Most current document processing models often struggle with maintaining context and coherence across multiple pages, leading to fragmented and inaccurate outputs. Some recent models have developed techniques to handle a document as a whole, and not page by page
. However, these advancements are still in their early stages and face several challenges. For instance, managing long-range dependencies within lengthy documents requires substantial computational resources, and ensuring the coherence and accuracy of information throughout the entire document remains a complex task. We review here some methods allowing multiple page document understanding.
We classify them in 2 types: those requiring an OCR module that first extracts text from documents, and those not depending on OCR tools:
##
1. OCR-free Models (VLMs) for multipage document handling
Modern LVLMs still struggle to achieve fine-grained document understanding, such as OCR/translation/caption for regions of interest to the user, tasks that require the context of the entire page, or even multiple pages. Accordingly, this paper proposes Fox, an effective pipeline, hybrid data, and tuning strategy, that catalyzes LVLMs to focus anywhere on single/multi-page documents. We introduce a novel task to boost the document understanding by making LVLMs focus attention on the document-level region, such as redefining full-page OCR as foreground focus. We employ multiple vision vocabularies to extract visual hybrid knowledge for interleaved document pages (e.g., a page containing a photo). Meanwhile, we render cross-vocabulary vision data as the catalyzer to achieve a full reaction of multiple visual vocabularies and in-document figure understanding. Further, without modifying the weights of multiple vision vocabularies, the above catalyzed fine-grained understanding capabilities can be efficiently tuned to multi-page documents, enabling the model to focus anywhere in both format-free and page-free manners. Besides, we build a benchmark including 9 fine-grained sub-tasks (e.g., region-level OCR/summary, color-guided OCR) to promote document analysis in the community. The experimental results verify the superiority of our model.
Show Paper Content
# Introduction [intro]
Recently, research on Large Vision-Language
Models [GPT4](https://arxiv.org/pdf/arXiv preprint arXiv:2303.08774), [minigpt4](http://arxiv.org/pdf/2402.17510v1), [Flamingo](http://arxiv.org/pdf/2205.07065v1) has been an attractive
direction. These models not only easily handle some conventional vision
tasks (*e.g.*, Image Caption [coco_text](http://arxiv.org/pdf/1707.08831v1),
OCR [OCRVQA](http://arxiv.org/pdf/2010.02582v1)), but also demonstrate powerful reasoning
capabilities like humans.
The LVLMs mostly give responses by leveraging large language
models [OPT](http://arxiv.org/pdf/2405.04515v2), [vicuna](https://lmsys.org/blog/2023-03-30-vicuna/), [T5](http://arxiv.org/pdf/1910.10683v4) to follow language instructions
while referring to the vision vocabulary to understand the input image.
Some researchers attempt to adopt LVLMs to advance the understanding of
large-resolution (*e.g.*, 833$\times$``{=html}1132) document
pages. For example, UReader [ye2023ureader](http://arxiv.org/pdf/2311.13165v1) crops the
input image into smaller patches to align with a CLIP-style vision
vocabulary of input size 224$\times$``{=html}224. Later,
TextMonkey [liu2024textmonkey](http://arxiv.org/pdf/2403.14252v1) divides the input image
into 448$\times$``{=html}448 patches and uses Openclip’s
ViT-bigG [openclip_ilharco_2024_10469088](openclip_ilharco_2024_10469088) along with a
resampling strategy to retain useful image tokens.
LLaVA-NeXT [liu2024llavanext](https://llava-vl.github.io/blog/2024-01-30-llava-next/) adopts CLIP-ViT-L-336px to
perform visual perception and splits the input image into smaller
patches to encode independently.
InternVL-V1.5 [chen2024far_intervl1.5](http://arxiv.org/pdf/2404.16821v2) proposes a
stronger vision vocabulary InternViT-6B with the input size of
448$\times$``{=html}448. Similarly, to capture more details of
the input image, InternVL-V1.5 [chen2024far_intervl1.5](http://arxiv.org/pdf/2404.16821v2)
dynamically divides the input image into 1 to 12 tiles. Different from
the methods above, without cropping patches,
Vary [wei2023vary](http://arxiv.org/pdf/2312.06109v1) writes an extra
SAM-style [SAM](http://arxiv.org/pdf/2305.01275v1) vision vocabulary specific to document
and chart data, running in parallel with the CLIP branch. Vary can
directly encode 1024$\times$``{=html}1024 page into 256 image
tokens with a high compression ratio.
The patch-based
models [ye2023ureader](http://arxiv.org/pdf/2311.13165v1), [liu2024textmonkey](http://arxiv.org/pdf/2403.14252v1), [liu2024llavanext](https://llava-vl.github.io/blog/2024-01-30-llava-next/), [chen2024far_intervl1.5](http://arxiv.org/pdf/2404.16821v2)
mostly employ CLIP-style vision vocabulary with small resolution, so a
large-scale document needs to be decomposed into many patches/tiles. A
patch/tile is independently encoded to 256 image tokens, and
InternVL-V1.5 [chen2024far_intervl1.5](http://arxiv.org/pdf/2404.16821v2) even produces
3,328 image tokens during training. However, numerous image tokens are
difficult to extend to multi-page documents for contextual
understanding. More importantly, there may still be dense characters on
these cropped patches, but CLIP-style vision vocabulary compresses
limited sparse information of small input images via global contrastive
learning, preventing these models from losslessly recovering the content
of the original document (, full-page OCR). Although
Vary [wei2023vary](http://arxiv.org/pdf/2312.06109v1) enjoys a high compression ratio and
avoids cropping patches by directly encoding the document page, the lack
of full collaboration across multiple vision vocabularies limits the
performance. For example, given an input document page,
Vary [wei2023vary](http://arxiv.org/pdf/2312.06109v1) tends to only activate the SAM-style
ViT branch due to the specific-vocabulary visual bias. In addition, the
above models are sensitive to document format (*e.g.*, multi-column) and
do not support fine-grained user interaction on specific regions on
documents.
Another key point for the document understanding is how to carry out
fine-grained interaction, such as OCR/summarizing/captioning a region of
interest. Actually, LVLMs with human-like referential dialogue
capability for natural scenes have been investigated, such as
Shikra [chen2023shikra](http://arxiv.org/pdf/2306.15195v2) and
ChatSpot [zhao2023chatspot](http://arxiv.org/pdf/2307.09474v1). They introduce referring
spatial coordinates to refer to the special region of the input natural
image, lifting the user experience and leading to more precise
conversations. But these models can not handle the document images due
to vision vocabulary CLIP-ViT [CLIP_radford2021learning](http://arxiv.org/pdf/2404.19696v1)
which is specific to natural scenes and has low input resolution.
Besides, CLIP-style pre-training method based on
Laion-COCO [schuhmann2021laion](http://arxiv.org/pdf/2111.02114v1) (image-phrase pairs) only
weakly write sparse visual knowledge, leading to a gap in understanding
the dense document. Thus, we may ask: *Can we devise an effective and
efficient pipeline for LVLMs to achieve the fine-grained multi-page
document understanding?*
In this paper, we propose Fox, an effective pipeline, hybrid data, and
tunning strategy, giving a pleasing answer to the above question. The
proposed Fox efficiently catalyzes the LVLM’s attention to anywhere on
single/multi-page documents in a user-friendly manner. Our solution has
three highlights: 1) *Focusing anywhere:* We introduce a novel task that
boosts document understanding by focusing on the region of interest via
fine-grained position-aware prompts, *i.e.*, click points, dragged
bounding boxes, and drawn color boxes. Notably, the dense full-page OCR
sub-task can be further optimized by being redefined as foreground
focus. 2) *Full reaction across multiple vision vocabularies:* To fully
interpret hybrid visual knowledge on interleaved document pages, we
synthesize cross-vocabulary vision data to activate multiple visual
vocabularies simultaneously to break down the specific-vocabulary bias
of visual content, catalyzing multiple vision vocabularies to a full
reaction. 3) *Supporting multi-column format and multiple pages:* With
the position-aware prompts, the pipeline of focusing anywhere can yield
robust performance regardless of document format. Moreover, benefiting
from the high compression ratio (one 1024$\times$``{=html}1024
page to 256 image tokes), we demonstrate the Fox can be efficiently
tuned to achieve the above fine-grained capabilities on multi-page
documents without modifying parameters of vision vocabulary.
As a result of the focusing catalytic process, the proposed Fox can not
only give specific-vocabulary responses (*e.g.*, page foreground OCR,
region/line-level OCR/translation) but also gain the noticeable ability
to utilize the cross-vocabulary visual knowledge (*e.g.*, color-guided
OCR, in-document figure caption). Furthermore, for more impressive
multi-page document features, Fox can give the OCR results of $region_1$
on $page_1$ and $region_n$ on $page_n$ by only one question. Note that
tasks like this with reference to cross-page content are of great
research significance. We encourage researchers to rethink the framework
design for LVLM-based document understanding and not be limited to
conventional single-page sparse QA tasks. Our contributions can be
summarized as follows:
- We introduce a series of novel tasks to boost document understanding
by enabling LVLMs to focus on document-level regions of interest. We
propose an effective and efficient solution named Fox to focus
anywhere on single/multi-page documents.
- To catalyze multiple vision vocabularies for figure-text interleaved
documents, we provide methods for generating hybrid data containing
cross-vocabulary visual elements.
- Fox is robust to documents of various formats due to the flexible
position-aware prompts. Without training vision vocabulary, our Fox
can be easily tuned to multi-page documents and gain cross-page
parsing capabilities.
- We build a fine-grained document benchmark, including 9 sub-tasks,
such as dense page OCR, region-level OCR/translation/summary,
color-guided OCR, multi-page OCR/VQA. Experimental results show that
our Fox outperforms other LVLMs by a large margin.
# Related Works
## Visual Document Understanding
Visual document understanding is widely investigated in the research
field of computer vision. Optical Character Recognition (OCR) is a basic
task, which plays a key role in document
digitalization [smith2007overview](http://arxiv.org/pdf/1003.5893v1), [moysset2017full](http://arxiv.org/pdf/1704.08628v1). The
layout analysis task [zhong2019publaynet](http://arxiv.org/pdf/1908.07836v1) aims to detect
various document elements and facilitate to understanding of spatial
relationships between them. We believe that OCR is a good task to test
whether LVLMs can compress documents losslessly. Besides, for
translation and
summary [vaswani2017attention](http://arxiv.org/pdf/2107.08000v1), [dong2019unified](http://arxiv.org/pdf/2212.06742v2) tasks, the
proposed Fox can directly give answers for document images via the
multimodal framework.
## Large Language Models
In recent times, the success of LLMs has ignited the fields of natural
language processing (NLP) and artificial general intelligence (AGI). The
LLMs are built with the popular transformer framework which is explored
by earlier NLP research, *e.g.*, BERT [Bert](http://arxiv.org/pdf/1810.04805v2),
GPT-2 [GPT-2](http://arxiv.org/pdf/2203.12926v1), T5 [T5](http://arxiv.org/pdf/1910.10683v4), and so on.
Afterward, it is discovered that when the model parameters are expanded
to a certain size, the language model will be greatly boosted due to the
so-called "emergent ability" [wei2022emergent](http://arxiv.org/pdf/2403.15796v2). Further,
the "GPT time" comes with amazing dialogue robots optimized by
Reinforcement Learning with Human
Feedback [RLHF_christiano2017deep](http://arxiv.org/pdf/2007.12904v2), *e.g.*,
InstructGPT [InstructGPT](http://arxiv.org/pdf/2302.05206v1) and
ChatGPT [ChatGPT](https://openai.com/blog/chatgpt/). Following that,
OPT [OPT](http://arxiv.org/pdf/2405.04515v2), LLaMA [llama](http://arxiv.org/pdf/2402.08075v1), and
GLM [GLM](http://arxiv.org/pdf/2004.13270v1) are accessible to the community to pursue the
performance like the GPT family. Based on the open-source LLMs, for more
specific requirements, some fine-tuned models have merged, such as
Alphaca [alpaca](https://github.com/tatsu-lab/stanford_alpaca) and Vicuna [vicuna](https://lmsys.org/blog/2023-03-30-vicuna/),
which also play critical roles in later Large Vision-Language Models.
## Large Vision-Language Models
For vision-centric tasks, Large Vision-Language Models
(LVLMs) [llava](http://arxiv.org/pdf/2402.11690v1), [Flamingo](http://arxiv.org/pdf/2205.07065v1), [lu2024deepseek](http://arxiv.org/pdf/2402.17510v1) have been
developed by connecting the vision networks to LLMs.
CLIP-ViT [CLIP_radford2021learning](http://arxiv.org/pdf/2404.19696v1) is a mature
pre-trained vision vocabulary widely used to inject visual modality into
language models. To ensure that LLMs can understand the visual context,
LLaVA [llava](http://arxiv.org/pdf/2402.11690v1) places the linear layers to project visual
tokens into text space. Later, beyond natural scenes, LVLMs for
large-resolution documents have emerged.
UReader [ye2023ureader](http://arxiv.org/pdf/2311.13165v1) is developed based on the LVLM
mPLUG-Owl [ye2023mplug](http://arxiv.org/pdf/2405.00390v2).
UReader [ye2023ureader](http://arxiv.org/pdf/2311.13165v1) devise a shape-adaptive approach
to crop input images into 224$\times$``{=html}224 patches and
feed them into CLIP vision encoder. Following
Qwen-VL [Qwen-VL](http://arxiv.org/pdf/2308.12966v3),
TextMonkey [liu2024textmonkey](http://arxiv.org/pdf/2403.14252v1) uses a more powerful
vision vocabulary Openclip’s
ViT-bigG [openclip_ilharco_2024_10469088](openclip_ilharco_2024_10469088) with
448$\times$``{=html}448 input size to endoce each cropped patch.
With the strategy of cropping patches,
LLaVA-NeXT [liu2024llavanext](https://llava-vl.github.io/blog/2024-01-30-llava-next/) adopts CLIP-ViT-L-336px to
perform visual perception. Similarly, to capture more details,
InternVL-V1.5 [chen2024far_intervl1.5](http://arxiv.org/pdf/2404.16821v2) dynamically
divides the input image into 1 to 12 tiles of
448$\times$``{=html}448. In contrast, without cropping patches,
Vary [wei2023vary](http://arxiv.org/pdf/2312.06109v1) writes an extra
SAM-style [SAM](http://arxiv.org/pdf/2305.01275v1) 1024$\times$``{=html}1024 vision
vocabulary specific to document and chart data, running in parallel with
the CLIP branch.
Compared to the above models, we believe that document understanding
should move towards more fine-grained (*e.g.,* region-level
OCR/translation) and multi-page tasks. Imagine how cool it would be if
we could use the LVLM like a reading pen! In this paper, we introduce
Fox which can achieve fine-grained features by focusing anywhere on
multi-page documents.
# Methods
In this section, we will elaborate on the details of the proposed Fox.
First, we introduce the flexible pipeline which supports
single/multi-page document understanding. Second, we provide the
strategy to produce the data containing hybrid visual elements to
activate multiple vocabularies concurrently. Last, we unify multi-task
data with position-aware prompts to conduct the focusing process.
## Framework for Focusing Anywhere
As illustrated in
Figure 2, the architecture of the
proposed Fox is built with two vision vocabularies, a large language
model, and embedding linear layers. Specifically, to better handle
figure-text interleaved large-resolution documents, there are two vision
vocabularies, including natural content-aware
CLIP-ViT [CLIP_radford2021learning](http://arxiv.org/pdf/2404.19696v1) and artificial
content-aware Vary-tiny [wei2023vary](http://arxiv.org/pdf/2312.06109v1). The overall
framework is neat and provides more user-friendly fine-grained
interactions, which can focus on the entire page and more specific
regions of interest (RoI). Impressively, the proposed Fox also supports
users to select RoIs on multiple pages at the same time, enabling
cross-page contextual understanding.
Given a set of input document pages $I=\{p_i\}_{i=1}^N$, users can
further indicate regions of interest $r_i$ on each page by clicking a
point, dragging boxes, or drawing color boxes, and then give some
language instructions $L^{instruct}$ about the questioning RoIs. $N$ is
the number of input pages. The spatial coordinates or color information
of $\{r_i\}_{i=1}^N$ is transformed into position-aware prompts and
combined with $L^{instruct}$ to produce complete referential
instructions. Meanwhile, two vision vocabularies will produce 256 image
tokens $v^C_i \in \mathbb{R}^{256\times1024}$ and
$v^S_i \in \mathbb{R}^{256\times1024}$ for each page $p_i$. These image
tokens $\{v^C_i\}_{i=1}^N$ and $\{v^S_i\}_{i=1}^N$ are sent into linear
layers $W^C$ and $W^S$ to align with linguistic space. Then, the final
image tokens $v_i \in \mathbb{R}^{256\times2048}$ can be obtained by
concatenation. Note that $v_i$ is compressed into cross-vocabulary
content, including dense characters and figures. Finally, with the
projected image tokens and referential instructions, LLM will generate
the response sequence $Q$ in an auto-regressive manner. The above
process can be formulated as follows:
$$\{v_i\}_{i=1}^N = \left[ W^C \circ \{v^C_i\}_{i=1}^N || W^S \circ \{v^S_i\}_{i=1}^N\right]$$
$$Q = \mathcal{LLM} \left( \{v_i\}_{i=1}^N, \left(L^{instruct}, \Psi \left(\{r_i\}_{i=1}^N \right)\right) \right)$$
where $\left[\cdot || \cdot \right]$ is the concatenation operation.
$\Psi(\cdot)$ denotes the normalization for spatial coordinates. Note
that multi-page ($N$ pages) image tokens $\{v_i\}_{i=1}^N$ are unified
into a sequence for cross-page contextual understanding. With the causal
masked sequence modeling, the training objective can be expressed as:
$$\mathcal{L}_t=-E_{(Q, V)\sim D}\operatorname{log} P_{\theta} \left( q_m | q_{
$$\label{eq1}
\left\{ \begin{aligned}
W_{new}^n & = \operatorname{randint}\left(\left[\alpha \cdot W^d \right], \left[\beta \cdot W^d\right] \right), H_{new}^n = \left[W_{new}^n/W^n \cdot H^n \right], & \text{if} \ W^n/H^n > W^d/H^d \\
H_{new}^n & = \operatorname{randint}\left(\left[\eta \cdot H^d \right], \left[\gamma \cdot H^d\right] \right), W_{new}^n = \left[H_{new}^n/H^n \cdot W^n \right], & \text{if} \ W^n/H^n \leq W^d/H^d\\
\end{aligned} \right.$$
where $W_{new}^n$/$H_{new}^n$ denote the desired width/height of the
scaled natural image. $\left[\cdot\right]$ means the integral function.
$\alpha$, $\beta$, $\eta$, and $\gamma$ are the hyperparameters that
control the scaling ratio, and they are set to 0.3, 0.9, 0.4, and 0.9,
respectively. Then, we randomly pick a suitable location
$(x^n_1, y^n_1, x^n_2, y^n_2)$ on the page to place the scaled natural
image. What’s more, to make the interleaved data reasonable and delete
the occluded text on this page, we calculate the intersection of union
(IoU) between $(x^n_1, y^n_1, x^n_2, y^n_2)$ and the vanilla text boxes
$\left\{ (x^d_{i,1}, y^d_{i,1}, x^d_{i,2}, y^d_{i,2}) \right\}_{i=1}^{N_d}$,
and fill the text boxes overlapped by the natural image with the white
color. $N_d$ is the number of text boxes on this document page. So, we
can obtain cross-vocabulary image-text pairs for in-document figure
caption. The text for each interleaved page includes the filtered
optical characters and the description of the pasted natural image.
#### Color-text hybrid data.
CLIP is written with the knowledge for recognizing colors, while the
Vary-tiny is not. We produce color-text hybrid data to further activate
multiple vocabularies, which is the key to enabling Fox to support the
conversations for users’ color-guided RoI. We randomly select three text
boxes and paint them directly on the document page in red, blue, and
green colors. The proposed Fox is expected to directly give the OCR
results in the area with the questioning color.
## Triggering Focusing Process via Fine-grained Instruction-following Tasks
We devise fine-grained instructions based on several position-aware text
prompts, such as points, boxes, and colors, to catalyze Fox to focus any
fine-grained region on single/multi-page documents.
#### Fine-grained document understanding.
We define several novel sub-tasks to drive the model to focus on
fine-grained regions for flexible document-level understanding: 1)
Foreground OCR. We redefine the page OCR task as the foreground focus to
further boost the dense perception. The instruction can be “*Give the
OCR results of the box $(x^f_{i,1}, y^f_{i,1}, x^f_{i,2}, y^f_{i,2})$*”.
The foreground box can be obtained by some simple operations. 2)
Region-level OCR. Based on the obtained text boxes, we transform the
content of one page into multiple region-level OCRs via multi-turn
conversations. An example can be “*Give the OCR results of the box
$(x^d_{i,1}, y^d_{i,1}, x^d_{i,2}, y^d_{i,2})$*”. 3) Line-level OCR. We
pick a point near the left side of each line as the position prompt.
Then, we construct the line-level multi-turn conversations and an
example can be like “*OCR the line $(x^d_{j}, y^d_{j})$*”. 4)
Color-guided OCR. Using the color-text hybrid data in
Section 3.2, we define the corresponding
cross-vocabulary task by some color-guided questions, such as “*OCR red
box*” and “*OCR blue box*”. 5) Region-level translation and summary. We
filter and retain the boxes with text lengths over 400 on each page.
Then, we employ GPT-3.5 [ChatGPT](https://openai.com/blog/chatgpt/) to generate the
translation and summary for each long in-box text as the corresponding
annotations. The instruction can be “*Translate/Summarize the content of
the box $(x^d_{i,1}, y^d_{i,1}, x^d_{i,2}, y^d_{i,2})$*”. 6) Document
layout: We convert the 330K high-quality annotations of
PubLayNet [zhong2019publaynet](http://arxiv.org/pdf/1908.07836v1) to the unified
conversation format. Further, we sample 1M extra PDF pages and use
PaddleOCRv2 [paddleocrv2_du2021pp](http://arxiv.org/pdf/2109.03144v2) tools to generate
pseudo layout annotations.
#### In-document figure understanding.
Based on the synthetic interleaved data, we organize the
cross-vocabulary image-text pairs into two sub-tasks: 1) In-document
figure caption. As a result of the added position-aware prompts, an
example language instruction is as follows: “*Give a brief description
for the region $(x^n_1, y^n_1, x^n_2, y^n_2)$ of the image*”. The box
denotes the boundary of the figure. 2) In-document in-figure chat. The
RegionChat [zhao2023chatspot](http://arxiv.org/pdf/2307.09474v1) dataset is built for
referential dialogue on natural images. After rendering it on PDF pages,
with spatial coordinates of the referring region, we can ask the
proposed Fox the following question: “*What can you see in this region?
$(x^n_1, y^n_1, x^n_2, y^n_2)$*”. At a more fine-grained level, the RoI
can be the box within the figure on the document page.
#### Extension for multi-page documents.
The proposed Fox can be easily tuned to focus on multiple regions of
multi-page documents using simple instructions. As a forerunner, we
define two basic yet interesting multi-page sub-tasks and give
position-aware instruction examples. 1) Multi-page region-level OCR:
“*OCR boxes on multiple pages. Page 1: $(x^1_1, y^1_1, x^1_2, y^1_2)$,
Page 2: $(x^2_1, y^2_1, x^2_2, y^2_2)$, $\dots$ Page N:
$(x^N_1, y^N_1, x^N_2, y^N_2)$*”. 2) Cross-page VQA: “*Which page’s box
contains more characters? Page 1: $(x^1_1, y^1_1, x^1_2, y^1_2)$, Page
2: $(x^2_1, y^2_1, x^2_2, y^2_2)$, $\dots$ Page N:
$(x^N_1, y^N_1, x^N_2, y^N_2)$*”.
It is worth noting that all the above methods are independent of
document format. The PDF data with any format or layout, such as
single-column, double-column, interleaved, *etc.*, can be parsed to
extract positional prompts and formulated into the corresponding
conversations. With the fine-grained position-aware instructions, the
vision query pipeline enjoys high human-AI interactivity and is robust
to different formats (multi-column) and multi-page documents.
## Catalyzing Fox by Multi-page and Multi-grained Data Engine
The data engine is a key part of the proposed Fox. To ensure the
performance on multiple tasks, We carefully control the quantity and
ratio of training data, and more details are reported in
Table [tab:data].
#### Pre-training data.
In the pre-training stage, we formulate a large number of multimodal
task-driven data. Specifically, for hybrid images of in-document caption
and chat sub-tasks, we render the BLIP558K [llava](http://arxiv.org/pdf/2402.11690v1) data,
1M natural images sampled in
Laion-COCO [schuhmann2021laion](http://arxiv.org/pdf/2111.02114v1) and
RegionChat100K [zhao2023chatspot](http://arxiv.org/pdf/2307.09474v1) data into an equal
amount of document pages sampled in prepared PDF data. For fine-grained
optical character understanding, we formulate 6 types of 4.6M document
image-text pairs, containing box/line/color position-aware prompts and
OCR/translation/summary interactive task forms. Further, we generate
800K multi-page data, including multi-page multi-region OCR and
cross-page QA. In addition, to maintain the general conversational
capabilities of our model, we sample 1M natural data from
Laion-COCO [schuhmann2021laion](http://arxiv.org/pdf/2111.02114v1) and NLP dialogue data
from Alpaca [alpaca](https://github.com/tatsu-lab/stanford_alpaca), Baize [xu2023baize](http://arxiv.org/pdf/2404.02406v1)
and ShareGPT.
#### SFT data.
In the supervised fine-tuning stage, To make the conversation experience
more comfortable, we sample 10K image-text pairs for each data type of
the above pre-training data, and adopt GPT3.5 [ChatGPT](https://openai.com/blog/chatgpt/)
to rewrite prompts ten times more diversified. Besides,
LLaVA80K [llava](http://arxiv.org/pdf/2402.11690v1) is also added to further tune our model
to generate pleasing answers.
#### Input and Conversation Format
For each input image, we resize it with a fixed resolution
1024$\times$``{=html}1024 before feeding it into the
SAM-style [SAM](http://arxiv.org/pdf/2305.01275v1) ViT branch and we perform a resize
operation to obtain a new image of 224$\times$``{=html}224 as
the input of the CLIP vision network. We choose
Qwen-1.8B [qwen](http://arxiv.org/pdf/2309.16609v1) with rich linguistic vocabulary as our
language model. Following the
LLaVA-MPT [llava](http://arxiv.org/pdf/2402.11690v1), [team2023introducing](http://arxiv.org/pdf/2311.16429v1) dialogue style, the
input conversation format can be summarized as follows:
\<\|im_start\|\>user: \"\"\ "*human question
\[position-aware prompts\]*"\<\|im_end\|\> \<\|im_start\|\>assistant:
"*AI responses*" \<\|im_end\|\>.
# Experiments
## Implementation Details
During the multi-task pre-training and SFT phase, the multiple vision
vocabularies (CLIP and SAM-style ViT) are frozen and only the parameters
of the embedding linear layers and language model are optimized. We
train our model using the optimizer AdamW [AdamW](http://arxiv.org/pdf/2311.11446v2) and a
cosine annealing scheduler [loshchilov2016sgdr](http://arxiv.org/pdf/1608.03983v5). The
learning rate is set to 1e-4 in pretraining and then to 2e-5 in SFT. In
both stages, we use 48 A800 GPUs with a per device batch of 4 and the
data epoch is set to 1.
## Multi-grained Benchmark and Metrics
To advance fine-grained document understanding, we build a bilingual
benchmark including 9 sub-tasks. We collect 112 English pages and 100
Chinese pages, including single/multi-column formats. The number of
words per page exceeds 1,000. These images are used to evaluate page
OCR, line-level OCR, color-guided OCR, region-level
OCR/translation/summary, multi-page multi-region OCR, and cross-page
VQA. Besides, to monitor the performance of interleaved data, we render
200 natural images sampled from
Laion-COCO [schuhmann2021laion](http://arxiv.org/pdf/2111.02114v1) onto 200 PDF pages to
evaluate the document-level in-figure caption task. The comprehensive
evaluation metrics contain normalized edit distance, F1-score,
BLEU [papineni2002bleu](http://arxiv.org/pdf/2202.11027v1),
METEOR [banerjee2005meteor](http://arxiv.org/pdf/2312.00536v1),
ROUGE [lin2004rouge](http://arxiv.org/pdf/2209.06517v2), and *etc*.
## Evaluation Results
#### Foreground focus for dense text recognition on a single page.
For the dense text recognition on the entire page, we directly input the
normalized box $\left[2, 2, 998, 998\right]$ as the foreground prompts.
As shown in Table 1 and
2, Fox showcases strong English and
Chinese dense OCR ability by almost lossless compression for the
document page. Specifically, Fox achieves the best edit distance of
0.046 and 0.061 in English and Chinese, respectively. Compared to
Vary-toy using the image-level prompts, the proposed Fox lifts the
English F1-score by 2.8% by redefining the task as foreground focus.
Note that the performance of LLaVA-NeXT and InternVL-ChatV1.5 which use
the CLIP-style vocabulary is bottle-necked, indicating that the dense
texts of each patch are not completely encoded.
#### Region focusing performance of in-document fine-grained tasks.
As shown in Table [tab:boxline], Fox can yield excellent
OCR results on various metrics under several
color-guided/region-level/line-level settings, indicating that our model
can accurately recognize the content in these randomly sampled RoIs. In
Table 3, for the region-level
translation, Fox yields an acceptable METEOR of 0.366 due to the smaller
language model of 1.8B parameters. In addition, we evaluate our model on
the fine-grained summary task and obtain a decent ROUGE-L-F score of
0.282. It is worth mentioning that this kind of usage similar to a
reading pen is exactly what users need more.
| **Fine-grained Translation** | | **Fine-grained Summary** | | | **Fine-grained Caption** | |
|:--:|:--:|:--:|:--:|:--:|:--:|:--:|
| 1-2 (rl)3-5 (rl)6-7 BLEU | METEOR | ROUGE-L R | ROUGE-L P | ROUGE-L F | METEOR | ROUGE-L F |
| 0.138 | 0.366 | 0.261 | 0.316 | 0.282 | 0.359 | 0.396 |
The performance of in-document fine-grained understanding tasks. The
fine-grained translation/summary/caption tasks are targeted at
interpreting in-document text/figure regions.
#### Cross-vocabulary focusing tasks on interleaved pages.
The color-guided task requires cross-vocabulary visual knowledge,
*i.e.*, CLIP for recognizing colors and Vary-tiny for capturing texts.
Table [tab:boxline] shows that the decent
results (0.940 and 0.884 on English and Chinese F1-score) meet our
expectations due to the collaboration across multiple vision
vocabularies. For the in-document figure caption task, we render natural
images onto document pages and ask our model “*What is this in the box
$$?*”, where $$ is the boundary of the natural image that is
pasted into the document page. As shown in
Table 3, when handling
interleaved data, Fox reaches the METEOR of 0.359 and ROUGE-L-F of 0.396
due to the full reaction of activating multiple vocabularies.
#### Exploration for focusing on multiple pages.
To verify the focusing capability of Fox on multi-page documents, we
report two relevant results in
Table 4. For the multi-page OCR task, we
ask the model to output the OCR results of 8 boxes on 8 complex pages
(in mixed English/Chinese and mixed single/multi-column formats) in a
single-turn conversation. Our Fox still performs an amazing F1-score of
0.946 and achieves true focus anywhere by parsing the entire 8-page
document simultaneously. For the cross-page visual question-answering
task which requires the model to answer which box has the largest number
of characters in multiple cross-page boxes, Fox yields a high accuracy
of 0.827, demonstrating that it is easier to perform VQA reasoning based
on successfully perceiving dense text of multiple pages.
#### Visualization.
Figure 3 shows our Fox can perform impressive
features with high human-AI interactivity. For the figure on the
academic page, Fox gives the response “global seismic hazards” which is
relevant to the content of the document. Fox can also give precise OCR
results by dense text perception. For the cartoon book, Fox can
recognize the interesting “lion” and can read the story texts for users.
This indicates that our Fox enjoys fine-grained focusing capabilities in
various scenarios.
# Conclusion and Limitations [discussion]
This paper proposes a user-friendly LVLM named Fox, which enjoys amazing
fine-grained capabilities of focusing anywhere on single/multi-page
documents. Further, after catalyzing the multiple vision vocabularies
into a full reaction, Fox gains impressive cross-vocabulary features on
figure-text interleaved pages. To advance the fine-grained document
understanding, we provide a benchmark containing comprehensive
sub-tasks. Our Fox can achieve promising scores in these experiments,
making a successful step to high human-AI interactivity on dense-content
documents. We believe that the proposed method has considerable room for
improvement (*e.g.*, the low-resolution CLIP), and we encourage more
researchers to focus on more reasonable multi-page document-level tasks.
# Appendix
We show more amazing output results of our model Fox. All testing images
are from the Internet.
[^1]: This work was done when the first author was interning at Megvii
Technology Inc.
##
2. OCR-dependent Models for multipage document handling
LongFin: A Multimodal Document Understanding Model for Long Financial Domain Documents
2024-01-26
Ahmed Masry, Amir Hajian
Document AI is a growing research field that focuses on the comprehension and extraction of information from scanned and digital documents to make everyday business operations more efficient. Numerous downstream tasks and datasets have been introduced to facilitate the training of AI models capable of parsing and extracting information from various document types such as receipts and scanned forms. Despite these advancements, both existing datasets and models fail to address critical challenges that arise in industrial contexts. Existing datasets primarily comprise short documents consisting of a single page, while existing models are constrained by a limited maximum length, often set at 512 tokens. Consequently, the practical application of these methods in financial services, where documents can span multiple pages, is severely impeded. To overcome these challenges, we introduce LongFin, a multimodal document AI model capable of encoding up to 4K tokens. We also propose the LongForms dataset, a comprehensive financial dataset that encapsulates several industrial challenges in financial documents. Through an extensive evaluation, we demonstrate the effectiveness of the LongFin model on the LongForms dataset, surpassing the performance of existing public models while maintaining comparable results on existing single-page benchmarks.
Show Paper Content
# Introduction
There has been a noticeable industrial interest surrounding the
automation of data extraction from various documents, including
receipts, reports, and forms to minimize manual efforts and enable
seamless downstream analysis of the extracted data
[zhang2020rapid](https://arxiv.org/pdf/2002.01861), [layoutlm](https://doi.org/10.1145/3394486.3403172). However, the process of
parsing documents poses several challenges, including obscure
information within scanned documents that may result in Optical
Character Recognition (OCR) errors, complex layouts (such as tables),
and intricate content structures.
To investigate and address these challenges, several datasets have been
made available. These datasets encompass a wide range of tasks, such as
classification [rvl-cdip](https://arxiv.org/pdf/2009.14457), semantic entity recognition
[cord](http://arxiv.org/pdf/2103.10213v1), [funsd](http://arxiv.org/pdf/1905.13538v2), relation extraction
[funsd](http://arxiv.org/pdf/1905.13538v2), question answering [docvqa](https://arxiv.org/pdf/2007.00398), and
key information extraction [sroie](https://doi.org/10.1109/icdar.2019.00244). Nonetheless, a
significant limitation shared by these datasets is that they mostly
consist of single-page documents with a limited amount of content. As a
consequence, these datasets fail to capture various challenges inherent
in parsing lengthy documents spanning multiple pages, which are commonly
encountered in the financial industry. Financial reports and documents
can become exceedingly lengthy, necessitating a comprehensive
understanding of the entire context to effectively analyze and extract
pertinent information.
First page from a 4-page example financial form in the
LongForms dataset. The information in these documents is spread over a
mix of tables and text spanning multiple pages which makes it
challenging for short-context models.
The limitations inherent in existing datasets have a direct impact on
the capabilities of the proposed models. In the literature, two primary
lines of work have emerged: *(i)* OCR-dependent architectures
[lilt](https://doi.org/10.18653/v1/2022.acl-long.534), [layoutlm](https://doi.org/10.1145/3394486.3403172), [layoutlmv2](https://doi.org/10.18653/v1/2021.acl-long.201), [layoutlmv3](https://doi.org/10.1145/3503161.3548112), [udop](https://arxiv.org/pdf/2212.02623) *(ii)*
OCR-free models [donut](https://arxiv.org/pdf/2111.15664), [pix2struct](https://arxiv.org/pdf/2210.03347). OCR-dependent models
typically employ transformer-based text encoders and incorporate spatial
information by leveraging the words’ coordinates in the documents as
additional embeddings. One notable exception is UDOP
[udop](https://arxiv.org/pdf/2212.02623) which consists of an encoder-decoder architecture.
Conversely, OCR-free models typically employ a vision encoder to process
the scanned document image and a text decoder to generate the desired
information. Nevertheless, a common limitation shared by most of these
models is their design and pretraining to handle a maximum of 512 tokens
or process a single input image.
In this work, we introduce two main contributions. Firstly, we present
the LongForms dataset, a comprehensive financial dataset primarily
comprising 140 long forms where the task is formulated as named entity
recognition. Due to privacy concerns and proprietary limitations, we
were unable to utilize our internal resources to construct this dataset.
Consequently, we obtained financial statements from the SEC website[^1],
aligning our tasks to encompass the significant challenges encountered
in the financial documents which require a deep understanding of lengthy
contexts. Secondly, we propose LongFin, a multimodal document
understanding model capable of processing up to 4K tokens. Our approach
builds upon LiLT [lilt](https://doi.org/10.18653/v1/2022.acl-long.534), one of the state-of-the-art
multimodal document understanding models. Additionally, we incorporate
techniques that effectively extend the capabilities of text-only models,
such as RoBERTa [roberta](https://arxiv.org/pdf/1907.11692), to handle longer sequences, as
demonstrated by Longformer [longformer](https://arxiv.org/pdf/2004.05150). By leveraging
these techniques, our proposed model exhibits enhanced performance in
processing lengthy financial forms. The efficacy of our approach is
extensively evaluated, showcasing its effectiveness and paving the way
for numerous commercial applications in this domain.
# Related Work [sec:relatedwork]
## Document Datasets
Several recently released datasets in the field of document
understanding have contributed significantly to advancing research in
this area. The RVL-CDIP dataset [rvl-cdip](https://arxiv.org/pdf/2009.14457) introduced a
classification task, encompassing 400K scanned documents categorized
into 16 classes, such as forms and emails. Another notable dataset,
DocVQA [docvqa](https://arxiv.org/pdf/2007.00398), focuses on document question answering
and comprises 50K question-answer pairs aligned with 12K scanned images.
In addition, the CORD dataset [cord](http://arxiv.org/pdf/2103.10213v1) consists of 11K
scanned receipts, challenging models to extract 54 different data
elements (e.g., phone numbers and prices). Furthermore, the FUNSD
dataset [funsd](http://arxiv.org/pdf/1905.13538v2) was proposed, featuring 200 scanned
forms. This dataset primarily revolves around two key tasks: semantic
entity recognition (e.g., header, question, answer) and relation
extraction (question-answer pairs). FUNSD is particularly relevant to
our dataset, LongForms, as it also mainly consist of forms. However,
FUNSD and all the above-mentioned datasets mainly focus on short
contexts, as they typically consist of single-page documents. In
contrast, our LongForms dataset primarily consists of multi-page
documents, presenting unique challenges that demand a comprehensive
understanding of lengthy contexts which is common in the financial
industry.
## Document AI Models
Numerous document understanding models have been developed to tackle the
challenges posed by the aforementioned benchmark datasets. These models
can be broadly categorized into two main groups: OCR-free and
OCR-dependent models. OCR-free models, exemplified by Donut
[donut](https://arxiv.org/pdf/2111.15664) and Pix2Struct [pix2struct](https://arxiv.org/pdf/2210.03347),
typically employ vision transformer-based encoders to process input
images and text decoders to handle output generation. These models are
often pretrained on OCR-related tasks, enabling them to comprehend the
text embedded within scanned documents effectively. On the other hand,
OCR-dependent models, including LayoutLM [layoutlm](https://doi.org/10.1145/3394486.3403172),
LayoutLMv2 [layoutlmv2](https://doi.org/10.18653/v1/2021.acl-long.201), LayoutLMv3
[layoutlmv3](https://doi.org/10.1145/3503161.3548112), LiLT [lilt](https://doi.org/10.18653/v1/2022.acl-long.534), DocFormer
[docformer](https://arxiv.org/pdf/2106.11539) and UDOP [udop](https://arxiv.org/pdf/2212.02623), rely on
external OCR tools to initially extract underlying text from scanned
documents. To incorporate layout information, these models utilize
specialized positional embeddings, encoding the coordinates of each word
in the document. Additionally, some models, such as LayoutLMv2,
LayoutLMv3, DocFormer, and UDOP, employ visual embeddings created by
splitting the image into patches. These visual embeddings, along with
the text and layout embeddings, are fed into the models. While LayoutLM,
LayoutLMv2, LayoutLMv3, DocFormer, and LiLT adopt an encoder-only
architecture, UDOP is based on the T5 model [t5](http://jmlr.org/papers/v21/20-074.html), which
follows an encoder-decoder architecture. Despite the impressive
achievements of these models, they share a common limitation: they are
typically designed to process a single page or a maximum of 512 tokens,
thereby restricting their applicability to multi-page documents.
[longdocument](http://arxiv.org/pdf/2108.09190v2) proposed a multimodal document
understanding model that can process up to 4096 tokens, however their
code is not publicly available and their model performance deteriorates
on the short-context datasets such as FUNSD [funsd](http://arxiv.org/pdf/1905.13538v2). In
contrast, our proposed model, LongFin, works efficiently on both short
and long contexts (to up 4096 tokens), making it particularly
well-suited for a variety of real-world industrial applications.
# LongForms Dataset [sec:longfin]
Due to privacy constraints, we are unable to utilize internal documents
for dataset construction. Instead, we turn to publicly available
financial reports and tailor our dataset, LongForms, to emulate the
challenges encountered in our proprietary datasets. This approach
ensures the task’s alignment with real-world financial contexts without
violating privacy.
## Dataset Collection & Preparation [sec:dataset_collection]
To construct LongForms, we leverage the EDGAR database [^2], a
comprehensive repository of financial filings and reports submitted by
US companies. These filings are based on different financial form types
(e.g., 10-K, 10-Q) which vary in structure and content. Our dataset
primarily centers around the SEC Form 10-Q, which provides a detailed
quarterly report on a company’s finances. This specific form is chosen
due to its similarity in both structure and content to to the documents
we frequently encounter in the financial services industry.
We download 140 10-Q forms that were published between 2018 and 2023.
This deliberate decision to keep the dataset relatively small is
intended to mirror the limited data challenges commonly encountered in
real-world scenarios, particularly in the finance domain, where strict
data confidentiality prevents access to large-scale datasets.
Consequently, it is common practice to construct smaller datasets that
mimic the proprietary datasets [madl2023approximate](https://arxiv.org/pdf/2307.01875).
Furthermore, our dataset size aligns with recently published datasets,
such as the FUNSD dataset [funsd](http://arxiv.org/pdf/1905.13538v2) which primarily
consists of single-page forms. Inspired by the FUNSD dataset, we perform
a random split of the LongForms dataset and divide the dataset into 105
training documents, which account for 75% of the total dataset, and 35
testing documents, representing the remaining 25%.
## Dataset Description & Setup [sec:task_desctiption]
Our dataset, LongForms, is formulated as a Named Entity Recognition
(NER) task. The dataset consists of $N$ examples, denoted as
$D = \{d_i, w_i, b_i, n_i\}_{i=1}^N$, where $d_i$ represents a PDF
document, $w_i$ represents the list of words, $b_i$ represents the list
of bounding boxes, and $n_i$ represents a list of entities present in
the document. To obtain the words ($w_i$) and their bounding boxes
($b_i$), each PDF document is processed using the pdftotext[^3] tool.
Moreover, we define six entity types: *(i)* Total Assets, *(ii)* Cash at
the beginning of the period (Beginning Cash), *(iii)* Cash at the end of
the period (End Cash), *(iv)* Cash provided by financial activities
(Financial Cash), *(v)* Net change in cash (Change in Cash), and *(vi)*
Quarter Keys. As shown in Table
[tab:data_stats], our LongForms
dataset contains 140 forms that consist of 685 pages, 168458 words, and
1128 entities in total. The models are trained to predict $n_i$ given
both $w_i$ and $b_i$.
# LongFin Model [sec:longlilt]
LongFinLocal + Global Atention
## Architecture
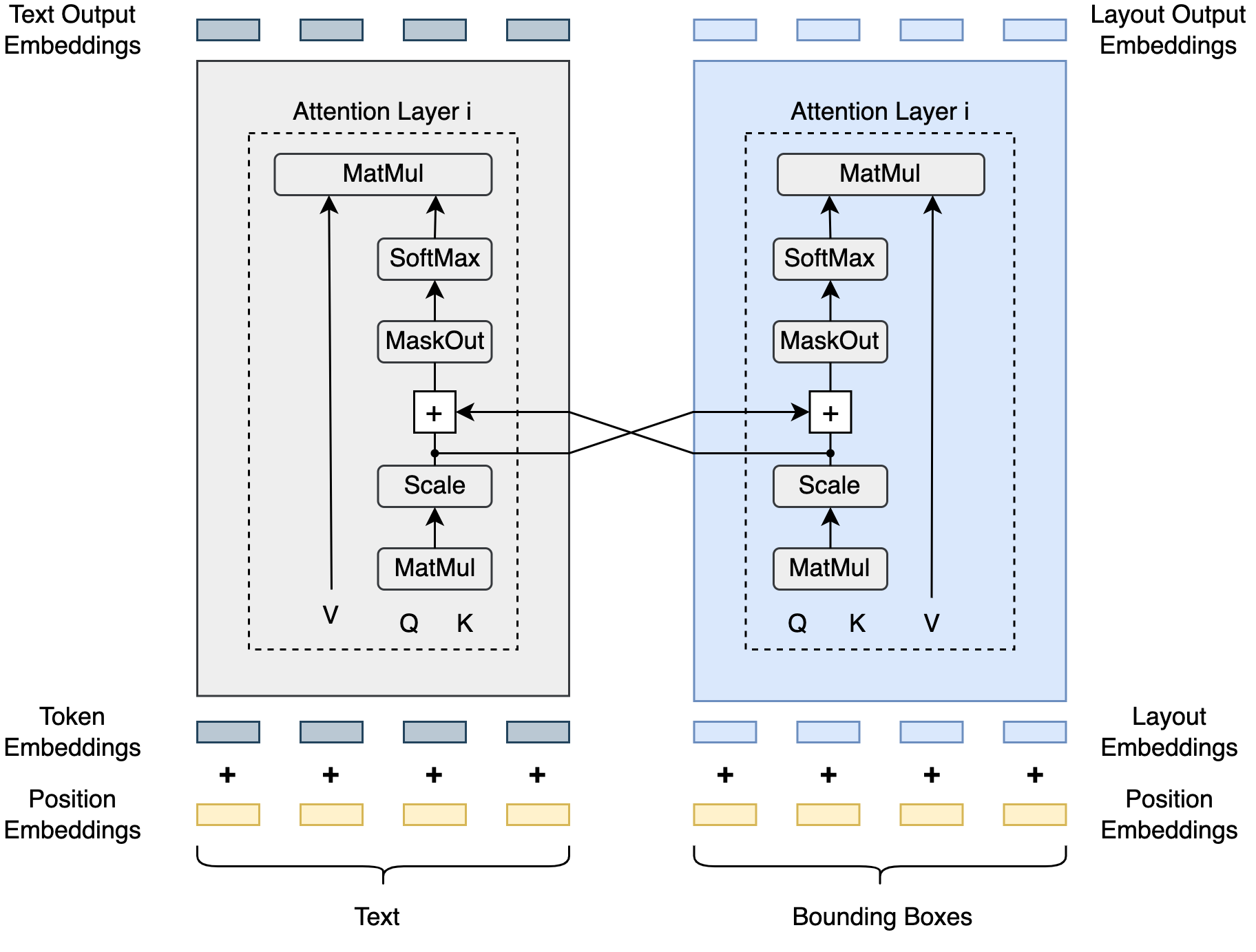
Figure [fig:models] illustrates the overall
architecture of our proposed model, LongFin, which builds upon recently
published models: LiLT [lilt](https://doi.org/10.18653/v1/2022.acl-long.534) and Longformer
[longformer](https://arxiv.org/pdf/2004.05150). Similar to LiLT [lilt](https://doi.org/10.18653/v1/2022.acl-long.534),
LongFin comprises three primary components: a text encoder, a layout
encoder, and the BiACM (bidirectional attention complementation
mechanism) layer [lilt](https://doi.org/10.18653/v1/2022.acl-long.534). However, LongFin introduces
additional mechanisms, namely sliding window local attention and
interval-based global attention, to effectively handle long contexts
within both the text and layout encoders. One key advantage of LongFin
is its ability to scale linearly with the input sequence length, in
contrast to the quadratic scaling ($O(n^2)$) observed in the original
transformers’ [vaswani2017attention](https://arxiv.org/pdf/1706.03762) attention mechanism.
This linear scaling, inspired by the Longformer model
[longformer](https://arxiv.org/pdf/2004.05150), allows LongFin to efficiently handle long
contexts up to 4K tokens.
### Text Encoder
For the text encoder in LongFin, we adopt the Longformer
[longformer](https://arxiv.org/pdf/2004.05150) model, which has been pretrained to handle
long textual contexts of up to 4096 tokens. As depicted in Figure
2, the input to the text encoder
consists of two types of embeddings: text embeddings ($E_{T}$) and
absolute position embeddings ($E_{P}$). These embeddings are added
together to produce the final embeddings ($E_{final}$). Subsequently, a
layer normalization [layernormalization](https://arxiv.org/pdf/1607.06450) operation is
applied, and the resulting output is fed into the encoder.
The attention mechanism in LongFin incorporates two types of attention:
local attention and global attention. The local attention employs a
sliding window approach, where each token attends to the 512 local
tokens surrounding it. On the other hand, the global attention involves
a set of global tokens, selected at intervals of 100. While other
approaches [longformer](https://arxiv.org/pdf/2004.05150), [longdocument](http://arxiv.org/pdf/2108.09190v2) may employ
different methods for selecting global tokens, such as random selection
or task-specific strategies, we limit our experimentation to
interval-based selection for simplicity and due to limited computational
resources. Each token in the input sequence attends to these global
tokens, in addition to its local context as shown in Figure
3. This combination of local and
global attention mechanisms enhances the model’s ability to capture both
local context and broader global dependencies within the long input
sequences.
### Layout Encoder
For the layout encoder in LongFin, we adopt the layout encoder utilized
in the LiLT model [lilt](https://doi.org/10.18653/v1/2022.acl-long.534). Similar to the text encoder,
the input for the layout encoder comprises two types of embeddings:
absolute position embeddings and layout embeddings. Each word in the
input document is associated with a bounding box that defines its
location within the document layout. This bounding box is represented by
four numbers: $x_0$, $y_0$, $x_1$, and $y_1$, which correspond to the
coordinates of the top-left and bottom-right points of the bounding box.
To normalize these coordinates within the range \[0,1000\], we use the
page’s height and width.
To generate the layout embedding for each word, each coordinate in the
normalized bounding box is used to obtain an embedding vector. The
different coordinates’ embedding vectors are then concatenated and
projected using a linear layer. The resulting layout embeddings are
added to the absolute position embeddings to obtain the final
embeddings. These final embeddings are then fed into the layout encoder.
Similar to the text encoder, we also employ the local & global attention
mechanisms in the layout encoder to process long sequences.
### BiACM
To facilitate communication between the text encoder and layout encoder,
we incorporate the BiACM layer from the LiLT model
[lilt](https://doi.org/10.18653/v1/2022.acl-long.534). As depicted in Figure
2, the BiACM layer adds the scores
resulting from the multiplication of keys and queries from both
encoders. In LiLT, a detach operation is applied to the scores generated
by the text encoder before passing them to the layout encoder. This
detachment prevents the layout encoder from backpropagating into the
text encoder during pretraining, promoting better generalization when
fine-tuning the model with different language text encoders. However,
since our focus is primarily on the English language for our
applications, we have chosen to remove the detach operation to expedite
pretraining, given our limited computational resources.
## Pretraining [sec:pretraining]
To pretrain LongFin, we utilize the IIT-CDIP [iit](https://doi.org/10.1145/1148170.1148307)
dataset which contains 11M scanned images that make up 6M documents. We
obtain the OCR annotations (words and their bounding boxes) from OCR-IDL
[ocraws](http://arxiv.org/pdf/2202.12985v1) which used the AWS Textract API[^4]. We
initialize our text encoder from Longformer [longformer](https://arxiv.org/pdf/2004.05150)
and our layout encoder from LiLT [lilt](https://doi.org/10.18653/v1/2022.acl-long.534) layout encoder.
Since the LiLT layout encoder was pretrained on inputs with a maximum
length of 512 tokens, we copy LiLT’s pretrained positional embeddings
eight times to initialize our layout encoder positional embeddings,
which consist of 4096 embedding vectors. This enables the layout encoder
to handle longer sequences while leveraging the pretrained positional
information from the LiLT model.
For the pretraining of LongFin, we employ the Masked Visual-Language
Modeling task [bert](https://arxiv.org/pdf/1810.04805), [lilt](https://doi.org/10.18653/v1/2022.acl-long.534). In this task, 15% of the
tokens in the input to the text encoder are masked. In 80% of the cases,
we replace the masked tokens with the
\[MASK\] token. In 10% of the cases, we
replace the masked tokens with random tokens. In the remaining 10%, we
keep the original token unchanged. Inspired by Longformer
[longformer](https://arxiv.org/pdf/2004.05150), we pretrain the model for 65K steps with a
learning rate of 3e-5 and batch size of 12 on one A100 GPU. We set the
warmup steps to 500 and use the AdaFactor optimizer
[shazeer2018adafactor](https://arxiv.org/pdf/1804.04235). Also, we utilize gradient
checkpointing [gradientcheckpointing](https://arxiv.org/pdf/1604.06174) to enable using a
large batch size. The pretraining loss curve is shown in Figure
4LongFin pretraining loss curve. The loss starts at 2.84 and
oscillated between 1.97 and 1.94 near convergence.
# Experiments & Evaluation [sec:evaluation]
## Tasks & Datasets
To assess the generalizability of LongFin on both short and long
contexts, we evaluate LongFin on two existing short (single-page)
datasets: FUNSD [funsd](http://arxiv.org/pdf/1905.13538v2) and CORD [cord](http://arxiv.org/pdf/2103.10213v1) to
show the generalizability of our model on short contexts as well as our
newly created LongForms dataset.
**$\bullet$** : This dataset comprises 200 scanned forms and requires
models to extract four main entities: headers, questions, answers, and
other relevant information. Additionally, it involves linking questions
with their corresponding answers, thereby encompassing named entity
recognition and relation extraction tasks. We mainly focus on the named
entity recognition task and use the entity-level F1 score as our
evaluation metric.
**$\bullet$** : With over 11,000 receipts, this dataset focuses on
extracting 54 different data elements (e.g., phone numbers) from
receipts. The task can be formulated as named entity recognition or
token classification. For evaluation, we use the entity-level F1 score.
## Baselines
To demonstrate the effectiveness of LongFin on our LongForms dataset, we
compare it against a set of publicly available text and text+layout
baselines that are capable of handling both short and long input
sequences. For the text baselines, we select the following models: *(i)*
BERT [bert](https://arxiv.org/pdf/1810.04805) which is a widely used text-based model known
for its strong performance on short context tasks (512 tokens), *(ii)*
Longformer [longformer](https://arxiv.org/pdf/2004.05150) which is specifically designed to
handle text long texts (up to 4096 tokens). For the text+layout
baseline, we utilize LiLT [lilt](https://doi.org/10.18653/v1/2022.acl-long.534), which is one of the
state-of-the-art models for document understanding [^5]. For the short
context models, we split the LongForms documents into chunks that can
fit within 512 tokens. Table
[tab:finetuningdetails] shows
the hyperparameters of the different models when finetuning on the
LongForms dataset. It also presents the hyperparameters we used when
finetuning LongFin on the previous single-page datasets. All the
finetuning experiments were performed on one A100 and one T4 GPUs.
## Results
## Previous (Single-Page) Datasets
As shown in Table [tab:prev_datasets], LongFin
outperforms other long-context models such as Longformer
[longformer](https://arxiv.org/pdf/2004.05150) and [longdocument](http://arxiv.org/pdf/2108.09190v2) on the
previous datasets that mainly consist of single-page documents. The
performance disparity is particularly pronounced on the FUNSD dataset
[funsd](http://arxiv.org/pdf/1905.13538v2), where all documents have very short textual
content (less than 512 tokens). Notably, LongFin also achieves
comparable performance to the short-context models on these datasets.
This comparison highlights the superior generalization ability of our
model, LongFin, which performs well on both short and long contexts. In
contrast, the performance of [longdocument](http://arxiv.org/pdf/2108.09190v2) model
deteriorates on short-context documents.
## LongForms Dataset [longforms-dataset]
As presented in Table
[tab:longfin_results], the
performance results on our LongForms dataset highlight the advantage of
our model, LongFin, compared to the short-context models. This
observation emphasizes the significance of long-context understanding
when working with financial documents. There is also a noticeable
difference in performance between the text models (BERT
[bert](https://arxiv.org/pdf/1810.04805) and Longformer [longformer](https://arxiv.org/pdf/2004.05150)) and
text+layout models (LiLT [lilt](https://doi.org/10.18653/v1/2022.acl-long.534) and LongFin). This is
mainly because the documents in LongForms contain diverse layouts that
might be challenging for text-only models.
To provide a deeper analysis of the results on the LongForms dataset, we
conduct ablations and report metrics by entity for both LiLT
[lilt](https://doi.org/10.18653/v1/2022.acl-long.534) and LongFin, as shown in Table
[tab:longfin_ablations]. We
notice that the gap in performance is more significant in the entities
that are typically found in long tables such as Beginning Cash, Ending
Cash, Financial Cash, and Change in Cash. To illustrate the challenges
posed by long tables, we present an examples from our test set in Figure
[fig:test_example_pred]. In
the example, the table header indicates "Nine Months," implying that the
table includes information for a nine-month period that should not be
extracted as we are only interested in the financial information per
quarter "Three Months". Due to the large number of rows and content in
the table, the short-context models may not be able to include all the
table information in a single forward pass of 512 tokens. Consequently,
when the long documents are split into chunks, such tables might be
divided as well, leading to the short-context models losing important
context when making predictions.
# Limitations
Despite the effectiveness of our model, LongFin, on both short and long
context document understanding datasets, it has a few limitations.
First, LongFin was trained and evaluated on the English language only.
In future, we plan to expand it to support multiple languages. Second,
although LongFin maximum input length (4096 tokens) can accommodate the
multi-page documents in the LongForms dataset as well as most our
proprietary datasets, it might not accommodate certain financial
documents that contain tens of pages. To overcome this limitation, we
may consider further expanding the positional embeddings to accomodate
16K tokens similar to the LED model [longformer](https://arxiv.org/pdf/2004.05150) or
explore utlizing a model architecture that uses relative position
embeddings [shaw-etal-2018-self](https://doi.org/10.18653/v1/N18-2074) such as T5
[t5](http://jmlr.org/papers/v21/20-074.html) instead of the absolute position embeddings. Third,
due to limited computational resources, we have not explored many
different hyperparameters setup. Hence, there might be room for
improvement in our model performance. Finally, while our LongForms shed
the light on long context understanding challenges which are frequent in
the financial industry, it is still limited in size. We encourage the
research community to explore this undercharted area of research since
it has various commercial applications in many industries such as
finance and legal.
# Conclusion
We introduce LongFin, a multimodal document AI model designed to handle
lengthy documents. Additionally, we present the LongForms dataset, which
aims to replicate real-world challenges in understanding long contexts,
specifically in the financial industry. Through our evaluation, we
demonstrate the superior performance of LongFin on the LongForms
dataset, which comprises multi-page documents, while achieving
comparable results on previous datasets consisting of single-page
documents. Moving forward, our plan is to deploy LongFin after training
it on our proprietary datasets in the finance domain. Furthermore, we
are working on extending LongFin to support different languages.
# Ethical Statement
All the documents used in our LongForms dataset is collected from the
EDGAR database which grants the right to use and distribute their data
without permissions [^6]. The dataset annotation process were
accomplished by data annotators who are fairly compensated. We provide
the hyperparameters and experimental setups of our experiments to ensure
the reproducibility of our work. Moreover, the models, LiLT
[lilt](https://doi.org/10.18653/v1/2022.acl-long.534) and Longformer [longformer](https://arxiv.org/pdf/2004.05150), on
which our LongFin model is built are published under permissive licenses
[^7][^8] that allow commercial use.
[^1]: https://www.sec.gov/edgar/
[^2]: https://www.sec.gov/edgar/
[^3]: https://pypi.org/project/pdftotext/
[^4]: https://aws.amazon.com/textract/
[^5]: LayoutLMv3 [layoutlmv3](https://doi.org/10.1145/3503161.3548112) is another state-of-the-art
document understanding model, but its usage is limited to
non-commercial applications
[^6]: https://www.sec.gov/privacy#dissemination
[^7]: https://github.com/allenai/longformer
[^8]: https://github.com/jpWang/LiLT
InstructDoc: A Dataset for Zero-Shot Generalization of Visual Document Understanding with Instructions
2024-01-24
Ryota Tanaka, Taichi Iki, Kyosuke Nishida, Kuniko Saito, Jun Suzuki
We study the problem of completing various visual document understanding (VDU) tasks, e.g., question answering and information extraction, on real-world documents through human-written instructions. To this end, we propose InstructDoc, the first large-scale collection of 30 publicly available VDU datasets, each with diverse instructions in a unified format, which covers a wide range of 12 tasks and includes open document types/formats. Furthermore, to enhance the generalization performance on VDU tasks, we design a new instruction-based document reading and understanding model, InstructDr, that connects document images, image encoders, and large language models (LLMs) through a trainable bridging module. Experiments demonstrate that InstructDr can effectively adapt to new VDU datasets, tasks, and domains via given instructions and outperforms existing multimodal LLMs and ChatGPT without specific training.
Show Paper Content
# Introduction
Building document artificial intelligence (Document AI) capable of
reading and comprehending real-world documents, including webpages,
office documents, mobile UIs, etc., has been a long-cherished goal.
Toward this goal, numerous works on visual document understanding (VDU)
have addressed a wide range of tasks, such as document question
answering (QA) [Mathew_2021_WACV](None) and information
extraction [jaume2019funsd](None). Document data contain both
textual and visual objects, with content spread structurally across
various locations depending on diverse document types and formats. To
address this complexity, previous works have proposed models that aim to
improve interactions among text/layout/visual
modalities [xu2020layoutlmv2](None), [appalaraju2021docformer](None).
However, the diversity of documents and tasks poses a challenge in
developing a unified model that can comprehend intricate relationships
between text and visual objects across a wide range of document types,
formats, and tasks.
To improve the generalizability and adaptivity of unseen vision-language
tasks, visual instruction
tuning [xu-etal-2023-multiinstruct](None), [liu2023llava](None) has been
introduced. This approach involves training multimodal large language
models (MLLMs) on a collection of images, task inputs, and instructions.
However, according to [liu2023hidden](None), most of the
previous visual instruction tuning datasets have primarily focused on
understanding visual (non-textual) objects in scene images and existing
models struggle with accomplishing tasks that require visual document
understanding abilities. While recent
works [zhang2023llavar](None), [ye2023mplugdocowl](None) attempt to deal
with the issue, they still exhibit limitations when generalizing to
unseen tasks and documents.
In this paper, we propose **InstructDoc**[^1], the first large-scale
visual instruction tuning dataset that covers a wide range of VDU tasks
and datasets (12 diverse tasks created from 30 openly available
datasets). Each dataset has diverse instructions annotated by experts,
following a unified instruction schema, composed of user’s *intent* and
*answer style*, for VDU tasks. As shown in
Figure [fig:samples], InstructDoc requires a
rich set of abilities, including understanding document layout, visual
representations of texts, and relation extraction of objects (e.g.,
graphs and charts) over open document types/formats with handcrafted
instructions.
Furthermore, to enhance the generalization performance on VDU tasks, we
present a **Instruct**ion-based **D**ocument **r**eading and
understanding model, InstructDr, which unifies the visual, text, and
layout modalities of documents by bridging the gap between a vision
encoder and a large language model (LLM) through a new bridging module
called Document-former. The Document-former converts documents into a
useful feature for the LLM. Experiments show that InstructDr achieves
the highest zero-shot performance among existing MLLMs and outperforms
ChatGPT on a wide range of VDU datasets with instructions.
# Related Work
### Visual document understanding.
Visual documents are ubiquitous and used in diverse applications,
including QA on business documents [Mathew_2021_WACV](None),
information extraction on receipts [jaume2019funsd](None), and
classification over large document
collections [harley2015evaluation](None). Due to this
diversity, previous works have generally been domain/task-specific,
lacking the sharing of underlying data, model architectures, and
objectives [XuLCHWZ20](None), [appalaraju2021docformer](None), [huang2022layoutlmv3](None).
Although pixel-based
methods [kim2022ocr](None), [lee2023pix2struct](None) can simplify
architectures, these methods have high computational costs (due to the
encoding of high-resolution images) and can have degraded performance on
new tasks. We leverage the reasoning abilities of LLMs and perform all
VDU tasks in a unified sequence-to-sequence format with instructions,
resulting in improved generalization performance.
### Instruction-following language models.
Training LLMs with instructions on various NLP tasks has proven
effective in improving zero-shot performance of unseen
tasks [wei2021finetuned](None), [iyer2022opt](None).
Flan [wei2021finetuned](None), [longpre2023flan](None),
PromptSource [bach-etal-2022-promptsource](None), and Natural
Instructions [mishra-etal-2022-cross](None) collected
instructions and datasets for a variety of general NLP tasks, such as
machine reading comprehension and summarization tasks on plain-text
documents. In contrast, we tackle the challenge of understanding
real-world documents organized in non-plain text formats (e.g., HTML and
PDF).
### Visual instruction tuning.
Researchers have recently explored the application of LLMs to
vision-language tasks by distilling the output of
LLMs [liu2023llava](None), [zhu2023minigpt](None), [ye2023mplugowl](None) or
training with handcrafted
instructions [xu-etal-2023-multiinstruct](None), [instructblip](None).
However, as pointed out in [liu2023hidden](None), these models
struggle with tasks requiring document understanding abilities because
they do not assume that text might be contained in images during
instruction tuning. To mitigate this issue,
LLaVAR [zhang2023llavar](None) and
LLMDoc [ye2023mplugdocowl](None) fine-tune MLLMs with
instruction tuning on document images. However, these approaches have
trouble understanding diverse real-world documents because (i) the
datasets provide a few document and task types, hindering zero-shot
generalization; and (ii) the models simply encode documents via vision
encoders and cannot explicitly learn document meta-information (e.g.,
document layout). In contrast, the InstructDoc covers diverse VDU tasks
and open document types/formats, and InstructDr learns rich
representations of the underlying structure of documents with
instructions.
# InstructDoc Dataset
## Problem Formulation
All of the tasks in InstructDoc are simply defined as: given an
instruction $T$ and a document image $I$, a model outputs an answer $A$.
Each task is composed of one or more datasets, where the dataset
$\mathcal{D}$ is associated with the set of $K$ instructions
$\mathcal{T^{\mathcal{D}}} = \{T^{\mathcal{D}}_1, ..., T^{\mathcal{D}}_K\}$
and contains $N$ instances
$\{(\mathcal{T^{\mathcal{D}}}, I_j, A_j)\}^{N}_{j=1}$. Here, we randomly
select the instruction from $\mathcal{T^{\mathcal{D}}}$ for every
instance. Note that we allow the utilization of external OCR engines to
derive the answer in our setting, as in the previous VDU
benchmark [borchmann2021due](None). Our goal is to enable the
model to perform a wide range of VDU tasks with instructions rather than
improving the accuracy of text
recognition [zhang2023llavar](None).
We mainly evaluate the models’ ability to perform zero-shot learning
scenarios. Specifically, we fine-tune a model on a collection of
instruction tasks and evaluate it on unseen datasets defined three
types: (i) **Test$_{\text{Cross-Dataset}}$**: datasets not used during
training, but whose tasks exist in training set; (ii)
**Test$_{\text{Cross-Task}}$**: datasets and associated tasks entirely
unseen during training; and (iii) **Test$_{\text{Cross-Domain}}$**:
datasets, tasks, and document types entirely unseen during training.
## Dataset Collection
In this section, we describe the collection process of the InstructDoc
dataset. InstructDoc is designed to cover a wide range of VDU tasks with
instructions that require reasoning among document layout, images, and
text.
### Source dataset collection.
Figure [fig:dataset] shows the source datasets
in InstructDoc. We collected 30 publicly available datasets and 12 tasks
in VDU areas from DUE [borchmann2021due](None) as well as
through manual searches. Following the task clusters defined in previous
works [wei2021finetuned](None), [instructblip](None), we divided the QA
datasets that require different reasoning abilities into different
tasks. As a result, we divided the collected datasets into the following
tasks:
- **Key Information Extraction (KIE)** assigns each word a semantic
entity label from predefined
categories [simsa2023docile](None), [jaume2019funsd](None), [sun2021spatial](None), [park2019cord](None), [huang2019icdar2019](None).
- **Single-page QA** is a task of QA on single-page documents and
focuses on document layout and textual content
understanding [DBLP:conf/aaai/TanakaNY21](None), [ChenZCJZLX021](None), [MishraSSC19](None), [Mathew_2021_WACV](None), [tuselmann2022recognition](None).
- **Single-page QA w/ Discrete Reasoning** requires various arithmetic
abilities, including addition, sorting, or
counting [zhu2022towards](None).
- **Single-page QA w/ Visual Reasoning** requires a set of abilities,
including object (e.g., icon) recognition, commonsense
understanding, and relation extraction on single-page
documents [lu2021iconqa](None), [kembhavi2016diagram](None), [lu2022learn](None), [kembhavi2016diagram](None).
- **Single-page QA w/ Discrete & Visual Reasoning** requires both
discrete and visual
reasoning [Mathew_2022_WACV](None), [masry-etal-2022-chartqa](None)
on single-page documents.
- **Multi-page QA w/ Multi-hop & Discrete & Visual Reasoning**
requires understanding the content relationship via multi-hop
reasoning as well as discrete/visual reasoning on multi-page
documents [SlideVQA2023](None), [landeghem2023document](None).
- **Document NLI** is a task of natural language inference that
predicts the entailment relationship between two sentences in a
document [borchmann2021due](None)
- **Dialogue** involves a human-agent interaction on the basis of
document images [zhang2023llavar](None).
- **Captioning** involves producing descriptions of
documents [hsu-etal-2021-scicap-generating](None), [wang2021screen2words](None).
- **Classification** involves classifying a document from a set of
candidate labels [harley2015evaluation](None).
- **Document Layout Analysis (DLA)** determines a document’s
components with bounding
boxes [li-etal-2020-docbank](None), [doclaynet](None)
- **Image-Text Matching (ITM)** requires the model to determine
whether a given OCR text and image match.
### Query rephrasing.
We found that two KIE datasets (FUNSD and CORD) are challenging because
they contain abbreviated queries that are difficult for humans to
comprehend. To bridge the gap between humans and machines, we replace
these queries with complete and more easily understandable phrases
(e.g., `menu.vatyn` $\to$ `menu_whether_price_tax_included`).
### Instruction annotation.
For each dataset, we manually crafted five to ten distinct instruction
templates in a unified format. For QA tasks, the answers have diverse
styles in the original datasets; for example, DocVQA’s answer is
extractive, which requires the model to extract a contiguous span of
words from the document, but VisualMRC’s answer is generative, which is
not limited to the word spans. Hence, an instruction that sufficiently
describes an arbitrary VDU task should include *intent* and *answer
style* or only *intent*. Specifically, as shown in
Figure [fig:samples], *intent* describes how
the task can be performed and *answer style* describes how the model
generates the output. If each dataset provides *query and options*, we
fill it in annotated instruction templates.
### Data split.
We split InstructDoc into 23 held-in and seven held-out datasets. For
the held-out evaluation, we aim to understand how instruction tuning on
the held-in datasets improves the zero-shot generalization performance
on unseen datasets, including (i) **Test$_{\text{Cross-Dataset}}$**:
FUNSD and CORD datasets, (ii) **Test$_{\text{Cross-Task}}$**: ChartQA,
InfoVQA, and TabFact datasets, and (iii)
**Test$_{\text{Cross-Domain}}$**: DUDE and SlideVQA datasets. All other
datasets were held-in ones to train our model. Note that the held-out
datasets were carefully selected in order to avoid data contamination.
## Comparison with Related Datasets
Table [tab:comparison] shows the
statistics of InstructDoc and other VDU instruction tuning datasets,
including LLaVAR [zhang2023llavar](None) and
DocOwl [ye2023mplugdocowl](None). InstructDoc has three unique
key properties; First, it is the first dataset to address open document
types, including multi-page documents and has the highest standard
deviation in the number of OCR tokens (1442.8) compared with LLaVAR
(93.1) and DocOwl (807.2). This implies that our dataset is a more
challenging setting. Second, InstructDoc covers the widest range of
tasks, offering four times more tasks compared with DocOwl, while LLaVAR
provides only a single task. Finally, InstructDoc provides a more
extensive set of instructions (20.3 words and 7.4 templates) and
annotates various answer styles within the instructions to deal with
various VDU tasks that require diverse abilities. In contrast, the
instructions in DocOwl are limited (five words and a single template)
and LLaVAR has only machine-generated instructions, and they may not
generalize well to reformulations and new tasks.
# Our Model
Figure [fig:instructdlip] depicts our
model, InstructDr (**Instruct**ion-based **D**ument **r**eading and
understanding model). We use pre-trained
BLIP-2 [li2023blip2](None), a state-of-the-art MLLM connected
with instruction-tuned FlanT5 [chung2022scaling](None), as the
base model. We extend BLIP-2 in three key ways; (i) equipping it with
Document-former, an enhanced Q-former module that can capture and
convert the visual and textual content/layout of documents into
representations of the LLM, (ii) conducting multi-task instruction
tuning with unified formats, and (iii) encoding multiple images in
parallel to facilitate understanding of multi-page documents.
## Spatial-aware Document Feature Extraction
### Document image/OCR and instruction encoding.
To encode a document image, we use a pre-trained
CLIP [radford2021learning](None) vision encoder to extract its
visual features $\mathbf{z}^{\text{vis}}$. Additionally, we process the
document image using an OCR engine and apply a sub-word tokenizer to
obtain $M$ word tokens $\{s_i\}_{i=1}^M$ and their corresponding
bounding boxes $\{ (x_i^1, y_i^1, x_i^2, y_i^2)\}_{i=1}^M$, where
($x^1$, $y^1$) and ($x^2$, $y^2$) represent the coordinates of the
top-left and bottom-right corners, respectively. To learn the visual
layout of the image, we construct a spatially aware OCR representation
$\mathbf{z}_i^{\text{ocr}} = \mathbf{z}_i^{\text{word}} + \mathbf{z}_i^{\text{bbox}}$
with learnable embedding layers $\mathbf{W}^{\{s, x, y, h, w\}}$, where
OCR text features are calculated as
$\mathbf{z}^{\text{word}}_i = \mathbf{W}^s(s_i)$ and spatial features
are calculated as
$\mathbf{z}^{\text{bbox}}_i = \mathbf{W}^x(x^1_i, x^2_i) + \mathbf{W}^y(y^1_i, y^2_i) + \mathbf{W}^h(y^2_i - y^1_i) + \mathbf{W}^w(x^2_i - x^1_i)$.
Similarly, we encode an instruction by $\mathbf{W}^{s}$ and obtain its
features $\mathbf{z}^{\text{ins}}$.
### Document-former.
We introduce Document-former, which is a trainable module to bridge the
gap between an image encoder and an LLM, enabling extraction of document
content/layout that LLMs can understand. The architecture of
Document-former is a stack of Transformer blocks with cross-attention
layers. To map document features into the LLM’s space, we use a set of
$m$ learnable tokens $\mathbf{z}^{\text{token}} \in \mathbb{R}^{d}$,
where $d$ is the dimension of the hidden size. These tokens
$\mathbf{z}^{\text{token}}$ interact with $\mathbf{z}^{\text{vis}}$
through cross-attention layers and with the input sequence, composed of
$\mathbf{z}^{\text{ins}}$ and $\mathbf{z}^{\text{ocr}}$, through
self-attention layers. As a result, we obtain $\mathbf{z}^{\text{doc}}$
and transform it via a projection feed-forward network (FFN) layer to
$\mathbf{h}^{\text{doc}} \in \mathbb{R}^{m \times d^{\text{LLM}}}$,
which have the same dimension $d^{\text{LLM}}$ as the LLM’s input
embedding.
## Multimodal Document Large Language Model
### Connecting document features to LLM.
The LLM receives the document embeddings $\mathbf{h}^{\text{doc}}$, the
instruction, and OCR tokens as input and outputs the answer
$\mathbf{A}$, token by token. The parameters of the LLM are initialized
from an instruction-tuned FlanT5.
### Parameter-efficient multi-task instruction tuning.
To achieve task-agnostic learning, we formulate the process of learning
all held-in tasks in a unified sequence-to-sequence abstraction through
instructions. To train the LLM efficiently, we update only the
parameters of the Document-former (including
$\mathbf{W}^{\{s, x, y, h, w\}}$) and the projection FFN layer, while
keeping other parameters frozen during training. We optimize the model
by minimizing the negative log-likelihood between the ground-truth and
predictions.
### Multi-page document understanding.
We also support performing reasoning across multiple document pages. As
shown in Figure [fig:instructdlip]b, each image is
processed individually by the image encoder and Document-former, and
their resulting document embeddings are mean-pooled together before
being fed into the LLM. The OCR input to the LLM consists of
concatenated tokens extracted from each page.
# Experiments
## Experimental Setup
We mainly conducted evaluations under three zero-shot settings,
including **Test$_{\text{Cross-Dataset}}$**,
**Test$_{\text{Cross-Task}}$**, and **Test$_{\text{Cross-Domain}}$**.
Furthermore, we evaluated our model under the task-specific fine-tuning
setting.
### Baselines.
We compared InstructDr with seven state-of-the-art (SOTA) MLLMs,
including **LLaVA** [liu2023llava](None),
**MiniGPT-4** [zhu2023minigpt](None) and
**mPLUG-Owl** [ye2023mplugowl](None), which align CLIP visual
encoder with Vicuna [vicuna2023](None) trained on a dialogue
generated by GPT-4 [openai2023gpt4](None);
**BLIP-2** [li2023blip2](None), which connects a FlanT5 with a
vision encoder; **InstructBLIP** [instructblip](None), which
fine-tunes BLIP-2 with instructions on scene images; and
**LLMDoc** [ye2023mplugdocowl](None) and
**LLaVAR** [zhang2023llavar](None), which fine-tune
mPULG-Owl/LLaVA on the DocOwl/LLaVAR datasets. Additionally, we used
**Supervised SOTA
models** [appalaraju2023docformerv2](None), [chen2023pali](None), [huang2022layoutlmv3](None), [landeghem2023document](None)
on each dataset and two text-based LLMs, **ChatGPT**
(`gpt-3.5-turbo-0613`) and **GPT-4**. To control the answer’s length, we
added control phrases (e.g., *use 1 to 3 words to answer*) to the
selected instructions.
### Evaluation metrics.
We followed the evaluation protocol of each dataset, we used
**ANLS** [BitenTMBRJVK19](None) for InfoVQA, DUDE, Text-VQA and
ST-VQA, **EM** for SlideVQA, Relaxed Accuracy (**RAcc.**) for ChartQA,
entity F1 (**eF1**) for FUNSD and CORD, Accuracy (**Acc.**) for TabFact,
and **ROUGE-L** for VisualMRC as evaluation metrics. Additionally, we
used **F1** as the optional metrics.
### Implementation details.
Following [wei2021finetuned](None), we balanced the training
instances of different tasks by sampling a maximum of 5k instances for
each held-in dataset while keeping all evaluation instances. We used the
AdamW [loshchilov2017decoupled](None) with a weight decay of
0.05. We applied a linear warmup during the initial 1,000 steps and used
a cosine learning rate decay with a minimum learning rate of 0. We set
the number of learnable tokens $m$ to $32$. All images of the model
input were resized to $224$. We trained on eight A100 (40G) GPUs for
three epochs and completed the training within two hours. If each
dataset does not provide OCR, we extracted it via the Google Vision API.
## Experimental Results and Analysis
### Does our model outperform existing MLLMs?
Table [tab:main] shows that our model achieved
the highest performance on all datasets compared with other MLLMs.
InstructDr consistently outperformed its original backbone, BLIP-2, by a
significant margin, indicating that instruction tuning on InstructDoc
effectively enhances performance on unseen VDU datasets, tasks, and
domains. In contrast, InstructBLIP, which is instruction-tuned BLIP-2
trained on scene images, performed worse than BLIP-2. This is because
that InstructBLIP does not assume that the images might contain text
during instruction tuning. BLIP-2 fine-tuned on InstructDoc falls short
of achieving the same level of performance compared with InstructDr,
indicating that InstructDr is better suited for comprehending diverse
real-world documents. This conclusion is further supported by the
results presented in
Table [tab:ablation], where ablations of
Document-former, spatial information, and strategy of gathering
multi-page features have a significant negative impact on performance.
### How well does our model perform in comparison with supervised SOTA models and powerful LLMs?
As shown in
Table [tab:compare_chatgpt], our
model outperformed ChatGPT on all datasets. Additionally, InstructDr
achieved competitive results with supervised SOTA models and GPT-4 on
the DUDE and SlideVQA datasets that require multiple reasoning skills
(e.g., discrete, visual, and multi-hop reasoning). This indicates that
our model can effectively learn diverse skills through instruction
tuning with InstructDoc.
### What is the role of instructions?
As shown in Table [tab:ablation], removing instructions
(i.e., only *query and options* as the model input) significantly
decreased zero-shot performance during training or/and test time,
indicating the effectiveness of incorporating instructions. This result
was observed on the high-quality instruction-tuning
datasets [wei2021finetuned](None), [xu-etal-2023-multiinstruct](None).
Moreover, our instruction annotations, including query rephrasing and
answer styles, helped to improve the zero-shot performance.
### Does our model have robustness towards diverse instructions?
Figure 1 shows the performance variance when
the models were given five different instructions; InstructDr exhibited
the smallest performance variance and outperformed the other models.
This indicates InstructDoc empowers the model with the ability to deal
with a variety of instructions. Our results also suggest that using
multiple instructions per dataset is important for achieving decent
performance.
### What is the impact of diverse task clusters?
As shown in
Figure 2, as the number of task clusters
increases, we can observe an improvement in models’ zero-shot
performance.
### Are our model weights effective for task-specific fine-tuning?
We further fine-tuned InstructDr (only Document-former module) on a
specific dataset to investigate the knowledge and transferability of our
instruction-tuned model weights.
Table [tab:finetune] shows the fine-tuning
performance on held-in (VisualMRC) and held-out (DUDE, SlideVQA) tasks.
InstructDr achieved state-of-the-art finetuning performance on
VisualMRC, DUDE, and SlideVQA using a unified model. Compared with
BLIP-2, InstructDr exhibited superior fine-tuning performance on both
held-in/out datasets, validating InstructDr as a better weight
initialization model for task-specific fine-tuning.
### Can our model also understand images other than documents?
Table [tab:textvqa] shows the zero-shot
performance of scene-text
VQA [SinghNSJCBPR19](None), [BitenTMBRJVK19](None) on scene images,
which are the unseen image types in InstructDoc but were used for
training our base model, BLIP-2. Note that ST-VQA’s images include the
part of COCO [lin2014microsoft](None) that InstructBLIP was
trained on. This result indicates that InstructDr can effectively learn
visual reasoning skills without forgetting the abilities of the original
backbone.
### Qualitative examples.
Figure [fig:output] visualizes output examples,
where the left/center/right examples require table/visual/hand-written
text understanding skills. ChatGPT gave incorrect answers because it can
only consider text information. Moreover, while BLIP-2 could not follow
instructions (e.g., *use 5 to 10 words*) and extract items from
structured text, InstructDr accomplished diverse VDU tasks with
instructions. As shown in the right example, all models affected OCR
quality, causing incorrect answers.
# Limitations
Despite its impressive performance on various VDU tasks with
instructions, InstructDr suffers from noisy OCR predictions, whose
performance depends highly on OCR text qualities (right of
Figure [fig:output]). We argue that our
approach is more cost-efficient and accurate because another approach,
the pixel-based ones [kim2022ocr](None), [chen2023pali](None), requires
a large amount of computation to encode high-resolution images and
cannot use document meta-information (e.g., bounding boxes). Moreover,
since InstructDoc only contains a single document-text pair per
instance, it cannot learn the correlation among multiple document-text
pairs and lacks an in-context learning capability. The same observation
has also been reported in the
Flamingo [alayrac2022flamingo](None) and BLIP-2. Finally, while
we have constructed diverse VDU tasks, the number of tasks and
corresponding instructions are still limited. We plan to consider
utilizing automatic generation and augmentation techniques to increase
the variety of instructions available.
# Conclusion
We introduced a new large-scale instruction-tuning dataset, InstructDoc,
to lay the foundation for building general-purpose VDU models that can
follow natural language instructions. We also introduced a simple yet
effective instruction tuning model, InstructDr, which unifies the
vision, text, and layout modalities of documents by bridging the gap
between a vision encoder and an LLM with Document-former. We performed a
comprehensive study on instruction tuning with InstructDoc and
demonstrated its generalization capability to a wide range of VDU
datasets, tasks, and domains with instructions. We believe that our
dataset will facilitate research on developing general-purpose document
artificial intelligence systems.
# Further InstructDoc Details
## Dataset Collection
### Dataset list.
Table [tab:datasets] shows the detail of all
datasets we used in InstructDoc. It contains 5,917,602 held-in instances
and 30,177 held-out instances.
### Query rephrasing.
Table [tab:query] shows the detail of the query
rephrasing annotation. The rephrased queries are more easily
understandable phrases than the original queries.
### Instruction annotation.
Table [tab:cord]-[tab:doclaynet] show the examples of
instructions for each task in InstructDoc.
## Dataset Analysis
### Starting words of the instructions.
Figure 3 shows the sunburst pattern of the
first three words of the instructions. It can be seen that the
instructions contain various types, such as questions (e.g., “*What is
the*") and requests (e.g., “*I want to*") used in real-world situations.
### Answer styles.
Figure 4 shows InstructDoc has five
diverse answer types.
### Word clouds.
Figure [fig:statistics] shows how diverse
the vocabulary space is in InstructDoc.
# Further Evaluation Setup Details
## Main Evaluation Datasets Details
### FUNSD.
Form Understanding in Noisy Scanned Documents
(FUNSD) [jaume2019funsd](None) evaluates on the *KIE* task:
predicting the entity, “title", “key", “value", or “other", for the
assigned text token.
### CORD.
Consolidated Receipt Dataset for Post-OCR Parsing
(CORD) [park2019cord](None) is the *KIE* dataset with 30 labels
under 4 categories such as “total" or “subtotal".
### InfographicVQA.
This dataset focuses on the task of *single-page QA w/ discrete & visual
reasoning* on infographics. It requires understanding plots/graphs,
texts, and layout [Mathew_2022_WACV](None).
### ChartQA.
This dataset focuses on the task of *single-page QA w/ discrete & visual
reasoning* on chart images. We used both two subsets: (i)
machine-generated set and (ii) human-written
set [masry-etal-2022-chartqa](None).
### TabFact.
This dataset studies the task of *Document NLI* with semi-structured
evidence over tables. It predicts the entailment relationship between
two sentences in a document [borchmann2021due](None).
### DUDE.
Document Understanding Dataset and Evaluation
(DUDE) [landeghem2023document](None) focuses on the task of
*multi-page QA w/ discrete & visual & multi-hop reasoning*. It is a
multi-page, multi-domain, and multi-industry Document VQA for real-world
document understanding.
### SlideVQA.
This dataset focuses on the task of *multi-page QA w/ discrete & visual
& multi-hop reasoning* on the slide deck composed of multiple images. It
requires selecting a set of evidence and answering the
question [SlideVQA2023](None).
## Other Evaluation Datasets Details
### VisualMRC.
Visual Machine Reading Comprehension
(VisualMRC) [DBLP:conf/aaai/TanakaNY21](None) is the task of
abstractive single-page QA on the Web screenshot. We used the end-to-end
setting where answers are derived from OCR results and images without
ROI detection.
### TextVQA.
It contains scene images from Open Images
dataset [kuznetsova2020open](None), with questions asking to
reason about text in the image [SinghNSJCBPR19](None).
### ST-VQA.
It contains scene images from multiple sources, such as Visual
Genome [KrishnaZGJHKCKL17](None). We used the Open Dictionary
setting where answer candidates and vocabularies are not provided at
test time [BitenTMBRJVK19](None).
[^1]: Our dataset and codes are publicly available at
SlideVQA: A Dataset for Document Visual Question Answering on Multiple Images
2023-01-12
Ryota Tanaka, Kyosuke Nishida, Kosuke Nishida, Taku Hasegawa, Itsumi Saito, Kuniko Saito
Visual question answering on document images that contain textual, visual, and layout information, called document VQA, has received much attention recently. Although many datasets have been proposed for developing document VQA systems, most of the existing datasets focus on understanding the content relationships within a single image and not across multiple images. In this study, we propose a new multi-image document VQA dataset, SlideVQA, containing 2.6k+ slide decks composed of 52k+ slide images and 14.5k questions about a slide deck. SlideVQA requires complex reasoning, including single-hop, multi-hop, and numerical reasoning, and also provides annotated arithmetic expressions of numerical answers for enhancing the ability of numerical reasoning. Moreover, we developed a new end-to-end document VQA model that treats evidence selection and question answering in a unified sequence-to-sequence format. Experiments on SlideVQA show that our model outperformed existing state-of-the-art QA models, but that it still has a large gap behind human performance. We believe that our dataset will facilitate research on document VQA.
Show Paper Content
# Introduction
Building intelligent agents that can read and comprehend real-world
documents, such as webpages, office documents, lecture slides, etc., has
been a long-standing goal of artificial intelligence. To achieve this
goal, machine reading comprehension (MRC), a central task in natural
language understanding, has been intensively studied. The typical
definition of the MRC task is quite simple, wherein given a short
natural language text as a context and a question about it, a machine
reads the text and then answers the question by extracting a span from
the text [RajpurkarZLL16](None), [RajpurkarJL18](None). However, this
definition is far from real-world applications, such as customer service
chatbots on e-commerce websites [CuiHWTDZ17](None) and
assistant systems for reading professional
literature [HongWJZW19](None), in that the context is composed
entirely of text, with no graphical elements.
To this end, visual question answering on document images (document VQA)
has received much attention. It is a challenging vision and language
task that requires methods to reason about document layout, textual
content, and visual
elements [Mathew_2021_WACV](None), [DBLP:conf/aaai/TanakaNY21](None), [Mathew_2022_WACV](None).
When the primary content in a document is text (e.g., e-mails and forms)
and the task is to understand it on the basis of its layout information,
state-of-the-art models have already achieved nearly human-level
performance [xu2020layoutlmv2](None), [powalski2021going](None). On the
other hand, challenges remain when it comes to handling diverse
real-world documents. First and foremost is that current models are not
capable of performing reasoning across multiple images since the
existing datasets focus on testing reasoning ability on a single image.
Moreover, compared with humans, document VQA models still have trouble
understanding documents that contain visual elements and understanding
questions that require numerical
reasoning [Mathew_2022_WACV](None).
To address the above challenges, we introduce a new document VQA
dataset[^1], SlideVQA, for tasks wherein given a slide deck composed of
multiple slide images and a corresponding question, a system selects a
set of evidence images and answers the question. Slide decks are one of
the most efficient document types that arrange visual and textual
elements for communication. As shown in
Figure [fig:example_dataset], SlideVQA
requires complex reasoning over slide images, including single-hop,
multi-hop, and numerical reasoning. These reasoning skills play
essential roles in MRC
tasks [Yang0ZBCSM18](None), [dua-etal-2019-drop](None).
Our main contributions are summarized as follows:
- We introduce a novel task and dataset, SlideVQA, wherein to answer
its questions, a machine has to read and comprehend a slide deck. It
is the largest multi-image document VQA dataset containing 2.6k+
slide decks (each consisting of 20 slides) and 14.5k questions. It
also provides bounding boxes around textual and visual elements for
understanding document layout and arithmetic expressions for
numerical reasoning.
- We developed a **M**ulti-**M**odal **M**ulti-image **D**ocument VQA
model, M3D, to jointly perform evidence selection and question
answering tasks and to enhance numerical reasoning by generating
arithmetic expressions.
- Our model outperformed existing state-of-the-art QA models on
SlideVQA, but its performance is still below that of humans by a
large margin.
# Related Work
### Datasets for VQA on document images.
Document VQA is the task of answering questions about document images,
and some useful datasets have been published, such as
DocVQA [Mathew_2021_WACV](None),
VisualMRC [DBLP:conf/aaai/TanakaNY21](None),
WebSRC [ChenZCJZLX021](None), and
InfographicVQA [Mathew_2022_WACV](None). The task assumes that
the datasets have a single relevant image, containing all the facts
required to answer.
The work most related to ours is
DocCVQA [tito2021document](None), wherein a large collection of
document images is used to answer a given question. Our dataset differs
from DocCVQA, as follows. First, SlideVQA consists of 14.5k questions,
wheres DocCVQA provides only 20 questions. Second, SlideVQA requires
multi-hop reasoning over multiple slides to find the answer, while
DocCVQA requires only single-hop reasoning on individual images to find
the answer. Besides these differences, SlideVQA provides questions that
require numerical reasoning and arithmetic expression annotations to
answer numerical questions (e.g., “30 - 28" for the answer “2"): no
other VQA dataset, including InfographicVQA that requires numerical
reasoning, provides such annotations. Furthermore, SlideVQA provides the
largest number of bounding boxes on all of the collected images among
the related datasets.
### Document VQA Models.
In parallel with the development of datasets,
Transformer [VaswaniSPUJGKP17](None) has come to be used for
understanding unstructured text in document images.
LayoutLM [XuLCHWZ20](None),
LayoutLMv2 [xu2020layoutlmv2](None),
LayoutT5 [DBLP:conf/aaai/TanakaNY21](None), and
TILT [powalski2021going](None) have achieved impressive results
in single-image document VQA tasks by combining textual, layout, and
visual features. By contrast, we focus on endowing models with the
ability to reason and comprehend multiple images. Moreover, while
[tito2021document](None) used a pipeline of retrieval and
reading models for DocCVQA, we use multi-task learning that jointly
performs evidence selection and question answering.
### Multi-modal question answering.
This type takes textual and visual information as input contexts, which
is different from document VQA that takes only a document image as the
input context. TQA [KembhaviSSCFH17](None) is comprised of
middle-school science lessons containing diagrams and text.
MultiModalQA [talmor2021multimodalqa](None) requires joint
reasoning over text, tables, and images in Wikipedia.
### VQA on videos or image sets.
VideoQA focuses on answering questions about video frames of TV
shows [lei-etal-2018-tvqa](None), [lei-etal-2020-tvqa](None) and
movies [tapaswi2016movieqa](None). A similar task is VQA on
image sets (ISVQA), which involves handling photos taken from different
viewpoint indoors [bansal2020visual](None). By contrast, our
dataset also requires a model to understand the text in images.
### Slide images understanding.
[haurilet2019spase](None), [haurilet2019wise](None) introduced a
benchmark for object segmentation on slide-pages.
[sun-etal-2021-d2s](None), [fu2021doc2ppt](None) tackled the task of
generating slides from research papers. Our work is the first to focus
on answering questions on sets of slide images.
### Reasoning over textual documents.
Numerical reasoning plays an important role in NLP
tasks [dua-etal-2019-drop](None), [zhang-etal-2020-language](None), [zhang-etal-2021-noahqa-numerical](None).
Moreover, multi-hop reasoning has taken the spotlight as it aligns with
the multi-hop nature of how humans reason to acquire knowledge, and has
led to a proliferation of
benchmarks [talmor-berant-2018-web](None), [Yang0ZBCSM18](None).
However, there is as yet no dataset for developing models to perform
both multi-hop and numerical reasoning on document images.
# The SlideVQA Task and Dataset
## Task Overview and Formulation
The SlideVQA task, requires a system to answer a question about a slide
deck, which is composed of an ordered set of slide images and to select
evidence slide images. We formulate the end-to-end SlideVQA task as
follows: MainTask (SlideVQA).
Given a question $q$ and
a slide deck $\mathbf{I} = \{I_1, \ldots, I_{K}\}$ ($K=20$), a model
outputs an answer $y$ and selects relevant slides
$\mathbf{\hat{I}} = \{\hat{I}_1, \ldots, \hat{I}_{K'}\}$.
The task can be decomposed into two subtasks:
**Subtask 1** (Evidence Selection). *Given a question $q$ and a slide
deck $\mathbf{I}$, a model identifies the images $\mathbf{\hat{I}}$ from
which to derive the answer $y$.*
**Subtask 2** (Question Answering). *Given a question $q$ and the slide
images ($\mathbf{I}$ or $\mathbf{\hat{I}}$), a model outputs an answer
$y$.*
SlideVQA has three answer types (see the examples in
Figure [fig:example_dataset]). A
single-span answer is a contiguous sequence of tokens in the reading
order extracted from the image, and a multi-span answer is formed from
multiple spans from the image. A non-span answer is not extracted and is
composed of numerical values and visual appearances.
We can also use annotations of bounding boxes around the objects (and
their categories) to understand the semantic structure of images and
annotations of arithmetic expressions to understand numerical reasoning
as additional input at training. These annotations are not given at
inference.
## Dataset Collection
In this section, we describe the collection process of the SlideVQA
dataset. To control the annotation quality, we recruited crowd workers
located in English-speaking countries and who had passed a rigorous
qualification procedure. Additionally, we asked other workers to assess
the quality of the annotated samples after each collection step.
### Slide decks collection.
First, we selected and downloaded 25,327 slide decks composed of more
than 20 slides from slideshare[^2] and covering 39 topics. We kept the
first 20 slides and truncated the rest of the pages. Then, the workers
filtered the collected decks that did not meet the following criteria:
(i) the main language is English; (ii) the content is easy for workers
to understand; (iii) the decks must contain one or more graphs, tables,
figures, or numerical data to avoid creating questions requiring only
text-level understanding.
### Bounding boxes and categories annotation.
To facilitate understanding of the semantic components of images, we
annotated all images with bounding boxes and their categories. The
workers indicated specific objects in each image by annotating bounding
boxes around the objects and classifying them into nine classes that
were based on SPaSe [haurilet2019spase](None) as follows:
- **Title**: presentation title, slide title
- **Page-text**: text in slide, bullet-point text list, text list
- **Obj-text**: text in a figure, image, diagram or table
- **Caption**: description of figure, image, diagram, or table
- **Other-text**: footnote, date, affiliation, code, URL
- **Diagram**: a graphical representation of data, a process
- **Table**: data arranged in rows and columns
- **Image**: drawing, logo, map, screenshot, realistic image
- **Figure**: graph with data points and coordinates
As shown in Figure 1, SlideVQA provides densely annotated
bounding boxes in images.
Distribution of bounding box categories, reasoning types,
numerical operations, and answer types in the test set.
### Single-hop QA creation.
We asked the workers to create 12,466 QA pairs by selecting a single
slide image from a slide deck. The selected slide can be used as
evidence to tell whether a system arrived at the right answer for the
right reasons. We encouraged questions that needed numerical reasoning,
including operations of arithmetic expressions with $\{+, -, /, *\}$,
counting, and comparisons. Additionally, the workers avoided creating
questions that (i) contained selected page numbers; (ii) required
external knowledge; (iii) were common to all of the slides (e.g., “What
is the title?").
### Multi-hop questions creation.
We created 2,018 QA pairs for multi-hop reasoning by editing the
single-hop questions created in the previous step. For example at the
left of Figure [fig:example_dataset], “North"
is replaced by the phrase “the region with 70% of journals". To this
end, we first identified one or two bridge entities in the created
questions, and the workers selected related slides as evidence that
mentioned the identified ones. Then, the content of the selected slides
was utilized to replace the entities in the created questions. The
process of creating multi-hop questions by editing may produce unnatural
questions, as mentioned in the “Limitations" section, but is easily
scalable. A similar approach was taken with
MultiModalQA [talmor2021multimodalqa](None), which requires
multi-hop reasoning over text, tables, and images in Wikipedia.
### Arithmetic expression annotation.
We provided arithmetic expressions like “30 - 28" in which the final
numerical answer can be arrived at with the four arithmetic operations.
The interpretation of the answer generation process is important for
creating explainable QA models.
## Statistics and Analysis
SlideVQA contains 14,484 QA pairs from 2,619 slide decks, consisting of
52,480 slide images annotated with 890,945 bounding boxes. We split the
dataset into 10,617 questions for training, 1,652 (2,215) questions for
development (test), making sure that each deck appears in the same
split.
### Images.
SlideVQA provides the largest number of images covering broad range of
topics among the datasets shown
in Table [tab:statistics_dataset].
Moreover, SlideVQA provides the largest number of bounding box
annotations, where the number of the annotations in SlideVQA is 14.7
times that of VisualMRC.
Figure 2a shows the distribution of
bounding boxes broken down into nine categories, which cover all
classes, including visually related ones (Image and Figure), unlike
DocVQA and DocCVQA. To analyze the OCR tokens, we extracted the text
shown in the images by using the Google Cloud Vision API[^3]. As a
result, the number of OCR tokens the system should consider
simultaneously is larger (1488.88 tokens) than those of single-image
document VQA datasets; the largest dataset (InfographicVQA) has 217.89
tokens.
### Questions and answers.
As shown in
Table [tab:statistics_dataset],
SlideVQA requires complex reasoning including single/multi-hop, and
numerical reasoning.
Figure 2b shows the diverse distribution
of questions related to reasoning types. 49.3% of the questions require
multi-hop or numerical reasoning. Moreover, SlideVQA provides
annotations of arithmetic expressions to improve numerical reasoning.
Figure 2c shows the distribution of
numerical operations. 25.5% of the numerical questions require
arithmetic operations, which current systems have particular difficulty
answering. Figure 2d shows that multi-span and
non-span account for 32.4% of the answers, indicating systems also need
to generate answers as well as extract multiple spans.
Figure 3 shows the sunburst pattern of the
first three words of the questions. “In" and “Regarding" are frequent
first words because SlideVQA needs to search for evidence images from a
slide deck, which is a special pattern in multi-text document
QA [Yang0ZBCSM18](None).
# Our Model
Figure [fig:proposed_model] shows an
overview of our model, called M3D (**M**ulti-**M**odal **M**ulti-image
**D**ocument VQA model). We use Fusion-in-Decoder
(FiD) [izacard2020leveraging](None), which is a
state-of-the-art multi-text encoder-decoder model, as our base model and
initialize FiD with a pre-trained T5 [RaffelSRLNMZLL20](None).
We extend FiD to perform the end-to-end SlideVQA task (defined in
MainTask) by (i) performing evidence
selection and question answering tasks as a unified sequence-to-sequence
format using multi-task learning, (ii) predicting arithmetic expressions
as intermediate reasoning steps instead of generating answers directly
to enhance numerical reasoning, and (iii) modifying the input sequence
to learn the visual layout and content of the image.
## Multi-modal Task-Specific Input
### Input token sequence.
For each image $I_k$, we first use Faster-RCNN
[ren2015faster](None), which was trained on SlideVQA, to
extract $N$ semantic regions (bounding boxes) and their labels (e.g.,
Title and Image). We parse the slide image for each extracted region $r$
by using an OCR engine and apply a sub-word tokenizer to obtain OCR
tokens $\mathbf{W}^r_k = \{w^{r}_{k,1},\ldots, w^{r}_{k,n}\}$ and
corresponding OCR bounding boxes. To jointly train the evidence
selection and question answering tasks, we add different task prefixes
$t \in$ {`Evidence Selection`, `Question Answering`} to the encoder
input. Specifically, the input sequence is as follows: $$\nonumber
x_k = (\texttt{task:} t \texttt{ question:} q \texttt{ page:} e_k \texttt{ context:} c_k),$$
where the sequence concatenates each slide and page number pair ($c_k$,
$e_k$) with the question $q$ and task prefix $t$. To tell the role of
each region, we insert region labels `[R`$^{r_i}_{k}$`]`, corresponding
to the region label of the $i$-th region $r_i$ in $k$-th page, before
the OCR tokens $\mathbf{W}^{r_i}_{k}$ extracted in $r_i$: $$\nonumber
c_k =
( [{\rm \texttt{R}}^{r_1}_{k}], \mathbf{W}^{r_1}_{k}, [{\rm \texttt{R}}^{r_2}_{k}], \mathbf{W}^{r_2}_{k}, \dots,
[{\rm \texttt{R}}^{r_N}_{k}], \mathbf{W}^{r_N}_{k} )$$
### Input embedding.
Following LayoutT5 [DBLP:conf/aaai/TanakaNY21](None), the input
embeddings $\mathbf{z}$ of the encoder are defined by utilizing
multi-modal information, including token $\mathbf{z}^{{\rm token}}$,
segment $\mathbf{z}^{{\rm seg}}$, layout $\mathbf{z}^{{\rm lay}}$, and
visual embeddings $\mathbf{z}^{{\rm vis}}$ as follows: $$\nonumber
\mathbf{z} = {\rm LN}(\mathbf{z}^{{\rm token}} + \mathbf{z}^{{\rm seg}} + \mathbf{z}^{{\rm lay}} + \mathbf{z}^{{\rm vis}}) \in \mathbb{R}^{L \times d},$$
where LN is a layer normalization [BaKH16](None), and $L$ and
$d$ are the length of the input sequence and a hidden vector size,
respectively. The segment embedding indicates which regions are included
in the input sequence. The layout embedding denotes the encoded bounding
box coordinates of the token within the image. We normalize all
coordinates by the size of images and use embedding layers to embed
x-axis and y-axis features separately. The visual embedding is the
appearance feature of each region and the OCR bounding boxes, which were
obtained from Faster-RCNN. Note that the layout and visual embeddings
are set to zero vectors for the task prefix, question, and page number.
## Multi-modal Encoder-Decoder
### Multi-modal encoder.
Our encoder is a stack of $m$ Transformer blocks, consisting of a
self-attention layer and a fully-connected layer with residual
connections. Following FiD [izacard2020leveraging](None), all
$K$ input sequences are encoded independently and then concatenated to
form a unified input representation. Formally, we transform each input
sequence $x_k$ into $\mathbf{x}_k \in \mathbb{R}^{L \times d}$ and
concatenate them into $\mathbf{X} \in \mathbb{R}^{K \times L \times d}$.
### Answer/Arithmetic-expression decoder.
Our decoder is another stack of $m$ Transformer blocks similar to the
multi-modal encoder, where each block has an additional layer of
cross-attention between the output sequence and $\mathbf{X}$. The answer
decoder is modeled as a conditional generation $p_\theta(y|\mathbf{X})$,
where $\theta$ represents the set of all model parameters. To allow the
model to perform numerical reasoning, we train the system to predict
annotated arithmetic expressions $y'$ (e.g., “$30 - 28$") instead of
numeric values $y$ (e.g., “$2$") by modeling $p_\theta(y'|\mathbf{X})$.
During inference, the model itself decides whether numerical reasoning
is required or not for each question by predicting an indicator token
`Answer:` or `Expression:` at the beginning of the output sequence.
### Evidence selector.
The selector shares the weights and the architecture of the
answer/arithmetic-expression decoder. Instead of only modeling answer
generation, we devise a simple method to train evidence selection in a
unified sequence. Specifically, we define the output sequence as
$\hat{\mathbf{I}}_{\text{pages}}$ $=$ (`Evidence pages:` $\hat{e}_1$,
$\ldots$, $\hat{e}_{K'}$), where each $\hat{e}$ is the page number of
the selected slide.
### Training and inference.
Our model is trained by minimizing the weighted sum of two losses
$\mathcal{L} = \mathcal{L}_{\text{dec}} + \mathcal{L}_{\text{sel}}$,
where $\mathcal{L}_{\text{dec}}$ and $\mathcal{L}_{\text{sel}}$ are the
negative log-likelihood between the ground-truth and the prediction
regarding the decoder and selector, respectively. During inference, we
obtain the final prediction to post-process the decoded sequence by
removing the task indicator. If an arithmetic expression is generated
(i.e., `Expression:` is generated), we use a calculator to obtain the
final results.
# Experiments
## Experimental Setup
We conducted experiments on the SlideVQA task, evidence selection task,
and question answering task respectively defined in
MainTask,
Subtasks1 and
2.
### Main task baselines.
We mainly evaluated pipeline models as baselines, consisting of evidence
selection that produces top-3 evidences and question answering that
takes the selection results as input. Here, we introduced a hierarchical
LayoutLMv2 (H-LayoutLMv2) inspired
by [tu2020select](None), [xu2020layoutlmv2](None), which encodes all
slides simultaneously by using another Transformer layer, as the
evidence selector. It achieved 96.0% on Recall@3 on the test set. We
used three generative QA models: a textual model
**T5** [RaffelSRLNMZLL20](None), a numerical and multi-hop
model **PreasM** [yoran-etal-2022-turning](None), and a
document VQA model
**LayoutT5** [DBLP:conf/aaai/TanakaNY21](None). We also used an
extractive document VQA model **LayoutLMv2** to predict the single span.
### Evidence selection baselines.
We also evaluated the evidence selection task alone.
**BM25** [robertson2009probabilistic](None) is a non-neural
retrieval framework to estimate the relevance of texts to a search
query. For the neural models,
**CLIP** [radford2021learning](None) encodes the question and
each image to predict the highest similar pair. BM25 and CLIP used the
top-1 slide as the prediction. **BERT** [DevlinCLT19](None) is
a pre-trained language model which only uses text information with the
Transformer architecture. **LayoutLM** [XuLCHWZ20](None)
incorporates layout information into the input embeddings of BERT.
**LayoutLMv2** includes image features produced by a CNN backbone in
input embeddings. To model the interactions between the slides, we used
**H-LayoutLMv2** described in the previous section. For neural evidence
selection baselines (except for CLIP), we use a hidden state of `[CLS]`
in the last layer to feed into an MLP classifier with a sigmoid
activation. Evidence is selected if its confidence of binary
classification is above the optimal value on the development set.
To evaluate the effectiveness of our generative evidence selection
module, we introduced **BinaryClass** as a classification baseline,
which uses a two-layer MLP classifier with a sigmoid activation on top
of each encoder representation at the start-of-sequence. We also
introduced a generative baseline, **ChainGen**, which generates a
sequence of selected slide page numbers before the
answer [wei2022chain](None).
### Question answering baselines.
In addition to the pipeline models, we developed **Q-only**, which takes
only the question into T5. We also used a VideoQA model
**UniVL** [Luo2020UniVL](None) that can take all of the slide
images as input. Furthermore, we evaluated our base model
**FiD** [izacard2020leveraging](None).
### Human performance.
We asked six crowdworkers (not among those recruited to collect our
dataset) to select slide images relevant to the question and answer the
question.
### Evaluation metrics.
Following HotpotQA [Yang0ZBCSM18](None), we used exact match
(EM) and F1 on each question answering and evidence selection task and
also used Joint EM (JEM) and Joint F1 (JF1) to evaluate both tasks.
These joint metrics penalize models that perform poorly on either task
and assess the accuracy and explainability of the question answering
models.
## Implementation Details
We implemented all of the models in PyTorch and experimented on eight
Tesla V100 32GB GPUs. The size of CLIP was `Large` and the size of the
other models was `Base`. We fine-tuned the models using
AdamW [loshchilov2017decoupled](None) with a learning rate of
5e-5 and a dropout rate of 10%, and we linearly warmed up the learning
rate over 1000 steps. The batch size was set to 32. We evaluated models
every 500 steps and selected the best one on the development set on the
basis of the loss. We used a maximum length of 200 tokens for each input
sequence of M3D, and set the maximum target sequence length to 50. We
trained Faster-RCNN [ren2015faster](None) with a
ResNet-101 [HeZRS16](None) backbone by using stochastic
gradient descent (SGD) [ruder2016overview](None) with a
learning rate of 1e-3 and batch size of one. Standard anchor scales of
\[8, 16, 32\] and anchor ratios of \[0.5, 1.0, 2.0\] were used. For the
VideoQA baseline, we created a new video at a rate of five frames per
second. We used the Google Cloud Vision API to extract text and bounding
boxes from images. When the OCR word is tokenized into sub-word tokens,
the bounding box coordinates of a sub-word token are the same as those
of its whole word.
## Experimental Results and Analysis
### Does our model outperform the baselines?
Table [tab:main] summarizes the results of the
main tasks. As shown in
Table [tab:main]a, M3D outperformed the
baselines on joint EM/F1, where the metrics evaluate the consistency
between the predicted evidence and answers. For the evidence selection
task, Table [tab:main]b shows that H-LayoutLMv2 and
M3D performed better than the baselines. This indicates that modeling
the interaction between multiple slides simultaneously is needed to
improve performance. For the QA task,
Table [tab:main]c shows that M3D outperformed
the pipeline methods in all metrics. Our end-to-end M3D model is better
at ignoring the slides irrelevant to the question than the answer
generator in the pipeline methods that strongly depend on the slides
narrowed down by the evidence selector. However, M3D$_{\texttt{GT}}$ in
Table [tab:main]a achieved a significant
improvement by knowing the ground-truth slides. There is room for
improving the correctness of evidence selection.
### What are the characteristics of our dataset?
Table [tab:main] shows that adding modality
information tended to improve performance in all tasks. This
demonstrates that SlideVQA requires methods to have the ability to
jointly understand the text, layout, and visual modalities of documents.
As shown in Table [tab:main]c, Q-only had the lowest
performance, showing that the systems could not answer the question
without reading documents in the SlideVQA task. Additionally, UniVL has
a comparative result to Q-only, indicating that SlideVQA requires
different abilities from VideoQA [le-hoi-2020-video](None),
especially the ability to read texts in images.
Tables [tab:main]a and
[tab:main]c show that LayoutT5, a
generative model, significantly outperformed LayoutLMv2, an extractive
approach. This result is inline with observations on the DROP
dataset [dua-etal-2019-drop](None), which also has non-span
answers [geva-etal-2020-injecting](None). Additionally, all of
the models performed all of the tasks significantly worse than humans.
To be specific, Figure 4 illustrates that (i) better multi-hop
reasoning over multiple images is needed and (ii) non-span answers to
questions involving arithmetic operations have to be improved.
### Do our sub-modules improve performance?
Table [tab:ablation] lists the results of an
ablation study. Here, performance consistently decreased as individual
modules were removed from M3D. This indicates that each of the modules
is effective. More precisely, the arithmetic expression (AE) generation
was influential on the QA and Joint performance, meaning that predicting
the arithmetic expression instead of the numerical value enhances the
ability to generate answers with numerical reasoning. As shown in
Figure 4, applying AE prediction increased F1
by a large margin (+10.4%) in the arithmetic type.
### What are the effective evidence selection methods?
Table [tab:qa_classification] shows
that our method, which generates the evidence selection and question
answering results separately, obtained the highest performance. It seems
that the generative methods (MultiGen and ChainGen) benefited from the
text-to-text pre-training of T5 more than the classification-based
method (BinaryClass). Our MultiGen decoder that separately trains
evidence selection and question answering had the advantage of being
easier to train than the ChainGen baseline decoder that trains the two
tasks as a single sequence generation task.
### On which categories does the object detection model not work well?
Table [tab:object_detection] lists
the object detection performance of Faster-RCNN broken down by bounding
box categories. These results show that detecting randomly placed and
small boxes, such as Obj-text, is more difficult than mostly fixed and
large boxes, such as Title.
### Qualitative examples.
Figure 5 demonstrates our model’s
performance by visualizing a qualitative example. This example needs
multi-hop reasoning and an answer involving an arithmetic operation. FiD
gave an incorrect answer because it did not consider the visual layout
of the slides. Moreover, while LayoutT5 could not understand the process
of getting numerical answers, M3D successfully extracted information
(“11%" and “12%") and generated the same answer as the ground-truth.
# Discussion and Limitations
SlideVQA is the largest document VQA benchmark that uses multiple images
as input and requires multi-hop reasoning; its limitation is that the
multi-hop questions created by editing are different from the questions
humans might actually ask the system. We argue that developing models
that can reason over multiple images is an important research direction,
and therefore, we employed an editing method that guarantees multi-hop
questions and easily extends the dataset size. Also, our model uses
cross-attention on all evidence candidates, which may cause a
computational problem when there are a lot of input images (e.g., as in
the open-domain QA setting like DocCVQA). To remedy this problem, we
consider that models that train a two-stage selector that roughly
narrows down candidates to a small number of images and then accurately
selects evidence images and an answer generator in an end-to-end manner
are promising [sachan-etal-2021-end](None), [sachan2021endtoend](None).
# Conclusion
We introduced a new document VQA dataset, SlideVQA, focused on the task
of understanding slide decks composed of multiple images. We also
introduced a unified end-to-end model, M3D, that can perform evidence
selection and question answering tasks and enhance numerical reasoning
by generating arithmetic expressions. While our evaluation highlighted
the promise of this approach, it also revealed a huge gap compared with
human performance, and several challenges emerge from multi-hop
reasoning on multiple images and generating answers with arithmetic
operations. We believe that our dataset will contribute to the
development of intelligent assistant agents that can comprehend diverse
real-world documents.
[^1]: Our dataset and codes are publicly available
at
[^2]:
[^3]: https://cloud.google.com/vision
Hierarchical multimodal transformers for Multi-Page DocVQA
2022-12-07
Rubèn Tito, Dimosthenis Karatzas, Ernest Valveny
Document Visual Question Answering (DocVQA) refers to the task of answering questions from document images. Existing work on DocVQA only considers single-page documents. However, in real scenarios documents are mostly composed of multiple pages that should be processed altogether. In this work we extend DocVQA to the multi-page scenario. For that, we first create a new dataset, MP-DocVQA, where questions are posed over multi-page documents instead of single pages. Second, we propose a new hierarchical method, Hi-VT5, based on the T5 architecture, that overcomes the limitations of current methods to process long multi-page documents. The proposed method is based on a hierarchical transformer architecture where the encoder summarizes the most relevant information of every page and then, the decoder takes this summarized information to generate the final answer. Through extensive experimentation, we demonstrate that our method is able, in a single stage, to answer the questions and provide the page that contains the relevant information to find the answer, which can be used as a kind of explainability measure.
Show Paper Content
# Introduction [sec:intro]
Automatically managing document workflows is paramount in various
sectors including Banking, Insurance, Public Administration, and the
running of virtually every business. For example, only in the UK more
than 1 million home insurance claims are processed every year. Document
Image Analysis and Recognition (DIAR) is at the meeting point between
computer vision and NLP. For the past 50 years, DIAR methods have
focused on specific information extraction and conversion tasks.
Recently, the concept of Visual Question Answering was introduced in
DIAR
[mathew2020document](mathew2020document), [mathew2021docvqa](mathew2021docvqa), [mathew2022infographicvqa](mathew2022infographicvqa).
This resulted in a paradigm shift, giving rise to end-to-end methods
that condition the information extraction pipeline on the
natural-language defined task. DocVQA is a complex task that requires
reasoning over typed or handwritten text, layout, graphical elements
such as diagrams and figures, tabular structures, signatures and the
semantics that these convey.
All existing datasets and methods for DocVQA focus on single page
documents, which is far from real life scenarios. Documents are
typically composed of multiple pages and therefore, in a real document
management workflow all pages of a document need to be processed as a
single set.
In this work we aim at extending single-page DocVQA to the more
realistic multi-page setup. Consequently, we define a new task and
propose a novel dataset, MP-DocVQA, designed for Multi-Page Document
Visual Question Answering. MP-DocVQA is an extension of the
SingleDocVQA [mathew2021docvqa](mathew2021docvqa) dataset where the
questions are posed on documents with between 1 and 20 pages.
Dealing with multiple pages largely increases the amount of input data
to be processed. This is particularly challenging for current
state-of-the-art DocVQA methods
[xu2020layoutlm](xu2020layoutlm), [xu2021layoutlmv2](xu2021layoutlmv2), [huang2022layoutlmv3](huang2022layoutlmv3), [powalski2021going](powalski2021going)
based on the Transformer architecture
[vaswani2017attention](vaswani2017attention) that take as input textual, layout
and visual features obtained from the words recognized by an OCR. As the
complexity of the transformer scales up quadratically with the length of
the input sequence, all these methods fix some limit on the number of
input tokens which, for long multi-page documents, can lead to
truncating a significant part of the input data. We will empirically
show the limitations of current methods in this context.
As an alternative, we propose the Hierarchical Visual T5(Hi-VT5), a
multimodal hierarchical encoder-decoder transformer build on top of
T5 [raffel2020exploring](raffel2020exploring) which is capable to naturally
process multiple pages by extending the input sequence length up to
20480 tokens without increasing the model complexity. In our
architecture, the encoder processes separately each page of the
document, providing a summary of the most relevant information conveyed
by the page conditioned on the question. This information is encoded in
a number of special tokens, inspired in the token of the BERT model
[devlin2018bert](devlin2018bert). Subsequently, the decoder generates the
final answer by taking as input the concatenation of all these summary
tokens for all pages. Furthermore, the model includes an additional head
to predict the index of the page where the answer has been found. This
can be used to locate the context of the answer within long documents,
but also as a measure of explainability, following recent works in the
literature [wang2020general](wang2020general), [tito2021document](tito2021document). Correct
page identification can be used as a way to distinguish which answers
are the result of reasoning over the input data, and not dictated from
model biases.
To summarize, the key contributions of our work are:
1. We introduce the novel dataset MP-DocVQA containing questions over
multi-page documents.
2. We evaluate state-of-the-art methods on this new dataset and show
their limitations when facing multi-page documents.
3. We propose Hi-VT5, a multimodal hierarchical encoder-decoder method
that can answer questions on multi-page documents and predict the
page where the answer is found.
4. We provide extensive experimentation to show the effectiveness of
each component of our framework and explore the relation between the
accuracy of the answer and the page identification result.
The dataset, baselines and Hi-VT5 model code and weights are publicly
available through the DocVQA Web portal[^1] and GitHub project[^2].
# Related Work
**Document VQA datasets**:
DocVQA [mathew2020document](mathew2020document), [tito2021icdar](tito2021icdar) has seen
numerous advances and new datasets have been released following the
publication of the SingleDocVQA [mathew2021docvqa](mathew2021docvqa)
dataset. This dataset consists of $50,000$ questions posed over industry
document images, where the answer is always explicitly found in the
text. The questions ask for information in tables, forms and paragraphs
among others, becoming a high-level task that brought to classic DIAR
algorithms an end purpose by conditionally interpreting the document
images. Later on,
InfographicsVQA [mathew2022infographicvqa](mathew2022infographicvqa) proposed
questions on infographic images, with more visually rich elements and
answers that can be either extractive from a set of multiple text spans
in the image, a multiple choice given in the question, or the result of
a discrete operation resulting in a numerical non-extractive answer. In
parallel, VisualMRC [tanaka2021visualmrc](tanaka2021visualmrc) proposed
open-domain questions on webpage screenshots with abstractive answers,
which requires to generate longer answers not explicitly found in the
text. DuReader~Vis~ [qi2022dureadervis](qi2022dureadervis) is a Chinese
dataset for open-domain document visual question answering, where the
questions are queries from the Baidu search engine, and the images are
screenshots of the webpages retrieved by the search engine results.
Although the answers are extractive, $43\%$ of them are non-factual and
much longer on average than the ones in previous DocVQA datasets. In
addition, each image contains on average a bigger number of text
instances. However, due to the big size of the image collection, the
task is posed as a 2-stage retrieval and answering tasks, where the
methods must retrieve the correct page first, and answer the question in
a second step. Similarly, the Document Collection Visual Question
Answering (DocCVQA) [tito2021icdar](tito2021icdar) released a set of
$20$ questions posed over a whole collection of $14,362$ single page
document images. However, due to the limited number of questions and the
low document variability, it is not possible to do training on this
dataset and current approaches need to rely on training on SingleDocVQA.
Finally, TAT-DQA [zhu2022towards](zhu2022towards) contains extractive and
abstractive questions on modern financial reports. Despite that the
documents might be multi-page, only 306 documents have actually more
than one page, with a maximum of 3 pages. Instead, our proposed
MP-DocVQA dataset is much bigger and diverse with $46,176$ questions
posed over $5,928$ multi-page documents with its corresponding $47,952$
page images, which provides enough data for training and evaluating new
methods on the new multi-page setting.
**Methods**: Since the release of the SingleDocVQA dataset, several
methods have tackled this task from different perspectives. From NLP,
Devlin proposed BertQA [mathew2021docvqa](mathew2021docvqa) which consists
of a BERT [devlin2018bert](devlin2018bert) architecture followed by a
classification head that predicts the start and end indices of the
answer span from the given context. While many models have extended BERT
obtaining better results
[liu2019roberta](liu2019roberta), [lan2019albert](lan2019albert), [garncarek2021lambert](garncarek2021lambert), [sanh2019distilbert](sanh2019distilbert)
by changing key hyperparameters during training or proposing new
pre-training tasks, T5 [raffel2020exploring](raffel2020exploring) has become
the backbone of many state-of-the-art
methods [powalski2021going](powalski2021going), [biten2022latr](biten2022latr), [lu2022unified](lu2022unified)
on different NLP and multimodal tasks. T5 relies on the original
Transformer [vaswani2017attention](vaswani2017attention) by performing minimal
modifications on the architecture, but pre-training on the novel
de-noising task on a vast amount of data.
On the other hand, and specifically designed for document tasks,
LayoutLM [xu2020layoutlm](xu2020layoutlm) extended BERT by decoupling the
position embedding into 2 dimensions using the token bounding box from
the OCR and fusing visual and textual features during the downstream
task. Alternatively, LayoutLMv2 [xu2021layoutlmv2](xu2021layoutlmv2) and
TILT [powalski2021going](powalski2021going), included visual information
into a multimodal transformer and introduced a learnable bias into the
self-attention scores to explicitly model relative position. In
addition, TILT used a decoder to dynamically generate the answer instead
of extracting it from the context.
LayoutLMv3 [huang2022layoutlmv3](huang2022layoutlmv3) extended its previous
version by using visual patch embeddings instead of leveraging a CNN
backbone and pre-training with 3 different objectives to align text,
layout position and image context. In contrast, while all the previous
methods utilize the text recognized with an off-the-shelf OCR,
Donut [kim2022ocr](kim2022ocr) and
Dessurt [davis2022end](davis2022end) are end-to-end encoder-decoder
methods where the input is the document image along with the question,
and they implicitly learn to read as well as understand the semantics
and layout of the images.
However, the limited input sequence length of these methods make them
unfeasible for tasks involving long documents such as the ones in
MP-DocVQA. Different
methods[dai2019transformer](dai2019transformer), [beltagy2020longformer](beltagy2020longformer), [zaheer2020big](zaheer2020big)
have been proposed in the NLP domain to improve the modeling of long
sequences without increasing the model complexity.
Longformer [beltagy2020longformer](beltagy2020longformer) replaces the common
self-attention used in transformers where each input attends to every
other input by a combination of global and local attention. The global
attention is used on the question tokens, which attend and are attended
by all the rest of the question and context tokens, while a sliding
window guides the local attention over the context tokens to attend the
other locally close context tokens. While the standard self-attention
has a complexity of $O(n^2)$, the new combination of global and local
attention turns the complexity of the model into $O(n)$. Following this
approach, Big Bird [zaheer2020big](zaheer2020big) also includes
attention on randomly selected tokens that will attend and be attended
by all the rest of the tokens in the sequence, which provides a better
global representation while adding a marginal increase of the complexity
in the attention pattern.
# MP-DocVQA Dataset
The Multi-Page DocVQA (MP-DocVQA) dataset comprises 46K questions posed
over 48K images of scanned pages that belong to 6K industry documents.
The page images contain a rich amount of different layouts including
forms, tables, lists, diagrams and pictures among others as well as text
in handwritten, typewritten and printed fonts.
## Dataset creation [subsec:dataset_creation]
Documents naturally follow a hierarchical structure where content is
structured into blocks (sections, paragraphs, diagrams, tables) that
convey different pieces of information. The information necessary to
respond to a question more often than not lies in one relevant block,
and is not spread over the whole document. This intuition was confirmed
during our annotation process in this multi-page setting. The
information required to answer the questions defined by the annotators
was located in a specific place in the document. On the contrary, when
we forced the annotators to use different pages as a source to answer
the question, those become very unnatural and did not capture the
essence of questions that we can find in the real world.
Consequently, we decided to use the
SingleDocVQA [mathew2021docvqa](mathew2021docvqa) dataset, which already
has very realistic questions defined on single pages. To create the new
MP-DocVQA dataset, we took every image-question pair from
SingleDocVQA [mathew2021docvqa](mathew2021docvqa) and added to every image
the previous and posterior pages of the document downloaded from the
original source UCSF-IDL[^3]. As we show in
[fig:doc_pages] most of documents in
the dataset have between $1$ and $20$ pages, followed by a long tail of
documents with up to $793$ pages. We focused on the most common scenario
and limited the number of pages in the dataset to $20$. For longer
documents, we randomly selected a set of $20$ pages that included the
page where the answer is found
Next, we had to analyze and filter the questions since we observed that
some of the questions in the SingleDocVQA dataset became ambiguous when
posed in a multi-page setup(e.g. asking for the page number of the
document). Consequently, we performed an analysis detailed in
[appendix:construction_details]
to identify a set of key-words, such as *‘document’*, that when included
in the text of the question, can lead to ambiguous answers in a
multi-page setting, as they originally referred to a specific page and
not to the whole multi-page document.
After removing ambiguous questions, the final dataset comprises $46,176$
questions posed over $47,952$ page images from $5,928$ documents. Notice
that the dataset also includes documents with a single page when this is
the case. Nevertheless, as we show in
[fig:questions_page_ranges],
the questions posed over multi-page documents represent the $85.95\%$ of
the questions in the dataset.
Finally, we split the dataset into train, validation and test sets
keeping the same distribution as in SingleDocVQA. However, following
this distribution some pages would appear in more than one split as they
originate from the same document. To prevent this, we trim the number of
pages used as context for such specific cases to ensure that no
documents are repeated between training and validation/test splits. In
[fig:questions_page_ranges]
we show the number of questions according to the final document length.
To facilitate research and fair comparison between different methods on
this dataset, along with the images and questions we also provide the
OCR annotations extracted with Amazon Textract[^4] for all the $47,952$
document images (including page images beyond the $20$ page limit to not
limit future research on longer documents).
## Dataset statistics
As we show in
[tab:datasets_stats], given that
MP-DocVQA is an extension of SingleDocVQA, the average question and
answer lengths are very similar to this dataset in contrast to the long
answers that can be found in the open-domain datasets VisualMRC and
DuReader~Vis~. On the contrary, the main difference lies in the number
of OCR tokens per document, which is even superior to the Chinese
DuReader~Vis~. In addition, MP-DocVQA adopts the multi-page concept,
which means that not all documents have the same number of pages
([fig:questions_page_ranges]),
but also that each page of the document may contain a different content
distribution, with varied text density, different layout and visual
elements that raise unique challenges. Moreover, as we show in Figs.
[fig:questions_page_ranges]
and [fig:words_per_question] the
variability between documents is high, with documents comprising between
$1$ and $20$ pages, and between $1$ and $42,313$ recognized OCR words.
# Hi-VT5 [sec:method]
Although documents contain dense information, not all of them is
necessary to answer a given question. Following this idea, we propose
the Hierarchical Visual T5(Hi-VT5), a hierarchical encoder-decoder
multimodal transformer where given a question, the encoder extracts the
most relevant information from each page conditioned to the question and
then, the decoder generates the answer from the summarized relevant
information extracted from the encoder. Figure
[fig:Hi-LT5] shows an overview of the
model. We can see that each page is independently processed by the
encoder taking as input the sequence of OCR tokens (encoding both text
semantics and layout features), a set of patch-based visual features and
the encoded question tokens. In addition, a number of learnable tokens
are introduced to embed at the output of the encoder the summary of
every page. These tokens are concatenated and passed through the decoder
to get the final answer. Moreover, in parallel to the answer generation,
the answer page identification module predicts the page index where the
information to answer the question is found, which can be used as a kind
of explainability measure. We utilize the T5 architecture as the
backbone for our method since the enormous amount of data and their
novel de-noising task utilized during pretraining makes it an excellent
candidate for the model initialization. In this section, we first
describe each module, then how they are integrated and finally, the
training process followed.
