Francisco Library. Biten et al.
[biten_ocr-idl_2022](https://doi.org/10.48550/arXiv.2202.12985) provide high quality OCR text for
PDFs from the IDL dataset. This does not include text formatting and is
only used for pre-training to teach the model basic OCR of scanned
documents.
## Splitting the pages
We split the markdown files according to the page breaks in the PDF file
and rasterize each page as an image to create the final paired dataset.
During the compilation, the LaTeX compiler determines the page breaks of
the PDF file automatically. Since we are not recompiling the LaTeX
sources for each paper, we must heuristically split the source file into
parts, which correspond to different pages. To achieve that we are using
the embedded text on the PDF page and match it to source text.
However, figures and tables in the PDF may not correspond to their
position in the source code. To address this issue, we remove these
elements in a pre-processing step using `pdffigures2`
[clark_pdffigures_2016](https://doi.org/10.1145/2910896.2910904). The recognized captions are are
then compared to the captions in the XML file and matched based on their
Levenshtein distance [levenshtein_binary_1965](https://www.semanticscholar.org/paper/Binary-codes-capable-of-correcting-deletions%2C-and-Levenshtein/b2f8876482c97e804bb50a5e2433881ae31d0cdd). Once the
source document has been split into individual pages, the removed
figures and tables are reinserted at the end of each page.
For a better matching we also replaced unicode characters in the PDF
text with corresponding LaTeX commands using the pylatexenc-library[^8].
**Bag of Words matching** First we extract the text lines from the PDF
using MuPDF[^9] and preprocess them to remove page numbers and potential
headers/footers. We then use a *Bag of Words* model
[harris_distributional_1954](https://doi.org/10.1080/00437956.1954.11659520) with TF-IDF vectorizer and a
linear Support Vector Machine classifier. The model is fitted to the PDF
lines with the page number as label. Next we split the LaTeX source into
paragraphs and predict the page number for each of them.
Ideally, the predictions will form a stair case function but in practice
the signal will be noisy. To find the best boundary points we employ a
similar logic as decision trees and minimize a measure based on the
*Gini* impurity
$$G_{[a,\:\!b]}(i) = (b-a) \cdot \left( 1 - p_{[a,\:\!b]}^2(i)- p_{[a,\:\!b]}^2(i+1)\right),
\label{eq:gini}$$ where $p_{[a,\:\!b]}(i)$ is the probability of
choosing an element with the predicted page number $i$ in the interval
$[a,\, b]$ that describes which paragraphs (elements) were considered
for the split.
The best splitting position $t$ in the interval $[a,\, b]$ is then
$${\hat t}_i = \mathop{\mathrm{\arg\,\min}}_t \left(G_{[a,\:\!t]}(i)+G_{[t,\:\!b]}(i) \right).
\label{eq:splitting_position}$$ The search process starts with all
paragraphs and for each subsequent page break, the lower bound of the
search interval is set to the previous split position. See Fig.
4 for a visualization of an example
page.
**Fuzzy matching** After this first coarse document splitting we try to
find the exact position within the paragraph. This is done by comparing
the source text within the neighborhood of the predicted splitting
position to the last sentences of the previous page of the embedded PDF
text, and the first sentences of the next page using the `fuzzysearch`
library[^10]. If the two dividing points are at the same location in the
source text, the page break is considered “accurate” and receives a
score of 1. On the other hand, if the splitting positions differ, the
one with the smallest normalized Levenshtein distance is selected and
given a score of 1 minus the distance. To be included in the dataset, a
PDF page must have an average score of at least 0.9 for both page
breaks. This results in an acceptance rate of about $47\%$ of all pages.
## Ground truth artifacts [seq:artifacts]
Because the dataset was pre-processed by LaTeXML, the markup version of
the source code can contain artifacts and commands from unsupported
packages. The HTML file may contain subsection titles with numbering
even though they are not numbered in the PDF. There may also be
instances where figures or tables are missing from the ground truth due
to processing errors.
In addition, the splitting algorithm of the source code will in some
cases include text from the previous page or cut off words from the end.
This is especially true for “invisible” characters used for formatting,
like italic, bold text or section header.
For PMC papers the inline math is written as Unicode or italic text,
while display math equations or tables are often included in image
format and will therefore be ignored.
Each of these issues reduces the overall data quality. However, the
large number of training samples compensates for these small errors.
# Results & Evaluation
Example of a page with many mathematical equations taken
from .
Left: Image of a page in the document, Right: Model output converted to
LaTeX and rendered to back into a PDF. Examples of scanned documents can
be found in the appendix 9.
In this section we discuss the results and performance of the model. For
an example see Fig.
5 or go to Sec.
9. The model focuses only on the
important content relevant features of the page. The box around the
equations is skipped.
## Metrics
We report the following metrics on our test set.
**Edit distance** The edit distance, or Levenshtein distance
[levenshtein_binary_1965](https://www.semanticscholar.org/paper/Binary-codes-capable-of-correcting-deletions%2C-and-Levenshtein/b2f8876482c97e804bb50a5e2433881ae31d0cdd), measures the number of
character manipulations (insertions, deletions, substitutions) it takes
to get from one string to another. In this work we consider the
normalized edit distance, where we divide by the total number of
characters.
**BLEU** The BLEU [papineni_bleu_2002](https://doi.org/10.3115/1073083.1073135) metric was
originally introduced for measuring the quality of text that has been
machine-translated from one language to another. The metric computes a
score based on the number of matching n-grams between the candidate and
reference sentence.
**METEOR** Another machine-translating metric with a focus on recall
instead of precision, introduced in
[banerjee_meteor_2005](https://aclanthology.org/W05-0909).
**F-measure** We also compute the F1-score and report the precision and
recall.
## Text modalities
In a scientific research article, there are three distinct types of
text: 1) plain text, which comprises the majority of the document, 2)
mathematical expressions, and 3) tables. It is important to separately
examine each of these components during the evaluation process. This is
necessary because in LaTeX, there are multiple ways to express the same
mathematical expression. While some variability has been eliminated
during the LaTeXML pre-processing step, there still is a significant
amount of ambiguity present, like ordering of subscript and superscript,
equivalent commands with different notation (`stackrel`, `atop`,
`substack` or `frac`, `over`), situationally interchangeable commands
(`bm`, `mathbf`, `boldsymbol`, `bf` or `\left(`, `\big(`, etc.),
whitespace commands, additional layers of brackets, and more. As a
consequence, there can be a discrepancy between prediction and ground
truth, even if the rendered formulas appear identical.
In addition, it is not always possible to determine, where a inline math
environment ends and text begins, when writing numbers and punctuation
(Example: `$\mathrm{H}_{0}$1,` vs. `H$_{0}1,$` $\to$
$\mathrm{H}_{0}$``{=html}1, vs. H$_{0}1,$). This ambiguity
reduces both math and plain text scores.
The expected score for mathematical expressions is lower than for plain
text.
## Comparison
We present our results in Table
1. As expected, the
mathematical expressions have the worst agreement with the ground truth.
For the plain text, most discrepancies come from formatting ambiguities
and missing text due to inline math, as described above. The output
format of GROBID is an XML file, which we convert into a compatible
markup language, similar to the PMC or arXiv files. To some extent,
GROBID provides support for formulas in its output, but it identifies
and stores them as the Unicode representations embedded in the PDF. We
replace each Unicode symbol with its corresponding LaTeX command to
increase the similarity. Additionally, GROBID mislabels small inline
expressions as text. For identified formulas, GROBID stores the bounding
box coordinates. We modify the program by sending the snippet to the
external formula recognition software LaTeX-OCR
[blecher_pix2tex_2023](https://github.com/lukas-blecher/LaTeX-OCR). This way we can also get a signal
for math modality. The reported results in this section are quite poor,
primarily due to the amount of missed formulas by GROBID and the
equation prediction accuracy is affected by the quality of the bounding
boxes. The performance of the embedded PDF text alone is better than
GROBID, which is due to formatting differences for the title page or
reference section.
Both Nougat small and base are able to outperform the other approach and
achieve high scores in all metrics. We note that the performance of the
smaller model is on par with the larger base model.
| Method | Modality | Edit distance $\downarrow$ | BLEU $\uparrow$ | METEOR $\uparrow$ | Precision $\uparrow$ | Recall $\uparrow$ | F1 $\uparrow$ |
|:---|:---|:--:|:--:|:--:|:--:|:--:|:--:|
| PDF | All | 0.255 | 65.8 | 82.1 | 77.1 | 81.4 | 79.2 |
| GROBID | All | 0.312 | 55.6 | 71.9 | 74.0 | 72.1 | 73.0 |
| 2-8 | Tables | 0.626 | 25.1 | 64.5 | 61.4 | 80.7 | 69.7 |
| \+ LaTeX OCR | Plain text | 0.363 | 57.4 | 69.2 | 82.1 | 70.5 | 75.9 |
| | Math | 0.727 | 0.3 | 5.0 | 11.0 | 8.6 | 9.7 |
| Nougat small (250M$^\ast$) | All | 0.073 | 88.9 | 92.8 | **93.6** | 92.2 | 92.9 |
| | Tables | 0.220 | 68.5 | 78.6 | 75.0 | 79.8 | 77.3 |
| | Plain text | 0.058 | 91.0 | 94.3 | 96.1 | 95.3 | 95.7 |
| | Math | 0.117 | 56.0 | 74.7 | 77.1 | 76.8 | 76.9 |
| Nougat base (350M$^\ast$) | All | **0.071** | **89.1** | **93.0** | 93.5 | **92.8** | **93.1** |
| | Tables | 0.211 | 69.7 | 79.1 | 75.4 | 80.7 | 78.0 |
| | Plain text | 0.058 | 91.2 | 94.6 | 96.2 | 95.3 | 95.7 |
| | Math | 0.128 | 56.9 | 75.4 | 76.5 | 76.6 | 76.5 |
Results on arXiv test set. PDF is the text embedded in the PDF file. The
modality “All" refers to the output text without any splitting.
$^\ast$Number of parameters.
## Repetitions during inference [seq:repeptition]
Examples for repetition detection on logits. Top: Sample
with repetition, Bottom: Sample without repetition. Left: Highest logit
score for each token in the sequence ℓ(x), Center: Sliding window
variance of the logits VarWinB[ℓ](x),
Right: Variance of variance from the position to the end VarEndB[ℓ](x)
We notice that the model degenerates into repeating the same sentence
over and over again. The model can not recover from this state by
itself. In its simplest form, the last sentence or paragraph is repeated
over and over again. We observed this behavior in $1.5\%$ of pages in
the test set, but the frequency increases for out-of-domain documents.
Getting stuck in a repetitive loop is a known problem with
Transformer-based models, when sampled with greedy decoding
[holtzman_curious_2020](http://arxiv.org/abs/1904.09751).
It can also happen that the model alternates between two sentences but
sometimes changes some words, so a strict repetition detection will not
suffice. Even harder to detect are predictions where the model counts
its own repetitions, which sometimes happens in the references
section.
In general we notice this kind behavior after a mistake by the model.
The model is not able to recover from the collapse.
**Anti-repetition augmentation** Because of that we introduce a random
perturbation during training. This helps the model to learn how to
handle a wrongly predicted token. For each training example, there is a
fixed probability that a random token will be replaced by any other
randomly chosen token. This process continues until the newly sampled
number is greater than a specified threshold (in this case, 10%). We did
not observe a decrease in performance with this approach, but we did
notice a significant reduction in repetitions. Particularly for
out-of-domain documents, where we saw a 32% decline in failed page
conversions.
**Repetition detection** Since we are generating a maximum of $4096$
tokens the model will stop at some point, however it is very inefficient
and resource intensive to wait for a “end of sentence” token, when none
will come. To detect the repetition during inference time we look at the
largest logit value $\ell_i=\max \boldsymbol{ \ell}_i$ of the ith token.
We found that the logits after a collapse can be separated using the
following heuristic. First calculate the variance of the logits for a
sliding window of size $B=15$
$$\operatorname{VarWin}_B[ \boldsymbol\ell](x)=\frac1B\sum_{i=x}^{x+B}\left(\ell_i-\frac1B\sum_{j=x}^{x+B}\ell_j\right)^2.\nonumber
\label{eq:varwin}$$ Here $\ell$ is the signal of logits and $x$ the
index. Using this new signal we compute variances again but this time
from the point $x$ to the end of the sequence
$$\operatorname{VarEnd}_B[ \boldsymbol\ell](x)=\frac{1}{S-x}\sum_{i=x}^{S}\left(\operatorname{VarWin}_B[ \boldsymbol\ell](i)-\frac{1}{S-x}\sum_{j=x}^{S}\operatorname{VarWin}_B[ \boldsymbol\ell](i) \right)^2.\nonumber
\label{eq:varend}$$ If this signal drops below a certain threshold
(we choose 6.75) and stays below for the remainder of the sequence, we
classify the sequence to have repetitions.
During inference time, it is obviously not possible to compute the to
the end of the sequence if our goal is to stop generation at an earlier
point in time. So here we work with a subset of the last 200 tokens and
a half the threshold. After the generation is finished, the procedure as
described above is repeated for the full sequence.
## Limitations & Future work
**Utility** The utility of the model is limited by a number of factors.
First, the problem with repetitions outlined in section
5.4. The model is trained on
research papers, which means it works particularly well on documents
with a similar structure. However, it can still accurately convert other
types of documents.
Nearly every dataset sample is in English. Initial tests on a small
sample suggest that the model’s performance with other Latin-based
languages is satisfactory, although any special characters from these
languages will be replaced with the closest equivalent from the Latin
alphabet. Non-Latin script languages result in instant repetitions.
**Generation Speed** On a machine with a NVIDIA A10G graphics card with
24GB VRAM we can process 6 pages in parallel. The generation speed
depends heavily on the amount of text on any given page. With an average
number of tokens of $\approx 1400$ we get an mean generation time of
19.5s per batch for the base model without any inference optimization.
Compared to classical approaches (GROBID 10.6 PDF/s
[lopez_grobid_2023](https://github.com/kermitt2/grobid)) this is very slow, but it is not
limited to digital-born PDFs and can correctly parse mathematical
expressions.
**Future work** The model is trained on one page at a time without
knowledge about other pages in the document. This results in
inconsistencies across the document. Most notably in the bibliography
where the model was trained on different styles or section titles where
sometimes numbers are skipped or hallucinated. Though handling each page
separately significantly improves parallelization and scalability, it
may diminish the quality of the merged document text.
The primary challenge to solve is the tendency for the model to collapse
into a repeating loop, which is left for future work.
# Conclusion
In this work, we present Nougat, an end-to-end trainable encoder-decoder
transformer based model for converting document pages to markup. We
apply recent advances in visual document understanding to a novel OCR
task. Distinct from related approaches, our method does not rely on OCR
or embedded text representations, instead relying solely on the
rasterized document page. Moreover, we have illustrated an automatic and
unsupervised dataset generation process that we used to successfully
train the model for scientific document to markup conversion. Overall,
our approach has shown great potential for not only extracting text from
digital-born PDFs but also for converting scanned papers and textbooks.
We hope this work can be a starting point for future research in related
domains.
All the code for model evaluation, training and dataset generation can
be accessed at .
# Acknowledgments
Thanks to Ross Taylor, Marcin Kardas, Iliyan Zarov, Kevin Stone, Jian
Xiang Kuan, Andrew Poulton and Hugo Touvron for their valuable
discussions and feedback.
Thanks to Faisal Azhar for the support throughout the project.
# Dataset
| Name | Number of Pages |
|:----------|----------------:|
| arXiv | 7,511,745 |
| PMC | 536,319 |
| IDL | 446,777 |
| **Total** | **8,204,754** |
Dataset composition
The most important data source is arXiv, making up $>91.5\%$ of the
corpus. On arXiv most research documents are paired with the LaTeX
source code provided by the authors. The LaTeX source offers more
information and is left unprocessed, unlike the XML format from PMC
where equations and tables are frequently substituted with images. This
allows us to select exactly which information we need to build the
dataset.
# Examples [seq:examples]
In this section we converted some pages from old text books using the
Nougat base model. The text books from the *Internet Archive*[^11] and
*Project Gutenberg*[^12] and are in public domain.
The performance for these scanned pages is noticeable worse than for
digital-born documents. However, the model does generate sensible text
for each page with few errors. For example see the first row of Fig.
9. Here the model mistakes the
almost illegible exponent $n$ for $\ast$. In the second row of the same
figure the model falls into a repetitive loop after predicting another
comma instead of a dot. Similar problems can be seen in Fig.
10.
In Fig. 11 we present pages, scanned
with a mobile device, from a printed master thesis and the Nougat
output. The model is robust to the artifacts that arise when
hand-scanning a document.
Explore the examples in this section on the project page:
.
Example of an old calculus text book . A selection of pages from a NASA conference from 1970 .Scan of a modern thesis with a mobile device camera, with
permission from the author. Pages with tables. Upper: Fan et al. page 6, Lower: Shah et al.
page 6
[^1]: Correspondence to:
[^2]: The paper reports 8.1M papers but the authors recently updated the
numbers on the GitHub page
[^3]:
[^4]:
[^5]:
[^6]:
[^7]:
[^8]:
[^9]:
[^10]:
[^11]:
[^12]:
DocParser: End-to-end OCR-free Information Extraction from Visually Rich Documents
2023-04-24
Mohamed Dhouib, Ghassen Bettaieb, Aymen Shabou
Information Extraction from visually rich documents is a challenging task that has gained a lot of attention in recent years due to its importance in several document-control based applications and its widespread commercial value. The majority of the research work conducted on this topic to date follow a two-step pipeline. First, they read the text using an off-the-shelf Optical Character Recognition (OCR) engine, then, they extract the fields of interest from the obtained text. The main drawback of these approaches is their dependence on an external OCR system, which can negatively impact both performance and computational speed. Recent OCR-free methods were proposed to address the previous issues. Inspired by their promising results, we propose in this paper an OCR-free end-to-end information extraction model named DocParser. It differs from prior end-to-end approaches by its ability to better extract discriminative character features. DocParser achieves state-of-the-art results on various datasets, while still being faster than previous works.
Show Paper Content
# Introduction
Information extraction from visually rich documents (VRDs) is an
important research topic that continues to be an active area of research
[chargrid](None), [visualwordgrid](http://arxiv.org/pdf/2010.02358v5), [Cutie](http://arxiv.org/pdf/1903.12363v4), [cloudscan](http://arxiv.org/pdf/1708.07403v1), [layoutlm](http://arxiv.org/pdf/2204.08387v3), [docreader](http://arxiv.org/pdf/2307.02499v1), [trie++](http://arxiv.org/pdf/1903.11279v1), [Layout-aware](http://arxiv.org/pdf/2005.11017v1), [Graph_based-1](http://arxiv.org/pdf/1903.11279v1)
due to its importance in various real-world applications.
The majority of the existing information extraction from visually rich
documents approaches [layoutlm](http://arxiv.org/pdf/2204.08387v3), [Lambert](None), [TILIT](http://arxiv.org/pdf/2102.09550v3), [Bros](http://arxiv.org/pdf/2108.04539v5) depend
on an external deep-learning-based Optical Character Recognition (OCR)
[text_detection](http://arxiv.org/pdf/1904.01941v1), [text_recognition](http://arxiv.org/pdf/1904.01906v4) engine. They follow a
two-step pipeline: First they read the text using an off-the-shelf OCR
system then they extract the fields of interest from the OCR’ed text.
These two-step approaches have significant limitations due to their
dependence on an external OCR engine. First of all, these approaches
need positional annotations along with textual annotations for training.
Also, training an OCR model requires large scale datasets and huge
computational resources. Using an external pre-trained OCR model is an
option, which can degrade the whole model performance in the case of a
domain shift. One way to tackle this is to fine-tune these off-the-shelf
OCR models which is still a delicate task. In fact, the documents full
annotations are generally needed to correctly fine-tune off-the-shelf
OCR models, which is time-consuming and difficult to obtain. OCR
post-correction
[OCR_Post_Correction](None), [OCR_Post_Correction_2](http://arxiv.org/pdf/2309.11549v1) is an option
to correct some of the recognition errors. However, this brings extra
computational and maintenance cost. Moreover, these two-step approaches
rarely fully exploit the visual information because incorporating the
textual information is already computationally expensive.
Recent end-to-end OCR-free information extraction approaches
[eaten](http://arxiv.org/pdf/2403.00724v1), [trie++](http://arxiv.org/pdf/1903.11279v1), [donut](http://arxiv.org/pdf/2305.09520v1) were proposed to tackle some of the
limitations of OCR-dependant approaches. The majority of these
approaches follow an encoder-decoder scheme. However, the used encoders
are either unable to effectively model global dependence when they are
primarily composed of Convolutional neural network (CNN) blocks
[docreader](http://arxiv.org/pdf/2307.02499v1), [eaten](http://arxiv.org/pdf/2403.00724v1) or they don’t give enough privilege to
character-level features extraction when they are are primarily composed
of Swin Transformer [Swin](http://arxiv.org/pdf/2306.13776v1) blocks
[donut](http://arxiv.org/pdf/2305.09520v1), [Dessurt](http://arxiv.org/pdf/2203.16618v3). In this paper, we argue that capturing
both intra-character local patterns and inter-character long-range
connections is essential for the information extraction task. The former
is essential for character recognition and the latter plays a role in
both the recognition and the localization of the fields of interest.
Motivated by the issues mentioned above, we propose an end-to-end
OCR-free information extraction model named DocParser. DocParser has
been designed in a way that allows it to efficiently perceive both
intra-character patterns and inter-character dependencies. Consequently,
DocParser is up to two times faster than state-of-the-art methods while
still achieving state-of-the-art results on various datasets.
# Related Work
## OCR-dependant Approaches
Most of the OCR-dependant approaches simply use an off-the-shelf OCR
engine and only focus on the information extraction task.
Prior to the development of deep learning techniques, earlier approaches
[earlier_approaches_0](http://arxiv.org/pdf/2402.14871v1), [earlier_approaches_1](http://arxiv.org/pdf/2005.01646v1), [earlier_approaches_2](http://arxiv.org/pdf/2311.11856v1)
either followed a probabilistic approach, relied on rules or used
manually designed features which often results in failure when applied
to unfamiliar templates. The initial deep learning approaches only
relied on textual information and simply used pre-trained language
models [Bert](None), [RoBERTa](http://arxiv.org/pdf/1907.11692v1). Later, several approaches tried to
take the layout information into consideration. First,
[chargrid](None) proposed Chargrid, a new type of text
representation that preserves the 2D layout of a document by encoding
each document page as a two-dimensional grid of characters. Then,
[Bert_grid](http://arxiv.org/pdf/1909.04948v2) added context to this representation by using
a BERT language model. Later, [visualwordgrid](http://arxiv.org/pdf/2010.02358v5) improved
the Chargrid model by also exploiting the visual information.
Graph-based models were also proposed to exploit both textual and visual
information [Graph_based-1](http://arxiv.org/pdf/1903.11279v1), [Graph_based-2](http://arxiv.org/pdf/2103.14470v1).
To successfully model the interaction between the visual, textual and
positional information, recent approaches
[layoutlm](http://arxiv.org/pdf/2204.08387v3), [Lambert](None), [TILIT](http://arxiv.org/pdf/2102.09550v3), [Bros](http://arxiv.org/pdf/2108.04539v5) resorted to pre-training
large models. First [layoutlmv0](None) tried to bring the
success of large pre-trained language models into the multi-modal domain
of document understanding and proposed LayoutLM. LayoutLMv2
[layoutlmv1](None) was later released where new pre-training
tasks were introduced to better capture the cross-modality interaction
in the pre-training stage. The architecture was also improved by
introducing spatially biased attention and thus making the spatial
information more influential. Inspired by the Vision Transformer (ViT)
[VIT](http://arxiv.org/pdf/2105.15075v2), [layoutlm](http://arxiv.org/pdf/2204.08387v3) modified LayoutLMv2 by
using patch embeddings instead of a ResNeXt [Resnext](http://arxiv.org/pdf/2007.06257v2)
Feature Pyramid Network [FPN](http://arxiv.org/pdf/2108.00580v3) visual backbone and
released LayoutLMv3. Pre-training tasks were also improved compared to
previous versions. [Lambert](None) proposed LAMBERT which used
a modified RoBERTa [RoBERTa](http://arxiv.org/pdf/1907.11692v1) that also exploits the
layout features obtained from an OCR system. [TILIT](http://arxiv.org/pdf/2102.09550v3)
proposed TILT, a pre-trained encoder-decoder model.
[Bros](http://arxiv.org/pdf/2108.04539v5) tried to fully exploit the textual and layout
information and released Bros which achieves good results without
relying on the visual features. However, the efficiency and the
computational cost of all the previously cited works are still hugely
impacted by the used OCR system.
## End-to-end Approaches
In recent years, end-to-end approaches were proposed for the information
extraction task among many other Visually-Rich Document Understanding
(VRDU) tasks. [eaten](http://arxiv.org/pdf/2403.00724v1), [docreader](http://arxiv.org/pdf/2307.02499v1) both used a CNN-based
encoder and a recurrent neuronal network coupled with an attention
mechanism decoder. However, the accuracy of these two approaches is
limited and they perform relatively badly on small datasets.
[trie++](http://arxiv.org/pdf/1903.11279v1) proposed TRIE++, a model that learns
simultaneously both the text reading and the information extraction
tasks via a multi-modal context block that bridges the visual and
natural language processing tasks. [VIES](http://arxiv.org/pdf/2102.06732v1) released VIES
which simultaneously performs text detection, recognition and
information extraction. However, both TRIE++ and VIES require the full
document annotation to be trained. [donut](http://arxiv.org/pdf/2305.09520v1) proposed
Donut, an encoder-decoder architecture that consists of a Swin
Transformer [Swin](http://arxiv.org/pdf/2306.13776v1) encoder and a Bart
[Bart](None)-like decoder. [Dessurt](http://arxiv.org/pdf/2203.16618v3) released
Dessurt, a model that processes three streams of tokens, representing
visual tokens, query tokens and the response. Cross-attention is applied
across different streams to allow them to share and transfer information
into the response. To process the visual tokens, Dessurt uses a modified
Swin windowed attention that is allowed to attend to the query tokens.
Donut and Dessurt achieved promising results, however, they don’t give
enough privilege to local character patterns which leads to sub-optimal
results for the information extraction task.
# Proposed Method
This section introduces DocParser, our proposed end-to-end information
extraction from VRDs model.
Given a document image and a task token that determines the fields of
interest, DocParser produces a series of tokens representing the
extracted fields from the input image. DocParser architecture consists
of a visual encoder followed by a textual decoder. An overview of
DocParser’s architecture is shown on figure
[fig:docparser_overview].
The encoder consists of a three-stage progressively decreased height
convolutional neural network that aims to extract intra-character local
patterns, followed by a three-stage progressively decreased width Swin
Transformer [Swin](http://arxiv.org/pdf/2306.13776v1) that aims to capture long-range
dependencies. The decoder consists of $n$ Transformer layers. Each layer
is principally composed of a multi-head self-attention sub-layer
followed by a multi-head cross-attention sub-layer and a feed-forward
sub-layer as explained in [attention](http://arxiv.org/pdf/2107.08000v1).
## Encoder
The encoder is composed of six stages. The input of the encoder is an
image of size $H \times W \times 3$. It is first transformed to
$\frac{H}{4} \times \frac{W}{4}$ patches of dimension $C_0$ via an
initial patch embedding. Each patch either represents a fraction of a
text character or a fraction of a non-text component of the input image.
First, three stages composed of ConvNext [ConvNext](http://arxiv.org/pdf/2007.00649v1)
blocks are applied at different scales for character-level
discriminative features extraction. Then three stages of Swin
Transformer blocks are applied with varying window sizes in order to
capture long-range dependencies. The output of the encoder is a feature
map of size $\frac{H}{32} \times \frac{W}{32} \times C_5$ that contains
multi-grained features. An overview of the encoder architecture is
illustrated in figure
[fig:encoder_architecture].
### Patch Embedding
Similar to [SVTR](http://arxiv.org/pdf/2401.09802v1), we use a progressive overlapping patch
embedding. For an input image of size $W \times H \times 3$, a
$3 \times 3$ convolution with stride $2$ is first applied to have an
output of size $\frac{W}{2} \times \frac{H}{2} \times \frac{C_0}{2}$. It
is then followed by a normalization layer and another $3 \times 3$
convolution with stride $2$. The size of the final output is
$\frac{W}{4} \times \frac{H}{4} \times C_0$.
### ConvNext-based Stages
The first three stages of DocParser’s encoder are composed of ConvNext
blocks. Each stage is composed of several blocks. The kernel size is set
to $7$ for all stages. At the end of each stage, the height of the
feature map is reduced by a factor of two and the number of channels
$C_i,$ $i \in [1,2,3]$ is increased to compensate for the information
loss. The feature map width is also reduced by a factor of two at the
end of the third stage. The role of these blocks is to capture the
correlation between the different parts of each single character and to
encode the non-textual parts of the image. We don’t reduce the width of
the feature map between these blocks in order to avoid encoding
components of different characters in the same feature vector and thus
allowing discriminative character features computation. We note that
contrary to the first encoder stages where low-level features extraction
occurs, encoding components of different characters in the same feature
vector doesn’t affect performance if done in the encoder last stages
where high-level features are constructed. This is empirically
demonstrated in section [abla]. We chose to use convolutional blocks
for the early stages mainly due to their good ability at modeling local
correlation at a low computational cost.
### Swin Transformer-based Stages
The last three stages of the encoder are composed of Swin Transformer
blocks. We modify Swin’s window-based multi-head self-attention to be
able to use rectangular attention windows. At the output of the fourth
and fifth stages, the width of the feature map is reduced by a factor of
two and the number of channels is increased to compensate for the
information loss. The role of these layers is to capture the correlation
between the different characters of the input image or between textual
and non-textual components of the image. In the forth and fifth stage,
the encoder focuses on capturing the correlation between characters that
belong to adjacent sentences. This is accomplished through the use of
horizontally wide windows, as text in documents typically has an
horizontal orientation. In the last stage, the encoder focuses on
capturing long-range context in both directions. This is achieved
through the use of square attention windows. As a result, the output of
the encoder is composed of multi-grained features that not only encode
intra-character local patterns which are essential to distinguish
characters but also capture the correlation between textual and
non-textual components which is necessary to correctly locate the fields
of interest. We note that positional embedding is added to the encoder’s
feature map before the encoder’s forth stage.
## Decoder
The decoder takes as input the encoder’s output and a task token. It
then outputs autoregressively several tokens that represent the fields
of interest specified by the input token. The decoder consists of
$n$[^2] layers, each one is similar to a vanilla Transformer decoder
layer. It consists of a multi-head self-attention sub-layer followed by
a multi-head cross-attention sub-layer and a feed-forward sub-layer.
### Tokenization
We use the tokenizer of the RoBERTa model [RoBERTa](http://arxiv.org/pdf/1907.11692v1) to
transform the ground-truth text into tokens. This allows to reduce the
number of generated tokens, and so the memory consumption as well as
training and inference times, while not affecting the model performance
as shown in section [abla]. Similar to [donut](http://arxiv.org/pdf/2305.09520v1),
special tokens are added to mark the start and the end of each field or
group of fields. Two additional special tokens $$ and $$
are used to separate fields or group of fields appearing more than once
in the ground truth. An example is shown in figure
[fig:token].
### At Training Time
When training the model, we use a teacher forcing strategy. This means
that we give the decoder all the ground truth tokens as input. Each
input token corresponding last hidden state is used to predict the next
token. To ensure that each token only attends to previous tokens in the
self-attention layer, we use a triangular attention mask that masks the
following tokens.
# Expriments and Results
## Pre-training
We pre-train our model on two different steps :
### Knowledge Transfer Step
Using an $L2$ Loss, we teach the ConvNext-based encoder blocks to
produce the same feature map as the PP-OCR-V2 [Paddle](http://arxiv.org/pdf/2109.03144v2)
recognition backbone which is an enhanced version of MobileNetV1
[mobilenet](http://arxiv.org/pdf/1909.02765v2). A pointwise convolution is applied to the
output of the ConvNext-based blocks in order to obtain the same number
of channels as the output of PP-OCR-V2 recognition backbone. The goal of
this step is to give the encoder the ability to extract discriminative
intra-character features. We use 0.2 million documents from the IIT-CDIP
[CDIP](http://arxiv.org/pdf/2305.06148v1) dataset for this task. We note that even though
PP-OCR-V2 recognition network was trained on text crops, the features
generated by its backbone on a full image are still useful thanks to the
translation equivariance of CNNs.
### Masked Document Reading Step
After the knowledge transfer step, we pre-train our model on the task of
document reading. In this pre-training phase, the model learns to
predict the next textual token while conditioning on the previous
textual tokens and the input image. To encourage joint reasoning, we
mask several $32 \times 32$ blocks representing approximately fifteen
percent of the input image. In fact, in order to predict the text
situated within the masked regions, the model is obliged to understand
its textual context. As a result, DocParser learns simultaneously to
recognize characters and the underlying language knowledge. We use 1.5
million IIT-CDIP documents for this task. These documents were annotated
using Donut. Regex rules were applied to identify poorly read documents,
which were discarded.
## Fine-tuning
After the pre-training stage, the model is fine-tuned on the information
extraction task. We fine-tune DocParser on three datasets: SROIE and
CORD which are public datasets and an in-house private Information
Statement Dataset.
#### SROIE
: A public receipts dataset with 4 annotated unique fields : company,
date, address, and total. It contains 626 receipts for training and 347
receipts for testing.
#### CORD
: A public receipts dataset with 30 annotated unique fields of interest.
It consists of 800 train, 100 validation and 100 test receipt images.
#### Information Statement Dataset (ISD)
: A private information statement dataset with 18 annotated unique
fields of interest. It consists of 7500 train, 3250 test and 3250 eval
images. The documents come from 15 different insurers, each insurer has
around 4 different templates. We note that for the same template, the
structure can vary depending on the available information. On figure
1 we show 3 samples from 3
different insurers.
Anonymized samples from our private in-house
dataset. The fields of interest are located within the red
boxes.
## Evaluation Metrics
We evaluate our model using two metrics:
### Field-level F1 Score
The field-level F1 score checks whether each extracted field corresponds
exactly to its value in the ground truth. For a given field, the
field-level F1 score assumes that the extraction has failed even if one
single character is poorly predicted. The field-level F1 score is
described using the field-level precision and recall as:
$$\text{Precision} = \frac{\text{The number of exact field matches}}{\text{The number of the detected fields}}$$
$$\text{Recall} = \frac{ \text{The number of exact field matches}}{\text{The number of the ground truth fields}}$$
$$\text{F1} = \frac{ 2 \times \text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}}$$
### Document Accuracy Rate (DAR)
This metric evaluates the number of documents that are completely and
correctly processed by the model. If for a given document we have even
one false positive or false negative, the DAR assumes that the
extraction has failed. This metric is a challenging one, but requested
in various industrial applications where we need to evaluate at which
extent the process is fully automatable.
## Setups
The dimension of the input patches and the output vectors of every stage
$C_i,$ $i \in [0\mathrel{{.}\,{.}}\nobreak 5]$ are respectively set to
$64$, $128$, $256$, $512$, $768$, and $1024$. We set the number of
decoder layers to $1$. This choice is explained in
Section [abla]. For both pre-training and fine-tuning
we use the Cross-Entropy Loss, AdamW [ADAMW](http://arxiv.org/pdf/2311.11446v2) optimizer
with weight decay of $0.01$ and stochastic depth [stocha](http://arxiv.org/pdf/1603.09382v3)
with a probability equal to $0.1$. We also follow a light data
augmentation strategy which consists of light re-scaling and rotation as
well as brightness, saturation, and contrast augmentation applied to the
input image. For the pre-training phase, we set the input image size to
$2560 \times 1920$. The learning rate is set to $1e-4$. The pre-training
is done on 7 A100 GPUs with a batch size of 4 on each GPU. We use
gradient accumulation of 10 iterations, leading to an effective batch
size of $280$. For the fine-tuning, the resolution is set to
$1600 \times 960$ for CORD and SROIE datasets and $1600 \times 1280$ for
the Information Statement Dataset. We pad the input image in order to
maintain its aspect ratio. We also use a Cosine Annealing scheduler
[cosine](http://arxiv.org/pdf/1608.03983v5) with an initial learning rate of $3e-5$ and a
batch size of $8$.
## Results
| | | | SROIE | | CORD | | ISD | | | |
|:--:|:--:|:--:|:--:|:--:|:--:|:--:|:--:|:--:|:--:|:--:|
| 4-5 | | | | | | | | | | |
| | OCR | Params(M) | F1(%) | Time(s) | F1(%) | Time(s) | F1(%) | Time(s) | | |
| LayoutLM-v3 | | $87+\alpha^{*}$ | $77.7$ | $2.1 + t^{*}$ | $80.2$ | $2.1+t^{*}$ | $90.8$ | $4.1+t^{*}$ | | |
| Donut | | 149 | 81.7 | 5.3 | 84 | 5.7 | 95.4 | 6.7 | | |
| Dessurt | | 87 | 84.9 | 16.7 | 82.5 | 17.9 | 93.5 | 18.1 | | |
| **DocParser** | | **70** | **87.3** | 3.5 | **84.5** | 3.7 | **96.2** | **4.4** | | |
**Performance comparisons on the three datasets.** The field-level
F1-score and the extraction time per image on an Intel Xenion W-2235 CPU
are reported. In order to ensure a fair comparison, we exclude
parameters related to vocabulary. Additional parameters $\alpha^{*}$ and
time $t^{*}$ for the OCR step should be considered for LayouLM-v3. For
the ISD dataset $t^{*}$ is equal to 3.6 seconds.
We compare DocParser to Donut, Dessurt and LayoutLM-v3. The results are
summarized in table
1. A
comparison of inference speed on an NVIDIA Quadro RTX 6000 GPU is
presented in table 2. Per-field extraction performances on our
Information Statement Dataset can be found in table
3.
DocParser achieves a new state-of-the-art on SROIE, CORD and our
Information Statement Dataset with an improvement of respectively 2.4,
0.5 and 0.8 points over the previous state-of-the-art. In addition,
Docparser has a significantly faster inference speed and less
parameters.
| | SROIE | CORD | ISD | |
|:--------------|:----------------|:----------------|:----------------|:----|
| LayoutLM-v3 | 0.041 + $t^{*}$ | 0.039 + $t^{*}$ | 0.065 + $t^{*}$ | |
| Donut | 0.38 | 0.44 | 0.5 | |
| Dessurt | 1.2 | 1.37 | 1.39 | |
| **DocParser** | 0.21 | 0.24 | **0.25** | |
**Comparison of inference speed on GPU.** Extraction time (seconds) per
image on an NVIDIA Quadro RTX 6000 GPU is reported. Additional time
$t^{*}$ for the OCR step should be considered for LayouLM-v3. For the
ISD dataset $t^{*}$ is equal to 0.5 seconds.
| | LayoutLM | DONUT | Dessurt | **DocParser** |
|:-----------------------|:---------|:------|:--------|:--------------|
| | | | | |
| | | | | |
| | | | | |
| | | | | |
| | | | | |
| first driver | | | | |
| | | | | |
| second driver | | | | |
| | | | | |
| third driver | | | | |
| | | | | |
| of contract | | | | |
| | | | | |
| | | | | |
| | | | | |
| | | | | |
| the document | | | | |
| | | | | |
| | | | | |
| driver | | | | |
| | | | | |
| driver | | | | |
| | | | | |
| | | | | |
| driver of the accident | | | | |
| | | | | |
| driver of the accident | | | | |
| | | | | |
| | | | | |
| | | | | |
**Extraction performances on our Information Statement Dataset.** Per
field (field-level) F1-score, field-level F1-score mean, DAR, and
extraction time per image on an Intel Xenion W-2235 CPU are reported.
The OCR engine inference time $t^{*}$ should be considered for
LayouLM-v3.
Regarding the OCR required by the LayoutLM-v3 approach, we use, for both
SROIE and CORD datasets, Microsoft Form Recognizer[^3] which includes a
document-optimized version of Microsoft Read OCR (MS OCR) as its OCR
engine. We note that we tried combining a ResNet-50
[Resnet](http://arxiv.org/pdf/1608.05895v1)-based DBNet++ [DB](http://arxiv.org/pdf/2202.10304v1) for text
detection and an SVTR [SVTR](http://arxiv.org/pdf/2401.09802v1) model for text recognition
and fine-tuned them on the fields of interest of each dataset. However,
the obtained results are worse than those obtained with Microsoft Form
Recognizer OCR engine. For the Information Statement Dataset, we don’t
use MS OCR for confidentiality purposes. Instead, we use an in-house OCR
fine-tuned on this dataset to reach the best possible performances. Even
though the best OCRs are used for each task, LayoutLM-v3 extraction
performances are still lower than those of OCR-free models. This proves
the superiority of end-to-end architectures over the OCR-dependent
approaches for the information extraction task. We note that for Donut,
we use the same input resolution as DocParser. For Dessurt, we use a
resolution of $1152 \times 768$, which is the resolution used to
pre-train the model.
# Primary Experiments and Further Investigation
## Primary Experiments
In all the experiments, the tested architectures were pre-trained on 0.5
Million synthesized documents and fine-tuned on a deskewed version of
the SROIE dataset. We report the inference time on a an Intel Xenion
W-2235 CPU, as we aim to provide a model suited for low resources
scenarios.
| | | | | |
|:-----------------------|:----|:----|:----|:----|
| EasyOCR-based encoder | | | | |
| PP-OCRv2-based encoder | | | | |
| Proposed encoder | | | | |
**Comparison of different encoder architectures.** The dataset used is a
deskewed version of the SROIE dataset. The field-level F1 score is
reported.
### On the Encoder’s Architecture
The table 4 shows a comparison between an
EasyOCR[^4]-based encoder, a PP-OCRv2 [Paddle](http://arxiv.org/pdf/2109.03144v2)-based
encoder and our proposed DocParser encoder. Concerning the EasyOCR and
PP-OCRv2 based encoders, each one consists of its corresponding OCR’s
recognition network followed by few convolutional layers that aim to
further reduce the feature map size and increase the receptive field.
Our proposed encoder surpasses both encoders by a large margin.
| | | | | |
|:---------------------|:--------------------------|:----|:----|:----|
| | | | | |
| where the feature | | | | |
| map width is reduced | | | | |
| (seconds) | F1(%) | | | |
| | | | | |
| (3,4,5) (proposed) | Transformer | | | |
| (3,4,5) | LSTM + Additive attention | | | |
| (1,2,3) | Transformer | | | |
| (1,2,3) | LSTM + Additive attention | | | |
| No reduction | Transformer | | | |
| No reduction | LSTM + Additive attention | | | |
**The effect of decreasing the width of the feature map in various
stages of DocParser’s encoder.** The dataset used is a deskewed version
of the SROIE dataset. The field-level F1-score and the extraction time
per image on an Intel Xenion W-2235 CPU are reported.
### On the Feature Map Width Reduction
While encoding the input image, the majority of the text recognition
approaches reduce the dimensions of the feature map mainly vertically
[SVTR](http://arxiv.org/pdf/2401.09802v1) [text_recognition](http://arxiv.org/pdf/1904.01906v4). Intuitively,
applying this approach for the information extraction task may seem
relevant as it allows different characters to be encoded in different
feature vectors. Our empirical results, however, show that this may not
always be the case. In fact, we experimented with reducing the encoder’s
feature map width at different stages. As a decoder, we used both a one
layer vanilla Transformer decoder and a Long Short-Term Memory (LSTM)
[LSTM](http://arxiv.org/pdf/2103.15232v1) coupled with an attention mechanism that uses an
additive attention scoring function [additive](http://arxiv.org/pdf/2201.01706v1).
Table 5 shows that reducing the width of the
feature map in the early stages affects drastically the model’s accuracy
and that reducing the width of the feature map in the later stages
achieves the the best speed-accuracy trade-off.
Table 5 also shows that while the LSTM-based
decoder struggles with a reduced width encoder output, the performance
of the vanilla Transformer-based decoder remains the same in both cases.
This is probably due to the multi-head attention mechanism that makes
the Transformer-based decoder more expressive than an LSTM coupled with
an attention mechanism.
### On the Tokenizer Choice
In addition to the RoBERTa tokenizer, we also tested a character-level
tokenizer.
Table 6
shows that the RoBERTa tokenizer allows faster decoding while achieving
the same performance as the character-level tokenizer.
| | | | | |
|:--------------------------|:----|:----|:----|:----|
| | | | | |
| RoBERTa tokenizer | | | | |
| Character-level tokenizer | | | | |
**Comparison between different tokenization techniques.** The dataset
used is a deskewed version of the SROIE dataset. The field-level
F1-score and the decoding time per image on an Intel Xenion W-2235 CPU
are reported.
### On the Number of Decoder Layers
Table 7 shows that increasing the number of
decoder layers doesn’t improve DocParser’s performance. Therefore, using
one decoder layer is the best choice as it guarantees less computational
cost.
### On the Data Augmentation Strategy
Additionally to the adopted augmentation techniques, we experimented
with adding different types of blur and noise to the input images for
both the pre-training and the fine-tuning. We concluded that this does
not improve DocParser’s performance. The lack of performance improvement
when using blur may be attributed to the fact that the datasets used for
evaluating the model do not typically include blurred images.
Additionally, it is challenging to accurately create realistic noise,
thus making the technique of adding noise to the input images
ineffective.
| | | | | |
|:----|:----|:----|:----|:----|
| | | | | |
| | | | | |
| | | | | |
| | | | | |
**Effect of the number of decoder layers on the performance and the
decoding inference time of DocParser.** The dataset used is a deskewed
version of the SROIE dataset. The field-level F1-score and the decoding
time per image on an Intel Xenion W-2235 CPU are reported.
## Further Investigation
| | | | | |
|:---------------------------------------------|:----|:----|:----|:----|
| | | | | |
| Knowledge transfer | | | | |
| Knowledge transfer + Document reading | | | | |
| Knowledge transfer + Masked document reading | | | | |
**Comparison between different pre-training strategies.** All the models
are pre-trained for a total of 70k steps. The field-level F1-score is
reported.
### On the Pre-training Strategy
Table
8
presents a comparison between different pre-training strategies. To
reduce compute used, all the models were pre-trained for 70k
back-propagation steps, with 7k knowledge transfer steps in the case of
two pre-training tasks. The results show that masking text regions
during the document reading pre-training task does effectively lead to
an increase in performance on all three datasets. It also confirms, as
demonstrated in [donut](http://arxiv.org/pdf/2305.09520v1) and [Dessurt](http://arxiv.org/pdf/2203.16618v3),
that document reading, despite its simplicity, is an effective
pre-training task.
### On the Input Resolution
Figure 2 shows the effect of the input
resolution on the performance of DocParser on the SROIE dataset.
DocParser shows satisfying results even with a low-resolution input. It
achieves 83.1 field-level F1 score with a $960 \times 640$ input
resolution. The inference time for this resolution on an Intel Xenion
W-2235 CPU is only 1.7 seconds. So, even at this resolution, DocParser
still surpasses Donut and LayoutLM-v3 on SROIE while being more than
three times faster. However, if the input resolution is set to
$640 \times 640$ or below, the model’s performance shows a drastic drop.
This may be due to the fact that the characters start to be illegible at
such a low resolution.
The impact of the input resolution on DocParser’s
performance on the SROIE dataset. The field-level F1 score is
reported.
# Conclusion
We have introduced DocParser, a fast end-to-end approach for information
extraction from visually rich documents. Contrary to previously proposed
end-to-end models, DocParser’s encoder is specifically designed to
capture both intra-character local patterns and inter-character
long-range dependencies. Experiments on both public and private datasets
showed that DocParser achieves state-of-the-art results in terms of both
speed and accuracy which makes it perfectly suitable for real-world
applications.
### Acknowledgments
The authors wish to convey their genuine appreciation to Prof. Davide
Buscaldi and Prof. Sonia Vanier for providing them with valuable
guidance. Furthermore, the authors would like to express their gratitude
to Paul Wassermann and Arnaud Paran for their assistance in proofreading
previous versions of the manuscript.
[^1]: The corresponding author
[^2]: For our final model, we set $n$=1
[^3]: https://learn.microsoft.com/en-us/azure/applied-ai-services/form-recognizer/concept-read?view=form-recog-3.0.0
[^4]: https://github.com/JaidedAI/EasyOCR/blob/master/easyocr
Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding
2022-10-07
Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova
Visually-situated language is ubiquitous -- sources range from textbooks with diagrams to web pages with images and tables, to mobile apps with buttons and forms. Perhaps due to this diversity, previous work has typically relied on domain-specific recipes with limited sharing of the underlying data, model architectures, and objectives. We present Pix2Struct, a pretrained image-to-text model for purely visual language understanding, which can be finetuned on tasks containing visually-situated language. Pix2Struct is pretrained by learning to parse masked screenshots of web pages into simplified HTML. The web, with its richness of visual elements cleanly reflected in the HTML structure, provides a large source of pretraining data well suited to the diversity of downstream tasks. Intuitively, this objective subsumes common pretraining signals such as OCR, language modeling, image captioning. In addition to the novel pretraining strategy, we introduce a variable-resolution input representation and a more flexible integration of language and vision inputs, where language prompts such as questions are rendered directly on top of the input image. For the first time, we show that a single pretrained model can achieve state-of-the-art results in six out of nine tasks across four domains: documents, illustrations, user interfaces, and natural images.
Show Paper Content
# Introduction
Research on the interaction between language and vision has
traditionally focused on tasks where images and text can be separated
into distinct channels, e.g. visual question answering or image
captioning. However, *visually-situated language* is a far more
pervasive way in which these modalities interact and blend together. For
example, documents, tables, infographics, and user interfaces (UIs) are
intended to be consumed holistically, without clear boundaries between
textual and visual elements
(Figure [fig:tasks]). Comprehensive understanding
of this information requires a deep set of skills, including the ability
to recognize text, understand language, and incorporate diverse visual
context.
Previous work on understanding visually-situated language is scattered.
The focus is typically on complex task-specific combinations of
available inputs and tools. For example, document-understanding
models [layoutlmv3](None) rely on external OCR systems,
UI-understanding models rely on platform-specific metadata (e.g. Android
view hierarchy) [uibert](https://doi.org/10.24963/ijcai.2021/235), and diagram-understanding
models rely on diagram parses [kembhavi2016diagram](http://arxiv.org/pdf/1603.07396v1).
Domain-specific engineering can be effective for high-resource settings
such as documents, where there is an abundance of tools and data
available. However, these pipelined models lack sharing of the
underlying data, model architectures, and objectives across domains,
limiting their general applicability. Moreover, relying on external
systems like OCR increases engineering complexity, limits adaptability,
and can increase overall computational cost. Recent work on OCR-free,
end-to-end document understanding from
images [donut](https://arxiv.org/abs/2111.15664), [dessurt](https://arxiv.org/abs/2203.16618) has attempted to remove such
task-specific engineering and reliance on external components during
inference by learning to decode OCR outputs during pretraining—a
significant step towards more general-purpose models. However, the focus
on text at the surface level limits the depth of knowledge transferred
from unsupervised data.
We present `Pix2Struct`[^1], a pretrained model that combines the
simplicity of purely pixel-level inputs with the generality and
scalability provided by self-supervised pretraining from diverse and
abundant web data. Specifically, we propose a *screenshot parsing*
objective that requires predicting an HTML-based parse from a masked
screenshot of a web page. HTML provides clean signals about text,
images, and layouts, while the masked inputs encourage joint reasoning
about their co-occurrence. With the diversity and complexity of textual
and visual elements found on the web, `Pix2Struct` learns rich
representations of the underlying structure of web pages, which we show
can effectively transfer to a variety of downstream visual language
understanding tasks.
A key ingredient which enables this transfer is processing inputs
visually and holistically as they are intended for human readers. We
introduce variable-resolution inputs for vision transformers (ViT) that
prevent distortion of the original aspect ratio, which can vary greatly
across documents, figures, and UIs. During finetuning, we render other
inputs (e.g., questions in VQA and bounding boxes in UI tasks) onto the
image input for the task. In effect, we consume all our inputs through a
single modality, simplifying the modality combination problem in
previous work.
We train two variants with 282M and 1.3B parameters, which we refer to
as `Pix2Struct`-Base and `Pix2Struct`-Large respectively, on 80M
screenshots of web pages collected from the URLs in the C4
corpus [t5](http://jmlr.org/papers/v21/20-074.html)[^2]. Experiments on four domains and nine
tasks show that our finetuned models strongly outperform Donut (ranging
from 9 to 53 points), the strongest existing baseline without pipelines.
Compared with models with domain-specific pipelines, we lag behind the
state of the art in high-resource domains such as documents and natural
images but observe significant improvements (ranging from 1 to 44
points) in low-resource domains such as illustrations and UIs. We hope
these results encourage the community to continue developing such
general-purpose methods and further enable new applications in this
currently fragmented intersection of language and vision.
To summarize, our major contributions are as follows:
- We introduce the area of general-purpose visually-situated language
understanding, which consists of diverse tasks but common
challenges.
- We propose a *screenshot parsing* pretraining objective based on the
HTML source of web pages. Our objective is shown to be more
effective than prior attempts to enable the elegant pixel-to-text
design for general-purpose visually-situated language understanding.
- We introduce variable-resolution input representations to ViT and
new fine-tuning strategies that seamlessly integrate language and
vision inputs by directly rendering any text prompts on top of the
input image.
# Method
## Background
Prior attempts at pixel-only modeling of visually situated language have
largely focused on documents and natural images. For documents,
Donut [donut](https://arxiv.org/abs/2111.15664) and Dessurt [dessurt](https://arxiv.org/abs/2203.16618)
combine pretrained objectives based on surface-level features from
synthetic images or predicted OCR outputs. For natural images, recent
work—GIT2 [wang2022git](http://arxiv.org/pdf/2204.07780v1) and
PaLI [pali](https://doi.org/10.48550/ARXIV.2209.06794)—focuses on collecting and training on large
scale image captioning data that transfers well to datasets with natural
images (e.g. TextCaps).
We aim to provide a single pretrained model that can be finetuned on a
wider variety of tasks and domains. The input to our model is an image
in the form of raw pixels only, and the output is text in the form of
token sequences, similar to Donut. The goal is a visual analog of models
like T5 [t5](http://jmlr.org/papers/v21/20-074.html), where the generality of simple inputs and
outputs is combined with the power of pretraining on large unsupervised
sources of data. During finetuning, the complexity of adapting to
diverse downstream tasks resides only in data preprocessing.
Even without visual context, pixel-only language modeling for text has
only recently been attempted [rust2022language](http://arxiv.org/pdf/2207.06991v2)—perhaps
because it requires solving multiple hard sub-problems. First, the
ability to read with high fidelity while also building rich high-level
representations poses a difficult optimization problem. Second, encoding
text-heavy inputs (e.g. long documents) involves processing
high-resolution images with variable aspect ratios. State-of-the-art
document understanding models [layoutlmv3](None) therefore
rely on the combination of (possibly noisy) OCR outputs with low
resolution images.
We show the components of `Pix2Struct` that address these challenges.
Section 2.2 discusses modifications to the
transformer inputs to handle variable aspect ratios and resolutions.
Section 2.3 details our proposed screenshot
parsing objective and
Section 2.4 describes curriculum learning
for more robust transfer learning. Finally,
Section 2.5 shows how `Pix2Struct` consumes
textual and visual inputs for downstream tasks (e.g. questions and
images) in the same space by rendering text inputs onto images.
## Architecture [sec:architecture]
`Pix2Struct` is an image-encoder-text-decoder based on
ViT [vit](http://arxiv.org/pdf/2105.15075v2). While the bulk of the model is fairly
standard, we propose one small but impactful change to the input
representation to make `Pix2Struct` more robust to various forms of
visually-situated language. Before extracting fixed-size patches, the
standard ViT scales the input images to a predefined resolution, which
creates two undesirable effects: (1) rescaling the image distorts the
true aspect ratio, which can be highly variable for documents, mobile
UIs, and figures. (2) transferring these models to downstream tasks with
higher resolution is
non-trivial [train-test-resolution](https://proceedings.neurips.cc/paper/2019/file/d03a857a23b5285736c4d55e0bb067c8-Paper.pdf), [simvlm](https://arxiv.org/abs/2108.10904), since the
model only observes one specific resolution during pretraining.
We instead propose to always scale our input image up or down such that
we extract the maximal number of fixed-size patches that fit within the
given sequence length
(Figure [fig:input_rep]). In order for the
model to handle variable resolutions unambiguously, we use 2-dimensional
absolute positional embeddings for the input patches. Together these
changes to the standard ViT inputs provide two major advantages in terms
of robustness to: (1) extreme aspect ratios, which is common in the
domains that we experiment with, and (2) on-the-fly changes to the
sequence length and resolution.
## Pretraining [sec:pretraining]
The goal of pretraining is for `Pix2Struct` to represent the underlying
structure of the input image. To that end, we create self-supervised
pairs of input images and target text from web pages. For each page in
the pretraining corpus, we start by collecting its HTML source and a
screenshot using a viewport of 1024 x 1024.
**Screenshot parsing inputs & outputs** The screenshot and HTML are
modified to ensure rich and dense learning signal during pretraining.
These modifications provide a reasonable trade-off between preserving
the semantics of the page and requiring a practical decoder sequence
length.
We condense the HTML DOM tree by (1) only keeping nodes with *visible*
elements or descendants with visible elements and (2) if a node does not
contain visible elements and it only has a single child, replacing the
singleton child with any grandchildren to remove chained nesting. In
each node, we only use the text, along with filenames and alt-text of
images. Much more information could be retained (e.g. element tags,
style, titles and URLs) in future work. The decoder sequence length is
further reduced by finding the largest linearized subtree that fits
within a predefined sequence length. A bounding box indicating the
region covered by the chosen subtree is also drawn on the screenshot.
For better context modeling, we introduce a
BART-like [lewis-etal-2020-bart](https://doi.org/10.18653/v1/2020.acl-main.703) learning signal by
masking 50% of the text and decoding the entire subtree. The masked
regions are randomly sampled spans of text from the chosen subtree where
we render masks
(Figure [fig:screenshot_parsing_running]).
:
$\rightarrow$
\<\<\ \\> \<\
\\> \<\
\\> \\>
**Comparison to existing pretraining strategies** Our proposed
screenshot parsing seamlessly integrates signals reminiscent of several
well-known pretraining strategies:
- Recovering the unmasked parts of the parse is similar to OCR, a
prerequisite skill for understanding language. OCR pretraining was
proposed in Donut which uses synthetic renderings or OCR outputs. In
Figure [fig:screenshot_parsing_running],
predicting `` exemplifies this learning signal.
- Recovering the masked parts of the parse is much like masked
language modeling [bert](https://doi.org/10.18653/v1/N19-1423). A major difference is that
the visual context often provides additional powerful cues. In
Figure [fig:screenshot_parsing_running],
predicting `` exemplifies this signal.
- Recovering the alt-text from images is a common pretraining strategy
for image
captioning [conceptual-captions](https://doi.org/10.18653/v1/P18-1238), [wang2022git](http://arxiv.org/pdf/2204.07780v1), [pali](https://doi.org/10.48550/ARXIV.2209.06794).
A major difference is that the model is permitted to use the web
page as additional context. In
Figure [fig:screenshot_parsing_running],
predicting `img_alt=C++` exemplifies this learning signal.
Appendix 13 contains more details
including examples of screenshots paired with their gold and predicted
parses.
## Warming up with a reading curriculum [sec:curriculum]
While we can directly pretrain `Pix2Struct` on the screenshot parsing
task, we find that doing this naively can result in instability and slow
learning. However, if we first expose the model to a short “warmup”
stage of simply learning to read, we find a strong curriculum learning
effect where (1) pretraining is more stable and converges faster, and
(2) we observe better finetuning performance, as discussed in
Section 5. We create images of text snippets
with random colors and fonts. The model is simply trained to decode the
original text (see
Appendix 12 for examples). This type of
curriculum learning was also used in Dessurt [dessurt](https://arxiv.org/abs/2203.16618)
and can also be viewed as a simplified version of Donut’s pretraining.
## Finetuning [sec:finetuning]
Finetuning `Pix2Struct` is straightforward and largely a matter of
preprocessing the downstream data to unambiguously reflect the task in
the image inputs and text outputs, analogous to the way
T5 [t5](http://jmlr.org/papers/v21/20-074.html) is used for text-based tasks. In this section,
we cover the preprocessing strategies for the tasks described in
Table [tab:datasets]. Examples of this
preprocessing are shown in
Figure [fig:tasks].
Captioning is the most straightforward, since the input image and the
output text can be directly used (as in TextCaps, Screen2Words). In the
case where the focus of the caption is a specific bounding box (as in
Widget Captioning), we draw the target bounding box on the image itself.
For visual question answering (as in OCR-VQA, ChartQA, DocVQA,
InfographicsVQA), while multimodal models typically reserve a
specialized text channel for the question, we opt to instead directly
render the question as a header at the top of the original
image. `Pix2Struct` reads both the question and the image jointly via
the visual modality. This strategy is analogous to the common practice
of simply concatenating all inputs during finetuning of pretrained text
models, first proposed in GPT [gpt](http://arxiv.org/pdf/2310.01427v1) and has been the
default method in NLP since then. Intuitively, this strategy is
effective because `Pix2Struct` has been pretrained to be sensitive to
long-range interactions between various parts of the input image. In the
case of multiple choice answers (as in AI2D), we also render the choices
in the header as part of the question.
The most complex scenario is RefExp, where the task is choosing between
UI components that a natural language expression could be referring to.
For each candidate, we create a training instance where the input image
contains the bounding box and referring expression, and the decoding
target is “true” or “false”. We sample five negative candidates per
positive candidate during training. During inference, we pick the
candidate for which the model generates “true” with the highest
score.[^3]
# Experimental Setup
## Benchmarks
We evaluate `Pix2Struct` on multiple benchmarks for visually-situated
language understanding across four domains: illustrations, user
interfaces, natural images, and documents. Since we are the first to
aggregate datasets with this scope, we optimized for diversity in
domains and in task-format. Evaluation is restricted to standard splits
without additional labeled data.
Table [tab:datasets] in
Appendix 10 provides a summary of
the datasets with details in
Section 4.
We use evaluation metrics as defined in the original papers: (a) average
normalized Levenshtein similarity (ANLS) for DocVQA and InfographicVQA,
(b) exact match (EM) for AI2D, RefExp, and OCR-VQA, (c) relaxed accuracy
(RA) for ChartQA, and (d) CIDEr for the generation tasks.
## Implementation and Baselines
**Pretraining** We pretrain two model variants: (a) a *base* model with
282M parameters including 12 encoder and 12 decoder layers with a hidden
size of 768, and (b) a *large* model with 1.3B parameters including 18
layers with a hidden size of 1536. Both models have the same warmup
stage using text rendered from BooksCorpus [books](http://arxiv.org/pdf/1506.06724v1)
lasting 30K steps with a maximum input sequence length of 128 patches.
The base model is then pretrained further for 270K steps with the
screenshot parsing objective using a batch size of 2048 on 64 Google
Cloud TPUs. The large model is pretrained for 170K steps with a batch
size of 1024 on 128 Google Cloud TPUs. Both models use an input sequence
length of 2048 patches and are optimized using
Adafactor [shazeer2018adafactor](http://arxiv.org/pdf/1604.06174v2). The learning rate
schedule uses a linear warmup of 1000 steps to 0.01, followed by cosine
decay to 0. The decoder sequence length is 128 tokens, and we choose
pretraining targets to have at most 1024 characters. As a reference
point, the base model reaches 30 BLEU and the large model reaches 32
BLEU on the pretraining validation set. Details about finetuning can be
found in Appendix 11.
**Baselines** Across all tasks, we found a large number of methods
which could serve as baselines. We compare `Pix2Struct` against state
of the art (SotA) methods in each domain (see
Section 4 for method descriptions). Several
methods use model ensembles, multitask with labeled training data from
other datasets [powalski2021going](http://arxiv.org/pdf/2102.09550v3), [wang2022git](http://arxiv.org/pdf/2204.07780v1), or train
with validation data [li2021structurallm](https://doi.org/10.18653/v1/2021.acl-long.493). For fair
comparison and ease of experimentation, we focus on single-model and
single-task baselines trained on standard splits. Several (per-task)
SotA [li2021vut](http://arxiv.org/pdf/2107.13731v2), [masry-etal-2022-chartqa](https://doi.org/10.18653/v1/2022.findings-acl.177) use
domain-specific inputs (e.g. view hierarchies for UIs or gold data
tables for charts) making it difficult to apply them to other domains.
For a strong, consistent visual baseline across domains, we finetuned
Donut on tasks where a purely visual baseline was unavailable.[^4]
# Results [sec:results]
Table [tab:main_res] compares
`Pix2Struct` with prior work.
## Illustrations
**ChartQA** [masry-etal-2022-chartqa](https://doi.org/10.18653/v1/2022.findings-acl.177) is a VQA dataset
with questions based on charts, i.e. visual representations of tabular
data.[^5]. VisionTaPas [masry-etal-2022-chartqa](https://doi.org/10.18653/v1/2022.findings-acl.177), the
current SotA, is a pipeline which operates on data tables predicted from
the given charts. It consists of (1) a ViT encoder for encoding the
chart image, (2) a TaPas encoder for encoding the question and the data
table, and (3) a cross-modal encoder. In contrast, `Pix2Struct` does not
rely on table extractors and uses the chart directly—improving the SotA
from 45.5 to 58.6 with the large variant.
**AI2D** [kembhavi2016diagram](http://arxiv.org/pdf/1603.07396v1) contains multiple choice
questions based on illustrative science diagrams (about geological
processes, biological structures etc.). The dataset comes with train and
test splits. We set aside 1% of the train split for validation. The
current SotA DQA-NET [kembhavi2016diagram](http://arxiv.org/pdf/1603.07396v1) focuses on
modeling entity relationships via a pipeline of tools for extracting
arrows, blobs, and other visual elements. `Pix2Struct`-Large outperforms
DQA-NET and Donut by 3.6 and 11.27 points respectively without any
domain-specific modifications.
**OCR-VQA** [mishra2019ocr](http://arxiv.org/pdf/2010.02582v1) is a VQA dataset on images
of book covers. The questions are based on book metadata such as title,
author, genre etc. Much of work on OCR-VQA, including the pipeline SotA
LATr [biten2022latr](http://arxiv.org/pdf/2309.17133v2), uses off-the-shelf OCR. Recent
work, GIT2 [wang2022git](http://arxiv.org/pdf/2204.07780v1), the current SotA, is
pretrained on 12.9B image caption pairs. Their final finetuning stage is
preceded by intermediate finetuning on eight VQA datasets including
VQAv2 [goyal2017making](http://arxiv.org/pdf/1612.00837v3),
VizWiz-VQA [chen2022grounding](http://arxiv.org/pdf/2202.01993v3), and
OCR-VQA [mishra2019ocr](http://arxiv.org/pdf/2010.02582v1) amongst others. Despite not
using more labeled training data, we outperform GIT2 by almost 1 point.
## UIs
**RefExp** [uibert](https://doi.org/10.24963/ijcai.2021/235) Given a natural language referring
expression, an app screenshot, and a set of components (via bounding
boxes on the screenshot), the goal is to retrieve the component that the
expression refers to. UIBert [uibert](https://doi.org/10.24963/ijcai.2021/235), the current SotA,
is pretrained on a combination of inputs from mobile apps including
screenshots, OCR text, and Android view hierarchies. Our models
substantially ourperform UI Bert by 1.4 and 3.4% absolute,
with `Pix2Struct`-Large setting the new SotA.
**Widget Captioning** [li-etal-2020-widget](https://doi.org/10.18653/v1/2020.emnlp-main.443) is an image
captioning task where the input is an app screenshot annotated with a
single bounding box denoting a widget (e.g. a button or a scroll bar).
The caption describes the functionality of the widget (e.g. *find
location*). VUT [li2021vut](http://arxiv.org/pdf/2107.13731v2), the current SotA uses a
specialized UI encoder combining images, bounding boxes, and view
hierarchies. `Pix2Struct`-Large improves the SotA CIDEr from 127.4 to
136.7.
**Screen2Words** [screen2words](https://doi.org/10.1145/3472749.3474765) is an image captioning
task where the input is an app screenshot and the caption describes the
functionality of the page (see
Figure [fig:tasks] for an example).
`Pix2Struct`-Large improves the state of the art CIDEr from 64.3 to
109.4.
## Natural Images
**TextCaps** Recently, GIT2 (5.1B parameters) and PaLI (17B parameters)
have advanced the state of the art on TextCaps by pretraining on 10B+
image-caption pairs extracted from the web. PaLI (CIDEr 135.4) and GIT2
(CIDEr 145) show comparable performance without OCR inputs. PaLI
achieves SotA (CIDEr 160.4) performance when finetuned with OCR,
indicating that even for large-scale methods, end-to-end pixel-only
performance lags behind pipeline SotA. While their image
captioning-based pretraining understandably improves TextCaps, previous
work [donut](https://arxiv.org/abs/2111.15664) shows that captioning may not transfer to
other domains (e.g. documents). Moreover, screenshot parsing subsumes
signals from captioning
(Section 2.3) while using a fraction of the
data used for pretraining GIT2 and PaLI. These results suggest that
`Pix2Struct` could further benefit from scaling in pretraining data and
model size.
## Documents
**DocVQA** [mathew2021docvqa](http://arxiv.org/pdf/2111.05547v1) is a dataset of questions
about scanned documents,[^6] including typewritten, printed, handwritten
and born-digital text. `Pix2Struct`-Large outperforms Donut, the
previous visual SotA on DocVQA by 9 points. Top-performing single-task
methods like UDOP [tang2022unifying](http://arxiv.org/pdf/2212.02623v3) (ANLS 84.7)
typically use three components: (a) an off-the-shelf OCR system, (b)
pretrained text and image encoders, and (c) additional pretraining on
the IIT-CDIP scanned documents corpus. Despite using purely visual
representations and no in-domain pretraining data, `Pix2Struct` achieves
competitive performance (ANLS 76.6).
**InfographicVQA** [mathew2022infographicvqa](http://arxiv.org/pdf/2104.12756v2) is a
dataset of questions about infographics from the web. A unique challenge
of this dataset is its large images with extreme aspect ratios. Donut
scales images to a fixed aspect ratio, which we speculate is the cause
of its poor performance with an ANLS of 11.6. `Pix2Struct`-Large sets
the state of the art amongst visual models with an ANLS of 40.
For both DocVQA and InfographicVQA, text-only baselines are at or near
the state of the art. A T5-based model (T5 + 2D + U) with 2D positional
biases [borchmann2021due](http://arxiv.org/pdf/2111.08609v1) achieves ANLS of 81 on DocVQA
and 46.1 on InfographicVQA. This is in part due to the text-heavy nature
of the data (especially DocVQA) where visual context plays a lesser
role, and the more mature pretrained text-based encoders can do the
heavy lifting.
**Common trends** Overall, `Pix2Struct` outperforms Donut in all tasks,
underscoring the effectiveness of our pretraining. We also advance the
single-task state of the art on six of nine benchmarks across four
domains. Scaling up from base to large results in considerable
improvements on all tasks despite the base model being trained for
3$\times$ more iterations than the large model. Previous
work [liu2019roberta](http://arxiv.org/pdf/1907.11692v1), [t5](http://jmlr.org/papers/v21/20-074.html) has shown that large batch
sizes and many training steps contribute greatly to the quality of the
pretrained model. Results indicate that further scaling up of
`Pix2Struct` is a promising direction.
# Analysis [sec:ablations]
| | | | |
|:------------------------|-----:|------:|------:|
| Pretraining | | | |
| VQA | | | |
| Captioning | | | |
| Full | 67.8 | 137.5 | 84.2 |
| – Warmup | 56.2 | 128.0 | 71.7 |
| – Masking | 55.7 | 129.4 | 77.4 |
| – Screenshot Parsing | 12.2 | 35.1 | 24.2 |
Ablations of pretraining components. Each ablation is a modification
with respect to the full model, while keeping the total number of
pretraining steps constant.
**Ablating pretraining objectives**
Table 1 analyzes the importance of each
component of our pretraining recipe on DocVQA, Widget Captioning, and
TextCaps validation sets. The full pretraining method consists of a
warmup reading stage on the BooksCorpus followed by pretraining using
the screenshot parsing objective. For these experiments, we use the base
variant with a total of 100K steps of pretraining including 30K warmup
steps followed by 70K steps of screenshot parsing. The screenshot
parsing ablation removes the screenshot parsing stage altogether and
uses an extended warmup stage of 100K steps. The warmup ablation skips
the warmup stage and directly pretrains from random initialization for
100K steps. The masking ablation uses 30K steps warmup followed by 70K
steps of screenshot parsing without masking.[^7]
The biggest drop in performance comes from ablating the screenshot
parsing stage, effectively reducing the pretraining to reading linear
text. Ablating the warmup and masking is nearly equivalent on DocVQA and
Widget Captioning while the warmup is slightly more important in
TextCaps. Overall, our results seem to indicate that reading and
understanding visually-situated language is a complex problem involving
skills including recognizing text, understanding language, and
incorporating visual context.
**Ablating variable-resolution inputs**
Figure 1 compares various ways to convert
input images into a constant number of patches. This ablation is
performed on the warmup stage
(Section 2.4), where we measure full sequence
accuracy. The ‘padded’ variant maintains the original aspect ratio, but
introduces significant padding, which sacrifices the effective
resolution. The ‘stretched’ variant, typically used in ViT, introduces
no padding but distorts the original image. Our variable-resolution
inputs get the best of both worlds by maintaining the original aspect
ratio while maximally utilizing the budget specified by the sequence
length. Experiments in
Appendix 8 show that this benefit leads to
more effective learning, even for a task as simple as transcribing text
in the input image.
Our variable-resolution inputs prevent aspect-ratio
distortion while minimizing padding.
# Discussion
This section lays out some of the challenges in training general-purpose
visual language understanding models, and discuss a road map for future
work.
**Resolution** Like Donut, we found that pretraining and finetuning
performance are extremely sensitive to the input resolutions.[^8] The
difficulty in using high-resolution images has been a bottleneck for
pixel-only models since higher resolutions often lead to longer sequence
lengths. This bottleneck has in part been responsible for the dominance
of OCR-based pipelines which are able to use lower image resolutions due
to a dedicated text encoder.[^9] However, steady progress with Donut
and `Pix2Struct` combined with recent progress in long range
transformers [press2021train](https://openreview.net/forum?id=R8sQPpGCv0) provides hope that
pixel-only models will bridge the gap with OCR-based pipelines.
**The visual web** As a first attempt towards a general-purpose visual
language understanding model, we focused on simplicity both in terms of
how we use the HTML source and our choice for the pretraining corpus,
C4—a known public corpus used in previous work [t5](http://jmlr.org/papers/v21/20-074.html) that
is significantly smaller and narrower than corpora used to train the
largest language models today. However, web data includes even richer
multimodal signals such as videos and interactions. We posit that future
versions of general-purpose visual language understanding models will
benefit from better data curation. This opportunity also comes with a
caveat: just like text-based models, we must be careful of harmful
content on the web, which multimodal models would also be sensitive to.
**Generality** While we have focused on general pixel-only models, we
do acknowledge that using OCR-pipelines or metadata can be appropriate
or even necessary in certain domains. For NLP, the scaling of pretrained
text based models has led to not only simpler model architectures and
preprocessing, but also emergent abilities on newer tasks which were
hitherto considered far too difficult [wei2022emergent](https://openreview.net/forum?id=yzkSU5zdwD).
A general-purpose model may also enable broader applications for visual
language, e.g. filling in missing accessibility
annotations [zhang2021screen](http://arxiv.org/pdf/2101.04893v1). Finally, given that the
overwhelming majority of prior work has leveraged OCR-based features, it
seems necessary to advance OCR-free alternatives (as this paper does) in
order to enable a clearer longer-term understanding around the proper
role for OCR. The broader objective of this work is to bring pretraining
for visually-situated language understanding a step closer to text-based
counterparts and pave the way for similar benefits from data and model
scaling.
# Related Work
To the best of our knowledge, no prior work has pretrained and evaluated
a visually-situated language understanding model on tasks spanning all
four domains of documents, illustrations, user interfaces, and natural
images. [^10] We build on prior work primarily focused on a single
domain and briefly highlight the similarities as well as the points of
departure with respect to such work here.
**Document understanding** State-of-the-art models in this domain are
based on a pipeline of an external OCR system and a model that combines
images and OCR
annotations [docformer](None), [powalski2021going](http://arxiv.org/pdf/2102.09550v3), [layoutlmv2](http://arxiv.org/pdf/2310.16527v1),
*inter alia*. Prominent representatives are
LayoutLMv3 [layoutlmv3](None), which uses a simplified
transformer-based architecture and losses that encourage patch–OCR
alignment. TILT [powalski2021going](http://arxiv.org/pdf/2102.09550v3) pretrains a text
decoder and an image + OCR-output encoder followed by intermediate
finetuning on multiple QA tasks. `Pix2Struct` is more closely related to
Donut and Dessurt [dessurt](https://arxiv.org/abs/2203.16618), both image-to-text models
without OCR at inference time; the main difference stems from our more
powerful pretraining task from ground truth structures and resolution
flexibility enabling transfer to a variety of visual language domains.
**UI understanding** Models in this group have focused solely on the UI
domain using pretraining data from mobile and web apps. While some
models use image-only
inputs [Liu2018LearningDS](http://arxiv.org/pdf/2309.10328v1), [Chen2020UnblindYA](http://arxiv.org/pdf/2003.00380v2), higher
accuracy approaches tend to benefit from often-noisy structures of view
hierarchies [li-etal-2020-mapping](https://doi.org/10.18653/v1/2020.acl-main.729) and element
annotations, e.g. UIBert [uibert](https://doi.org/10.24963/ijcai.2021/235),
ActionBert [actionbert](http://arxiv.org/pdf/2402.07938v2),
VUT [li2021vut](http://arxiv.org/pdf/2107.13731v2). One exception is concurrent
work [li2023spotlight](https://openreview.net/forum?id=9yE2xEj0BH7) which achieves comparable
performance with image-only inputs. The screen parsing
task [wu2021screen](None), while similar in name, is an
amalgamation of pipelines over domain-specific structures that are not
intended to produce transferable representations.
**Natural image understanding** Pix2Seq uses the image-to-text
architecture for core vision tasks such as object detection and instance
segmentation [chen2022unified](http://arxiv.org/pdf/2206.07669v2), [chen2021pix2seq](http://arxiv.org/pdf/2305.18279v1).
Additionally, a variety of model
architectures [singh2019towards](http://arxiv.org/pdf/1811.11903v1), [sidorov2019textcaps](http://arxiv.org/pdf/1709.08299v2), [wang2020multimodal](http://arxiv.org/pdf/2108.02059v1)
and objectives [yang2021tap](http://arxiv.org/pdf/2311.01038v2) have been proposed for
understanding natural images containing short segments of text (e.g.
street signs). The predominant source of pretraining data has been
image-caption pairs often in conjunction with the output of
OCR [pali](https://doi.org/10.48550/ARXIV.2209.06794), [yang2021tap](http://arxiv.org/pdf/2311.01038v2).
GIT2 [wang2022git](http://arxiv.org/pdf/2204.07780v1), the pixel-only SoTA, learns from
12.9 billion image-caption pairs and is about 4 times larger than
`Pix2Struct`— it outperforms our model significantly on natural images
(TextCaps) but underperforms on illustrations (OCR-VQA). PaLI benefits
from using a pipeline with OCR, obtaining higher performance on
TextCaps. These methods have not been evaluated on more text-dense input
domains.
**Illustrations** Models for illustrations have not been fully
pretrained on large scale data, perhaps because such data is not readily
available. Some components of such models, e.g. T5 and
TaPas [eisenschlos-etal-2020-understanding](https://doi.org/10.18653/v1/2020.findings-emnlp.27) used in the
VL-T5 and VisionTaPas models of
[masry-etal-2022-chartqa](https://doi.org/10.18653/v1/2022.findings-acl.177) or LATr’s OCR output
encoder [biten2022latr](http://arxiv.org/pdf/2309.17133v2) have been pretrained on
digital-born or OCR-ed documents. Our approach outperforms current SotA
models, without relying on other intermediate structures.
**Models learning from markup
structure** MarkupLM [li2021markuplm](https://doi.org/10.18653/v1/2022.acl-long.420) and
Webformer [wang2022webformer](http://arxiv.org/pdf/2202.00217v1) learn encoders of HTML
from web pages. HTLM [aghajanyan2021htlm](https://openreview.net/forum?id=P-pPW1nxf1r) and
CM3 [aghajanyan2022cm3](http://arxiv.org/pdf/2201.07520v1) are generative models of
simplified HTML to enable zero-shot prompting with text and natural
images. Im2Tex [deng2017image](http://arxiv.org/pdf/1709.06308v1) is conceptually the most
relevant in showing that a pixel-only parser can be learned from
freely-available pairs of markup and renders, but doesn’t focus on
transferring this signal to wider applications.
**Datasets** We have selected datasets representing challenges in
visually-situated language understanding in a variety of domains, but
our selection is not aimed to be exhaustive. The DUE
benchmark [borchmann2021due](http://arxiv.org/pdf/2111.08609v1) focuses on a more limited
domain of visual document understanding (e.g. excluding natural images
and UIs), but integrates a more comprehensive set of tasks within the
document understanding domain.
# Resolution in visually-situated language understanding tasks [sec:resolution]
Previous methods rescale input images to fixed resolutions, which can
introduce severe aspect ratio distortions for inputs such as webpages
and documents. In contrast, we prevent aspect ratio distortion by
rescaling input images up or down such that we extract the maximal
number of patches that fit within the given sequence length
(Figure [fig:input_rep]).
Figure [fig:resolution] gives an overview
of the importance of input resolutions in visually-situated language
understanding tasks. Though `Pix2Struct` is more efficient at making use
of the input resolution, both `Pix2Struct` and Donut require high
resolutions to perform well on DocVQA (note the log scale). For example,
we only see significantly diminishing returns after about 1M pixels
(4096 patches of $16\times16$ pixels for `Pix2Struct` and
$1024\times1024$ for fixed-resolution models). However, ViT models
typically pretrain with resolutions of $224\times224$ and finetune with
up to $512\times512$. This is a subtle but critical detail that makes
using standard ViT out of the box suboptimal.
On the right of
Figure [fig:resolution], we also present
example inference speeds on a v3-8 Cloud TPU when performing inference
on DocVQA. At full resolution (4096 sequence length or 1M pixels), the
base model processes 62 documents per second, and the large model
processes 20 documents per second.
# Full Results [sec:full_results]
Table [tab:full_res] reports full results
for pipeline and pixel-only methods. For fair comparison and ease of
experimentation, we focus on single-model and single-task baselines
trained on standard splits. Several (per-task)
SotA [li2021vut](http://arxiv.org/pdf/2107.13731v2), [masry-etal-2022-chartqa](https://doi.org/10.18653/v1/2022.findings-acl.177) use
domain-specific inputs (e.g. view hierarchies for UIs or gold data
tables for charts) making it difficult to apply them to other domains.
| Dataset | Domain | Description |
|:---|:---|:---|
| OCR-VQA | Illustrations | VQA over book covers. |
| ChartQA | Illustrations | VQA over charts (visualization of tabular data) |
| AI2D | Illustrations | VQA over science diagrams |
| RefExp | UIs | Detect UI component matching a natural language query |
| Widget Captioning | UIs | Captioning a UI component on a screen |
| Screen2Words | UIs | Captioning a UI screen to describe functionality |
| TextCaps | Natural images | Captioning of natural images containing text |
| DocVQA | Documents | VQA over scanned documents. |
| InfographicsVQA | Documents | VQA over high-res infographics. |
# Finetuning Dataset Details [sec:finetuning_datasets]
Table [tab:datasets] show the datasets in
our benchmark for visually-situated language understanding.
# Hyperparameters [sec:hyperparams]
The base and large models are finetuned with an input sequence length of
4096 and 3072 respectively, except the base model on InfographicVQA
which benefits from a longer sequence length of 6144. We cannot use a
longer sequence length for the large variant due to TPU/GPU memory
constraints. We finetune for 5000 or 10000 steps with a batch size of
32, 128, or 256, with hyperparameter tuning and early stopping based on
the validation set.
Table [tab:hyperparams] contains
hyperparameter values for all tasks.
$\rightarrow$
The elves, it seemed, were possessed of some mysterious power over the
arts; without eve
For the warmup stage, we create images of text snippets from the
BooksCorpus [books](http://arxiv.org/pdf/1506.06724v1) with random colors (uniformly sampled
from all possible RGB values), fonts (uniformly sampled from all
possible Google Fonts [^11]), and font sizes (uniformly sampled from
12pt to 36pt) on a white background. The text snippets are up to 128
bytes long. The width of the images are 640 pixels, and the text is
wrapped of it exceeds the width of the image. The height of the image is
fit to the content height. The text is unmasked as this stage is
intended purely as a learning-to-read task.
Exposing the model to a short “warmup” stage of simply learning to read,
results in a strong curriculum learning effect where (1) pretraining is
more stable and converges faster, and (2) we observe better finetuning
performance. Figure [fig:warmup] shows an example of
rendered text from the BooksCorpus with its “parse”.
# Pretraining Data [sec:pretraining_ex]
The pretraining data is constructed from URLs in the C4 corpus. We
collect 80M (about one third of the total number of documents) pairs of
screenshots paired with their HTML source. The screenshots have a width
of 1024 pixels, and the height of the image is fit to the content
height.
The figures below show screenshots of our pretraining data along with
ground-truth and predicted parses.
#### Predicted Parse
<<<>
<>>
<<>
<< <<1:1 drop-in for
#### Ground-truth Parse
<, I tried something Valentine's themed. If you'd like to help
raise money for fighting children's cancer you can follow the link right
above and help out, too. As inspiration for this semi-homemade recipe,
I looked at the two recipes on the bag of sweet dough, I got an idea and
today I'm going to share with you how that worked out.
\xa0 I got the bag of Sweet Dough using a coupon for a free product
that was sent to my by Rhodes BakeNServ in exchange for testing out
their products and sharing the results with all of you; no other form of
compensation was received.>
#### Predicted Parse
<, I tried something Valentine's themed. If you'd like to help
out, I think you'd go right ahead and do a post. Click on the link right
above and help out, too. As inspiration for this semi-homemade recipe,
I've shared up two recipes on the bag of sweet dough. I got an idea and
today I'm going to share with you the second one.
Thank you for any of the amazing baking ideas plus this free product
that was sent to my by Rhodes BakeNServ in exchange for testing.
I'm really excited and sharing this recipe with all of you
[^1]: For pretrained checkpoints and code, see
.
[^2]: We do not use the released text in C4. The web page content and
screenshots were crawled directly from the URLs.
[^3]: or lowest score if something other than “true” was generated
[^4]: Except RefExp due to the complexity inference.
[^5]: We evaluate on the task without the gold data table.
[^6]: from the UCSF Industry Documents Library
[^7]: All models use the same hyperparameters.
[^8]: See Appendix 8 for a concrete comparison.
[^9]: OCR pipelines, while noisy, often result in manageable sequence
lengths for large-scale text encoders.
[^10]: Some prior approaches have been evaluated on two domains.
[^11]:
Screenshot Parsing Pretraining
AI2D
Screen2Words
DocVQA
<<Pro>
<<<$15> </mo>>
<<20 users included>
<10 GB of storage>
<Priority email support>
<Help center access>>
<Get started>>>
carnivore
list of videos
for weather
reports in
different
locations
Fred LeCrone
TRIE++: Towards End-to-End Information Extraction from Visually Rich Documents
2022-07-14
Zhanzhan Cheng, Peng Zhang, Can Li, Qiao Liang, Yunlu Xu, Pengfei Li, Shiliang Pu, Yi Niu, Fei Wu
Recently, automatically extracting information from visually rich documents (e.g., tickets and resumes) has become a hot and vital research topic due to its widespread commercial value. Most existing methods divide this task into two subparts: the text reading part for obtaining the plain text from the original document images and the information extraction part for extracting key contents. These methods mainly focus on improving the second, while neglecting that the two parts are highly correlated. This paper proposes a unified end-to-end information extraction framework from visually rich documents, where text reading and information extraction can reinforce each other via a well-designed multi-modal context block. Specifically, the text reading part provides multi-modal features like visual, textual and layout features. The multi-modal context block is developed to fuse the generated multi-modal features and even the prior knowledge from the pre-trained language model for better semantic representation. The information extraction part is responsible for generating key contents with the fused context features. The framework can be trained in an end-to-end trainable manner, achieving global optimization. What is more, we define and group visually rich documents into four categories across two dimensions, the layout and text type. For each document category, we provide or recommend the corresponding benchmarks, experimental settings and strong baselines for remedying the problem that this research area lacks the uniform evaluation standard. Extensive experiments on four kinds of benchmarks (from fixed layout to variable layout, from full-structured text to semi-unstructured text) are reported, demonstrating the proposed method's effectiveness. Data, source code and models are available.
Show Paper Content
Cheng *et al.*: Bare Demo of IEEEtran.cls for Computer Society Journals
[^1]: $^*$Z. Cheng, P. Zhang and C. Li contributed equally to this
research.
visually rich document (VRD) is a traditional yet very important
research topic
[zhang2020trie](None), [katti2018chargrid](None), [zhao2019cutie](None), [palm2017cloudscan](None), [sage2019recurrent](None), [Aslan2016APB](None), [Janssen2012Receipts2GoTB](None), [dengel2002smartfix](None), [schuster2013intellix](None), [Simon1997AFA](None).
This is because automatically understanding VRDs can greatly facilitate
the key information entry, retrieval and compliance check in enormous
and various applications, including file understanding in court trial,
contract checking in the business system, statements analysis in
accounting or financial, case recognition in medical applications,
invoice recognition in reimburses system, resume recognition in
recruitment system, and automatically examining test paper in education
applications, etc.
In general, a VRD system can be divided into two separated parts: text
reading and key information extraction. Text reading module refers to
obtaining text positions as well as their character sequence in document
images, which falls into the computer vision areas related to optical
character recognition (*abbr*. OCR)
[wang2020all](None), [qiao2020textperceptron](None), [feng2019textdragon](None), [liao2017textboxes](None), [jaderberg2016reading](None), [wang2012end](http://arxiv.org/pdf/2207.04651v1), [shi2016end](None), [liao2019mask](None).
Information extraction (IE) module is responsible for mining key
contents (entity, relation) from the captured plain text, related to
natural language processing (NLP) techniques like named entity
recognition (NER)
[nadeau2007survey](None), [lample2016neural](None), [ma2019end](None) and
question-answer
[yang2016stacked](None), [anderson2018bottom](None), [fukui2016multimodal](None).
Early works [palm2017cloudscan](None), [sage2019recurrent](None)
implement the VRD frameworks by directly concatenating an offline OCR
engine and the downstream NER-based IE module, which completely discards
the visual features and position/layout[^1] information from images.
However, as appearing in many applications
[palm2017cloudscan](None), [zhang2020trie](None), [dengel2002smartfix](None), [schuster2013intellix](None), [sun2021spatial](None), [wang2021tag](None),
VRDs are usually organized with both semantic text features and flexible
visual structure features in a regular way. For better results,
researchers should consider the key characteristics of documents into
their techniques, such as layout, tabular structure, or even font size
in addition to the plain text. Then recent works begin to incorporate
these characteristics into the IE module by embedding multi-dimensional
information such as text content and their layouts
[katti2018chargrid](None), [denk2019bertgrid](None), [zhao2019cutie](None), [palm2019attend](None), [liu2019graph](None),
and even image features
[xu2019layoutlm](http://arxiv.org/pdf/2205.00476v2), [PICK2020YU](None), [Xu2020LayoutLMv2MP](None).
Unfortunately, all existing methods suffer from two main problems:
First, multi-modality features (like visual, textual and even layout
features) are essential for VRD , but the exploitation of the
multi-modal features is limited in previous methods. Contributions of
different kinds of features should be addressed for the IE part. For
another, text reading and IE modules are highly correlated, but their
contribution and relations have rarely been explored.
Considering the above issues, in this paper, we propose a novel
end-to-end . The workflow is as shown in
Figure 1. Instead of focusing on information
extraction task only, we bridge *text reading* and *information
extraction* tasks via a developed multi-modal context block. In this
way, two separated tasks can reinforce each other amidst a unified
framework. Specifically, the text reading module produces diversiform
features, including layout features, visual features and textual
features. The multi-modal context block fuses multi-modal features with
the following steps: (1) Layout features, visual features and textual
features are first fed into the multi-modal embedding module, obtaining
their embedding representation. (2) Considering the effectiveness of the
language model like BERT [denk2019bertgrid](None), (3) The
embedded features are then correlated with the spatial-aware attention
to learn the instance-level interactions. It means different text
instances may have explicit or implicit interactions, the ‘Total-Key’
and ‘Total-Value’ in receipts are highly correlated.
Consequently, the multi-modal context block can provide robust features
for the information extraction module, and the supervisions in
information extraction also contribute to the optimization of text
reading. Since all the modules in the network are differentiable, the
whole network could be trained in a global optimization way. To the best
of our knowledge, this is the first end-to-end trainable framework.
We also notice that it is difficult to compare existing methods directly
due to the different benchmarks used (most of them are private), the
non-uniform evaluation protocols, and even various experimental
settings. As is known to all, text reading
[Chen2020TextRI](None) is a rapidly growing research area,
attributing to its various applications and its uniform benchmarks and
evaluation protocols. We here reckon that these factors may restrict the
study of document understanding. To remedy this problem, we first
analyze many kinds of documents, and then categorize VRDs into four
groups along the dimensions of *layout* and *text type*. *Layout* refers
to the relative position distribution of texts or text blocks, which
contains two modes: the fixed mode and the variable mode. The former
connotes documents that follow a uniform layout format, such as passport
and the national value-added tax invoice, while the latter means that
documents may appear in different layouts. Referring to
[judd2004apparatus](http://arxiv.org/pdf/2305.19912v1), [soderland1999learning](None), we define
*text type* into two modalities[^2] : the structured and the
semi-structured. In detail, the structured type means that document
information is organized in a predetermined schema, i.e., the key-value
schema of the document is predefined and often tabular in style, which
delimits entities to be extracted directly. For example, taxi invoices
usually have quite a uniform tabular-like layout and information
structure like ‘Invoice Number’, ‘Total’, ‘Date’ etc. The
semi-structured type connotes that document content is usually
ungrammatical, but each portion of the content is not necessarily
organized in a predetermined format. For example, a resume may include
some predefined fields such as job experience and education information.
Within the job experience fields, the document may include free text to
describe the person’s job experience. Then, the user may desire to
search on free text only within the job experience field.
Table [table:dataset_summary]
summarizes the categories of visually rich documents from the previous
research literature. Secondly, we recommend or provide the corresponding
benchmarks for each kind of documents, and also provide the uniform
evaluation protocols, experimental settings and strong baselines,
expecting to promote this research area.
Major contributions are summarized as follows. (1) We propose an
end-to-end trainable framework TRIE++ for , which can be trained from
scratch, with no need for stage-wise training strategies. (2) We
implement the framework by simultaneously learning text reading and
information extraction tasks via a well-designed multi-modal context
block, and also verify the mutual influence of text reading and
information extraction. (3) To make evaluations more comprehensive and
convincing, we define and divide VRDs into four categories, in which
three kinds of real-life benchmarks are collected with full annotations.
For each kind of document, we provide the corresponding benchmarks,
experimental settings, and strong baselines. (4) Extensive evaluations
on four kinds of real-world benchmarks show superior performance
compared with the state-of-the-art. Those benchmarks cover diverse types
of document images, from fixed to variable layouts, from structured to
semi-unstructured text types.
Declaration of major extensions compared to the conference version
[zhang2020trie](None): (1) Instead of modelling context with
only layout and textual features in [zhang2020trie](None), we
here enhance the multi-modal context block by fusing three kinds of
features (layout, visual and textual features) with a spatial-aware
attention mechanism. Besides, we expand the application ranges of our
method, showing the ability to handle with four kinds of VRDs. (2)
Following the suggestions in the conference reviews that the prior
knowledge may be helpful to our method, we also attempt to introduce the
pre-trained language model [denk2019bertgrid](None) into the
framework with a knowledge absorption module for further improving the
information extraction performance. (3) We address the problem of
performance comparison in existing methods, and then define the four
categories of VRDs. To promote the document understanding area, we
recommend the corresponding benchmarks, experimental settings, and
strong baselines for each kind of document. (4) We explore the effects
of the proposed framework with more extensive experimental evaluations ,
which demonstrates its advantages.
[^1]: Note that, terms of ‘position’ and ‘layout’ are two different but
highly relevant concepts. The former refers to the specific
coordinate locations of candidate text regions generated by text
reading module. The later means the abstract spatial information
(position arrangement of text regions) derived from the generated
position results via some embedding operations. Thus, layout can be
treated as the high-level of spatial information in document
understanding. In the follow-up, we use term ‘layout’ instead of
term ‘position’ as one kind of modality.
[^2]: Another text type, the unstructured, is also defined in
[judd2004apparatus](http://arxiv.org/pdf/2305.19912v1), which means that document
content is grammatically free text without explicit identifiers such
as books. Since such documents usually lack visually rich elements
(layout), we exclude it from the concept of VRD.
# Related Works [related_work]
Thanks to the rapid expansion of artificial intelligence techniques
[zhuang2020next](None), advanced progress has been made in many
isolated applications such as document layout analysis
[esser2012automatic](http://arxiv.org/pdf/2312.02941v1), [xu2019layoutlm](http://arxiv.org/pdf/2205.00476v2), scene text spotting
[liu2018fots](None), [Qiao2020MANGOAM](None), video understanding
[xu2019segregated](None), named entities identification
[yadav2019survey](None), question answering
[duan2018temporality](http://arxiv.org/pdf/2103.12876v1), or even causal inference
[kuang2020causal](http://arxiv.org/pdf/acc-phys/9411001v1) etc. However, it is crucial to build
multiple knowledge representations for understanding the complex and
challenging world. VRD is such a real task greatly helping office
automation, which relies on integrating multiple techniques, including
object detection, sequence learning, information extraction and even the
multi-modal knowledge representation. Here, we roughly brief techniques
as follows.
## Text Reading
Text reading belongs to the OCR research field and has been widely
studied for decades. A text reading system usually consists of two
parts: text detection and text recognition.
In *text detection*, methods are usually divided into two categories:
anchor-based methods and segmentation-based methods. Following Faster
R-CNN [RenHG017](None), anchor-based
methods [he2017single](None), [liao2017textboxes](None), [liao2018textboxes++](None), [liao2018rotation](None), [ma2018arbitrary](None), [liu2017deep](None), [shi2017detecting](None), [Rosetta18Borisyuk](None)
predicted the existence of texts and regress their location offsets at
pre-defined grid points of the input image. To localize arbitrary-shaped
text, Mask RCNN [HeGDG17mask](None)-based methods
[xie2018scene](None), [Zhang2019look](None), [liu2019Towards](None) were
developed to capture irregular text and achieve better performance.
Compared to anchor-based methods, segmentation can easily be used to
describe the arbitrary-shaped text. Therefore, many segmentation-based
methods [zhou2017east](None), [long2018textsnake](None), [Wang2019Shape](None), [xu2019textfield](None)
were developed to learn the pixel-level classification tasks to separate
text regions apart from the background. In *text recognition*, the
encoder-decoder architecture
[CRNN](None), [shi2018aster](None), [cheng2017focusing](None) dominates the
research field, including two mainstreaming routes:
CTC[Graves2006](None)-based
[shi2016end](None), [Rosetta18Borisyuk](None), [wang2017gated](None), [R2AM](None) and
attention-based
[cheng2017focusing](None), [shi2018aster](None), [cheng2018aon](None) methods. To
achieve the global optimization between detection and recognition, many
end-to-end trainable
methods [liu2018fots](None), [li2017towards](None), [he2018end](None), [busta2017deep](None), [wang2020all](None), [qiao2020textperceptron](None), [feng2019textdragon](None), [MaskTextspotter18Lyu](None), [Qiao2020MANGOAM](None)
were proposed, and achieved better results than the pipeline approaches.
## Information Extraction
Information extraction is a traditional research topic and has been
studied for many years. Here, we divide existing methods into two
categories as follows.
### Rule-based Methods
Before the advent of learning-based models, rule-based
methods[riloff1993automatically](None), [huffman1995learning](http://arxiv.org/pdf/1904.02634v1), [muslea1999extraction](None), [dengel2002smartfix](None), [schuster2013intellix](None), [esser2012automatic](http://arxiv.org/pdf/2312.02941v1)
dominated this research area. It is intuitive that the key information
can be identified by matching a predefined pattern or template in the
unstructured text. Therefore, expressive pattern matching languages
[riloff1993automatically](None), [huffman1995learning](http://arxiv.org/pdf/1904.02634v1) were
developed to analyze syntactic sentence, and then output one or multiple
target values.
To extract information from general documents such as business
documents, many solutions
[dengel2002smartfix](None), [schuster2013intellix](None), [Rusiol2013FieldEF](None), [esser2012automatic](http://arxiv.org/pdf/2312.02941v1), [Medvet2010APA](http://arxiv.org/pdf/2005.01646v1)
were developed by using the pattern matching approaches. In detail,
[schuster2013intellix](None), [Rusiol2013FieldEF](None), [Cesarini2003AnalysisAU](http://arxiv.org/pdf/2311.11856v1)
required a predefined document template with relevant key fields
annotated, and then automatically generated patterns matching those
fields.
[dengel2002smartfix](None), [esser2012automatic](http://arxiv.org/pdf/2312.02941v1), [Medvet2010APA](http://arxiv.org/pdf/2005.01646v1) all
manually configured patterns based on keywords, parsing rules or
positions. The rule-based methods heavily rely on the predefined
template, and are limited to the documents with unseen templates. As a
result, it usually requires deep expertise and a large time cost to
conduct the templates’ design and maintenance.
### Learning-based Methods
Learning-based methods can automatically extract key information by
applying machine learning techniques to a prepared training dataset.
Traditionally machine learning techniques like logistic regression and
SVM were widely adopted in document analysis tasks.
[Shilman2005LearningNG](http://arxiv.org/pdf/2304.01746v1) proposed a general machine
learning approach for the hierarchical segmentation and labeling of
document layout structures. This approach modeled document layout as
grammar and performed a global search for the optimal parse based on a
grammatical cost function. This method utilized machine learning to
discriminatively select features and set all parameters in the parsing
process.
The early methods often ignore the layout information in the document,
and then the document understanding task is downgraded to the pure NLP
problem. That is, many named entity recognition (NER) based methods
[lample2016neural](None), [ma2019end](None), [yadav2019survey](None), [devlin2018bert](None), [dai2019transformer](None), [yang2019xlnet](None)
can be applied to extract key information from the one-dimensional plain
text. Inspired by this idea, [palm2017cloudscan](None)
proposed CloudScan, an invoice analysis system, which used recurrent
neural networks to extract entities of interest from VRDs instead of
templates of invoice layout. [sage2019recurrent](None)
proposed a token level recurrent neural network for end-to-end table
field extraction that starts with the sequence of document tokens
segmented by an OCR engine and directly tags each token with one of the
possible field types. However, they discard the layout information
during the text serialization, which is crucial for document
understanding.
Observing the rich layout and visual information contained in document
images, researchers tended to incorporate more details from VRDs. Some
works
[katti2018chargrid](None), [denk2019bertgrid](None), [zhao2019cutie](None), [palm2019attend](None), [wang2021tag](None)
took the layout into consideration, and worked on the reconstructed
character or word segmentation of the document. Concretely,
[katti2018chargrid](None) first achieved a new type of text
representation by encoding each document page as a two-dimensional grid
of characters. Then they developed a generic document understanding
pipeline named Chargrid for structured documents by a fully
convolutional encoder-decoder network. As an extension of Chargrid,
[denk2019bertgrid](None) proposed Bertgrid in combination with
a fully convolutional network on a semantic instance segmentation task
for extracting fields from invoices. To further explore the effective
information from both semantic meaning and spatial distribution of texts
in documents, [zhao2019cutie](None) proposed a convolutional
universal text information extractor by applying convolutional neural
networks on gridding texts where texts are embedded as features with
semantic connotations. [palm2019attend](None) proposed the
attend, copy, parse architecture, an end-to-end trainable model
bypassing the need for word-level labels. [wang2021tag](None)
proposed a tag, copy or predict network by first modelling the semantic
and layout information in 2D OCR results, and then learning the
information extraction in a weakly supervised manner. Contemporaneous
with the above-mentioned methods, there are methods
[liu2019graph](None), [MajumderPTWZN20](None), [sun2021spatial](None), [xu2019layoutlm](http://arxiv.org/pdf/2205.00476v2), [Xu2020LayoutLMv2MP](None), [li2021structurallm](None), [li2021structext](None)
which resort to graph modeling to learn relations between multimodal
inputs. [liu2019graph](None) introduced a graph
convolution-based model to combine textual and layout information
presented in VRDs, in which graph embedding was trained to summarize the
context of a text segment in the document, and further combined with
text embedding for entity extraction. [MajumderPTWZN20](None)
presented a representation learning approach to extract structured
information from templatic documents, which worked in the pipeline of
candidate generation, scoring and assignment.
[sun2021spatial](None) modelled document images as
dual-modality graphs by encoding both textual and visual features, then
generated key information with the proposed Spatial Dual-Modality Graph
Reasoning method (SDMG-R). Besides, they also released a new dataset
named WildReceipt.
## End-to-End Information Extraction from VRDs
Two related concurrent works were presented
in [qin2019eaten](None), [carbonell2019treynet](None).
[qin2019eaten](None) proposed an entity-aware attention text
extraction network to extract entities from VRDs. However, it could only
process documents of relatively fixed layout and structured text, like
train tickets, passports and business cards.
[carbonell2019treynet](None) localized, recognized and
classified each word in the document. Since it worked in the word
granularity, it required much more labeling efforts (layouts, content
and category of each word) and had difficulties extracting those
entities which were embedded in word texts (extracting ‘51xxxx@xxx.com’
from ‘153-xxx97$|$``{=html}51xxxx@xxx.com’). Besides, in its
entity recognition branch, it still worked on the serialized word
features, which were sorted and packed in the left to right and top to
bottom order. The two existing works are strictly limited to documents
of relatively fixed layout and one type of text (structured or
semi-structured). Similar to the conference version
[zhang2020trie](None) of our method,
[wang2021towards](None) recently proposed an end-to-end
framework accompanied by a Chinese examination paper head dataset.
Unlike them, our method acts as a general , and can handle documents of
both fixed and variable layouts, structured and semi-structured text
types.
# Methodology
The overall framework. The network predicts text locations,
text contents and key entities in a single forward pass.
This section introduces the proposed framework, which has three parts:
text reading, multi-modal context block and information extraction
module, as shown in
Figure 1.
## Text Reading
Text reading module commonly includes a shared convolutional backbone, a
text detection branch as well as a text recognition branch. We use
ResNet-D [he2019bag](http://arxiv.org/pdf/2001.03992v1) and Feature Pyramid Network (FPN)
[LinDGHHB17feature](None) as our backbone to extract the shared
convolutional features. For an input image $x$, we denote $\mathcal{I}$
as the shared feature maps.
**Text detection**. The branch takes $\mathcal{I}$ as input and predicts
the locations of all candidate text regions, i.e., $$\label{equa1}
\mathcal{B}=\textit{Detector}(\mathcal{I})$$ where the
$\textit{Detector}$ can be the
anchor-based [he2017single](None), [liao2017textboxes](None), [liu2017deep](None), [shi2017detecting](None)
or segmentation-based
[zhou2017east](None), [long2018textsnake](None), [Wang2019Shape](None) text
detection heads. $\mathcal{B}=(b_1, b_2,\dots, b_m)$ is a set of $m$
text bounding boxes, and $b_i=(x_{i0}, y_{i0},$ $x_{i1}, y_{i1})$
denotes the top-left and bottom-right positions of the $i$-th text. In
mainstream methods, RoI-like operations (*e.g.*, RoI-Pooling
[RenHG017](None) used in [li2017towards](None),
ROI-Align [HeGDG17mask](None) used in
[he2018end](None), RoI-Rotate used in
[liu2018fots](None), or even RoI-based arbitrary-shaped
transformation [qiao2020textperceptron](None), [wang2020all](None)) are
applied on the shared convolutional features $\mathcal{I}$ to get their
text instance features. Here, the text instance features are denoted as
$\mathcal{C}=(c_1, c_2,\dots, c_m)$. The detailed network architecture
is shown in Section [sec-impl].
**Text recognition**. The branch predicts a character sequence from each
text region features $c_i$. Firstly, each instance feature $c_i$ is fed
into an encoder (CNN and LSTM [LSTM](None)) to extract a
higher-level feature sequence $\mathcal{H}=(h_1, h_2, \dots, h_l)$,
where $l$ is the length of the extracted feature sequence. Then, a
general sequence decoder (attention-based
[shi2016end](None), [cheng2017focusing](None)) is adopted to generate
the sequence of characters $y=(y_1, y_2,\dots, y_T)$, where $T$ is the
length of label sequence. Details are shown in Section
[sec-impl].
We choose attention-based sequence decoder as the character recognizer.
It is a recurrent neural network that directly generates the character
sequence $y$ from an input feature sequence $\mathcal{H}$.
## Multi-modal Context Block
We design a multi-modal context block to consider layout features,
visual features and textual features altogether. Different modalities of
information are complementary to each other, and fully fused for
providing robust multi-modal feature representation.
### Multi-modal Feature Generation
Document details such as the apparent color, font, layout and other
informative features also play an important role in document
understanding.
A natural way of capturing the layout and visual features of a text is
to resort to the convolutional neural network. Concretely, the position
information of each text instance is obtained from the detection branch,
i.e., $\mathcal{B}=(b_1, b_2,\dots, b_m)$. For visual feature, different
from [xu2019layoutlm](http://arxiv.org/pdf/2205.00476v2), [Xu2020LayoutLMv2MP](None) which extract
these features from scratch, we directly reuse text instance features
$\mathcal{C}=(c_1, c_2, \dots, c_m)$ by text reading module as the
visual features. Thanks to the deep backbone and lateral connections
introduced by FPN, each $c_i$ summarizes the rich local visual patterns
of the $i$-th text.
In sequence decoder, give the $i$-th text instance, its represented
feature of characters before softmax contain rich semantic information.
For the attention-based decoder, we can directly use
$z_i=(s_1, s_2, \dots, s_T)$ as its textual features.
### Prior Knowledge Absorption
Since pre-trained language model contains general language knowledge
like semantic properties, absorbing knowledge from the language model
may help improve the performance of information extraction. Compared to
the conference paper [zhang2020trie](None), we here attempt to
bring the language model into our framework. However, prior language
information has different contributions on different VRDs. For example,
on Resume scenario that require semantics, prior language information
contributes more, while on Taxi scenario which requires less semantics,
prior language information contributes less. Inspired by the gating
operation in LSTM [LSTM](None), we design a gated knowledge
absorption mechanism to adjust the prior knowledge flows in our
framework, as shown in Figure
2.
In order to dynamically determine the degree of dependency of the
pre-trained model, we use an on-off gate $g^\prime$
$$g^\prime = \sigma(W_{g^\prime}a + U_{g^\prime}z + b_{g^\prime})$$ to
balance the flow of the prior knowledge activation $r^\prime$
$$r^\prime = \delta(W_{r^\prime}a + U_{r^\prime}z + b_{r^\prime}).$$
Here, the gate is used for determining whether general knowledge is
needed. Then the modulated textual feature $o$ is calculated as
$$\label{gating}
o = g^\prime \odot r^\prime + W_oz.$$
### Multi-modal Context Modelling
We first embed each modality information into feature sequences with the
same dimension, and fuse them with a normalization layer. Inspired by
the powerful Transformer
[devlin2018bert](None), [VisualBERTLi](None), [Lu2019ViLBERT](None), [Xu2020LayoutLMv2MP](None),
the self-attention mechanism is used to build deep relations among
different modalities,
**Multi-modal Feature Embedding** Given a document with $m$ text
instance, we can capture the inputs of position
$\mathcal{B}=(b_1,b_2,\dots,b_m)$, the inputs of visual feature
$\mathcal{C}=(c_1,c_2,\dots,c_m)$ and the inputs of modulated textual
feature $o=(o_1,o_2,\dots,o_m)$.
Since position information provides layout information of documents, we
introduce a position embedding layer to preserve layout information, for
the $i$-th text instance in a document,
$$pe_i=\sum_{j=1}^{|b_i|} embedding(b_{ij}),$$ where $embedding$ is a
learnable embedding layer, $b_i=(x_{i0},y_{i0},x_{i1},y_{i1})$ and
$pe_i\in \mathbb{R}^{d_e}$.
For $c_i$ visual feature, we embed it using a convolutional neural
network layer with the same shape of $pe_i$,
$$\widehat{c_i}=ConvNet_c(c_i).$$
For $o_i$ textual feature, a $ConvNet$ of multiple kernels similar
to [zhang2015character](None) is used to aggregate semantic
character features in $o_i$ and outputs
$\widehat{z_i}\in\mathbb{R}^{d_e}$, $$\widehat{z_i}=ConvNet_z(o_i).
\label{eq:textual}$$
Then, the $i$-th text’s embedding is fused of $\widehat{c_i}$,
$\widehat{z_i}$ and $pe_{i}$, followed by the $LayerNorm$ normalization,
defined as $$emb_i=LayerNorm(\widehat{c_i} + \widehat{z_i} + pe_i).$$
Afterwards, we pack all the texts’ embedding vector together, i.e.,
$emb=(emb_1, emb_2, \dots, emb_m)$, which serves as the $K$, $Q$ and $V$
in the scaled dot-product attention.
**Spatial-Aware Self-Attention** To better learn pair-wise interactions
between text instances, we use the spatial-aware self-attention
mechanism instead of the original self-attention, and the correlative
context features
$\widetilde{\mathcal{C}}=(\widetilde{c_1}, \widetilde{c_2}, \dots, \widetilde{c_m})$
are obtained by, $$\begin{split}
\widetilde{\mathcal{C}}&=Attention(Q,K,V) \\
&=softmax(\frac{QK^\mathsf{T}}{\sqrt{d_{info}}}+pe_{\Delta \mathcal{B}})V
\end{split}$$ where $d_{info}$ is the dimension of text embedding, and
$\sqrt{d_{info}}$ is the scaling factor. $pe_{\Delta \mathcal{B}}$
refers to the spatial-aware information, and is calculated by embedding
features of position relations ${\Delta \mathcal{B}}$ among different
text instances in $\mathcal{B}$, i.e.,
$pe_{\Delta \mathcal{B}}= embedding({\Delta \mathcal{B}})$. Here,
${\Delta \mathcal{B}}$ is defined as $$\Delta \mathcal{B} =
\left[
\begin{array}{cccc}
0 & b_1-b_2 & \cdots & b_1-b_m\\
b_2-b_1 & 0 & \cdots & b_2-b_m\\
\cdots & \cdots & \cdots &\cdots \\
b_m-b_1 & b_m-b_2 & \cdots & 0
\end{array}
\right].$$ To further improve the representation capacity of the
attended feature, multi-head attention is introduced. Each head
corresponds to an independent scaled dot-product attention function and
the text context features $\widetilde{\mathcal{C}}$ is given by:
$$\begin{split}
\widetilde{\mathcal{C}}&=MultiHead(Q,K,V)\\
&=[head_1, head_2, ..., head_n]W^{info}
\end{split}$$ $$head_j=Attention(QW_j^Q, KW_j^K, VW_j^V)$$ where
$W^Q_j$, $W^K_j$ and $W^V_j$ $\in \mathbb{R}^{(d_{info}\times d_n)}$ are
the learned projection matrix for the $j$-th head, $n$ is the number of
heads, and $W^{info}\in \mathbb{R}^{(d_{info} \times d_{info})}$. To
prevent the multi-head attention model from becoming too large, we
usually have $d_n = \frac{d_{info}}{n}$.
**Context Fusion** Both the multi-modal context and textual features
matter in entity extraction. The multi-modal context features
($\widetilde{\mathcal{C}}$) provide necessary information to tell
entities apart while the textual features $o$ enable entity extraction
in the character granularity, as they contain semantic features for each
character in the text. Thus, we need to fuse them further. That is, for
the $i$-the text instance, we pack its multi-modal context vector
$\widetilde{c_i}$ and its modulated textual features $o_i$ together
along the channel dimension, i.e., $(u_{i1}, u_{i2},\dots, u_{iT})$
where $u_{ij}=[o_{i,j}, c_i]$.
## Information Extraction [ie]
Then, a Bidirectional-LSTM is applied to further model the long
dependencies within the characters,
$$H_{i}^\prime=(h_{i,1}^\prime, h_{i,2}^\prime, \dots, h_{i,T}^\prime) = BiLSTM(u_i),$$
which is followed by a fully connected network and a layer, projecting
the output to the dimension of [SangV99representing](None)
label space. $$p_{i,j}^{info} = CRF(Linear(h_{i,j}^\prime))$$
## Optimization [sec3.5]
The proposed network can be trained in an end-to-end manner and the
losses are generated from three parts, $$\label{losses}
\mathcal{L}=\mathcal{L}_{det} + \lambda_{recog}\mathcal{L}_{recog} + \lambda_{info}\mathcal{L}_{info}$$
where hyper-parameters $\lambda_{recog}$ and $\lambda_{info}$ control
the trade-off between losses.
$\mathcal{L}_{det}$ is the loss of text detection branch, which can be
formulated as different forms according to the selected detection heads.
Taking Faster-RCNN [RenHG017](None) as the detection head, the
detection part consists of a classification loss and a regression loss.
For sequence recognition part, the attention-based recognition loss is
$$\mathcal{L}_{recog}=-\frac{1}{T}\sum_{i=1}^{m}\sum_{t=1}^{T}log\ p(\hat{y}_{i,t}|\mathcal{H}),$$
where $\hat{y}_{i,t}$ is the ground-truth label of $t$-th character in
$i$-th text from recognition branch.
The information extraction loss is the CRFLoss, as used
in [lample2016neural](None), [wang2021towards](None).
Note that since *text reading* and *information extraction* modules are
bridged with the multi-modal context block, they can reinforce each
other. Specifically, the multi-modality features of text reading are
fully fused and essential for information extraction. At the same time,
the semantic feedback of information extraction also contributes to the
optimization of the shared convolutions and text reading module.
# Benchmarks [benchmark]
As addressed in Section 1, most existing works verify their methods on
private datasets due to their privacy policies. It leads to difficulties
for fair comparisons between different approaches. Though existing
datasets like SROIE [HuangCHBKLJ19competition](None) have been
released, they mainly fall into Category III, i.e., documents with
variable layout and structured text type. The remaining three kinds of
application scenarios (Category I, II and IV) have not been studied well
because of the limited real-life datasets.
## Dataset inventory
To boost the research of VRD understanding, we here extend the
benchmarks of VRD, especially on Category I, II and IV. Table
[table:datasets] shows the detailed
statistics of these benchmarks.
- *Category I* refers to document images with uniform layout and
structured text type, which is very common in everyday life.
Contrastively, its research datasets are very limited due to various
privacy policies. Here, we find only two available benchmarks, i.e.,
train ticket and passport dataset released by
[qin2019eaten](None), which are generated with a synthetic
data engine and provide only entity-level annotations. To remedy
this issue, we release a new real-world dataset containing 5000 taxi
invoice images. Except for providing the text position and character
string information for OCR tasks (text detection and recognition),
entity-level labels including 9 entities (Invoice code, Invoice
number, Date, Get-on time, Get-off time, Price, Distance, Wait time,
Total) are also provided. Besides, this dataset is very challenging,
as many images are in low-quality (such as blur and occlusion).
- *Category II* refers to those documents with fixed layout and
semi-structured text type, like business email or national housing
contract. NER datasets like CLUENER2020
[xu2020cluener2020](None) are only collected for NLP tasks,
and they provide only semantic content while ignoring the important
layout information. As addressed in Section
[sec:introduction], the joint
study of OCR and IE is essential. Unfortunately, we have not found
available datasets that contains both OCR and IE annotations. We
also ascribe the issue to various privacy policies. We here collect
a new business email dataset from RVL-CDIP
[Harley2015EvaluationOD](http://arxiv.org/pdf/1502.07058v1), which has 1645 email images
with 35346 text instances and 15 entities (To, From, CC, Subject,
BCC, Text, Attachment, Date, To-key, From-key, CC-key, Subject-key,
BCC-key, Attachment-key, Date-key).
- *Category III* means documents which are with variable layout and
structured text type like purchase receipt dataset SROIE
[HuangCHBKLJ19competition](None). These datasets are
usually composed of small documents (*e.g.*, purchase receipts,
business cards, etc.), and entities are organized in a predetermined
schema. We note that most previous literature focus on this
category. We here list five available datasets. SROIE is a scanned
receipt dataset widely evaluated in many methods, which is fully
annotated and provides text position, character string and key-value
labels. Business card is a synthesized dataset released by
[qin2019eaten](None), and has only key-value pair
annotations without OCR annotations. FUNSD
[Jaume2019FUNSDAD](None) is a dataset aiming at extracting
and structuring the textual content from noisy scanned forms. It has
only 199 forms with four kinds of entities, i.e., question, answer,
header and other. CORD$^2$ [Park2019CORDAC](None) is a
consolidated receipt dataset, in which images are with text
position, character string and multi-level semantic labels. EPHOIE
[wang2021towards](None) is a Chinese examination paper head
dataset, in which each image is cropped from the full examination
paper. This dataset contains handwritten information, and is also
fully annotated. WildReceipt [sun2021spatial](None) is a
large receipt dataset collected from document images of unseen
templates in the wild. It contains 25 key information categories, a
total of about 69000 text boxes.
- *Category IV* means documents that have variable layout and
semi-structured text type. Different from those datasets in Category
III, Kleister-NDA[Gralinski2020KleisterAN](None) aims to
understand long documents (i.e., Non-disclosure Agreements
document), but it provides only 540 documents with four general
entity classes. To enrich benchmarks in this category, we release a
large-scale resume dataset, which has 1527 images with ten kinds of
entities(Name, Time, School, Degree, Specialty, Phone number,
E-mail, Birth, Title, Security code). Since resumes are personally
designed and customized, it is a classic document dataset with
variable layouts and semi-structured text.
## Challenges in different kinds of documents
It will be the most straightforward task to extract entities from
documents in Category I, which attributes to its complete fixed layout
and structured text type. For this kind of documents, challenges are
mainly from the text reading part, such as the distorted interference.
The standard object detection methods like Faster-RCNN
[RenHG017](None) also can be further developed to handle this
task. In Category II, the layout is fixed, but the text is
semi-structured. Thus, in addition to modelling layout information, we
also should pay attention to mining textual information. Then some NLP
techniques like the pre-trained language model can be exploited. As to
the text reading part, long text recognition is also challenging.
Documents in Category III face the problem of complex layout. Thus the
layout modelling methods [liu2019graph](None), [PICK2020YU](None) like
graph neural networks are widely developed for coping with this issue.
The documents in Category IV are in the face of both complex layout and
NLP problems, which becomes the most challenging task.
# Experiments [experiment]
In subsection 1.1, we first introduce the implementation
details of network and training skills. In subsection
1.2, we perform ablation study to verify
the effectiveness of the proposed method on four kinds of VRD datasets,
i.e., Taxi Invoice, Business Email, WildReceipt and Resume. In
subsection
1.3,
we compare our method with existing approaches on several recent
datasets like FUNSD, SROIE, EPHOIE and WildReceipt, demonstrating the
advantages of the proposed method. Then, we provide a group of strong
baselines on four kinds of VRDs in subsection
1.4. Finally, we discuss the challenges of
the different categories of documents. Codes and models are available at
*https://davar-lab.github.io/publication/trie++.html*.
## Implementation Details [sec-impl]
### Data Selecting
To facilitate end-to-end document understanding (*text reading* and
*information extraction*), datasets should have position, text and
entity annotations. Hence, we only consider those datasets which satisfy
the above requirement. On the ablation and strong baseline experiments,
we select one classic dataset from each category, which has the largest
number of samples. They are Taxi Invoice dataset from Category I,
Business Email dataset from Category II, WildReceipt dataset from
Category III and Resume dataset from Category IV. When compared with the
state-of-the-arts, since they mainly report their results on popular
SROIE, FUNSD and EPHOIE benchmarks, we also include these benchmarks in
Section 1.3.
### Network Details
The backbone of our model is ResNet-D [he2019bag](http://arxiv.org/pdf/2001.03992v1),
followed by the FPN [LinDGHHB17feature](None) to further
enhance features. The text detection branch in *text reading module*
adopts the Faster R-CNN [RenHG017](None) network and outputs
the predicted bounding boxes of possible texts for later sequential
recognition. For each text region, its features are extracted from the
shared convolutional features by RoIAlign [HeGDG17mask](None).
The shapes are represented as $32\times256$ for Taxi Invoice and
WildReceipt, and $32\times512$ for Business Email and Resume. Then,
features are further decoded by LSTM-based attention
[cheng2017focusing](None), where the number of hidden units is
set to 256.
In the *multimodal context block*, BERT [devlin2018bert](None)
is used as the pre-trained language model. Then, convolutions of four
kernel size $[3, 5, 7, 9]$ followed by max pooling are used to extract
final textual features.
In the *information extraction module*, the number of hidden units of
BiLSTM used in entity extraction is set to 128. Hyper-parameters
$\lambda_{recog}$ and $\lambda_{info}$ in Equation
[losses] are all empirically set to 1 in our
experiments.
### Training Details
Our model and its counterparts are implemented under the PyTorch
framework [paszke2019pytorch](None). For our model, the AdamW
[loshchilov2017decoupled](http://arxiv.org/pdf/2311.11446v2) optimization is used. We set
the learning rate to 1e-4 at the beginning and decreased it to a tenth
at 50, 70 and 80 epochs. The batch size is set to 2 per GPU. For the
counterparts, we separately train text reading and information
extraction tasks until they are fully converged. All the experiments are
carried out on a workstation with 8 NVIDIA A100 GPUs.
### Evaluation Protocols [protocals]
We also note that different evaluation protocols are adopted in previous
works. For example in the evaluation of information extraction part,
both EATEN [qin2019eaten](None) and PICK
[PICK2020YU](None) used the defined mean entity accuracy (mEA)
and mean entity f1-score (mEF) as metrics. CUTIE
[zhao2019cutie](None) adopted the average precision (AP) as the
metric, and Chargrid [katti2018chargrid](None) developed new
evaluation metric like word error rate for evaluation. While the
majority of methods
[zhang2020trie](None), [Gralinski2020KleisterAN](None), [xu2019layoutlm](http://arxiv.org/pdf/2205.00476v2)
used the F1-score as the evaluation metric. As a result, the non-uniform
evaluation protocols bring extra difficulties on comparisons. Therefore,
we attempt to describe a group of uniform evaluation protocols for VRD
understanding by carefully analyzing previous methods, including the
evaluation protocols of text reading and information extraction parts.
Text reading falls into the OCR community, and it has uniform evaluation
standards by referring to mainstream text detection
[liao2017textboxes](None), [liu2019Towards](None), [liu2018fots](None) and text
recognition [CRNN](None), [shi2018aster](None), [cheng2017focusing](None)
methods. *precision* (*abbr*. PRE$_d$) and *recall* (*abbr*. REC$_d$)
are used to measure performance of text localization, and *F-measure*
(*abbr*. F$_d$-m) is the harmonic average of *precision* and *recall*.
To evaluate text recognition, the *accuracy* (abbr. ACC) used in
[CRNN](None), [shi2018aster](None), [cheng2017focusing](None) is treat as its
measurement metric. When evaluating the performance of end-to-end text
detection and recognition, the end-to-end level evaluating metrics like
precision (denoted by PRE$_r$), recall (denoted by REC$_r$) and
F-measure (denoted by F$_r$-m) following [2011End](None)
without lexicon is used, in which all detection results are considered
with an IoU$>$``{=html}0.5.
For information extraction, we survey the evaluation metrics from recent
research works
[zhang2020trie](None), [Gralinski2020KleisterAN](None), [xu2019layoutlm](http://arxiv.org/pdf/2205.00476v2), [Jaume2019FUNSDAD](None), [liu2019graph](None), [wang2021towards](None), [Xu2020LayoutLMv2MP](None),
and find that the precision, recall and F1-score of entity extraction
are widely used. Hereby, we recommend the *entity precision* (abbr.
ePRE), *entity recall* (abbr. eREC) and *entity F1-score* (eF1) as the
evaluation metrics for this task.
## Ablation Study [ablation]
In this section, we perform the ablation study on Taxi Invoice, Business
Email, WildReceipt and Resume datasets to verify the effects of
different components in the proposed framework.
### Effects of multi-modality features [forward_effect]
To examine the contributions of visual, layout and textual features to
information extraction, we perform the following ablation study on four
kinds of datasets, and the results are shown in
Table 1. *Textual feature*
means that entities are extracted using features from the text reading
module only. Since the layout information is completely lost, this
method presents the worst performance. Introducing either the *visual
features* or *layout features* brings significant performance gains.
Further fusion of the above multi-modality features gives the best
performance, which verifies the effects. We also show examples in
Figure. [fig:modality_contribution]
to verify their effects. By using the *textual feature* only, the model
misses the ‘Store-Name’ and has confusion between ‘Total’ and
‘Product-Price’ entities. Combined with the *layout feature*, the model
can recognize ‘Product-Price’ correctly. When combined with the *visual
feature*, the model can recognize Store-Name, because the *visual
feature* contains obvious visual clues such as the large font size. It
shows the best result by integrating all modality features.
### Effects of different components
From Table [table:components], we see that
SaSa can boost performance, especially on the WildReceipt. This is
because, compared to the original self-attention using entities’
absolute positions only, the spatial-aware self-attention also makes use
of relative position offsets between entities, and learns their pairwise
relations. Visual examples are shown in
Figure. 1. We see that ‘Product-Item’ and
‘Product-Price’ always appear in pairs. Spatial-aware self-attention can
capture such pairwise relations and then improve model performances. Its
attention map is visualized in
Figure. 2, which demonstrates that the
spatial-aware self-attention indeed learns the pairwise relations
between entities (pair of ‘Total-Key’ and ‘Total-Value’, and pair of
‘Product-Item’ and ‘Product-Price’).
When introducing the prior knowledge from Bert
[devlin2018bert](None), the performance of information
extraction is significantly improved on the scenarios that require
semantics like WildReceipt, Business Email and Resume. As shown in
Figure 4, in the Resume case, introducing
the pre-trained language model helps recognize ‘School’ and ‘Specialty’
entities, which are hard to be extracted solely using textual features.
### Effects of different number of layers and heads
Table 3 analyzes
the effects of different numbers of layers and heads in the
spatial-aware self-attention. Taxi Invoices is relatively simple and has
a fixed layout. Thus the model with 1 or 2 layers and the small number
of heads achieves promising results. For scenes with complex layout
structures like Resumes and WildReceipt, deeper layers and heads can
help improve the accuracy results. In practice, one can adjust these
settings according to the complexity of a task.
### Effects of the end-to-end training
To verify the effects of the end-to-end framework on text reading and
information extraction, we perform the following experiments on four
kinds of VRD datasets. We first define two strong baselines for
comparison. (1) *Base1*. The detection, recognition and information
extraction modules are separately trained, and then pipelined as an
inference model. (2) *Base2*. The detection and recognition tasks are
jointly optimized, and then pipelined with the separately trained
information extraction task. While joint training of the three modules
is denoted as our *end-to-end* framework. Notice that all multi-modal
features (See Section
1.2.1) are integrated. The layer and
head numbers in self-attention are set as (2, 2, 4, 2) and (32, 32, 16,
32) for four different tasks (Taxi Invoice, Business Email, WildReceipt,
Resume in order), respectively.
## Comparisons with the State-of-the-Arts [sota]
Recent methods
[xu2019layoutlm](http://arxiv.org/pdf/2205.00476v2), [Xu2020LayoutLMv2MP](None), [li2021structurallm](None), [li2021structext](None)
focused on the information extraction task by adding great number of
extra training samples like IIT-CDIP dataset
[Lewis2006BuildingAT](http://arxiv.org/pdf/2305.06148v1) and
DocBank [li2020docbank](http://arxiv.org/pdf/2006.01038v3), and then have impressive results
on the downstream datasets. Following the typical routine, we also
compare our method with them on several popular benchmarks.
**Evaluation on FUNSD** The dataset is a noisy scanned from the dataset
with 200 images. The results are shown in FUNSD column of
Table [table:sotas]. To be fair, we first
compare our method with those without introducing extra data. Our method
significantly outperforms them with a large margin (83.53 *v.s.* 81.33
of MatchVIE[tang2021matchvie](None)). When comparing with
models trained with extra data, our method is still competitive. It only
falls behind the LLMv2[Xu2020LayoutLMv2MP](None) and
SLM[li2021structurallm](None).
**Evaluation on SROIE** The dataset has 963 scanned receipt images,
which is evaluated on four entities in many works. Most of the results
are impressive, as shown in SROIE column of
Table [table:sotas]. This is because methods
tend to achieve the performance upper bound of this dataset. For
example, StrucText [li2021structext](None) (with extra data)
has achieved 96.88 of *eF1*, which only has slight advantage over 96.57
of MatchVIE[tang2021matchvie](None). Our method shows promising
results on this benchmark, with 96.80 $eF1$ in the token granularity
(same to most
works [PICK2020YU](None), [wang2021tag](None), [wang2021towards](None), [tang2021matchvie](None), [xu2019layoutlm](http://arxiv.org/pdf/2205.00476v2), [Xu2020LayoutLMv2MP](None), [zhang2020trie](None))
and 98.37 in the segment granularity (same to
StrucText [li2021structext](None)).
**Evaluation on EPHOIE** The dataset is a Chinese examination paper head
dataset. Our method obviously surpasses previous methods Similar to
SROIE, its performance upper bound is limited. That is, only 1.15% of
improvement space is left.
**Evaluation on WildReceipt** This receipt dataset
[sun2021spatial](None) is more challenging than SROIE, which is
collected from document images with unseen templates in the wild. Most
of the methods like GAT[velivckovic2018graph](None) have rapid
performance degradation compared to results in SROIE and EPHOIE. While
our method still has the best result (90.15% of *eF1*) compared to
existing methods , which verifies the advantages of the proposed method.
## Strong Baselines on Four Categories of VRD [baseline]
For the pure information extraction task, their results (as shown in
Table [table:sotas]) are calculated based on
the ground truth of detection and recognition. However, the influence of
OCR should not be neglected in reality. Considering the real
applications, i.e., , one way is to divide the task as two pipelined
steps: (1) obtaining text spotting results with a public OCR engines,
(2) and then performing the information extraction. We here provide on
four kinds of VRDs.
### Comparison of Inference Speed
We evaluate the running time of our model and its counterparts in frames
per second (*abbr*. FPS). Results are as shown in the last column of
Table [table:baseline]. Thanks to feature
sharing between *text reading* and *information extraction* modules, A
more prominent trend is that the algorithm runs faster in scenarios
where the length of texts is short in a document (Taxi Invoice and
WildReceipt), while on Resume/Business Email datasets with long texts,
the FPS drops slightly.
### Evaluations among Different Modules
In the detection part, all methods achieve the satisfactory performance
of *F$_d$-m* (larger than 90%), while the performance on WildReceipt is
the lowest. This is because the receipt images in WildReceipt are
captured in the wild, and they are of non-front views, even with folds.
When considering the end-to-end text spotting task, results on Business
and Resume are poor due to the problems of character distortion and long
text. This problem will be a new research direction for OCR. For the
end-to-end information extraction, results on Business Email are the
worst, and the second-worst is Resume. It reveals that there is plenty
of work to do concerning end-to-end information extraction.
From the perspective of systems, we surprisingly discover that the text
recognition may be the top bottleneck for end-to-end understanding VRD
on Category II, III and IV. The information extraction is another
bottleneck due to the complex layouts and long character sentence
(Referring to Table [table:baseline],
1 and
[table:components]). Luckily, the
end-to-end training strategy can enhance both the text reading and the
final information extraction task. In future, more attention should be
paid to the effects of text reading *w.r.t* information extraction.
## Limitations
First, our method currently requires the annotations of position,
character string and entity labels of texts in a document, and the
labeling process is cost-expensive. We will resort to
semi/weakly-supervised learning algorithms to alleviate the problem in
the future. Another limitation is that the multi-modal context block
captures context in the instance granularity, which can be much more
fine-grained if introduced token/ character granularity context. Much
more fine-grained context is beneficial to extracting entities across
text instances.
# Conclusion
In this paper, we present an end-to-end trainable network integrating
text reading and information extraction for document understanding.
These two tasks can mutually reinforce each other via a multi-modal
context block, i.e., the multi-modal features, like visual, layout and
textual features, can boost the performances of information extraction,
while the loss of information extraction can also supervise the
optimization of text reading. On various benchmarks, from structured to
unstructured text type and fixed to variable layout, the proposed method
significantly outperforms previous methods. To promote the VRD
understanding research, we provide four kinds of benchmarks along the
dimensions of layout and text type, and also contribute four groups of
strong baselines for the future study.
OCR-free Document Understanding Transformer
2021-11-30
Geewook Kim, Teakgyu Hong, Moonbin Yim, Jeongyeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, Seunghyun Park
Understanding document images (e.g., invoices) is a core but challenging task since it requires complex functions such as reading text and a holistic understanding of the document. Current Visual Document Understanding (VDU) methods outsource the task of reading text to off-the-shelf Optical Character Recognition (OCR) engines and focus on the understanding task with the OCR outputs. Although such OCR-based approaches have shown promising performance, they suffer from 1) high computational costs for using OCR; 2) inflexibility of OCR models on languages or types of document; 3) OCR error propagation to the subsequent process. To address these issues, in this paper, we introduce a novel OCR-free VDU model named Donut, which stands for Document understanding transformer. As the first step in OCR-free VDU research, we propose a simple architecture (i.e., Transformer) with a pre-training objective (i.e., cross-entropy loss). Donut is conceptually simple yet effective. Through extensive experiments and analyses, we show a simple OCR-free VDU model, Donut, achieves state-of-the-art performances on various VDU tasks in terms of both speed and accuracy. In addition, we offer a synthetic data generator that helps the model pre-training to be flexible in various languages and domains. The code, trained model and synthetic data are available at https://github.com/clovaai/donut.
Show Paper Content
# Introduction
# Method
## Preliminary: background
# Experiments and Analyses [sec:exp]
# Related Work
# Conclusions
# Appendix
## Details of OCR Engines (MS, CLOVA, Easy, Paddle) [sec:detail_of_ocr_engines]
Current state-of-the-art visual document understanding (VDU) backbones,
such as BROS [hong2021bros](https://ojs.aaai.org/index.php/AAAI/article/view/21322),
LayoutLM [xu2019_layoutLM](https://doi.org/10.1145/3394486.3403172) and
LayoutLMv2 [xu-etal-2021-layoutlmv2](https://aclanthology.org/2021.acl-long.201), are dependent on
off-the-shelf OCR engines. These backbones take the output of OCR as
their (one of) input features. For the OCR-dependent methods, in our
experiments, we use state-of-the-art OCR engines that are publicly
available, including 2 OCR API products (i.e., MS OCR[^3] and CLOVA
OCR[^4]) and 2 open-source OCR models (i.e., Easy OCR[^5] and Paddle
OCR[^6]). In the main paper, Paddle OCR is used for the Chinese train
ticket dataset [eaten](eaten) and CLOVA OCR is used for the rest
datasets in the document information extraction (IE) tasks. MS OCR is
used to measure the running time of the LayoutLM family in document
classification and visual question answering (VQA) tasks, following the
previous work of Xu et al. [xu-etal-2021-layoutlmv2](https://aclanthology.org/2021.acl-long.201).
Each OCR engine is explained in the following.
### MS OCR
MS OCR is the latest OCR API product from Microsoft and used in several
recent VDU methods, e.g.,
LayoutLMv2 [xu-etal-2021-layoutlmv2](https://aclanthology.org/2021.acl-long.201). This engine
supports 164 languages for printed text and 9 languages for handwritten
text (until 2022/03).
### CLOVA OCR
CLOVA OCR is an API product from NAVER CLOVA and is specialized in
document IE tasks. This engine supports English, Japanese and Korean
(until 2022/03). In the ablation experiments on the CORD
dataset [park2019cord](park2019cord) (Figure 9 in the main paper), the
CLOVA OCR achieved the best accuracy.
### Easy OCR
Easy OCR is a ready-to-use OCR engine that is publicly available at
GitHub. This engine supports more than 80 languages (until 2022/03).
Unlike the aforementioned two OCR products (i.e., MS OCR and CLOVA OCR),
this engine is publicly opened and downloadable. The entire model
architecture is based on the modern deep-learning-based OCR
modules [baek2019craft](baek2019craft), [baek2019wrong](baek2019wrong) with some
modifications to make the model lighter and faster. The total number of
model parameters is 27M which is small compared to the state-of-the-art
models [baek2019craft](baek2019craft), [baek2019wrong](baek2019wrong).
### Paddle OCR
Paddle OCR is an open-source OCR engine available at GitHub. We used a
lightweight (i.e., mobile) version of the model which is specially
designed for a fast and light OCR of English and Chinese texts. The
model is served on a CPU environment and the size of the model is
extremely small, which is approximately 10M.
## Details of Synthetic Document Generator (SynthDoG) [sec:detail_of_synthdog]
In this section, we explain the components of the proposed Synthetic
Document Generator (SynthDoG) in detail. The entire pipeline basically
follows Yim et al. [synthtiger](synthtiger). Our source code is
available at . More samples are shown
in Figure 1.
### Background
Background images are sampled from
ImageNet [deng2009imagenet](deng2009imagenet). Gaussian blur is randomly
applied to the background image to represent out-of-focus effects.
### Document
Paper textures are sampled from the photos that we collected. The
texture is applied to an white background. In order to make the texture
realistic, random elastic distortion and Gaussian noise are applied. To
represent various view angles in photographs, a random perspective
transformation is applied to the image.
### Text Layout and Pattern
To mimic the layouts in real-world documents, a heuristic rule-based
pattern generator is applied to the document image region to generate
text regions. The main idea is to set multiple squared regions to
represent text paragraphs. Each squared text region is then interpreted
as multiple lines of text. The size of texts and text region margins are
chosen randomly.
### Text Content and Style
We prepare the multi-lingual text corpora from Wikipedia.[^7] We use
Noto fonts[^8] since it supports various languages. SynthDoG samples
texts and fonts from these resources and the sampled texts are rendered
in the regions that are generated by the layout pattern generator. The
text colors are randomly assigned.
### Post-processing
Finally, some post-processing techniques are applied to the output
image. In this process, the color, brightness, and contrast of the image
are adjusted. In addition, shadow effect, motion blur, Gaussian blur,
and JPEG compression are applied to the image.
## Details of Document Information Extraction
Information Extraction (IE) on documents is an arduous task since it
requires (a) reading texts, (b) understanding the meaning of the texts,
and (c) predicting the relations and structures among the extracted
information. Some previous works have only focused on extracting several
pre-defined key information [eaten](eaten). In that case, only
(a) and (b) are required for IE models. We go beyond the previous works
by considering (c) also. Although the task is complex, its interface
(i.e., the format of input and output) is simple. In this section, for
explanation purposes, we show some sample images (which are the raw
input of the IE pipeline) with the output of Donut.
In the main paper, we test four datasets including two public benchmarks
(i.e., *CORD* [park2019cord](park2019cord) and
*Ticket* [eaten](eaten)) and two private industrial datasets
(i.e., *Business Card* and *Receipt*).
Figure 2 shows examples of *Ticket*
with the outputs of Donut.
Figure 3 shows examples of *CORD* with
the outputs of Donut. Due to strict industrial policies on the private
industrial datasets, we instead show some real-like high-quality samples
of *Business Card* and *Receipt* in
Figure 4.
## Details of Model Training Scheme and Output Format [sec:detail_of_scheme_and_format]
In the model architecture and training objective, we basically followed
the original Transformer [vaswani2017transformer](https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf), which
uses a Transformer encoder-decoder architecture and a teacher-forcing
training scheme. The teacher-forcing scheme is a model training strategy
that uses the ground truth as input instead of model output from a
previous time step.
Figure 5 shows a details of the model training
scheme and decoder output format.
## Implementation and Training Hyperparameters [sec:detail_of_implementation_and_hyperparams]
The codebase and settings are available at GitHub.[^9] We implement the
entire model pipeline with Huggingface’s
`transformers`[^10] [wolf-etal-2020-transformers](https://aclanthology.org/2020.emnlp-demos.6) and an
open-source library `TIMM` (PyTorch image
models)[^11] [rw2019timm](https://github.com/rwightman/pytorch-image-models).
For all model training, we use a half-precision (fp16) training. We
train Donut using Adam optimizer [Adamoptim](http://arxiv.org/abs/1412.6980) by
decreasing the learning rate as the training progresses. The initial
learning rate of pre-training is set to 1e-4 and that of fine-tuning is
selected from 1e-5 to 1e-4. We pre-train the model for 200K steps with
64 NVIDIA A100 GPUs and a mini-batch size of 196, which takes about 2-3
GPU days. We also apply a gradient clipping technique where a maximum
gradient norm is selected from 0.05 to 1.0. The input resolution of
Donut is set to 2560$\times$``{=html}1920 at the pre-training
phase. In downstream tasks, the input resolutions are controlled. In
some downstream document IE experiments, such as,
*CORD* [park2019cord](park2019cord), *Ticket* [eaten](eaten)
and *Business Card*, smaller size of input resolution, e.g.,
1280$\times$``{=html}960, is tested. With the
1280$\times$``{=html}960 setting, the model training cost of
Donut was small. For example, the model fine-tuning on *CORD* or
*Ticket* took approximately 0.5 hours with one A100 GPU. However, when
we set the 2560$\times$``{=html}1920 setting for larger
datasets, e.g., *RVL-CDIP* or *DocVQA*, the cost increased rapidly. With
64 A100 GPUs, *DocVQA* requires one GPU day and *RVL-CDIP* requires two
GPU days approximately. This is not surprising in that increasing the
input size for a precise result incurs higher computational costs in
general. Using an efficient attention
mechanism [wang2020linformer](wang2020linformer) may avoid the problem in
architectural design, but we use the original
Transformer [vaswani2017transformer](https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf) as we aim to present
a simpler architecture in this work. Our preliminary experiments in
smaller resources are available in
Appendix 6.6.
For the implementation of document IE baselines, we use the
`transformers` library for BERT [devlinBERT2018](https://aclanthology.org/N19-1423),
BROS [hong2021bros](https://ojs.aaai.org/index.php/AAAI/article/view/21322),
LayoutLMv2 [xu-etal-2021-layoutlmv2](https://aclanthology.org/2021.acl-long.201), [layoutxlm](layoutxlm) and
WYVERN [hwang2021costeffective](https://aclanthology.org/2021.emnlp-main.271). For the
SPADE [hwang-etal-2021-spatial](https://aclanthology.org/2021.findings-acl.28) baseline, the official
implementation[^12] is used. The models are trained using NVIDIA P40,
V100, or A100 GPUs. The major hyperparameters, such as initial learning
rate and number of epochs, are adjusted by monitoring the scores on the
validation set. The architectural details of the OCR-dependent VDU
backbone baselines (e.g., LayoutLM and LayoutLMv2) are available in
Appendix 6.7.
## Preliminary Experiments in Smaller Resources [sec:smaller_resources]
In our preliminary experiments, we pre-trained Donut with smaller
resources (denoted as Donut$_{\text{Proto}}$), i.e., smaller data
(SynthDoG 1.2M) and fewer GPUs (8 V100 GPUs for 5 days). The input size
was 2048$\times$``{=html}1536. In this setting,
Donut$_{\text{Proto}}$ also achieved comparable results on *RVL-CDIP*
and *CORD*. The accuracy on *RVL-CDIP* was 94.5 and *CORD* was 85.4.
After the preliminaries, we have scaled the model training with more
data.
## Details of OCR-dependent Baseline Models [sec:detail_of_VDU_backbone]
In this section, we provide a gentle introduction to the general-purpose
VDU backbones, such as LayoutLM [xu2019_layoutLM](https://doi.org/10.1145/3394486.3403172) and
LayoutLMv2 [xu-etal-2021-layoutlmv2](https://aclanthology.org/2021.acl-long.201). To be specific, we
explain how the conventional backbones perform downstream VDU tasks;
document classification, IE, and VQA. Common to all tasks, the output of
the OCR engine is used as input features of the backbone. That is, the
extracted texts are sorted and converted to a sequence of text tokens.
The sequence is passed to the Transformer encoder to get contextualized
output vectors. The vectors are used to get the desired output. The
difference in each task depends on a slight modification on the input
sequence or on the utilization of the output vectors.
### Document Classification
At the start of the input sequence, a special token `[CLS]` is appended.
The sequence is passed to the backbone to get the output vectors. With a
linear mapping and softmax operation, the output vector of the special
token `[CLS]` is used to get a *class-label* prediction.
### Document IE
With a linear mapping and softmax operation, the output vector sequence
is converted to a *BIO-tag* sequence [hwang2019pot](hwang2019pot).
#### IE on 1-depth structured documents
When there is no hierarchical structure in the document (See
Figure 2), the tag set is defined as
{“B$_{k}$”, “I$_{k}$”, “O” $\mid k\in$ pre-defined keys}. “B$_{k}$” and
“I$_{k}$” are tags that represent the beginning (B) and the inside (I)
token of the key $k$ respectively. The “O” tag indicates that the token
belongs to no key information.
#### IE on $n$-depth structured documents
When there are hierarchies in the structure (See
Figure 3), the BIO-tags are defined for
each hierarchy level. In this section, we explain a case where the depth
of structure is $n=2$. The tag set is defined as {“B$_{g}$.B$_{k}$”,
“B$_{g}$.I$_{k}$”, “I$_{g}$.B$_{k}$”, “I$_{g}$.I$_{k}$”, “O” $\mid g\in$
pre-defined parent keys, $k\in$ pre-defined child keys}. For instance,
the Figure 3 shows an example where a parent
key is “menu” and related child keys are {“cnt”, “nm”, “price”}.
“B$_{g}$” represents that one group (i.e., a parent key such as “menu”)
starts, and “I$_{g}$” represents that the group is continuing.
Separately from the BI tags of the parent key (i.e., “B$_{g}$” and
“I$_{g}$”), the BI tags of each child key (i.e., “B$_{k}$” and
“I$_{k}$”) work the same as in the case of $n=1$. This BIO-tagging
method is also known as *Group BIO-tagging* and the details are also
available in Hwang et al. [hwang2019pot](hwang2019pot).
### Document VQA
With a linear mapping and softmax operation, the output vector sequence
is converted to a *span-tag* sequence. For the input token sequence, the
model finds the beginning and the end of the answer span. Details can
also be found in the Section 4.2 of Devlin et
al. [devlinBERT2018](https://aclanthology.org/N19-1423).
[^1]: Corresponding author: gwkim.rsrch@gmail.com
[^2]: This work was done while the authors were at NAVER CLOVA.
[^3]: .
[^4]: .
[^5]: .
[^6]: .
[^7]: .
[^8]: .
[^9]: .
[^10]: .
[^11]: .
[^12]: .
Understanding document images (*e.g.*, invoices) is a core but
challenging task since it requires complex functions such as *reading
text* and a *holistic understanding of the document*. Current Visual
Document Understanding (VDU) methods outsource the task of reading text
to off-the-shelf Optical Character Recognition (OCR) engines and focus
on the understanding task with the OCR outputs. Although such OCR-based
approaches have shown promising performance, they suffer from 1) high
computational costs for using OCR; 2) inflexibility of OCR models on
languages or types of documents; 3) OCR error propagation to the
subsequent process. To address these issues, in this paper, we introduce
a novel OCR-free VDU model named , which stands for **Do**cume**n**t
**u**nderstanding **t**ransformer. As the first step in OCR-free VDU
research, we propose a simple architecture (*i.e.*, Transformer) with a
pre-training objective (*i.e.,* cross-entropy loss). Donut is
conceptually simple yet effective. Through extensive experiments and
analyses, we show a simple OCR-free VDU model, , achieves
state-of-the-art performances on various VDU tasks in terms of both
speed and accuracy. In addition, we offer a synthetic data generator
that helps the model pre-training to be flexible in various languages
and domains. The code, trained model, and synthetic data are available
at .
(a) Pipeline Overview.(b) System
Benchmarks.
The pipeline overview and benchmarks. The
proposed end-to-end model, , outperforms the recent OCR-dependent VDU
models in memory, time cost and accuracy. Performances on visual
document IE are
shown in (b). More results on various VDU tasks are available at
Section [sec:exp] showing the same
trend
Document images, such as commercial invoices, receipts, and business
cards, are easy to find in modern working environments. To extract
useful information from such document images, Visual Document
Understanding (VDU) has not been only an essential task for industry,
but also a challenging topic for researchers, with applications
including document
classification [Kang2014ConvolutionalNN](Kang2014ConvolutionalNN), [7333933](7333933),
information
extraction [hwang2019pot](hwang2019pot), [majumder2020representation](https://www.aclweb.org/anthology/2020.acl-main.580), and
visual question
answering [mathew2021docvqa](mathew2021docvqa), [icdar21docvqa](icdar21docvqa).
Current VDU
methods [hwang2019pot](hwang2019pot), [hwang2020spade](https://aclanthology.org/2021.findings-acl.28), [xu2019_layoutLM](https://doi.org/10.1145/3394486.3403172), [xu-etal-2021-layoutlmv2](https://aclanthology.org/2021.acl-long.201), [hong2021bros](https://ojs.aaai.org/index.php/AAAI/article/view/21322)
solve the task in a two-stage manner: 1) reading the texts in the
document image; 2) holistic understanding of the document. They usually
rely on deep-learning-based Optical Character Recognition
(OCR) [baek2019craft](baek2019craft), [baek2019wrong](baek2019wrong) for the text reading
task and focus on modeling the understanding part. For example, as shown
in Figure [fig:problem_definition], a
conventional pipeline for extracting structured information from
documents (a.k.a. document parsing) consists of three separate modules
for text detection, text recognition, and
parsing [hwang2019pot](hwang2019pot), [hwang2020spade](https://aclanthology.org/2021.findings-acl.28).
However, the OCR-dependent approach has critical problems. First of all,
using OCR as a pre-processing method is expensive. We can utilize
pre-trained off-the-shelf OCR engines; however, the computational cost
for inference would be expensive for high-quality OCR results. Moreover,
the off-the-shelf OCR methods rarely have flexibility dealing with
different languages or domain changes, which may lead to poor
generalization ability. If we train an OCR model, it also requires
extensive training costs and large-scale
datasets [baek2019craft](baek2019craft), [baek2019wrong](baek2019wrong), [Liu_2020_CVPR](Liu_2020_CVPR), [spts](https://arxiv.org/abs/2112.07917).
Another problem is, OCR errors would propagate to the VDU system and
negatively influence subsequent
processes [ocr_error_negative](ocr_error_negative), [hwang2021costeffective](https://aclanthology.org/2021.emnlp-main.271).
This problem becomes more severe in languages with complex character
sets, such as Korean or Chinese, where the quality of OCR is relatively
low [rijhwani-etal-2020-ocr](https://aclanthology.org/2020.emnlp-main.478). To deal with this, post-OCR
correction
module [schaefer-neudecker-2020-two](https://aclanthology.org/2020.latechclfl-1.6), [rijhwani-etal-2020-ocr](https://aclanthology.org/2020.emnlp-main.478), [duong-etal-2021-unsupervised](https://aclanthology.org/2021.nodalida-main.24)
is usually adopted. However, it is not a practical solution for real
application environments since it increases the entire system size and
maintenance cost.
We go beyond the traditional framework by modeling a direct mapping from
a raw input image to the desired output without OCR. We introduce a new
OCR-free VDU model to address the problems induced by the
OCR-dependency. Our model is based on Transformer-only architecture,
referred to as **Do**cume**n**t **u**nderstanding **t**ransformer (),
following the huge success in vision and
language [devlinBERT2018](https://aclanthology.org/N19-1423), [dosovitskiy2020vit](https://openreview.net/forum?id=YicbFdNTTy), [pmlr-v139-kim21k](http://proceedings.mlr.press/v139/kim21k.html).
We present a minimal baseline including a simple architecture and
pre-training method. Despite its simplicity, shows comparable or better
overall performance than previous methods as shown in
Figure 1.
We take pre-train-and-fine-tune
scheme [devlinBERT2018](https://aclanthology.org/N19-1423), [xu2019_layoutLM](https://doi.org/10.1145/3394486.3403172) on training. In
the pre-training phase, learns *how to read the texts* by predicting the
next words by conditioning jointly on the image and previous text
contexts. is pre-trained with document images and their text
annotations. Since our pre-training objective is simple (*i.e.*, reading
the texts), we can realize domain and language flexibility
straightforwardly pre-training with synthetic data. During fine-tuning
stage, learns *how to understand the whole document* according to the
downstream task. We demonstrate has a strong understanding ability
through extensive evaluation on various VDU tasks and datasets. The
experiments show a simple OCR-free VDU model can achieve
state-of-the-art performance in terms of both speed and accuracy.
The contributions are summarized as follows:
1. We propose a novel OCR-free approach for VDU. To the best of our
knowledge, this is the first method based on an OCR-free Transformer
trained in end-to-end manner.
2. We introduce a simple pre-training scheme that enables the
utilization of synthetic data. By using our generator SynthDoG, we
show can easily be extended to a multi-lingual setting, which is not
applicable for the conventional approaches that need to retrain an
off-the-shelf OCR engine.
3. We conduct extensive experiments and analyses on both public
benchmarks and private industrial datasets, showing that the
proposed method achieves not only state-of-the-art performances on
benchmarks but also has many practical advantages (e.g.,
*cost-effective*) in real-world applications.
4. The codebase, pre-trained model, and synthetic data are available at
GitHub.[^1]
[^1]: .
There have been various visual document understanding (VDU) methods to
understand and extract essential information from the semi-structured
documents such as
receipts [8977955](8977955), [hwang-etal-2021-spatial](https://aclanthology.org/2021.findings-acl.28), [hong2021bros](https://ojs.aaai.org/index.php/AAAI/article/view/21322),
invoices [8978079](8978079), and form
documents [7333829](7333829), [8977962](8977962), [majumder-etal-2020-representation](https://aclanthology.org/2020.acl-main.580).
Earlier VDU attempts have been done with OCR-independent visual
backbones [Kang2014ConvolutionalNN](Kang2014ConvolutionalNN), [7333933](7333933), [7333910](7333910), [eaten](eaten), [docreader](https://doi.org/10.1007/978-3-030-86549-8\_29),
but the performances are limited. Later, with the remarkable advances of
OCR [baek2019craft](baek2019craft), [baek2019wrong](baek2019wrong) and
BERT [devlinBERT2018](https://aclanthology.org/N19-1423), various OCR-dependent VDU models
have been proposed by combining
them [hwang2019pot](hwang2019pot), [hwang2020spade](https://aclanthology.org/2021.findings-acl.28), [hwang2021costeffective](https://aclanthology.org/2021.emnlp-main.271).
More recently, in order to get a more general VDU, most
state-of-the-arts [xu-etal-2021-layoutlmv2](https://aclanthology.org/2021.acl-long.201), [hong2021bros](https://ojs.aaai.org/index.php/AAAI/article/view/21322)
use both powerful OCR engines and large-scale real document image data
(e.g., IIT-CDIP [iitcdip](https://doi.org/10.1145/1148170.1148307)) for a model pre-training.
Although they showed remarkable advances in recent years, extra effort
is required to ensure the performance of an entire VDU model by using
the off-the-shelf OCR engine.
## Document Understanding Transformer
is an end-to-end (i.e., self-contained) VDU model for general
understanding of document images. The architecture of is quite simple,
which consists of a
Transformer [vaswani2017transformer](https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf), [dosovitskiy2020vit](https://openreview.net/forum?id=YicbFdNTTy)-based
visual encoder and textual decoder modules. Note that does not rely on
any modules related to OCR functionality but uses a visual encoder for
extracting features from a given document image. The following textual
decoder maps the derived features into a sequence of subword tokens to
construct a desired structured format (e.g., JSON). Each model component
is Transformer-based, and thus the model is trained easily in an
end-to-end manner. The overall process of is illustrated in
Figure [fig:teaser].
### Encoder.
The visual encoder converts the input document image
$\mathbf{x}{\in}\mathbb{R}^{H\times W\times C}$ into a set of embeddings
$\{\mathbf{z}_{i} | \mathbf{z}_{i}{\in}\mathbb{R}^{d}, 1{\le}i{\le}n\}$,
where $n$ is feature map size or the number of image patches and $d$ is
the dimension of the latent vectors of the encoder. Note that CNN-based
models [HeZRS16](HeZRS16) or Transformer-based
models [dosovitskiy2020vit](https://openreview.net/forum?id=YicbFdNTTy), [Liu_2021_ICCV](Liu_2021_ICCV) can be used as
the encoder network. In this study, we use Swin
Transformer [Liu_2021_ICCV](Liu_2021_ICCV) because it shows the best
performance in our preliminary study in document parsing. Swin
Transformer first splits the input image $\mathbf{x}$ into
non-overlapping patches. Swin Transformer blocks, consist of a shifted
window-based multi-head self-attention module and a two-layer MLP, are
applied to the patches. Then, patch merging layers are applied to the
patch tokens at each stage. The output of the final Swin Transformer
block $\{\mathbf{z}\}$ is fed into the following textual decoder.
### Decoder.
Given the $\{\mathbf{z}\}$, the textual decoder generates a token
sequence $(\mathbf{y}_{i})_{i=1}^{m}$, where
$\mathbf{y}_{i}{\in}\mathbb{R}^{v}$ is an one-hot vector for the $i$-th
token, $v$ is the size of token vocabulary, and $m$ is a hyperparameter,
respectively. We use BART [lewis-etal-2020-bart](https://aclanthology.org/2020.acl-main.703) as the
decoder architecture. Specifically, we initialize the decoder model
weights with those from the publicly available[^1] pre-trained
multi-lingual BART model[liu-etal-2020](https://aclanthology.org/2020.tacl-1.47).
### Model Input.
Following the original
Transformer [vaswani2017transformer](https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf), we use a
teacher-forcing scheme [williams1989learning](williams1989learning), which is a
model training strategy that uses the ground truth as input instead of
model output from a previous time step. In the test phase, inspired by
GPT-3 [NEURIPS2020_1457c0d6](https://proceedings.neurips.cc/paper/2020/file/1457c0d6bfcb4967418bfb8ac142f64a-Paper.pdf), the model generates a token
sequence given a prompt. We add new special tokens for the prompt for
each downstream task in our experiments. The prompts that we use for our
applications are shown with the desired output sequences in
Figure [fig:teaser]. Illustrative explanations
for the teacher-forcing strategy and the decoder output format are
available in
Appendix [sec:detail_of_scheme_and_format].
### Output Conversion.
The output token sequence is converted to a desired structured format.
We adopt a JSON format due to its high representation capacity. As shown
in Figure [fig:teaser], a token sequence is
one-to-one invertible to a JSON data. We simply add two special tokens
`[START_`$\ast$`]` and `[END_`$\ast$`]`, where $\ast$ indicates each
field to extract. If the output token sequence is wrongly structured, we
simply treat the field is lost. For example, if there is only
`[START_name]` exists but no `[END_name]`, we assume the model fails to
extract “name” field. This algorithm can easily be implemented with
simple regular expressions [Friedl06](https://www.safaribooksonline.com/library/view/mastering-regular-expressions/0596528124/).
## Pre-training
### Task. [sec:pretraining]
The model is trained to read all texts in the image in reading order
(from top-left to bottom-right, basically). The objective is to minimize
cross-entropy loss of next token prediction by jointly conditioning on
the image and previous contexts. This task can be interpreted as a
pseudo-OCR task. The model is trained as a visual language model over
the visual corpora, i.e., document images.
### Visual Corpora.
We use IIT-CDIP [iitcdip](https://doi.org/10.1145/1148170.1148307), which is a set of 11M scanned
english document images. A commercial CLOVA OCR API is applied to get
the pseudo text labels. As aforementioned, however, this kind of dataset
is not always available, especially for languages other than English. To
alleviate the dependencies, we build a scalable ***Synth**etic
**Do**cument **G**enerator*, referred to as **SynthDoG**. Using the
SynthDog and Chinese, Japanese, Korean and English Wikipedia, we
generated 0.5M samples per language.
### Synthetic Document Generator.
The pipeline of image rendering basically follows Yim et al.
[synthtiger](synthtiger). As shown in
Figure 1, the generated sample consists of
several components; background, document, text, and layout. Background
image is sampled from ImageNet [deng2009imagenet](deng2009imagenet), and a
texture of document is sampled from the collected paper photos. Words
and phrases are sampled from Wikipedia. Layout is generated by a simple
rule-based algorithm that randomly stacks grids. In addition, several
image rendering
techniques [Gupta16](Gupta16), [long2020unrealtext](long2020unrealtext), [synthtiger](synthtiger) are
applied to mimic real documents. The generated examples are shown in
Figure 1. More details of SynthDoG are
available in the code and
Appendix [sec:detail_of_synthdog].
## Fine-tuning
After the model learns *how to read*, in the application stage (i.e.,
fine-tuning), we teach the model *how to understand* the document image.
As shown in Figure [fig:teaser], we interpret all
downstream tasks as a JSON prediction problem.
The decoder is trained to generate a token sequence that can be
converted into a JSON that represents the desired output information.
For example, in the document classification task, the decoder is trained
to generate a token sequence `[START_class][memo][END_class]` which is
1-to-1 invertible to a JSON {“class”: “memo”}. We introduce some special
tokens (e.g., `[memo]` is used for representing the class “memo”), if
such replacement is available in the target task.
[^1]: .
In this section, we present fine-tuning results on three VDU
applications on six different datasets including both public benchmarks
and private industrial service datasets. The samples are shown in
Figure [fig:datasets].
## Downstream Tasks and Datasets
### Document Classification.
To see whether the model can distinguish across different types of
documents, we test a classification task. Unlike other models that
predict the class label via a softmax on the encoded embedding, generate
a JSON that contains class information to maintain the uniformity of the
task-solving method. We report overall classification accuracy on a test
set.
#### RVL-CDIP.
The RVL-CDIP dataset [harley2015icdar](harley2015icdar) consists of 400K
images in 16 classes, with 25K images per class. The classes include
letter, memo, email, and so on. There are 320K training, 40K validation,
and 40K test images.
### Document Information Extraction.
To see the model fully understands the complex layouts and contexts in
documents, we test document information extraction (IE) tasks on various
real document images including both public benchmarks and real
industrial datasets. In this task, the model aims to map each document
to a structured form of information that is consistent with the target
ontology or database schema. See
Figure [fig:problem_definition] for
an illustrative example. The model should not only read the characters
well, but also understand the layouts and semantics to infer the groups
and nested hierarchies among the texts.
We evaluate the models with two metrics; field-level F1
score [hwang2019pot](hwang2019pot), [xu2019_layoutLM](https://doi.org/10.1145/3394486.3403172), [hong2021bros](https://ojs.aaai.org/index.php/AAAI/article/view/21322) and
Tree Edit Distance (TED) based
accuracy [ted](ted), [teds](teds), [hwang2021costeffective](https://aclanthology.org/2021.emnlp-main.271). The F1 checks
whether the extracted field information is in the ground truth. Even if
a single character is missed, the score assumes the field extraction is
failed. Although F1 is simple and easy to understand, there are some
limitations. First, it does not take into account partial overlaps.
Second, it can not measure the predicted structure (e.g., groups and
nested hierarchy). To assess overall accuracy, we also use another
metric based on TED [ted](ted), that can be used for any
documents represented as trees. It is calculated as,
$\max(0, 1-\text{TED}(\text{pr},\text{gt})/\text{TED}(\phi,\text{gt}))$,
where $\text{gt}$, $\text{pr}$, and $\phi$ stands for ground truth,
predicted, and empty trees respectively. Similar metrics are used in
recent works on document IE [teds](teds), [hwang2021costeffective](https://aclanthology.org/2021.emnlp-main.271)
We use two public benchmark datasets as well as two private industrial
datasets which are from our active real-world service products. Each
dataset is explained in the followings.
#### CORD.
The Consolidated Receipt Dataset (CORD)[^1][park2019cord](park2019cord)
is a public benchmark that consists of 0.8K train, 0.1K valid, 0.1K test
receipt images. The letters of receipts is in Latin alphabet. The number
of unique fields is 30 containing menu name, count, total price, and so
on. There are complex structures (i.e., nested groups and hierarchies
such as `items>item>``{``name, count, price``}`) in the information. See
Figure [fig:problem_definition] for
more details.
#### Ticket.
This is a public benchmark dataset [eaten](eaten) that consists
of 1.5K train and 0.4K test Chinese train ticket images. We split 10% of
the train set as a validation set. There are 8 fields which are ticket
number, starting station, train number, and so on. The structure of
information is simple and all keys are guaranteed to appear only once
and the location of each field is fixed.
#### Business Card (In-Service Data).
This dataset is from our active products that are currently deployed.
The dataset consists of 20K train, 0.3K valid, 0.3K test Japanese
business cards. The number of fields is 11, including name, company,
address, and so on. The structure of information is similar to the
*Ticket* dataset.
#### Receipt (In-Service Data).
This dataset is also from one of our real products. The dataset consists
of 40K train, 1K valid, 1K test Korean receipt images. The number of
unique field is 81, which includes store information, payment
information, price information, and so on. Each sample has complex
structures compared to the aforementioned datasets. Due to industrial
policies, not all samples can publicly be available. Some real-like
high-quality samples are shown in
Figure [fig:datasets] and in the
supplementary material.
### Document Visual Question Answering.
To validate the further capacity of the model, we conduct a document
visual question answering task (DocVQA). In this task, a document image
and question pair is given and the model predicts the answer for the
question by capturing both visual and textual information within the
image. We make the decoder generate the answer by setting the question
as a starting prompt to keep the uniformity of the method (See
Figure [fig:teaser]).
#### DocVQA.
The dataset is from Document Visual Question Answering competition[^2]
and consists of 50K questions defined on more than 12K
documents [mathew2021docvqa](mathew2021docvqa). There are 40K train, 5K
valid, and 5K test questions. The evaluation metric is ANLS (Average
Normalized Levenshtein Similarity) which is an edit-distance-based
metric. The score on the test set is measured via the evaluation site.
## Setups
We use Swin-B [Liu_2021_ICCV](Liu_2021_ICCV) as a visual encoder of with
slight modification. We set the layer numbers and window size as
$\{2, 2, 14, 2\}$ and 10. In further consideration of the speed-accuracy
trade-off, we use the first four layers of BART as a decoder. As
explained in
Section [sec:pretraining], we train the
multi-lingual using the 2M synthetic and 11M IIT-CDIP scanned document
images. We pre-train the model for 200K steps with 64 A100 GPUs and a
mini-batch size of 196. We use Adam [Adamoptim](http://arxiv.org/abs/1412.6980)
optimizer, the learning rate is scheduled and the initial rate is
selected from 1e-5 to 1e-4. The input resolution is set to
2560$\times$``{=html}1920 and a max length in the decoder is set
to 1536. All fine-tuning results are achieved by starting from the
pre-trained multi-lingual model. Some hyperparameters are adjusted at
fine-tuning and in ablation studies. We use
960$\times$``{=html}1280 for Train Tickets and Business Card
parsing tasks. We fine-tune the model while monitoring the edit distance
over token sequences. The speed of is measured on a P40 GPU, which is
much slower than A100. For the OCR based baselines, states-of-the-art
OCR engines are used, including MS OCR API used in
[xu-etal-2021-layoutlmv2](https://aclanthology.org/2021.acl-long.201) and CLOVA OCR API[^3] used in
[hwang2020spade](https://aclanthology.org/2021.findings-acl.28), [hwang2021costeffective](https://aclanthology.org/2021.emnlp-main.271). An analysis on
OCR engines is available in
Section [sec:ablation_and_analysis].
More details of OCR and training setups are available in
Appendix [sec:detail_of_ocr_engines]
and [sec:detail_of_implementation_and_hyperparams].
## Experimental Results
### Document Classification.
The results are shown in
Table [tbl:docclass]. Without relying on any
other resource (e.g., off-the-shelf OCR engine), shows a
state-of-the-art performance among the general-purpose VDU models such
as LayoutLM [xu2019_layoutLM](https://doi.org/10.1145/3394486.3403172) and
LayoutLMv2 [xu-etal-2021-layoutlmv2](https://aclanthology.org/2021.acl-long.201). In particular,
surpasses the LayoutLMv2 accuracy reported in
[xu-etal-2021-layoutlmv2](https://aclanthology.org/2021.acl-long.201), while using fewer parameters
with the 2x faster speed. Note that the OCR-based models must consider
additional model parameters and speed for the entire OCR framework,
which is not small in general. For example, a recent advanced OCR-based
model [baek2019craft](baek2019craft), [baek2019wrong](baek2019wrong) requires more than
80M parameters. Also, training and maintaining the OCR-based systems are
costly [hwang2021costeffective](https://aclanthology.org/2021.emnlp-main.271), leading to needs for the
-like end-to-end approach.
### Document Information Extraction.
Table [tbl:information_extraction]
shows the results on the four different document IE tasks. The first
group uses a conventional BIO-tagging-based IE
approach [hwang2019pot](hwang2019pot). We follows the conventions in
IE [xu2019_layoutLM](https://doi.org/10.1145/3394486.3403172), [hong2021bros](https://ojs.aaai.org/index.php/AAAI/article/view/21322). OCR extracts texts and
bounding boxes from the image, and then the serialization module sorts
all texts with geometry information within the bounding box. The
BIO-tagging-based named entity recognition task performs token-level tag
classification upon the ordered texts to generate a structured form. We
test three general-purpose VDU backbones,
BERT [devlinBERT2018](https://aclanthology.org/N19-1423),
BROS [hong2021bros](https://ojs.aaai.org/index.php/AAAI/article/view/21322),
LayoutLM [xu2019_layoutLM](https://doi.org/10.1145/3394486.3403172), and
LayoutLMv2 [xu-etal-2021-layoutlmv2](https://aclanthology.org/2021.acl-long.201), [layoutxlm](layoutxlm).
We also test two recently proposed IE models,
SPADE [hwang2020spade](https://aclanthology.org/2021.findings-acl.28) and
WYVERN [hwang2021costeffective](https://aclanthology.org/2021.emnlp-main.271). SPADE is a graph-based
IE method that predicts relations between bounding boxes. WYVERN is an
Transformer encoder-decoder model that directly generates entities with
structure given OCR outputs. WYVERN is different from in that it takes
the OCR output as its inputs.
For all domains, including public and private in-service datasets, shows
the best scores among the comparing models. By measuring both F1 and
TED-based accuracy, we observe not only can extract key information but
also predict complex structures among the field information. We observe
that a large input resolution gives robust accuracies but makes the
model slower. For example, the performance on the CORD with
1280$\times$``{=html}960 was 0.7 sec./image and 91.1 accuracy.
But, the large resolution showed better performances on the low-resource
situation. The detailed analyses are in
Section [sec:ablation_and_analysis].
Unlike other baselines, shows stable performance regardless of the size
of datasets and complexity of the tasks (See
Figure [fig:datasets]). This is a significant
impact as the target tasks are already actively used in industries.
### Document Visual Question Answering.
Table 1 shows the results on the DocVQA
dataset. The first group is the general-purposed VDU backbones whose
scores are from the LayoutLMv2
paper [xu-etal-2021-layoutlmv2](https://aclanthology.org/2021.acl-long.201). We measure the running
time with MS OCR API used in [xu-etal-2021-layoutlmv2](https://aclanthology.org/2021.acl-long.201).
The model in the third group is a DocVQA-specific-purposed fine-tuning
model of LayoutLMv2, whose inference results are available in the
official leader-board.[^4]
As can be seen, achieves competitive scores with the baselines that are
dependent on external OCR engines. Especially, shows that it is robust
to the handwritten documents, which is known to be challenging to
process. In the conventional approach, adding a post-processing module
that corrects OCR errors is an option to strengthen the
pipeline [schaefer-neudecker-2020-two](https://aclanthology.org/2020.latechclfl-1.6), [rijhwani-etal-2020-ocr](https://aclanthology.org/2020.emnlp-main.478), [duong-etal-2021-unsupervised](https://aclanthology.org/2021.nodalida-main.24)
or adopting an encoder-decoder architecture on the OCR outputs can
mitigate the problems of OCR
errors [hwang2021costeffective](https://aclanthology.org/2021.emnlp-main.271). However, this kind of
approaches tend to increase the entire system size and maintenance cost.
shows a completely different direction. Some inference results are shown
in Figure 1. The samples show the current
strengths of as well as the left challenges in the -like end-to-end
approach. Further analysis and ablation is available in
Section [sec:ablation_and_analysis].
max width=
| | Fine-tuning set | OCR | \#Params$^{\dag}$ | Time (ms) | $^{\text{ANLS}^{\:}}_{\text{test set}}$ | $^{\text{ANLS}^\ast}_{\text{handwritten}}$ |
|:---|:--:|:--:|:--:|:--:|:--:|:--:|
| BERT [xu-etal-2021-layoutlmv2](https://aclanthology.org/2021.acl-long.201) | train set | | 110M + $\alpha^{\ddag}$ | 1517 | 63.5 | n/a |
| LayoutLM[xu2019_layoutLM](https://doi.org/10.1145/3394486.3403172) | train set | | 113M + $\alpha^{\ddag}$ | 1519 | 69.8 | n/a |
| LayoutLMv2[xu-etal-2021-layoutlmv2](https://aclanthology.org/2021.acl-long.201) | train set | | 200M + $\alpha^{\ddag}$ | 1610 | 78.1 | n/a |
| | train set | | 176M | **782** | 67.5 | **72.1** |
| LayoutLMv2-Large-QG[xu-etal-2021-layoutlmv2](https://aclanthology.org/2021.acl-long.201) | train + dev + QG | | 390M + $\alpha^{\ddag}$ | 1698 | **86.7** | 67.3 |
**Average Normalized Levenshtein Similarity (ANLS) scores on DocVQA.**
shows a promising result without OCR. $^{\ast}$shows a high ANLS score
on the handwritten documents which are known to be challenging due to
the difficulty of handwriting OCR (See
Figure 1). $^\dag$Token embeddings for
English is counted for a fair comparison. $^\ddag$\# parameters for OCR
should be considered
[^1]: .
[^2]: .
[^3]: .
[^4]: .
## Optical Character Recognition
Recent trends of OCR study are to utilize deep learning models in its
two sub-steps: 1) text areas are predicted by a detector; 2) a text
recognizer then recognizes all characters in the cropped image
instances. Both are trained with a large-scale datasets including the
synthetic images [Jaderberg14c](Jaderberg14c), [Gupta16](Gupta16) and real
images [7333942](7333942), [Phan_2013_ICCV](Phan_2013_ICCV).
Early detection methods used CNNs to predict local segments and apply
heuristics to merge
them [Huang10.1007/978-3-319-10593-2_33](Huang10.1007/978-3-319-10593-2_33), [Zhang_2016_CVPR](Zhang_2016_CVPR).
Later, region proposal and bounding box regression based methods were
proposed [LiaoSBWL17](https://ojs.aaai.org/index.php/AAAI/article/view/11196). Recently, focusing on the
homogeneity and locality of texts, component-level approaches were
proposed [CTPN](CTPN), [baek2019craft](baek2019craft).
Many modern text recognizer share a similar
approach [starnet](https://dx.doi.org/10.5244/C.30.43), [Shi2016RobustST](Shi2016RobustST), [Shi2017AnET](Shi2017AnET), [jianfeng2017deep](https://proceedings.neurips.cc/paper/2017/file/c24cd76e1ce41366a4bbe8a49b02a028-Paper.pdf)
that can be interpreted into a combination of several common deep
modules [baek2019wrong](baek2019wrong). Given the cropped text instance
image, most recent text recognition models apply CNNs to encode the
image into a feature space. A decoder is then applied to extract
characters from the features.
## Visual Document Understanding
Classification of the document type is a core step towards automated
document processing. Early methods treated the problem as a general
image classification, so various CNNs were
tested [Kang2014ConvolutionalNN](Kang2014ConvolutionalNN), [7333933](7333933), [7333910](7333910).
Recently, with BERT [devlinBERT2018](https://aclanthology.org/N19-1423), the methods based
on a combination of CV and NLP were widely
proposed [xu2019_layoutLM](https://doi.org/10.1145/3394486.3403172), [li-etal-2021-structurallm](https://aclanthology.org/2021.acl-long.493). As
a common approach, most methods rely on an OCR engine to extract texts;
then the OCR-ed texts are serialized into a token sequence; finally they
are fed into a language model (e.g., BERT) with some visual features if
available. Although the idea is simple, the methods showed remarkable
performance improvements and became a main trend in recent
years [xu-etal-2021-layoutlmv2](https://aclanthology.org/2021.acl-long.201), [selfdoc](selfdoc), [Appalaraju_2021_ICCV](Appalaraju_2021_ICCV).
Document IE covers a wide range of real
applications [hwang2019pot](hwang2019pot), [majumder2020representation](https://www.aclweb.org/anthology/2020.acl-main.580),
for example, given a bunch of raw receipt images, a document parser can
automate a major part of receipt digitization, which has been required
numerous human-labors in the traditional pipeline. Most recent
models [hwang-etal-2021-spatial](https://aclanthology.org/2021.findings-acl.28), [hwang2021costeffective](https://aclanthology.org/2021.emnlp-main.271)
take the output of OCR as their input. The OCR results are then
converted to the final parse through several processes, which are often
complex. Despite the needs in the industry, only a few works have been
attempted on end-to-end parsing. Recently, some works are proposed to
simplify the complex parsing
processes [hwang-etal-2021-spatial](https://aclanthology.org/2021.findings-acl.28), [hwang2021costeffective](https://aclanthology.org/2021.emnlp-main.271).
But they still rely on a separate OCR to extract text information.
Visual QA on documents seeks to answer questions asked on document
images. This task requires reasoning over visual elements of the image
and general knowledge to infer the correct
answer [mathew2021docvqa](mathew2021docvqa). Currently, most
state-of-the-arts follow a simple pipeline consisting of applying OCR
followed by BERT-like
transformers [xu2019_layoutLM](https://doi.org/10.1145/3394486.3403172), [xu-etal-2021-layoutlmv2](https://aclanthology.org/2021.acl-long.201).
However, the methods work in an extractive manner by their nature.
Hence, there are some concerns for the question whose answer does not
appear in the given image [icdar21docvqa](icdar21docvqa). To tackle the
concerns, generation-based methods have also been
proposed [10.1007/978-3-030-86331-9_47](10.1007/978-3-030-86331-9_47).
In this work, we propose a novel end-to-end framework for visual
document understanding. The proposed method, , directly maps an input
document image into a desired structured output. Unlike conventional
methods, does not depend on OCR and can easily be trained in an
end-to-end fashion. We also propose a synthetic document image
generator, SynthDoG, to alleviate the dependency on large-scale real
document images and we show that can be easily extended to a
multi-lingual setting. We gradually trained the model from *how to read*
to *how to understand* through the proposed training pipeline. Our
extensive experiments and analysis on both external public benchmarks
and private internal service datasets show higher performance and better
*cost-effectiveness* of the proposed method. This is a significant
impact as the target tasks are already practically used in industries.
Enhancing the pre-training objective could be a future work direction.
We believe our work can easily be extended to other domains/tasks
regarding document understanding.
Swin Transformer V2: Scaling Up Capacity and Resolution
2021-11-18
Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo
Large-scale NLP models have been shown to significantly improve the performance on language tasks with no signs of saturation. They also demonstrate amazing few-shot capabilities like that of human beings. This paper aims to explore large-scale models in computer vision. We tackle three major issues in training and application of large vision models, including training instability, resolution gaps between pre-training and fine-tuning, and hunger on labelled data. Three main techniques are proposed: 1) a residual-post-norm method combined with cosine attention to improve training stability; 2) A log-spaced continuous position bias method to effectively transfer models pre-trained using low-resolution images to downstream tasks with high-resolution inputs; 3) A self-supervised pre-training method, SimMIM, to reduce the needs of vast labeled images. Through these techniques, this paper successfully trained a 3 billion-parameter Swin Transformer V2 model, which is the largest dense vision model to date, and makes it capable of training with images of up to 1,536$ imes$1,536 resolution. It set new performance records on 4 representative vision tasks, including ImageNet-V2 image classification, COCO object detection, ADE20K semantic segmentation, and Kinetics-400 video action classification. Also note our training is much more efficient than that in Google's billion-level visual models, which consumes 40 times less labelled data and 40 times less training time. Code is available at url{https://github.com/microsoft/Swin-Transformer}.
Show Paper Content
# Introduction [sec:intro]
Scaling up language models has been incredibly successful. It
significantly improves a model’s performance on language
tasks [devlin2018bert](devlin2018bert), [radford2019language](http://arxiv.org/pdf/1909.07245v1), [raffel2019t5](raffel2019t5), [Turing-17B](http://arxiv.org/pdf/2010.07075v1), [fedus2021switch](http://arxiv.org/pdf/2110.03888v3), [Megatron-Turing-530B](http://arxiv.org/pdf/2201.11990v3)
and the model demonstrates amazing few-shot capabilities similar to that
of human beings [brown2020language](http://arxiv.org/pdf/2010.09461v1). Since the BERT large
model with 340 million parameters [devlin2018bert](devlin2018bert),
language models are quickly scaled up by more than 1,000 times in a few
years, reaching 530 billion dense
parameters [Megatron-Turing-530B](http://arxiv.org/pdf/2201.11990v3) and 1.6 trillion sparse
parameters [fedus2021switch](http://arxiv.org/pdf/2110.03888v3). These large language models
are also found to possess increasingly strong few-shot capabilities akin
to human intelligence for a broad range of language
tasks [brown2020language](http://arxiv.org/pdf/2010.09461v1).
On the other hand, the scaling up of vision models has been lagging
behind. While it has long been recognized that larger vision models
usually perform better on vision
tasks [simonyan2014vgg](simonyan2014vgg), [he2015resnet](he2015resnet), the absolute model
size was just able to reach about 1-2 billion parameters very
recently [kolesnikov2019bigtransfer](kolesnikov2019bigtransfer), [goyal2021selfsupervised](http://arxiv.org/pdf/2102.04341v3), [zhai2021scaling](http://arxiv.org/pdf/2108.00154v2), [riquelme2021scaling](http://arxiv.org/pdf/2106.05974v1), [dai2021coatnet](http://arxiv.org/pdf/2106.04803v2).
More importantly, unlike large language models, the existing large
vision models are applied to the image classification task
only [zhai2021scaling](http://arxiv.org/pdf/2108.00154v2), [riquelme2021scaling](http://arxiv.org/pdf/2106.05974v1), [dai2021coatnet](http://arxiv.org/pdf/2106.04803v2).
To successfully train large and general vision model, we need to address
a few key issues. Firstly, our experiments with large vision models
reveal an instability issue in training. We find that the discrepancy of
activation amplitudes across layers becomes significantly greater in
large models. A closer look at the original architecture reveals that
this is caused by the output of the residual unit directly added back to
the main branch. The result is that the activation values are
accumulated layer by layer, and the amplitudes at deeper layers are thus
significantly larger than those at early layers. To address this issue,
we propose a new normalization configuration, called res-post-norm,
which moves the LN layer from the beginning of each residual unit to the
backend, as shown in
Figure 1. We find this new configuration
produces much milder activation values across the network layers. We
also propose a scaled cosine attention to replace the previous dot
product attention. The scaled cosine attention makes the computation
irrelevant to amplitudes of block inputs, and the attention values are
less likely to fall into extremes. In our experiments, the proposed two
techniques not only make the training process more stable but also
improve the accuracy especially for larger models.
Secondly, many downstream vision tasks such as object detection and
semantic segmentation require high resolution input images or large
attention windows. The window size variations between low-resolution
pre-training and high-resolution fine-tuning can be quite large. The
current common practice is to perform a bi-cubic interpolation of the
position bias maps [dosovitskiy2020vit](dosovitskiy2020vit), [liu2021swin](http://arxiv.org/pdf/2208.02034v1). This
simple fix is somewhat ad-hoc and the result is usually sub-optimal. We
introduce a log-spaced continuous position bias (Log-CPB), which
generates bias values for arbitrary coordinate ranges by applying a
small meta network on the log-spaced coordinate inputs. Since the meta
network takes any coordinates, a pre-trained model will be able to
freely transfer across window sizes by sharing weights of the meta
network. A critical design of our approach is to transform the
coordinates into the log-space so that the extrapolation ratio can be
low even when the target window size is significantly larger than that
of pre-training. The scaling up of model capacity and resolution also
leads to prohibitively high GPU memory consumption with existing vision
models. To resolve the memory issue, we incorporate several important
techniques including
zero-optimizer [rajbhandari2020zero](http://arxiv.org/pdf/1910.02054v3), activation check
pointing [chen2016training](http://arxiv.org/pdf/1604.06174v2) and a novel implementation of
sequential self-attention computation. With these techniques, the GPU
memory consumption of large models and resolutions is significantly
reduced with only marginal effect on the training speed.
With the above techniques, we successfully trained a 3 billion Swin
Transformer model and effectively transferred it to various vision tasks
with image resolution as large as 1,536$\times$``{=html}1,536,
using Nvidia A100-40G GPUs. In our model pre-training, we also employ
self-supervised pre-training to reduce the dependency on super-huge
labeled data. With 40$\times$ less labelled data than that in previous
practice (JFT-3B), the 3 billion model achieves the state-of-the-art
accuracy on a broad range of vision benchmarks. Specifically, it obtains
84.0% top-1 accuracy on the ImageNet-V2 image classification validation
set [recht2019imagenet](http://arxiv.org/pdf/1906.02168v3), 63.1 / 54.4 box / mask AP on the
COCO test-dev set of object detection, 59.9 mIoU on ADE20K semantic
segmentation, and 86.8% top-1 accuracy on Kinetics-400 video action
classification, which are +NA%, +4.4/+3.3, +6.3 and +1.9 higher than the
best numbers in the original Swin
Transformers [liu2021swin](http://arxiv.org/pdf/2208.02034v1), [liu2021video](http://arxiv.org/pdf/2106.13230v1), and surpass
previous best records by +0.8% ([zhai2021scaling](http://arxiv.org/pdf/2108.00154v2)),
+1.8/+1.4 ([xu2021endtoend](http://arxiv.org/pdf/2108.10520v3)), +1.5
([bao2021beit](http://arxiv.org/pdf/2203.05796v1)) and +1.4%
([ryoo2021tokenlearner](http://arxiv.org/pdf/2106.11297v4)).
By scaling up both capacity and resolution of vision models with strong
performance on general vision tasks, just like a good language model’s
performance on general NLP tasks, we aim to stimulate more research in
this direction so that we can eventually close the capacity gap between
vision and language models and facilitate the joint modeling of the two
domains.
# Related Works
#### Language networks and scaling up
Transformer has served the standard network since the pioneer work
of [vaswani2017attention](vaswani2017attention). The exploration of scaling
this architecture has since begun, and the progress has been accelerated
by the invention of effective self-supervised learning approaches, such
as masked or auto-regressive language
modeling [devlin2018bert](devlin2018bert), [radford2019language](http://arxiv.org/pdf/1909.07245v1), and has
been further encouraged by the discovery of a scaling
law [kaplan2020scaling](http://arxiv.org/pdf/1906.09379v1). Since then, the capacity of
language models has increased dramatically by more than 1,000 times in a
few years, from BERT-340M to the
Megatron-Turing-530B [raffel2019t5](raffel2019t5), [Turing-17B](http://arxiv.org/pdf/2010.07075v1), [brown2020language](http://arxiv.org/pdf/2010.09461v1), [Megatron-Turing-530B](http://arxiv.org/pdf/2201.11990v3)
and sparse Switch-Transformer-1.6T [fedus2021switch](http://arxiv.org/pdf/2110.03888v3).
With increased capacity, the accuracy of various language benchmarks has
been significantly improved. The zero-shot or few-shot performance is
also significantly improved [brown2020language](http://arxiv.org/pdf/2010.09461v1), which is
a foundation of human generic intelligence.
#### Vision networks and scaling up
CNNs have long been the standard computer vision
networks [lecun1998lenet](lecun1998lenet), [krizhevsky2012alexnet](krizhevsky2012alexnet). Since
AlexNet [krizhevsky2012alexnet](krizhevsky2012alexnet), architectures have
become deeper and larger, which has greatly advanced various visual
tasks and largely fueled the wave of deep learning in computer vision,
such as VGG [simonyan2014vgg](simonyan2014vgg),
GoogleNet [szegedy2015googlenet](szegedy2015googlenet) and
ResNet citehe2015resnet. In the past two years, the CNN architectures
have been further scaled up to about 1 billion parameters
[kolesnikov2019bigtransfer](kolesnikov2019bigtransfer), [goyal2021selfsupervised](http://arxiv.org/pdf/2102.04341v3),
however, absolute performance may not be so encouraging, perhaps due to
inductive biases in the CNN architecture limiting modeling power.
Last year, Transformers started taking over one representative visual
benchmark after another, including ImageNet-1K image-level
classification benchmarks [dosovitskiy2020vit](dosovitskiy2020vit), COCO
region-level object detection benchmark [liu2021swin](http://arxiv.org/pdf/2208.02034v1),
ADE20K pixel-level semantic segmentation
benchmark [zheng2020SETR](zheng2020SETR), [liu2021swin](http://arxiv.org/pdf/2208.02034v1), Kinetics-400
video action classification benchmark [arnab2021vivit](http://arxiv.org/pdf/2112.13478v2),
etc. Since these works, numerous vision Transformer variants have been
proposed to improve the accuracy at relatively small
scale [touvron2020deit](touvron2020deit), [li2021localvit](http://arxiv.org/pdf/2107.04735v1), [chu2021twins](http://arxiv.org/pdf/2304.11320v1), [wang2021pyramid](http://arxiv.org/pdf/2102.12122v2), [yuan2021tokenstotoken](http://arxiv.org/pdf/2211.05187v1), [zhang2021multiscale](http://arxiv.org/pdf/2302.12185v1), [dong2021cswin](http://arxiv.org/pdf/2107.00652v3), [yang2021focal](http://arxiv.org/pdf/2107.00641v1), [huang2021shuffle](http://arxiv.org/pdf/2106.09358v1), [xiao2021early](xiao2021early), [yuan2021volo](yuan2021volo).
Only a few works have attempted to scale up the vision
Transformers [zhai2021scaling](http://arxiv.org/pdf/2108.00154v2), [riquelme2021scaling](http://arxiv.org/pdf/2106.05974v1), [dai2021coatnet](http://arxiv.org/pdf/2106.04803v2).
However, they rely on a huge image dataset with classification labels,
i.e., JFT-3B, and are only applied to image classification problems.
#### Transferring across window / kernel resolution
For CNNs, previous works typically fixed kernel size during pre-training
and fine-tuning. Global vision Transformers, such as
ViT [dosovitskiy2020vit](dosovitskiy2020vit), compute attention globally,
with the equivalent attention window size linearly proportional to the
increased input image resolution. For local vision Transformer
architectures, such as Swin Transformer [liu2021swin](http://arxiv.org/pdf/2208.02034v1),
the window size can be either fixed or changed during fine-tuning.
Allowing variable window sizes is more convenient in use, so as to be
divisible by the probably variable entire feature map and to tune
receptive fields for better accuracy. To handle the variable window
sizes between pre-training and fine-tuning, bi-cubic interpolation was
the previous common
practice [dosovitskiy2020vit](dosovitskiy2020vit), [liu2021swin](http://arxiv.org/pdf/2208.02034v1). In this
paper, we propose a log-spaced continuous position bias approach
(Log-CPB) that more smoothly transfers pre-trained model weights at low
resolution to deal-with higher resolution windows.
#### Study on bias terms
In NLP, the relative position bias method proved
beneficial [raffel2019t5](raffel2019t5), compared to the absolute
position embedding used in the original
Transformer [vaswani2017attention](vaswani2017attention). In computer vision,
the relative positional bias method is more commonly
used [hu2019localrelation](hu2019localrelation), [liu2021swin](http://arxiv.org/pdf/2208.02034v1), [yang2021focal](http://arxiv.org/pdf/2107.00641v1),
probably because the spatial relationships of visual signals play a more
important role in visual modeling. A common practice is to directly
learn the bias values as model weights. There are also a few works
particularly study how to set and learn the bias
terms [ke2021rethinking](http://arxiv.org/pdf/2006.15595v4), [wu2021rethinking](http://arxiv.org/pdf/2107.14222v1).
#### Continuous convolution and variants
Our Log-CPB approach is also related to earlier works on continuous
convolution and variants
[schutt2017schnet](schutt2017schnet), [wang2018continuousconvcvpr](wang2018continuousconvcvpr), [hu2018relation](hu2018relation), [liu2020closer](http://arxiv.org/pdf/2007.01294v1),
which utilize a meta network to handle irregular data points. Our
Log-CPB approach is inspired by these efforts while solving a different
problem of transferring relative position biases in vision Transformers
across arbitrary window sizes. We also propose log-spaced coordinates to
alleviate the difficulty of extrapolation when transferring between
large size changes.
# Swin Transformer V2
## A Brief Review of Swin Transformer [sec.swin_v1]
Swin Transformer is a general-purpose computer vision backbone that has
achieved strong performance in various granular recognition tasks such
as region-level object detection, pixel-level semantic segmentation, and
image-level image classification. The main idea of Swin Transformer is
to introduce several important visual priors into the vanilla
Transformer encoder, including hierarchy, locality, and translation
invariance, which combines the strength of both: the basic Transformer
unit has strong modeling capabilities, and the visual priors make it
friendly to a variety of visual tasks.
#### Normalization configuration
It is widely known that normalization
technologies [ioffe2015batch](http://arxiv.org/pdf/1802.07590v1), [ba2016layer](http://arxiv.org/pdf/1611.04520v2), [wu2018group](wu2018group), [ulyanov2017instance](http://arxiv.org/pdf/1607.08022v3)
are crucial in stably training deeper architectures. The original Swin
Transformer inherits the common practice in the language
Transformers [radford2019language](http://arxiv.org/pdf/1909.07245v1) and vanilla
ViT [dosovitskiy2020vit](dosovitskiy2020vit) to utilize a pre-normalization
configuration without extensive study, as shown in the
figure 1. In the following subsections, we will
examine this default normalization configuration[^2].
#### Relative position bias
is a key component in the original Swin Transformer which introduces an
additional parametric bias term to encode the geometric relationship in
self-attention calculation: $$\label{eq.att}
\text{Attention}(Q, K, V) = \text{SoftMax}(QK^T/\sqrt{d}+B)V,$$
where $B \in \mathbb{R}^{M^2 \times M^2}$ is the relative position bias
term for each head; $Q, K, V \in \mathbb{R}^{M^2\times d}$ are the
*query*, *key* and *value* matrices; $d$ is the *query*/*key* dimension,
and $M^2$ is the number of patches in a window. The relative position
bias encodes relative spatial configurations of visual elements and is
shown critical in a variety of visual tasks, especially for dense
recognition tasks such as object detection.
In Swin Transformer, the relative positions along each axis are within
the range of $[-M+1, M-1]$ and the relative position bias is
parameterized as a bias matrix
$\hat{B} \in \mathbb{R}^{(2M-1)\times (2M-1)}$, and the elements in $B$
are taken from $\hat{B}$. When transferring across different window
sizes, the learnt relative position bias matrix in pre-training is used
to initialize the bias matrix of a different size in fine-tuning by
bi-cubic interpolation.
#### Issues in scaling up model capacity and window resolution
We observe two issues when we scale up the capacity and window
resolution of the Swin Transformer.
- *An instability issue when scaling up model capacity*. As shown in
Figure 2, when we scale up the original Swin
Transformer model from small size to large size, the activation
values at deeper layers increase dramatically. The discrepancy
between layers with the highest and the lowest amplitudes has
reached an extreme value of $10^4$. When we scale it up further to a
huge size (658 million parameters), it cannot complete the training,
as shown in
Figure 3.
- *Degraded performance when transferring models across window
resolutions*. As shown in the first row of
Table [tab:lcpb], the accuracy decreases
significantly when we directly test the accuracy of a pre-trained
ImageNet-1K model ($256\times 256$ images with $8\times 8$ window
size) at larger image resolutions and window sizes through the
bi-cubic interpolation approach. It may be worth re-examining the
relative position bias approach in the original Swin Transformer.
In the following subsections, we present techniques to address these
issues, including *residual post normalization* and *scaled cosine
attention* to address the instability issue, and a *log-spaced
continuous position bias* approach to address the issue in transferring
across window resolutions.
## Scaling Up Model Capacity
As mentioned in Section 3.1, the original Swin Transformer (and
most vision Transformers) adopts a layer norm layer at the beginning of
each block, inherited from vanilla ViT. When we scale up the model
capacity, a significant increase in activation values is observed at
deeper layers. In fact, in a pre-normalization configuration, the output
activation values of each residual block are merged directly back to the
main branch, and the amplitude of the main branch grows larger and
larger at deeper layers. Large amplitude discrepancy in different layers
causes training instability.
#### Post normalization
To ease this problem, we propose to use a *residual post normalization*
approach instead, as shown in
Figure 1. In this approach, the output of each
residual block is normalized before merging back into the main branch,
and the amplitude of the main branch does not accumulate when the layer
goes deeper. As shown in
Figure 2, the activation amplitudes by this
approach are much milder than in the original pre-normalization
configuration.
In our largest model training, we introduce an additional layer
normalization layer on the main branch every 6 Transformer blocks, to
further stabilize training.
#### Scaled cosine attention
In the original self-attention computation, the similarity terms of the
pixel pairs are computed as a dot product of the *query* and *key*
vectors. We find that when this approach is used in large visual models,
the learnt attention maps of some blocks and heads are frequently
dominated by a few pixel pairs, especially in the *res-post-norm*
configuration. To ease this issue, we propose a *scaled cosine
attention* approach that computes the attention logit of a pixel pair
$i$ and $j$ by a scaled cosine function: $$\label{eq.att}
\text{Sim}(\mathbf{q}_i, \mathbf{k}_j) = \text{cos}(\mathbf{q}_i, \mathbf{k}_j) / \tau + B_{ij},$$
where $B_{ij}$ is the relative position bias between pixel $i$ and $j$;
$\tau$ is a learnable scalar, non-shared across heads and layers. $\tau$
is set larger than 0.01. The cosine function is naturally normalized,
and thus can have milder attention values.
## Scaling Up Window Resolution
In this subsection, we introduce a log-spaced continuous position bias
approach, so that the relative position bias can be smoothly transferred
across window resolutions.
#### Continuous relative position bias
Instead of directly optimizing the parameterized biases, the
*continuous* position bias approach adopts a small meta network on the
relative coordinates: $$\label{eq.cpb}
B (\Delta x, \Delta y) = \mathcal{G} (\Delta x, \Delta y),$$ where
$\mathcal{G}$ is a small network, e.g., a 2-layer MLP with a ReLU
activation in between by default.
The meta network $\mathcal{G}$ generates bias values for arbitrary
relative coordinates, and thus can be naturally transferred to
fine-tuning tasks with arbitrarily varying window sizes. In inference,
the bias values at each relative position can be pre-computed and stored
as model parameters, such that the inference is the same as the original
parameterized bias approach.
#### Log-spaced coordinates
When transferring across largely varying window sizes, a large portion
of the relative coordinate range needs to be extrapolated. To ease this
issue, we propose using log-spaced coordinates instead of the original
linear-spaced ones: $$\begin{aligned}
\label{eq.log_coord}
\widehat{\Delta x} = \text{sign}(x) \cdot \log(1+|\Delta x|), \\
\widehat{\Delta y} = \text{sign}(y) \cdot \log(1+|\Delta y|),
\end{aligned}$$ where $\Delta x$, $\Delta y$ and $\widehat{\Delta x}$,
$\widehat{\Delta y}$ are the linear-scaled and log-spaced coordinates,
respectively.
By using the log-spaced coordinates, when we transfer the relative
position biases across window resolutions, the required extrapolation
ratio will be much smaller than that of using the original linear-spaced
coordinates. For an example of transferring from a pre-trained
$8\times 8$ window size to a fine-tuned $16\times 16$ window size, using
the original raw coordinates, the input coordinate range will be from
$[-7, 7]\times [-7, 7]$ to $[-15, 15]\times [-15, 15]$. The
extrapolation ratio is $\frac{8}{7}=1.14\times$ of the original range.
Using log-spaced coordinates, the input range will be from
$[-2.079, 2.079]\times [-2.079, 2.079]$ to
$[-2.773, 2.773]\times [-2.773, 2.773]$. The extrapolation ratio is
$0.33\times$ of the original range, which is an about 4 times smaller
extrapolation ratio than that using the original linear-spaced
coordinates.
Table [tab:lcpb] compares the transferring
performance of different position bias computation approaches. It can be
seen that the log-spaced CPB (continuous position bias) approach
performs best, particularly when transferred to larger window sizes.
## Self-Supervised Pre-training
Larger models are more data hungry. To address the data hungry problem,
previous large vision models typically utilize huge labelled data such
as
JFT-3B [zhai2021scaling](http://arxiv.org/pdf/2108.00154v2), [riquelme2021scaling](http://arxiv.org/pdf/2106.05974v1), [dai2021coatnet](http://arxiv.org/pdf/2106.04803v2).
In this work, we exploit a self-supervised pre-training method,
SimMIM [simmim](simmim), to alleviate the demands on labelled
data. By this approach, we successfully trained a powerful Swin
Transformer model of 3 billion parameters which achieves
state-of-the-art (SOTA) on 4 representative visual benchmarks, by using
only 70 million labelled images (1/40 of that in JFT-3B).
## Implementation to Save GPU Memory
Another issue lies in the unaffordable GPU memory consumption with a
regular implementation when both the capacity and resolution are large.
To facility the memory issue, we adopt the following implementations:
- *Zero-Redundancy Optimizer
(ZeRO)* [rajbhandari2020zero](http://arxiv.org/pdf/1910.02054v3). In a general
data-parallel implementation of optimizers, the model parameters and
optimization states are broadcasted to every GPU. This
implementation is very unfriendly on GPU memory consumption, for
example, a model of 3 billion parameters will consume 48G GPU memory
when an AdamW optimizer and fp32 weights/states are used. With a
ZeRO optimizer, the model parameters and the corresponding
optimization states will be split and distributed to multiple GPUs,
which significantly reduces memory consumption. We adopt the
DeepSpeed framework and use the ZeRO stage-1 option in our
experiments. This optimization has little effect on training speed.
- *Activation check-pointing* [chen2016training](http://arxiv.org/pdf/1604.06174v2).
Feature maps in the Transformer layers also consume a lot of GPU
memory, which can create bottlenecks when image and window
resolutions are high. The activation check-pointing technology can
significantly reduce the memory consumption, while the training
speed is up to 30% slower.
- *Sequential self-attention computation*. To train large models on
very large resolutions, for example, an image of
1,536$\times$``{=html}1,536 resolution with a window size of
32$\times$``{=html}32, regular A100 GPUs (40GB memory) are
still unaffordable, even with the above two optimization
technologies. We found that in this case, the self-attention module
constitutes a bottleneck. To alleviate this problem, we implement
self-attention computation sequentially, instead of using the
previous batch computation approach. This optimization is applied to
the layers in the first two stages and has little impact on the
overall training speed.
With these implementations, we managed to train a 3B model using the
Nvidia A100-40G GPUs for COCO object detection with an input image
resolution of 1,536$\times$``{=html}1,536, and Kinetics-400
action classification with an input resolution of
$320\times 320 \times 8$.
## Model configurations
We maintain the stage, block, and channel settings of the original Swin
Transformer for 4 configurations of Swin Transformer V2:
- SwinV2-T: $C$ = $96$, \#. block = $\{2, 2, 6, 2\}$
- SwinV2-S/B/L: $C$=$96/128/192$, \#.block=$\{2, 2, 18, 2\}$
with $C$ the number of channels in the first stage.
We further scale up Swin Transformer V2 to its huge size and giant size,
with 658 million parameters and 3 billion parameters, respectively:
- SwinV2-H: $C=352$, \#. block = $\{2, 2, 18, 2\}$
- SwinV2-G: $C=512$, \#. block = $\{2, 2, 42, 4\}$
For SwinV2-H and SwinV2-G, we add an additional layer normalization
layer on the main branch every 6 layers. To save experimental time, we
only employ SwinV2-G for large-scale experiments. SwinV2-H is employed
for another parallel study about self-supervised
learning [simmim](simmim).
# Experiments
## Tasks and Datasets
We conduct experiments on ImageNet-1K image classification (V1 and
V2) [deng2009imagenet](deng2009imagenet), [recht2019imagenet](http://arxiv.org/pdf/1906.02168v3), COCO object
detection [lin2014coco](lin2014coco), and ADE20K semantic
segmentation [zhou2018semantic](zhou2018semantic). For the 3B model
experiments, we also report the accuracy on Kinetics-400 video action
recognition [kay2017kinetics](kay2017kinetics).
- *Image classification*. ImageNet-1K V1 and V2 val are
used [deng2009imagenet](deng2009imagenet), [recht2019imagenet](http://arxiv.org/pdf/1906.02168v3) for
evaluation. ImageNet-22K [deng2009imagenet](deng2009imagenet) which has
14M images and 22K categories is optionally employed for
pre-training. For the pre-training our largest model SwinV2-G, a
privately collected ImageNet-22K-ext dataset with 70 million images
is used. For this dataset, a duplicate removal
process [radford2021clip](http://arxiv.org/pdf/2404.19696v1) is conducted to exclude
overlapping images with ImageNet-1K V1 and V2 validation sets.
- *Object detection*. COCO [lin2014coco](lin2014coco) is used for
evaluation. For our largest model experiments, we employ an
additional detection pre-training phase using Object 365 v2
dataset [Shao_2019_ICCV](Shao_2019_ICCV), in-between the image
classification pre-training phase and the COCO fine-tuning phase.
- *Semantic segmentation*. ADE20K [zhou2018semantic](zhou2018semantic) is
used.
- *Video action classification*. Kinetics-400
(K400) [kay2017kinetics](kay2017kinetics) is used in evaluation.
The pre-training and fine-tuning settings will be detailed in Appendix.
## Scaling Up Experiments
We first present the results on various representative visual benchmarks
by scaling up models to 3 billion parameters and to high image/window
resolutions.
#### Settings for SwinV2-G experiments
We adopt a smaller $192\times 192$ image resolution in pre-training to
save on training costs. We take a 2-step pre-training approach. First,
the model is pre-trained using a self-supervised
method [simmim](simmim) on the ImageNet-22K-ext dataset by 20
epochs. Second, the model is further pre-trained by 30 epochs using the
image classification task on this dataset. Detailed pre-training and
fine-tuning setups are described in the appendix.
In the following paragraphs, we report the accuracy of SwinV2-G on
representative vision benchmarks. Note that since our main goal is to
explore how to feasibly scale up model capacity and window resolution,
and whether the vision tasks can benefit from significantly larger
capacity, we did not particularly align complexities or pre-training
data in comparisons.
#### ImageNet-1K image classification results
Table [tab:sota_imagenet] compares the
SwinV2-G model with previously largest/best vision models on ImageNet-1K
V1 and V2 classification. SwinV2-G is the largest dense vision model to
present. It achieves a top-1 accuracy of 84.0% on the ImageNet V2
benchmark, which is +0.7% higher than previous best one (83.3%). Our
accuracy on ImageNet-1K V1 is marginally lower (90.17% vs 90.88%). The
performance difference might come from different degrees of dataset
over-tuning [recht2019imagenet](http://arxiv.org/pdf/1906.02168v3). Also note we employ much
less training iterations and lower image resolutions than those in
previous efforts, while performing very well.
We also compare the SwinV2-B and SwinV2-L to the original SwinV1-B and
SwinV1-L, respectively, where a +0.8% and +0.4% gains are observed. The
shrunken gains by SwinV2-L than that of SwinV2-B may imply that if
exceeding this size, more labeled data, stronger regularization, or
advanced self-supervised learning methods are required.
#### COCO object detection results
Table [tab:sota_coco] compares the SwinV2-G
model with previous best results on COCO object detection and instance
segmentation. It achieves 63.1/54.4 box/max AP on COCO test-dev, which
is +1.8/1.4 higher than previous best numberw (61.3/53.0 by
[xu2021endtoend](http://arxiv.org/pdf/2108.10520v3)). This suggests that scaling up vision
model is beneficial for the dense vision recognition task of object
detection. Our approach can use a different window size at test to
additionally benefit, probably attributed to the effective Log-spaced
CPB approach.
#### ADE20K semantic segmentation results
Table [tab:sota_ade] compares the SwinV2-G
model with previous best results on the ADE20K semantic segmentation
benchmark. It achieves 59.9 mIoU on ADE20K val set, +1.5 higher than the
previous best number (58.4 by [bao2021beit](http://arxiv.org/pdf/2203.05796v1)). This
suggests scaling up vision model is beneficial for pixel-level vision
recognition tasks. Using a larger window size at test time can
additionally bring +0.2 gains, probably attributed to the effective
Log-spaced CPB approach.
#### Kinetics-400 video action classification results
Table 1 compares the SwinV2-G model
with previous best results on the Kinetics-400 action classification
benchmark. It achieves 86.8% top-1 accuracy, +1.4% higher than previous
best number [ryoo2021tokenlearner](http://arxiv.org/pdf/2106.11297v4). This suggests that
scaling up vision models also benefits video recognition tasks. In this
scenario, using a larger window size at test time can also bring
additional benefits of +0.2%, probably attributed to the effective
Log-spaced CPB approach.
| Backbone | pre-norm | `\cite`{=latex} | `\cite`{=latex} | |
|:--------:|:--------:|:----------------:|:----------------:|:--------:|
| Swin-S | 83.2 | 82.6 | 83.3 | **83.6** |
| Swin-B | 83.6 | \- | 83.6 | **84.1** |
| | | | | |
Comparison with other normalization methods. The post-norm method
diverges at the default learning rate, and we use 1/4 of the default
learning rate for this method. Sandwich performs worse than ours,
probably because it sacrifices expressiveness.
## Ablation Study
#### Ablation on res-post-norm and scaled cosine attention
Table 2 ablates the performance of
applying the proposed res-post-norm and scaled cosine attention
approaches to Swin Transformer. Both techniques improve the accuracy at
all the tiny, small and base size, and the overall improvements are
+0.2%, +0.4% and +0.5% respectively, indicating the techniques are more
beneficial for larger models. It also turns out to benefit ViT
architecture (+0.4%). The proposed normalization approach also performs
better than some other normalization methods, as shown in
Table 3.
More importantly, the combination of post-norm and scaled cosine
attention stabilize the training. As shown in
Figure 2, while the activation values at deeper
layers for the original Swin Transformer are almost exploded at large
(L) size, those of the new version have much milder behavior. On a huge
size model, the self-supervised pre-training [simmim](simmim)
diverges using the original Swin Transformer, while it trains well by a
Swin Transformer V2 model.
#### Scaling up window resolution by different approaches
Table [tab:lcpb] and
4 ablate the performance of 3
approaches by scaling window resolutions from $256\times 256$ in
pre-training to larger sizes in 3 down-stream vision tasks of
ImageNet-1K image classification, COCO object detection, and ADE20K
semantic segmentation, respectively. It can be seen that: 1) Different
approaches have similar accuracy in pre-training (81.7%-81.8%); 2) When
transferred to down-stream tasks, the two continuous position bias (CPB)
approaches perform consistently better than the parameterized position
bias approach used in Swin Transformer V1. Compared to the linear-spaced
approach, the log-spaced version is marginally better; 3) The larger the
change in resolutions between pre-training and fine-tuning, the larger
the benefit of the proposed log-spaced CPB approach.
In Table [tab:lcpb] and
4, we also report the accuracy
using targeted window resolutions without fine-tuning (see the first
number in each column in the ImageNet-1K experiments). The recognition
accuracy remains not bad even when the window size is enlarged from $8$
to $24$ (78.9% versus 81.8%), while the top-1 accuracy of the original
approach significantly degrades from 81.7% to 68.7%. Also note that
without fine-tuning, using a window size of $12$ that the pre-trained
model has never seen before can even be +0.4% higher that the original
accuracy. This suggests that we can improve accuracy through test-time
window adjustment, as also observed in
Table [tab:sota_coco],
[tab:sota_ade] and
1.
# Conclusion
We have presented techniques for scaling Swin Transformer up to 3
billion parameters and making it capable of training with images of up
to 1,536$\times$``{=html}1,536 resolution, including the
*res-post-norm* and *scaled cosine attention* to make the model easier
to be scaled up in capacity, as well a log-spaced continuous relative
position bias approach which lets the model more effectively transferred
across window resolutions. The adapted architecture is named Swin
Transformer V2, and by scaling up capacity and resolution, it sets new
records on 4 representative vision benchmarks. By these strong results,
we hope to stimulate more research in this direction so that we can
eventually close the capacity gap between vision and language models and
facilitate the joint modeling of the two domains.
# Acknowledgement [acknowledgement]
We thank many colleagues at Microsoft for their help, in particular,
Eric Chang, Lidong Zhou, Jing Tao, Aaron Zhang, Edward Cui, Bin Xiao, Lu
Yuan, Peng Cheng, Fan Yang for useful discussion and the help on GPU
resources and datasets.
# Experimental Settings for Ablation
This section describes the experimental settings for ablation, including
models of SwinV2-T, SwinV2-S, and SwinV2-B, and tasks of ImageNet-1K
image classification, COCO object detection and ADE semantic
segmentation.
## ImageNet-1K Pre-training
All ablation study use the ImageNet-1K image classification task for
pre-training. We adopt an input image size (window size) of
256$\times$``{=html}256 (8$\times$``{=html}8)[^3].
Following [liu2021swin](http://arxiv.org/pdf/2208.02034v1), we employ an
AdamW [loshchilov2017decoupled](loshchilov2017decoupled) optimizer for 300 epochs
using a cosine decay learning rate scheduler with 20 epochs of linear
warm-up. A batch size of 1024, an initial learning rate of
$1\times10^{-3}$, a weight decay of 0.05, and gradient clipping with a
max norm of 5.0 are used. Augmentation and regularization strategies
include RandAugment [cubuk2020randaugment](cubuk2020randaugment),
Mixup [zhang2017mixup](zhang2017mixup),
Cutmix [yun2019cutmix](yun2019cutmix), random
erasing [zhong2020random](zhong2020random) and stochastic
depth [huang2016deep](huang2016deep). An increasing degree of stochastic
depth augmentation is employed for larger models, i.e. $0.2, 0.3, 0.5$
for tiny, small, and base models, respectively.
## Fine-tuning on various tasks
#### ImageNet-1K image classification
For ImageNet-1K image classification experiments, we conduct a
fine-tuning step if the input image resolution is larger than that in
the pre-training step. The fine-tuning lasts for 30 epochs, with an
AdamW [loshchilov2017decoupled](loshchilov2017decoupled) optimizer, a cosine decay
learning rate scheduler with an initial learning rate of
$4\times10^{-5}$, a weight decay of $1\times10^{-8}$, and the same data
augmentation and regularizations as those in the first stage.
#### COCO object detection
We use cascade mask R-CNN [he2017mask](he2017mask), [cai2018cascade](cai2018cascade)
implemented in mmdetection [chen2019mmdetection](chen2019mmdetection) as the
object detection framework. In training, a multi-scale
augmentation [carion2020detr](carion2020detr), [sun2020sparsercnn](sun2020sparsercnn) with the
shorter side between 480 and 800 and the longer side of 1333 is used.
The window size is set 16$\times$``{=html}16. An
AdamW [loshchilov2017decoupled](loshchilov2017decoupled) optimizer with an initial
learning rate of $1\times10^{-4}$, a weight decay of 0.05, a batch size
of 16, and a 3$\times$ scheduler are used.
#### ADE20K semantic segmentation
We adopt an image size (window size) of 512$\times$``{=html}512
(16$\times$``{=html}16). In training, we employ an
AdamW [loshchilov2017decoupled](loshchilov2017decoupled) optimizer with an initial
learning rate of $4\times10^{-5}$, a weight decay of 0.05, a learning
rate scheduler that uses linear learning rate decay and a linear warm-up
of 1,500 iterations. Models are trained with batch size of 16 for 160K
iterations. We follow the mmsegmentation codebase to adopt augmentations
of random horizontal flipping, random re-scaling within ratio range
\[0.5, 2.0\] and a random photometric distortion. Stochastic depth with
ratio of $0.3$ is applied for all models. A layer-wise learning rate
decay [bao2021beit](http://arxiv.org/pdf/2203.05796v1) of 0.95 is adopted for all
experiments.
# Experimental Settings for System-Level Comparison
## SwinV2-B and SwinV2-L Settings
Table 2, 3 and 4 include results of SwinV2-B and SwinV2-L. For these
experiments, we first conduct ImageNet-22K pre-training, and then
fine-tune the pre-trained models on individual down-stream recognition
tasks.
#### ImageNet-22K pre-training
Both models use an input image size (window size) of
192$\times$``{=html}192 (12$\times$``{=html}12). We
employ an AdamW optimizer [loshchilov2017decoupled](loshchilov2017decoupled) for
90 epochs using a cosine learning rate scheduler with 5-epoch linear
warm-up. A batch size of 4096, an initial learning rate of 0.001, a
weight decay of 0.1, and gradient clipping with a max norm of 5.0 are
used. Augmentation and regularization strategies include
RandAugment [cubuk2020randaugment](cubuk2020randaugment),
Mixup [zhang2017mixup](zhang2017mixup),
Cutmix [yun2019cutmix](yun2019cutmix), random
erasing [zhong2020random](zhong2020random) and stochastic
depth [huang2016deep](huang2016deep) with ratio of 0.2.
#### ImageNet-1K image classification
We consider input image sizes of 256$\times$``{=html}256 and
384$\times$``{=html}384. The training length is set 30 epochs,
with a batch size of 1024, a cosine decay learning rate scheduler with
an initial learning rate of $4\times10^{-5}$, and a weight decay of
$1\times10^{-8}$. The ImageNet-1K classification weights are also
initialized from the corresponding ones in the ImageNet-22K model.
#### COCO object detection
We adopt HTC++ [chen2019htc](chen2019htc), [liu2021swin](http://arxiv.org/pdf/2208.02034v1) for experiments.
In data pre-processing, Instaboost [fang2019instaboost](fang2019instaboost),
a multi-scale training [ghiasi2019fpn](ghiasi2019fpn) with an input
image size of 1536$\times$``{=html}1536, a window size of
32$\times$``{=html}32, and a random scale between $[0.1, 2.0]$
are used. An AdamW optimizer [loshchilov2017decoupled](loshchilov2017decoupled)
with an initial learning rate of $4\times10^{-4}$ on batch size of 64, a
weight decay of 0.05, and a $3\times$ scheduler are used. The backbone
learning rate is set $0.1\times$ of the head learning rate. In
inference, soft-NMS [Bodla2017softnms](Bodla2017softnms) is used. Both
single-scale and multi-scale test results are reported.
#### ADE20K semantic segmentation
The input image size (window size) is set
640$\times$``{=html}640 (40$\times$``{=html}40). We
employ an AdamW [loshchilov2017decoupled](loshchilov2017decoupled) optimizer with
an initial learning rate of $6\times10^{-5}$, a weight decay of 0.05, a
linear decayed learning rate scheduler with 375-iteration linear
warm-up. The model is trained with batch size of 64 for 40K iterations.
We follow the default settings in mmsegmentation for data augmentation,
including random horizontal flipping, random re-scaling within ratio
range $[0.5, 2.0]$ and random photometric distortion. Stochastic depth
with ratio of $0.3$ is applied.
## SwinV2-G Settings
#### Stage-1 self-supervised pre-training
The model is first pre-trained using a self-supervised learning
approach [anonymous](anonymous) on the ImageNet-22K-ext dataset (70
million images) for 20 epochs. To reduce experimental overheads, we
adopt a smaller image size of 192$\times$``{=html}192. The model
is trained using the AdamW [loshchilov2017decoupled](loshchilov2017decoupled)
optimizer with a cosine decay learning rate scheduler with 30000 steps
of linear warm-up. A batch size of 9216, an initial learning rate of
$1.4\times10^{-3}$, a weight decay of 0.1, and gradient clipping with a
max norm of 100.0 are used. A light data augmentation strategy is
employed: random resize cropping with scale range of \[0.67, 1\] and a
aspect ratio range of \[3/4, 4/3\], followed by a random flipping and a
color normalization steps.
#### Stage-2 supervised pre-training
The model is further pre-trained using the class labels on the
ImageNet-22K-ext dataset. We employ an
AdamW [loshchilov2017decoupled](loshchilov2017decoupled) optimizer for 30 epochs,
using a cosine decayed learning rate scheduler with 20000 steps of
linear warm-up. A batch size of 9216, an initial learning rate of
$1.4\times10^{-3}$, a layer-wise learning rate decay of 0.87, a weight
decay of 0.1, and gradient clipping with a max norm of 100.0 are used.
Augmentation and regularization strategies include
RandAugment [cubuk2020randaugment](cubuk2020randaugment), random
erasing [zhong2020random](zhong2020random) and a stochastic
depth [huang2016deep](huang2016deep) ratio of 0.3.
#### Fine-tuning on ImageNet-1K image classification
We adopt an input image size of 640$\times$``{=html}640 for
experiments. An AdamW [loshchilov2017decoupled](loshchilov2017decoupled) optimizer
is employed for 10 epochs, using a cosine decayed learning rate
scheduler and a 2-epoch linear warm-up. A batch size of 576, an initial
learning rate of $2.1\times10^{-5}$, a weight decay of 0.1, and gradient
clipping with a max norm of 100.0 are used. Augmentation and
regularization strategies include
RandAugment [cubuk2020randaugment](cubuk2020randaugment), random
erasing [zhong2020random](zhong2020random) and a stochastic
depth [huang2016deep](huang2016deep) ratio of 0.5.
In evaluation, we test top-1 accuracy on both ImageNet-1K V1 and V2.
#### Fine-tuning on COCO object detection
We first conduct inter-mediate fine-tuning using the Objects-365 V2
dataset. In this stage, we remove the mask branch of the HTC++
framework [chen2019htc](chen2019htc), [liu2021swin](http://arxiv.org/pdf/2208.02034v1) because there are no
mask annotations. The input image resolution and window size are set as
$[800, 1024]$ and $32\times 32$, respectively. In training, an
AdamW [loshchilov2017decoupled](loshchilov2017decoupled) optimizer with initial
learning rate of $1.2\times10^{-3}$, a weight decay of 0.05 and a batch
size of 96 are used, and the training length is set 67,500 steps.
Then we fine-tune the HTC++ model on COCO dataset, with the mask branch
randomly initialized and other model weights loaded from the
Objects-365-V2 pre-trained model. In this training stage, the input
image resolution is set 1536$\times$``{=html}1536 with a
multi-scale ratio of $[0.1, 2.0]$. The window size is set
32$\times$``{=html}32. The
AdamW [loshchilov2017decoupled](loshchilov2017decoupled) optimizer is employed,
with an initial learning rate of $6\times10^{-4}$, a weight decay of
0.05, and a batch size of 96, and is trained 45,000 steps.
In test, Soft-NMS [Bodla2017softnms](Bodla2017softnms) is used. Both window
sizes of $32\times32$ and $48\times 48$ are considered.
#### Fine-tuning on ADE20K semantic segmentation
The input image size (window size) is set
640$\times$``{=html}640 (40$\times$``{=html}40). An
AdamW optimizer [loshchilov2017decoupled](loshchilov2017decoupled) is employed,
with an initial learning rate of $4\times10^{-5}$, a weight decay of
0.05, a linear decayed learning rate scheduler with 80K iterations, a
batch size of 32, and a linear warm-up of 750 iterations. For
augmentations, we follow the default settings in mmsegmentation to
include random horizontal flipping, random re-scaling within ratio range
$[0.5, 2.0]$ and random photometric distortion. The stochastic depth
ratio is set $0.4$.
#### Fine-tuning on Kinetics-400 video action recognition
A 2-stage fine-tuning process is employed. In the first stage, an input
resolution of 256$\times$``{=html}256$\times$``{=html}8
with 16$\times$``{=html}16$\times$``{=html}8 window size
is adopted. We employ the AdamW optimizer for 20 epochs using a cosine
decayed learning rate scheduler with 2.5-epoch linear warm-up. Other
training hyper-parameters are: batch-size 80, an initial learning rate
of $3.6\times10^{-4}$, and a weight decay of 0.1.
In the second stage, we further fine-tune the model using a larger input
video resolution of
320$\times$``{=html}320$\times$``{=html}8 with
20$\times$``{=html}20$\times$``{=html}8 window size. We
employ the AdamW optimizer for 5 epochs using a cosine decayed learning
rate scheduler with 1-epoch linear warm-up. A batch-size of 64, an
initial learning rate of $5\times10^{-5}$ and a weight decay of 0.1 are
set.
# Learnt Relative Position Bias by Different Approaches
Figure [fig:rpe_s0b0] visualizes the relative
position bias matrices ($\hat{B} \in \mathbb{R}^{(2M-1)\times (2M-1)}$)
learnt by different bias computation approaches, using a SwinV2-T model.
The bias matrices of the 3 heads in the first block are visualized. The
left shows the bias matrices learnt by using an input image size of
256$\times$``{=html}256 and a window size of $8\times 8$. The
right shows the bias matrices after fine-tuning on a larger input image
resolution of 512$\times$``{=html}512 and a larger window size
of 16$\times$``{=html}16. It turns out that the bias matrices
learnt by two CPB(continuous position bias) approaches are more smoothly
than that learnt by P-RPE (parameterized relative position bias).
Figure [fig:rpe_s3b0] shows more examples
using the last block of this model.
[^1]: Equal. $^\dag$Project lead. Ze, Yutong, Zhuliang, Zhenda, Yixuan,
Jia are long-term interns at MSRA.
[^2]: There have been a few alternative normalization configurations,
such as post-normalization [vaswani2017attention](vaswani2017attention) and
sandwich normalization [ding2021cogview](ding2021cogview).
Post-normalization harms training
stability [xiongLN2020](http://arxiv.org/pdf/2001.01679v19), and sandwich normalization
sacrifices representation power due to too many normalization
layers.
[^3]: Most of our experiments have the window size as an even number to
make the window shifting offset divisible by the window size.
Nevertheless, an odd number of window size also works well, as is
right the case in the original Swin Transformer ($7\times 7$).