Overview de toutes les approches d'explicabilité des LLMs
Nous identifions 4 familles d’approches d’explicabilité des LLMs:
- celles de “training data attribution”, identifiant les données d’entraînement qui ont un fort impact (positif ou négatif) sur la génération du LLM, à l’aides des fonctions d’influence, décrites en détail dans ce post,
- celles de “context attribution”, identifiant quelles parties des données d’entrée (input) a un impact sur quelle partie de la génération du LLM (à l’aide des cartes de saillance et des cartes d’attention notamment),
- celles d’explicabilité mécanistique (model inference), consistant à trouver les circuits dans le LLM qui capturent certains concepts, avec des circuits identifiés par approches d’observation de l’espace latent (ACP sur les états cachés du LLM à différents niveaux du réseau), de dictionnary learning pour visualiser quels concepts sont capturés par chaque neurones / groupes de neurones, ou par “patching”, en modifiant certains états cachés pour voir l’effet sur le modèle.
- On peut considérer également une 4ème famille d’approches en étudiant la génération des modèles, notamment des modèles dits de “raisonnement” (thinking) qui détaillent leur raisonnement dans la réponse qu’ils fournissent.
Ces 4 familles sont détaillées dans le papier Interpretation Meets Safety: A Survey on Interpretation Methods and Tools for Improving LLM Safety:

Explicabilité par Training Data Attribution
Attribution basée sur la représentation
Compare la similarité entre les vecteurs latents de chaque exemple d’entraînement et la sortie
- Références : Yeh et al. (2018), Tsai et al. (2023), Su et al. (2024b), He et al. (2024b)
- Limitation : N’établit pas de causalité (Cheng et al., 2025a)
Méthodes basées sur le gradient
Estiment la sensibilité des paramètres du modèle aux exemples individuels
- TracIn (Pruthi et al., 2020) : Trace l’influence en mesurant l’alignement entre les gradients
- Variantes améliorées :
- Han & Tsvetkov (2021, 2022)
- Yeh et al. (2022)
- Wu et al. (2022)
- Ladhak et al. (2023)
- Adaptations pour LLM : Xia et al. (2024), Pan et al. (2025b)
Méthodes basées sur les fonctions d’influence
Estiment comment la pondération d’un exemple affecte les paramètres et prédictions
- Améliorations de scalabilité :
- Han et al. (2020)
- Ren et al. (2020)
- Barshan et al. (2020)
- Guo et al. (2021)
- Extensions aux LLM : Grosse et al. (2023), Kwon et al. (2024), Choe et al. (2024)
- Débat : Efficacité contestée due aux hypothèses fortes (convexité du modèle)
Data Shapley
Estime la contribution en approximant l’effet de suppression/ajout de données
- Références : Ghorbani & Zou (2019), Jia et al. (2019), Feldman & Zhang (2020)
- Applications LLM : Wang et al. (2024b, 2025a)
- Limitation : Coût computationnel élevé, limité aux petits modèles
Les limites de ces approches TDA sont:
- Inaccessibilité des données d’entraînement propriétaires (Bommasani et al., 2021)
- Scalabilité computationnelle
Explicabilité par Context Attribution
Attribuer les sorties du modèle à des tokens d’entrée spécifiques pour comprendre leur influence.
Dans ce papier: A Close Look at Decomposition-based XAI-Methods for Transformer Language Models, 2025, ils comparent plusieurs approches:

Méthodes basées sur l’attention
Poids d’attention plus élevés = plus grande importance
- Références fondamentales :
- Wiegreffe & Pinter (2019)
- Abnar & Zuidema (2020)
- Kobayashi et al. (2020)
- Agrégation : Moyenne, max (Tu et al., 2021), attention rollout (Abnar & Zuidema, 2020)
- Applications sécurité : Détection d’hallucinations (Dale et al., 2023; Chuang et al., 2024)
Ces approches basées sur l’attention peuvent être utilisées pour “forcer” le modèle à porter / ne pas porter leur attention sur certains tokens:
- Incitation des LLM à porter attention aux tokens de sécurité
- Suppression des tokens déclencheurs de jailbreak (Pan et al., 2025a)
- Manipulation de l’attention vers tokens fiables (Zhang et al., 2024b)
Méthodes basées sur les vecteurs
Décomposent les vecteurs latents en contributions des tokens d’entrée (ACP)
- Références clés :
- Kobayashi et al., Incorporating Residual and Normalization Layers into Analysis of Masked Language Models, 2021
- Modarressi et al. GlobEnc: Quantifying Global Token Attribution by Incorporating the Whole Encoder Layer in Transformers, 2022
- Ferrando et al. Measuring the Mixing of Contextual Information in the Transformer, 2022, Ferrando et al., Explaining How Transformers Use Context to Build Predictions, 2023

- Applications LLM modernes : Arras et al., A Close Look at Decomposition-based XAI-Methods for Transformer Language Models, 2025

- Limitation : Nécessitent des conceptions spécifiques au modèle
Méthodes basées sur la perturbation
Modifient les tokens et observent les changements
- Types de perturbations :
- Altération de vecteurs latents Deiseroth et al., AtMan: Understanding Transformer Predictions Through Memory Efficient Attention Manipulation, 2023
- Masquage d’embeddings Jacovi et al., Contrastive Explanations for Model Interpretability, 2021

- Remplacement de tokens Finlayson et al., Causal Analysis of Syntactic Agreement Mechanisms in Neural Language Models, 2021
- Contrefactuels Bhattacharjee et al., Towards LLM-guided Causal Explainability for Black-box Text Classifiers, 2023
- Valeur de Shapley : Horovicz & Goldshmidt, TokenSHAP: Interpreting Large Language Models with Monte Carlo Shapley Value Estimation, 2024, Mohammadi, Explaining Large Language Models Decisions Using Shapley Values, 2024

Méthodes basées sur le gradient
Calculent le gradient de la sortie par rapport aux embeddings d’entrée
- Évolution :
- Modèles classiques : Simonyan et al. (2014), Bach et al. (2015)
- LLM : Barkan et al., Improving LLM Attributions with Randomized Path-Integration, 2024, Pan et al., The Hidden Dimensions of LLM Alignment: A Multi-Dimensional Analysis of Orthogonal Safety Directions, 2025
Voir le code: https://github.com/BMPixel/safety-residual-space/blob/main/src/experiments/plrp_relevance_tokens.py:

- Explications contrastives : Jacovi et al. (2021), Sarti et al. (2024)
2.5 Autres approches
- Similarité : Comparaison embeddings finaux/tokens d’entrée Ferrando et al., Measuring the Mixing of Contextual Information in the Transformer, 2022 avec leur approche ALTI:

- Basées sur les prompts : Instructions aux LLM pour identifier les tokens influents Wang et al., DELMAN: Dynamic Defense Against Large Language Model Jailbreaking with Model Editing, 2025