**Textual representation:** Following recent literature on document
understanding [huang2022layoutlmv3](huang2022layoutlmv3), [powalski2021going](powalski2021going)
which demonstrates the importance of layout information when working
with Transformers, we utilize a spatial embedding to better align the
layout information with the semantic representation. Formally, given an
OCR token $O_{i}$, we define the associated word bounding box as
$(x^{i}_{0}, y^{i}_{0}, x^{i}_{1}, y^{i}_{1})$.
Following [biten2022latr](biten2022latr), to embed bounding box
information, we use a lookup table for continuous encoding of one-hot
vectors, and sum up all the spatial and semantic representations
together: $$\small
\mathcal{E}_{i} = E_{O} (O_{i}) + E_{x}(x^{i}_{0}) + E_{y}(y^{i}_{0})+E_{x}(x^{i}_{1}) + E_{y}(y^{i}_{1})
% \vspace{-5pt}
\label{eq:ocr_emb}$$
**Visual representation:** We leverage the Document Image Transformer
(DIT) [li2022dit](li2022dit) pretrained on Document Intelligence
tasks to represent the page image as a set of patch embeddings.
Formally, given an image I with dimension $H \times W \times C$, is
reshaped into $N$ 2D patches of size $P^{2} \times C$, where $(H, W)$ is
the height and width, $C$ is the number of channels, $(P, P)$ is the
resolution of each image patch, and $N = HW/P^{2}$ is the final number
of patches. We map the flattened patches to $D$ dimensional space, feed
them to DiT, pass the output sequence to a trainable linear projection
layer and then feed it to the transformer encoder. We denote the final
visual output as $V=\{v_{0}, \ldots, v_{N}\}$.
**Hi-VT5 hierarchical paradigm:** Inspired by the
BERT [devlin2018bert](devlin2018bert) token, which is used to represent
the encoded sentence, we use a set of $M$ learnable tokens to represent
the page information required to answer the given question. Hence, we
input the information from the different modalities along with the
question and the learnable tokens to the encoder to represent in the
tokens the most relevant information of the page conditioned by the
question. More formally, for each page
$p_{j} \in P=\{p_{0}, \ldots, p_{K}\}$, let
$V_{j}=\{v_{0}, \ldots, v_{N}\}$ be the patch visual features,
$Q=\{q_{0}, \ldots, q_{m}\}$ the tokenized question,
$O_{j}=\{o_{1}, \ldots, o_{n}\}$ the page OCR tokens and
$K_{j}=\{k_{0}, \ldots, k_{M}\}$ the learnable tokens. Then, we embed
the OCR tokens and question using
[eq:ocr_emb] to obtain the OCR
$\mathcal{E}_{j}^{o}$ and question $\mathcal{E}^{q}$ encoded features.
And concatenate all the inputs
$[K_{j};V_{j};\mathcal{E}^{q};\mathcal{E}_{j}^{o}]$ to feed to the
transformer encoder. Finally, all the contextualized $K^{'}$ output
tokens of all pages are concatenated to create a holistic representation
of the document $D=[K_{0}^{'}; \ldots; K_{K}{'}]$, which is sent to the
decoder that will generate the answer, and to the answer page prediction
module.
**Answer page identification module**: Following the trend to look for
interpretability of the answers in VQA [wang2020general](wang2020general),
in parallel to the the answer generation in the decoder, the
contextualized tokens $D$ are fed to a classification layer that outputs
the index of the page where the answer is found.
**Pre-training strategy:** Since T5 was trained without layout
information, inspired by [biten2022latr](biten2022latr) we propose a
hierarchical layout-aware pretraining task to align the layout and
semantic textual representations, while providing the tokens with the
ability to attend to the other tokens. Similar to the standard
de-noising task, the layout-aware de-noising task masks a span of tokens
and forces the model to predict the masked tokens. Unlike the normal
de-noising task, the encoder has access to the rough location of the
masked tokens, which encourages the model to fully utilize the layout
information when performing this task. In addition, the masked tokens
must be generated from the contextualized $K^{'}$ tokens created by the
encoder, which forces the model to embed the tokens with relevant
information regarding the proposed task.
**Training strategy:** Even though Hi-VT5 keeps the same model
complexity as the sum of their independent components (T5~BASE~ (223M) +
DiT~BASE~ (85M)) and despite being capable to accept input sequences of
up to 20480 tokens, the amount of gradients computed at training time
scales linearly with the number of pages since each page is passed
separately through the encoder and the gradients are stored in memory.
Consequently, it is similar to have a batch size $P$ times bigger in the
encoder compared to a single page setting. While this could be tackled
by parallelizing the gradients corresponding to a set of pages into
different GPUs, we offer an alternative strategy using limited
resources. We train the model on shortened versions of the documents
with only two pages: the page where the answer is found and the previous
or posterior page. Even though this drops the overall performance of the
model, as we show in
[appendix:train_doc_pages],
training with only 2 pages is enough to learn the hierarchical
representation of the model achieving results close to the ones using
the whole document, and offers a good trade-off in terms of memory
requirements. However, after the training phase the decoder and the
answer page identification module can’t deal with the full version of
the documents of up to 20 pages. For this reason, we perform a final
fine-tuning phase using the full-length documents and freezing the
encoder weights.
# Experiments [sec:experiments]
To evaluate the performance of the methods, we use the standard
evaluation metrics in DocVQA, accuracy and Average Normalized
Levenshtein Similarity (ANLS) [biten2019scene](biten2019scene). To assess
the page identification we use accuracy.
## Baselines
As Multi-Page DocVQA is a new task, we adapt several state-of-the-art
methods as baselines to analyze their limitations in the multi-page
setup and compare their performance against our proposed method. We
choose BERT [devlin2018bert](devlin2018bert) because it was the first
question-answering method based on transformers, and it shows the
performance of such a simple baseline.
Longformer [beltagy2020longformer](beltagy2020longformer) and Big
Bird [zaheer2020big](zaheer2020big) because they are specially designed
to deal with long sequences, which might be beneficial for the
multi-page setting. In the case of Big Bird it can work following two
different strategies. The former, Internal Transformer Construction
(ITC) only sets the global attention over one single token, while the
Extended Transformer Construction (ETC) sets the global attention over a
set of tokens. Although the latter strategy is the desired setup for
question-answering tasks by setting all the question tokens with global
attention, the current released code only supports the ITC strategy and
hence, we limit our experiments to this attention strategy. We also use
LayoutLMv3 [huang2022layoutlmv3](huang2022layoutlmv3) because it is the
current public state-of-the-art method on the SingleDocVQA task and uses
explicit visual features by representing the document in image patches.
Finally, T5 [raffel2020exploring](raffel2020exploring) because it is the only
generative baseline and the backbone of our proposed method.
However, all these methods are not directly applicable to a multi-page
scenario. Consequently, we define three different setups to allow them
to be evaluated on this task. In the *‘oracle’* setup, only the page
that contains the answer is given as input to the transformer model.
Thus, this setup aims at mimicking the Single page DocVQA task. It shows
the raw answering capabilities of each model regardless of the size of
the input sequences they can accept. So, it should be seen as a
theoretical maximum performance, assuming that the method has correctly
identified the page where the information is found. In the *‘concat’*
setup, the context input to the transformer model is the concatenation
of the contexts of all the pages of the document. This can be considered
the most realistic scenario where the whole document is given as a
single input. It is expected that the large amount of input data becomes
challenging for the baselines. The page corresponding to the predicted
start index is used as the predicted page, except for T5, since being a
generative method it does not predict the start index. Finally, max conf
is the third setup, which is inspired in the strategy that the best
performing methods in the DocCVQA challenge
[tito2021document](tito2021document) use to tackle the big collection of
documents. In this case, each page is processed separately by the model,
providing an answer for every page along with a confidence score in the
form of logits. Then, the answer with the highest confidence is selected
as the final answer with the corresponding page as the predicted answer
page.
For BERT, Longformer, Big Bird and T5 baselines we create the context
following the standard practice of concatenating the OCR words in the
image following the reading (top-left to bottom-right) order. For all
the methods, we use the
Huggingface [wolf2020transformers](wolf2020transformers) implementation and
pre-trained weights from the most similar task available. We describe
the specific initialization weights and training hyperparameters in
[appendix:hyperparameters].
## Baseline results
As we show in
[tab:methods_results], the
method with the best answering performance in the oracle setup (i.e.
when the answer page is provided) is T5, followed by LayoutLMv3, Big
Bird, Longformer and BERT. This result is expected since this setup is
equivalent to the single page document setting, where T5 has already
demonstrated its superior results. In contrast, in the *‘max conf.’*
setup, when the logits of the model are used as a confidence score to
rank the answers generated for each page, T5 performs the worst because
the softmax layer used across the vocabulary turns the logits unusable
as a confidence to rank the answers. Finally, in the concat setup, when
the context of all pages are concatenated Longformer outperforms the
rest, showing its capability to deal with long sequences as seen in
[fig:methods_anls_by_answer_page],
which shows that the performance gap increases as long as the answer
page is placed at the end of the document. The second best performing
method in this setting is T5, which might seem surprising due to its
reduced sequence length. However, looking at
[fig:methods_anls_by_answer_page]
it is possible to see that is good on questions whose answers can fit
into the input sequence, while it is not capable to answer the rest. In
contrast, Big Bird is capable to answer questions that require long
sequences since its maximum input length is 4096 as Longformer.
Nevertheless, it performs worse due to the ITC strategy Big Bird is
using, which do not set global attention to all question tokens and
consequently, as long as the question and the answer tokens become more
distant, it is more difficult to model the attention between the
required information to answer the question.
## Hi-VT5 results
In our experiments we fixed the number of tokens to $M=10$, through
experimental validation explained in detail in
[appendix:num_page_tokens].
We observed no significant improvements beyond this number. We pretrain
Hi-VT5 on hierarchical aware de-noising task on a subset of 200,000
pages of OCR-IDL [biten2022ocr](biten2022ocr) for one epoch. Then, we
Train on MP-DocVQA for 10 epochs with the 2-page shortened version of
the documents and finally, perform the fine-tuning of the decoder and
answer page identification module with the full length version of the
documents for 1 epoch. During training and fine-tuning all layers of the
DiT visual encoder are frozen except a last fully connected projection
layer.
Hi-VT5 outperforms all the other methods both on answering and page
identification in the concat and *‘max conf.’* setups, which are the
most realistic scenarios. In addition, when looking closer at the ANLS
per answer page position (see [fig:methods_anls_by_answer_page]),
the performance gap becomes more significant when the answers are
located at the end of the document, even compared with Longformer, which
is specifically designed for long input sequences. In contrast, Hi-VT5
shows a performance drop in the *‘oracle’* setup compared to the
original T5. This is because it must infer the answer from a compact
summarized representation of the page, while T5 has access to the whole
page representation. This shows that the page representation obtained by
the encoder has still margin for improvement.
Finally, identifying the page where the answer is found at the same time
as answering the question allows to better interpret the method’s
results.
In [tab:methods_results] we can
see that Hi-VT5 obtains a better answer page identification performance
than all the other baseline methods. In addition, in
1 we show that it is capable to
predict the correct page even when it cannot provide the correct answer.
Interestingly, it answers correctly some questions for which the
predicted page is wrong, which means that the answer has been inferred
from a prior learned bias instead of the actual input data. We provide
more details by analyzing the attention of Hi-VT5 in
[appendix:attention_viz].
# Ablation studies [sec:ablation]
To validate the effectiveness of each feature proposed in Hi-VT5, we
perform an ablation study and show results in
[tab:ablation_results].
Without the answer page prediction module the model performs slightly
worse on the answering task, showing that both tasks are complementary
and the correct page prediction helps to answer the question. The most
significant boost comes from the hierarchical de-noising pre-training
task, since it allows the tokens to learn better how to represent the
content of the document. The last fine-tuning phase where the decoder
and the answer page prediction module are adapted to the 20 pages
maximum length of the MP-DocVQA documents, is specially important for
the answer page prediction module because the classification layer
predicts only page indexes seen during training and hence, without
finetuning it can only predict the first or the second page of the
documents as the answer page. Finally, when removing the visual features
the final scores are slightly worse, which has also been show in other
works in the
literature [huang2022layoutlmv3](huang2022layoutlmv3), [biten2022latr](biten2022latr), [powalski2021going](powalski2021going),
the most relevant information is conveyed within the text and its
position, while explicit visual features are not specially useful for
grayscale documents.
# Conclusions [sec:conclusions]
In this work, we propose the task of Visual Question Answering on
multi-page documents and make public the MP-DocVQA dataset. To show the
challenges the task poses to current DocVQA methods, we convey an
analysis of state-of-the-art methods showing that even the ones designed
to accept long sequences are not capable to answer questions posed on
the final pages of a document. In order to address these limitations, we
propose the new method Hi-VT5 that, without increasing the model
complexity, can accept sequences up to 20,480 tokens and answer the
questions regardless of the page in which the answer is placed. Finally,
we show the effectiveness of each of the components in the method, and
perform an analysis of the results showing how the answer page
prediction module can help to identify answers that might be inferred
from prior learned bias instead of the actual input data.
# Acknowledgements [acknowledgements]
This work has been supported by the UAB PIF scholarship B18P0070, the
Consolidated Research Group 2017-SGR-1783 from the Research and
University Department of the Catalan Government, and the project
PID2020-116298GB-I00, from the Spanish Ministry of Science and
Innovation.
[^1]: [rrc.cvc.uab.es/?ch=17](https://rrc.cvc.uab.es/?ch=17)
[^2]: [github.com/rubenpt91/MP-DocVQA-Framework](https://github.com/rubenpt91/MP-DocVQA-Framework)
[^3]:
[^4]: In the MP-DocVQA task, questions are posed
over multi-page documents where methods are required to understand the
text, layout and visual elements of each page in the document to
identify the correct page (blue in the figure) and answer the
question.
| **Method** | **Accuracy** | **ANLS** | **Ans. Page Acc.** |
|:------------|:------------:|:--------:|:------------------:|
| Hi-VT5 | 48.28 | 0.6201 | 79.23 |
| –2D-pos | 46.12 | 0.5891 | 78.21 |
| –Vis. Feat. | 46.82 | 0.5999 | 78.22 |
| –APPM | 47.78 | 0.6130 | 00.00 |
| –Pretrain | 42.10 | 0.5864 | 81.47 |
| –Fine-tune | 42.86 | 0.6263 | 55.74 |
**ablation studies**. We study the effect of removing different
components independently from namely the 2D position embedding (2D-pos),
visual features (Vis. Feat.), the answer page prediction module (APPM),
the pretraining (Pretrain) and the last fine-tuning (Fine-tune) phase of
the decoder and answer page prediction module.
# construction process [appendix:construction_details]
As described in
[subsec:dataset_creation],
the source data of the dataset is the
SingleDocVQA [mathew2021docvqa](mathew2021docvqa) dataset. The first row of
[tab:construction_process_stats]
shows the number of documents, pages and questions in this dataset. The
first step to create the dataset was to download and append to the
existing documents their previous and posterior pages, increasing the
number of page images from 12,767 to 64,057, as shown in the second row
of [tab:construction_process_stats].
However, not all questions are suited to be asked on multi-page
documents. Therefore, we performed an analysis based on manually
selected key-words that appear in the questions, searching for those
questions whose answer becomes ambiguous when they are posed over a
document. Some of the selected key-words are shown in table
[tab:key-word_analysis],
along with some examples of potentially ambiguous questions containing
those key-words. The most clear example is with the word ’document’.
When looking at each document page separately, we can observe that many
times they start with a big text on the top that can be considered as
the title, which is actually the answer in the single page DocVQA
scenario when the question asks about the title of the document.
However, this pattern is repeated in every page of the document, making
the question impossible to answer when multiple pages are taken into
account. Moreover, even if there is only one page with a title, the
answer can still be considered wrong, since the title of the document is
always found in the first page like in the example in
[fig:task]. On the other hand, when we
analyzed more closely other potentially ambiguous selected key-words
such as ’image’, ’appears’ or ’graphic’ we found out that the answers
were not always ambiguous and also the amount of questions with those
words was negligible compared to the entire dataset. Thus, we decided to
keep those questions in our dataset. Finally, we found that the key-word
’title’ was mostly ambiguous only when it was written along with the
word ’document’. Hence, we decided to remove only the questions with the
word ’document’ in it, while keeping all the rest. This filtered
version, which is represented in the third row of
[tab:construction_process_stats]
is the dataset version that was released and used in the experiments.
Nevertheless, it is important to notice that not all the questions in
are posed over multi-page documents. We keep the documents with a single
page because they are also a possible case in a real life scenario.
However, as showed in the fourth row of
[tab:construction_process_stats],
the questions posed over multiple pages represent the 85.95% of all the
questions in the dataset.
# Number of tokens [appendix:num_page_tokens]
embeds the most relevant information from each page conditioned by a
question into $M$ tokens. However, we hypothesize that contrary to
BERT [devlin2018bert](devlin2018bert), which represents a sentence with a
single token, will require more than one token to represent a whole
page, since it conveys more information. Consequently, we perform an
experimental study to find the optimum number of tokens to use. We start
by defining the maximum number of tokens $M$ that can be used, which is
limited by the decoder input sequence length $S$, and the number of
pages $P$ that must be processed. Formally,
$$M=int\left(\frac{S}{P}\right) \label{eq:page_tokens_tradeoff}
\vspace{-2mm}$$ We can set $M$ as an hyperparameter to select depending
on the number of pages we need to process, where in the extreme cases we
can represent a single page with 1024 tokens, or a 1024 page document
with a single token for each page.
Constraining to the 20 pages documents scenario of , the maximum
possible number of tokens $M$ would be 51. We performed a set of
experiments with different tokens to find the optimal value. As we show
in 1, the model is able to answer
correctly some questions even when using only one or two tokens.
However, the performance increases significantly when more tokens are
used. Nevertheless, the model does not benefit from using more than 10
tokens, since it performs similarly either with 10 or 25 tokens.
Moreover, the performance decreases when using more. This can be
explained because the information extracted from each page can be fully
represented by 10 tokens, while using more, not only does not provide
any benefit, but also makes the training process harder.
# Document pages during training [appendix:train_doc_pages]
As described in [sec:method], it is not feasible to
train with 20 page length documents due to training resource
limitations. However, as we show in
[tab:train_pages], even though the
model performs significantly worse when trained with a single page, the
returns become diminishing when training with more than 2. Thus, as
explained in [sec:method] we decided to use 2 pages
in the first stage of training.
# Hyperparameters [appendix:hyperparameters]
# Page identification accuracy by answer page position
In [fig:methods_ret_prec_by_answer_page]
we show the answer page identification accuracy of the different
baselines and the proposed method, as a function of the page number of
the answer. The overall performance follows a similar behavior as the
answer scores. is the baseline that performs the best in the concat
setting, and and the performance gap between this and the rest of the
baselines becomes more significant as the answer page is located in the
final pages of the document. However, outperforms all the baselines by a
big margin.
# attention visualization [appendix:attention_viz]
To further explore the information that embeds into the tokens, we show
the attention scores for some examples in . The attention of
1, corresponds to the first
token, which usually performs a global attention over the whole document
with a slight emphasis on the question tokens, which provides a holistic
representation of the page. Other tokens like in
3 focuses its attention over
the other , and question tokens. More importantly, there is always a
token that focuses its attention to the provided answer like in Figs.
2 and
4.