- Optimisation : Recherche d’attributions maximisant les métriques d’interprétabilité Zhou & Shah, The Solvability of Interpretability Evaluation Metrics, 2023
Explicabilité mécanistique: comprendre quelle partie du LLM est responsable de quel concept
Le papier Open Problems in Mechanistic Interpretability
Sondes sur l’espace latent
Projection de l’espace latent calculé sur différents concepts.
Hypothèse de base : Représentation linéaire - les concepts sont encodés comme directions linéaires (cf ACP).
Méthodes principales :
- Vecteurs moyens : Calcul pour données avec/sans concept spécifique
- Applications : hallucinations (Liu et al., On the Universal Truthfulness Hyperplane Inside LLMs, 2024), jailbreaks (Arditi et al. Refusal in Language Models Is Mediated by a Single Direction, 2024)
- Réduction dimensionnelle : PCA, SVD pour découvrir les axes de comportements non sûrs
- Références : Duan et al., Do LLMs Know about Hallucination? An Empirical Investigation of LLM’s Hidden States, Ball et al. (2024), Pan et al. (2025a)
- Classificateurs de sondage : Prédiction de propriétés liées à la sécurité
- Succès : Détection d’hallucinations Burns et al., Discovering Latent Knowledge in Language Models Without Supervision, 2022, Truth is Universal: Robust Detection of Lies in LLMs, Bürger et al., 2024, jailbreaks Zhou et al., How Alignment and Jailbreak Work: Explain LLM Safety through Intermediate Hidden States, 2024,
- Améliorations : Classificateurs non-linéaires (Azaria & Mitchell, 2023), apprentissage contrastif (He et al., 2024a)
Exemple de Truth is Universal: Robust Detection of Lies in LLMs, Bürger et al., 2024 pour détecter les hallucinations du modèle ou quand le modèle “ment”: Ils font une ACP pour essayer de prouver qu’une partie du réseau encode les faits vrais (que le modèle a appris) et faux (que le modèles n’a pas appris):
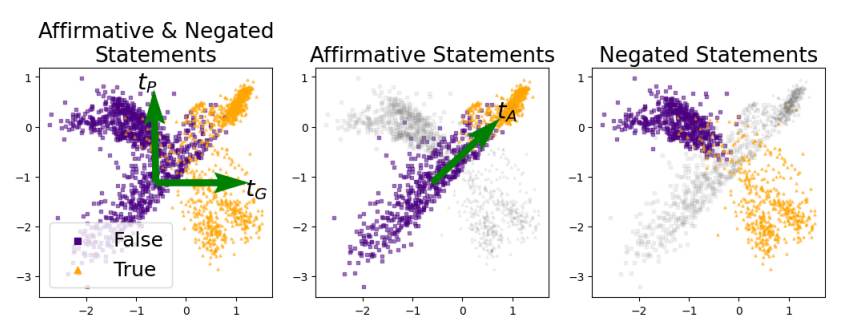
En gros ils font l’ACP sur les activations du dernier token de chaque phrases (le “.”). puisque le modèle est autorégressif, ce dernier token encode la globalité de la phrase. Pour un modèle non-autorégressif, comme BERT, on pourrait faire ça sur le token [CLS] par exemple, qui a le même rôle normalement (utilisé d’ailleurs pour la classification). Et ils ont affiché les activations sur un ensemble de données comptenant des phrases vraies (violet) et fausses (jaunes), qu’ils avaient taggé au préalable.
Et dans ce papier, ils voient que c’est la layer 12 qui sépare le mieux les faits “vrais” et “faux”, ie appris et non appris:
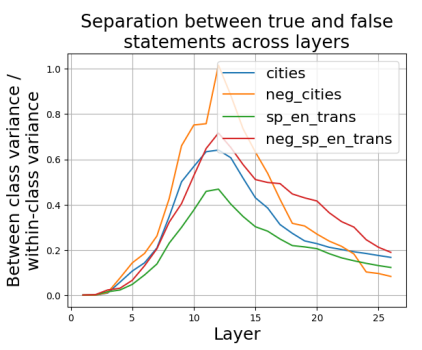
Cet autre papier Liu et al., On the Universal Truthfulness Hyperplane Inside LLMs, 2024 propose cette analyse:

Cette approche d'explicabilité permet de "corriger" le modèle, notamment en dirigeant les Vecteurs Latents:
- Ingénierie de représentation : ajout de vecteurs de sécurité identifiés
- Applications : hallucinations Li et al., Inference-Time Intervention: Eliciting Truthful Answers from a Language Model, 2023, jailbreaks Turner et al.,Steering Language Models With Activation Engineering, 2023
Exemple des figures de ces papiers pour “corriger” le modèle selon ces direction:
Le papier Inference-Time Intervention: Eliciting Truthful Answers from a Language Model propose cette approche:

Le papier Steering Language Models With Activation Engineering propose cette approche:

Le papier Refusal in Language Models Is Mediated by a Single Direction qui corrige les poids du modèle de la direction $r$ identifiée comme générant des jailbreaks : $x’ = x - rr^Tx$. L’ablation directionnelle « met à zéro » la composante suivant $r$ pour chaque activation du flux résiduel $x \in \mathbb{R}^{d_{\text{model}}}$.
Perturber certains neurones / couches et Évaluer l’Impact
Analyse basée sur le gradient
- Calcul des gradients de sortie par rapport aux paramètres
- Applications : Conflits de connaissances RAG (Jin et al., 2024), générations biaisées (Liu et al., 2024b)
Knockout de composants
- Ablation de couches, têtes d’attention ou paramètres
- Localisation de composants responsables :
- Hallucinations : Jin et al. (2024), Li et al. (2024a)
- Jailbreaks : Zhao et al. (2024d), Wei et al. (2024)
- Biais : Yang et al. (2023b), Ma et al. (2023)
Patching d’activation
- Inspiré de l’analyse de médiation causale (Pearl, 2001)
- Remplacement d’activations intermédiaires
- Applications : Hallucinations (Monea et al., 2024), biais (Vig et al., 2020)
Circuits computationnels
- Extraction de graphes : nœuds = composants, arêtes = flux d’information
- Références : Geiger et al. (2021), Elhage et al. (2021)
- Path patching : Wang et al. (2023), Goldowsky-Dill et al. (2023)
Déchiffrer les Vecteurs Latents à partir de concepts
Analyse des neurones individuels
- Identification des entrées activant fortement un neurone
- Références : Geva et al. (2021), Foote et al. (2023)
- Défi : Polysémantique des neurones (Arora et al., 2018)
Autoencodeurs épars (SAE)
- Objectif : Désentrelement des concepts superposés
- Architecture : Encodeur → vecteur épars de concepts → Décodeur
- Références clés :
- Fondamentaux : Sharkey et al. (2022), Bricken et al. (2023)
- Améliorations : Rajamanoharan et al. (2024a), Templeton et al. (2024)
- Applications sécurité :
- Hallucinations : Ferrando et al. (2025), Theodorus et al. (2025)
- Jailbreaks : Härle et al. (2024), Muhamed et al. (2025)
- Biais : Hegde (2024), Zhou et al. (2025a)
Logit lens
- Projection des vecteurs latents intermédiaires sur l’espace vocabulaire
- Origine : nostalgebraist (2020), Elhage et al. (2021)
- Améliorations : Belrose et al. (2023), Din et al. (2023)
- Applications : Mécanismes de stockage/rappel (Yu et al., 2023), hallucinations (Yu et al., 2024b)
Ces approches permettent de “corriger” le modèle, par exemple en supprimant de neurones risqués via SAE (Soo et al., 2025).
Explicabilité par Génération de Raisonnement du LLM
Explorer comment les LLM peuvent interpréter leurs propres sorties en exprimant le raisonnement sous-jacent.
Raisonnement en génération**
- LLM incités/entraînés à générer réponses + justifications
- Références fondamentales :
- Camburu et al. (2018)
- Rajani et al. (2019)
- Marasovic et al. (2022)
- Estimations d’incertitude : Kadavath et al. (2022), Amayuelas et al. (2024)
Chain-of-Thought (CoT)
Génération d’étapes de raisonnement intermédiaires
- Référence originale : Wei et al. (2022)
- Variantes :
- Raisonnement complexe : Yao et al. (2023), Besta et al. (2024)
- Amélioration de la fidélité : Qu et al. (2022), Lyu et al. (2023)
- Limitations : Explications peu fiables (Gao et al., 2023), nécessitant vérification (Weng et al., 2023)
Explications post-hoc
- Évaluation/explication après génération
- Division des réponses en affirmations factuelles
- Vérification contre les connaissances du modèle
- Applications : Hallucinations (Dhuliawala et al., 2024), biais (Li et al., 2024b)
Enjoy Reading This Article?
Here are some more articles you might like to read next: